

mysql 主要是由 server 层和存储层两部分构成的。server 层主要包括连接器、查询缓存,分析器、优化器、执行器。存储层主要是用来存储和查询数据的,常用的存储引擎有 InnoDB、MyISAM,MySQL 5.5.5版本后使用 InnoDB 作为默认存储引擎。
mysql 中的 InnoDB 在底层是采用 B+ 树这种数据结构来存储数据的。
一、几种常见的数据结构
mysql 的索引主要是为了提高查询效率的,那一定得找一个合适的数据结构来存储数据,哈希表、数组、二叉搜索树这三种常见的数据结构都可以提高查询效率。
-
哈希表
哈希表就是一种以键值对来存储数据的结构,你可以通过一个 key 就可以很快的查询出对用的 value 值。哈希表主要是利用了数组的随机访问特性,实现思想主要是通过一个哈希函数把 key 转换成一个哈希值,这个哈希值就对应数组中的某个下标。
但是由于哈希表是无序的,区间查询效率会非常的慢,所以哈希表通常只用于查询单个值。
-
有序数组
数组就好说了,数组具有连续性和随机访问特性,因此数组都能很高效的进行单个等值查询和区间查询,但是 mysql 不仅仅是查询数据,还会有插入和删除数据的操作。在有序数组中插入或删除一个数据会需要批量移动数组中其他数据,这是一个不小的消耗,影响性能。因此有序数组适合处理静态数据,比如一些过往的不会再修改的数据。
在这里你可能会问,既然哈希表其实也是利用了数组的特性,那有了数组为啥还需要哈希表呢。是因为数组下标 key 只能是数字,而哈希表可以支持字符串 key,哈希函数可以把这个 key 转换成一个数组下标。
同时,不同的 key 如果通过哈希函数转换成了相同的数组下标,这就会造成冲突,在哈希表中一般会通过再拉出一个链表来保存这个冲突的值。
-
二叉搜索树
注意,二叉搜索树和二叉树不一样,二叉树是指每个节点的左儿子小于父节点,父节点又小于右儿子,即二叉搜索树的中序遍历就是一个有序序列。
由于索引不仅仅是存在内存中,还会存储在硬盘中,因此就会涉及到 IO 性能了,就要求树的高度不能太高。实际上 B+ 树就是通过二叉搜索树推演改进的。
- B+ 树
