二、变量、整数、字符串、列表、字典、集合。
一、输入与输出
- print是输出的意思
- input是输入的意思
1.1:输出
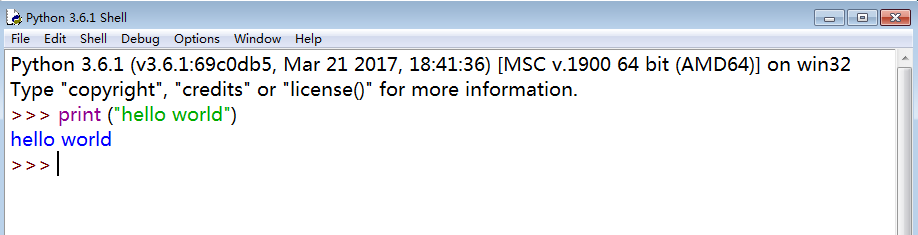
1.2:输出
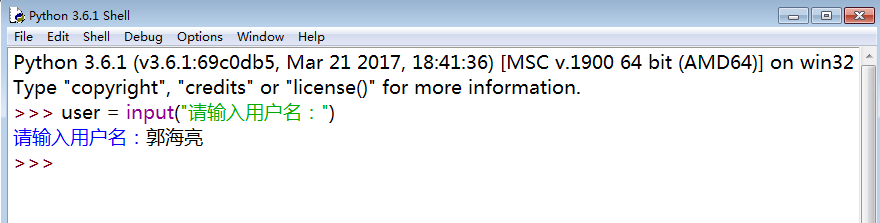
二、变量
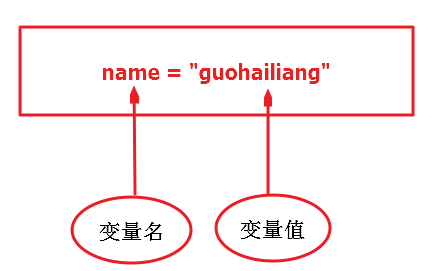
2.1:声明变量
例如:
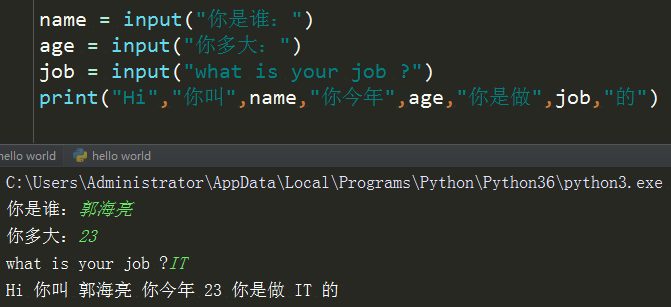
2.2:变量定义规则
- 变量名只能是数字,字母或下划线的任意组合;
- 变量名的第一个字符不能是数字;
- 内置的关键字不能声明为变量名{'and','as','del','def','if','else','with','continue','break','exec','elif','except','class','yield','return','while',,"finally","try'',"catch"}
三、数数类型(int)
3.1:long(长整型)
注意:在Python3里不再有long类型了,全都是int
3.1:int(整型)
- 在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
- 在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
- Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
- 从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。

四、字符串(str)
- 在Python中,加了引号的字符都被认为是字符串。
- 存储少量的数据,进行简单的操作。
注意:双引号、单引号、没有任何区别,作用就是字符串必须用引号。
多引号只用于多行字符串。

4.1:字符串拼接
数字可以进行加减乘除等运算,字符串只能进行"相加"和"相乘"运算。

4.2:切片
切片操作(slice)可以从一个字符串中获取子字符串(字符串的一部分)。我们使用一对方括号、起始偏移量start、终止偏移量end 以及可选的步长step 来定义一个分片。
格式: [start:end:step]
- 顾首不顾尾(结尾多取一个)
- s[起始索引:结束索引+1]
- s[起始索引:结束索引+1:步长]
- [:] 提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串;
- [start:] 从start 提取到结尾;
- [:end] 从开头提取到end - 1;
- [start:end] 从start 提取到end - 1;
- [start:end:step] 从start 提取到end - 1,每step 个字符提取一个;
- 左侧第一个字符的位置/偏移量为0,右侧最后一个字符的位置/偏移量为-1;
#!/user/bin/env python # -*- coding:utf-8 -*- s = 'alexwusirritian' #取出alex s5 = s[0:4] #如果是从头开始可以不写0 s5 = s[:4] print(s5) #取出wusir s6 = s[4:9] print(s6) #取出所有 s7 = s[:] print(s7) #取出aew s8 = s[:5:2] print(s8) #取出nait s9 = s[-1:-5:-1] print(s9) #取出tian s10 = s[-4:] print(s10)
输入一个字符串,返回倒序排序的结果,:如:‘abcdef’ 返回:'fedcba'
>>> G = "abcd"
>>> print(G)
abcd
>>> S = G[::-1]
>>> print(S)
dcba
>>>
test = 'nothing is impossible' #取出nothing test1 = test[:8] print(test1) #取出is test2 = test[8:11] print(test2) #取出impossible test3 = test[-10:] print(test3) #取出所有 test4 = test[:] print(test4) #反向取出所有 test5 = test[-1:-22:-1] print(test5) test6 = test[::-1] print(test6) #输出结果为: nothing is impossible nothing is impossible elbissopmi si gnihton elbissopmi si gnihton
4.3:字符串的常用方法
capitalize:首字母大写其余字母小写
s = 'alexWUsir'
s1 = s.capitalize()
print(s1)
#输出结果为:
Alexwusir
test = 'nothing is impossible' test1 = test.capitalize() print(test1) #输出结果为: Nothing is impossible
swapcase:大小写翻转
s = 'alexWUsir'
s2 = s.swapcase()
print(s2)
#输出结果为:
ALEXwuSIR
test = 'Nothing Is imPOssiBle' test1 = test.swapcase() print(test1) #输出结果为: nOTHING iS IMpoSSIbLE
