

爬取红薯小说网数据详细步骤
步骤一
小说详情页面鼠标左右键全部禁用,但是支持按F12调出控制台
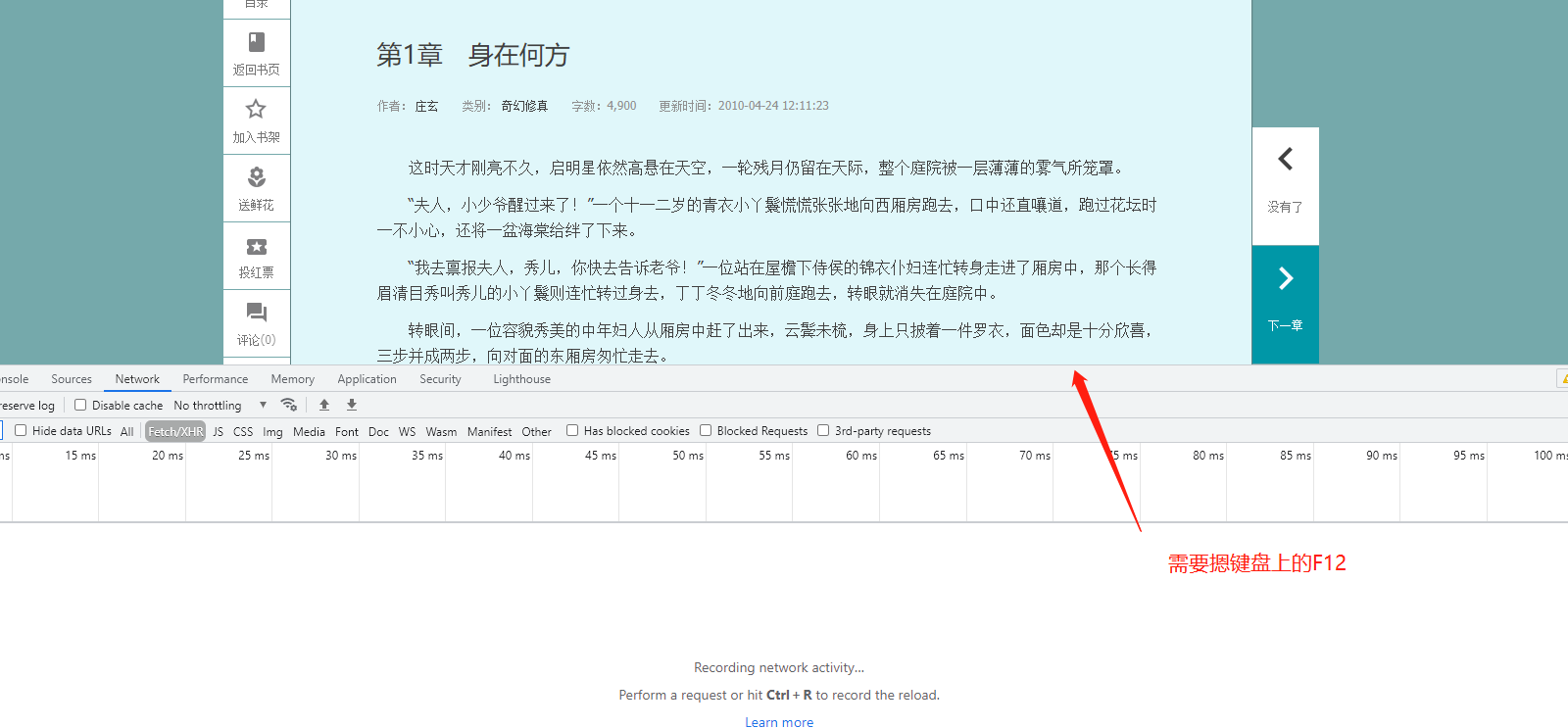
步骤二
研究发现小说文字不是直接加载,于是我们可以查找相关二次请求