B+ 树就是一种多叉树,是由二叉搜索树不断演变过来的,为了满足区间快速查询,B+ 树的叶子节点通过双向链表串联起来。
这里使用双向链表是为了支持顺序和倒序查询,虽然双向链表相对于单向链表虽然会浪费一倍的指针空间,但是在硬盘中这点空间几乎微乎其微,用这点空间换时间是一件很值得的事情。
B+ 树的子节点数不超过 m 个,同时也不能少于 m/2 个,一旦超过就需要分裂,一旦少于就需要合并。
小结
哈希表适合等值查询,由于是无序的,区间查询会很慢。有序数组适合等值和区间查询,但是数组具有连续性,插入和删除操作都可能需要移动其他元素。二叉搜索树由于树的高度,区间查询需要中序遍历,都会导致查询效率很慢。
注意,在一些文章中经常会把 B+ 树说成 B 树或者 B-tree,这其实是错误的,B 树和 B+ 是两种不同的树,B+ 树是 B 树的一个优化。
而且 B- 树其实也就是 B 树,这个符号并不是加减中的减号,并不是所谓的 "B 减树",只是一个连接符号而已。
二、索引为什么要保存在硬盘中
服务器存储一般分内存和硬盘,内存的大小相对于硬盘来说是很小的。内存的访问速度是纳秒级别的,非常快,而硬盘的访问速度相对内存来说就比较慢了。
不管是访问内存还是硬盘数据,操作系统都是按数据页来读取数据的,即每访问一次硬盘或内存,只读取一页大小的数据,一页的大小约等于 4 kb,向硬盘读取数据的操作叫做磁盘 IO。
看到这里你或许会知道了 mysql 索引为啥不保存在内存中了吧,一方面是虽然内存访问速度快但容量一般都比较小,存不了多少数据,再一个 mysql 需要让数据持久化,如果服务器断电或异常重启会导致数据丢失。
三、怎么让二叉搜索树支持区间查询
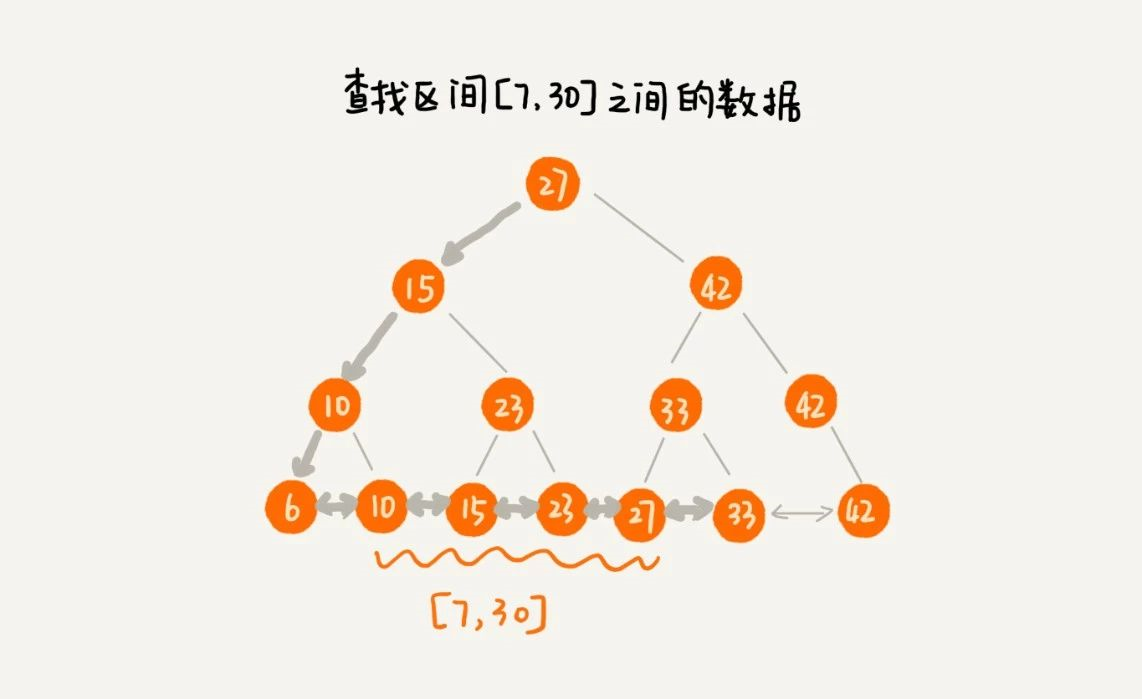
为了让二叉搜索树也支持区间查询,我们把二叉树的叶子节点通过一个双向链表来连接,并且这个链表是有序的,注意叶子节点和普通节点是不一样的,注意看下面的图。

因此只需要先找到区间的起始值在链表中的位置,然后再往后遍历,直到遍历到区间的终止值,即可完成区间查询。如下图查找 7-30 这个区间的数据。
四、如何提升查询速度
