

selenuim进阶爬虫案例
目录
- 百度自动登录
- 爬取京东商品数据
- 知乎登录案例
百度自动登录
思路
1.使用谷歌浏览器访问百度首页 2.查找页面上的登录按钮 3.点击登录按钮 4.查找点击短信登录按钮 5.查找手机号输入框并填写内容 6.查找发送验证码按钮并点击 7.查找并点击登录按钮
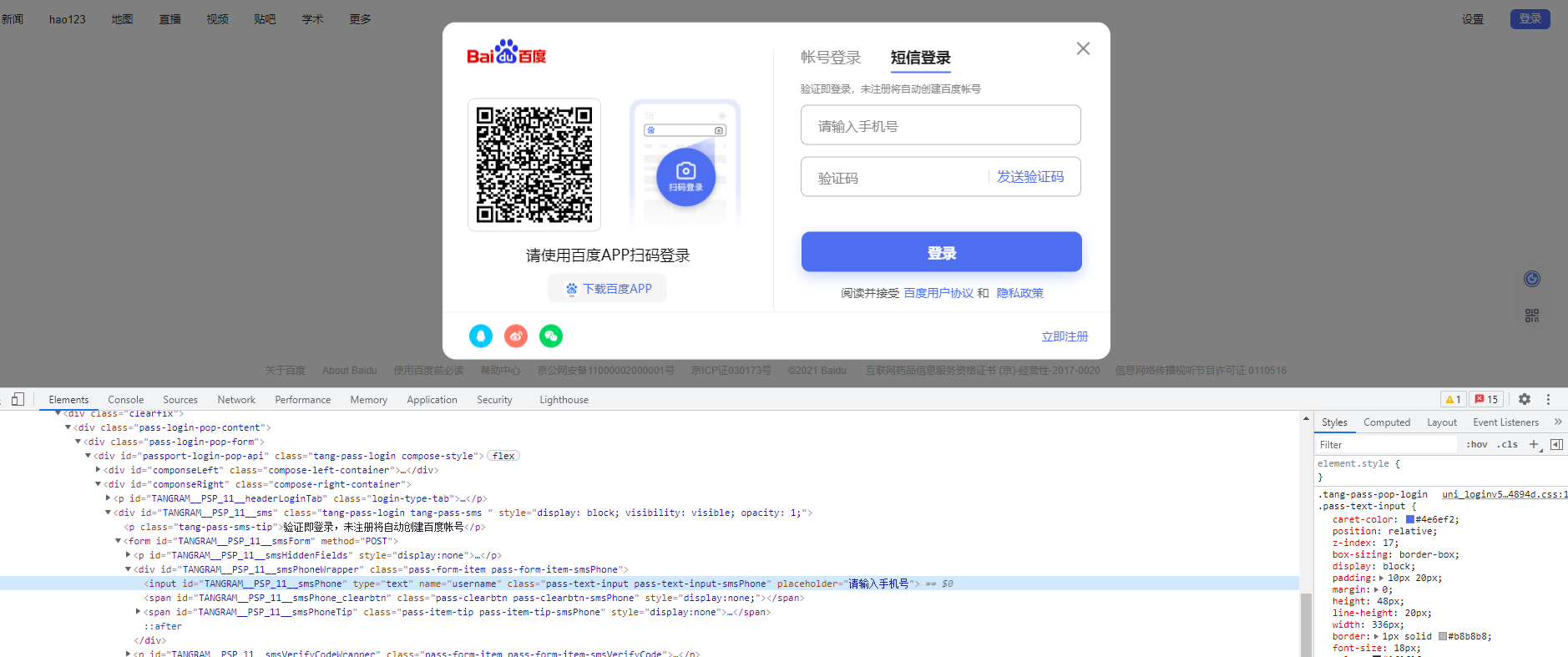
在访问网站数据的时候加载需要一定的时间,没有加载完全的情况下代码 容易报错 此时需要等待页面数据加载完毕 # 解决措施 bro.implicitly_wait()
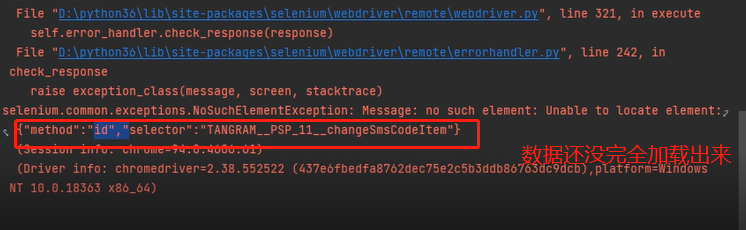
完整代码


from selenium import webdriver import time bro = webdriver.Chrome() bro.get('https://www.baidu.com/') login_tag = bro.find_element_by_id('s-top-loginbtn') time.sleep(0.5) login_tag.click() time.sleep(3) message_tag = bro.find_element_by_id('TANGRAM__PSP_11__changeSmsCodeItem') message_tag.click() time.sleep(0.5) phone_tag = bro.find_element_by_id('TANGRAM__PSP_11__smsPhone') phone_tag.send_keys(18818188888) time.sleep(0.5) btn_tag = bro.find_element_by_id('TANGRAM__PSP_11__smsTimer') btn_tag.click() time.sleep(0.5) submit_tag = bro.find_element_by_id('TANGRAM__PSP_11__smsSubmit') submit_tag.click() time.sleep(0.5) bro.close()
