目录
- 字符编码
- 编码与解码
- 文件操作
- 读写模式
- 操作模式
- 作业
![img]()
字符编码
#前提:
计算机是基于电工作的 而电信号只有高低电频两种状态
所以计算机只认识两种状态 人为的定义为0和1
人类的字符与数字之间存在对应关系
#发展史
1.一家独大
ASCII码:内部记录了英文与数字的对应关系
2.群雄割据
中国GBK码:内部记录了英文、中文与数字的对应关系
韩国Euc_kr码:内部记录了英文、韩文与数字的对应关系
日本shift_JIS码:内部记录了英文、日文与数字的对应关系
3.天下一统
unicode码(万国码):内部记录了国家文字与数字的对应关系
utf8(万国码优化版本):目前默认使用该编码
"""
如果文本文件出现了乱码,尝试切换字符编码即可
"""
![img]()
编码与解码
#编码
按照指定的编码本将人类的字符编程成计算机能够识别的二进制数据
#解码
按照指定的编码本将计算机的二进制数据解析成人类能够读懂的字符
eg:
res = '啦啦啦啦啦啦'
#编码
res1 = res.encode('gbk')
print(rest1)
#解码
res2 = res1.decode('gbk')
print(res2)
![img]()
文件操作
#第一种
with open(文件路径,读写模式,字符编码) as 变量名:
with子代码
#第二种
变量名 = open(文件路径,读写模式,字符编码)
一系列操作
变量名.colse()
读写模式
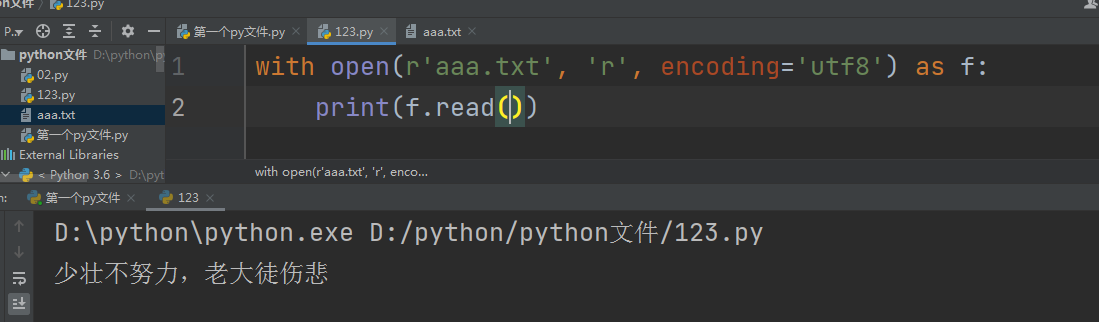
r (只读模式)
1.文件路径不存在会直接报错
2.文件存在则打开并可读取文件内容
#光标在文件开头
eg:
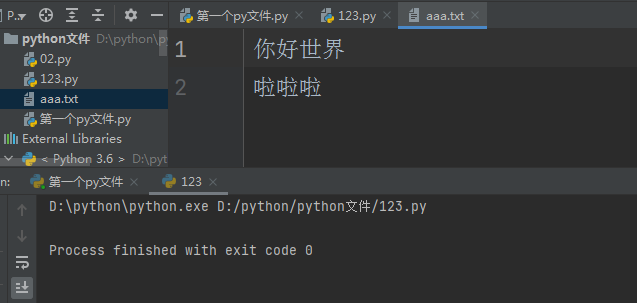
with open(r'aaa.txt', 'r', encoding='utf8') as f:
print(f.read()) # 一次性读取文件内容
![]()
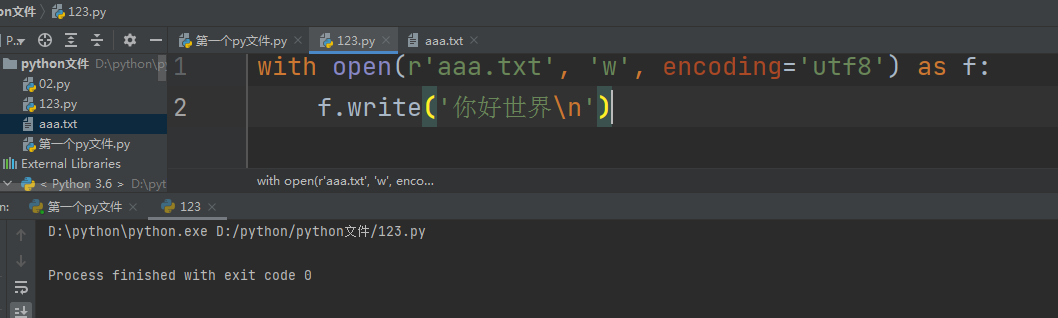
w (只写模式)
1.文件路径不存在会自动创建
2.文件路径存在会先清空该文件内容然后再写入
eg:
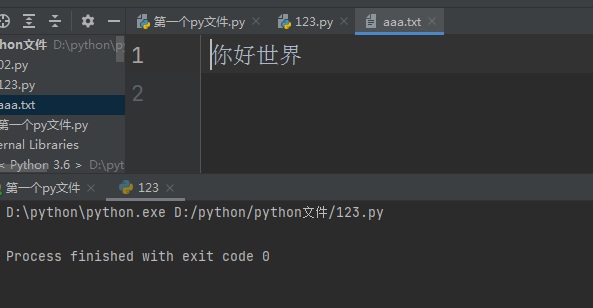
with open(r'aaa.txt', 'w', encoding='utf8') as f:
f.write('你好世界\n')
![]()
![]()
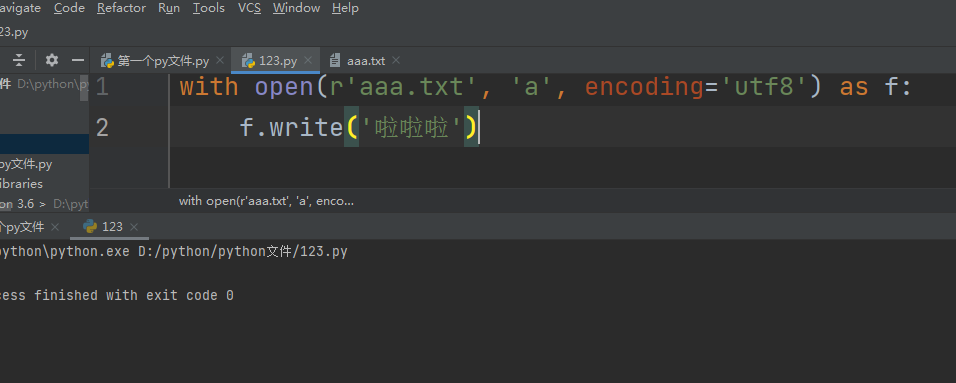