因为二叉搜索树保存在硬盘中,我们每访问一个节点,就对应着一次硬盘 IO 操作,上面有说过向硬盘读取数据速度比较慢。因此树的高度就代表硬盘 IO 操作的次数,所以我们要想办法让树的高度变矮,来减少硬盘 IO。
要想树变矮一些,那就把树多分一些叉来吧,变成一颗多叉树。下面分别用二叉树和五叉树来存储 16 条数据,看下树的高度又怎样的变化。
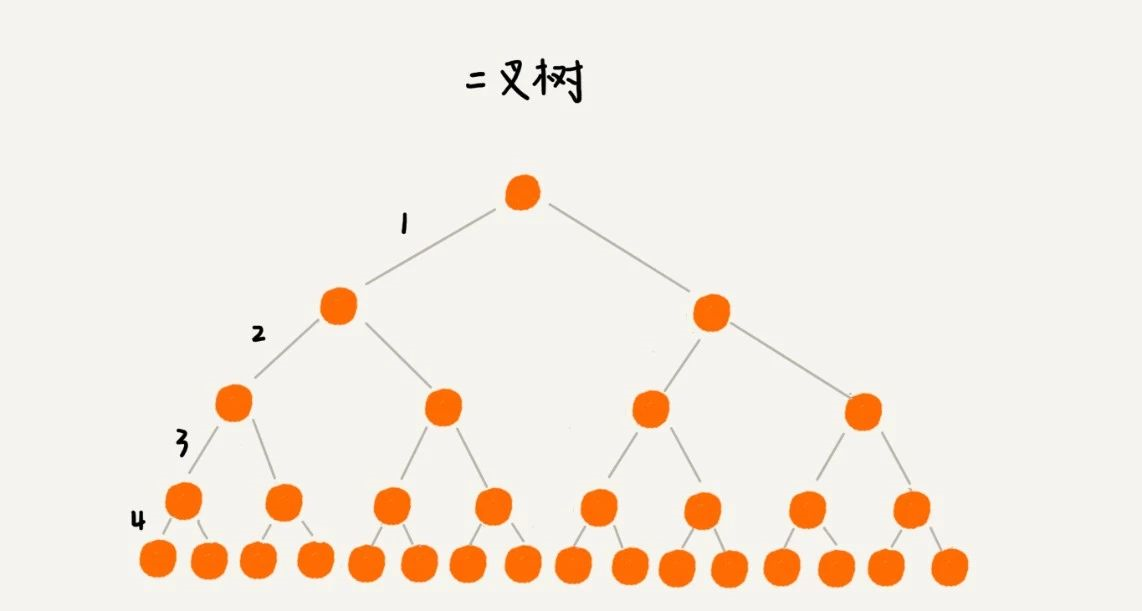
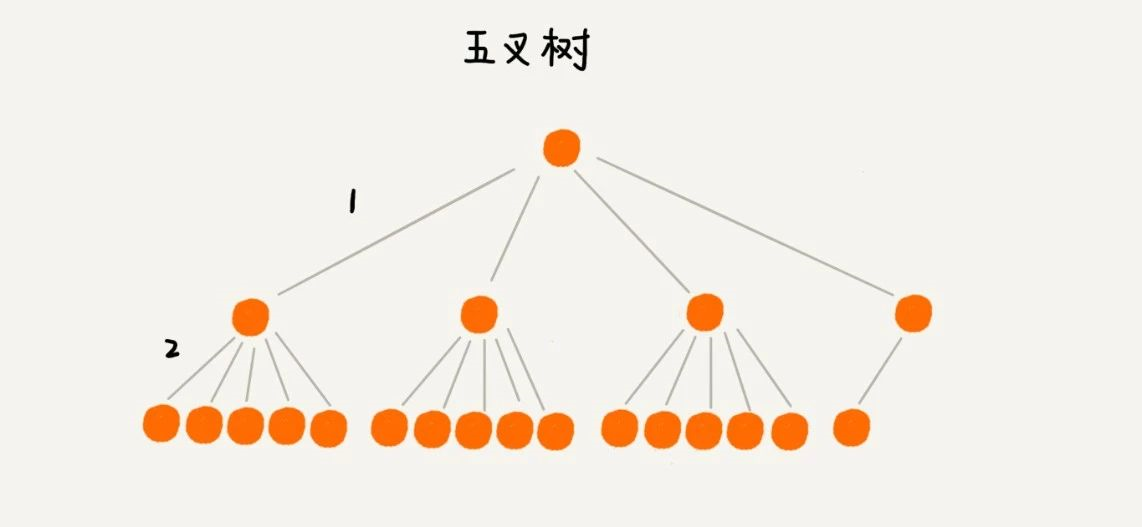
根节点一般存储在内存中,普通节点和叶子结点保存在硬盘中,因此显然二叉树的高度为 5,需要 5 次硬盘 IO,而五叉树的高度为 2,查询一个数据只需要 2 次硬盘 IO。
那么问题又来了,对于相同的数据量,是不是构建的多叉树的叉越多越好呢,因为叉越多树的高度就会越矮?
上面有说过操作系是按数据页大小来访问硬盘的,每次 IO 只读取一个数据页大小的数据,如果要读取的数据大于一个数据页,则会导致多次 IO。因此我们要尽量让每个节点的数据大小刚好等于一个数据页大小,即每访问一个节点只需一次 IO。
五、插入和删除数据怎么办
这里我们把多叉树称作 m 叉树,这个 m 值是通过数据页大小和节点数计算出来的,尽量保证每访问一个节点就是一个数据页的大小,而且每个节点最多只有 m 个子节点。
现在我们要往数据库中插入新的数据,即要往 m 叉树中插入新的节点,这可能就会导致某些节点的子节点个数大于 m,也就会导致该节点大小大于一个数据页,访问该节点就需要多次 IO。
为了解决这个问题,m 叉树会把该节点分裂成两个节点,然后改分裂操作又会导致其父节点的子节点数可能超过 m,我们再用同样的方法分裂节点,一直影响到根节点。
删除操作也是类似的思想,如果有频繁的删除节点,就会导致某些节点的子节点过少,就会浪费存储空间并降低查询效率。所以就要想办法让这些节点合并起来,合并的话就有可能会导致其子节点数超过 m,超过的话就再用上面的分裂方法分裂子节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号