pandas其他操作与可视化模块之matplotlib
目录
-
-
pandas实战案例
-
缺失值处理
1. df.isnull
2. df.notnull 3. df.fillna 4. df.dropna
案例
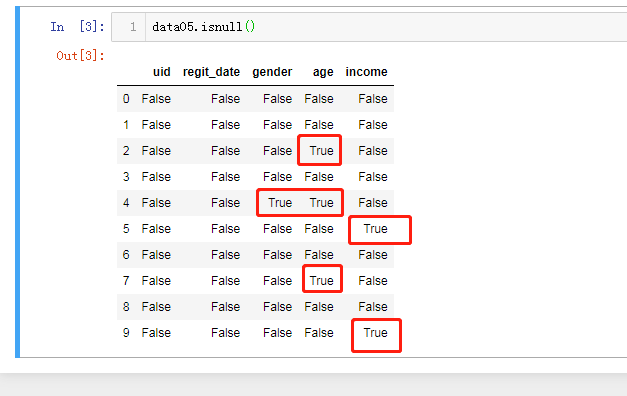
统计每个数据项是否有缺失
data05.isnull()
统计列字段下是否含有缺失
data05.isnull().any(axis = 0)

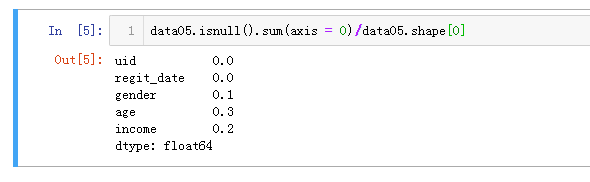
计算各列数据的缺失比例
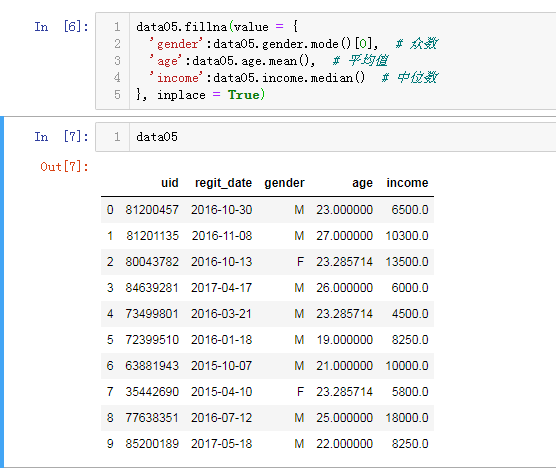
针对不同的缺失值,使用合理的填充手段
data05.fillna(value = { 'gender':data05.gender.mode()[0], 'age':data05.age.mean(), 'income':data05.income.median() }, inplace = True)
透视表功能
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All') data:指定需要构造透视表的数据集 values:指定需要拉入“数值”框的字段列表 index:指定需要拉入“行标签”框的字段列表 columns:指定需要拉入“列标签”框的字段列表 aggfunc:指定数值的统计函数,默认为统计均值,也可以指定numpy模块中的其他统计函数 fill_value:指定一个标量,用于填充缺失值 margins:bool类型参数,是否需要显示行或列的总计值,默认为False dropna:bool类型参数,是否需要删除整列为缺失的字段,默认为True margins_name:指定行或列的总计名称,默认为All
基本使用
data06 = pd.read_csv(r'diamonds.csv') data06.head() pd.pivot_table(data06, index = 'color', values='price', aggfunc='mean')

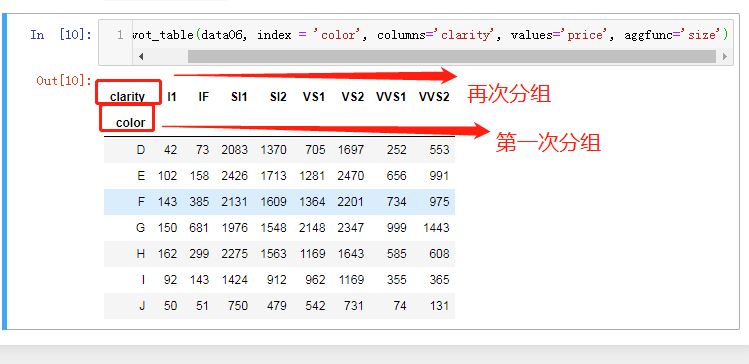
pd.pivot_table(data06, index = 'color', columns='clarity', values='price', aggfunc='size')
通过groupby方法,指定分组变量
import numpy as np grouped = data06.groupby(by = ['color','cut'])

对分组变量进行统计汇总
result = grouped.aggregate({'color':np.size, 'carat':np.min,
