

当有很多MCP服务可用时,会出现两大瓶颈:
- “长上下文”(Long Context)的限制,不可能把所有可能的工具说明书一次性的全塞进提示词中。
- 对于复杂多步任务,“一次性检索不够用”。
论文:《MCP-Zero: Active Tool Discovery for Autonomous LLM Agents》提出通过一种“LLM规划 + 按需工具库”的协同模式来解决上面问题。
论文:https://arxiv.org/abs/2506.01056
源码:https://github.com/xfey/MCP-Zero
它的核心思想是不让 LLM 成为一个“无所不知”的万能工具箱,而是把它变成一个“聪明的规划师”。这个规划师在执行任务时,如果发现自己缺少某个能力,它不会卡住,而是会主动地、按需地向一个外部的“工具库”(由检索器管理)发出请求,获取完成当前这一步所需的那个特定工具,然后使用它,通过不断迭代循环来完成任务。
这样就不需要为了学习使用某个新工具而进行专门的训练或微调。只要工具的描述被添加到了工具库里,LLM 就有能力通过这种 “提问-获取-使用” 的模式来调用它,这使得系统具有极强的扩展性。
使用 MCP-Zero 主动构建“制作美味佳肴”的工具链
这个图示中,演示了前面两种问题和MCP-Zero的解决方案:

(a) MCP info in system prompt
将所有的 MCPs(完整的工具说明书)一次性全部放入 LLM 的系统提示(System Prompt)中。
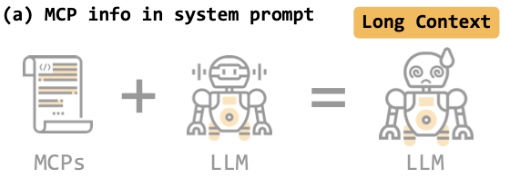
这会带来"Long Context" (长上下文) 的问题:
当 MCPs 数量庞大时(成百上千个工具),这会导致输入给 LLM 的上下文变得极长。
这不仅会增加计算成本和延迟,还可能超出 LLM 的上下文窗口限制,并且过多的信息容易让 LLM 感到“困惑”(如图中头晕的机器人),导致其性能下降,难以准确选择正确的工具。
(b) Retrieval-augmented tool selection (先查一下用户可能需要什么工具)
这是一种改进方法,即检索增强生成(RAG)。
当用户提出一个查询(Query)时,系统首先使用检索器(Retriever)在所有 MCPs 中搜索,找出与当前查询最相关的一个工具,然后将这个工具的信息提供给 LLM。