title:非字母隔开的每个单词的首字母大写
s = 'alex wusir*taibai2ritian'
s3 = s.title()
print(s3)
#输出结果为:
Alex Wusir*Taibai2Ritian
test = 'No#th-in)g I$s imPO*ss+iB%le' test1 = test.title() print(test1) #输出结果为: No#Th-In)G I$S Impo*Ss+Ib%Le
center:设置总长度,并居中
s = 'alexWUsir'
s4 = s.center(30,)
print(s4)
#长度为30
#输出结果为: alexWUsir
#长度为30,填充物为*
s = 'alexWUsir'
s4 = s.center(30,'*')
print(s4)
#输出结果为:
**********alexWUsir***********
#长度为50,填充物为+ test = 'Nothing is impossible' test1 = test.center(50,'+') print(test1) #输出结果为: ++++++++++++++Nothing is impossible+++++++++++++++
upper():全大写
s = 'alexWUsir'
s5 = s.upper()
print(s5)
#输出结果为:
ALEXWUSIR
#验证码例子
s = 'alexWUsir' code = 'AwEqr' username= input('请输入用户名:') your_code = input('请输入验证码:') if username == 'alex' and your_code.upper() == code.upper(): print('验证成功') #输出结果为: 请输入用户名:alex 请输入验证码:aweqr 验证成功

test = 'Nothing is impossible' test1 = test.upper() print(test1) #输出结果为: NOTHING IS IMPOSSIBLE
lower():全小写
test = 'NOTHING IS IMPOSSIBLE' test1 = test.lower() print(test1) #输出结果为: nothing is impossible
startswith:检测字符串是否是由相同的开头,返回True或False
s = 'alexWUsir'
s6 = s.startswith('a')
s7 = s.startswith('alex')
s8 = s.startswith('W', 4,)
print(s6,s7,s8)
#输出结果为:
True True True

test = 'Nothing is impossible' test1 = test.startswith('i') test2 = test.startswith('N') #第14个元素是不是以po开头 test3 = test.startswith('po',13) print(test1) print(test2) print(test3) #输出结果为: False True True
endswith:检测字符串是否是由相同的结尾,返回True或False
test = 'Nothing is impossible' #整个字符串是否以e结尾 test1 = test.endswith('e') #整个字符串是否以N结尾 test2 = test.endswith('N') #第二个元素是否以t开头第四个元素是否以h结尾 test3 = test.endswith('th',2,4) print(test1) print(test2) print(test3) #输出结果为: True False True
str = "this is string example....wow!!!" suffix = "wow!!!" print (str.endswith(suffix)) print (str.endswith(suffix,20)) suffix = "is" print (str.endswith(suffix, 2, 4)) print (str.endswith(suffix, 2, 6)) #输出结果为: True True True False
strip:默认去除字符串前后的空格,换行符,制表符
s = ' alexWUsir\t'
print(s)
#输出结果为:
alexWUsir
s = ' alexWUsir\t'
print(s)
s7 = s.strip()
print(s7)
#输出结果为:
alexWUsir
alexWUsir
username = input('>>>').strip()
password = input('>>>').strip()
if username == '郭海亮' and password == '123':
print('登录成功')
#输出结果为:
>>>郭海亮
>>>123
登录成功
ss = 'abc郭海亮q'
ss1 = ss.strip('abqc')
print(ss1)
#输出结果为:
郭海亮
str = "*****this is string example....wow!!!*****" print (str.strip('*')) #输出结果为: this is string example....wow!!!
