
芜湖起飞。
1.冯诺依曼计算机模型
计算机在运行时,先从内存中取出第一条指令,通过控制器的译码,按指令的要求,从存储器中取出数据进行指定的运算和逻辑操作等加工,然后再按地址把结果送到内存中去。 接下来,再取出第二条指令,在控制器的指挥下完成规定操作。依此进行下去。直至遇到停止指令。
程序与数据一样存贮,按程序编排的顺序,一步一步地取出指令,自动地完成指令规定 的操作是计算机最基本的工作模型。
这都是数学家冯.诺依曼提出的,所以被称作冯诺依曼计算机模型。
计算机核心组成部分:
1. 控制器(Control):是整个计算机的中枢神经,其功能是对程序规定的控制信息进行 解释,根据其要求进行控制,调度程序、数据、地址,协调计算机各部分工作及内存与外设 的访问等。
2. 运算器(Datapath):运算器的功能是对数据进行各种算术运算和逻辑运算,即对数据 进行加工处理。
3. 存储器(Memory):存储器的功能是存储程序、数据和各种信号、命令等信息,并在 需要时提供这些信息。
4. 输入(Input system):输入设备是计算机的重要组成部分,输入设备与输出设备合你 为外部设备,简称外设,输入设备的作用是将程序、原始数据、文字、字符、控制命令或现 场采集的数据等信息输入到计算机。常见的输入设备有键盘、鼠标器、光电输入机、磁带 机、磁盘机、光盘机等。
