
一.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
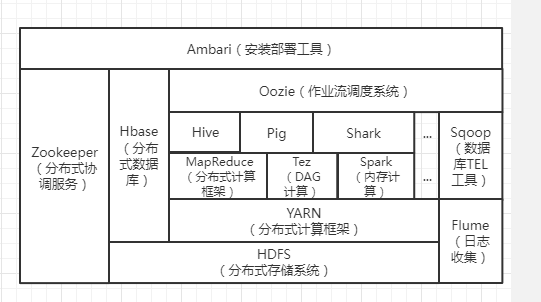
HDFS:分布式存储系统。
YARN:资源调度。
MapReduce:任务计算。
Hive:让hadoop集群拥有关系型数据库的sql体验,本质是Hadoop的一个插件,如果有统计,加减乘除等计算任务就会将sql语句转化为MapReduce。
Hbase:让hdfs拥有海量存储功能,并且在大数据量的情况下实现秒级查询,本质还是建立在hdfs上。
Zookeeper:从定义上来说,zk是一个监控以及通知分布式系统。类似于一个小型的hadoop,即小型分布式系统。
Spark:一种计算框架,不用安装hadoop,也可以独立使用,相比于MapReduce使用内存,计算快。
Sqoop:数据库etl工具,将hive和hbase与msql相互转数据。
Flume:收集日志。
2.对比Hadoop与Spark的优缺点。
Spark 是在借鉴了 MapReduce 之上发展而来的,继承了其分布式并行计算的优点并改进了 MapReduce 明显的缺陷,(spark与hadoop 的差异)具体如下:
(1)Spark 把中间数据放到内存中,迭代运算效率高。MapReduce 中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而 Spark 支持 DAG 图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。
(2)Spark 容错性高。Spark 引进了弹性分布式数据集 RDD (Resilient DistributedDataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD 计算时可以通过 CheckPoint 来实现容错。
(3)Spark 更加通用。MapReduce 只提供了 Map 和 Reduce 两种操作,Spark 提供的数据集操作类型有很多,大致分为:Transformations 和 Actions 两大类。Transformations包括 Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort 等多种操作类型,同时还提供 Count, Actions 包括 Collect、Reduce、Lookup 和 Save 等操作。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop 的生态系统,以弥补MapReduce的不足。
3.如何实现Hadoop与Spark的统一部署?
由于Hadoop、MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号