'price':np.mean, 'table':np.max})
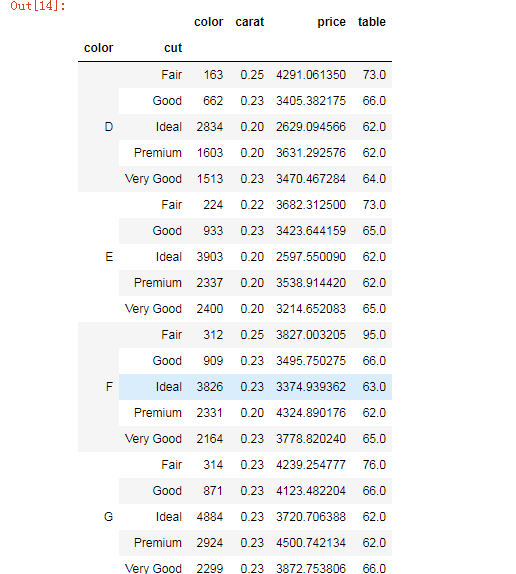
调整变量名的顺序
result = pd.DataFrame(result, columns=['color','carat','price','table'])
数据集重命名
result.rename(columns={'color':'counts',
'carat':'min_weight',
'price':'avg_price',
'table':'max_table'},
inplace=True)
分析NBA各球队冠军次数及球员FMVP次数
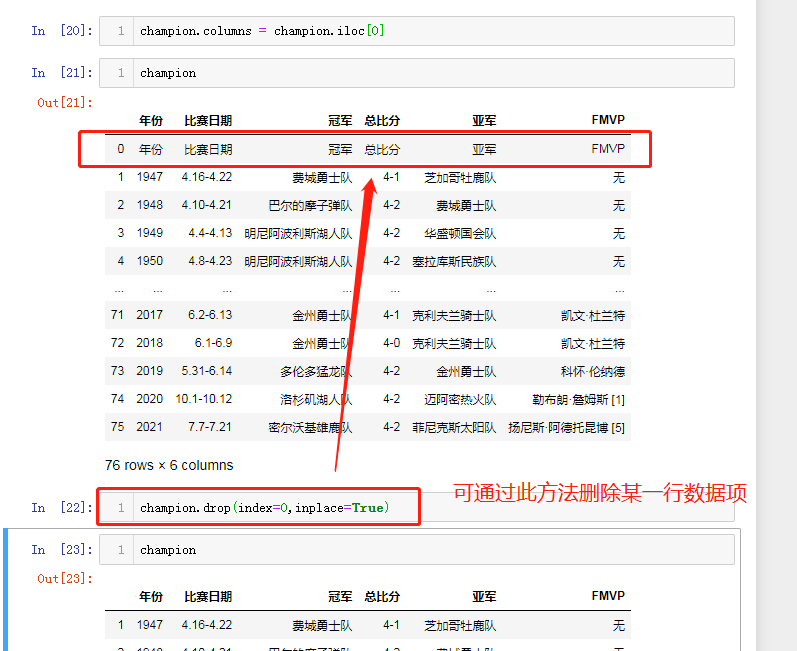
res = pd.read_html('https://baike.baidu.com/item/NBA%E6%80%BB%E5%86%A0%E5%86%9B/2173192?fr=aladdin') # 返回的是一个列表 type(res) res # 获取有效数据 champion = res[0] champion

处理列字段名称
champion.columns = champion.iloc[0] champion.drop(index=0,inplace=True) champion
获取每个球队的夺冠次数
res1 = champion.groupby(by='冠军').aggregate({'冠军':np.size}) res1

获取每个球队的夺冠次数和球员FMVP
# res2 = champion.groupby(['冠军','FMVP']).size() res2 = champion.groupby(['冠军','FMVP']).aggregate({'冠军':np.size}) res2

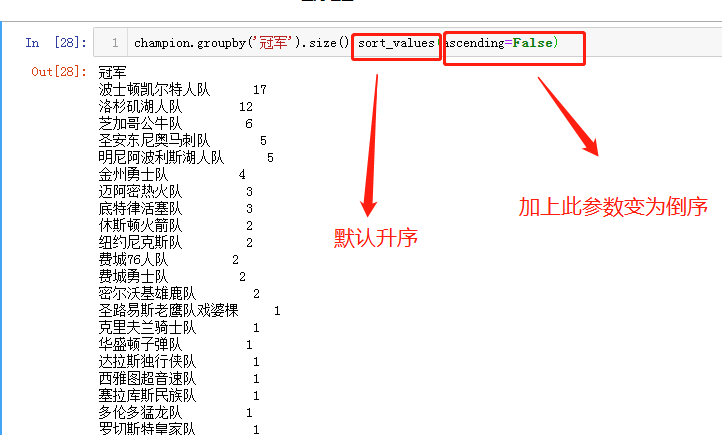
获取各组冠军次数(升序/降序)
champion.groupby('冠军').size().sort_values(ascending=False)
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None) objs:指定需要合并的对象,可以是序列、数据框或面板数据构成的列表 axis:指定数据合并的轴,默认为0,表示合并多个数据的行,如果为1,就表示合并多个数据的列 join:指定合并的方式,默认为outer,表示合并所有数据,如果改为inner,表示合并公共部分的数据 join_axes:合并数据后,指定保留的数据轴 ignore_index:bool类型的参数,表示是否忽略原数据集的索引,默认为False,如果设为True,就表示忽略原索引并生成新索引 keys:为合并后的数据添加新索引,用于区分各个数据部分