lstrip():默认只去除左边的空格
str = " this is string example....wow!!! " print( str.lstrip() ) str = "88888888this is string example....wow!!!8888888" print( str.lstrip('8') ) #输出结果为: this is string example....wow!!! this is string example....wow!!!8888888
rstrip():默认只去除右边的空格
str = " this is string example....wow!!! " print (str.rstrip()) str = "*****this is string example....wow!!!*****" print (str.rstrip('*')) #输出结果为: this is string example....wow!!! *****this is string example....wow!!!
replace:字符串替换
s = 'alex 分甘共苦老地方 alex 风刀霜剑卡乐芙'
s8 = s.replace('alex', 'SB')
print(s8)
#输出结果为:
SB 分甘共苦老地方 SB 风刀霜剑卡乐芙
#只替换第一个
s = 'alex 分甘共苦老地方 alex 风刀霜剑卡乐芙'
s9 = s.replace('alex', 'SB',1)
print(s9)
#输出结果为:
SB 分甘共苦老地方 alex 风刀霜剑卡乐芙
str = "this is string example....wow!!! this is really string" print (str.replace("is", "was")) print (str.replace("is", "was", 3)) #输出结果为: thwas was string example....wow!!! thwas was really string thwas was string example....wow!!! thwas is really string
split: 分隔,str ---> list
s1 = 'alex wusir taibai ritian'
s2 = 'alex,wusir,taibai,ritian'
s3 = 'alexwusirtaibairitian'
s4 = 'alexwusirtaibairitian'
l1 = s1.split()
l2 = s2.split(',')
l3 = s3.split('a')
l4 = s4.split('a',2) #以a为分隔符,分割两次
print(l1)
print(l2)
print(l3)
print(l4)
#输出结果为:
['alex', 'wusir', 'taibai', 'ritian']
['alex', 'wusir', 'taibai', 'ritian']
['', 'lexwusirt', 'ib', 'iriti', 'n']
['', 'lexwusirt', 'ibairitian']
str = "this is string example....wow!!!" print (str.split( )) print (str.split('i',1)) print (str.split('w')) #输出结果为: ['this', 'is', 'string', 'example....wow!!!'] ['th', 's is string example....wow!!!'] ['this is string example....', 'o', '!!!']
