
续啃:编程指北 C++ (从 RAII开始的,RAII这一小节,学了将近两个月,RAII 的内容早在之前就主动追问豆包搞懂了,这节主要是自己无尽追问探索出很多其他知识,后来发现其实堪比精啃 CSAPP & APUE 等圣书)
关于 C++ RAII 思想机制详解:(这里之前自己主动探索过,根本不需要学啥,但自己又主动探索到了个其他东西,他妈的超级大超级大的血案,浪费了一个半月!!)(尸山血海异常痛苦~~~~(>_<)~~~~)(堪比赵云七进七出反复抽插底层涉及到完全不考的东西妈逼的钻研了将近两个月)(堪比精啃 CSAPP & APUE 等经典圣书!)
没想到一直牵扯出这么多知识点,所有涉及到此文搜的东西,搜不到就去上一篇的《编程指北 C++》里搜
作者原文:
资源获取即初始化( Resource Acquisition Is Initialization,简称RAII )是一种 C++ 编程技术,它将在使用前获取(分配的堆内存、执行线程、打开的套接字、打开的文件、锁定的互斥量、磁盘空间、数据库连接等有限资源)的资源的生命周期与某个对象的生命周期绑定在一起。
确保在控制对象的生命周期结束时,按照资源获取的相反顺序释放所有资源。
同样,如果资源获取失败(构造函数退出并带有异常),则按照初始化的相反顺序释放所有已完全构造的成员和基类子对象所获取的资源。
这利用了核心语言特性(对象生命周期、作用域退出、初始化顺序和堆栈展开),以消除资源泄漏并确保异常安全。
这段话我看个开头一句就知道自己会!之前代码涉及过!
RAll的原理
核心思想就是:利用栈上局部变量的自动析构来保证资源一定会被释放。
因为我们平常 C++ 编程过程中,经常会忘了释放资源,比如申请的堆内存忘了手动释放,那么就会导致内存泄露。
还有一些常见是程序遇到了异常,提前终止了,我们的资源也来不及释放。
但是变量的析构函数的调用是由编译器保证的一定会被执行,所以如果资源的获取和释放与对象的构造和析构绑定在一起,就不会有各种资源泄露问题。
RAII 类实现步骤:
设计一个类封装资源,资源可以是内存、文件、socket、锁等等一切
在构造函数中执行资源的初始化,比如申请内存、打开文件、申请锁
在析构函数中执行销毁操作,比如释放内存、关闭文件、释放锁
使用时声明一个该对象的类,一般在你希望的作用域声明即可,比如在函数开始,或者作为类的成员变量
先科普几个东西:
C 语言中用
fopen打开文件,fclose关闭,需手动管理:#include <stdio.h> int main() { FILE* fp = fopen("example.txt", "r"); // 打开文件,"r"为只读模式 if (fp == NULL) { // 必须检查是否打开成功 perror("Failed to open file"); return 1; } // 操作文件(如fread、fgets等) fclose(fp); // 必须手动关闭,否则资源泄漏 fp = NULL; // 避免野指针 return 0; }模式:
"r"(读)、"w"(写,覆盖)、"a"(追加)等。风险:若忘记
fclose或中途异常退出,会导致文件描述符泄漏,需手动保证配对调用,不如 C++ 的ifstream(RAII)安全。操作系统对进程能打开的文件描述符数量有限制,若反复打开文件却不关闭,会耗尽资源,后续fopen会失败(返回NULL)。程序退出后操作系统会回收资源,但长期运行的服务端程序就会有问题。例如:循环中反复
fopen而不fclose,很快会因 “打开文件数超限” 崩溃。这也是 C++ 的ifstream(RAII 自动关闭)比 C 的fopen更安全的核心原因。C++ 流对象(如
ifstream/ofstream)析构时自动调用close(),无需手动操作异常退出指程序未按正常流程结束,比如:
主动调用
exit()、abort()强制终止;发生未捕获的异常(C++)、段错误(如访问野指针)、除零错误等崩溃;
被外部信号终止(如
kill命令、Ctrl+C)。短期或单次运行的程序,异常退出后未释放的资源(如文件描述符)会被操作系统回收,看似 “不管也行”。但在长期运行的服务端程序中,若程序频繁异常退出(如偶发崩溃),每次退出前未释放的资源(即使 OS 会回收)可能导致瞬时资源占用峰值,影响系统稳定性;更关键的是:异常退出前,未
fclose的文件可能存在数据未刷新的问题(如写操作缓存未同步到磁盘),导致数据丢失。
fclose会先刷新缓冲区(确保数据写入文件),再释放文件描述符。而 RAII 机制(如
ifstream)在多数异常场景下会触发析构,确保资源释放和数据一致性,这也是服务端开发必须重视的原因。引出
ifstream:1、资源获取与释放:
fopen需手动调用fclose释放文件描述符,且必须保证配对(漏写或异常退出可能导致泄漏);
std::ifstream的myfile对象构造时打开文件(获取资源),析构时自动调用关闭逻辑(类似fclose,包括刷新缓存、释放描述符),无需手动干预,RAII 机制确保 “获取即管理,销毁即释放”。2、异常场景安全性:
若用
fopen后程序因异常(如崩溃、抛错)退出,fclose可能来不及执行,导致文件描述符泄漏或数据未刷新;
std::ifstream在对象生命周期结束时(即使异常退出触发栈解旋),析构函数一定会执行,避免上述问题。3、使用复杂度:
fopen需要手动检查返回值(是否为NULL)、管理关闭时机,逻辑冗余且易出错;
std::ifstream封装了打开 / 关闭细节,通过is_open()检查状态即可,代码更简洁,符合 C++ 封装思想。简单说:
fopen是 “手动挡”,需全程操控;std::ifstream是 “自动挡”,RAII 机制自动完成资源管理,更适合工程化开发(尤其服务端长期运行场景)。我艹!!突然发现这些之前自己主动探索过!!此文搜"AII。核心就是塞",妈逼的之前写成了
rall的大写,应该是raii的大写。这里说点其他的:
今天又学到个东西,相当高潮!!(实际花了大半个月!)
开始叙述:
由于作者给的代码好多封装的东西看不懂,先科普点自己查到的东西,主要就是针对
std::ifstream:
File类通过成员m_handle(std::ifstream对象)管理文件资源,构造时传入文件名并尝试打开(资源获取),析构时自动关闭文件(资源释放)。即使不手动调用
close(),File对象销毁时,m_handle的析构函数也会确保文件关闭,双层 RAII 嵌套(File依赖std::ifstream的 RAII)进一步保证安全性。然后运行作者代码报错了,发现
std::ifstream是输入文件流,用于读取文件,只尝试打开已存在的文件,若文件不存在则打开失败,不会自动创建新文件。如果需要 “文件不存在时自动创建”,应使用输出文件流
std::ofstream(或读写流std::fstream配合写入模式)C++ 流操作的模式与 C 语言
fopen的模式对应,比如:
std::ifstream默认对应fopen的"r"(只读,文件必须存在);
std::ofstream默认对应"w"(只写,文件不存在则创建,存在则清空);若需更灵活的模式(如追加、读写),可显式指定,例如:
std::fstream("file.txt", std::ios::in | std::ios::out)→ 对应"r+"(读写);
std::ofstream("file.txt", std::ios::app)→ 对应"a"(追加)。本质和
fopen的模式语义一致,只是 C++ 用枚举常量(std::ios::xxx)表示,更类型安全。先科普下涉及到的其他的一些东西,唉他妈烦,看到就要钻研弄懂:
关于
getline,死全家的狗逼豆包误人子弟!给我科普了这个:查看代码
#include <stdio.h> #include <stdlib.h> // 需用malloc/free int main() { char *line = NULL; // 存储读取的字符串(初始必须为NULL) size_t len = 0; // 缓冲区大小(初始设为0,会自动分配) ssize_t read; // 实际读取的字符数(含换行,不含结束符) // 从标准输入(键盘)读一行 read = getline(&line, &len, stdin); if (read != -1) printf("你输入了:%s", line); // 输出包含换行符 free(line); // 必须释放内存 }
getline:第 3 个参数(stdin)是从哪里读、第 1 个参数(&line)是存、第 2 个参数(&len)是记录存储结果用了多大空间(自动算好填进来)返回值:
成功:返回实际读取的字符数(包含换行符
\n,但不包含字符串结束符\0)。失败(如读到文件尾或出错):返回
-1。逐句分析:
#include <stdlib.h>:引入内存管理函数(比如free)的声明。
char *line = NULL;:定义一个指针,暂时不指向任何内存(后面由getline分配)。
size_t len = 0;:定义一个变量,记录line指向的内存块大小,初始为 0,函数会根据实际读取内容的长度,自动计算并更新len的值,让它等于当前缓冲区的实际大小(方便后续复用缓冲区时知道已有多大空间)。
ssize_t read;:定义一个变量,记录实际读到的字符数量(含换行)。
read = getline(&line, &len, stdin);:从键盘读一行内容到line,同时更新len为实际内存大小。
if (read != -1) {:判断是否成功读到内容(-1 表示失败)。
free(line);:释放getline给line分配的内存(必须做,否则内存泄漏)。实操过程:
你输入了
n个字节(包括空格、换行);函数自动找一块能放下
n+1个字节的内存(多 1 个存结束符\0);用
line指针指向这块内存(所以line会从NULL变成有效地址);把
n+1(实际占用的内存大小)存到len里。妈了个逼的!操.你妈!!结果这逼玩意是必须用纯 C 语言开发,且需要读取不确定长度的一行文本(比如处理用户输入的长句子、配置文件行等)才用的!
而且最主要的是狗逼豆包说错了!被我质疑出来的,上面这个代码只有 Linux 下可以,win 的 codeblock 编译报错。
C 是编程语言,有自己的标准库(ISO C),标准库里没有
getline。POSIX 是系统接口标准,Linux 等系统遵循它,在 C 语言的编译环境中额外加了
getline函数(属于 C 语言的 “扩展函数”,不是 C 标准自带)。即编译器扩展C++ 自己的标准库,自带
std::getlineACM 刷题中用的
getline是 C++ 标准库的std::getline,Windows 的 C 环境没有getline,Linux 的 C 环境有getline。回忆刷算法和以后大厂都是用 C++ 的
getline:C++ 的getline俩参数,从第一个参数读(一般是cin,即键盘),存到第二个参数(一个string变量)。#include <iostream> #include <string> using namespace std; int main() { string s; getline(cin, s); // 从cin读一行,直接放进s里 cout << s; // 输出s,完事 return 0; }不用管内存,不用记大小,
string会自动处理一切,C 的getline因为要手动管内存)C 的
getline返回字节数(含 \n),C++ 的std::getline返回流对象。准确说不是 C 的,是扩展。
然后再捋清楚几个东西(从底层到应用)
ios类(终极的最父类):最顶层的 “规则类”,这逼玩意跟苹果 IOS 完全不是一个东西
只负责 3 件事:定模式(
in/out等)、记状态(failbit等)、提供基础操作(open()/close())。不负责具体读写,只是给所有流类定标准,自身不包含
istream/ostream。
istream和ostream类:ios的直接子类,继承ios所有成员,没有stream都是加个i或者o各种前缀,另外那些人打游戏用的是 Steam
istream:继承ios的规则,新增读数据的方法(>>、getline()等,比如从键盘 / 文件读数据)。
ostream:继承ios的规则,新增写数据的方法(<<、write()等,比如往屏幕 / 文件写数据)。
ifstream/ofstream/fstream:文件专用流类继承
istream/ostream,把 “读 / 写方法” 绑定到文件上(比如ifstream用istream的>>从文件读)。
ifstream直接继承istream(是istream的子类,间接继承ios)。给istream增加 “操作文件” 的能力(专门读文件)。
ofstream直接继承ostream(是ostream的子类,间接继承ios)。给ostream增加 “操作文件” 的能力(专门写文件)。
iostream直接继承istream+ostream(同时是两者两者的子类)。整合读和写的功能(为第 4 层做基础)。
fstream类
地位:直接继承
iostream(是iostream的子类,间接继承istream/ostream/ios)。作用:给
iostream增加 “操作文件” 的能力(既能读又能写文件)。总结:
ios是顶层基类:
ios→istream(继承ios,负责 “读” 功能)→ifstream(继承istream,专门 “读文件”)同时:
ios→ostream(继承ios,负责 “写” 功能)→ofstream(继承ostream,专门 “写文件”)另外:
ios→istream和ostream(平级,都是ios的子类)→iostream→fstream(继承iostream,专门 “读写文件”,f是 file)注意:这里的
iostream同时继承istream和ostream,同时读 + 写功能,属缝合怪,没有自己的独立父类分支,而是把istream(读)和ostream(写)的功能 “缝合” 到一起,形成 “既能读又能写” 的基础类。fstream则是在这个 “缝合基础类” 上,再叠加 “文件操作能力”,所以能同时读写文件。关于使用:
可以直接初始化对象(直接定义实例)的类,都是绑定了具体输入输出设备的类,包括:
ifstream:直接初始化(绑定文件,用于读):ifstream fin("file.txt");初始化读文件对象
ofstream:直接初始化(绑定文件,用于写):ofstream fout("file.txt");初始化写文件对象
fstream:直接初始化(绑定文件,用于读写):fstream fs("file.txt");初始化读写文件对象
cin/cout:标准库已预定义的全局实例,分别绑定键盘 / 屏幕,是已经创建好的对象,直接用,而ifstream、ofstream、fstream是类,但你可以手动创建它们的实例(对象)来用,比如:ifstream fin;、fin ofstream fout;、fout fstream fs;不能 / 无需手动初始化对象的类:
ios/istream/ostream:纯基类,仅用于被继承,不直接绑定设备,手动初始化无意义(比如istream is;无法指定读哪里,没用)。
iostream:istream+ostream的派生类,同样不绑定具体设备,不可拿来初始化,也就是不能拿来创建对象,上面说的初始化就是创建对象,就是实例化,而fstream是它的子类,已绑定文件,用fstream即可。
继续巩固:
ofstream的对象(如fout)和cout都属于ostream家族,都能使用<<运算符进行输出(写操作),<<是ostream类重载的运算符,专门用于输出(写)操作,属于ostream类的成员功能。
ofstream是ostream的子类(继承关系),专门用于 “写文件”,可以创建对象(如ofstream fout;)。
cout是ostream类的全局对象(不是子类),由标准库预先创建,专门用于 “写屏幕”。
istream类的>>操作符用于读操作,ifstream的对象(如fin)继承自istream(读自文件),cin是istream类的全局对象(读自键盘),
cin >> x→ 从键盘读数据到x
fin >> x→ 从文件读数据到x
getline是istream类的成员函数,可用于istream家族的对象(包括cin和ifstream的对象):
getline(cin, str)→ 从键盘读一行到str
getline(fin, str)→ 从文件(fin关联的文件)读一行到str本质是专门为流式设计的“按行读”工具,和
>>一样属于读操作,只是更适合读取带空格的整行内容。
cin和cout:控制台流对象
cin是istream的实例(已经创建好的对象),专门用istream的>>从键盘读数据。
cout是ostream的实例,专门用ostream的<<往屏幕写数据。打个比方(仅结构,非比喻):
ios是 “地基”,istream/ostream是在地基上盖的 “房子”—— 房子用了地基的结构,但地基不包含房子本身。所以ios不 “包括”stream,stream是ios的 “继承者” 并扩展了功能。那
#include <iostream>是啥?这是一个头文件,作用是 “把
istream/ostream类的定义、cin/cout对象的声明” 加载到你的代码里。没有它,你写cin >> x或cout << x时,编译器不认识cin/cout和>>/<<,会报错。它间接包含了ios类的定义(因为istream/ostream继承ios,所以必须一起加载)。
为什么加
std::?因为这些类和对象都定义在std这个 “命名空间” 里(避免名字冲突)。嫌麻烦可以开头加
using namespace std;,之后直接写cout不用加std::。读字符串(用
getline)cin >>遇到空格会停,读整行必须用getline(cin, 变量)。你写
cout << "abc"时:cout是ostream的对象,继承了ios的规则;<<是ostream新增的写方法,负责把"abc"送到屏幕;整个过程遵循ios定的模式(默认out模式,允许写)。你写
cin >> age时:cin是istream的对象,继承了ios的规则;>>是istream新增的读方法,负责从键盘拿数据给age;遵循ios的in模式(允许读)。
>>从流中“读数据”,功能是将左侧流对象中的数据读取到右侧的变量中。
<<往流中“写数据”,功能是将右侧的数据发送到左侧的流对象中。
最常用的是
ifstream和ofstream:
ifstream读配置文件(比如服务启动参数、路由表)、读日志文件(分析历史数据):查看代码
ifstream fin("config.conf"); // 打开配置文件 if (!fin.is_open()) { // 必须判断是否打开成功(服务端必做) // 实际开发中会记录错误日志,然后退出服务 return -1; } string line; while (getline(fin, line)) { // 按行读配置 // 解析每行配置(比如"port=8080") } fin.close();
ofstream:写日志(服务运行状态、错误信息)、写临时文件(中间计算结果)。用法示例(写日志,追加模式):查看代码
// 追加模式(ios::app),每次写都加在文件末尾 ofstream fout("server.log", ios::app); if (!fout.is_open()) return -1; // 写日志(带时间戳,服务端常用格式) fout << "2025-11-15 10:00:00 [INFO] 服务启动成功" << endl; fout.close();偶尔使用
fstream,对文件进行读写混合操作(比如修改配置文件中的某个字段),fs.get(c)读取包括空格 / 换行的单个字符,>>跳过空白字符读取下一个有效字符(如字母、数字):查看代码
fstream fs("data.txt"); // 默认ios::in|ios::out(可读可写) if (!fs.is_open()) return -1; // 1. 先读:读取第3个字符(位置2) char c; fs.seekg(2); // 移动读指针到位置2 fs.get(c); // 读该位置的字符(这是“读”操作) cout << "读到的字符:" << c << endl; // 2. 再写:在位置5覆盖一个字符(这是“写”操作) fs.seekp(5); // 移动写指针到位置5 fs << 'x'; // 覆盖写 fs.close();以上这些是流啥的,然后继续说还有个东西就是模式,我反复追问,死全家的狗逼豆包给我解释了一天我都没懂,最后极致的追问然后自己总结完清晰易懂,豆包来了句“你的理解非常准确,核心点完全抓对了”操!就他妈不能自己主动这么说!!
