

前面分析了LLM有了超长上下文,还需要RAG么?,结论是:RAG 在精准性、实时性和成本上仍有绝对优势。如果你需要精准答案、实时数据、低幻觉,RAG 仍是必选项。
哪在目前目前常见LLM的上下文普遍支持64K–128K,部分达到百万级背景下,RAG的拆分块大小是否需要增大呢?
先说结论: RAG的拆分块大小可以适当增大,但通常仍应保持较小。
块大小(chunk size)是RAG系统中的关键参数,影响检索精度和生成质量。
块大小选择的影响因素
块大小的选择受到多个因素的影响,包括检索精度、嵌入模型的限制以及LLM的性能。以下是关键考虑:
检索精度:
较小的块能更精确地捕捉特定信息,提高检索的相关性。较大的块可能导致嵌入向量失去针对性,降低检索质量。
嵌入模型限制:
嵌入模型(如OpenAI text-embedding-3-large)通常有较小的上下文窗口(如8K tokens),因此块大小需要适应这些限制。
“针在干草垛”问题:
当上下文过大时,LLM可能难以聚焦于相关信息,导致回答质量下降。较小的块通过检索多个相关块来缓解此问题。
成本与延迟:
较大的块减少了块的数量,可能降低存储成本和检索延迟,但可能牺牲精度。
上面的认知是有研究证据的:
Nvidia研究:OP-RAG机制
Nvidia的论文 In Defense of RAG in the Era of Long-Context Language Models 提出了一种名为OP-RAG(Order-Preserve RAG)的机制,专门针对长上下文LLM。
https://arxiv.org/html/2409.01666v1
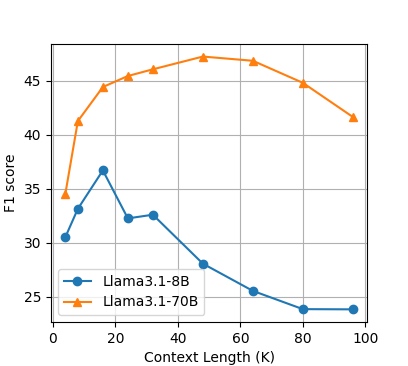
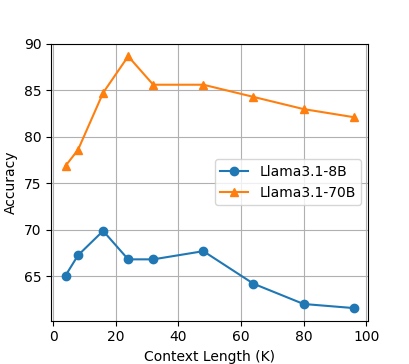
研究使用128 tokens的块大小,并发现性能在16K到48K tokens的总上下文长度时达到峰值。例如:
EN.QA 测试集
EN.MC 测试集
-
Llama3.1-8B在EN.QA和EN.MC数据集上的最佳性能为16K tokens。
-
Llama3.1-70B在EN.QA上的最佳性能为48K tokens。
这表明,即使上下文窗口很大(如128K),使用小的块(128 tokens)并检索多个块能显著提高回答质量。
研究还指出,长上下文LLM在处理大量信息时容易失去对相关信息的聚焦,OP-RAG通过保持块的原始顺序并使用小块来改善此问题。
Databricks研究:长上下文RAG性能
Databricks的博客Long Context RAG Performance of LLMs报告了使用512 tokens块大小和256 tokens步长的实验设置。
https://www.databricks.com/blog/long-context-rag-performance-llms
研究评估了多个长上下文LLM(如GPT-4o、Claude-3-5-Sonnet等)在RAG任务中的表现,上下文长度从2,000到128,000 tokens变化。

GPT、Claude、Llama、Mistral 和 DBRX 模型在 4 个精选 RAG 数据集(Databricks DocsQA、FinanceBench、HotPotQA 和 Natural Questions)上的长上下文性能
他的检索设置 :
- 嵌入模型:(OpenAI)text-embedding-3-large
- 块大小:512 个token(我们将语料库中的文档分成 512 个标记的块大小)
- 步幅大小:256 个 token(相邻块之间的重叠为 256 个 token)
- 向量存储: FAISS (带有 IndexFlatL2 索引)
结果显示,512 tokens的块大小在多种数据集上表现良好,特别是在长上下文场景下。
LlamaIndex的块大小评估
LlamaIndex的博客 Evaluating the Ideal Chunk Size for a RAG System using LlamaIndex 测试了128、256、512、1024和2048 tokens的块大小,发现1024 tokens在响应时间和质量(忠实度和相关性)之间达到最佳平衡。
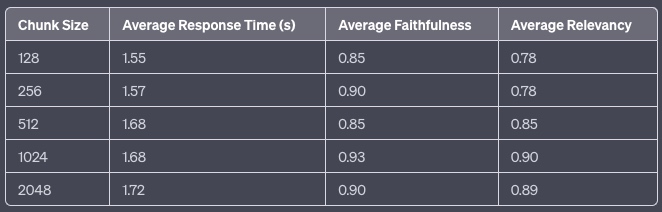
然而,该研究主要针对较小上下文窗口的LLM,适用于更广泛的场景。
行业最佳实践
多个技术博客(如Pinecone的Chunking Strategies for LLM Applications和Unstructured的Considerations for Chunking for Optimal RAG Performance)建议从128到1024 tokens的范围开始实验。
https://www.pinecone.io/learn/chunking-strategies/
Pinecone特别提到,较小的块(如256或512 tokens)在语义搜索中表现更好,因为它们减少了噪声并保持相关性。
https://unstructured.io/blog/chunking-for-rag-best-practices
为什么使用较小的块大小?
即使LLM的上下文窗口达到64K或128K,研究仍倾向于使用较小的块大小,原因包括:
聚焦相关信息:
长上下文LLM容易在大量信息中失去焦点,较小的块通过检索多个相关块帮助模型聚焦(SuperAnnotate的博客RAG vs. Long-context LLMs提到,Nvidia研究发现长上下文可能导致回答质量下降)。
https://www.superannotate.com/blog/rag-vs-long-context-llms
嵌入质量:
嵌入模型的上下文窗口通常较小(如8K tokens),较大的块可能超出嵌入模型的能力,导致嵌入质量下降。
检索效率:
较小的块允许更细粒度的检索,特别是在使用相似性搜索时,能更好地匹配用户查询。
推荐块大小范围
基于以上研究,推荐的块大小范围为:
-
一般范围:128到512 tokens,适合大多数RAG应用,特别是长上下文场景。
-
实验范围:可以扩展到1024 tokens,特别是在需要更多上下文的复杂任务中。
注意事项:
块大小不应超过嵌入模型的上下文窗口(如8K tokens),且需要考虑块之间的重叠(stride),如Databricks使用的256 tokens步长。
结论与建议
对于输入上下文长度达到64K或128K的LLM,RAG系统的块大小不需增大到与上下文窗口相当。
研究和实践表明,较小的块大小(如128到512 tokens)通常更优,能提高检索精度和回答质量。
用户应根据具体任务和数据特性进行实验,建议从128到1024 tokens的范围开始测试,并评估性能指标(如忠实度、相关性和响应时间)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号