这是"Not Enough" (不够用)
这种方法对于简单的、一步就能完成的任务可能有效。
但对于复杂的多步骤任务(比如吃一顿西餐需要叉子、刀子和勺子),它在任务开始时只检索一次,可能只找到了第一步最需要的工具(叉子)。
当 LLM 完成第一步后,它不知道接下来该做什么,因为后续需要的工具(刀、勺)信息并没有被提供。
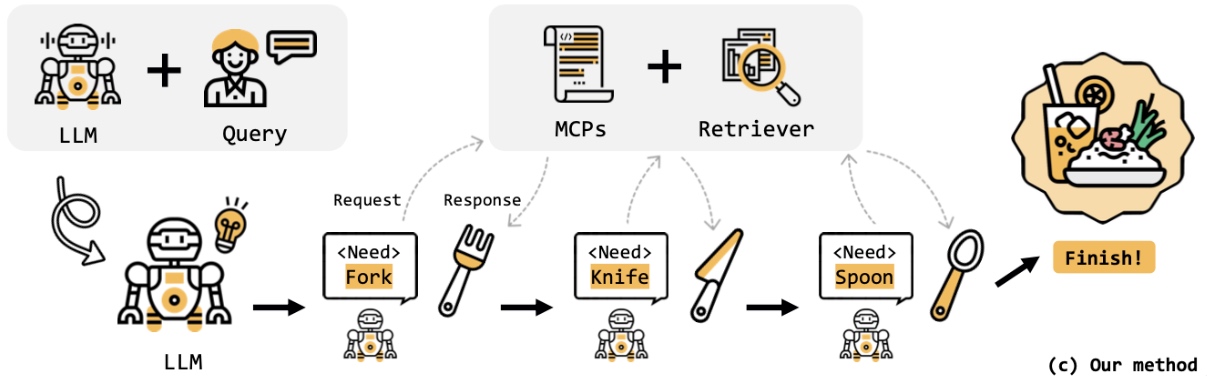
MCP-Zero 的方法
这是论文提出的核心方法,它是一个动态的、迭代的推理-检索循环。
-
开始: LLM (机器人) 接收到用户的初始 Query (指令)。
-
思考与请求 (Reasoning & Request): LLM 首先进行思考(由卷曲箭头和灯泡表示),将复杂任务分解为第一步。它判断出当前最需要的是“叉子”,于是生成一个内部请求
Fork。 -
按需检索 (On-demand Retrieval): 这个
Fork 请求被发送到 MCPs + Retriever 模块。检索器此时才开始工作,精确地从所有 MCPs 中找到“叉子”这个工具的详细说明和用法。 -
响应与执行 (Response & Execution): 检索器将“叉子”的信息返回(Response)给 LLM。LLM 接收到信息后,就知道如何使用叉子来完成第一步操作。
-
循环迭代: 完成第一步后,LLM 继续思考,发现还需要“刀子”。于是它再次发出请求
Knife,重复上述的检索-响应-执行流程。这个过程一直持续,直到它获取并使用了所有必要的工具(叉子、刀子、勺子)。 -
完成: 当所有子任务都通过这种“需要时才去查找”的方式完成后,整个复杂任务(吃完一顿饭)也就成功了,最终达到 "Finish!" 的状态。
这张图形象地说明了 MCP-Zero 方法的优越性:
-
对比 (a): 它避免了一次性加载所有工具信息,从而解决了长上下文带来的低效和性能下降问题。它的上下文是动态和精简的。
-
对比 (b): 它不是一次性检索,而是将任务分解,并在每一步都进行按需检索。这使得 LLM 能够像人一样,一步一步地思考和行动,从而完成需要多个工具协作的复杂任务,解决了“一次检索不够用”的问题。
因此,MCP-Zero 方法的核心是一种 “让LLM做规划,让检索器做执行辅助” 的协同工作模式。
LLM 负责高级的推理和任务分解,而检索器则作为其外部知识库,在需要时为其提供精确、即时的工具信息,从而实现高效、准确且可扩展的零样本(Zero-shot)任务自动化。
代码调试任务拆解示例
论文中还有另外一个案例展示:
用户向 LLM Agent 发出了一个指令:Debug my code: 'src/train.py'
整个过程分为三个清晰的阶段,每个阶段都是一个完整的“请求-检索-执行”循环。
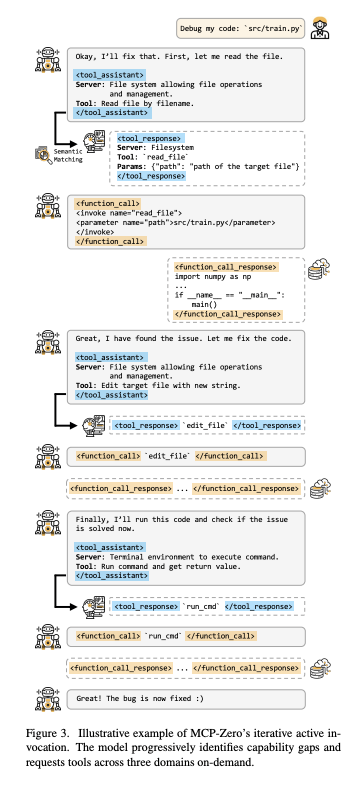
阶段一:读取文件
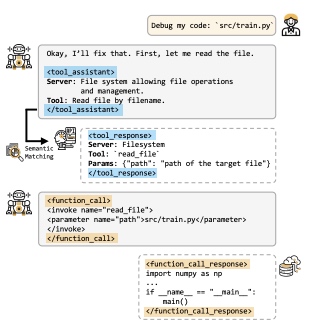
思考与请求: LLM 接收到用户指令。它的第一步自然是查看代码。它心想:“好的,我来修复它。首先,让我读一下这个文件。” 然后,它将这个需求形式化,放进 <tool_assistant> 标签中,描述它需要一个来自“文件系统(File system)”服务器的、能够“按文件名读取文件(Read file by filename)”的工具。
检索: 语义匹配模块接收到这个描述,找到了 read_file 这个工具。它在 <tool_response> 中返回该工具的正式定义,指明了工具名和它需要一个 path 参数。
执行: LLM 现在知道了如何使用这个工具。它构建一个 <function_call>,调用 read_file 并传入正确的参数 path="src/train.py"。
获取结果: 系统执行调用,并在 <function_call_response> 标签中返回 src/train.py 文件的实际内容。
修复代码
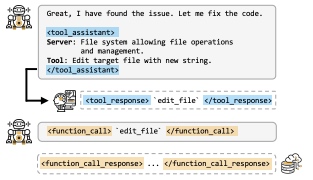
思考与请求: 在分析了文件内容后,LLM 找到了 bug 所在。现在它需要修复代码。它心想:“很好,我找到问题了。现在来修改代码。” 这需要一个新的能力:编辑文件。于是它生成一个新的 <tool_assistant> 请求,这次需要一个能“用新字符串编辑目标文件(Edit target file with new string)”的工具。
检索与执行: 流程重复。系统检索到 edit_file 工具,LLM 调用它并传入必要的参数(如文件路径和修改后的新代码内容,图中用 ... 省略)。
获取结果: 系统确认文件已被成功修改。
验证修复

