

数据操作常用命令sort、paste、awk
场景:很多时候我们需要对已经有的文件进行排序、拼接或者截取其中的部分列,对于使用mac的同学可以快速通过Linux命令来实现
1、对于文件中指定列进行排序然后输入到新文件中
sort -n -k 3 -t , allTopData.csv -o allTopData2.csv
2、两个相同行数的文件进行拼接并输出到新文件中
paste allTopData2.csv driverToken2.csv > result.csv
3、截取文件部分列并输出到新文件中
awk -F "," '{print $1, $3 }' result.csv > completefile.csv
其实也可以打乱列的顺序
awk -F "," '{print $3,$2,$1}' result.csv > completefile333.csv
其他:
1、如果是取数据集可参考:https://blog.csdn.net/dezi1550/article/details/101481353
集合操作 1. 取出两个文件的并集(重复的行只保留一份)
cat file1 file2 | sort | uniq
2. 取出两个文件的交集(只留下同时存在于两个文件中的文件)
cat file1 file2 | sort | uniq -d
3. 删除交集,留下其他的行
cat file1 file2 | sort | uniq -u
2、结果输出到文件
查询结果输出到文件
1. 仅转向不显示
(1)ls > test.txt 把输出转向到指定的文件,如文件已存在的话也会重新写入,文件原内容不会保留
(2)ls >> test.txt 是把输出附向到文件的后面,文件原内容会保留下来
2. 转向同时显示
ls | tee ls_tee.txt 把输出转向到指定的文件,同时显示,原文件内容不保存
ls | tee ls_tee.txt 原文件内容保存
3、文件打乱操作
将datadaluan.csv文件行数打乱,然后输入到datadaluan2.csv文件中
shuf datadaluan.csv -o datadaluan2.csv
4、将文件分割成多个文件
有时候我们打乱文件后需要分割成多个文件,分割文件可以按照大小来分割,也可以按照行数来分割
按照行来切割:split -l 50 datadaluan2.csv ./datadaluan2.
按照大小来切割:split -b 10k datadaluan2.csv ./datadaluan2.
问题:最后的结果文件不能指定格式,比如我想要csv文件,如果是下面这种格式的我可能就不能直接打开了,但是通过Linux命令是可以的
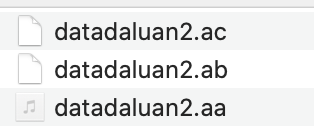
思考:如何合并文件呢?这个在我们日常的工作中有啥作用不?
5、同一文件删除行重复数据
参考:https://blog.csdn.net/weixin_43314519/article/details/109741706
6、同一行中某个字段重复的删除
7、包含指定字段的行删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号