5. 输出(Output system):输出设备与输入设备同样是计算机的重要组成部分,它把外 算机的中间结果或最后结果、机内的各种数据符号及文字或各种控制信号等信息输出出来。 微机常用的输出设备有显示终端CRT、打印机、激光印字机、绘图仪及磁带、光盘机等。
图解冯诺依曼计算机模型:

这是一个抽象的模型,并不是我们现代计算机具体实现的模型,那么我们现代计算机的硬件和模型是怎么样的呢?
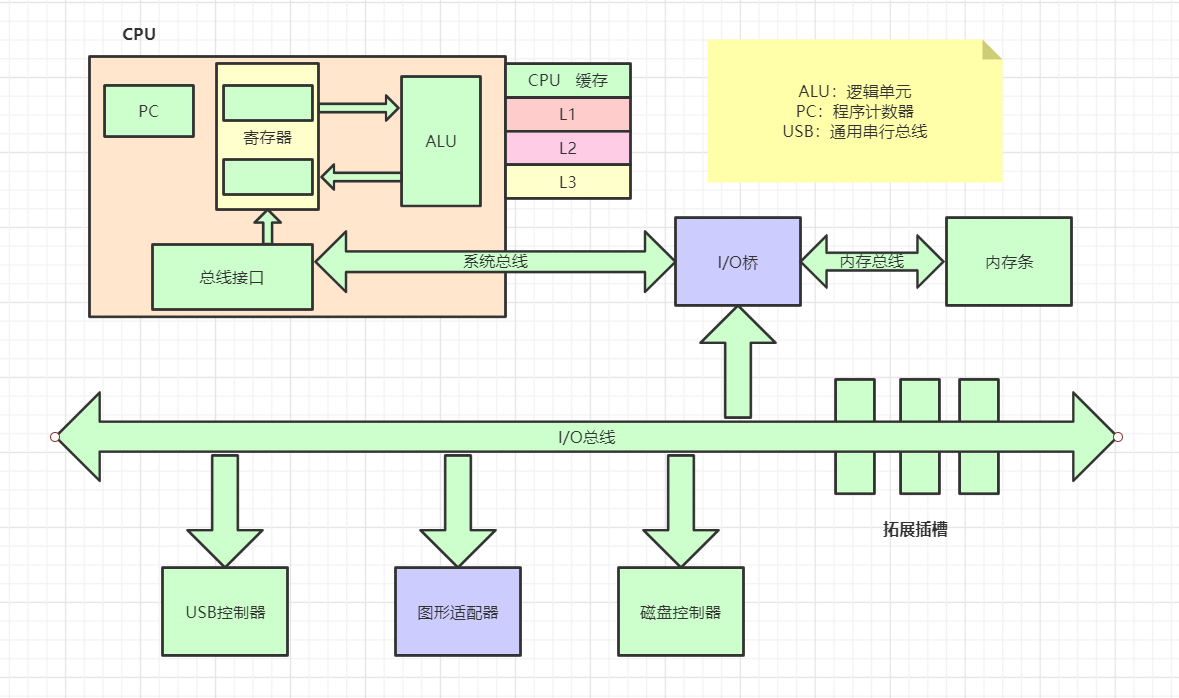
2.运行时内存
运行时内存,就是内存条大小,你的内存条是16g,你的计算机运行内存就是接近16g;
操作系统有用户空间与内核空间两个概念,目的也是为了做到程序运行安全隔离与稳定。
以32位系统,4g内存为例,内存的分配就是下图所示:
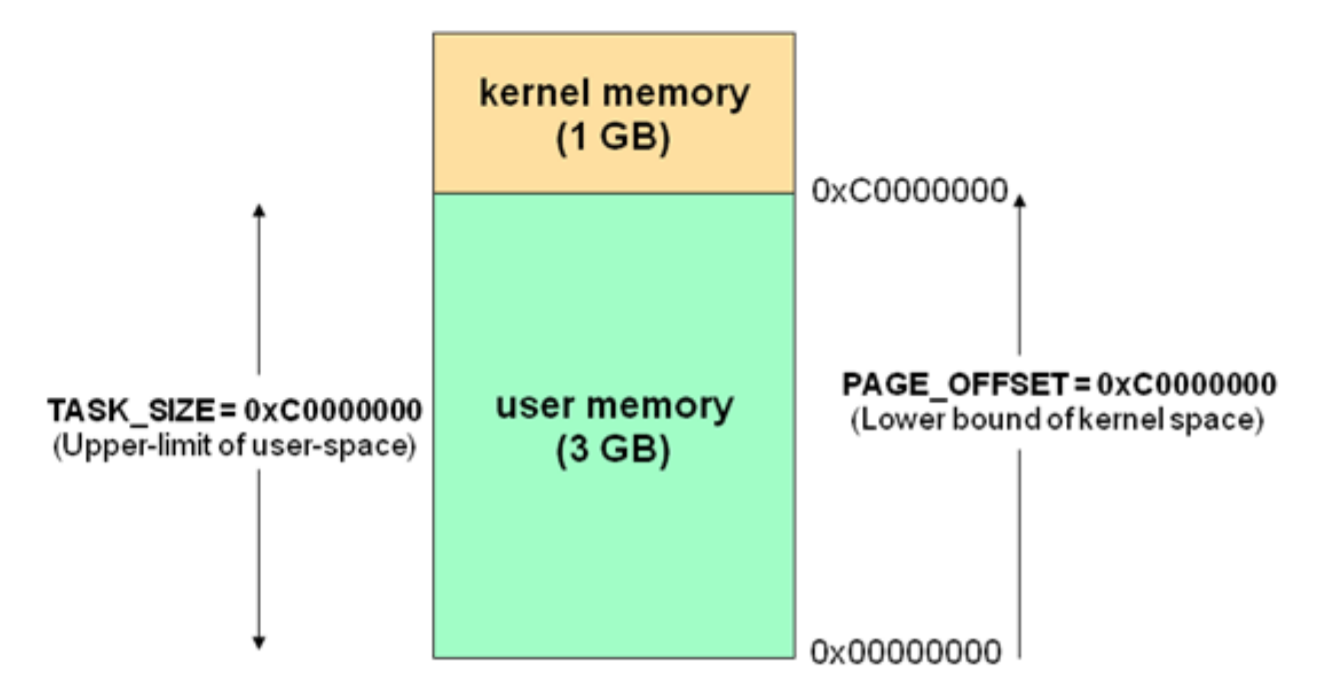
Linux为内核代码和数据结构预留了几个页框,这些页永远不会被转出到磁盘上。从 0x00000000 到 0xc0000000(PAGE_OFFSET) 的线性地址可由用户代码 和 内核代码进 行引用(即用户空间)。