多表查询
目录
- 补充知识
- 多表查询理论
- 可视化软件navicat
- 作业

补充知识
group_concat()方法
作用:用于分组之后
# 获取除分组以外其他字段数据 本质可以理解为是拼接操作
演示
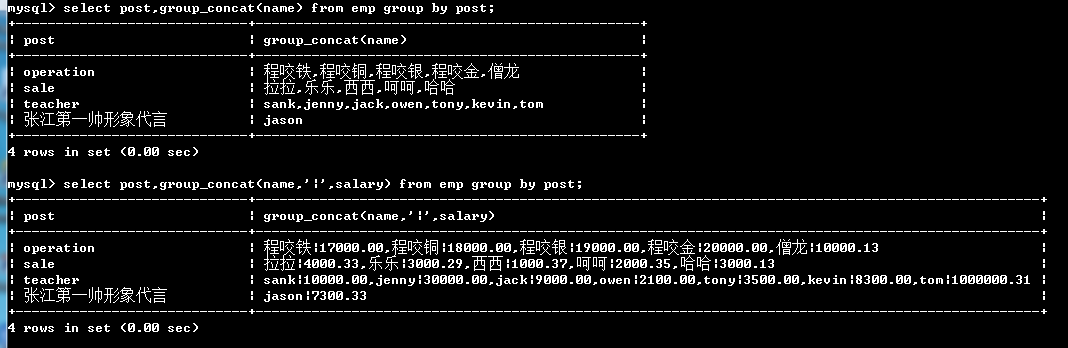
select post,group_concat(name) from emp group by post; select post,group_concat(name,'|',salary) from emp group by post;
concat()方法
用于分组之前
演示
select post,group_concat(name,':',salary) from emp group by post;

concat_ws()方法
用于分组之前 多个字段相同分隔符情况
演示
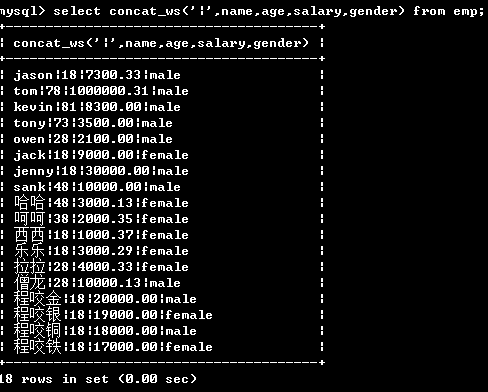
select concat_ws('|',name,age,salary,gender) from emp;
as语法
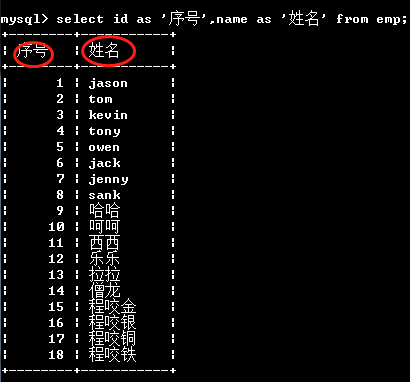
# 可以给查询出来的字段名起别名 select id as '序号',name as '姓名' from emp;
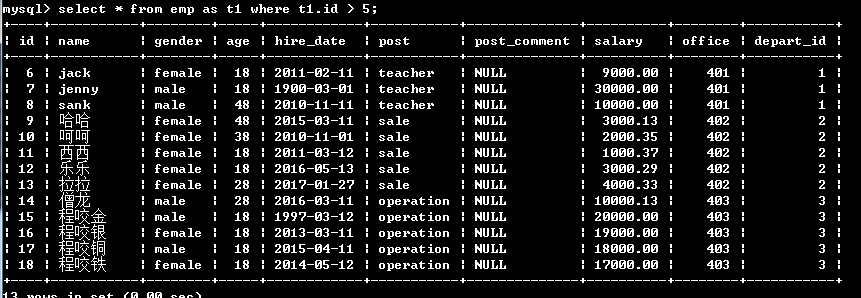
还可以给表名起别名 # 将emp表名起别名为t1 之后使用t1替代emp select * from emp as t1 where t1.id > 5;
多表查询理论
演示代码