a (只追加模式)
1.文件路径不存在会自动创建
2.文件路径存在光标会移动到文件末尾
eg:
with open(r'aaa.txt', 'a', encoding='utf8') as f:
f.write('啦啦啦')
![]()
![]()
补充
读取优化
eg:
with open(r'aaa.txt', 'r', encoding='utf8') as f:
for line in f: # 一行行读取文件内容 能够避免内存溢出
print(line)
操作模式
#t模式
文本模式(也是上述三种读写模式默认的模式)
rt
wt
at
1.该模式只能操作文本文件
2.该模式下必须指定encoding参数
3.读写都是以字符串为单位
#b模式
二进制模型
rb
wb
ab
1.该模式可以操作任意类型的文件
2.该模式下不需要指定encoding参数
3.读写都是以bytes(二进制)为单位
![]()
作业
1.利用文件操作编写一个简易的文件拷贝系统
让用户输入需要拷贝的文件路径
然后再获取即将拷贝到哪儿的路径
a=input('请输入你需要拷贝的文件路径>>>:')
b=input('请输入你拷贝到的文件路径>>>:')
with open(a,'r',encoding='utf8') as f1:
c=f1.read()
with open(b,'w',encoding='utf8') as f2:
f2.write(c)
2.利用文件操作完成用户的注册、登录
userinfo.txt
#基本要求
用户注册获取用户名和密码然后写入文件
登录获取用户名和密码之后去文件中比对
上述操作完成一次就算成功
print('注册')
a1 = input('用户名:')
b1 = input('密码:')
c1 = a1+'|'+b1
with open(r'abc.txt','a',encoding='utf8') as f1:
f1.write(c1)
print('注册成功!')
print('登陆账号')
a2 = input('用户名:')
b2 = input('密码:')
c2 = a2+'|'+b2
with open(r'abc.txt','r',encoding='utf8') as f2:
d = f2.read()
if c2 in d:
print('登陆成功!')
else:
print('登陆失败!')
#拔高练习
用户注册可以多次注册并且校验用户名是否重复
登录需要逐行比对




 浙公网安备 33010602011771号
浙公网安备 33010602011771号