思考与请求: 代码改好了,但任务还没结束。代理需要验证修复是否有效。它心想:“最后,我来运行一下代码,看看问题是否解决了。” 这需要来自另一个领域的又一个能力:在终端中运行命令。于是它生成 <tool_assistant> 请求,需要一个来自“终端环境(Terminal environment)”的工具,用于“运行命令并获取返回值(Run command and get return value)”。
检索与执行: 系统检索到 run_cmd 工具。LLM 接着调用这个函数,命令很可能是 python src/train.py。
获取结果: 系统执行该命令并返回输出。假设代码成功运行没有报错,代理便可以确认 bug 已被修复。
最后,LLM 向用户汇报最终结果:"Great! The bug is now fixed 😃" (太棒了!Bug 已经修复了 😃)。
上面这张图完美地诠释了:“MCP-Zero 迭代式主动调用。模型逐步识别能力差距,并按需请求跨三个领域的工具。”
-
逐步与迭代 (Progressive & Iterative): 它不是一次性解决问题,而是分了三个步骤,一步步推进。
-
识别能力差距 (Identifies Capability Gaps): 在每一步(读、改、运行),LLM 都意识到自己需要一个外部工具来弥补自身能力的不足。
-
按需请求 (On-demand Requests): 它只在读完文件后才去寻找 edit_file 工具;只在改完文件后才去寻找 run_cmd 工具。这种方式非常高效。
-
跨领域 (Across Three Domains): 它无缝地使用了来自不同“服务器”或环境的工具(文件系统 和 终端),展示了该方法的灵活性和通用性。
总结
MCP-Zero 的核心思想非常巧妙:它不把 LLM 当作一个需要背下所有工具用法说明的“万能工匠”,而是将其定位为一个 “聪明的总规划师”。这个规划师在执行任务时,会采用一个动态的、迭代的“思考-请求-执行”循环:
- 分解任务,识别出完成当前步骤所需要的能力(例如“读取文件”)。
- 发起按需请求,用自然语言描述它需要一个什么样的工具。
- 外部检索器根据请求,精确地从庞大的工具库中找到并返回该工具的用法。
- LLM 调用该工具,完成当前步骤。
- 重复此循环,直到整个复杂任务被一步步分解并最终完成。
它解决了两大核心问题:
-
解决了“长上下文”瓶颈:通过“按需检索”而非“一次性加载”所有工具,它极大地降低了计算成本和延迟,避免了因上下文过长导致的性能下降,让 LLM 始终能专注在当前任务上。
-
解决了“一次检索不够用”的难题:通过“迭代循环”,它使 LLM 能够处理需要多个不同工具、分多步完成的复杂任务,完美解决了传统检索增强方法在多步任务中会“卡住”的问题。

MCP-Zero 就像是赋予了一个大厨(LLM)一本巨大的菜谱(工具库)和一个能帮他快速翻页的助手(检索器)。大厨不需要记住所有菜的做法,他只需专注于规划要做哪道菜,然后在需要时让助手立刻翻到那一页,从而高效地烹饪出一桌丰盛的宴席(完成复杂任务)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号