

昨天,我们还在欢呼:“LLAMA-4 支持 1M-10M 的超长上下文!以后一本书塞进去,直接问细节,岂不是无敌?”
今天,Fiction.LiveBench 的评测结果狠狠打脸
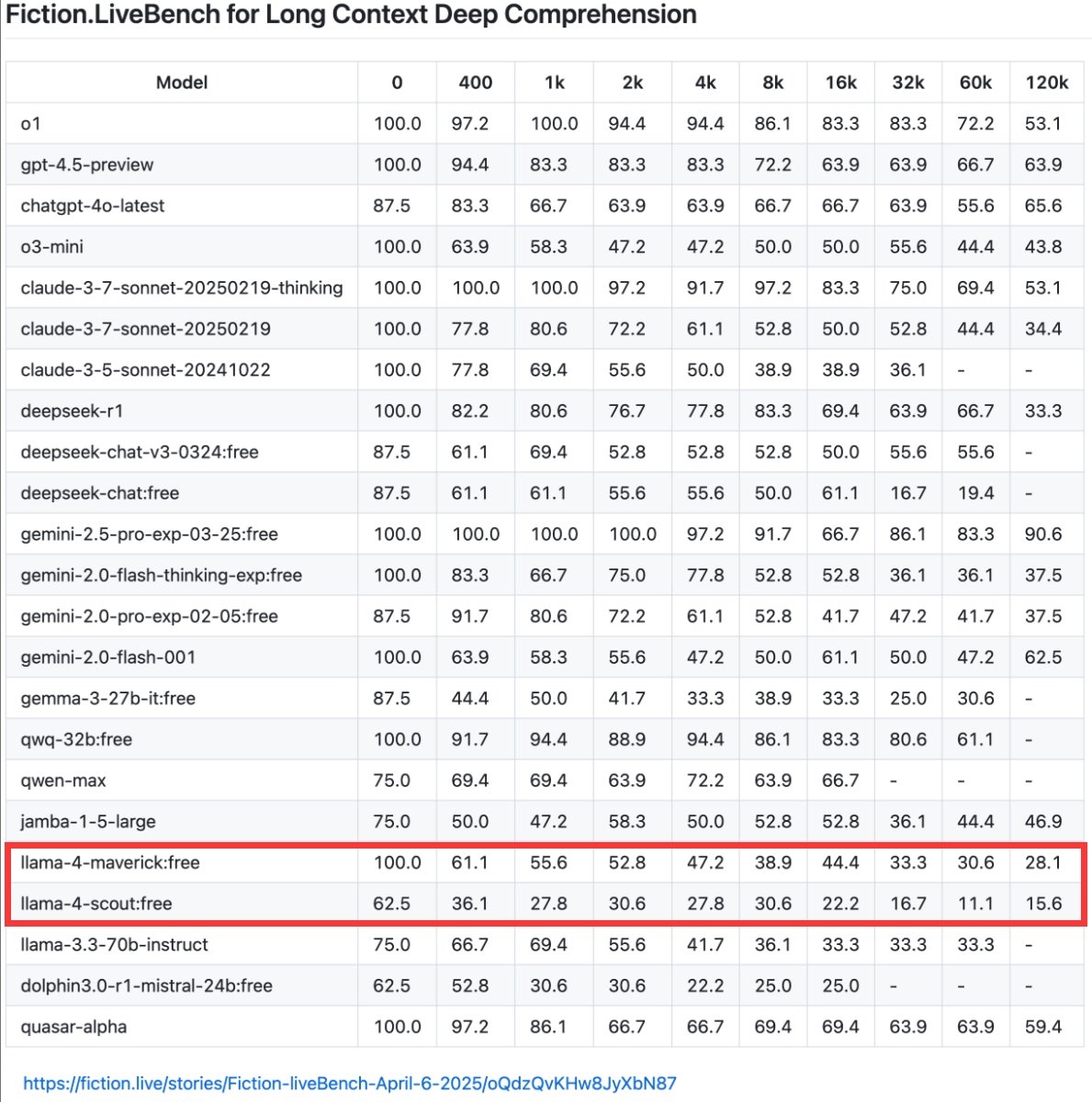
Llama-4 在 1K token 上下文时,召回率(近似回答正确率)就已经掉到 60% 以下,
而 Llama-4-Scout 在 16K 上下文时,正确率暴跌至 22%。
https://fiction.live/stories/Fiction-liveBench-April-6-2025/oQdzQvKHw8JyXbN87
这意味着什么?
