【笔记】VolTeMorph
VolTeMorph
Introduction
和NeRF-Editing类似,采用弯曲光线的方式,完成对模型的编辑,不同点有四个
- 扩展到更多区域,例如嘴内部
- 利用显卡的光追单元,做到了实时(单张3090)
- 对view direction做了校正
- 不使用编辑mesh再传播的方法,而是直接对四面体几何进行操作,可以结合物理模拟
另外,加入了一些tricks,比如对嘴部的特殊优化,Sparsity Loss和NeRF采样策略的改进等
Method
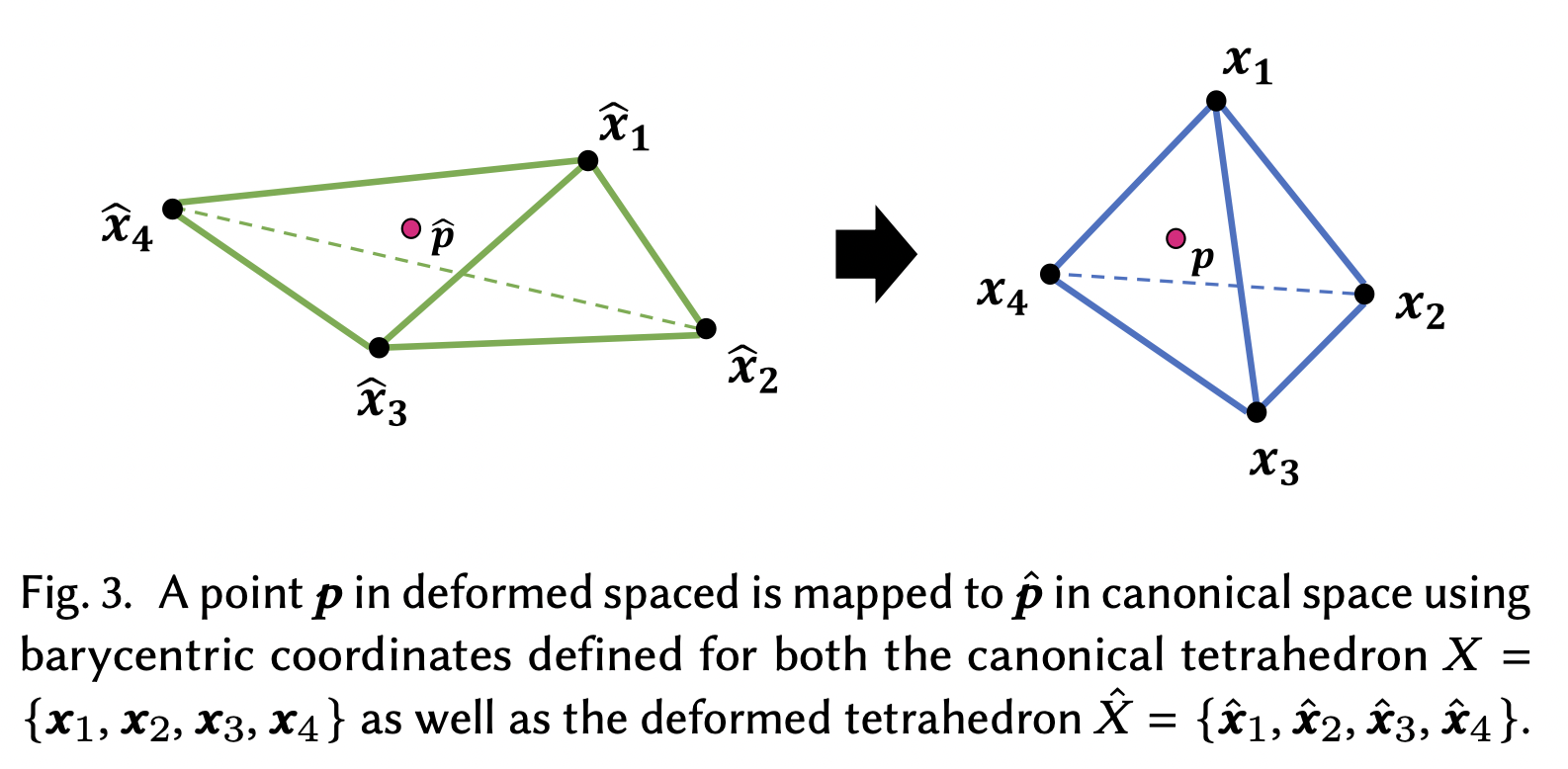
Closed Triangular Primitives
使用四面体作为基本元素,可以使用GPU的光追加速,同时能重建出锐利的边界,并易于编辑
定义一个四面体为
变形后的四面体为
对于落在四面体内的点,可以得到它的坐标
记作 barycentric coordinates \((\lambda_1,\lambda_2,\lambda_3,\lambda_4)\)
Changes in View Direction
每个点的color和density不仅和position有关,还和view direction有关