这里反复追问真的浪费时间,但追问、和豆包配合的能力有了质的飞跃!!还是之前那句话,大模型现在就是个智障,整天被气死整天辱骂豆包,经常瞎编 C++规则,经常误人子弟,又墙头草无脑附和无脑道歉,但我如今会问、会分析、节省大量时间可以通过豆包来学知识,豆包回答专业问题错误肯定经常有,但如今学会了可以互相启发、合作,逐渐提问比如我只懂 1,提问深度 123,他解释 3 的时候有对有错,我学到 2 ,又重新根据 12 来提问,反复互相合作配合。这比没大模型的时候好多了!!如果不思考不追问嫌麻烦不是那块料一定会得出结论“豆包都是错的,自学用豆包就是扯淡”。再比如就是我问他,他回答让我明白些许,然后自己思考、捋顺,但经常里面夹杂着错误,我给他指出来,互相配合!
那些继承
ios的类是用来往屏幕或者文件读写的派生类,然后这个模式是是ios里写的,ios这个基类本身不能直接用,但可以ios::in这样用里面面模式,然后模式是对上面说的派生类读写的一种补充,或者说模式是给读写行为定规则,比如ofstream天生能写,但ios::trunc规定写之前清空,ios::app规定写只能追加到末尾,没有这些规则,写操作的行为就不明确。ios是抽象基类(不能直接创建对象),但它的成员(模式、状态标志、方法)通过 “继承” 被istream/ofstream等类 “拿过去用”,所以你操作ofstream时,本质是在间接用ios里的东西。继续深入:
ofstream的继承链是ios → ostream → ofstream,ios中的ios::in是一个模式常量(类似一个全局常量),所有继承ios的类(包括ostream)都能 “看到” 并ios::in使用它,但ostream的设计目标决定了它不会默认启用ios::in,也不实现任何读操作。能访问ios::in符号 ≠ 具备读资格,假设ios里定义了两个开关:class ios { public: static const int in = 1; // 读开关(符号) static const int out = 2; // 写开关(符号) int mode; // 当前启用的模式(默认0,啥都没开) };
ostream继承ios后,能看到in和out这两个符号,但它的构造函数里会主动设置mode = out(只开写开关):class ostream : public ios { public: ostream() { mode = out; // 主动启用写模式,不碰in } };
ofstream继承ostream后,直接用ostream设定的mode = out,也不会去改in:class ofstream : public ostream { // 继承了ostream的mode = out,不会启用in };这里的mode就是流内部记录 “当前启用了哪些模式” 的变量,和你打开文件时传入的模式参数(比如ios::out | ios::app)是一回事 ——打开文件时传入的模式,最终会赋值给这个mode变量,流的所有行为都以mode的值为准。当你写ofstream f("a.txt")时,背后发生的是:
ofstream调用父类ostream的构造函数;
ostream的构造函数会默认给mode赋值ios::out | ios::trunc(这就是 “主动设置”);最终
f的mode里只有out和trunc,没有in—— 所以无论ios里有没有in这个符号,f的mode里没它,就不具备读能力。如果手动传入模式,比如
ofstream f("a.txt", ios::out | ios::app),则:mode会被赋值为ios::out | ios::app(覆盖默认的trunc),但依然没有in。
ofstream并非主动拒绝in,而是设计时就没把in放进mode模式参数是是覆盖默认,每个流类都有自己的默认
mode,ofstream默认mode = ios::out | ios::trunc;当你手动传模式(如ios::out | ios::app),新的mode会完全替代默认值,而不是和默认值取并集。查看代码
ofstream f1("a.txt"); // 默认 mode = out | trunc(覆盖原文件) ofstream f2("a.txt", ios::app); // 实际 mode = out | app(追加,覆盖了默认的 trunc),ofstream 有个特殊规则:无论手动传入什么模式,ios::out 都会被强制包含
ios::out和<<是 “写操作” 的两个不同层面
ios::out:是权限开关(模式),作用是 “允许流进行写操作”。没有ios::out,流就没有写权限,任何写操作(包括<<)都无法执行。例如ofstream f("a.txt")能写,正是因为它默认带ios::out权限。
<<:是具体的写操作工具(运算符),作用是 “把数据实际写到流里”。它必须在有ios::out权限的前提下才能用,否则会失败。例如f << "hello"是用<<这个工具,把 “hello” 写到文件里,而这一切的前提是f有ios::out权限。简单说:
ios::out是 “允许写的资格”,<<是 “执行写的动作”—— 有资格才能动作用,动作用依赖资格存在。
ios作为基类,包含了所有流的通用功能(模式、状态等),但它本身不直接实现 “读” 或 “写” 的具体操作。
istream和ostream是ios的两个直接子类,分别专注于 “读” 和 “写”:
istream继承ios后,通过继承获得ios::in模式(允许读权限),然后在这个基础上,主动实现并重载了>>运算符,即只扩展实现了 “读” 相关的操作(如>>、getline()),不涉及 “写”。
ostream继承ios后,通过继承获得ios::out模式(允许写权限),然后在这个基础上,主动实现并重载了<<运算符,即只扩展实现了 “写” 相关的操作(如<<、write()),不涉及 “读”。那说一个,另一个同理:
getline(流成员函数)和>>运算符重载,来源和依赖完全一致:
来源相同:两者都是
istream类(继承自ios)中定义的 “读操作工具”——>>是运算符重载,getline是成员函数,都属于istream对 “读功能” 的具体实现。依赖相同:两者都必须基于
ios::in模式(读权限)才能工作 —— 没有ios::in,流对象不具备读权限,无论是>>还是getline都会失败(触发failbit)。操作对象相同:都作用于
istream及其子类对象(如ifstream、cin),本质是通过这些对象的读权限和底层接口完成数据读取。继续(有重复内容,但就像手机录解锁屏幕指纹一样,逐渐修正完善):
ofstream继承并直接使用ios中的这些核心内容:
模式常量:
默认使用
ios::out(写权限)和ios::trunc(写时清空文件),这两个是ios中定义的模式,决定了ofstream天生能写且默认覆盖文件。可手动添加
ios::app(追加)、ios::binary(二进制必须用这个,否则乱码)等ios模式,修改写行为。状态标志及判断方法:
使用
ios中的failbit、goodbit等状态标志,通过ofstream的fail()、good()等方法(继承自ios)判断写操作是否成功。基础方法:
继承
ios的open()、close()、is_open()等方法,用于打开 / 关闭文件、检查文件是否打开成功。简单说:
ofstream所有与 “写规则”“状态判断”“文件管理” 相关的底层支持,都来自ios。看几个常用的:
核心类:
ifstream(读文件)、ofstream(写文件)、fstream(读写文件)。继承关系:
ios←istream/ostream←ifstream/ofstream/fstream。常用模式(
ios中定义):ios::in(读权限)、ios::out(写权限)、ios::trunc(写时清空)、ios::app(写时追加)。类与模式的默认绑定:
ifstream默认带ios::in;
ofstream默认带ios::out | ios::trunc;
fstream默认带ios::in | ios::out。基础操作:
打开:
ifstream fin("a.txt")或fin.open("a.txt");判断打开成功:
if (!fin.is_open()) { /* 错误处理 */ };读:
getline(fin, line)或fin >> var;写:
fout << "text"或fout.write(buf, size);关闭:
fin.close()。状态判断(
ios方法):fin.good()(正常)、fin.fail()(失败)、fin.eof()(到文件尾)。C++ 中,流是 “数据传输的抽象”,所有数据的输入输出(比如从键盘读、往屏幕写、从文件读、往文件写)都被统一称为 “流操作”。
总结几个东西:
三大主要功能之一:打开文件(3 种方式)
查看代码
#include <fstream> #include <string> using namespace std; int main() { // 方式1:定义时直接打开(推荐,简单) ifstream fin("input.txt"); // 读文件,默认ios::in ofstream fout("output.txt"); // 写文件,默认ios::out|trunc // 方式2:先定义,后用open()打开(灵活,可动态指定文件名) fstream fs; string filename = "data.txt"; fs.open(filename, ios::in | ios::out); // 读写已有文件 // 方式3:指定特殊模式(追加/创建读写) ofstream fapp("log.txt", ios::app); // 追加模式(不清空,末尾加内容) fstream fcreate("newfile.txt", ios::out); // 创建并读写(无ios::in,文件不存在则创建) // 关键:打开后必须判断是否成功!(大厂必做,防止崩溃) if (!fin.is_open()) { // 实际开发中会打日志,这里简化用cout cout << "打开input.txt失败!可能文件不存在" << endl; return -1; } // ... 操作文件 ... // 关闭文件(虽然后台会自动关,但手动关是好习惯) fin.close(); fout.close(); fs.close(); }三大主要功能之二:读文件(3 种常用方式)
查看代码
/* input.txt里是 hello 123 456 */ #include <fstream> #include <iostream> #include <string> using namespace std; int main() { // 1. 定义ifstream对象fin,打开文件"input.txt" ifstream fin("input.txt"); // 等价于 ifstream fin; fin.open("input.txt"); // 必须判断文件是否打开成功(核心步骤,缺一不可) if (!fin.is_open()) { cout << "文件打开失败!可能原因:文件不存在或权限不足" << endl; return -1; // 打开失败就退出,避免后续操作崩溃 } // 2. 按行读取(方式1) cout << "=== 按行读 ===" << endl; string line; while (getline(fin, line)) { // getline成功读取一行时返回true,到文件尾返回false cout << "读到一行:" << line << endl; } // 注意:按行读完后,文件指针已经到末尾了,需要重置指针才能继续用其他方式读 fin.clear(); // 清除之前的"到文件尾"状态 fin.seekg(0, ios::beg); // 把读指针移回文件开头(ios::beg表示从文件开始算) // 3.· 按空格/换行分割读(方式2) cout << "\n=== 按分割符读 ===" << endl; string s; int a, b; fin >> s; // 读第一个单词"hello"(遇到空格停止) fin >> a; // 读整数123(遇到非数字停止,这里是换行) fin >> b; // 读整数456 cout << "读到:" << s << " " << a << " " << b << endl; // 再次重置指针,准备二进制读 fin.clear(); fin.seekg(0, ios::beg); // 4. 二进制方式读(方式3) cout << "\n=== 二进制读 ===" << endl; char buffer[1024] = {0};//很重要 fin.read(buffer, sizeof(buffer)); // 尝试读1024字节到buffer int bytes_read = fin.gcount(); // 获取实际读到的字节数(可能小于1024) cout << "实际读到" << bytes_read << "字节,内容(部分):" << buffer << endl; // 5. 关闭文件(虽然后台会自动关,但手动关是好习惯) fin.close(); }
解释代码:
clear()清除流的 “错误状态标志”(比如文件读完的eofbit、操作失败的failbit)。不清的话:
流会一直处于 “错误状态”,后续所有读写操作都会直接失败(比如读完文件后,不
clear()就无法重新读)。流有错误状态时,默认会停止读取(>>、read()等操作会失效)必须用
clear()重置状态,流才能恢复正常操作。只有当流处于 “错误状态”(比如读完文件触发
eofbit、操作失败触发failbit)时,才需要clear()重置。如果流状态正常(goodbit有效),clear()可调用可不调用,不影响后续操作。
fin.seekg(0, ios::beg)是移动文件的 “读指针” 到指定位置:
seekg:专门用于移动 “读指针” 的函数(g代表 get,读操作)。
0:偏移量(移动的字节数)。
ios::beg:偏移的基准位置(beg代表 beginning,文件开头)。合起来:把读指针移到 “从文件开头算起,偏移 0 字节” 的位置 → 也就是文件的最开头。作用:读完文件后,指针会停在末尾,用这句能把指针移回开头,重新读取文件内容。
cout << "\n=== 按分割符读 ===" << endl; string s; int a, b;:从
fin关联的文件(这里是input.txt)中读。
fin是ifstream对象,已通过ifstream fin("input.txt")绑定到input.txt文件。fin >> sfin >> a这些操作,本质是从fin对应的文件中,按空格 / 换行分割读取数据。简单说:>>左边是哪个流对象(这里是fin),就从哪个流(文件)读。
<<尖朝左,右数据向左流(写);>>尖朝右,左流向右变量(读)。死全家的豆包妈逼的连<<尖端朝左还是右都搞不清翻来覆去犯错误误人子弟!起初输出的最后一行是:
123 456 ////////////,是没是未初始化缓冲区的垃圾值,用char buffer[1024] = {0}初始化就好了。
豆包误人子弟误打误撞学到个东西:
Windows 换行符
\r\n在 Linux 下的残留(所以 txt 文件要用),ws是 C++ 标准库定义的输入操纵符,当用于fin >> ws时,会从输入流fin中连续提取所有空白字符(空格 、换行\n、制表符\t等),直到遇到第一个非空白字符为止。这些被提取的空白字符不会被存储,仅会被从流中移除。Windows 的文本文件,
\n会被转换成\r\n(回车 + 换行)。Linux 的文本文件,换行是\n
input.txt如果在 Windows 下创建,换行是\r\n。当 Linux 下的程序读这个文件时:
按行读(
getline)会正常处理\r\n,把hello world\r\n当成一行,输出没问题。但重置指针后按
>>读时,\r会被当成 “不可见的残留字符”。当程序读完hello后,下一个要读的是world\r\n123 456,>>遇到\r会认为是 “非数字字符”,导致读取123失败,a和b就被赋默认值 0。解决办法(针对跨系统文件):
让文件用 Linux 格式保存:在 VSCode 里打开
input.txt,右下角点 “CRLF”(Windows 格式),改成 “LF”(Linux 格式),保存后换行符会变成\n,问题直接消失代码里兼容两种格式:读数字前用
ignore()跳过可能的\r:fin >> s; // 读hello fin.ignore(1, '\r'); // 跳过可能的回车符 fin >> a; // 读123 fin.ignore(1, '\r'); // 再跳过可能的回车符 fin >> b; // 读456
关于
fin.ignore(numeric_limits<streamsize>::max(), '\n'):他是一个用于精准删除输入流中特定内容的操作,具体特性如下:它会从流的当前位置开始,连续删除字符,直到满足以下两个条件中的任意一个:
已删除的字符数达到
numeric_limits<streamsize>::max()(一个极大值,可视为 “无限”);遇到了第二个参数指定的字符(例如
'\n'),此时会连这个字符一起删除。第二个参数(
'\n')可以替换为任意字符。结合指针定位(seekg)可以去掉任意位置后的东西。
fin.ignore(...):从当前位置开始,跳过最多max()个字符,直到遇到指定分隔符(如'\n'),会连分隔符一起跳过。关于
fin >> ws:仅跳过流开头的所有空白(空格、换行等),不跳过非空白内容。区别:
fin >> sfin >> a这些操作,本质是从fin对应的文件中,按空格 / 换行分割读取数据。
读取
int时,会自动忽略整数前的所有空白字符(空格、换行、制表符等)
突然想起网络编程的那个 Linux 的系统调用的 read,哎,强迫症又去追问好久,狗逼豆包误人子弟真的痛苦,真的!!用豆包自学真的有种要习惯吃屎往下咽的感觉:
read函数的原型,定义在istream类中,是 C++ 标准库封装的流方法按流模式(文本 / 二进制)从流中读取指定字节数,原型
istream& read(char* s, streamsize n);,意思是返回值是istream&类型,表示该函数返回一个istream类对象的引用(即流对象本身),为了支持链式调用,比如fin.read(buf, 10).read(buf2, 5);,前一个read返回流对象fin,接着可以继续调用它的read方法。比如:
fin.read(buffer, size)
参数 1 :存哪?