create table dep( id int primary key auto_increment, name varchar(20) ); create table emp( id int primary key auto_increment, name varchar(20), gender enum('male','female') not null default 'male', age int, dep_id int ); #插入数据 insert into dep values (200,'技术'), (201,'人力资源'), (202,'销售'), (203,'运营'); insert into emp(name,gender,age,dep_id) values ('jason','male',18,200), ('egon','female',48,201), ('kevin','male',18,201), ('nick','male',28,202), ('owen','male',18,203), ('jerry','female',18,204);
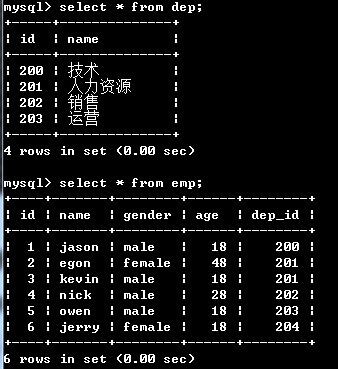
例子
1.查询各员工姓名及对应的部门名称
推导过程
1.select * from emp,dep; # 笛卡尔积 2.select * from emp,dep where emp.dep_id=dep.id; 3.select emp.name,dep.name from emp,dep where emp.dep_id=dep.id;
# SQL语句查询出来的结果可以看成是一张表,而涉及到多表可能会出现字段名冲突,需在字段名前面加上表名作限制
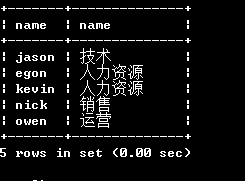
多表查询之联表
将多张表拼接成一张大表 然后在基于单表查询完成
拼接表关键字种类
inner join (内链接)
select * from emp inner join dep on emp.dep_id=dep.id; # 只链接两种表中都有对应的数据
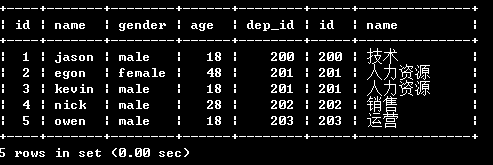
left join (左链接)
select * from emp left join dep on emp.dep_id=dep.id; # 以关键字左表为基础展示左表所有的数据 没有对应的数据以null填充

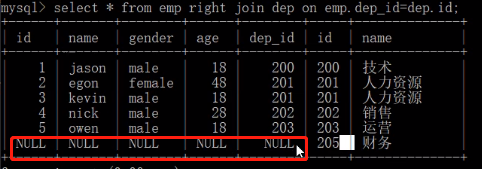
right join (右链接)
select * from emp right join dep on emp.dep_id=dep.id; # 以关键字右表为基础展示右表所有的数据 没有对应的以null填充
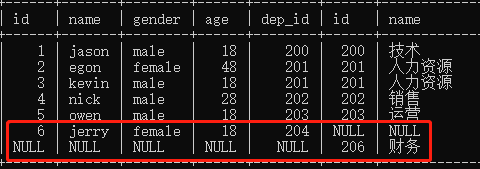
union (全链接)
# 不管有没有对应数据,全部展示,其实就是把左链接和右链接用union连起来
select * from emp left join dep on emp.dep_id=dep.id union select * from emp right join dep on emp.dep_id=dep.id;
将一张表的查询结果括号括起来当成另外一条SQL语句的条件
例子
1.查询部门是技术或者人力资源的员工信息
方法1:连表操作 select emp.name,emp.age,dep.name from emp inner join dep on emp.dep_id=dep.id where dep.name in ('技术','人力资源');
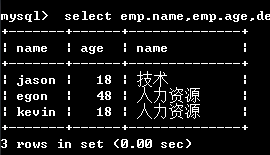
方式2:子查询
1.先查询技术和人力资源id号
select id from dep where name in ('技术','人力资源');
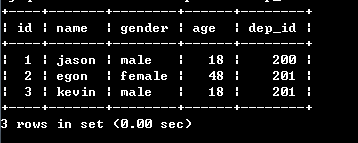
2.再去员工表里面根据部门id号筛选出员工数据
select * from emp where dep_id in (select id from dep where name in ('技术','人力资源'));
Navicat是一款可以操作多种数据库的软件 内部其实就是封装了相应的SQL语句