join:分割,list---> str
注意:列表里面的元素必须都是字符串
s = '郭海亮'
s1 = '-'.join(s)
print(s1)
#输出结果为:
郭-海-亮
l1 = ['alex', 'wusir', 'ritian']
s10 = ' '.join(l1)
print(s10,type(s10))
#输出结果为:
alex wusir ritian <class 'str'>
str = "-" # 字符串序列 seq = ("a", "b", "c") print (str.join(seq)) #输出结果为: a-b-c
find:通过元素找索引,找不到返回-1
s = 'alexwausir'
s11 = s.find('e')
s12 = s.find('ex')
s13 = s.find('QWE')
print(s11,type(s11))
print(s12,type(s12))
print(s13,type(s13))
#输出结果为:
2 <class 'int'>
2 <class 'int'>
-1 <class 'int'>
str1 = "Runoob example....wow!!!" str2 = "exam" print (str1.find(str2)) print (str1.find(str2, 5)) print (str1.find(str2, 10)) #输出结果为: 7 7 -1
index:通过元素找索引,找不到会报错
#从列表中找出某个值第一个匹配项的索引位置) a = ["q","w","r","t","y"] print(a.index("r"))
str1 = "this is string example....wow!!!" str2 = "exam" print (str1.index(str2))
#从索引10开始找 print (str1.index(str2, 10))
#从索引40开始找 print (str1.index(str2, 40)) #输出结果为: 15 15 Traceback (most recent call last): File "F:/Python/My road of Python/day02/test.py", line 12, in <module> print (str1.index(str2, 40)) ValueError: substring not found
len:测量个数
s = 'alexwausir'
print(len(s))
#输出结果为:
10
>>>str = "runoob" >>> len(str) # 字符串长度 6 >>> l = [1,2,3,4,5] >>> len(l) # 列表元素个数 5
count:(数)(方法统计某个元素在列表中出现的次数)
s = 'alexwausir'
print(s.count('a'))
#输出结果为:
2
str = "this is string example....wow!!!" sub = "i" print ("str.count(sub, 4, 40) : ", str.count(sub, 4, 40)) sub = "wow" print ("str.count(sub) : ", str.count(sub)) #输出结果为: str.count(sub, 4, 40) : 2 str.count(sub) : 1
format:格式化输出
s = "我叫{},今年{},爱好{}"
#第一种用法
s12 = s.format('海亮', '23', '女')
print(s12)
#第二种用法
s1 = "我叫{0},今年{1},爱好{2},我依然叫{0}"
s13 = s1.format('海亮', '23', '女')
print(s13)
#第三种用法
s3 = "我叫{name},今年{age},爱好{hobby}"
s14 = s3.format(age=23,hobby='girl',name='海亮')
print(s14)
#输出结果为:
我叫海亮,今年23,爱好女
我叫海亮,今年23,爱好女,我依然叫海亮
我叫海亮,今年23,爱好girl
# 不设置指定位置,按默认顺序 >>>"{} {}".format("hello", "world") 'hello world' # 设置指定位置 >>> "{0} {1}".format("hello", "world") 'hello world' # 设置指定位置 >>> "{1} {0} {1}".format("hello", "world") 'world hello world'
print("网站名:{name}, 地址 {url}".format(name="个人小站", url="www.guohailiang.club")) # 通过字典设置参数 site = {"name": "个人小站", "url": "www.guohailiang.club"} print("网站名:{name}, 地址 {url}".format(**site)) # 通过列表索引设置参数 my_list = ['个人小站', 'www.guohailiang.club'] print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
isalnum:检验字符串是否由字母和数字组成
name = '123' print(name.isalnum()) #输出结果为: True
str = "runoob2016" print (str.isalnum()) str = "www.runoob.com" print (str.isalnum()) #输出结果为: True False
isalpha:检测字符串是否只由字母组成
name = '123' print(name.isalpha()) #输出结果为: False
test = 'Nothing is impossible' print(test.isalpha()) #输出结果为: False