参数 2 :要读几个字节?
返回值:
istream&(返回流对象本身,支持链式调用,虽然很少常用)。用
gcount()获取实际读取的字节数。如果要读 100 个,存的内存是 8,那只能读 8 个。
Linux 的
read是系统调用(用于网络编程的),直接操作文件描述符(整数),从内核缓冲区读取原始字节,语法:read(fd, buffer, size)。起初以为二者完全不是一个东西,但有关系且都读二进制:
查看代码
C++ 代码:ifstream.read(buffer, size); ↓ C++ 标准库:std::basic_istream::read() 方法(属于ios的) ↓ Linux 系统调用:read()(内核处理实际的文件 I/O)(<unistd.h>)然后开始逐渐深入说点东西:
C++ 的 read 是否也涉及到文件描述符?
1. 关于
read和文件描述符
C++ 的
ifstream::read:C++ 标准库提供的函数,属于用户态代码。不直接操作文件描述符。Linux 的
read():它是操作系统提供的系统调用,属于内核态接口。它必须通过文件描述符来操作文件、套接字等资源。核心关系:
ifstream::read内部会调用read()系统调用。你在 C++ 代码中创建ifstream对象时,标准库会请求操作系统打开文件,操作系统会创建一个file对象并返回一个文件描述符。ifstream对象会持有并管理这个文件描述符,当你调用read时,它会把这个文件描述符作为参数传递给底层的read()系统调用,从而完成实际的数据读取。一句话总结:C++ 的
read是包裹着系统调用read()的 “壳”,它负责管理文件描述符等细节,让你不用直接和内核打交道。2. 到底咋理解内核和内存
内核 (Kernel):
操作系统的核心,是硬件和软件之间的桥梁。
它管理着所有硬件资源(CPU、内存、磁盘、网卡等)。
它运行在内核态,拥有最高权限,可以直接访问硬件。
像
read()、write()、socket()这些系统调用,就是你的程序请求内核帮忙做事的 “接口”。内存 (Memory):
程序运行时存放数据和指令的地方,速度远快于磁盘。
为了安全和稳定,内核将内存划分为两部分:
内核空间 (Kernel Space):只有内核可以访问的区域,存放着内核代码和数据结构(比如文件描述符表、进程控制块等)。
用户空间 (User Space):普通应用程序(比如你的 C++ 程序)运行的区域。应用程序不能直接访问内核空间,也不能直接操作硬件。
我自己的理解(经过豆包肯定):操作系统运行在内核态也就是内存里内核空间,这里是总的最高权限的指挥中心,程序员的代码无法触碰操控这里,想操控必须用 read,然后这个 read 做一个跑腿的中间人去和指挥中心对接。
然后先知晓几个专业术语,以便于接下来深入抽插:页缓存(Page Cache):这是内核在内存(内核空间)中开辟的一块区域,专门用来临时存放从磁盘上读取的数据。目的是为了提高性能。
串联实际过程:你的 C++ 程序运行在用户空间。当它需要读取文件时,它不能自己去访问磁盘,必须通过
read()系统调用请求内核(运行在内核空间)帮忙。内核接收到请求后,会:
检查自己的缓冲区(页缓存,属于内核空间)。如果找到了(缓存命中),内核就直接从页缓存里把数据复制到你提供的用户空间的
buf里。这个过程很快,因为数据已经在内存里了。- 如果没找到(缓存未命中),内核就会发起一个磁盘 I/O 操作,真正去磁盘上把数据读取到内核的页缓存中。
然后,内核再把数据从内核空间复制到你的程序提供的用户空间内存(比如你的
buf数组)中。再继续梳理并深入:
内存分为:用户内存空间 & 内核内存空间
用户空间没有系统级缓存,缓存只在 kernel 空间(页缓存是核心)。
写个缓存数组是用户空间缓存
串联:
在read()系统调用的内核处理流程中,确实只涉及内核的页缓存,不直接涉及用户空间的缓存。让我来澄清一下这两者的关系:
内核的页缓存 (Page Cache):
位置: 内核空间。
管理: 由操作系统内核统一管理。
目的: 作为磁盘数据在内存中的高速缓存,避免频繁的磁盘 I/O,加速所有进程对文件的读取操作。
read()流程中如何工作: 当你调用read(),内核首先检查页缓存。如果数据在缓存里,就直接从缓存复制到你的用户缓冲区;如果不在,就去磁盘读,读完后先存入页缓存,再复制到你的用户缓冲区。用户的缓存 (比如你写的
my_buffer):
位置: 用户空间。
管理: 由你的应用程序自己管理。
目的: 为了你的应用程序自身的性能优化。
与
read()的关系: 它是read()调用的目的地,而不是read()流程的一部分。read()最终会把数据从内核空间(页缓存)复制到你指定的这个用户空间的缓存里。举一个完整的例子,把两者串起来:假设你的程序要读取一个很大的文件,并且需要多次访问其中的数据。在
read()系统调用中,必须提供一个用户空间的缓冲区(buf),否则内核不知道要把数据复制到哪里
场景一:不使用用户自己定义的长期存储的缓存
你的代码第一次调用
read(fd, buf, size)。内核检查页缓存,发现数据不在(缓存未命中)。内核发起磁盘 I/O,将数据读入页缓存。内核将数据从页缓存复制到你的buf(用户空间)。你的程序处理buf里的数据。过了一会儿,你的代码再次需要读取同一部分数据,于是再次调用read(fd, buf, size)。内核检查页缓存,发现数据已经在里面了(缓存命中)。内核直接将数据从页缓存复制到你的buf(用户空间)。 (这一步比第一次快得多,因为省去了磁盘 I/O)这里的
buf其实也是长期永久的用户缓冲,但我们把他叫做【用户空间的 I/O 缓冲区 (I/O Buffer)】因为你下次调用read他会被覆盖,所以有了场景二需要你及时处理,这个及时处理的地方就叫做【用户空间的缓存 (Cache)】
场景二:使用用户自己定义的长期存储缓存
你的代码声明了一个数组
char my_cache[1024];(这是额外的用户空间的缓存)。你的代码第一次调用read(fd, buf, size)后,又memcpy(my_cache, io_buf, 1024);,内部流程仍然是:内核检查页缓存 -> 读磁盘(如果需要) -> 填充页缓存 -> 复制到my_cache。现在,my_cache里已经有了文件的一部分数据。过了一会儿,你的程序需要访问这部分数据中的某一小段。你不需要再调用read()了。你直接在my_cache这个数组里查找和使用数据即可。
read()调用必须有一个 I/O 缓冲区(用户空间),用于接收数据。用户缓存是可选的,是你为了减少
read()调用次数、提高程序效率而额外设计的。提到 IO 缓存是泛指,可以指自己写的,也可以指标准库的缓存(只是程序员无法操作和感知这部分缓存)
然后还有个事,页缓存里没有从磁盘进货的时候,还有个磁盘缓存
关于谁快的问题:
内核空间的页缓存 (Page Cache):
速度: 非常快。因为它本身就是内存(RAM)的一部分。访问内存的速度是以纳秒(ns)为单位的。
为什么快: 因为数据已经在内存里了,CPU 可以直接通过内存地址访问,不需要涉及任何机械运动或慢速的外部设备。
磁盘 (Disk):
速度: 非常慢。相比内存,磁盘 I/O 的速度是以毫秒(ms)甚至秒(s)为单位的。
为什么慢: 传统硬盘(HDD)需要移动磁头和旋转磁盘来寻找和读取数据,这是物理运动,速度非常有限。即使是固态硬盘(SSD),虽然没有机械部件,但它的接口和内部控制器的速度也远低于内存。
核心结论:访问速度 内存 (页缓存) >> 磁盘
现在我们来解决你最困惑的问题:用户空间自己的缓存呢?比内核还快?
答案是:不,它不比内核的页缓存快,它们的访问速度是一样快的。
原因如下:
用户空间的缓存(比如你定义的
my_cache数组)和内核空间的页缓存(Page Cache)都位于同一个物理内存(RAM)中。CPU 访问内存的速度只取决于内存本身的硬件性能(如 DDR4, DDR5 等),而不取决于这块内存在逻辑上被划分给了用户空间还是内核空间。
那它们的区别是什么?
它们的区别在于管理方式和目的,而不在于物理访问速度。
管理方式:
内核的页缓存: 由操作系统内核统一、透明地管理。内核决定缓存哪些数据、缓存多大、以及什么时候把旧数据从缓存中淘汰出去(换出到磁盘)。
用户的缓存: 由你的应用程序代码完全控制。你决定缓存什么数据、缓存多久、以及如何组织这些数据。
目的:
内核的页缓存: 目的是减少磁盘 I/O。它对所有应用程序都有益。当你第一次读取一个文件时,数据从磁盘读到页缓存。当你(或其他程序)再次读取同一部分时,就可以直接从页缓存读取,避免了再次访问慢速的磁盘。
用户的缓存: 目的是减少系统调用和数据拷贝。当你已经把数据从内核的页缓存通过
read()系统调用复制到了你的用户空间缓冲区(buf)后,如果你还需要反复访问这些数据,你可以把它们存放在一个你自己管理的my_cache结构中。这样做的好处是,你不需要再一次次地调用read()(这涉及系统调用的开销),也不需要内核再一次次地把数据从页缓存复制到你的buf(这涉及内存拷贝的开销)。你可以直接在自己的my_cache里访问,虽然物理上还是访问内存,但省去了中间的许多步骤。总结速度对比:
最快: 访问你自己程序里的用户缓存 (
my_cache)。
因为:数据已经在你的程序地址空间里,CPU 可以直接访问,没有任何中间开销。
次快: 内核从页缓存复制数据到你的用户缓冲区 (
buf)。
因为:数据在内存里,但需要一次系统调用(
read())和一次内核态到用户态的数据拷贝。最慢: 内核从磁盘读取数据到页缓存,再复制到你的用户缓冲区。
因为:包含了最慢的磁盘 I/O 操作。
一个形象的比喻:
磁盘:是你家的仓库,很远,取东西要花很长时间(磁盘 I/O)。
内核的页缓存:是你家客厅的一个公共茶几。当你从仓库取来一样东西(第一次读文件),你先放在茶几上。下次再用这个东西(再次读同一部分),就不用跑仓库了,直接从茶几上拿,快多了。
用户的缓存:是你自己书房里的私人书桌。你从客厅的茶几上(页缓存)把东西拿过来(
read()),放在自己的书桌上(my_cache)。以后你在书房工作时,直接从自己的书桌上拿就好了,连去客厅的功夫都省了。所以,用户缓存并不比内核缓存 “快”,它只是让你在自己的 “地盘” 里取用数据更方便(省去了来回 “客厅” 的麻烦)。
感觉懂了些浅显的东西,但依旧有些混乱的东西,比如无论是否写长久用户那个cache,和是否内核写到页缓存有无关系?标准库的缓冲区又是咋回事?感觉还是有点朦胧:my_cache确实是用户空间的缓存,但它和标准库的缓冲区是两回事。
标准库的缓冲区:
是谁的:是 C/C++ 标准库(比如
stdio.h或<iostream>)内部创建和管理的。在哪里:在你的程序的用户空间内存里。
目的:为了减少系统调用
read()/write()的次数,从而提升 I/O 性能。你能看到吗:不能直接看到。它是标准库内部的一个数组或
char*指针。例子:当你使用
printf("hello")时,数据并不是立刻就通过系统调用写入终端,而是先被复制到stdout对应的标准库缓冲区里。当缓冲区满了或者你手动fflush(stdout)时,标准库才会调用write()系统调用,把缓冲区里的数据一次性写入内核。你自己写的
my_cache:
是谁的:是你(程序员)在你的代码里手动创建和管理的。
在哪里:也在你的程序的用户空间内存里。
目的:为了你自己程序的逻辑需求,比如重复访问某块数据,避免重复的计算或重复的
read()调用(以及随之而来的数据拷贝)。你能看到吗:当然能,它就是你定义的一个普通变量。
例子:你读取了一个配置文件到
my_cache数组里,然后你的程序在运行过程中需要多次访问配置里的某个值,你就可以直接从my_cache里读,而不需要再去文件里读了。总结一下:
标准库的缓冲区:是 “库” 帮你管理的,透明的,主要为了优化 I/O。
你自己的
my_cache:是 “你” 自己管理的,可见的,主要为了优化你自己的业务逻辑。它们都在用户空间,但一个是 “系统” 帮你弄的,一个是 “你自己” 弄的。
myfile是一个ifstream(输入文件流)对象,它已经通过open()或构造函数与某个实际文件关联,
ifstream的read()成员函数会返回myfile本身,你可以通过myfile.gcount()获取实际读取的字节数,或通过myfile.eof()/myfile.fail()判断是否读取失败 / 到达文件末尾。
myfile.read(buffer, 100)会从与myfile绑定的文件中读取最多 100 个字节,并存入你指定的buffer数组,这些我都懂,那【检查流的内部缓冲区:
ifstream对象不会立即调用read()系统调用。它会先检查自己的内部缓冲区(一块在用户空间分配的内存) 】这句话里的内部缓冲在哪里啊?我看不到是不是?完全内部的隐形的?对!这个 “内部缓冲区”是
ifstream对象内部的一块内存,是 C++ 标准库(iostream库)在你创建ifstream对象时(比如ifstream myfile("data.txt");)自动为你分配和管理的。它的特点就是:
对用户完全透明:你无法直接访问它,也看不到它的名字。它是
ifstream对象的一个私有成员变量。由标准库自动管理:当你调用
myfile.read()时,标准库内部的代码会决定是直接从这个内部缓冲区取数据,还是需要调用系统read()来填充它。目的是性能优化:如我们之前讨论的,它的存在是为了减少系统调用的次数。
假设
data.txt文件里有 1000 个字节。你写了如下代码:#include <fstream> #include <iostream> int main() { std::ifstream myfile("data.txt", std::ios::in); if (!myfile) { std::cerr << "Error opening file!" << std::endl; return 1; } char buffer[100]; // 第一次调用 read myfile.read(buffer, 100); std::cout << "First read: " << myfile.gcount() << " bytes read." << std::endl; // 第二次调用 read myfile.read(buffer, 100); std::cout << "Second read: " << myfile.gcount() << " bytes read." << std::endl; myfile.close(); return 0; }内部发生了什么?
std::ifstream myfile("data.txt");
系统创建了一个
ifstream对象myfile。作为创建过程的一部分,
myfile在用户空间里分配了一块内存作为它的内部缓冲区即标准库缓存(比如大小是 4096 字节)。你看不到这块内存,也不知道它的地址。
myfile.read(buffer, 100);(第一次调用)
myfile的内部代码检查自己的内部缓冲区。此时缓冲区是空的。因为缓冲区为空,
myfile会发起一次系统调用read(),从磁盘文件data.txt中读取一大块数据(比如 4096 字节),填充到自己的内部缓冲区。然后,
myfile从刚刚填满的内部缓冲区中,复制前 100 个字节到你提供的buffer数组中。现在,
myfile的内部缓冲区还剩 4096 - 100 = 3996 个字节的数据。
myfile.read(buffer, 100);(第二次调用)
myfile的内部代码再次检查自己的内部缓冲区。此时缓冲区里还有 3996 个字节的数据,足够满足你读取 100 个字节的需求。这次,它不会发起任何系统调用!
它直接从自己的内部缓冲区中,复制接下来的 100 个字节到你的
buffer数组中。现在,内部缓冲区还剩 3996 - 100 = 3896 个字节的数据。
起初我以为第二次要读的和第一次无关,但其实不是,
ifstream使用内部缓冲区时,它的策略是预读取,你的需求:读取 100 个字节。
ifstream的行为:它不会只去磁盘读取 100 个字节。为了效率,它会一次性读取一大块数据(比如 4096 字节)到它的内部缓冲区里。这个 “大块” 的大小通常是磁盘块的整数倍,或者是一个固定的优化值。因为磁盘 I/O 有固定开销(寻道、旋转、数据传输)。读取 100 字节和读取 4096 字节的固定开销几乎是一样的。所以,一次性多读一点,把后续可能用到的数据提前加载到内存里,可以极大地减少未来的磁盘 I/O 次数。第二次调用
read()时,只要你需要读取的字节数(比如 100 字节)小于或等于ifstream内部缓冲区中剩余的数据(比如 3996 字节),它就会直接从缓冲区复制数据给你,不会发起任何系统调用,也不会去访问磁盘。而超过 3996 字节,或者说缓存空了,就要去读了,这里具体咋理解?其实还有些细节:
缓存空了本质就是:根据当前文件偏移,要读取的数据不在缓存里,所以才需要从内核(标准库缓存)或磁盘(页缓存)读取,
第一次调用
read(fd, buf, 4096),会从文件的起始位置(偏移量 0)读取 4096 字节,然后文件指针自动移动到偏移量 4096 的位置。第二次调用
read(fd, buf, 4096),会从偏移量 4096 的位置开始读取下一个 4096 字节,然后文件指针移动到偏移量 8192 的位置。只有中间用
lseek(fd, 0, SEEK_SET);才是回到首位置读,但已经读过了呀,所以也就不需要再读内核突然思考王Y涵的腾讯天美游戏和 LinuxC++ 服务端开发 哪个难?
