

前端其他标签与正则表达式
目录
-
-
常用标签
-
列表标签
-
表格标签
-
表单标签
-

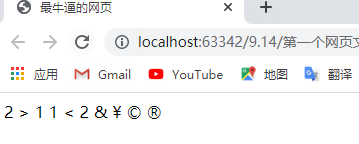
特殊符号
空格 > > < < & & ¥ ¥ 版权 © 注册 ®
常用标签
<a href="网址">链接标签</a> href参数后面写网址 用户点击即可跳转到该网页 <img src="111.png" alt="">图片标签 src参数后面写图片的地址 网络或本地都可以 <div>页面布局标签</div> 内部可以无限制的嵌套任意标签 <span>页面文本标签</span> 是所有网页中涉及到文字可能会出现的标签
列表标签
"""在网页上看似有规则排列的横向或者竖向的内容基本都是用列表标签完成的""" <ul> <li>001</li> <li>002</li> <li>003</li> <li>004</li> <li>005</li> </ul>

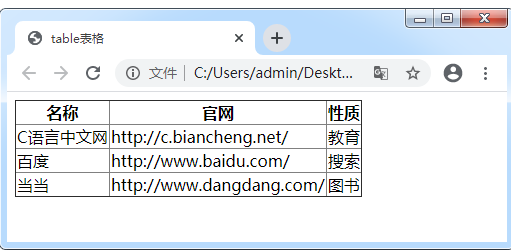
表格标签
'''涉及到多条相同格式数据展示的时候可以考虑使用表格标签''' <table> <thead> <tr> <th>序号</th> <!--书写一个个字段名--> <th>姓名</th> <th>年龄</th> </tr> <!--一个tr就是一行--> </thead> <!--书写表头数据(字段名)--> <tbody> <tr> <td>1</td> <!--书写一个个真实数据--> <td>ben</td> <td>123</td> </tr> </tbody> <!--书写表单数据(真实数据)--> </table>
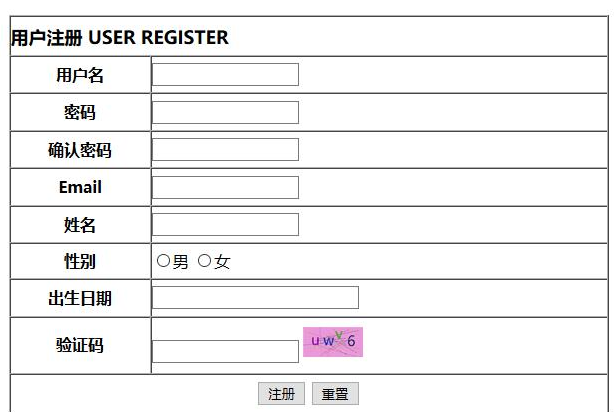
表单标签
"""涉及到用户数据的获取一般都需要使用表单标签""" input标签 type 参数 text 普通文本 password 密文展示 email 邮箱格式 date 日期格式 radio 单选 checkbox 多选 file 文件 submit 提交按钮 reset 重置按钮 button 普通按钮
select标签
option子标签
textarea标签 获取大量文本
标签特性
<a id='' class=''></a> 上述id、class等都称之为a标签的属性
标签两大核心属性
id # 单独查找某个人 类似于标签的身份证号码 用于唯一标识标签 在同一个html文档中id不能重复

class # 批量查找一群人 类似于标签的种群(类别) 用于区分不同的类 在用一个html文档中class值可以重复 表示属于同一个类别
"""标签还可以自定义任意的属性"""
<a username='jason' pwd=123></a>

标签之间的关系描述
<div>只要是div内部的标签都可以称之为是div的后代 <a>上一级div的儿子</a> <p>上一级div的儿 <span>上一级p的儿子,上上一级div的孙子</span> </p> <div>上一级div的儿 <a>上一级div的儿子,上上一级div的孙子</a> </div> <span>上一级div的儿子</span> </div>

