

网络爬虫
目录
- 常见收集数据网站
- 爬虫及分类
- 网页组成

常见收集数据网站
免费类(国内)
# 网站:https://index.baidu.com/v2/index.html#/ 百度指数
是以百度海量网民行为数据为基础的数据分析平台 是当前互联网乃至整个数据时代最重要的统计分析平台之一
常见功能
搜索指数图
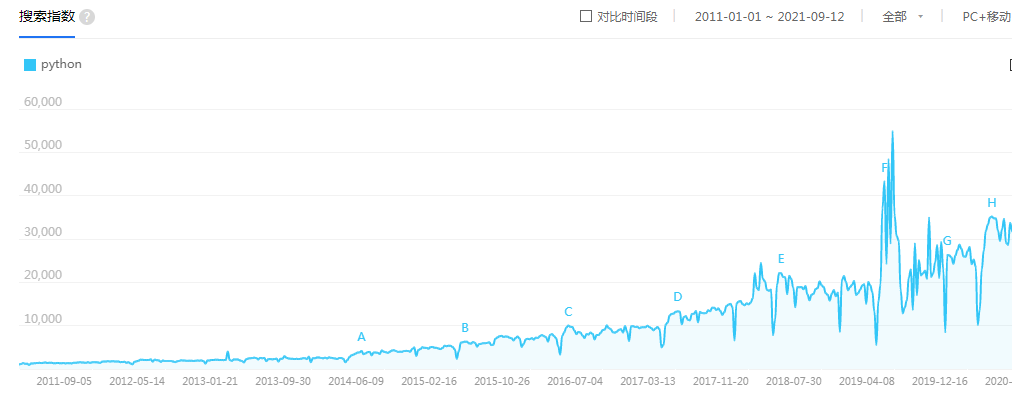
咨询指数图

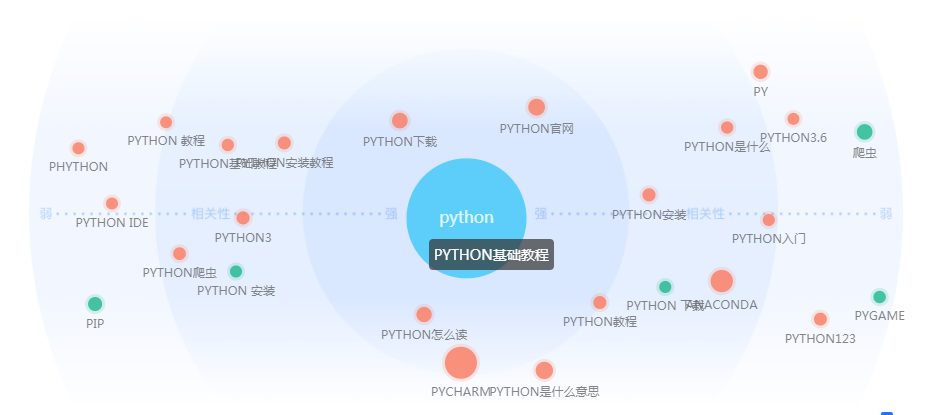
需求图谱
# 网站:https://data.weibo.com/index 新浪指数
是对提及量、阅读量、互动量加权得出的综合指数,更加全面的体现关键词在微博上的热度情况。

# 网站:http://www.gov.cn/shuju/index.htm 国家数据 中国各项有关政治类的数据都在其中
免费类(国外)
# 网站:https://data.worldbank.org.cn/ 世界银行
是联合国的一个专门机构,上面的数据基本都是有关银行,金融,贷款等。
# 网站:https://www.nasdaq.com/zh/market-activity 纳斯达克 是美国的一个电子证券交易机构,里面的数据基本都是与股票相关
# 网站:http://data.un.org/ 联合国 里面是有关自由贸易,出入境人员记录等数据

付费类(国内)
# 网站:https://www.iresearch.com.cn/ 艾瑞咨询 是解决商业决策问题的专业第三方机构。通过研究咨询等专业服务,助力用户提高对新经济产业的认知水平、盈利能力和综合竞争力

付费类(国际)
# 网址:https://www.accenture.com/cn-zh 埃森哲 为客户提供战略、咨询、数字、技术和运营服务及解决方案
# 网站:https://www.mckinsey.com.cn/ 麦肯锡 帮助领先的企业机构实现显著、持久的经营业绩改善,打造能够吸引、培育和激励杰出人才的优秀组织机构
付费类(第三方平台)
# 网站:https://www.datatang.com/ 数据堂 数据堂专注于人工智能数据服务,致力于为全球人工智能企业提供数据获取及数据产品服务,实现数据价值最大化,推动人工智能技术、应用和产业的创新