文件指针在哪,
read()就从哪开始读,是否读过数据,不比对,取决于 “当前指针位置 + 要读的字节范围” 之前是否被加载到页缓存。lseek这个函数,作用就是手动修改这个 “起始偏移” —— 它不读也不写文件,只改 “下一次操作的起点坐标”。结合4096就是读的跨度、范围然后我的问题是,如果读过了是不是就不进行系统调用了?豆包又引出了无穷无尽的知识点你妈逼的艹!
lseek只改文件指针,不读数据;要读数据仍需read系统调用,标准库会先查自身缓存,未命中才触发系统调用,由内核从页缓存或磁盘读取。
lseek移动的是内核的文件指针,不影响标准库缓存;fseek移动的是标准库的逻辑指针,并会清空标准库缓存使用
lseek系统调用查看代码
int fd = open("file.txt", O_RDONLY); // 打开文件,得到文件描述符 char buf[10]; read(fd, buf, 5); // 从偏移量0读取5个字节,内核偏移量变为5 lseek(fd, 0, SEEK_SET); // 【关键】将内核中的文件偏移量重置为0 read(fd, buf, 5); // 再次从偏移量0读取5个字节(会再次触发系统调用) close(fd);使用
fseek标准库函数查看代码
FILE *fp = fopen("file.txt", "r"); // 打开文件,得到 FILE 指针 char c; fgetc(fp); // 标准库会预读一块数据到缓存,比如4096字节 fseek(fp, 0, SEEK_SET); // 【关键】重置标准库的逻辑指针,并清空缓存 fgetc(fp); // 从标准库缓存中重新读取(可能会再次触发系统调用填充缓存) fclose(fp);标准库缓存就是像 C
stdio.h里fopen/fread/fwrite,C++ 的std::ifstream::read()这些函数自带的缓冲区,而内核的页缓存是read这种 Linux 的系统调用。
如果用
lseek+read:会触发系统调用。因为read是系统调用,它不经过标准库缓存,直接从内核的页缓存读,没有的话从磁盘读。lseek只是移动了内核的文件指针如果用
fseek+fread:不会触发系统调用(如果数据已在缓存中)。因为fread是标准库函数,它会先检查标准库的缓存。fseek会保证缓存中的数据是正确位置的
seek是 C 标准库中的函数,作用是:修改文件流(FILE*)的当前读写位置,并清空标准库缓存,确保后续fread/fgetc等操作从新位置开始读取(若新位置数据不在缓存,会触发系统调用加载数据到缓存)。
fseek必须搭配标准库的fread/fgetc,lseek必须搭配系统调用的read一句话说清绑定关系 + 核心差异:
fseek(标准库)→ 只能跟fread(标准库,走标准库缓存),会清缓存;lseek(内核)→ 只能跟read(系统调用,不走标准库缓存),不清缓存;俩函数没法用同一个 “read”,因为归属不同层级!验证(狗逼豆包他妈的给的是半成品代码,确实只是个助手,需要我修改,妈逼的自己不动脑修改,问他让他找毛病,就会给你胡扯说不到点上,能气死你)
想验证
fseek会清理缓冲,结果stdin验证出问题了:查看代码
#include <stdio.h> #include <stdlib.h> int main() { char c1, c2; // 测试1:不使用 fseek,观察输入缓冲区残留 printf("=== 测试1:不清理输入缓冲 ===\n"); printf("请输入一个字符:"); scanf("%c", &c1); // 读取1个字符(比如输入 'a' 后按回车,缓冲区残留 '\n') printf("你输入的字符是:#%c#\n", c1); // 尝试读取下一个字符(会直接读取缓冲区残留的 '\n',无需手动输入) printf("尝试读取下一个字符无需输入:"); scanf("%c", &c2); printf("读取到的是#%c#\n", c2); int fseek_ret; fseek_ret = fseek(stdin, 0, SEEK_END); if (fseek_ret == 0) printf("fseek执行成功!\n"); else printf("fseek执行失败!(返回值:%d)\n", fseek_ret); // 测试2:使用 fseek 清空输入缓冲 printf("=== 测试2:用 fseek 清理输入缓冲 ===\n"); printf("请输入一个字符:"); scanf("%c", &c1); // 输入 'b' 后按回车,缓冲区残留 '\n' printf("你输入的字符是:#%c#\n", c1); // 关键:用 fseek 清空 stdin 输入缓冲(SEEK_CUR, 0 表示“当前位置不变”,仅触发缓冲清理) fseek_ret = fseek(stdin, 0, SEEK_CUR); if (fseek_ret == 0) printf("fseek执行成功!\n"); else printf("fseek执行失败!(返回值:%d)\n", fseek_ret); // 再次尝试读取下一个字符(此时缓冲区已清空,必须手动输入) printf("尝试读取下一个字符(需要手动输入):"); scanf("%c", &c2); printf("你输入的第二个字符是:#%c#\n", c2); } Linux的输出: === 测试1:不清理输入缓冲 === 请输入一个字符:abc 你输入的字符是:#a# 尝试读取下一个字符无需输入:读取到的是#b# fseek执行失败!(返回值:-1) === 测试2:用 fseek 清理输入缓冲 === 请输入一个字符:你输入的字符是:#c# fseek执行失败!(返回值:-1) 尝试读取下一个字符(需要手动输入):你输入的第二个字符是:# # 描述下:当我输入abc回车后,直接结束了 win 的 codeblock: === 测试1:不清理输入缓冲 === 请输入一个字符:abc 你输入的字符是:#a# 尝试读取下一个字符无需输入:读取到的是#b# fseek执行失败!(返回值:-1) === 测试2:用 fseek 清理输入缓冲 === 请输入一个字符:y 你输入的字符是:#y# fseek执行成功! 尝试读取下一个字符(需要手动输入):o 你输入的第二个字符是:#o# 描述下:我输入abc回车后,测试1结束,测试2需要我输入y,和oWindows 下:
这个失败的
fseek后,测试 2 的 c1 能手动输入,是因为 Windows 标准库有fseek 对 stdin 失败后重置缓冲读取状态的隐性处理,在测试 1 后、测试 2 前加一句printf("残留字符:%c", getchar());,就会卡那,等我输入,Windows 标准库在处理这个 “失败请求” 时,隐性清空了缓冲里的 'c'+'\n'(这是 Windows 独有的兼容行为,不管返回成功还是失败,这个 SEEK_END 操作会清缓冲);而且这说的清缓冲指的是:注意比如输入ab回车,终端行缓冲无论系统都是先存入终端缓冲,然后回车后就传给标准库缓冲,那么读了a,b剩下的回车就在标准库缓冲里,清的就是这个。也就是说这里win的实际返回
fseek(stdin, 0, SEEK_END)和fseek(stdin, 0, SEEK_CUR)都能清缓冲(所以后续输入会等你手动输),区别只在于返回值(SEEK_END 返 -1 失败,SEEK_CUR 返 0 成功);返回失败的会连带额隐形清下Linux 下:
没有这个隐性处理,测试 2 的 c1 直接读了残留,严格遵循 POSIX 标准和 C 标准,将键盘(stdin 对应的 IO 设备)定义为「不可定位的流式字符设备」,直接禁止 fseek 对这类设备执行任何操作
「不可定位」意味着 fseek 失去作用基础 ——fseek 的核心是 “移动读写位置”,但键盘输入是 “实时流式数据”(敲一个传一个,一直往下读,没有固定的字节地址,没法 “回到上一个字符”“跳到末尾”,不能跳也不能倒),Linux 内核和标准库直接拒绝给这种设备提供 “定位” 能力,自然也不会执行 fseek 附带的任何操作(比如清缓冲);
简单说:Linux 认为 “键盘输入就该是单向流式的,不能定位、不能回退”,所以从底层禁止了 fseek 对 stdin 的所有操作,自然清不了缓冲;而 Windows 是为了兼容,给
fseek(stdin, 0, SEEK_CUR)开了 “特例”,让它能清标准库缓冲 —— 本质是两个系统对 “键盘 IO 设备的功能定义” 不一样,Linux 坚守标准,Windows 做了兼容妥协。可是代码摆在这,我写博客删对话,把写完的给豆包让找错误,直到现在豆包还在反复的否定、反悔,无尽痛苦,真都不想研究这里了!
那么以上是踩的粪坑沼泽地,文件 IO 的缓存逻辑磁盘文件是 “可定位的块设备”(有固定字节地址,能跳着读 / 写),fseek/lseek 的设计初衷就是给这类设备用的,缓存逻辑(标准库缓存→内核页缓存→磁盘)也完全适配;而 stdin(键盘)是「不可定位的流式字符设备」(数据实时输入,没有固定地址,只能单向读),
强迫症纠结到这,该怎么收尾?不用觉得 “白研究”:你其实搞懂了两个关键知识点:
① 设备类型(可定位 / 不可定位)决定工具用法(fseek 能不能用);
② 系统兼容差异(Linux 守标准 / Windows 重兼容)对错误用法的影响;后续记住:清 stdin 缓存(处理输入残留),可以用 win 下 codeblock(w64devkit)亲测有效的
fflush(stdin)即全部清空,但 C 里没有这个,这是编译器扩展,w64devkits 虽说属 GCC 阵营但 GCC 原生没有fflush,即 Linux里用不好使,大厂都是循环
getchar()读残留(C 标准库函数,跨平台适配:本质是调用fgetc (stdin))只要是「文件流」(包括 stdin、磁盘文件、管道等)都能用,跨平台也靠谱!
C 语言(还有 Unix/Linux 等系统的设计思路)里:键盘(stdin)、屏幕(stdout)、打印机这些设备,本质上都被 “当作文件流” 来处理,不是说它们是 “磁盘上的文件”,而是系统把所有 “输入输出源” 都统一成了 “文件流” 的接口,这样代码写起来更通用
你以为的 “文件”:是磁盘上的物理文件(比如
test.txt),打开后得到FILE* fp,这是 “文件流”;其实的 “文件流”:
stdin:键盘对应的 “输入文件流”(系统默认打开,不用你写
fopen()),所以能直接用fgetc(stdin)(也就是getchar())读;stdout:屏幕对应的 “输出文件流”(系统默认打开),所以能直接用
fprintf(stdout, "xxx")(也就是printf("xxx"))写;好处:比如你写个函数
read_data(FILE* stream),既能传磁盘文件的fp读文件内容,也能传stdin读键盘输入 —— 代码不用改,通用性拉满!③fseek 是给文件用的,别用在键盘输入上,这才是对应场景的正确工具!
那么其实 stdin 的缓存是「终端行缓存」(敲回车才传给标准库缓存),这是 IO 缓存的一种场景;而大多数说的IO缓存是磁盘(标准库→页缓存→磁盘)
那些 C/C++ 都是用上层封装,额外加用户层的标准库缓存,底层仍依赖系统调用 + 内核页缓存!
Linux 纯 read 系统调用有内核层的页缓存,没有的是 C 标准库的用户层缓存
数据不在标准库缓存 → 触发系统调用从内核页缓存拿 → 页缓存也没有 → 内核从磁盘读数据填充页缓存,再逐级往上传
先呼应之前的关联:stdin 是指向 “键盘对应的 FILE 结构体” 的指针,键盘输入的字符(包括回车 '\n')会存在这个 FILE 结构体的 “输入缓冲” 里;
为什么 Linux 下 fseek 没用?
- FILE 结构体的功能是 “管理 IO 对象”,但不同 IO 对象(键盘 / 文件)支持的操作不一样:
- 如果你操作的是 “文件”(比如用 fopen 打开的文件),它的 FILE 结构体支持 fseek(移动读写位置、清理缓冲);
- 但 Linux 里的 “键盘” 是 “字符设备”,它的 FILE 结构体不支持 fseek—— 标准库没给这个 IO 对象(键盘)实现 fseek 的功能,所以你调用了也没用,输入缓冲里的 '\n' 还在;
fseek 是给 “文件” 这种 IO 对象设计的,“键盘”(stdin)在 Linux 下不支持这个操作,所以清不了缓冲。
总结:核心还是 “IO 对象决定 FILE 结构体支持的操作”—— 键盘这个 IO 对象,在 Linux 里不让 fseek 干活,所以代码里的 fseek 等于白写。
Windows下没问题,Linux下必须改用while ((getchar()) != '\n');否则输入ab+ 回车后,测试 1 的c1读a、c2读b,回车还留在缓冲里,测试 2 的c1根本不用重新输入;而
Windows中fseek(stdin, 0, SEEK_END)能真正清空缓冲,测试 2 会正常等你输入。行缓冲是终端输入时的核心机制:先暂存你敲的所有字符,按回车才把整行数据传给程序
Linux敲ab+ 回车后,整行字符先存在终端「行缓冲」,按回车才把这堆字符传给程序的「标准库缓冲」,fseek只清标准库缓冲、清不掉终端行缓冲的残留。
Windows终端也有行缓冲(你敲的字符仍需按回车才提交),但Windows把 “终端行缓冲” 和 “程序标准库缓冲” 做了关联 —— 用fseek清标准库缓冲时,会顺带清空终端的行缓冲
fseek是C标准库函数(C/C++通用),lseek是Linux/Unix专属的系统调用(不属于C标准,Windows要用_lseek替代)。
C只规定了fseek对文件的操作行为,完全没规定它对stdin(终端输入)的缓冲清理行为,这种跨平台差异,是因为不同系统对终端输入的缓冲管理逻辑不同,不是C的问题
while ((getchar()) != '\n');的逻辑特别简单:一直读缓冲里的字符,直到读到回车为止;只要读到回车,缓冲就被清空了,同时退出循环。
行缓冲(终端层面)→标准库缓冲(C 标准库层面)→页缓存(操作系统内核层面),是数据从键盘到程序的三层 “临时仓库”,各管一段、互不相关!具体拆重点:
行缓冲:终端(比如 Linux 的 bash)管的,只针对键盘输入 / 屏幕输出,特点是 “按回车才提交整行数据”,
fseek碰不到;标准库缓冲:C 标准库(
stdio.h)管的,是程序和内核之间的缓冲(比如printf/scanf用的),fseek只能清这个;页缓存:操作系统内核管的,是内核和硬盘之间的缓冲(比如读文件时先存硬盘数据到内存),和终端输入、
fseek完全没关系!简单说:你敲
ab+ 回车,先过「行缓冲」(终端暂存)→ 按回车传给「标准库缓冲」(程序暂存)→ 程序从这读数据;而「页缓存」是管文件读写的,和键盘输入根本不搭边总结:
你提供的
buffer:是你自己的内存,用于接收数据,你可以随意访问。
ifstream的内部缓冲区:是ifstream对象私有的、隐藏的内存,用于临时存放从文件读取的大量数据,以减少系统调用。它在幕后工作,你不需要也无法直接操作它。但上面写的没有写页缓存的事!现在再把这个加进来:
页缓存它工作在一个更低的、你看不见的层级。上面写的【内部发生了什么】要聚焦于应用程序层面(用户态)发生的事情。而页缓存的工作则发生在操作系统内核层面(内核态)。这两个缓存是协同工作的,共同构成了文件 I/O 的性能优化体系,那就不完整,从应用程序发起读取请求,到最终从磁盘获取数据,
第一层:应用程序层
std::ifstream的工作这正是你描述的过程:
myfile对象检查自己的内部缓冲区(一个位于用户态内存的、大小为 4096 字节的缓冲区)。发现缓冲区是空的。
myfile对象需要填充这个缓冲区,于是它向下层(操作系统内核)发起一个读取请求,这个请求最终会转化为一个系统调用,比如read()。到这里,应用程序的工作就暂时告一段落了,它把接力棒交给了操作系统内核。
第二层:操作系统内核层 (Kernel Space) - 页缓存 (Page Cache) 的工作
当内核收到
read()系统调用后,它会做以下事情:
检查页缓存 (Page Cache):
内核会首先检查自己管理的页缓存。页缓存是内核在内存中为所有打开的文件内容开辟的一块高速缓存区域。它缓存的是文件的 “页”(通常是 4KB 大小)。
内核会询问:“我有没有缓存
data.txt中,从文件起始位置开始的这 4096 字节的数据?”情况 A:页缓存未命中 (Cache Miss):
如果这是程序第一次读取这个文件,或者内核因为内存不足等原因已经把
data.txt的这部分内容从页缓存中淘汰了,那么内核的回答就是:“没有。”这时,真正的磁盘 I/O 发生了。 内核会向磁盘控制器发送指令,要求从
data.txt文件在磁盘上的物理位置读取相应的扇区数据。磁盘控制器将数据从磁盘读取到内存的内核地址空间中,具体来说,就是填充到页缓存的某个页面中。
现在,
data.txt的这 4096 字节数据就已经存在于页缓存中了。情况 B:页缓存命中 (Cache Hit):
如果内核之前已经读取过
data.txt的这部分内容,并且它还在页缓存里,那么内核的回答就是:“有!”这时,不会发生任何磁盘 I/O。
数据拷贝:
无论数据是刚刚从磁盘读到页缓存的(情况 A),还是早就已经在页缓存里了(情况 B),数据现在都已经在内核的页缓存中了。
接下来,内核会从页缓存中,把这 4096 字节的数据拷贝到
myfile对象在用户态申请的那个 4096 字节的内部缓冲区里。到这里,内核的工作完成,它把接力棒交还给应用程序。
第一层:应用程序层 (User Space) -
std::ifstream继续工作
myfile对象的内部缓冲区(位于用户态)现在已经被 4096 字节的数据填满了。
myfile对象从这个内部缓冲区中,复制前 100 个字节到你提供的buffer数组中。
myfile对象更新自己的状态,记录下内部缓冲区中还有 3996 字节的数据未被读取,并记住下一次应该从哪个位置开始读取。两次
read调用的完整图景
调用 标准库缓存 (应用层) 页缓存 (内核层) 磁盘 I/O 第一次 read(100)1. 检查内部缓冲区(空)。 2. 发起系统调用read(4096)填充它。3. 从填满的内部缓冲区复制 100 字节到用户buffer。1. 检查页缓存(无)。 2. 发起磁盘 I/O,将数据读入页缓存。3. 从页缓存复制 4096 字节到应用程序的内部缓冲区。发生 第二次 read(100)1. 检查内部缓冲区(有 3996 字节)。 2. 无需系统调用。3. 直接从内部缓冲区复制下一个 100 字节到用户buffer。完全不参与,因为数据已经在应用程序的缓存里了。 不发生 核心区别与联系
特性 标准库缓存 ( std::ifstreambuffer)页缓存 (Page Cache)
所有者 应用程序 / C++ 标准库 操作系统内核
作用域 仅对当前 std::ifstream对象可见对整个操作系统的所有进程可见(共享)
主要目的 减少系统调用的次数 减少磁盘 I/O 的次数
管理方式 由 std::ifstream对象自动管理由操作系统内核的内存管理和文件系统模块统一、智能地管理(包括缓存淘汰、预读等)
简单来说,它们是 “合作伙伴” 关系:
std::ifstream的内部缓存,通过一次读取一大块数据(4096 字节),来减少昂贵的系统调用次数。而操作系统的页缓存,则通过缓存磁盘文件的数据,来减少更昂贵的磁盘寻道和读取次数。当
std::ifstream向下请求 4096 字节时,内核会先看自己的页缓存里有没有,如果没有才会去麻烦磁盘。所以,你代码描述中的read()系统调用,它读取的 “一大块数据”,绝大多数情况下是从内存(页缓存)中读取的,而不是直接从磁盘读取的。你的提问非常棒,这表明你已经开始深入思考 I/O 背后的原理了。理解了这两层缓存,你对文件操作的性能优化就会有更深刻的认识。
1. 为什么系统调用昂贵珍贵宝贵?(便于回顾需要看这里的时候好搜索)
系统调用的成本主要在于 “上下文切换”(Context Switch)。
核心原因: 用户程序和操作系统内核运行在不同的 “特权级别”。用户程序不能直接访问硬件或内核内存,必须通过系统调用请求内核代劳。
切换过程:
CPU 从执行用户程序的指令,切换到执行内核代码。
保存当前用户程序的执行状态(寄存器、程序计数器等)。
加载内核的执行状态。
内核执行相应操作(比如读取文件)。
操作完成后,再切换回用户程序状态,恢复之前保存的寄存器和计数器。
开销所在: 这个切换过程涉及到 CPU 状态的保存和恢复、内存地址空间的切换,是一个复杂的硬件和软件协同操作,需要消耗大量 CPU 时钟周期。
系统调用贵就贵在 “用户态” 和 “内核态” 之间来回切换的开销。
2. 为什么磁盘 I/O 昂贵?