如何破解
破解地址:https://defcon.cn/214.html
老版本破解:http://www.ddooo.com/softdown/59996.htm
功能之链接
点击左上角‘连接’,选择MySQL,输入密码,即可链接。
功能之创建
选择连接,右键新建数据库,输入数据库名,选择‘utf8mb4’字符集。
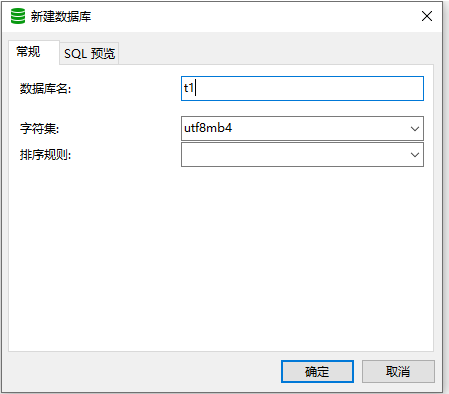
双击数据库,选择表,右键新建表,输入字段名和字段类型,设置主键。
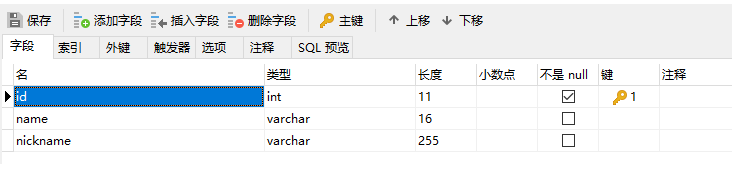
功能之外键
点击外键,设置完之后选择保存即可

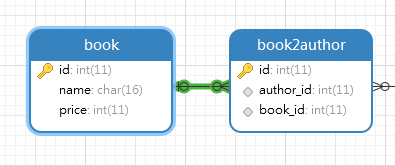
表的连接关系
选择数据库,右键选择‘逆向数据库到模型’,可以看到表之间的连接关系。
建立SQL文件
选择一个数据库,右键选择‘转储SQL文件--结构和数据’,可以生成一个sql文件
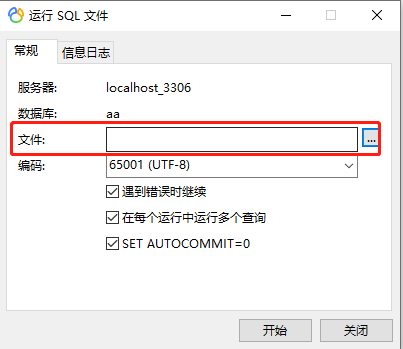
使用sql文件
新建一个数据库,右键‘运行SQL文件’,选择文件导入,即可使用
作业
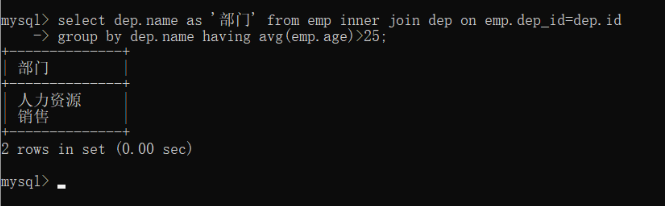
查询平均年龄在25岁以上的部门
# 联表
select dep.name as '部门' from emp inner join dep on emp.dep_id=dep.id group by dep.name having avg(emp.age)>25;
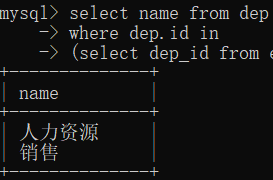
# 子查询
select name from dep where dep.id in (select dep_id from emp group by dep_id having avg(age)>25);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号