isdigit:检测字符串是否只由数字组成
name = '123' print(name.isdigit()) #输出结果为: True
str = "123456" print (str.isdigit()) str = "Runoob example....wow!!!" print (str.isdigit()) #输出结果为: True False
sort()正序排序列表中的元素
l1 = [1, 9, 8, 4, 3, 2, 6,] l1.sort() print(l1) #输出结果为: [1, 2, 3, 4, 6, 8, 9]
list1 = ['Google','Runoob','Taobao','Baidu'] list1.sort() print ("列表排序后 : ", list1) #输出结果为: 列表排序后 : ['Baidu', 'Google', 'Runoob', 'Taobao']
sort()倒叙排序列表中的元素
l1 = [1, 9, 8, 4, 3, 2, 6,] l1.sort(reverse=True) print(l1) #输出结果为: [9, 8, 6, 4, 3, 2, 1]
reverse()翻转列表中的元素
l1 = [1, 9, 8, 4, 3, 2, 6,] l1.reverse() print(l1) #输出结果为: [6, 2, 3, 4, 8, 9, 1]
4.4:数字、字符串、布尔之间的转换
str ---> int
前提是:转换前的字符串全都由数字组成
int ---> str
- 所有数字都能转换为字符串
- str(int)
int ---> bool
- 0---> False
- 非0 ---> True
- bool(int)
print(bool(100)) print(bool(-1)) print(bool(0)) #输出结果为: True True False
bool --> int
- True ---> 1
- False --->0
- int(bool)
print(int(True)) print(int(False)) #输出结果为: 1 0
str ---> bool
- 非空---> True
- 空字符串---> False
- bool('str')
print(bool('')) print(bool('fdsaf')) #输出结果为: False True
bool --->str
没有意义
print(str(True),type(str(True))) #输出结果为: True <class 'str'>
str ---> list
-
split
list --> str
-
join
五、布尔类型(bool)
两个值 ,一个True(真),一个False(假), 主要用记逻辑判断;
六 、列表(list)
包含在[ ]内,用逗号分隔。
里面可以存放各种数据类型比如:li = [‘alex’,123,Ture,(1,2,3,’wusir’),[1,2,3,’小明’,],{‘name’:’alex’}]
用途:(存多个值,可以修改)
6.1:列表语法
| 表达式 | 结果 | 描述 |
| L[2] | 'SPAM!' | 读取列表中第三个元素 |
| L[-2] | 'Spam' | 读取列表中倒数第二个元素 |
| L[1:] | ['Spam', 'SPAM!'] | 从第二个元素开始截取列表 |
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print x | 1 2 3 | 迭代 |
6.2:列表操作包含以下函数
| cmp(list1, list2) | 比较两个列表的元素 |
| len(list) | 列表元素个数 |
| max(list) | 返回列表元素最大值 |
| min(list) | 返回列表元素最小值 |
| list(seq) | 将元组转换为列表 |
6.3:列表包含以下方法
| list.append(obj) | 在列表末尾添加新的对象 |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index, obj) | 将对象插入列表 |
| list.pop(obj=list[-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
| list.reverse() | 反向列表中元素 |
| list.sort([func]) | 对原列表进行排序 |
6.4:查看

#按照索引,切片(步长),for 循环遍历。 l = ['WuSir', 'alex', 'OldBoy', 'barry'] for i in l: print(i) #输出结果为: WuSir alex OldBoy barry
6.5:增加

li = [1,'a','b',2,3,'a']
insert#按照索引去增加 li.insert(0,55) print(li) #输出结果为: [55, 1, 'a', 'b', 2, 3, 'a'] append#增加到最后 li.append('aaa') print(li) #输出结果为: [1, 'a', 'b', 2, 3, 'a', 'aaa'] #增加到最后 li.append([1,2,3]) print(li) #输出结果为: [1, 'a', 'b', 2, 3, 'a', [1, 2, 3]] extend#迭代的去增 li.extend(['q,a,w']) li.extend(['q,a,w','aaa']) li.extend('a') li.extend('abc') li.extend('a,b,c') print(li) #输出结果为: [1, 'a', 'b', 2, 3, 'a', 'q,a,w', 'q,a,w', 'aaa', 'a', 'a', 'b', 'c', 'a', ',', 'b', ',', 'c']