磁盘 I/O 的成本主要在于 “物理设备的机械运动”。
核心原因: 传统机械硬盘(HDD)的读写依赖于磁头在高速旋转的盘片上寻道。
操作过程:
寻道时间(Seek Time): 移动磁头臂到数据所在的磁道。这是最耗时的一步,通常需要几个毫秒(ms)。
旋转延迟(Rotational Latency): 等待盘片旋转,使目标扇区移动到磁头下方。这也需要几个毫秒。
数据传输时间(Transfer Time): 实际读取或写入数据。这一步相对较快。
开销对比:
一次内存访问的时间大约是 几纳秒(ns)。
一次磁盘 I/O 的时间大约是 几毫秒(ms)。
一毫秒等于一百万纳秒。也就是说,一次磁盘 I/O 的时间,CPU 可以执行上百万条指令。
磁盘 I/O 贵就贵在磁头寻道和盘片旋转的物理等待时间,这比电子信号在内存中的传输慢了上百万倍。
两者的关系
页缓存的目的,就是为了避免频繁的磁盘 I/O。用内存的高速访问,替代磁盘的慢速访问。
标准库缓存的目的,就是为了避免频繁的系统调用。用用户态内存的访问,替代需要上下文切换的内核调用。
所以,整个 I/O 流程的优化目标就是:尽量用最快的内存访问,来替代较慢的系统调用和最慢的磁盘 I/O。
页缓存:内核用的,一次多拿点磁盘数据放内存,减少「磁盘 I/O 次数」;
标准库缓存:应用 / 标准库用的,一次多从内核拿点数据放用户态内存,减少「系统调用次数」
C++ 中大部分高层读取函数(比如
std::ifstream的read()、get()、operator>>等),底层最终都会通过系统调用read()(Windows 上是ReadFile())来读取文件数据。它们的关系是:C++ 标准库函数 → C 标准库函数(如
fread)→ 系统调用(read)→ 内核(页缓存)→ 磁盘。标准库缓存 (Standard Library Cache)
read语句里用户每次读一个,那就老鼻子慢了,所以read标准库缓存比如 4096 就一下子从内核读了 4096,然后后续每次调用(这里的 “调用” 指的是你对标准库函数的调用,比如fgetc()或fread())都直接从内核给用户返回标准库缓存是应用程序(用户态)和内核(内核态)之间的一道缓冲。当标准库的缓存为空时,它会一次性调用
read()系统调用,从内核(内核可能从页缓存或磁盘读取)读取一大块数据(比如 4096 字节),存入自己的缓存中。工作流程:你调用
fgetc()(想读一个字符)。标准库检查自己的缓存。如果缓存里有数据,它直接从自己的缓存里取一个字符返回给你,不会调用read()系统调用。如果缓存空了,它才会调用read()系统调用,从内核读取一大块数据(比如 4096 字节)填满自己的缓存,然后再从缓存里取一个字符返回给你。核心目的: 减少系统调用的次数。因为系统调用(用户态切换到内核态)有开销,一次性多读点,存起来,后续的小读取就可以直接在用户态内存里完成,速度快得多。
页缓存 (Page Cache)
页缓存是内核用来缓存从磁盘读取的数据的地方。当内核收到一个
read()系统调用时,它会先检查页缓存:
如果数据在页缓存里,内核就直接从页缓存复制数据给标准库的缓存,不需要访问磁盘。
如果数据不在页缓存里,内核才会去磁盘读取数据,读取后先存入页缓存,然后再从页缓存复制给标准库的缓存。
内核与磁盘交互时,不是按字节,而是按页(Page)来读取的。一页的大小通常是 4KB。即使你只需要 1 个字节,内核也会把包含这 1 个字节的整个 4KB 数据块从磁盘读到页缓存里。
核心目的: 减少磁盘 I/O 的次数。因为磁盘 I/O(寻道、旋转、数据传输)的开销极大,比内存访问慢上几个数量级。把读过的数据暂时存在内存(页缓存)里,下次再读同一部分数据时,就可以直接从内存读取,速度极快。
总结一下整个流程(以
fgetc()为例)假设一个文件内容是 "ABCDEFG...",且所有缓存都是空的:
你调用
fgetc():
标准库缓存为空。
标准库就会调用
read(fd, stdio_buffer, 4096)系统调用。否则直接从缓存拿数据。内核处理
read()系统调用:
内核检查页缓存,发现数据不在。
内核向磁盘发出指令,读取包含文件开头的一个或多个数据块(比如 4KB)。
磁盘将数据块返回给内核。
内核将这些数据块存入页缓存。
内核从页缓存中复制请求的数据(这里是 4096 字节)到标准库的缓存 (
stdio_buffer)。标准库处理:
标准库的缓存 (
stdio_buffer) 现在有了 "ABCDEFG...(共 4096 字节)"。标准库从自己的缓存里取出第一个字符 'A' 返回给你。
你再次调用
fgetc():
标准库检查自己的缓存,里面还有 "BCDEFG..."。
直接从缓存里取出 'B' 返回给你。
没有调用任何系统调用,也没有访问磁盘。一句话概括:
标准库缓存:应用程序的 “小仓库”,避免频繁向内核 “要货”(减少系统调用)。
页缓存:内核的 “大仓库”,避免频繁向磁盘 “进货”(减少磁盘 I/O)。
Linux 的
read是系统调用,在<unistd.h>里,直接内核交互,无缓冲,返回字节数 / 0(EOF)/-1(错误)。
read()是系统调用:它是用户程序进入内核态,请求内核从文件(或其他文件描述符对应的对象)中读取数据的接口。内核缓冲区:Linux 内核为了提高 I/O 效率,会维护一个页缓存(Page Cache),这是一种内核级别的缓冲区。当你调用
read()时,内核会先检查数据是否已在页缓存中。如果在,就直接从缓存复制到你提供的用户态缓冲区(buffer参数指向的内存);如果不在,内核才会发起真正的磁盘 I/O 操作,将数据读入页缓存,然后再复制到你的用户态缓冲区。用户态缓冲区:
read()函数的buffer参数是一个指针,指向你在用户程序中分配的一块内存。这块内存是用户态的,用于接收从内核复制过来的数据。总结:
read()本身不是无缓冲的。它依赖于内核的页缓存来提升性能。人们通常说的 "无缓冲 I/O" 是指不使用标准库的缓冲区(比如 C 语言中
printf使用的stdout缓冲区)。read()作为系统调用,它绕过了标准库的缓冲机制,直接与内核交互。但它并没有绕过内核自身的缓冲机制。最后读的数据依旧要写到用户指定的用户态缓存比如buf里C 的 fread 是标准库函数:这个此文上下有说不再啰嗦了
C++
ios的read()标准库函数:istream成员函数,<iostream>,带缓冲,返回流对象,失败时fail()为true。这个主要是C++的标准库函数,底层是共享 C 标准库的用户态缓冲机制,而 C 的 fread 又是调用系统级的 read,只不过 C++ 的这个比 C 的多了些自动关闭文件啥的,打开读写文件功能都一样:
读取源头:先从「标准库缓冲区(用户态)」读取;若缓存中没有,标准库会调用 Linux 的
read()系统调用,从内核缓存(或磁盘)读取数据到标准库缓存,再返回给用户。- 核心点:经过标准库缓冲,减少系统调用次数。
ifstream::read()的两个参数:第一个是目标缓冲区指针(如char buf[]),用于存储读取到的数据;第二个是要读取的字节数(如1024),表示希望从文件中读取的字节长度。
fread:C 标准库,<cstdio>,按块读取,带缓冲,返回成功读取的块数。自动
close:C++ 流对象(如ifstream/ofstream)析构时自动调用close(),无需手动操作。“带不带缓冲” 核心是:数据传输 / 处理时是否先存入临时缓存区(而非直接实时交互),带缓冲 = 先存后处理(提升效率、减少 IO),不带 = 实时读写(低延迟、数据即时同步)
ifstream:
从
ios继承的基础方法(所有流通用):
状态相关:
clear()、good()、fail()、eof()等(管理状态标志)。模式 / 打开关闭:
open()、close()、is_open()等(控制文件打开关闭)。从
istream继承的 “读专用” 方法(输入流特有):
读取操作:
>>运算符(格式化读)、read()(二进制读)、getline()(按行读,严格说是全局函数但依赖istream)。指针移动:
seekg()(移动读指针,g对应 get)、tellg()(获取当前读指针位置)。辅助:
gcount()(获取最后一次读的字节数)。
ifstream自身不新增方法,它的核心作用是 “将istream的读功能绑定到文件”,所有读写相关的逻辑都来自父类istream和ios。三大主要功能之三:写文件(3 种常用方式)
查看代码
#include <fstream> // 包含文件流操作所需类 #include <iostream> // 用于控制台输出(验证用) #include <cstring> // 用于字符串操作(给结构体赋值) using namespace std; // 定义示例结构体(二进制写入用) struct User { int id; // 整数类型(4字节) char name[20]; // 固定长度字符数组(20字节,避免指针问题) }; int main() { // -------------------------- // 方式1:按文本格式写入(自动处理格式) // -------------------------- ofstream fout_text("text_output.txt"); // 默认模式:ios::out | ios::trunc(创建+清空) if (!fout_text.is_open()) { cerr << "打开文本文件失败!" << endl; return -1; } // 类似cout的写法,自动处理换行和空格 fout_text << "写入一行文本" << endl; // 写入字符串并换行 fout_text << 123 << " " << 456 << endl; // 写入数字+空格,再换行 fout_text.close(); // 关闭文件 // -------------------------- // 方式2:写入二进制数据(结构体示例) // -------------------------- // 打开二进制文件,必须加ios::binary模式 ofstream fout_bin("binary_output.bin", ios::binary); if (!fout_bin.is_open()) { cerr << "打开二进制文件失败!" << endl; return -1; } // 初始化结构体 User u; u.id = 1001; strcpy(u.name, "zhangsan"); // 给字符数组赋值(注意长度不超过20) // 按字节写入整个结构体(共24字节:4+20) fout_bin.write((char*)&u, sizeof(u)); // (char*)&u:将结构体地址转为字节指针 fout_bin.close(); // 读取刚才写入的二进制文件 ifstream fin_bin("binary_output.bin", ios::binary); if (fin_bin.is_open()) { User read_u; fin_bin.read((char*)&read_u, sizeof(read_u)); cout << "读取到的id:" << read_u.id << endl; // 输出 1001 cout << "读取到的name:" << read_u.name << endl; // 输出 zhangsan fin_bin.close(); } // -------------------------- // 方式3:追加模式写入(日志场景常用) // -------------------------- // 打开文件时指定ios::app模式(追加) ofstream fout_app("log.txt", ios::out | ios::app); if (!fout_app.is_open()) { cerr << "打开日志文件失败!" << endl; return -1; } // 每次写入都会追加到文件末尾,不会覆盖原有内容 fout_app << "这是一条日志:程序启动" << endl; fout_app << "这是一条日志:处理完成" << endl; fout_app.close(); cout << "三种写入方式均执行完成,请查看生成的文件。" << endl; }
解释代码(还是挺好理解的):
cout是ostream类的实例,且是标准输出流的全局对象,定义在<iostream>头文件中,用于向标准输出设备(通常是屏幕)输出数据。核心区别:功能相似(都能写数据),但操作对象不同。
cout是ostream的实例,专门向标准输出设备(屏幕) 写数据;
ofstream的实例(如fout)是ostream的子类实例,专门向文件写数据。两者都继承了
ostream的写操作能力(比如都能用<<运算符),但操作的目标不同 —— 一个输出到屏幕,一个输出到文件,这是最核心的区别。
ofstream手动传模式时,ios::out会被强制包含,所以写ios::binary等价于ios::out | ios::binary,两种写法都对。
ifstream默认自带ios::in,即使不写,打开时也会强制包含in模式(必须文件存在才能读),所以直接写ifstream fin("file.txt")即可,无需显式加ios::in。
fout_bin.write((char*)&u, sizeof(u))是将结构体u的内存字节原样写入文件,拆解理解:
&u:取结构体变量u的内存地址(起始地址);
(char*)&u:将地址强制转为char*类型(按单个字节访问内存,确保能逐个字节读写);
sizeof(u):计算结构体u占用的总字节数(比如User结构体是 24 字节);整体:从
u的起始地址开始,读取sizeof(u)个字节,原样写入fout_bin关联的文件中。作用:二进制保存数据(保留内存原始布局),适合存储结构化数据(如协议包、结构体)
.bin只是文件后缀名(约定俗成的标识),不代表文件内容一定是二进制。
后缀
.bin通常用来标记 “二进制格式文件”(比如结构体数据、固件、二进制协议数据),方便人识别这不是文本文件。但本质上,文件内容是否为二进制,取决于写入时是否用
ios::binary模式且按原始字节存储,和后缀无关。哪怕后缀是.txt,只要用二进制模式写入非文本数据,它就是二进制文件(记事本打开乱码)。但我实践发现无论哪种都提示【此文件是二进制文件或使用了不受支持的文本编码,所以无法在文本编辑器中显示】简单说:
.bin是 “二进制文件” 的常用标签,但不是绝对标准,关键看内容和写入方式。关于那段“读取刚才写入的二进制文件”:
打开二进制文件
ifstream fin_bin("binary_output.bin", ios::binary);
用
ifstream打开文件binary_output.bin,指定ios::binary模式(二进制读取,保证字节不被转换)。因为
ifstream默认带ios::in(读模式),所以无需额外写,但必须确保文件存在。检查文件是否打开成功
if (fin_bin.is_open()) { ... }
这是必要的判断,避免文件不存在找到或权限问题导致的后续操作崩溃。
读取二进制数据到结构体
fin_bin.read((char*)&read_u, sizeof(read_u));
read()是二进制读取函数,第一个参数是 “接收数据的内存地址”(强制转char*是因为函数要求字节指针),第二个参数是 “要读取的字节数”(sizeof(read_u)即结构体总大小,比如前面的User是 24 字节)。作用:从文件中读取和结构体大小完全一致的字节,直接 “填” 到
read_u的内存里,还原出写入时的id和name。输出读取结果
read_u.id和read_u.name能直接正确输出,因为二进制读取完整还原了写入时的内存结构,没有丢失或转换任何字节。
read()函数本身是二进制读取操作,它的作用是从流中读取指定数量的原始字节,不做任何编码转换或格式解析(比如不会把字节转成字符、数字等),读取的就是内存中最原始的二进制数据。无论流是否打开了