从0xc0000000(PAGE_OFFSET)到 0xFFFFFFFFF的线性地址只 能由内核代码进行访问(即内核空间)。内核代码及其数据结构都必须位于这 1 GB的地址 空间中,但是对于此地址空间而言,更大的消费者是物理地址的虚拟映射。
这意味着在 4 GB 的内存空间中,只有 3 GB 可以用于用户应用程序。进程与线程只能 运行在用户方式(usermode)或内核方式(kernelmode)下。用户程序运行在用户方式 下,而系统调用运行在内核方式下。在这两种方式下所用的堆栈不一样:用户方式下用的是 一般的堆栈(用户空间的堆栈),而内核方式下用的是固定大小的堆栈(内核空间的堆栈,一 般为一个内存页的大小),即每个进程与线程其实有两个堆栈,分别运行与用户态与内核 态。
(用户空间和内核空间隔离是为了保护操作系统空间不受用户进程影响,保护操作系统)
jvm运行所用的就是用户空间,那么我们程序跟内存是怎么交互的呢?如下图:
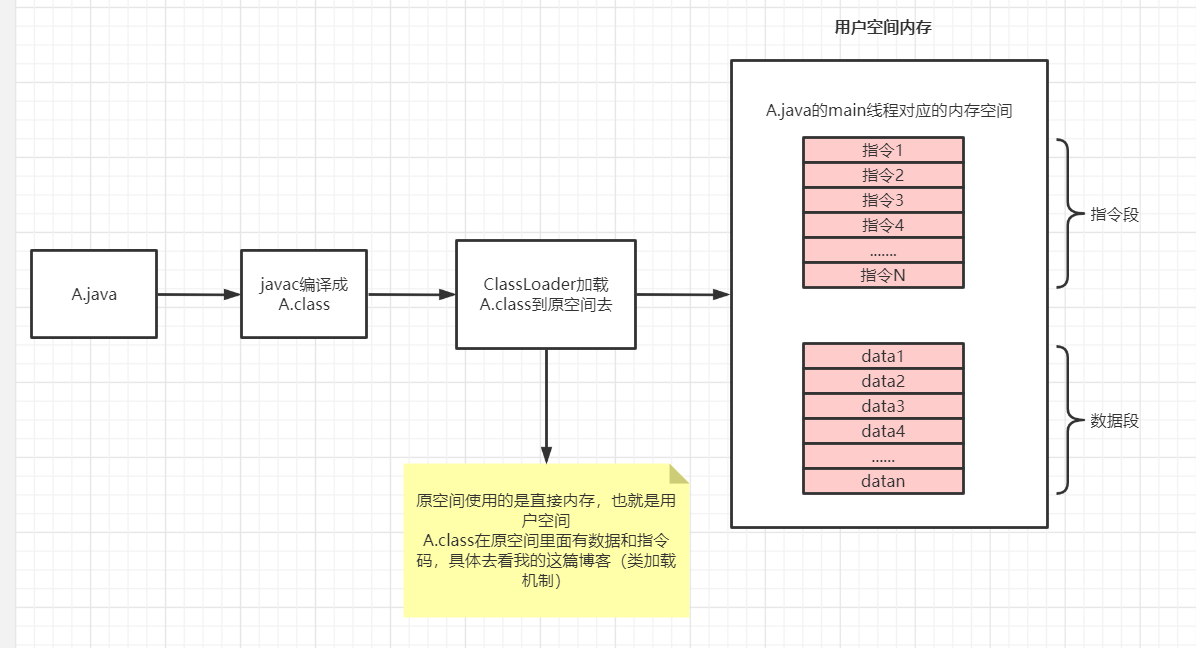
3.CPU处理器
3.1CPU结构
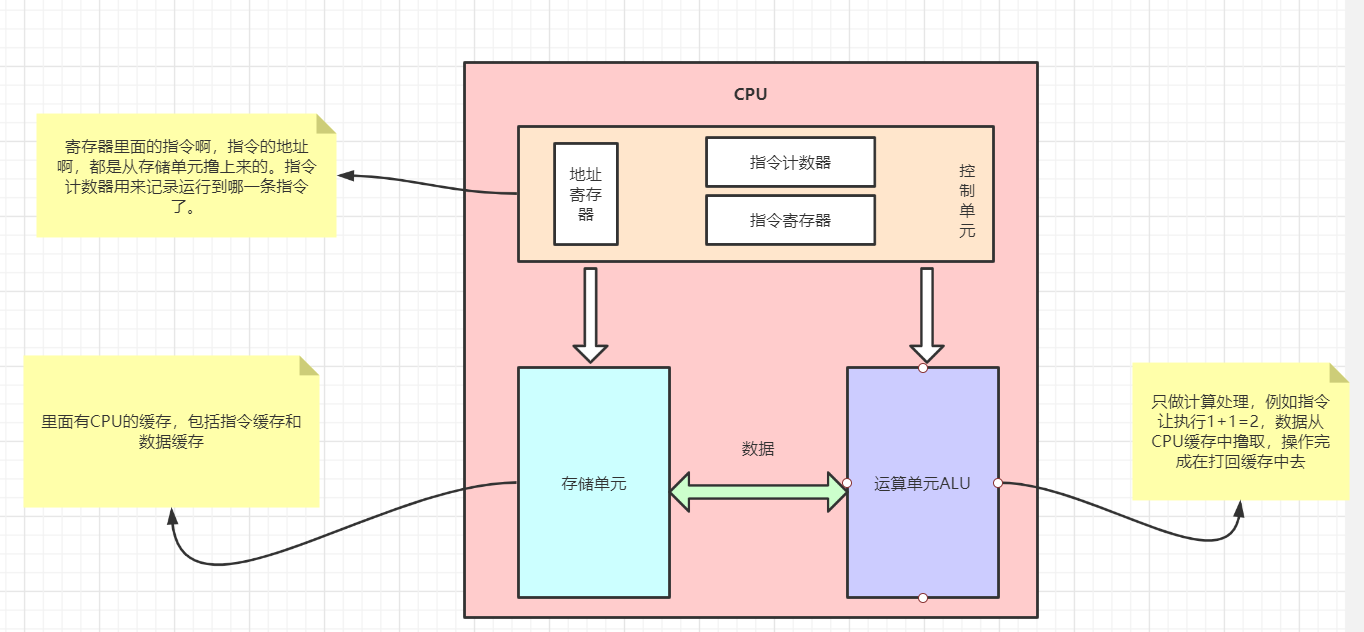
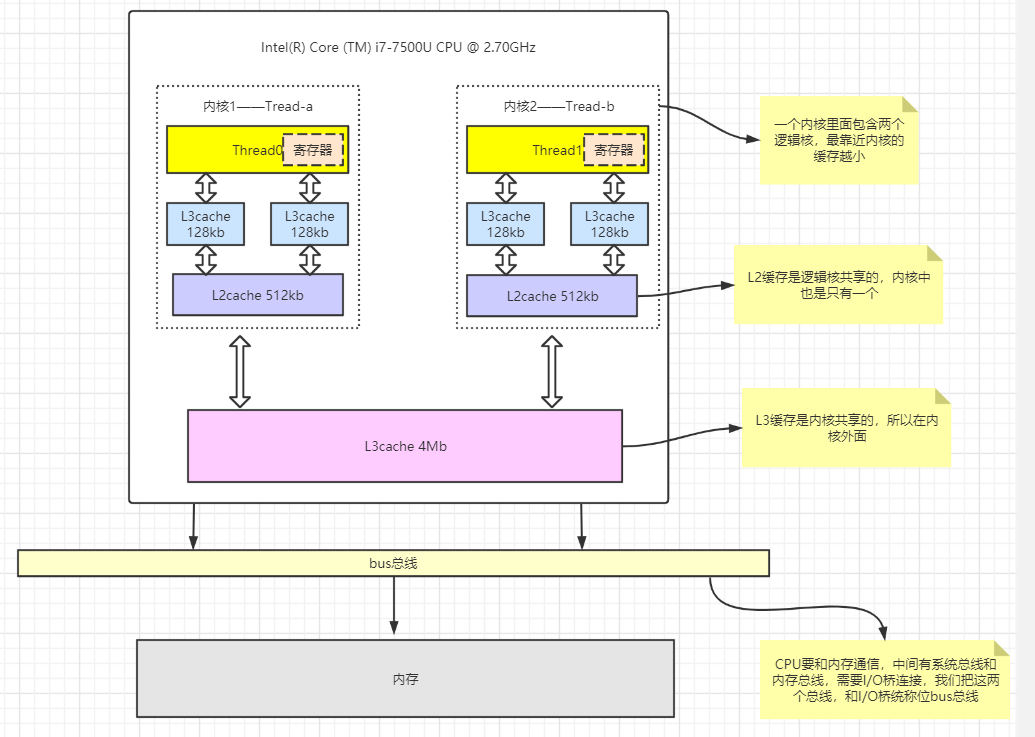