正则表达式
python代码实现数据校验


# 1.获取用户手机号 phone = input('phone num>>>:').strip() # 2.先判断长度是否是11位 if len(phone) == 11: # 3.再判断是否是纯数字 if phone.isdigit(): # 4.最后判断开头是否是13 14 15 18 if phone.startswith('13') or phone.startswith('14') or phone.startswith('15') or phone.startswith('18'): print('是一个合法的手机号') else: print('手机号格式错误') else: print('手机号必须是纯数字') else: print('手机号必须是11位')
正则表达式校验
import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|18)[0-9]{9}$',phone_number): print('是合法的手机号码') else: print('不是合法的手机号码') # 使用正则表达式可以极大的简化数据筛选和校验的步骤

[0123456789] 匹配0到9之间的任意一个数字包括首尾
[0-9] 简写:匹配0到9之间的任意一个数字包括首尾
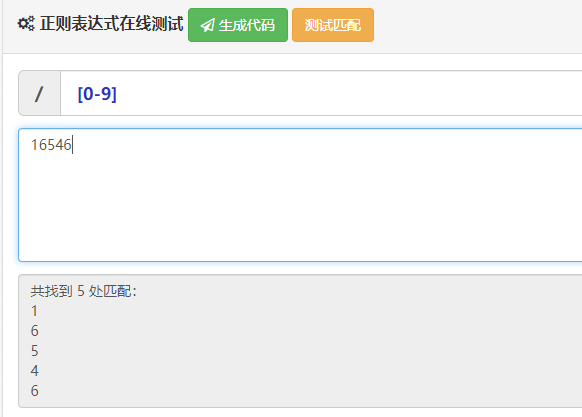
[a-z] 匹配小写字母a到z之间的任意一个字母包括首尾
[A-Z] 匹配大写字母A到Z之间的任意一个字母包括首尾
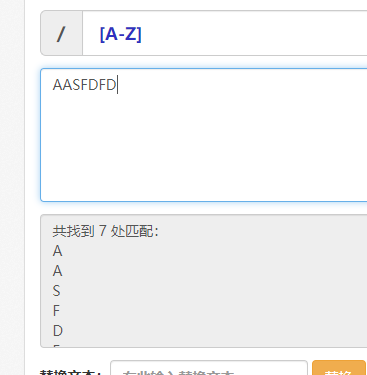
[0-9a-zA-Z] 匹配数字或者小写字母或者大写字母
字符组在匹配内容的时候是单个单个字符挨个匹配
. 匹配除换行符以外的任意字符 \d 匹配数字 ^ 匹配字符串的开始 $ 匹配字符串的结尾 a|b 匹配字符a或字符b () 给正则表达式分组 本身没有任何意义 [...] 匹配字符组中的字符 [^...] 匹配除了字符组中字符的所有字符(取反)
# 跟在正则表达式的后面可以一次性匹配多个字符 '''量词必须跟在正则表达式后面 不能单独出现使用''' * 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次
练习题
不同的正则表达式
海. 海燕海娇海东

^海. 海燕海娇海东

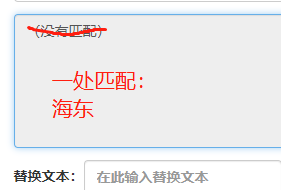
海.$ 海燕海娇海东
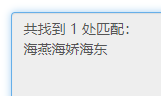
海.* 海燕海娇海东
贪婪匹配
右侧尽可能多的匹配直到根据相关条件才停止
非贪婪匹配
将贪婪匹配变成非贪婪匹配只需要在量词后面加一个问号即可

取消转义
\n 匹配的是换行符
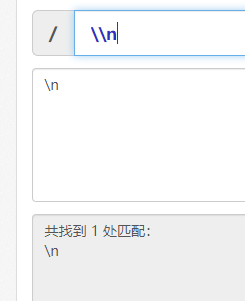
\\n 匹配的是\n
\\\\n 匹配的是\\n
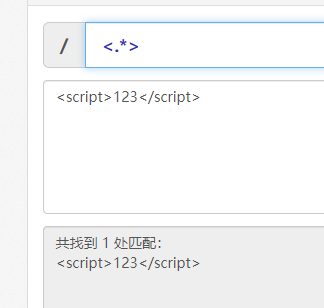
re模块
# 如果想在python代码中使用正则表达式需要借助于内置模块re import re text = '<script>123</script>' res = re.findall('<.*?>',text) print(res)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号