构造数据集
df1 = pd.DataFrame({ 'name':['张三','李四','王二'], 'age':[21,25,22], 'gender':['男','女','男']} ) df2 = pd.DataFrame({ 'name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']} )
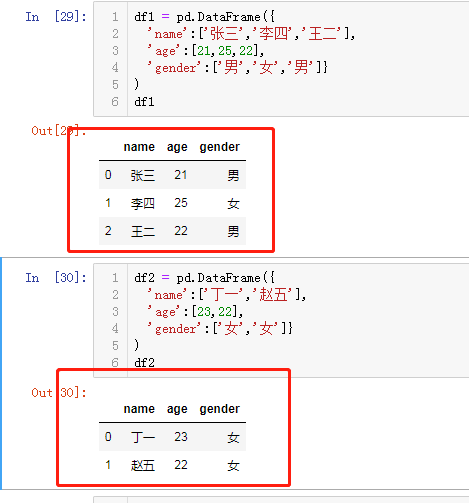
数据集的纵向合并
pd.concat([df1,df2]
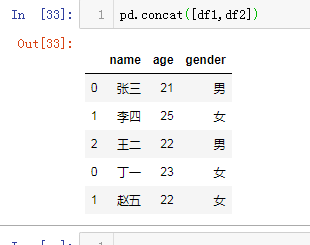
加keys参数可以在合并之后看到数据来源
pd.concat([df1,df2] , keys = ['df1','df2'])
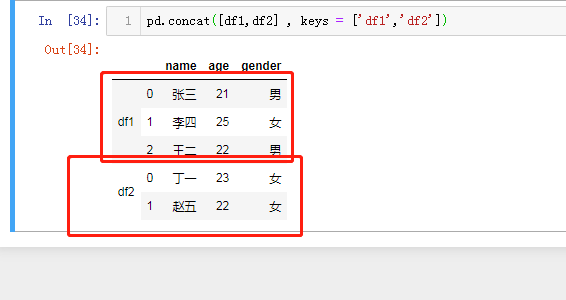
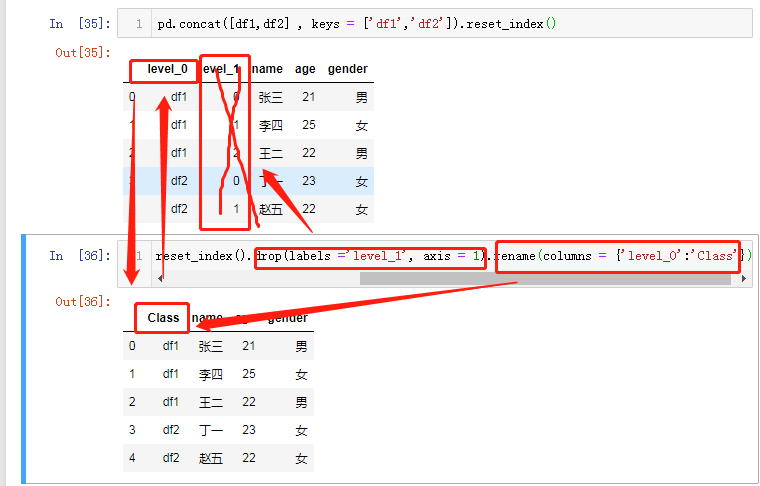
pd.concat([df1,df2] , keys = ['df1','df2']).reset_index() pd.concat([df1,df2] , keys = ['df1','df2']).reset_index().drop(labels ='level_1', axis = 1).rename(columns = {'level_0':'Class'})
假设
# 如果df2数据集中的“姓名变量为Name” df2 = pd.DataFrame({ 'Name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']} ) # 数据集的纵向合并 pd.concat([df1,df2])

小结论
concat行合并,数据源的变量名称需完全相同
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y')) left:指定需要连接的主 right:指定需要连接的辅表 how:指定连接方式,默认为inner内连,还有其他选项,如左连left、右连right和外连outer on:指定连接两张表的共同字段 left_on:指定主表中需要连接的共同字段 right_on:指定辅表中需要连接的共同字段 left_index:bool类型参数,是否将主表中的行索引用作表连接的共同字段,默认为False right_index:bool类型参数,是否将辅表中的行索引用作表连接的共同字段,默认为False sort:bool类型参数,是否对连接后的数据按照共同字段排序,默认为False suffixes:如果数据连接的结果中存在重叠的变量名,则使用各自的前缀进行区分
构造数据集