控制单元:控制单元是整个CPU的指挥控制中心,由指令寄存器IR(Instruction Register)、指 令译码器ID(Instruction Decoder)和 操作控制器OC(Operation Controller) 等组 成,对协调整个电脑有序工作极为重要。它根据用户预先编好的程序,依次从存储器中取出 各条指令,放在指令寄存器IR中,通过指令译码(分析)确定应该进行什么操作,然后通过 操作控制器OC,按确定的时序,向相应的部件发出微操作控制信号。操作控制器OC中主要 包括:节拍脉冲发生器、控制矩阵、时钟脉冲发生器、复位电路和启停电路等控制逻辑。
运算单元:运算单元是运算器的核心。可以执行算术运算(包括加减乘数等基本运算及其附加运 算)和逻辑运算(包括移位、逻辑测试或两个值比较)。相对控制单元而言,运算器接受控 制单元的命令而进行动作,即运算单元所进行的全部操作都是由控制单元发出的控制信号来 指挥的,所以它是执行部件。
存储单元:存储单元包括 CPU 片内缓存Cache和寄存器组,是 CPU 中暂时存放数据的地方,里 面保存着那些等待处理的数据,或已经处理过的数据,CPU 访问寄存器所用的时间要比访 问内存的时间短。 寄存器是CPU内部的元件,寄存器拥有非常高的读写速度,所以在寄存 器之间的数据传送非常快。