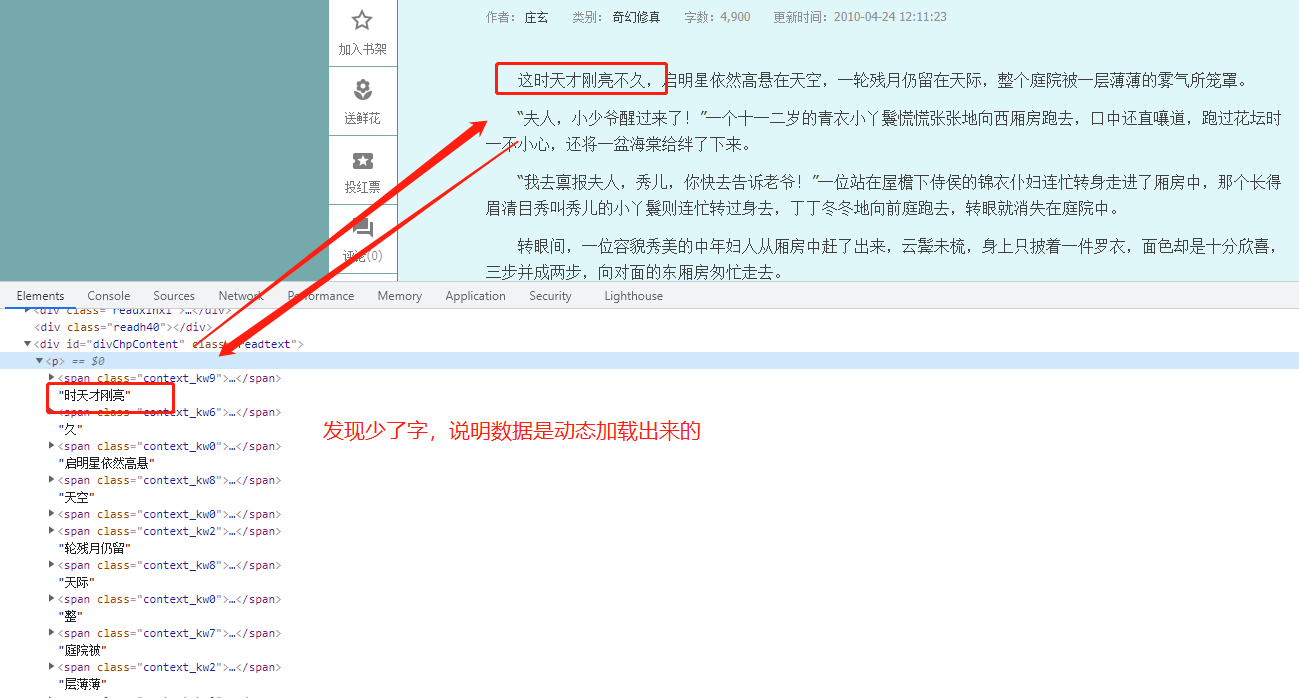
步骤三
查找可疑的响应文件,结果发现了两处可疑点
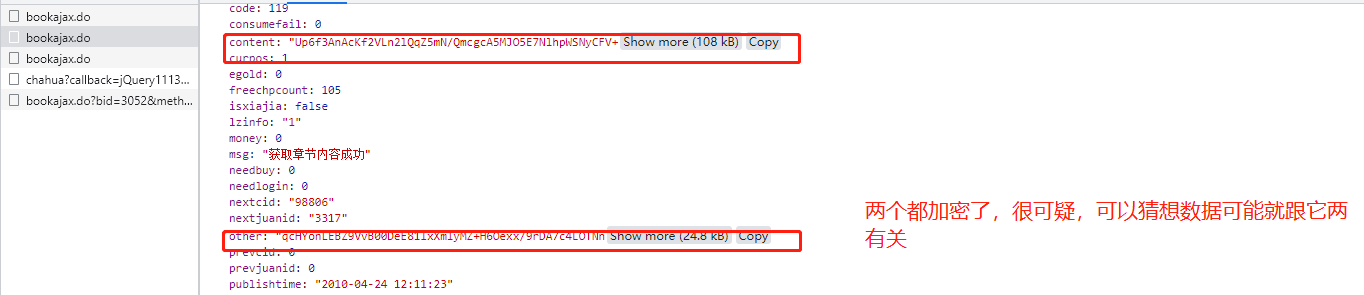
步骤四
然后再次研究发现,请求体里也有重要参数