爬取京东商品数据
思路
1.访问京东首页并加入延时等待 2.查找搜索款并输入商品名称 3.按下enter键进入商品展示页
4.商品数据的展示页存在动态加载的情况 需要往下滚动 5.循环获取每一个li标签,筛选所需数据
6.图片数据存在懒加载现象
7.最后通过打印展示数据
注意事项
1.如何查看页面高度
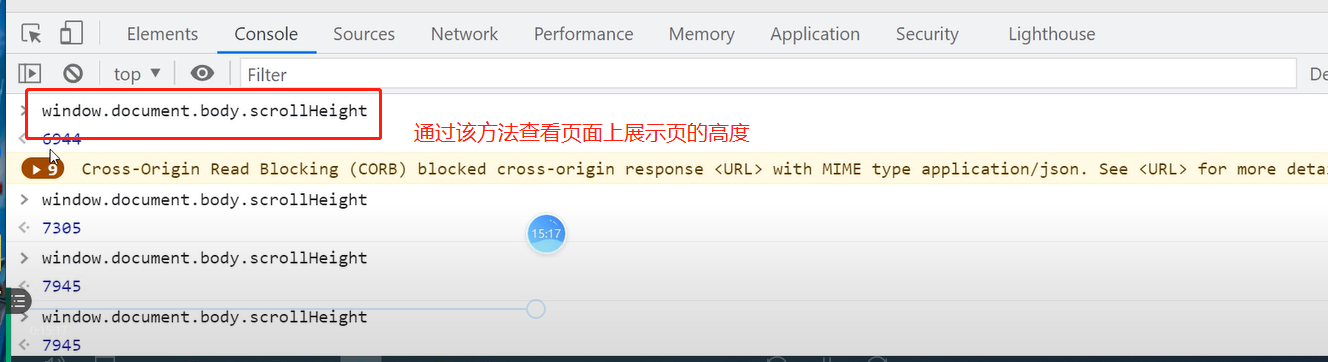
解决措施
# 由于数据存在滚动加载的现象 for i in range(0, 8000, 1000): # 不能直接到底 要有一个波段 bro.execute_script('window.scrollTo(0,%s)' % i) time.sleep(0.5)
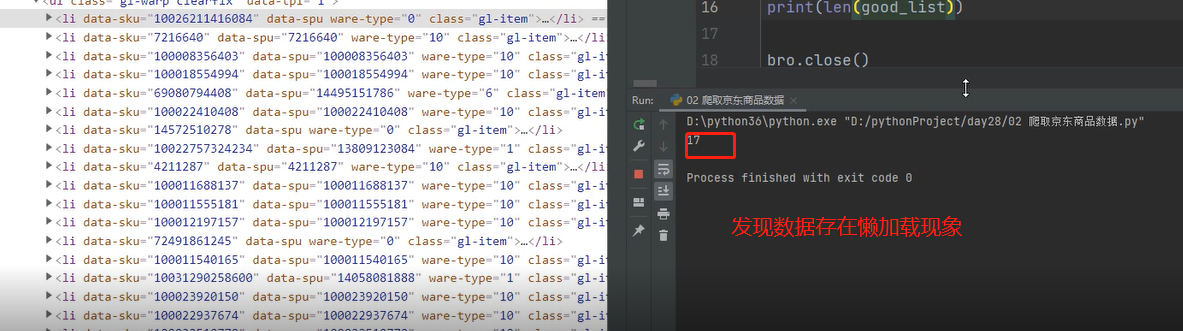
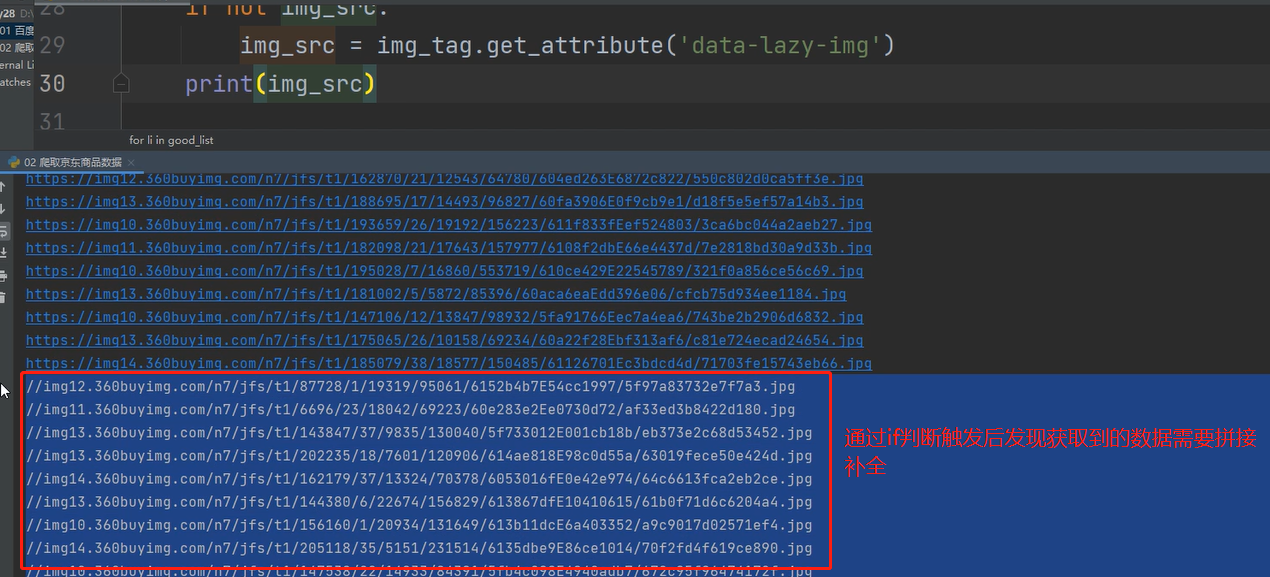
2.筛选数据时,针对图片数据存在缺失现象,进入network查看

解决措施
代码
if not img_src: img_src = 'https:' + img_tag.get_attribute('data-lazy-img')
然后后面筛选所需数据时都最好打印看一看
# 商品价格 price_tag = li.find_element_by_css_selector('div.p-price strong') order_price = price_tag.text # 商品描述 desc_tag = li.find_element_by_css_selector('div.p-name a em') order_desc = desc_tag.text # 商品链接 link_tag = li.find_element_by_css_selector('div.p-name a') order_link = link_tag.get_attribute('href') # 商品销量 commit_tag = li.find_element_by_css_selector('div.p-commit strong a') order_commit = commit_tag.text # 店铺名称 shop_tag = li.find_element_by_css_selector('div.p-shop span a') shop_name = shop_tag.text # 店铺链接 shop_link = shop_tag.get_attribute('href')
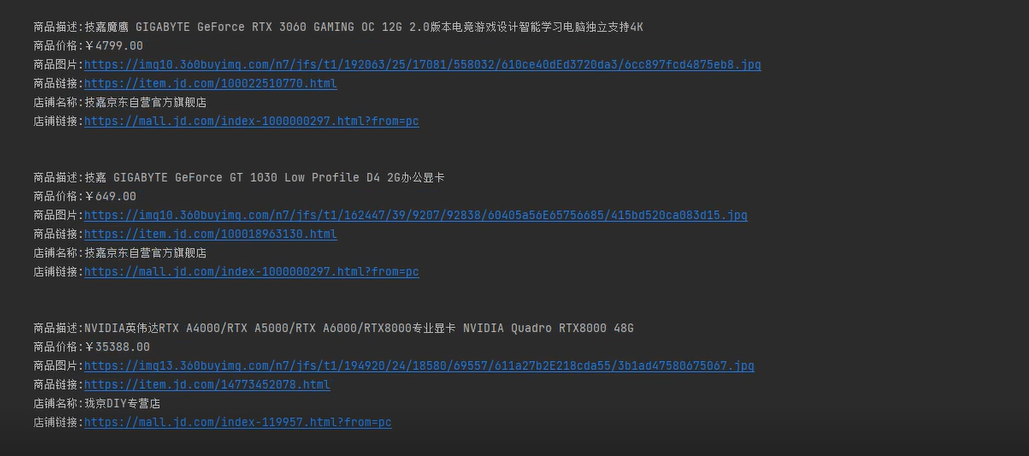
最后打印展示数据
print(""" 商品描述:%s 商品价格:%s 商品图片:%s 商品链接:%s 店铺名称:%s 店铺链接:%s """ % (order_desc, order_price, img_src, order_link, shop_name, shop_link))
多页爬取
大致思路
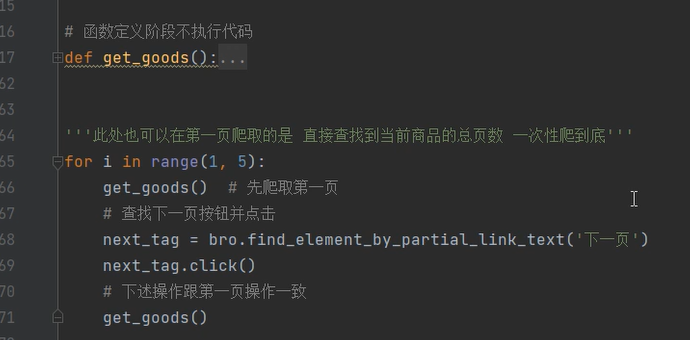
由于我们使用的是selenuim所以此处只需要查找下一页按钮点击即可
将单页爬取数据的代码封装成一个函数 之后就可以循环爬取多页
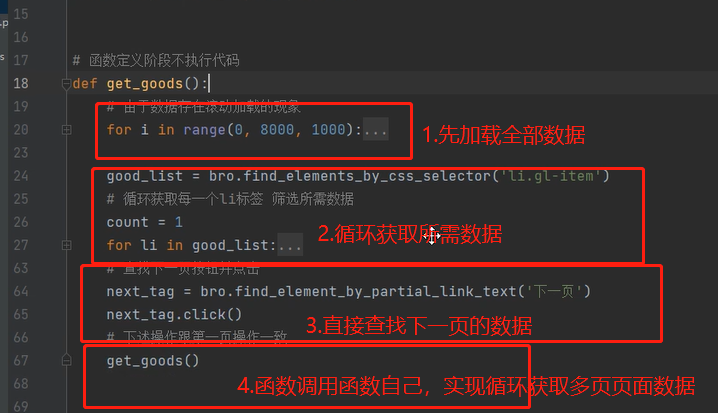
研究发现,上述循环会带有每次爬取下一页时伴随第一页的爬取,所以可以更加精简,使用下面的代码让它一直爬下去直到没有下一页
考虑到实际应用中会存在爬取数据时的暂停,可利用异常捕获的方法
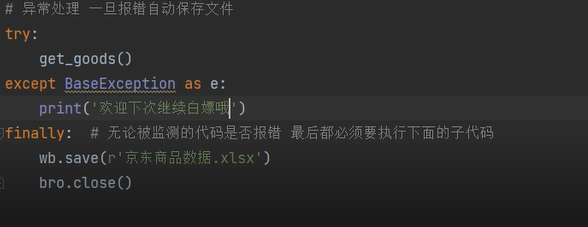
最后数据的持久化
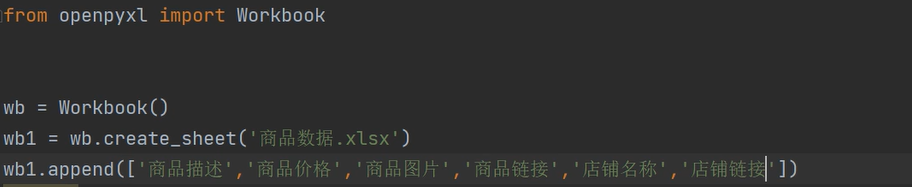