ios::binary模式,read()都是按字节读取,但区别在于:
带
ios::binary时:字节完全原样读取,不处理换行符(比如 Windows 下的\r\n不会被转换为\n)。不带
ios::binary时(文本模式):系统可能会自动转换某些特殊字节(如换行符),导致读取的字节数和实际存储的不一致。因此,用
read()时几乎都要配合ios::binary模式,才能保证读取的字节和写入的完全一致(尤其是结构化数据、二进制文件)。Linux 系统调用
read()(不是 C++ 的read()成员函数)本质上也是二进制读取—— 它直接从文件描述符对应的文件中读取指定数量的原始字节(字节流),不做任何编码或格式转换,读取的是文件在磁盘上存储的原始二进制数据,比如用read(fd, buffer, n)时,buffer里得到的就是文件中连续的n个字节(无论这些字节是文本、图片还是结构体),和数据的具体格式无关。这一点和 C++ 中ifstream::read()配合ios::binary模式的行为一致:都是 “按字节原样搬运”,不解析内容,只处理原始二进制数据。不乱码本质是数据字节符合文本编码(如 ASCII)的可打印规则。
二进制写入(
ios::binary)的核心是按内存原始字节直接存储,不做任何编码转换(包括不转 ASCII),这些字节是给计算机程序读取的(比如后续用代码解析结构体)。
ios::binary模式的典型场景:
存储结构化数据(如结构体、协议包);
存储非文本文件(图片、音频、视频);
需要精确保留数据原始字节(比如加密数据、二进制协议)。
二进制写入的内容无论输出到什么后缀的文件(.txt、.bin 等),用记事本打开大概率乱码—— 因为记事本强制按文本编码(ASCII/UTF-8 等)解析字节,而二进制数据中包含大量不可打印的字节(如整数、浮点数的原始字节),自然显示乱码。
不是 “只能输出到二进制文件”,而是二进制数据本身不适合用文本编辑器查看,后缀名只是标识,关键是数据格式。即使后缀是
.txt,二进制内容用记事本打开还是乱码,必须用代码按原始结构(如结构体)读取才能正确解析。
二进制模式:原样读写字节,适合非文本数据(如结构体),无转换,不乱码。
文本模式:自动转换换行符、误判符,适合纯字符,非文本数据用会乱码。
所以读二进制写入的内容必须用 binary 模式。
三大主要功能之外的实战场景,大厂面试 / 工作常遇到的几个东西:
定位读写位置(随机访问,服务端处理大文件常用)
查看代码
#include <fstream> #include <iostream> #include <string> using namespace std; int main() { // 1. 准备一个测试文件,先写入初始内容 ofstream finit("data.txt"); finit << "abcdefghij"; // 写入10个字符:a b c d e f g h i j(索引0-9) finit.close(); // 2. 用读写模式打开文件(ios::in | ios::out) fstream fs("data.txt", ios::in | ios::out); if (!fs.is_open()) { cout << "文件打开失败!" << endl; return -1; } // 3. 移动写指针到第5个字节(索引4),写入'x' fs.seekp(4, ios::beg); // 从开头偏移4字节(指向第5个字符'e') fs << "x"; // 覆盖'e'为'x',此时文件内容变为:a b c d x f g h i j // 4. 移动读指针到第3个字节(索引2),读取字符 fs.seekg(2, ios::beg); // 从开头偏移2字节(指向第3个字符'c') char c; fs >> c; // 读取'c' // 5. 输出结果 cout << "第3个字节的字符是:" << c << endl; // 输出:c // 6. 验证文件整体内容(读取全部内容打印) fs.seekg(0, ios::beg); // 读指针移回开头 string content; getline(fs, content); cout << "修改后的文件内容:" << content << endl; // 输出:abcdxfghij fs.close(); }
解释:
fs是流对象,fs << "x"是向该流关联的文件写入 "x"。不调用
seekp时,写指针默认在文件开头,fs << "x"会覆盖文件第一个字符。这里'x'、“x”都是一个字符x,只有abc字符串必须是双引号。
seekp用于移动输出(写)指针,指定下一次写入数据的位置;
seekg用于移动输入(读)指针,指定下一次读取数据的位置。两者参数相同(偏移量和起始位置),但分别控制读写操作的位置。如果读指针当前位置是 5 时,若再用
seekg(n, ios::cur)(从当前位置偏移),新位置就是 5 + n;若用ios::beg则从开头算(与当前位置无关),ios::end从结尾算
fstream fs("data.txt", ios::in | ios::out);这行是 “打开文件” 的操作,后续close针对这个的
if (!fs.is_open())只是判断,和打开无关。
fstream在定义时如果不写模式,默认就是ios::in | ios::out,所以这两种写法完全等价:fstream fs("data.txt"); // 不写模式,默认就是 ios::in | ios::out fstream fs("data.txt", ios::in | ios::out); // 显式写出模式,效果一样
必须文件预先存在(因为带
ios::in),否则打开失败;打开后不会清空文件原有内容(默认不带
ios::trunc);读写指针默认都在文件开头,写入时会从当前位置覆盖内容(比如原有
abc,写入d会变成dbc)。简单说:
fstream默认是 “读写已有文件,不清空,按位置覆盖”。实际开发中,显式写出模式更推荐,尤其是团队协作时 —— 别人一眼就能看出你要 “读写” 文件,避免误解(比如误以为默认模式是只写或只读)
三大主要功能之外的实战场景,大厂面试 / 工作常遇到的几个东西:
如何判断文件是否读完?
Q:有必须要学吗?豆包回答
A:这些基础文件流操作是大厂 Linux C++ 服务端开发基础岗的必备知识,必须掌握,服务端开发天天和 “数据持久化”“日志读写”“配置文件解析” 打交道,比如:
读取配置文件(如
server.conf)初始化服务参数;写日志文件(如
access.log)记录请求信息;临时文件处理(如缓存中间数据)。
这些场景本质都是文件读写,
ifstream/ofstream的基础操作(打开 / 判断成功 / 按行读 / 格式化写 / 关闭)是最常用的工具,面试和工作中一定会。查看代码
#include <fstream> // 文件流核心头文件 #include <iostream> // 控制台输入输出 #include <string> // 字符串处理 #include <cstring> // 字符数组操作(二进制读写用) using namespace std; // 演示文本文件读写(按行读写) void text_file_operation() { cout << "\n===== 文本文件操作 =====" << endl; // 1. 写文件(默认模式:ios::out | ios::trunc → 创建+清空) ofstream fout("text.txt"); if (!fout.is_open()) { // 必须检查打开是否成功 cerr << "创建text.txt失败!" << endl; return; } // 写入几行内容 fout << "第一行:hello world" << endl; fout << "第二行:12345" << endl; fout << "第三行:C++ file stream" << endl; fout.close(); // 写完关闭(好习惯) // 2. 读文件(默认模式:ios::in → 必须文件存在) ifstream fin("text.txt"); if (!fin.is_open()) { cerr << "打开text.txt失败!可能文件不存在" << endl; return; } // 按行读取并打印 string line; int line_num = 1; cout << "读取text.txt内容:" << endl; while (getline(fin, line)) { // 简洁写法:循环读直到结束 cout << "第" << line_num++ << "行:" << line << endl; } // 判断读取终止原因 if (fin.eof()) { cout << "→ 正常读完所有内容" << endl; } else if (fin.fail()) { cerr << "→ 读取过程出错!" << endl; } fin.close(); } // 演示二进制文件读写(适合存储结构体、二进制数据) void binary_file_operation() { cout << "\n===== 二进制文件操作 =====" << endl; // 定义一个结构体(模拟网络协议数据、用户信息等) struct Student { int id; char name[20]; // 固定长度,避免string的二进制兼容性问题 float score; }; // 1. 写二进制文件(必须加ios::binary模式) ofstream fbin_out("student.bin", ios::out | ios::binary); if (!fbin_out.is_open()) { cerr << "创建student.bin失败!" << endl; return; } // 写入两个学生数据 Student s1 = {1001, "张三", 95.5}; Student s2 = {1002, "李四", 88.0}; fbin_out.write((char*)&s1, sizeof(s1)); // 按字节写入 fbin_out.write((char*)&s2, sizeof(s2)); fbin_out.close(); // 2. 读二进制文件(必须加ios::binary模式) ifstream fbin_in("student.bin", ios::in | ios::binary); if (!fbin_in.is_open()) { cerr << "打开student.bin失败!" << endl; return; } // 读取并打印 Student temp; cout << "读取student.bin内容:" << endl; while (fbin_in.read((char*)&temp, sizeof(temp))) { // 循环读结构体 cout << "ID:" << temp.id << ",姓名:" << temp.name << ",分数:" << temp.score << endl; } // 判断读取终止原因 if (fbin_in.eof()) { cout << "→ 正常读完所有二进制数据" << endl; } else if (fbin_in.fail()) { cerr << "→ 二进制读取出错!" << endl; } fbin_in.close(); } int main() { text_file_operation(); // 文本文件读写 binary_file_operation(); // 二进制文件读写 }
先解释代码的作用:
服务端开发中:
文本操作的核心需求是 “人类可读写”:
配置文件(如
.conf.ini):人类可直接编辑(比如修改服务端口、超时时间),必须用文本格式。日志文件(如
.log):需要人类能直接查看(比如排查错误时 grep 关键词),文本格式最方便。协议交互(如 HTTP、JSON):基于文本的协议易读易调试,广泛用于跨系统通信。
二进制操作主要用于存储 / 传输结构化数据,核心优势:读写效率高、数据紧凑,适合对性能敏感的场景:
保存用户信息、游戏存档等结构化数据(用结构体直接读写,比文本解析快);
网络传输协议数据(二进制格式体积小、解析快,避免文本转义问题);
读写图片、音频等二进制文件(这类文件本身不是文本,必须用二进制模式)。
C++ 的
ifstream/ofstream/fstream(ios 派生类)析构时会自动关闭,C 语言的fopen打开的文件需手动用fclose关闭。细节
cout << "第" << line_num++ << "行:" << line << endl;,line_num++是后置自增,先输出当前line_num的值,再让它加 1(这个总拿不准)继续解释其他自己挖掘的东西:(以下所有的一切依旧是豆包误人子弟反复言之凿凿的瞎编各种规则,需要我反复质疑实践才行,狗逼豆包狗改不了吃屎!!死全家的垃圾玩意!每次学个最最最操.你妈简答的东西都得被豆包气个半死!!)(全世界除了我!没任何第二个人能做到通过傻逼狗逼豆包学习!!操.你妈没豆包真的无法进行,自己会思考很多东西,但有豆包,基本每天的犯错率高达 80%!!且回答 90% 都是垃圾信息,但可以用我的顶尖的追问质疑思考能力化解)(又他妈扯到了编译器版本啥的)
while (fin.good() && getline(fin, line))、while (getline(fin, line))(大厂常用)、while (getline(...) && !fin.fail())等价。
fin.good():检查流的状态是否 “完全正常”,即goodbit有效,无任何错误标志
返回
true:说明之前的操作没出错,可以继续读。返回
false:可能是已经读到末尾(eofbit),或发生错误(failbit/badbit),循环终止。
getline(fin, line):从文件流fin中读取一行内容到line变量。
成功读取一行时,返回
true,继续循环。失败时(比如已到文件尾,或读取出错),返回
false,循环终止。此文搜“字符,直到遇到指定分隔符”,其实
getline也是,原型为getline(istream& is, string& str, char delim),默认delim是 '\n'
fin.good()会提前排除 “已到文件末尾” 的情况,而getline(fin, line)“读到末尾”返回的也是失败。
!fin.fail()为真时,包含两种情况:流完全正常(goodbit),或仅到达文件末尾(eofbit且无错误)。
good()为真时,仅表示流完全正常(无任何错误标志,包括eofbit也不能有)。
二进制那里,出错的本质就是没完整读完一个结构体。
比如这里如果文本的来解读结构体,是没有字节边界的,只有连续字符(
1001张三95.5),全靠>>的 “类型规则” 拆分:
读
id(int):只取数字字符,遇到非数字(“张”)就停,没错读了1001读
name(char[]):没有 “字节限制”,只认空白字符当终止信号,“张三” 后面是 “95.5”(非空白),就一直读,直到文件结束,自然把score的字符也吞进去;读
score(float):已经没字符可读,只能是垃圾值。二进制:
1001、"张三"、95.5写的时候就分了 3 个块(id4 字节 +name20 字节 +score4 字节),然后读时按块取,各块不干扰。且name里的\0能识别有效字符结束,双重保障不读95.5;文本:读
char[]时,根本不把\0当终止信号!只认空格 / 换行,且写时不分块,把 3 个成员的字符全拼进一个连续块,读时无块边界,只能盲目一个内存块一直读,读name时,读文本用getline只认换行,用>>只认空格,所以哪怕name里有\0也跳过,继续读后面的95.5。千辛万苦的追问,豆起初始终不回答这个!!
