
mysql索引解析
1、基本概念
数据读写性能主要是IO次数,单次从磁盘读取单位是页,即便只读取一行记录,从磁盘中也是会读取一页的()单页读取代价高,一般都会进行预读)
(1)扇区是磁盘的最小存储单元
(2)块是文件系统的最小存储单元,比如你保存一个记事本,即使只输入一个字符,也要占用4KB的存储,这就是最小存储的意思
(3)页是B+树的最小存储单元
| 单元 | 谁的(归属) | 最小大小 |
|---|---|---|
| 扇区 | 磁盘 | 512B |
| 块 | 文件系统 | 4K |
| 页 | B+ | 16K |
2、有无索引的读取数据比较
无索引情况下,会直接在磁盘中读取经过多次IO才能找到需要的数据,首先读取这个扇区的数据,需要将磁头放到这个扇区上方,这个过程叫做寻道,花费时间叫做寻道时间,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗时叫旋转耗时,磁盘读取数据时间包含寻道和旋转时间。
有索引情况下,会读取索引数据经过几次IO就能找到需要的数据。下面计算通过索引(B+TREE,主键id采用bigint占用8字节,一行数据占用1KB)计算:
(1)第一层
一个页16K,每一个索引键的大小8字节(bigint)+6字节(指针大小),因此第一层可存储16*1024/14=1170个索引键。
(2)第二层
第二层只存储索引键,能存储多少个索引键呢?1170(这么多个页,有第一层延伸的指针)1170(每页的索引键个数,跟第一步计算一致)=1368900
如果第二层存储数据呢?1170(这么多个页,有第一层延伸的指针)16(16KB的页大小/1KB的数据大小)=18720,也就是能存储一万多条数。
(3)第三层
直接看三层能存储多少数据?1170*1170*16=21902400,是不是很强大,此处应该有掌声和鲜花,3次IO就可以查询到2千多万左右的数据,也就是这么大的数据量如果通过主键索引来查找是很快,这就是explain一个sql时,type=const为什么性能是最优的。
3、mysql索引类型
表级别索引设置
(1)应用层:唯一索引,普通索引,复合索引
(2)存储结构:BTree(BTree或B+Tree)、Hash索引,full-index全文索引,R-Tree索引。
(3)数据物理顺序与键值逻辑:聚集索引,非聚集索引。
聚集索引的B+Tree中的叶子节点存放的是整张表的行记录数据。辅助索引与聚集索引的区别在于辅助索引的叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键,即主键。
聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法。特点是存储数据的顺序和索引顺序一致。 一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引。
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
4、B-TREE
(1)特点
B-树相对B树,B-树的各层节点要存储数据,导致每页能够容纳的节点就很少,直接导致树深度加大
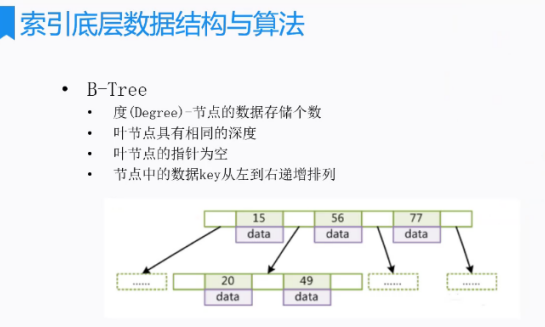
(2)实例
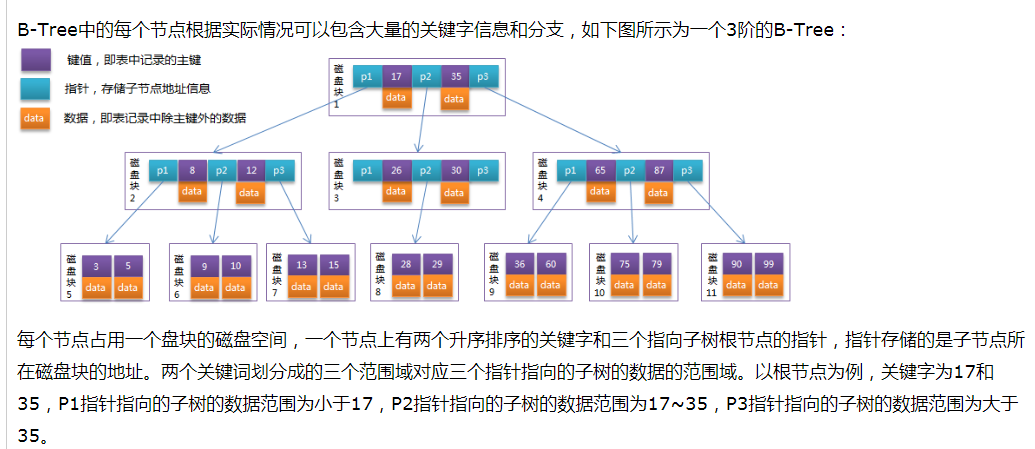