现在的做法,只移动了position,如果view direction不变的话,光线会出错
因此,对view direction进行对应的旋转,从而弥补这个问题
其中\(R\)是旋转矩阵,来自
U和V来自视角变化的奇异值分解(即旋转分量)
这样便修正了view direction,变形也会影响光照效果,结果更加逼真
但在实践中,对每个变形的四面体计算SVD,非常缓慢,作者采用了随机化的方法
即随机计算5%四面体的旋转矩阵,然后用最近邻插值扩展到所有四面体上
Learning from a Single Frame
作者指出,由于真实物体的变形参数是估计得来的,有误差
用更多帧训练,会导致错误更多,且光照也会有改变,导致图像模糊
作者根据经验,选择仅使用一帧图像(同一时刻,多个相机)进行训练,结果更锐利
Tetrahedral Point Lookups
算法中需要大量计算“一个点是否在某个四面体内”的问题,传统算法太慢
首先给出一个假设(也将成为模型的一个limitation):模型不会自相交
作者借鉴前人思想,从这个点随机射出一条射线,找碰到的第一个三角形,以及在哪一面
这就足以确定在哪个四面体了,因为此时一个三角形最多属于2个四面体,且正好有2面区分
在硬件加速的帮助下,这样的查询非常迅速
作者进一步拓展了这个算法,一方面,添加了对三角形面片的支持(不一定非要四面体)
另一方面,考虑到查询往往是连续进行的,一条射线上许多点都会落在同一个四面体内
如果知道了前一个和后一个交点,便可以通过线性插值算中间所有点的坐标
这样的算法能很方便地整合进作者之前的工作,FastNeRF
Applications
Generic Objects
作者将自己的FastNeRF进行修改
先从volumetric geometry中提出mesh,然后在此基础上重建四面体结构
接着就可以用软件对其进行变形、物理模拟等操作
Human Faces
作者将3DMM的blend shapes重建为四面体模型,并人工调整,使其不发生自相交

蓝色的是3DMM的surface,绿色的重建的四面体立体结构,还可以扩展到红色区域(头发,耳机等)
3DMM无法处理嘴内部的信息,在四面体模型上,如果直接对内部填充四面体,会造成失真
因此,作者将嘴内部重建为不规则的三角形mesh,内部的运动根据两片平面进行

两片平面中间认为是空的,落在中间的sample不渲染(因此无法还原舌头)
Implementation