这些结论很 JB 飘渺,况且狗逼豆包说的误人子弟自相矛盾,直接让豆包给个实验代码,自己运行后就嘎嘎透彻了,反而觉得上面这些结论是累赘,这个实验才是有价值的
查看代码
#include <fstream> #include <iostream> #include <string> using namespace std; void printState(ifstream& fin) { cout << "good=" << fin.good() << " eof=" << fin.eof() << " fail=" << fin.fail() << endl; } int main() { // 创建测试文件:内容为 "a\nb"(a换行b,无结尾换行) ofstream("test.txt") << "a\nc"; ifstream fin("test.txt"); string line; cout << "初始状态:"; printState(fin); cout << "读第一行:"; getline(fin, line); // 读"a" bool res1 = !fin.fail(); // 用 fail() 判断是否成功 cout << "res=" << res1 << " "; printState(fin); cout << "读第二行:"; getline(fin, line); // 读"b" bool res2 = !fin.fail(); cout << "res=" << res2 << " "; printState(fin); cout << "读第三行:"; getline(fin, line); // 到末尾,失败 bool res3 = !fin.fail(); cout << "res=" << res3 << " "; printState(fin); } 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./abc 初始状态:good=1 eof=0 fail=0 读第一行:res=1 good=1 eof=0 fail=0 读第二行:res=1 good=0 eof=1 fail=0 读第三行:res=0 good=0 eof=1 fail=1 root@VM-8-2-ubuntu:~/cpp_projects_2#自己零零碎碎的总结是(经过豆包肯定):
注意,起初写的是
bool res1 = !getline(fin, line);但报错,getline返回的是流对象,不能直接赋值给bool变量,所以这么写了,其实也可以bool res = !getline(...).fail()。
good是读到什么东西,他后面没东西了,但这次读取完good就返回 0(这不是 “错误”,只是流不再完全正常),后续再读就是已经没东西的,必然依旧是 0,而getline等价!fail,读到什么东西,他后面没东西了,但这次读取完返回的依旧是 1。所有流状态成员(
eof()/good()/fail()等)的状态,都是在 当前读取操作完成后 才更新的。
所有 C++ 输入流操作(
>>、getline、read等),本质都是通过修改流的状态标志(eof/fail/good)来反馈结果,只是触发时机和getline有差异。再验证个>>查看代码
#include <fstream> #include <iostream> #include <string> using namespace std; void printState(ifstream& fin) { cout << "good=" << fin.good() << " eof=" << fin.eof() << " fail=" << fin.fail() << endl; } int main() { ofstream("test.txt") << "a\nb"; // 文件内容:a换行b(无结尾换行) ifstream fin("test.txt"); string line; cout << "初始状态:"; printState(fin); cout << "读第一个字符串:"; fin >> line; // 读"a"(跳过后续换行) bool res1 = !fin.fail(); cout << "res=" << res1 << " "; printState(fin); cout << "读第二个字符串:"; fin >> line; // 读"b" bool res2 = !fin.fail(); cout << "res=" << res2 << " "; printState(fin); cout << "读第三个字符串:"; fin >> line; // 无内容可读 bool res3 = !fin.fail(); cout << "res=" << res3 << " "; printState(fin); } 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./abc 初始状态:good=1 eof=0 fail=0 读第一个字符串:res=1 good=1 eof=0 fail=0 读第二个字符串:res=1 good=0 eof=1 fail=0 读第三个字符串:res=0 good=0 eof=1 fail=1 root@VM-8-2-ubuntu:~/cpp_projects_2#
>>和getline的标志处理完全一样。
bad()是流的另一个状态标志,仅在 “流底层发生严重错误”(如硬件故障、文件被意外删除)时为 1,日常读写(末尾、正常失败啥的)都不会触发。good()的判断逻辑是eof=0 && fail=0 && bad=0。流对象(如
fin)被隐式转换为bool时,结果等价于!fail()这是 C++ 标准强制规定,getline(fin, line)返回fin,转换为bool就是!fin.fail():成功时fail()为 0,转换后为true;失败时fail()为 1,转换后为false。
eof()仅在 “尝试读取超出文件 / 流末尾”时返回true
fail()在读取失败时(比如读到文件末尾后还想继续读、读入数据类型不匹配等),返回true
getline不能直接cout输出有意义的结果
getline执行后,fin的fail()状态会被更新,if (getline(fin, line))本质上就是在判断!fin.fail(),底层绑定!fail(),getline会把读到的字符存进line里)。
流对象是 C++ 标准库中用于输入 / 输出操作的具体对象实例,比如:
ifstream fin("file.txt")定义的fin(文件输入流对象);
cin(标准输入流对象,对应键盘);
ofstream fout("out.txt")定义的fout(文件输出流对象)。
good()/eof()/fail()是它们的成员函数(直接属于这些对象),这些实例弄好以后,就可以用getline、运算符重载函数 >>、read()之类的函数来操作流对象的函数,调用后返回的就是这些对象本身,返回本身的意思是说,调用完之后,流里就有了数据,且查询功能good/eof/fail一并更新,但这里豆包指出了我的理解问题:“调用后返回的就是这些对象本身,返回本身的意思是说,调用完之后,流里就有了数据”—— 这里的 “返回本身” 和 “流里有数据” 无关。
返回流对象本身,单纯是函数设计的返回值形式(方便链式调用,比如
getline(fin, line).getline(fin, line2)),而 “流里有数据” 是操作(比如getline)的结果,两者是分开的:操作会让流的状态(good/eof/fail)更新,也会把数据读到变量(比如line)里,而返回流对象只是提供了一个 “继续操作该流” 的入口。
cout << a << b << c这种连续使用<<的写法叫 “链式调用”(连锁操作)。
这里其实我的思考是,俩代码都只是侧面验证,并没有直接输出
getline,而这个东西又无法直接输出,算了不研究了(邓钦泽,遇到了再说)
常用搭配(推荐):
二进制文件通常用
read()/write()(按字节操作,适合非文本数据);文本文件通常用
getline()或>>(按字符 / 行操作,适合人类可读的文本)。
辩论解析:
二进制文件不适合用
getline,原因是:getline的核心逻辑是 “从流中读取字符,直到遇到换行符\n为止”,这是针对文本文件的设计(文本中\n是明确的换行标记)。而二进制文件中,
\n可能只是普通字节(比如图片、视频数据中随机出现0x0A,即\n的 ASCII 码),此时getline会误判为 “行结束”,导致读取的数据被截断或错乱,因此,二进制文件应始终用read()按字节数读取。
read能读文本文件,但不推荐:read是按字节数强制读取(比如read(buffer, 100)读 100 字节),不管内容是不是文本,会原封不动读字节(包括换行符\n、空格等)。但文本文件的核心是 “按字符 / 行解析”,用getline或>>更方便(自动处理换行、空格分隔)。
getline按\n读完整行(包括中间空格)。
>>按空格 和\n等分隔符读(遇到分隔符就停,不是读完整行)。
read会从当前位置连续读取指定字节数(如read(buf, 1024)就读 1024 字节),不关心内容中的空格、换行等分隔符,纯粹按字节连续读。
if (fin.eof()):检查是否设置了eofbit标志(eof()是判断该标志的函数)。
如果
true:说明循环是因为 “读到文件末尾” 而终止,属于正常情况(比如文件内容全部读完)。
else if (fin.fail()):检查是否设置了failbit标志(fail()是判断该标志的函数)。
如果
true:说明读取过程中发生 “可恢复的错误”(比如用>>读数字时遇到字母,或文件突然被删除)。
文本的懂了,然后解读
while (fbin_in.read((char*)&temp, sizeof(temp))):
fbin_in是二进制输入流对象(如ifstream),read尝试从流中读取sizeof(temp)字节到temp地址((char*)&temp是类型转换,确保字节级操作)。
若读取成功(读到预期字节数),此时流状态为未失败(即依旧是看
!fail,不说正常是因为可能已触发eofbit),条件为真,继续循环;
read函数的返回值本质就是流对象,但作为循环条件时起作用的是其 bool 转换结果(即!fail()),流对象能作为条件是因为其内部重载了 bool 转换运算符,实际返回的是!fail()的结果,而非单纯 “返回对象本身” 这一形式
!fail()仅表示未发生失败(failbit和badbit未设置),但可能已设置eofbit(如最后一次读取恰好到文件尾且读满),这种情况不属于 “完全正常”,只是操作有效,不代表流无任何标志位(可能含 eofbit)。
若 读取失败(循环退出),分两种场景:
场景 1:因 “到达文件尾” 导致未读到
sizeof(temp)字节(如文件只剩 2 字节却要读 4 字节):此时同时设置eofbit和failbit,即eof()、fail()为真。注意如果文件尾恰好与
sizeof(temp)字节对齐(即最后一次读满),则eofbit会被设置但failbit不会,此时属于 “读取成功”。不属于该场景。
场景 2:因 “非文件尾原因” 导致未读到
sizeof(temp)字节(如文件损坏、权限不足、读取中断):仅设置failbit(或叠加badbit),eofbit为假;两种场景均因
fail()为真,导致条件为假,循环退出
哎!傻逼豆包啰里吧嗦我就给帖上了,兴许以后会用到,但其实脑海里有代码运行真他妈觉得废话连篇!
fail()为真时,说明设置了failbit(如格式错误:用>>读整数却遇到字母),这种错误可通过clear()清空标志后继续操作流(可恢复);而badbit(严重错误,如硬件故障)会让fail()也为真,但此时流无法恢复。
fail()为假时,才是 “无failbit且无badbit”,此时可能是good()(全正常)或仅eofbit置位(读到尾)。
!fail()返回 true(1) 时 = 既没有可恢复失败(failbit),也没有严重错误(badbit),也就是说fail如果为真,那么就是failbit或badbit至少有一个。“可恢复” 指的是操作失败但流还能继续用,比如:
用
>>读整数时遇到字母(格式错),fail()会触发,但可以清空错误标志后重新读其他内容;而
badbit是严重错误(如硬件故障),流彻底用不了,不可恢复。
!fail()排除的是这种 “可恢复的失败”,但文件尾(eofbit)不算失败,所以eof时!fail()为真,但流已经读到头了:
!fail()就像在说:“上次的操作还算顺利,没有出什么岔子”。但是,“顺利” 也包括 “顺利地读完了所有数据”。所以,当你read()到文件最后一个字节时,操作是顺利的(!fail()为true),但文件也确实读完了(eofbit被设置)。因此,光看!fail()为true,你无法确定接下来还能不能读到数据。你还需要检查eof()来确认是否已到文件末尾
总结:
good()是 “一切完美”(没到尾,没任何错);为真条件:仅当所有错误标志(包括 eof、fail、bad)都为假,是唯一 “完全正常” 的状态。
!fail()是 “没出大错”(可能到尾了,但没格式错、没硬件故障,还能接着用或正常结束);
fail()是 “出了可修复的错”(比如读错格式,清掉标志还能救);
bad()是 “彻底完蛋”(硬件故障,救不活了)。
注意后面还有说法!!这些只针对
getline、>>。
三大主要功能之外的实战场景,大厂面试 / 工作常遇到的几个东西:
如何处理大文件(避免内存爆炸)?
绝对不能一次性读入内存!必须 “分片读”
先搞懂核心问题:为啥不能 “一次性读大文件”?比如你要读一个 10GB 的电影文件:
如果你想 “一次性读完”,就得在内存里开一个 10GB 的空间装它;
但普通服务器 / 电脑的内存可能就 8GB/16GB,根本装不下,程序会直接崩溃(这就是 “内存爆炸”);
就像你搬 100 箱苹果,不能一次全抱在怀里(抱不动),得一次抱 2 箱,分 50 次搬 —— 这就是 “分片读”。
查看代码
// 1. 定义一个“搬运箱子”的大小:4KB(4096个字节) // 为啥是4KB?是系统和磁盘的“最佳搬运尺寸”,效率最高,不用纠结,照用就行 const int BUFFER_SIZE = 4096; // 2. 造一个“4KB的箱子”(内存里的一块空间),专门用来装每次读的文件片段 char buffer[BUFFER_SIZE]; // 3. 循环“搬箱子”:每次从大文件里读4KB到“箱子”里 // 直到“没的可搬”(读到文件末尾) while (fin.read(buffer, BUFFER_SIZE)) { // 4. 把“箱子”里的4KB数据,写到目标文件里(相当于把2箱苹果搬到目的地) fout.write(buffer, BUFFER_SIZE); } // 5. 处理“最后剩下的零头”:比如大文件是4097字节,最后一次只能读1字节 // gcount() 就是“最后一次实际搬了多少字节” int remaining = fin.gcount(); // 6. 如果有零头,就把零头也写进去(不然最后1字节会丢) if (remaining > 0) { fout.write(buffer, remaining); }然后先科普个东西 —— 代码规范,说大厂有用且后面完整代码就涉及到这个
@是Doxygen注释的标记,让工具自动提取注释生成规范文档
param是parameter(参数)的缩写,配合 @标记函数输入参数的含义和要求,格式:@param 参数名 描述(含要求)注释里的 “标签” 就是带
@的标记(比如@brief/@param),用来给注释分类,让人一眼分清 “功能”“参数”“返回值”。
//是短注释
/** ... */是 “长注释”,适合写函数 / 类的详细说明,里面的@xxx是约定好的标签写法,用来分类说明(比如 @brief 说功能、@param 说参数),可以被工具生文档,比如查看代码
/** * @brief 复制超大文件(支持任意大小,不爆内存) * 👉 解释:这行是函数的“一句话功能总结”,告诉别人这个函数最核心的作用——复制大文件,还不会让内存爆炸。 * * @param src_path 源文件路径(必须存在) * 👉 解释:@param 表示“函数的输入参数”,这里说的是: * - src_path 是参数名(代码里用这个名字接收用户输入的路径); * - 作用是“源文件的路径”(就是你要复制的那个文件,比如 /home/user/10GB.iso); * - 括号里是“使用要求”:这个文件必已经存在 * * @param dst_path 目标文件路径(存在则覆盖,不存在则创建) * 👉 解释:第二个输入参数: * - dst_path 是参数名; * - 作用是“复制后新文件的路径”(比如 /home/user/copy_10GB.iso); * - 使用要求:如果这个路径已经有同名文件,就直接覆盖它;如果没有,就自动创建一个新文件。 * * @return true:复制成功;false:复制失败(会打印错误原因) * 👉 解释:@return 表示“函数执行完后返回给调用者的结果”: * - 返回 true → 复制搞定了; * - 返回 false → 复制没成功(比如文件打不开、磁盘满了) */继续科普,
win的cmd实现win → linux:scp C:\Users\GerJCS岛\Desktop\图图.jpg root@81.70.100.61:/root/cpp_projects_2这是win → linux,倒过来顺序就是linux → win。
这个操作是从 Windows 直接向 Linux 服务器上传文件。你的 Windows 是客户端,Linux 服务器是接收端。为了让你能把文件放到 Linux 服务器上,服务器需要验证你的身份,所以你得输入服务器上
root用户的密码!Zzxc11位。由于我登陆
SSH的是root的目录下的,传的目标目录就是/root/cpp_projects_2,所以@前必须是root,写成~/cpp_projects_2也行,~自动绑定@前面那个用户名的家目录,顺序都是scp 源 目的,如果是别人电脑往我服务器传,依旧是如此。
Linux里实现win → Linux,由于不认识C盘符,所以具体是:scp GerJCS岛@192.168.43.86:/C/Users/GerJCS岛/Desktop/图图.jpg root@81.70.100.61:/root/cpp_projects_2
但报错了,第一中文名说找不到,第二 win 下执行的是 “Win 作为客户端 → 连 Linux 服务器”,只需要 Linux 开 SSH(22 端口)就行;但 Linux 端执行的是 “Linux 作为客户端 → 连 Win”,这就需要 Win 也开 SSH 服务(监听 22 端口),我貌似 win 没有,不强行搞了。
这个操作是从 Windows 电脑向 Linux 服务器拉取文件。此时,Linux 服务器变成了客户端,它需要连接到你的 Windows 电脑去获取文件。你的 Windows 电脑为了安全,会要求 Linux 服务器证明自己的身份,所以你需要输入 Windows 电脑上
GerJCS岛用户的密码。术语:
Linux 服务器主动从你的 Windows 电脑获取文件就是拉取,Windows 主动把文件传给 Linux 服务器就是推送。但输入密码这块,是谁主动发起操作,就输入 “对方”(目标端)的密码,和 “拉取 / 推送” 的说法无关,本质是 “客户端验证目标端的身份”。
且不管谁往谁传,双方都必须联网,联网的具体知识是:
关于win,不是必须联网才能看到 IP,但未联网时的 IP 基本没用,一般无法和外网通信,顶多系统会自动分配一个
169.254.x.x开头的私有 IP,任何169.254.x.x的都是没网的东西不用看,只能用于本地设备间的临时通信。只有当 Windows 连网,才能获取到能和外网交互的有效 IP,此时用 ipconfig 命令看到的 IPv4。关于腾讯云 Linux 服务器,它的公网 IP 是客观存在且绑定服务器的,不管联不联网都有,但是必须联网才能通信,才能用。
Q:老子发现
VScode可以拖,那你他妈给这scp不是多此一举脱裤子放屁了吗?A:直接拖文件到 Linux:只有 “本地设备和 Linux 在同一台电脑 / 同一局域网” 才管用,
scp主要是给真正的异地服务器啥的用到。开始说大文件的代码:
豆包说,大厂 Linux 服务端互相传东西是为了:
同步代码、配置(比如把开发好的程序传到测试 / 生产服务器);
共享数据(比如日志文件、用户数据在多台机器间流转);
分布式计算(把大任务拆给多台机器一起做,结果汇总)。
简单说:单台 Linux 干不了所有活,必须多台组队,传东西是组队的 “信息 / 资源纽带”。
Q:你意思大厂合并啥的还需要写段代码?
A:大厂合并数据、服务等场景,必须写代码(或用脚本)来自动化处理数据同步、服务调度、资源整合,不然靠人工根本搞不定大规模集群的协作。
Q:没有啥按钮合并?