df3 = pd.DataFrame({ 'id':[1,2,3,4,5], 'name':['张三','李四','王二','丁一','赵五'], 'age':[27,24,25,23,25], 'gender':['男','男','男','女','女']}) df4 = pd.DataFrame({ 'Id':[1,2,2,4,4,4,5], 'score':[83,81,87,75,86,74,88], 'kemu':['科目1','科目1','科目2','科目1','科目2','科目3','科目1']}) df5 = pd.DataFrame({ 'id':[1,3,5], 'name':['张三','王二','赵五'], 'income':[13500,18000,15000]})
df3和df4连接
merge1 = pd.merge(left = df3, right = df4, how = 'left', left_on='id', right_on='Id')
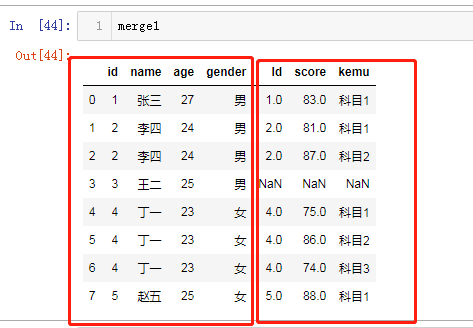
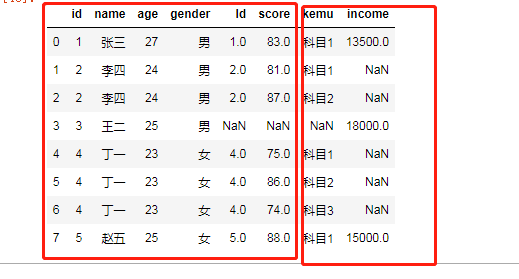
还可以将连接结果与df5连接
merge2 = pd.merge(left = merge1, right = df5, how = 'left')
matplotlib简介
是一个强大的python绘图和数据可视化工具包,数据可视化也是我们数据分析重要环节之一,可以帮助我们分析出很多价值信息,也是数据分析的最后一个可视化阶段
下载
# python纯开发环境下 pip3 install matplotlib # anaconda环境下 conda install matplotlib
导入
import matplotlib.pyplot as plt
饼图的绘制
饼图是将一个圆分割成不同大小的楔(扇)形,而圆中的每一个楔形代表了不同的类别值,通常根据楔形的面积大小来判断类别值的差异
基本使用
pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, labeldistance=1.1)
x:指定绘图的数据
explode:指定饼图某些部分的突出显示,即呈现爆炸式
labels:为饼图添加标签说明,类似于图例说明
colors:指定饼图的填充色
autopct:自动添加百分比显示,可以采用格式化的方法显示
pctdistance:设置百分比标签与圆心的距离
labeldistance:设置各扇形标签(图例)与圆心的距离
例子
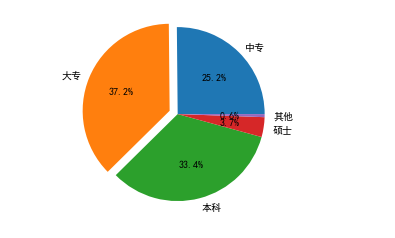