Sparsity Loss
和之前的那篇Neural Parameterization有些类似,采用了Cauchy Loss的形式,减少伪影
仅应用在头部周围和口腔内部,前者具体来说,是在四面体内部的,和穿过背景射线上的sample
区分背景通过成熟的2D face segmentation算法求解得到
Sampling
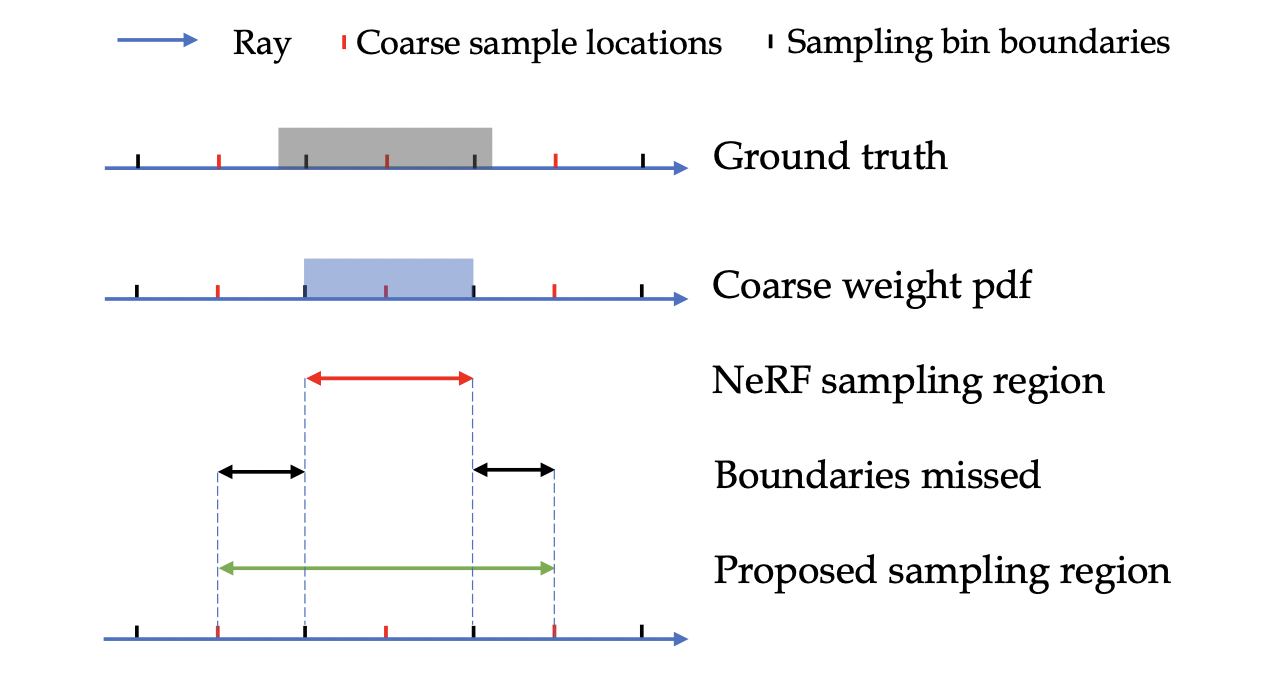
作者认为,NeRF的采样方法会丢失边角信息,因此加长了采样区间
Experiments
Synthetic Data
Baseline
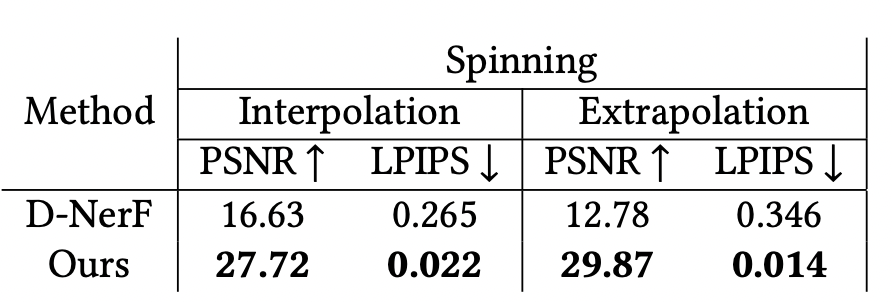
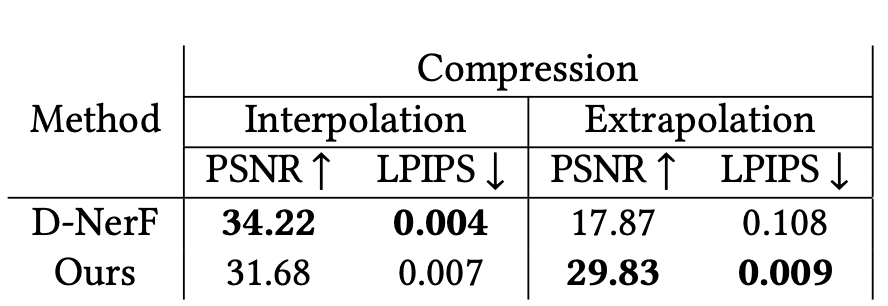
由于D-NeRF用了更多数据训练,而这个工作每个角度只用了一帧,所以在interpolation上输了
但是本工作在extrapolation上还能保持相似的水准,D-NeRF就大幅下降了
Generalization


支持更多的变形,甚至包括打碎的效果
Face Data

一致性非常好,三个人的表情几乎一样


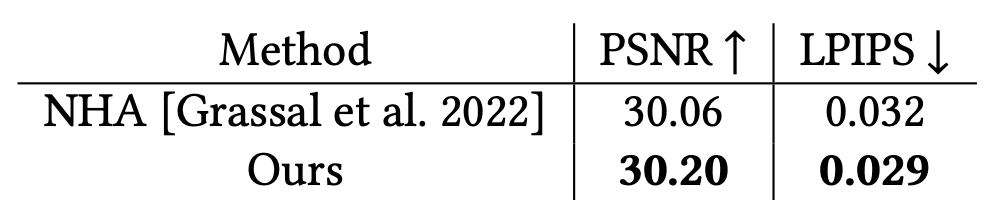