后期还可以优化成用户填写自己想要的商品名称

单页爬取京东商品数据的完整代码
import time from selenium import webdriver from selenium.webdriver.common.keys import Keys bro = webdriver.Chrome() # 1.访问京东首页 bro.get('https://www.jd.com/') bro.implicitly_wait(10) # 延时等待 # 2.查找搜索款并输入商品名称 search_input = bro.find_element_by_id('key') search_input.send_keys('显卡') # 3.按下enter键进入商品展示页 search_input.send_keys(Keys.ENTER) # 由于数据存在滚动加载的现象 for i in range(0, 8000, 1000): # 千万不能直接到底 一定要有一个波段 bro.execute_script('window.scrollTo(0,%s)' % i) time.sleep(0.5) good_list = bro.find_elements_by_css_selector('li.gl-item') # 循环获取每一个li标签 筛选所需数据 for li in good_list: # 图标标签的src属性 img_tag = li.find_element_by_css_selector('div.p-img a img') img_src = img_tag.get_attribute('src') '''img标签的src属性存在懒加载现象 src没有就在data-lazy-img属性下''' if not img_src: img_src = 'https:' + img_tag.get_attribute('data-lazy-img') # 商品价格 price_tag = li.find_element_by_css_selector('div.p-price strong') order_price = price_tag.text # 商品描述 desc_tag = li.find_element_by_css_selector('div.p-name a em') order_desc = desc_tag.text # 商品链接 link_tag = li.find_element_by_css_selector('div.p-name a') order_link = link_tag.get_attribute('href') # 商品销量 commit_tag = li.find_element_by_css_selector('div.p-commit strong a') order_commit = commit_tag.text # 店铺名称 shop_tag = li.find_element_by_css_selector('div.p-shop span a') shop_name = shop_tag.text # 店铺链接 shop_link = shop_tag.get_attribute('href') # 通过打印展示数据 也可以数据持久化到表格文件 print(""" 商品描述:%s 商品价格:%s 商品图片:%s 商品链接:%s 店铺名称:%s 店铺链接:%s """ % (order_desc, order_price, img_src, order_link, shop_name, shop_link)) bro.close()
知乎登录案例
一、研究发现电脑端知乎不登陆是无法直接访问首页的
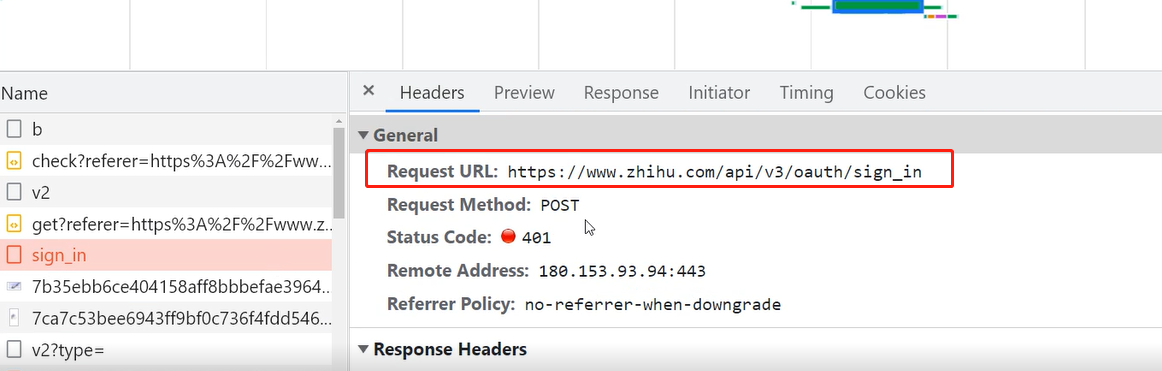
二、在network监控中发送登录请求体数据为加密

三、搜索关键字encrypt通过断点调试查看到内部真实数据