采用寄存器,可以减少 CPU 访问内存的次数,从而提高了 CPU 的工作速度。寄存器组可分为专用寄存器和通用寄存器。专用寄存器的作用是固定的,分别 寄存相应的数据;而通用寄存器用途广泛并可由程序员规定其用途。
图解CPU结构:
3.2CPU缓存结构
现代CPU为了提升执行效率,减少CPU与内存的交互(交互影响CPU效率),一般在CPU上集 成了多级缓存架构,常见的为三级缓存结构。
L1 Cache:分为数据缓存和指令缓存,逻辑核独占
L2 Cache:物理核独占,逻辑核共享
L3 Cache:所有物理核共享
打开任务管理器,打开第二栏性能,我们就能查看自己电脑的CPU缓存情况,下面是我的电脑CPU的L1,L2,L3缓存情况:
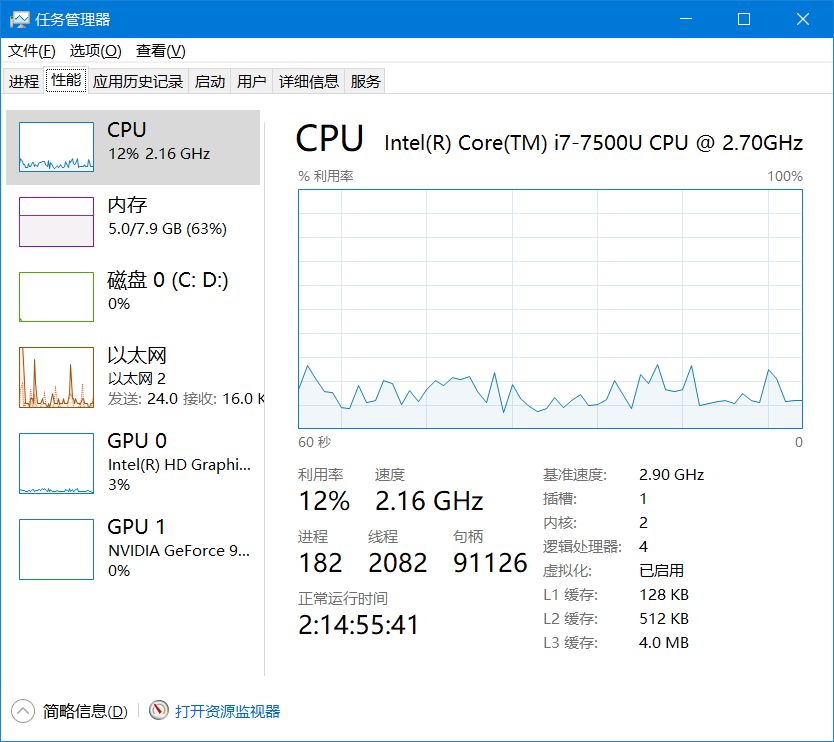
图解CPU缓存结构:
存储器存储空间大小:内存>L3>L2>L1>寄存器;
存储器速度快慢排序:寄存器>L1>L2>L3>内存;(越接近内核的存储容量越小,效率越高)
缓存行:缓存是由最小的存储区块-缓存行(cacheline)组成,缓存行大小通 常为64byte。(比如你的L1缓存大小是512kb,而cacheline = 64byte,那么就是L1里有512 * 1024/64个)
为什么CPU要设计缓存?