# 导入第三方模块 import matplotlib.pyplot as plt # 解决中文乱码情况 plt.rcParams['font.sans-serif'] = ['SimHei'] # 构造数据 edu = [0.2515,0.3724,0.3336,0.0368,0.0057] labels = ['中专','大专','本科','硕士','其他'] explode = [0,0.1,0,0,0] # 绘制饼图 plt.axes(aspect='equal') # 如果python版本较低可能是扁的需要加该代码 plt.pie(x = edu, # 绘图数据 labels=labels, # 添加教育水平标签 autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数 explode = explode ) # 显示图形 plt.show()
对于条形图而言,对比的是柱形的高低,柱体越高,代表的数值越大,能够使人们一眼看出各个数据的大小,易于比较数据之间的差别。
基本使用
bar(x, height, width=0.8, bottom=None, color=None, edgecolor=None, tick_label=None, label = None, ecolor=None) x:传递数值序列,指定条形图中x轴上的刻度值 height:传递数值序列,指定条形图y轴上的高度 width:指定条形图的宽度,默认为0.8 bottom:用于绘制堆叠条形图 color:指定条形图的填充色 edgecolor:指定条形图的边框色 tick_label:指定条形图的刻度标签 label:指定条形图的标签,一般用以添加图例
例子
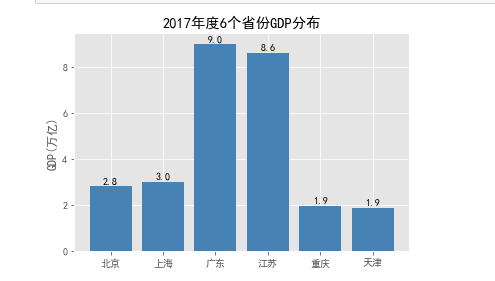
import pandas as pd # 读入数据 GDP = pd.read_excel(r'Province GDP 2017.xlsx') # 设置绘图风格(不妨使用R语言中的ggplot2风格) plt.style.use('ggplot') # 绘制条形图 plt.bar(x = range(GDP.shape[0]), # 指定条形图x轴的刻度值 height = GDP.GDP, # 指定条形图y轴的数值 tick_label = GDP.Province, # 指定条形图x轴的刻度标签 color = 'steelblue', # 指定条形图的填充色 ) # 添加y轴的标签 plt.ylabel('GDP(万亿)') # 添加条形图的标题 plt.title('2017年度6个省份GDP分布') # 为每个条形图添加数值标签 for x,y in enumerate(GDP.GDP): plt.text(x,y+0.1,'%s' %round(y,1),ha='center') # 显示图形 plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号