# append() l = ['WuSir', 'alex', 'OldBoy', 'barry'] l.append('景女神') print(l) l.append(1) print(l) l.append([1, 2, 3]) print(l) #输出结果为: ['WuSir', 'alex', 'OldBoy', 'barry', '景女神'] ['WuSir', 'alex', 'OldBoy', 'barry', '景女神', 1] ['WuSir', 'alex', 'OldBoy', 'barry', '景女神', 1, [1, 2, 3]] # insert() l = ['WuSir', 'alex', 'OldBoy', 'barry'] l.insert(1, '葫芦') print(l) #输出结果为: ['WuSir', '葫芦', 'alex', 'OldBoy', 'barry'] # extend() l = ['WuSir', 'alex', 'OldBoy', 'barry'] l.extend('abc') print(l) l.extend([1, '2122', 56]) print(l) #输出结果为: ['WuSir', 'alex', 'OldBoy', 'barry', 'a', 'b', 'c'] ['WuSir', 'alex', 'OldBoy', 'barry', 'a', 'b', 'c', 1, '2122', 56]
6.6:修改

li = [1,'a','b',2,3,'a'] li[1] = 'dfasdfas' print(li) #输出结果为: [1, 'dfasdfas', 'b', 2, 3, 'a'] li = [1,'a','b',2,3,'a'] li[1:3] = ['a','b'] print(li) #输出结果为: [1, 'a', 'b', 2, 3, 'a']
l = ['WuSir', 'alex', 'OldBoy', 'barry'] #按照索引改 l[0] = '日天' print(l) l[2] = '老男孩' print(l) #输出结果为 ['日天', 'alex', 'OldBoy', 'barry'] ['日天', 'alex', '老男孩', 'barry'] # 按照切片去改 l = ['WuSir', 'alex', 'OldBoy', 'barry'] l[:3] = 'abcdgfdljgkfdgjlfdlgjfdsaklfdjskladsfj' l[:3] = 'a' l[:3] = [11, 22, 33, 44] #加步长 必须一一对应 l[:3:2] = 'ab' print(l) #输出结果为: ['a', 22, 'b', 44, 'f', 'd', 'l', 'j', 'g', 'k', 'f', 'd', 'g', 'j', 'l', 'f', 'd', 'l', 'g', 'j', 'f', 'd', 's', 'a', 'k', 'l', 'f', 'd', 'j', 's', 'k', 'l', 'a', 'd', 's', 'f', 'j', 'barry']
6.7:删除

li = [1,'a','b',2,3,'a']
#按照索引pop l1 = li.pop(1) print(l1) #输出结果为: a #按照位置、切片del del li[1:3] print(li) #输出结果为: [1, 2, 3, 'a'] #按照元素remove li.remove('a') print(li) #输出结果为: [1, 'b', 2, 3, 'a'] #清空列表clear li.clear() #输出结果为:
#将索引为奇数对应的元素删除 l1 = [11, 22, 33, 44, 55] del l1[1::2] print(l1) #输出结果为: [11, 33, 55]
#再循环一个列表时,不要改变列表的大小,这样会影响结果。 l1 = [11, 22, 33, 44, 55] for i in range(len(l1)): print(i) print(l1) if i % 2 == 1: del l1[i] print(i) print(l1) print(l1) #输出结果为: 0 [11, 22, 33, 44, 55] 0 [11, 22, 33, 44, 55] 1 [11, 22, 33, 44, 55] 1 [11, 33, 44, 55] 2 [11, 33, 44, 55] 2 [11, 33, 44, 55] 3 [11, 33, 44, 55] 3 [11, 33, 44] 4 [11, 33, 44] 4 [11, 33, 44] [11, 33, 44]
l1 = [11, 22, 33, 44, 55] for i in range(len(l1)-1,-1,-1): if i % 2 == 1: del l1[i] print(l1) #输出结果为: [11, 33, 55]
dic = {'k1': 'v1', 'k2': 'v2', 'k3':'v3', 'name':'alex'}
s1 = 'abc'
print('a' in s1)
l1 = []
for i in dic:
if 'k' in i:
l1.append(i)
print(l1)
for i in l1:
del dic[i]
print(dic)
#
dic = dict.fromkeys('abc',666)
print(dic)
#输出结果为:
True
['k1', 'k2', 'k3']
{'name': 'alex'}
{'a': 666, 'b': 666, 'c': 666}
6.8:列表的嵌套
l1 = [1, 2, 'alex', ['WuSir', 'taibai', 99], 6] # 将alex该成Alex l1[2] = l1[2].capitalize() print(l1) #输出结果为: [1, 2, 'Alex', ['WuSir', 'taibai', 99], 6]