步骤五
然后发现文字内容的解密过程发送在浏览器本地
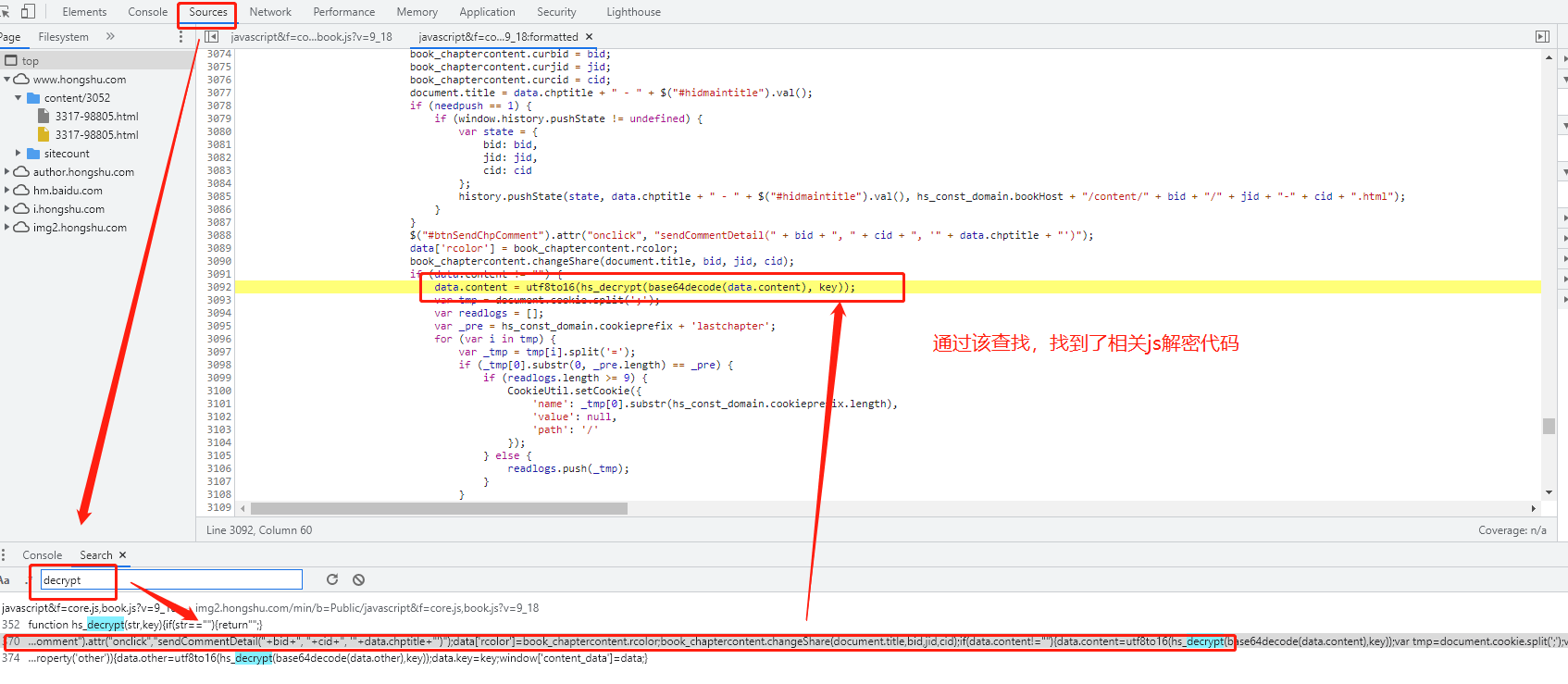
通过浏览器查找相应的js代码,查看该代码内的解密算法
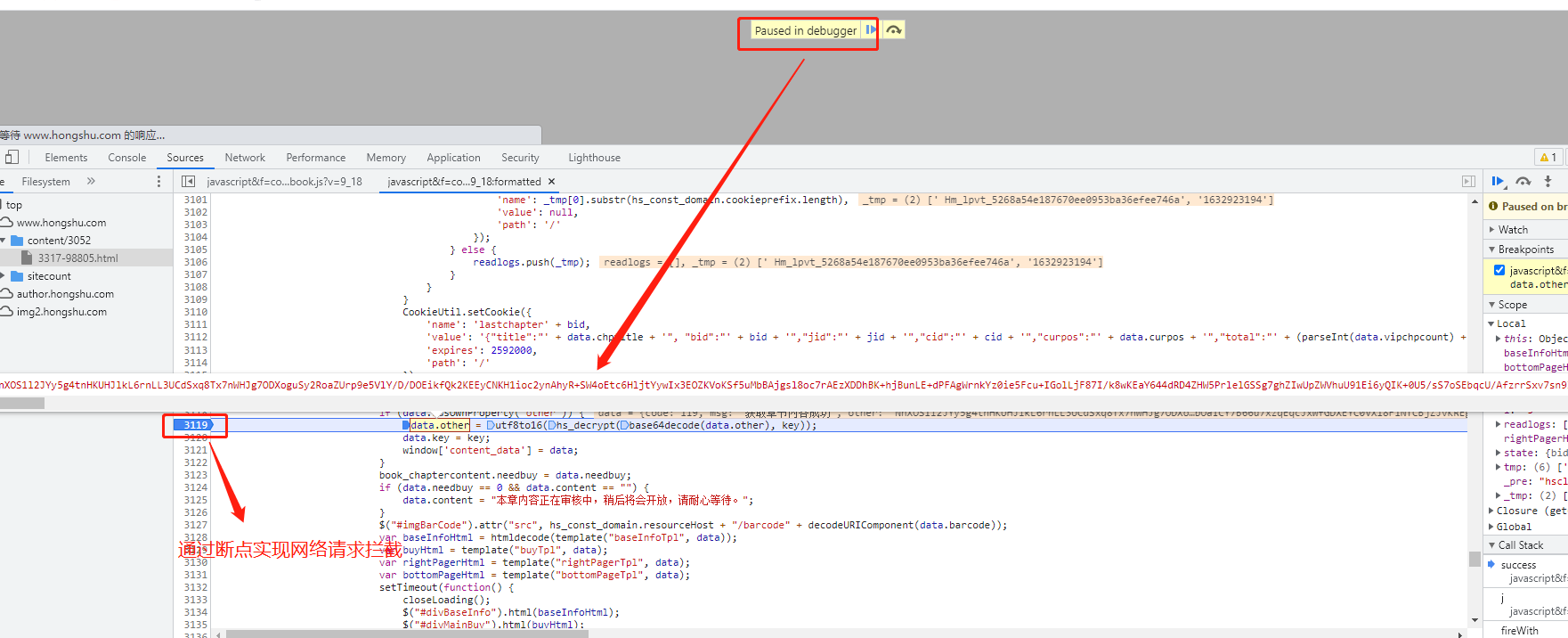
步骤五
文字主要内容的界面utf8to16(hs_decrypt(base64decode(data.content), key))
解密之后仍然存在数据缺失的情况

