


1. 为什么要引入Yarn和Spark。
答:(1)因为Yarn通用资源管理系统可以为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
(2)因为Spark基于内存运算,速度快;支持多语言;通用,可以处理批处理、交互式查询、实时流、机器学习和图计算;兼容性好,可以使用Hadoop的YARN作为它的资源管理和调度器。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
答:Spark生态系统包括,
(1)Spark Core,分布式大数据处理框架;
(2)Spark Streaming,数据流处理;
(3)Spark SQL,SQL查询;
(4)MLlib,机器学习;
(5)GraphX,图计算。
3. 用图文描述你所理解的Spark运行架构,运行流程。
答:
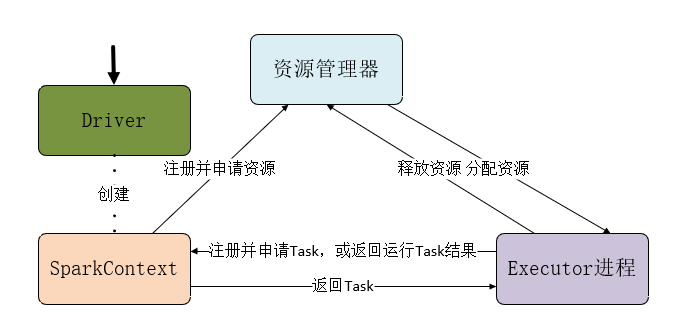
1、Driver创建SparkContext对象
2、SparkContext向资源管理器申请资源
3、资源管理器为Executor进程分配资源,并启动Executor进程
4、Executor进程向SparkContext申请Task
5、SparkContext根据RDD依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理,TaskScheduler向Executor返回Task
6、Executor运行Task,并向TaskScheduler和DAGScheduler返回运行结果
7、写入数据,释放资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号