l1 = [1, 2, 'alex', ['WuSir', 'taibai', 99], 6] #将'WuSir'变成全部大写。 l1[3][0] = l1[3][0].upper() print(l1) #输出结果为: [1, 2, 'alex', ['WUSIR', 'taibai', 99], 6]
l1 = [1, 2, 'alex', ['WuSir', 'taibai', 99], 6] # 99让其通过数字加1的方式变成 '100'. l1[3][-1] = str(l1[3][-1] + 1) print(l1) #输出结果为: [1, 2, 'alex', ['WuSir', 'taibai', '100'], 6]
七、字典(dict)
- key-values存储,可以存储大量的的关系型数据,查询速度非常快。
- 字典的键 必须是唯一的,不可重复,value 可以为任意数据类型或者对象。
- 字典的键只能是不可变的数据类型:
- 数据类型的分类:
- 不可变(可哈希的)得数据类型:int str tuple bool
- 可变的(不可哈希的)数据类型:dict,list,set
- 定义:在{},用逗号隔开,每一个元素的形式都是键值对,即key:value。
- 用途:可以有多个值,这一点与列表相同,但可以是任意数据类型
- 特征:每一个值都有唯一一个对应关系,即key。key、字符串、数字是不可变类型。
7.1:字典包含了以下内置函数
| cmp(dict1, dict2) | 比较两个字典元素 |
| len(dict) | 计算字典元素个数,即键的总数 |
| str(dict) | 输出字典可打印的字符串表示 |
| type(variable) | 返回输入的变量类型,如果变量是字典就返回字典类型 |
7.2:字典包含了以下内置方法
| radiansdict.clear() | 删除字典内所有元素 |
| radiansdict.copy() | 返回一个字典的浅复制 |
| radiansdict.fromkeys() | 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| radiansdict.get(key, default=None) | 返回指定键的值,如果值不在字典中返回default值 |
| radiansdict.has_key(key) | 如果键在字典dict里返回true,否则返回false |
| radiansdict.items() | 以列表返回可遍历的(键, 值) 元组数组 |
| radiansdict.keys() | 以列表返回一个字典所有的键 |
| radiansdict.setdefault(key, default=None) | 和get()类似, 但如果键不已经存在于字典中,将会添加键并将值设为default |
| radiansdict.update(dict2) | 把字典dict2的键/值对更新到dict里 |
| radiansdict.values() | 以列表返回字典中的所有值 |
7.3:查看

dic = { 'name': '老男孩', 'age': 10000, 'sex': '男', } print(dic['name']) print(dic.get('name')) #输出结果为: 老男孩 老男孩
dic = { 'name': '老男孩', 'age': 10000, 'sex': '男', } # 类似于列表的一个容器,没有索引 print(dic.keys()) for i in dic.keys(): print(i) for i in dic: print(i) #输出结果为: dict_keys(['name', 'age', 'sex']) name age sex name age sex
dic = { 'name': '老男孩', 'age': 10000, 'sex': '男', } print(dic.values()) print(dic.items()) for i in dic.items(): print(i) #输出结果为: dict_values(['老男孩', 10000, '男']) dict_items([('name', '老男孩'), ('age', 10000), ('sex', '男')]) ('name', '老男孩') ('age', 10000) ('sex', '男')
dic = { 'name': '老男孩', 'age': 10000, 'sex': '男', } # 分别赋值 a, b = 1 ,3 a, b = [22, 33] print(a,b) for k, v in dic.items(): print(k, v) #输出结果为: 22 33 name 老男孩 age 10000 sex 男
7.4:增加

dic = { 'name': '老男孩', 'age': 10000, 'sex': '男', } # 无责增加,有责修改。 dic['hobby'] = 'old_girl' dic['name'] = 'alex' print(dic) #输出结果为: {'name': 'alex', 'age': 10000, 'sex': '男', 'hobby': 'old_girl'} # 有key则不修改,无责添加。 dic.setdefault('high') dic.setdefault('high', 169) dic.setdefault('name', 'wusir') print(dic) #输出结果为: {'name': 'alex', 'age': 10000, 'sex': '男', 'hobby': 'old_girl', 'high': None}
7.5:修改

dic = { 'name': '老男孩', 'age': 10000, 'sex': '男', } # 无责增加,有责修改. dic['name'] = 'alex' print(dic) #输出结果为: {'name': 'alex', 'age': 10000, 'sex': '男'}