utf8to16(hs_decrypt(base64decode(data.other), key)) 解密之后是一段js代码
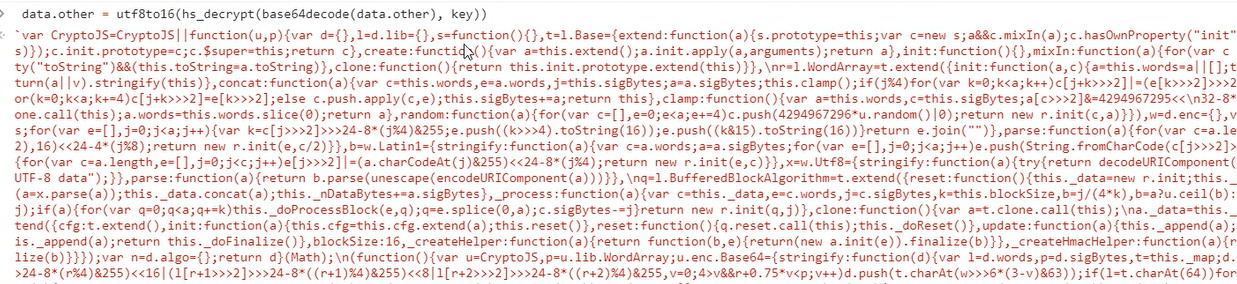
步骤六
怀疑缺失的数据与解析出来js代码有很大的关系,自己新建一个html文件,将content内部拷贝只body内
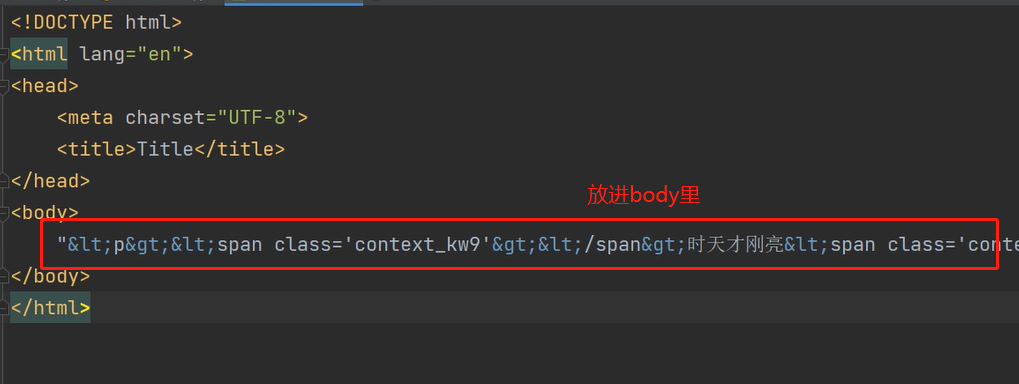

复制之后再次查看页面

将js代码引入到该html文件夹

步骤七
然后我们发现数据完整了,但选不中全部内容

之前缺失的文字,被放在了:befor标签的css属性里
css反扒破解--js注入
思路
1.通过js定位到所有的:befor标签 2.然后,获取到css属性的值(缺失的文字) 3.把缺失的文字插入到标签之间(innerText)
代码


var element_list = document.querySelectorAll('#divChpContent span') for(var i=0;i<element_list.length;i++){ var content = window.getComputedStyle( element_list[i],':before' ).getPropertyValue('content') element_list[i].innerText = content.trim('"'); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号