CPU在摩尔定律的指导下以每18个月翻一番的速度在发展,然而内存和硬盘的发展速度远远不及 CPU。这就造成了高性能能的内存和硬盘价格及其昂贵。然而CPU的高度运算需要高速的数据。为了解决 这个问题,CPU厂商在CPU中内置了少量的高速缓存以解决I\O速度和CPU运算速度之间的不匹配问题。(内存条的硬件发展跟不上CPU,为了减少CPU和内存条交互,CPU的发展过程中就加入了缓存)
3.3CPU读取存储数据过程
1、CPU要取寄存器X的值,只需要一步:直接读取。
2、CPU要取L1 cache的某个值,需要1-3步(或者更多):把cache行锁住,把某个数据拿来,解 锁,如果没锁住就慢了。
3、CPU要取L2 cache的某个值,先要到L1 cache里取,L1当中不存在,在L2里,L2开始加锁,加 锁以后,把L2里的数据复制到L1,再执行读L1的过程,上面的3步,再解锁。
4、CPU取L3 cache的也是一样,只不过先由L3复制到L2,从L2复制到L1,从L1到CPU。
5、CPU取内存则最复杂:通知内存控制器占用总线带宽,通知内存加锁,发起内存读请求,等待 回应,回应数据保存到L3(如果没有就到L2),再从L3/2到L1,再从L1到CPU,之后解除总线锁定。
CPU执行计算的流程
1. 程序以及数据被加载到主内存
2. 指令和数据被加载到CPU的高速缓存
3. CPU执行指令,把结果写到高速缓存
4. 高速缓存中的数据写回主内存
3.4CPU局部性
在CPU访问存储设备时,无论是存取数据抑或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理。
时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。 比如循环、递归、方法的反复调用等。(如果一个数据被load到内存里面,对这个数据的操作指令执行完成以后,这个数据不会在缓存中马上清除,很有可能这个数据还会再次被用到)
空间局部性(Spatial Locality):如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。 比如顺序执行的代码、连续创建的两个对象、数组等。(从内存中加载一个数据到缓存里面去,CPU会把这个数据周围的一些数据也加载到缓存中去)(缓存行)
对于空间局部性,我们来看下面这段代码:
private static int length1 = 1024*1024; private static int length2 = 6; private static int runs = 100; public static void main(String[] args) { long[][] array = new long[1024*1024][6]; /** * 