-
《哈利波特与魔法石》全文约 16K token,你塞进去后问:“哈利小时候住在楼梯下的储物间还是卧室?”
-
Llama-4-Scout 只有 22% 的概率答对,比随机猜(50%)还差!
Fiction.LiveBench 的测试并非简单“搜索答案”,而是要求模型:
- 跟踪角色关系动态变化(如“从恨到爱再到痴迷”)。
- 基于伏笔进行逻辑预测。
- 区分“读者已知但角色未知”的秘密。
这些任务需要深度理解,而不仅是“找到关键词”。在Fiction.LiveBench评测中,部分模型表现尚可,Gemini 2.5 Pro 成为当前 SOTA(最高水平),Claude Sonnet 3.7 和 GPT-4.5 也表现稳定,但仍未达到“可靠写作助手”的标准。
为什么大上下文模型仍然“记不住”?
1、注意力机制的局限
Transformer 的注意力机制会随着上下文增长而“稀释”,导致模型更难聚焦关键信息。
2、训练数据的偏差
大多数模型在训练时优化的是短文本任务,超长上下文的泛化能力未被充分验证。
3、召回率 vs. 理解力
大模型或许能“理解”长文本的语义,但精准召回细节(如数字、人名、特定描述)仍然是硬伤。
我们实际使用时,肯定不能容忍1K以内召回达不到100%的模型,太长的上下文,容忍就容忍了,但是短的1K以内的,绝对没法容忍。
RAG 的不可替代性:精准、实时、可控
既然大模型在长上下文里“找东西”这么吃力,那 RAG(检索增强生成) 的优势反而更突出了:
1、精准召回
RAG 通过向量检索,直接定位关键段落,准确率远高于依赖模型“记忆”。
例如:问“《三体》中叶文洁何时首次发送信号?”
-
RAG:通过向量检索直接定位相关段落,准确率碾压依赖“模型记忆”。
-
纯LLM:可能胡编时间,甚至混淆事件。
2、实时数据支持
大模型的训练数据是固定的,而 RAG 可以实时检索最新信息(新闻、股价、论文)。
3、降低计算成本
处理 100K+ token 的上下文,GPU 开销巨大,而 RAG 只需检索相关片段,更高效、更便宜。
从上面排行榜中看,虽然 DeepSeek-r1、Qwen-max 长上下文下依然存在明显衰减, 但性价比突出。
未来方向:大模型 + RAG = 最佳组合
大上下文模型和 RAG 并非对立,而是互补,结合两者优势解决业务问题:
-
用大模型处理长上下文中的复杂逻辑。 大上下文LLM 负责复杂推理、情感分析、创意生成(如角色动机分析、故事大纲创作)。
-
用RAG补充实时或专有数据。 RAG 负责事实核查、细节召回、实时更新(如时间线整理、伏笔追踪)。
典型案例:
-
法律咨询场景中,模型分析用户的长篇案情描述(大上下文能力),同时通过RAG检索最新法律条文。
-
可解释性与可控性: RAG提供检索结果的引用来源,增强结果可信度(如学术研究、客户支持),而纯模型生成缺乏透明性。
结论:RAG 不会消失,只会更智能
Fiction.LiveBench 的测试证明:
-
当前大模型的长上下文能力仍不成熟,尤其在需要深度理解的场景中。目前如果你需要长文本创意生成(如小说写作),可尝试 Gemini 2.5 Pro 等领先模型。
-
RAG 在精准性、实时性和成本上仍有绝对优势。如果你需要精准答案、实时数据、低幻觉,RAG 仍是必选项。
未来会怎样?
注意力机制的局限性和经济成本的考虑,至少在技术没有重大突破前,RAG仍是刚需。
你怎么看?欢迎留言讨论!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号