达到了新的SOTA
Performance
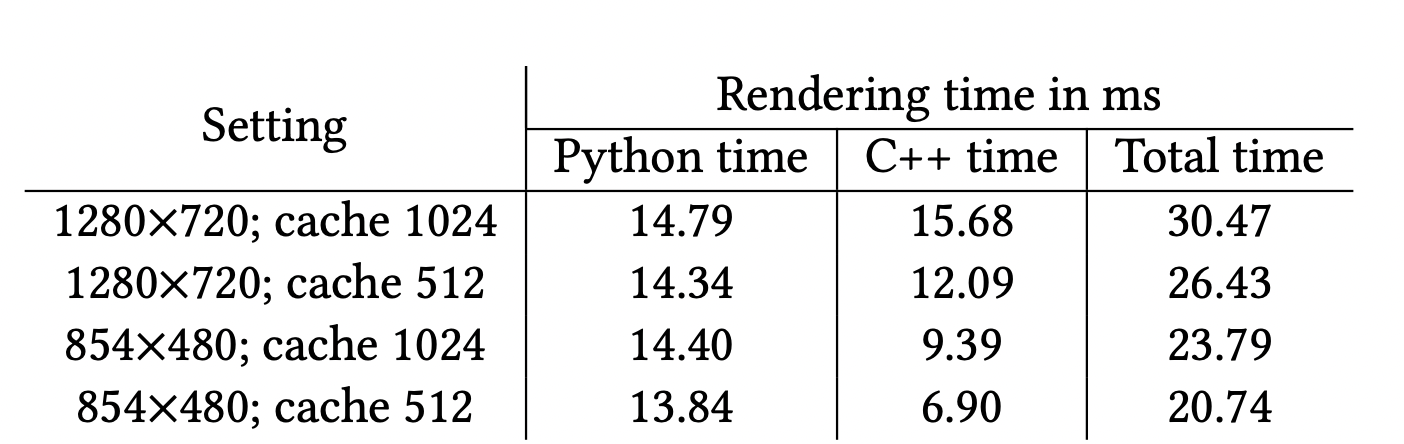
python和CUDA/C++混合实现,速度很快,达到了实时 (30fps+)
作者指出把python代码改写成CUDA/C++还能更快
Ablation Study
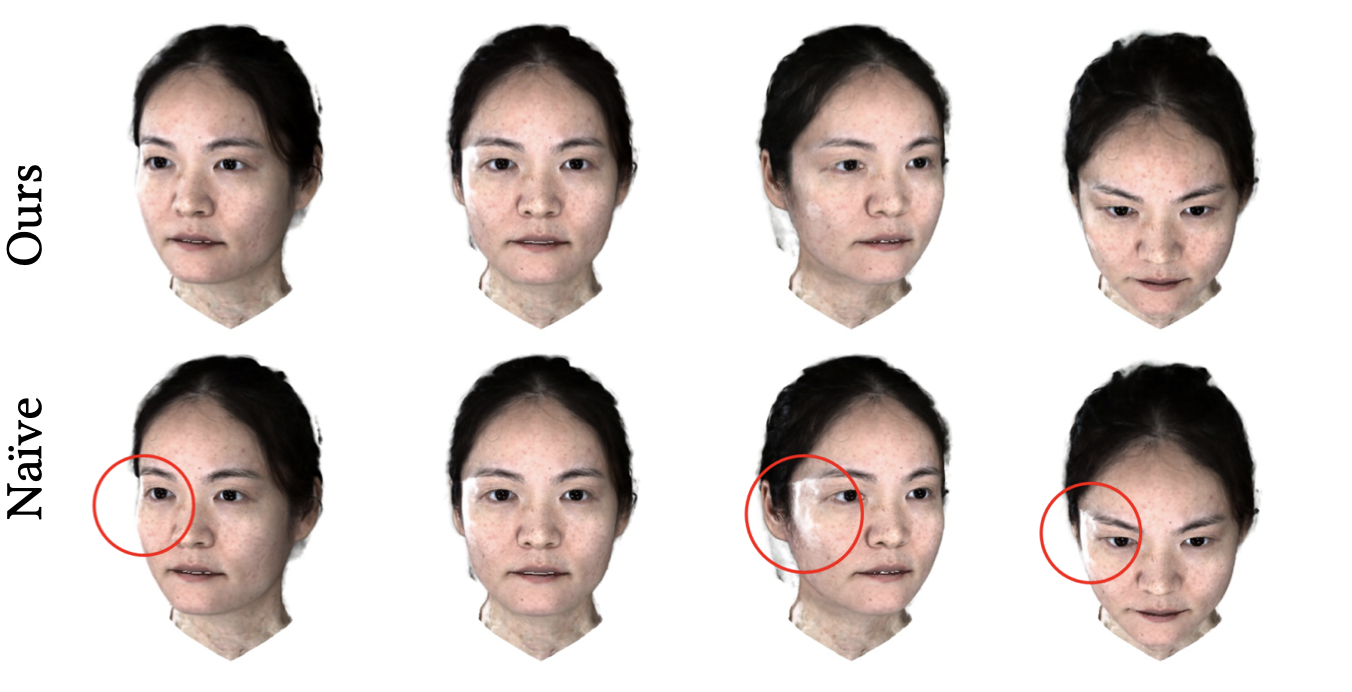
View Direction
对View Direction的修正,带来更好的光线效果
Mouth Interior
通过对嘴部的单独处理,得到了更好的效果

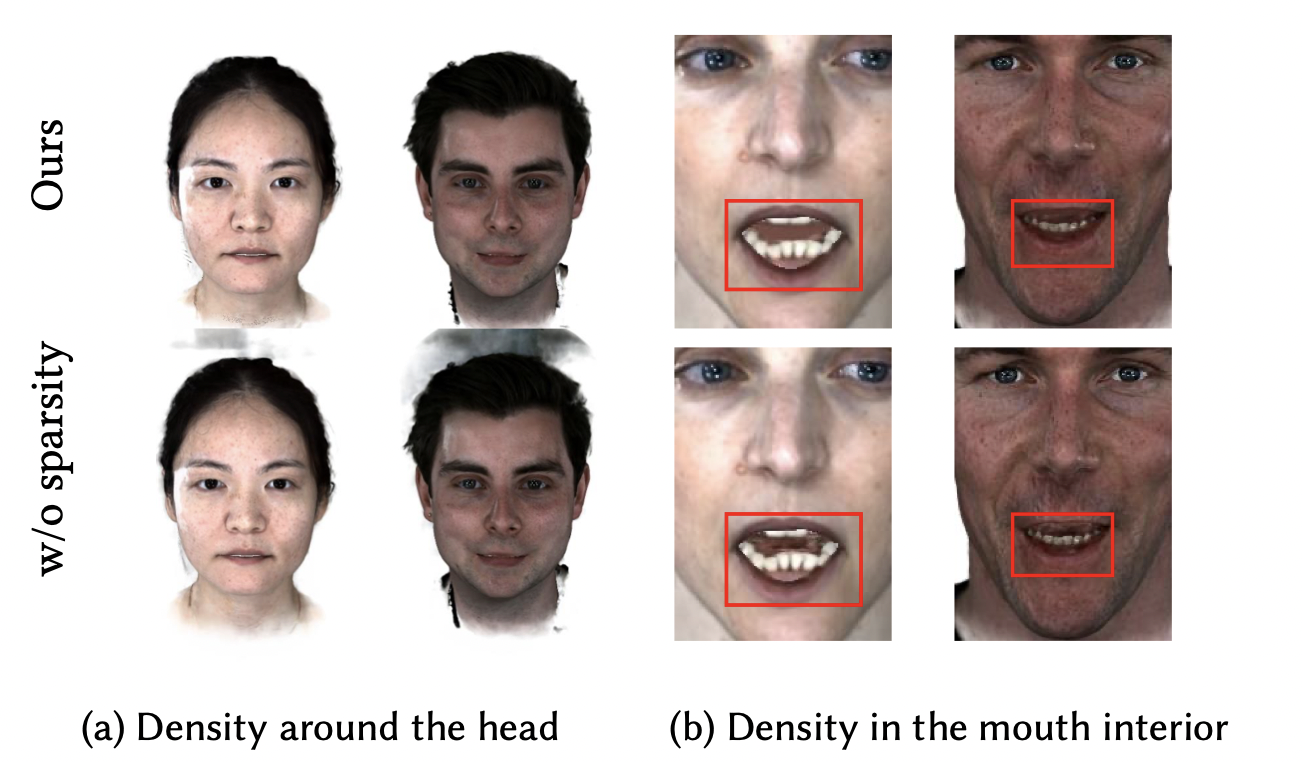
Sparsity Loss
添加sparsity loss后,减少了许多伪影
Improved Sampling
改进后的sampling策略,改善了一些细节效果

本文来自博客园,作者:GhostCai,转载请注明原文链接:https://www.cnblogs.com/ghostcai/p/16573361.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号