初始化二维数组 */ for (int i = 0; i < length1; i++) { array[i] = new long[length2]; for (int j = 0; j < length2; j++) { array[i][j] = 1; } } System.out.println("数组初始化完毕++++"); long sum = 0L; long start = System.currentTimeMillis(); for (int i = 0; i < runs; i++) { for (int j = 0; j < length1; j++) { for (int k = 0; k< length2; k++) { sum += array[j][k]; } } } long end = System.currentTimeMillis(); System.out.println("sum:"+ sum); System.out.println("第一次相加完毕,耗时"+ (end - start)); sum = 0L; start = System.currentTimeMillis(); for (int i = 0; i < runs; i++) { for (int j = 0; j < length2; j++) { for (int k = 0; k< length1; k++) { sum += array[k][j]; } } } end = System.currentTimeMillis(); System.out.println("sum:"+ sum); System.out.println("第二次相加完毕,耗时"+ (end - start)); }
执行 结果:
数组初始化完毕++++ sum:629145600 第一次相加完毕,耗时1643 sum:629145600 第二次相加完毕,耗时3461
我们可以看出,第一次执行速度明显要高于第二次执行速度。
这是因为如果以第一种循环方式,循环1024*1024次,每次只相加6条数据,6条数据,都是long,一共是48byte,我们cpu的缓存行一个是64byte,然后根据空间局部性原则,这6个数据都会被读到一个缓存行里面;如果是第二种循环方式,循环6次,每次都是1024*1024条数据,一个缓存行肯定是放不下的,所以CPU要去和内存交互1024*1024次,所以效率比第一种循环要低得多。
3.4CPU运行安全等级
CPU有4个运行级别,分别为:
ring0
ring1
ring2
ring3