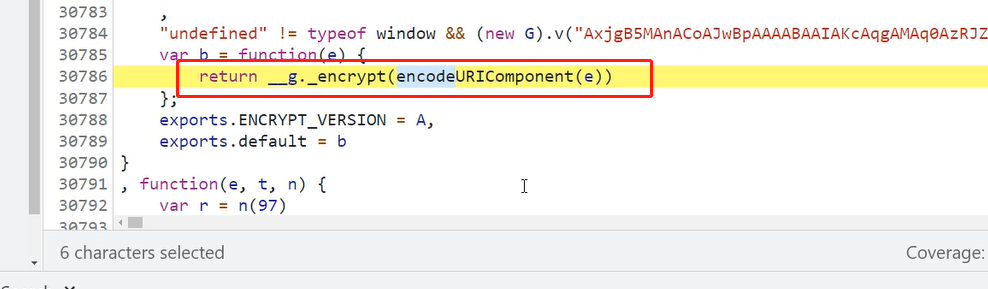
四、此时可以研究e这个变量

五、python里调url解析库解个码,结果如下:
client_id 用户id(固定值) grant_type 验证方式(固定值) timestamp 时间戳*1000,去尾 source (固定值) signature 签名(js加密,变动) username 用户名 password 密码 captcha 验证码 lang 验证码方式(固定值) utm_source (固定值) ref_source (固定值)other_https://www.zhihu.com/signin?next=%2F
六、signature是加密的,得找出它的js加密算法
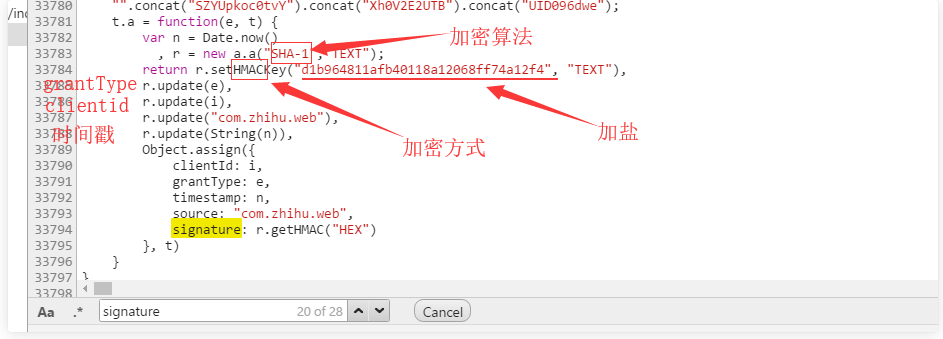
七、hamc的加密方式,sha-1的加密算法,用python的hmac,hashlib

八、在python里调用node.js去执行,执行js的库叫做 PyExecJS,需要下载
九、node.js中的运行环境和浏览器的运行环境是不一样的,浏览器中会有document,window对象
node.js的运行环境就一个单纯的jsv8引擎,所以需要依赖一个node.js的库jsdom来模拟浏览器环境
十、然后在js代码上面加上一段代码
const jsdom = require("jsdom"); const { JSDOM } = jsdom; const dom = new JSDOM(`<!DOCTYPE html><p>Hello world</p>`); window = dom.window; document = window.document; XMLHttpRequest = window.XMLHttpRequest; atob = window.atob

 浙公网安备 33010602011771号
浙公网安备 33010602011771号