# 网站:http://gbdex.bdgstore.cn/ 贵阳大数据 是一个面向全国提供数据交易服务的创新型交易场所,遵循“开放、规范、安全、可控”的原则
采用“政府指导,社会参与、市场化运作”的模式
旨在促进数据流通,规范数据交易行为,维护数据交易市场秩序,保护数据交易各方合法权益
向社会提供完整的数据交易、结算、交付、安全保障、数据资产管理和融资等综合配套服务

网络爬虫的理论
互联网
互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样
互联网建立的核心目的
互联网的核心价值在于数据的共享/传递
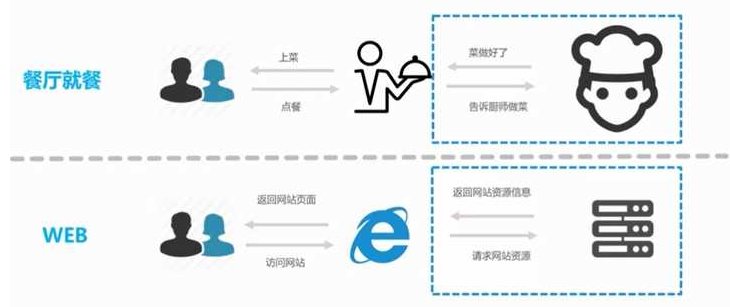
上网
由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程
爬虫
跳过代码模拟网络请求获取数据并解析数据最后保存

爬虫的价值
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据
爬虫的分类
通用爬虫
搜索引擎用的爬虫系统,类似于百度
尽可能把互联网所有的网页下载放到本地服务器形成备份
再对这些网页做相关处理最后给用户提供检索结果
搜索引擎如何获取一个网站URL
1.主动向搜索引擎提交网址 网址收录:https://ziyuan.baidu.com/site/index 2.在其他网址设置网站外链 3.与DNS服务商合作(DNS即域名解析技术) 简便获取ip地址:ping URL -t
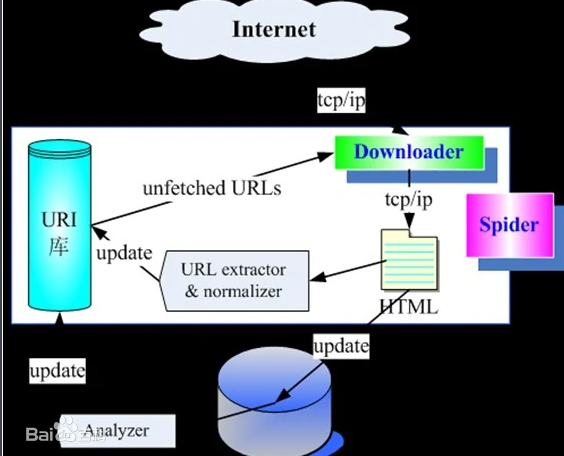
robots协议
协议内会指明可以爬取网页的部分数据
百度快照
每个被收录的网页,在百度上都存有一个纯文本的备份,称为“百度快照”。百度速度较快,您可以通过“快照”快速浏览页面内容。 不过,百度只保留文本内容,所以,那些图片、音乐等非文本信息,快照页面还是直接从原网页调用。
通用爬虫工作流程
爬取网页>>>存储数据>>>内容处理>>>提供检索及排名服务
排名:
1.PageRank值
根据网站的流量统计
2.竞价排名
金钱交易过后晋升上去
聚焦爬虫
爬虫程序员写的针对指定内容的爬虫
网页组成
HTML:超文本标记语言 # 浏览器可以展示出来的界面都是由HTML构成的 eg: 天猫官网

前端与后端
前端 任何与用户直接打交道的操作界面都可以称之为"前端" 后端 程序员编写的运行在程序内部不直接与用户打交道的程序代码 一般都是指代程序员编写的代码
前端三剑客
HTML 网页的骨架
CSS 网页的样式
JavaScript(JS) 网页的动态效果

# 网页文件一般都是以.html结尾 # HTML语法结构 <html> <head>书写的一般都是给浏览器看的</head> <body>书写的就是浏览器要展示给用户看的</body> </html>
head内常见标签
title 定义网页标题
style 内部直接书写css代码
link 引入外部css文件
script 内部可以直接书写js代码也可以引入外部js文件
meta 定义网页源信息
html标签分类
双标签(有头有尾) <a></a>
单标签(自闭和) <img/>
基本标签
h标签
<h1>This is a heading</h1> <h2>This is a heading</h2> <h3>This is a heading</h3> <h4>This is a heading</h4> <h5>This is a heading</h5> <h6>This is a heading</h6>

b/i/u/s标签
<b>加粗</b> <i>斜体</i> <u>下划线</u> <s>删除线</s>
P标签
<p>吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮</p> <p>吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮</p> <p>吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮</p>

br标签
<p>吃葡萄不吐葡萄皮,<br />不吃葡萄倒吐葡萄皮</p>

hr标签
<p>This is a paragraph<p>
<hr />


 浙公网安备 33010602011771号
浙公网安备 33010602011771号