Linux与Windows只用到了2个级别:ring0、ring3,操作系统内部内部程序指令通常运行在ring0级别,操作系统以外的第三方程序运行在ring3级别,第三方程序如果要调用操作 系统内部函数功能,由于运行安全级别不够,必须切换CPU运行状态(IO操作,JVM创建线程等,都需要切换到ring3级别),从ring3切换到ring0, 然后执行系统函数,说到这里相信明白为什么JVM创建线程,线程阻塞唤醒是重型操作了,因为CPU要切换运行状态。
JVM创建线程CPU的工作过程:
1:CPU从ring3切换ring0创建线程
2:创建完毕,CPU从ring0切换回ring3
3:线程执行JVM程序
4:线程执行完毕,销毁还得切会ring0
3.5CPU线程模型
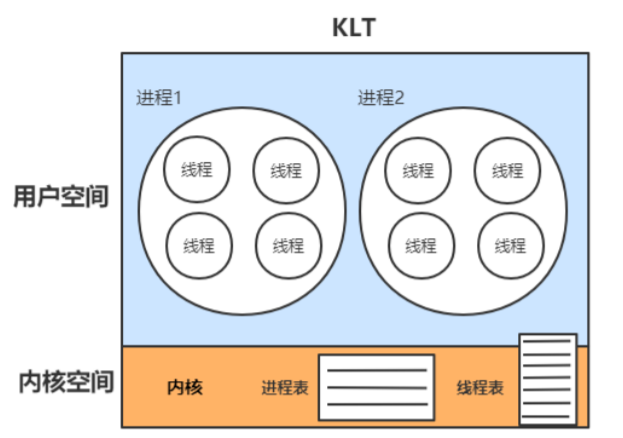
内核线程模型:系统内核管理线程(KLT),内核保存线程的状态和上下文信息,线程阻塞不会引起进程阻塞。在多处理器系统上,多线程在多处理器上并行运行。线程的创建、调度和管 理由内核完成,效率比ULT要慢,比进程操作快。
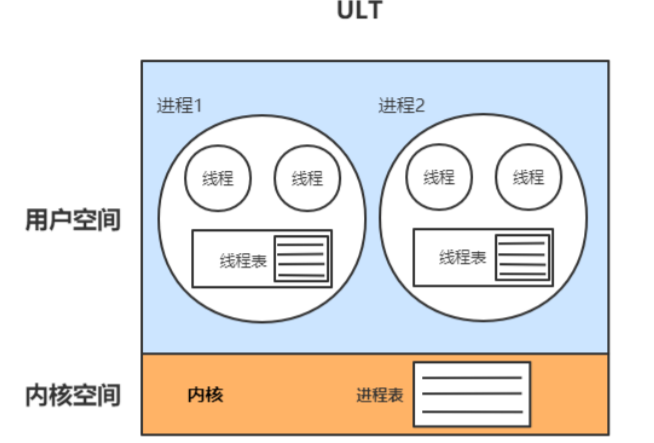
用户线程模型:用户程序实现,不依赖操作系统核心,应用提供创建、同步、调度和管理线程 的函数来控制用户线程。不需要用户态/内核态切换,速度快。内核对ULT无感知,线程阻 塞则进程(包括它的所有线程)阻塞。
JVM使用的线程模型?
我们来看下面代码:
public static void main(String[] args) { for (int i =0; i < 200; i++) { new Thread(new Runnable() { @Override public void run() { while (true) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); } }
如果我们的CPU能感知到线程的创建,那么久说明JVM用的是用户线程模型,如果CPU不能感知,那么就是内核线程模型。
执行前我们打开任务管理器,看看系统线程是多少个:
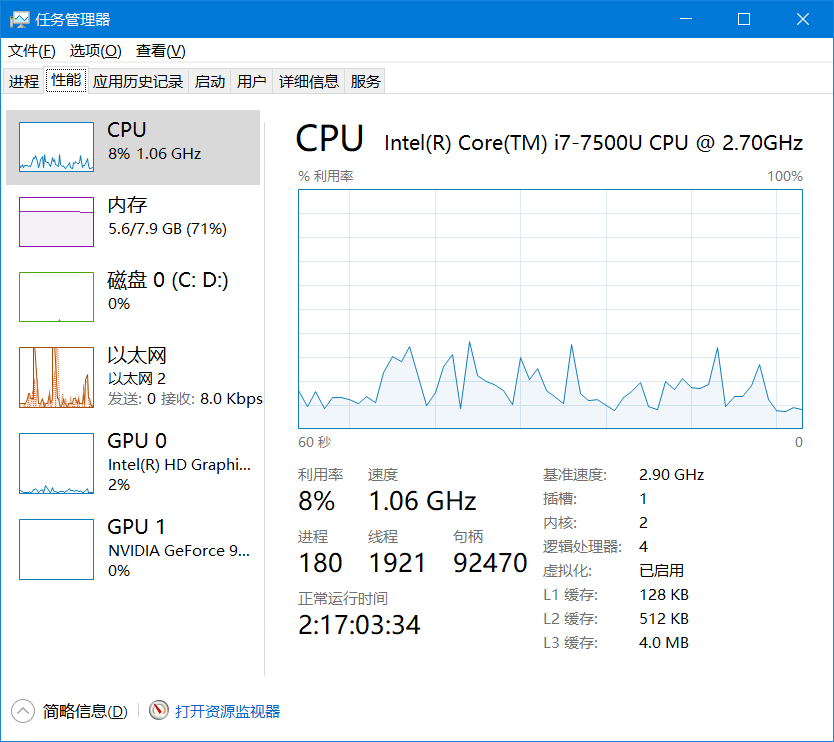
基本稳定在1940左右,我们执行代码,在看线程数量:
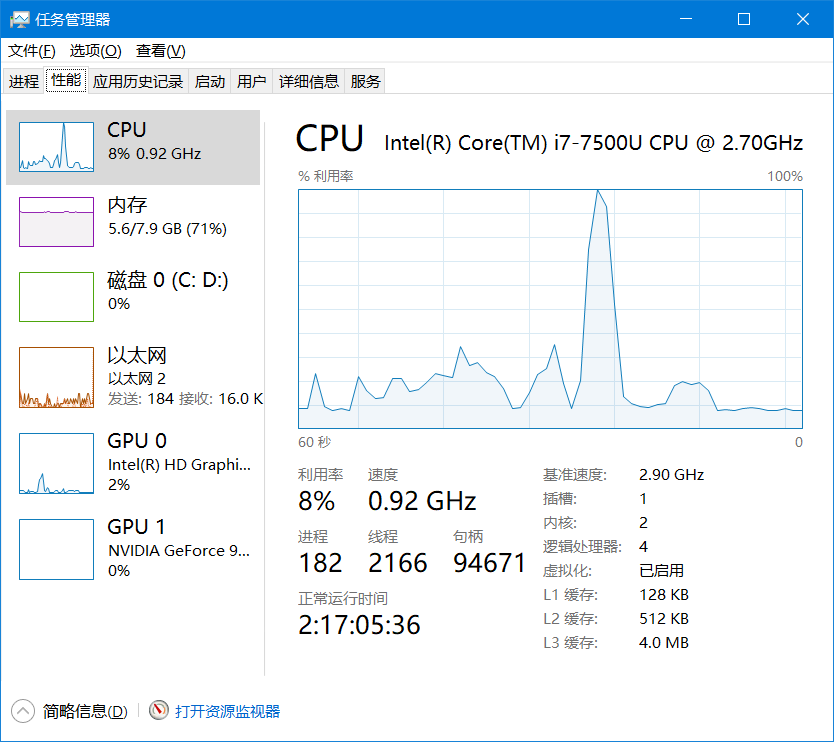
基本上是多个200个线程左右,这说明,这些线程都是由操作系统创建的,所以,JVM的线程就是用户线程模型。
4.运行内存和CPU关系
用一张图来说的话:
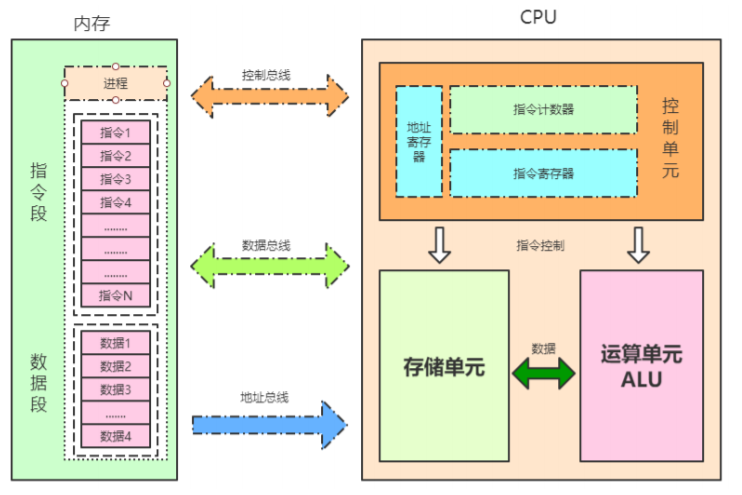
上面就是运行内存和CPU的一些初步认知,我们学这些东西只是为了更好的了解电脑工作原理,了解程序和硬件之间的交互,为了写出更高质量的代码!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号