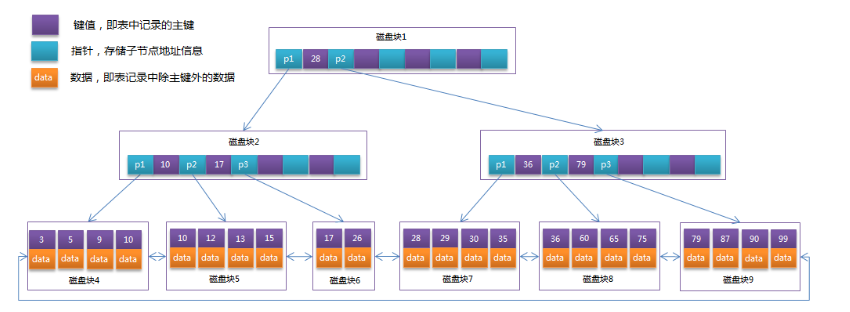
5、B+TREE
(1)特点

(2)实例

6、MyISAM的索引结构
MyISAM有三个文件,.frm,MYD,MYI分别是表结构,表数据,表索引。先查找主键值对应的value,然后根据value查找对应的行

7、innodb索引结构
InnoDB存储引擎就是用B+Tree实现其索引结构。由frm,ibd文件组成,主键索引存储数据,非主键索引存储主键数据
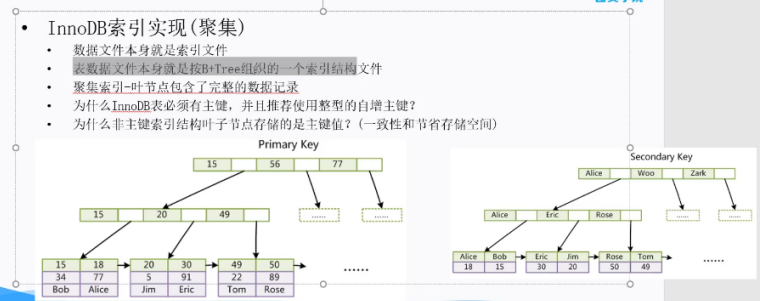
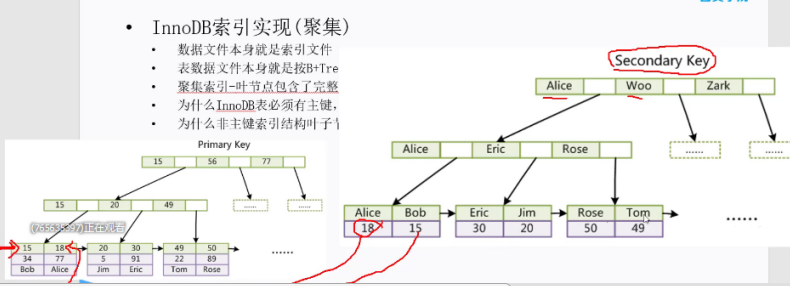
8、innodb和myisam主键索引和其他索引区别


 浙公网安备 33010602011771号
浙公网安备 33010602011771号