dic = {"name": "jin", "age": 18,"sex": "male"}
dic2 = {"name": "alex", "weight": 75}
#将dic里面的键值对覆盖并更新到dic2中,dic不变 。
dic2.update(dic)
print(dic)
print(dic2)
#输出结果为:
{'name': 'jin', 'age': 18, 'sex': 'male'}
{'name': 'jin', 'weight': 75, 'age': 18, 'sex': 'male'}
7.6:删除

dic = { 'name': '老男孩', 'age': 10000, 'sex': '男', } # 返回值 print(dic.pop('name')) dic.pop('name1',None) print(dic) #输出结果为: 老男孩 {'age': 10000, 'sex': '男'} #popitem 随机删除 有返回值 print(dic.popitem()) print(dic) #输出结果为: ('sex', '男') {'name': '老男孩', 'age': 10000} #clear删除整个字典 dic.clear() print(dic) #输出结果为: {} #按照键去删除键值对 del dic['name'] print(dic) #输出结果为: {'age': 10000, 'sex': '男'}
7.7:字典的嵌套
dic = {'name_list':['高猛', '于其',],
1:{
'alex': '李杰',
'high': '175',
}
}
###为['高猛', '于其',] 追加一个元素'wusir',2,
### 为{'alex': '李杰','high': '175' } 增加一个键值对 'sex': man,
dic['name_list'].append('wusir')
print(dic)
print(dic[1])
dic[1]['sex'] = 'man'
print(dic)
#输出结果为:
{'name_list': ['高猛', '于其', 'wusir'], 1: {'alex': '李杰', 'high': '175'}}
{'alex': '李杰', 'high': '175'}
{'name_list': ['高猛', '于其', 'wusir'], 1: {'alex': '李杰', 'high': '175', 'sex': 'man'}}
八、集合
8.1:作用
可以包含多个元素,用逗号分割,将不同的值存放在一起做关系运算。
1.每个元素必须是不可变类型(可hash,可作为字典的key)
2.没有重复的元素
3.无序
8.2:用法
- |(并集)
- &(交集)
- -(差集)
- ^(对称差集)
集合add方法:是把要传入的元素做为一个整个添加到集合中,例如:
>>> a = set('boy')
>>> a.add('python')
>>> a
set(['y', 'python', 'b', 'o'])
集合update方法:是把要传入的元素拆分,做为个体传入到集合中,例如:
>>> a = set('boy')
>>> a.update('python')
>>> a
set(['b', 'h', 'o', 'n', 'p', 't', 'y'])
集合删除操作方法:remove
set(['y', 'python', 'b', 'o'])
>>> a.remove('python')
>>> a
set(['y', 'b', 'o'])
8.3:例子
- bingo = {"人","生","苦","短","我","用","python"}
- awful = {"python","要","被","我","所","用"}
1.求bingo和awful的交集
>>> bingo = {"人","生","苦","短","我","用","python"}
>>> awful = {"python","要","被","我","所","用"}
>>> print(bingo & awful)
{'我', '用', 'python'}
>>>
2.求bingo和awful的并集
>>> bingo = {"人","生","苦","短","我","用","python"}
>>> awful = {"python","要","被","我","所","用"}
>>> print(bingo | awful)
{'用', '所', '生', '人', '我', '要', 'python', '苦', '被', '短'}
>>>
3.求只在bingo中出现的元素集合
>>> bingo = {"人","生","苦","短","我","用","python"}
>>> awful = {"python","要","被","我","所","用"}
>>> print(bingo - awful)
{'短', '人', '苦', '生'}
>>>
4.求没有同时存在bingo和awful中的元素集合
>>> bingo = {"人","生","苦","短","我","用","python"}
>>> awful = {"python","要","被","我","所","用"}
>>> print(bingo ^ awful)
{'所', '要', '生', '人', '被', '苦', '短'}
>>>
5.解压
test,*_={'包子','饺子','丸子',}
print(test)
九、数据类型嵌套

作者:HaydenGuo
出处:https://www.cnblogs.com/ghl1024/
每一个前十年都想不到后十年我会演变成何等模样,可知人生无常,没有什么规律,没有什么必然。
只要我还对新鲜的知识、品格的改进、情感的扩张、有胃口,这日子就是值得度过的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号