A:在大厂的 Linux 服务端场景中,几乎没有 “一键合并” 的按钮,必须靠代码 / 脚本实现自动化,因为:
大厂的系统是 “定制化、分布式、大规模” 的,通用按钮满足不了复杂业务逻辑;
代码能精准控制合并的每一步(比如数据校验、并发处理、故障回滚),按钮做不到。
查看代码
真的好痛苦!总想求助王钰涵!求助鱼皮 帮帮我 我410元的硬座从乌鲁木齐到哈尔滨回家过年,坐72h的火车硬座都没求过人 求人不是我的性格! 我就要干死他们!!饿肚子都没想过求谁 如今这真的太痛苦了3天解决一个100%不考的各种细节!每天解决一个细节且都是无关紧要的哎 强迫症陷里面了!!感觉C++强迫症挖掘太多东西了!清晰知道自己在深渊!但就是无法出头 更加的对自己狠 王志文抬进考场 罗斯 中科院黄国平! 爸爸的病 我要逼自己更加砸时间!而不是求那些商人!!!!! 更加高效率,除了学习导管子可以不看手机 破而后立 强迫症考古回忆确认占实际学习的60% 垃圾豆包信息写博客占用80% 什么都查什么都学好奇无数琐碎钻研,占用90%的时间 且豆包回答每天 80%的错误率 90%的垃圾信息 看透他们99%的人 可我呢 我何时能出头?能显化? 我的春天在哪里 妈妈给我钱 爸爸两面手一次术,割肾造瘘,可我能做什么? 每天在家什么也做不了 只有我可以带来好消息 儿子出息之类的 我热。起码学就可以会 但爸爸的病,只能听天由命 爸爸妈妈的希望是我 儿我的希望。是让父母开心 虽然妈妈一直说,希望我做个平凡普通人 我年轻 吃烂的水果,吃便宜的吃的,我可以恢复 爸爸的病,无法改变。没法变好了 我c++真有那么难吗 现在学这个 scp这 打字都打累了 骂都骂累了 豆包大模型真的完全是幼儿园的水平 但我又能问谁? 我躺在烂泥粪坑里打滚的 僵死的臭虫抽搐 殿大头踩着头 磐不妄把头按在粪坑里 画彩璃 星神子 更加狠绝给自己鼓气 没水没卫生间只能大小便在屋子里,洗澡拿着淋浴器洗个60%,洗衣服洗个60%,上厕所排个60% 这一年多,成长最慢的是技术,成长最快的是挖掘天赋和心性磨练 考个公吧没本事成啥样 我考上深圳东北 但不去 证明自己 我大厂LinuxC++服务端开发 做技术的,技术出生 但你要知道我29去之前的经历阅历! 技术!对我来说,是我最不擅长的弱势弱点!!!我因为没办法要赚钱,才逼自己学程序员这些玩意。 我要多多的年薪 我不想考公务员 我想投资经商 跟政府谈生意,谈判 我想成为雷军马化腾马云那样的人 这些是我擅长的!! 我想做互联网的大厂高管管理! 国企体制内做技术,就是垃圾 考公就是温饱 想活着 最低要求 不去竞争晋升 真的很舒服 如果还活不下去 说明你真的很垃圾 在我眼里公务员就是最垃圾最没用的回到这个大文件代码,必须都搞到
VScode里,就是Linux上,这时候上面提前追问的就用上了,这里我选择直接导入吧,傻逼豆包给我扯东扯西,追问半天误人子弟,结果VScode除了拖拽就只能scp,根本没右键上传的按钮,打算拖拽上传,然后尝试运行并理解这个复制大文件的代码,因为大文件我最先想到的是视频,直接传了个
35M 的 mp4 文件,但出问题了艹,拖拽完等待 1h 都一直的跑马灯一样蓝色线在资源管理那跑,其他所有东西都卡住,结束没法结束,然后查说想中断要么左下角关闭远程,重新打开,这会确保之前所有的旧连接和任务都被彻底清理掉。或者调出进程杀进程,中断个东西这么麻烦!
这是因为
VSCode的Remote-SSH插件在图形化拖拽文件时,底层依赖的SSH协议本身有加密和网络开销,再加上大文件传输时的资源消耗,练完了scp现在又给我说大厂最常用的是rsync,支持断点续传但有报错,
rsync不允许源地址(GerJCS岛@...)和目标地址(root@...)同时是远程服务器,原来豆包搞错了我的意图,后来弄懂了,现在有个问题是,win用rsync会报错,具体原因是:先捋顺之前的scp,由于当你在 Linux 服务器上运行:
scp GerJCS岛@192.168.43.86:/C/Users/GerJCS岛/Desktop/图图.jpg ...这个命令的意思是:“
Linux服务器啊,请你去连接192.168.43.86这台机器,然后把它上面的/C/Users/.../图图.jpg文件复制过来。”但是,
192.168.43.86是你的Windows电脑。要让Linux服务器能成功连接并复制文件,需要满足几个条件,这也是你之前失败的原因:
Windows电脑需要开启一个 “文件传输服务”:就像你去别人家要拿东西,别人家得有人开门,并且允许你拿。这个 “开门” 的服务通常是SSH服务。你的Windows默认是关闭这个服务的,所以Linux服务器连不上。
Windows的防火墙需要放行:即使开了SSH服务,Windows的防火墙也可能会把 Linux 服务器的连接请求挡住。中文用户名和路径的问题:
GerJCS岛和图图.jpg中的中文,在Linux命令行环境下容易出现编码问题,导致命令无法正确解析路径。虽然可以通过一些方法解决,但这确实是一个常见的坑。但以上这些都根据经验没啥搞的意义,只是
linux无法,但我win可以完美实现,把Windows电脑上的文件传到Linux服务器,正确的方向是 从Windows主动发起传输,即“我的Windows电脑啊,请你把我本地的C:\...\图图.jpg文件,通过网络发送给81.70.100.61这台 Linux 服务器,并存放到它的/root/cpp_projects_2目录下。”
发起方是
Windows:Windows知道自己的文件在哪里。目标是
Linux:Windows通过网络连接到Linux服务器的SSH服务(这个服务Linux通常是默认开启的)。数据流向是
Windows -> Linux:这完全符合 “本地 -> 远程” 的逻辑。且腾讯云服务器
linux本身自带各种监听啥的(Windows默认没有SSH服务(无法被Linux主动连接读取文件),Linux默认开启 SSH 服务(可接收Windows推送)—— 这就是核心原因)哎这些行内代码都是一个一个手动加的
Q:研究这些跑偏吗?
A:不跑偏,有必要,但不用深钻 “封块” 细节 —— 面试核心考的是Linux 命令使用、远程传输逻辑、问题排查思路,你练的 “本地→云服务器传文件 + 服务器内复制” 刚好贴合这些基础考点。
重点:不用纠结 4G/6G 大文件封块(实际工作中
rsync/scp已自动处理),但要掌握:
rsync/scp基本用法(面试可能让写命令);传输卡死 / 失败的排查(如 SSH 连接、权限、路径问题);
服务器内复制用
scp/rsync的区别(如rsync增量同步更高效,只同步变化的)。这些都是服务端开发的日常基础操作,面试会隐含考察(比如问 “怎么把本地代码传到服务器”“大文件传输中断怎么办”),你的练习方向完全对。
Q:那我就想问一下子,我用scp传过去就完事,然后不用实际打开,是吗?那这玩意传有啥意义啊?既然你说不会在服务器上看视频,那一般好像也没有这么大几 G 的,正常大厂实际用的话,他是什么东西能传到 G 这个级别去来回复制?因为我理解就只有视频才能达到这么大。
A:正常!你的疑问很贴合实际 —— 大厂传 G 级文件,核心不是视频,而是服务端开发的核心工作物料,传完也不是 “打开看”,而是 “用起来”(运行、编译、存储等),具体说:
1. 大厂常传的 G 级文件(非视频)
代码 / 项目包:大型 C++ 服务端项目(如分布式系统、数据库内核),源码 + 依赖库压缩后可能达几 G;
数据文件:日志(如服务器天级 / 周级日志,GB 级很常见,用于排查问题)、数据库备份(MySQL/Redis 快照,动辄 10G+)、训练数据(AI 团队的模型训练样本,TB 级都有);
二进制包 / 镜像:编译后的服务程序(大型 C++ 二进制文件可能几 G)、Docker 镜像(复杂服务镜像常达数 G,用于部署);
中间件 / 工具包:如大数据组件(Hadoop、Spark)的安装包,或自定义工具集,多为 G 级。
2. 传这些文件的意义(不是 “看”,是 “用”)
部署服务:把编译好的 C++ 二进制包传到云服务器,启动后端服务(比如用户访问 APP 的接口服务);
数据同步:日志 / 数据库备份传到服务器,用于故障排查、数据恢复;
协作开发:把本地写好的大型项目代码传到服务器,进行远程编译、测试(避免本地环境不一致);
资源分发:把工具包 / 镜像传到多台服务器,统一部署集群(比如分布式服务的多节点)。
3. 关键结论(贴合你面试)
你练的 “本地→服务器传文件” 完全不跑偏 —— 这是服务端开发的日常操作;
不用纠结 “打开文件”:服务端传大文件的核心是 “使用”(运行、编译、存储),不是 “查看”;
面试可能问:“大文件传输中断怎么办?”“怎么高效同步多台服务器的文件?”(你练的
rsync就是答案),这些比 “传什么文件” 更重要。
但我
win用rsync报错了,因为scp和rsync都依赖SSH协议进行安全连接和数据传输。当你在Linux上执行scp时,Linux会尝试通过SSH连接到你的Windows电脑。如果Windows没有开启SSH服务来监听这个连接请求,那么连接就会失败(通常是 “Connection refused”)。它只意味着 “从
Linux拉取Windows文件” 这个操作不行。而 “从Windows推送文件到Linux” 这个操作是完全可行的,而win有scp但没有rsync,所以win用rsync报错,而linux有rsync但根本没法用因为win没开ssh那些,所以rsync咋都没法用,除非win装ssh那些开各种监听,然后在linux上用,或者win装rsync然后再win上用豆包给润色后:
SCP:Win自带scp.exe客户端,可以推送文件到开启了SSH服务的Linux。但Windows默认没有SSH服务,所以Linux无法用scp拉取Windows的文件
Rsync:Windows默认没有rsync命令。Linux虽然有rsync,但它同样依赖SSH来连接另一台机器。因此:
在
Windows上直接用rsync会报错(因为没有这个命令)。在
Linux上用rsync拉取Windows文件也会失败(因为Windows没有SSH服务)。Q:我不装影响我去大厂吗?
A:完全不影响!大厂面试和工作的核心逻辑是:你得懂 “
Windows→Linux推送文件” 的正确方式(这是你已经掌握的,比如用scp推送),且清楚 “为什么不用Linux反向拉取”(因为Windows没开SSH服务,没必要额外配置)—— 这就够了。
“装不装
rsync/ 开不开WindowsSSH” 是 “工具选择”,不是 “能力考察”:面试考察的是你对SSH协议、文件传输逻辑的理解(比如知道scp/rsync依赖SSH,知道推送 vs 拉取的区别),而不是 “你电脑有没有装某个工具”;大厂服务端开发的标准流程就是 “本地→服务器推送”:没人会在
Linux服务器上反向拉取本地Windows文件(效率低、需额外配置本地服务,不符合生产规范),你现在用scp从Windows推送到Linux,完全契合实际工作场景。Q:懂了但我发现,用拖拽卡死,各种无尽的卡死!然后想点这个
mp4删除或者右键删除依旧卡死,而scp或者rm -f秒之A:两个问题核心原因一致:
VSCode远程操作大文件(35M 对VSCode远程预览来说不算小)时,会触发 “文件元数据读取 / 预览尝试”,导致进程阻塞,界面卡死,命令行操作不受此影响,具体拆解:1、右键删除卡死,
rm -f秒删的原因
右键删除:是 VScode 图形界面的操作 —— 你右键时,VSCode 会先尝试读取视频文件的元数据(比如分辨率、时长、文件编码),甚至偷偷启动预览进程(但服务器无视频解码能力),这个过程直接卡住 VSCode 的界面线程,导致删除操作迟迟无法执行;
rm -f秒删:是 Linux 命令行操作 —— 直接跳过所有图形化预览 / 元数据读取,底层调用文件系统接口强制删除文件,不依赖 VS Code 界面进程,自然秒完成。2、拖文件卡死,
scp正常的原因
拖文件(本地拖到
VSCode远程窗口 / 远程窗口内拖动):同样触发VSCode的 “远程文件操作逻辑”—— 拖动时VSCode会同步读取文件数据、校验文件完整性,甚至尝试预加载文件内容(视频文件无法解析,导致进程阻塞),界面就卡死了;
scp正常:是纯命令行基于SSH协议传输 —— 只做 “数据传输”,不涉及任何图形化预览、元数据解析,直接和 Linux 服务器的文件系统交互,没有额外进程开销,所以不会卡。总结核心逻辑:
VS Code远程管理文件的 “图形化功能”(预览、右键操作、拖动),对视频这类 “无法解析的大文件” 兼容性极差,容易触发进程阻塞;而Linux原生命令行(rm -f、scp)不依赖图形化界面,直接操作文件系统,效率极高,所以不会出现卡死问题。后续远程操作大文件(尤其是视频、压缩包等非文本 / 图片文件),优先用命令行:删除用
rm -f 文件名,上传用scp,避免用VSCode图形界面的右键 / 拖动操作,直接绕开卡死问题。
至此基本科普完移动文件这个事,然后开始看代码,豆包给的代码
看图,起初运行报错了,原因:
~是一个 Shell 环境变量(在 Bash、Zsh 等终端中),它代表当前用户的主目录(Home Directory)。对于root用户,~就代表/root。这是内置路径替换规则(仅 Shell 会自动将其解析为用户主目录/home/用户名),当你在终端里执行命令时,Shell 会先对命令进行解析。它看到~,就会自动把它替换成/root。所以你实际执行的命令是ls /root/cpp_projects_2,这当然能找到文件。其他程序(包括 C++/Python 代码、系统命令)不会识别。当运行
./abc并输入~/cpp_projects_2/斜门.mp4时,程序接收到的是一个原始的字符串"~/cpp_projects_2/斜门.mp4"。C++ 的标准库(如fstream)并不知道~在 Shell 中的特殊含义,它会把这个路径当作字面量去解释。备注:这个
斜门.MP4是之前闲鱼给人做新年拜年视频红色大门啥的,做视频赚点钱用的。
至此实操完,证明豆包给的代码没问题(埋个坑,注意我只看提示就觉得成功了),开始学习代码:
注意至此我有大量思考,混淆了很多东西,其实很多东西本身就是混杂的,哎最后精通了,说下心路历程吧:
我起初思考是:(算是处理零头的功能引发的血案)
这个代码看似很正常没啥问题,但
while后处理零头没懂,豆包说是读到末尾会返回false,哪怕读到了东西,这就是所谓的零头,然后在读到末尾是返回false还是true咋都说不明白,反复听我口气反复变了 100 个版本,然后我回忆上面说过“所有 C++ 输入流操作(>>、getline、read等),本质都是通过修改流的状态标志(eof/fail/good)来反馈结果,只是触发时机和getline有差异”的那个实验,到末尾!fail位又是1,也就是到末尾是不会退出while的,这里却说到末尾会退出,需要处理零头,然后又扯出来
read和getline、>>不同,我就很疑惑觉得豆包错了,然后又说while会把!fail这个事,到末尾eof时,fail置1,可是之前又说
!fail是包括eof的,那我理解就是fail不包括末尾!也就是可恢复的不包括末尾!!现在豆包又说当
read()操作因为到达文件末尾(EOF)而无法读取请求的全部字节数时,它会设置eofbit。在大多数(如果不是全部)C++ 标准库实现中,设置eofbit也会同时设置failbit。因此,fail()返回true,operator bool()返回false,导致循环退出。也即是fail包括末尾可是却又和代码实际处理零头退出那吻合。咋感觉处处都是疑点?事实又证明了都是对的?
却又都互相矛盾?艹精分了!
其实上面看似乱套的东西就是真实的脉络地图!!只不过太底层了!!深入说:
起初我理解
while里判断read、getline、>>都是!fail先手写证明几个东西
while(read..):查看代码
#include <iostream> #include <fstream> using namespace std; int main() { ofstream fout("test.txt"); for (int i = 0; i < 10; i++) fout.write("A", 1); fout.close(); ifstream fin("test.txt"); char buf[8]; int count = 0; // 循环读取,直到read()返回false while (fin.read(buf, 8)) { count++; cout << "第" << count << "次读取:" << fin.gcount() << "字节(" << (fin.gcount() == 8 ? "读满缓冲区" : "没读满缓冲区") << ")" << endl; } cout << "\n循环结束:read()返回false,最后一次实际读到的字节数:" << fin.gcount() << endl; fin.close(); } 输出: 第1次读取:8字节(读满缓冲区) 循环结束:read()返回false,最后一次实际读到的字节数:2手动手写
read:查看代码
#include <iostream> #include <fstream> using namespace std; // 用于打印流状态的函数 void printState(ifstream& fin) { cout << " (good=" << fin.good() << ", eof=" << fin.eof() << ", fail=" << fin.fail() << ")"; } int main() { ofstream fout("test.txt"); for (int i = 0; i < 10; i++) fout.write("A", 1); fout.close(); ifstream fin("test.txt"); char buf[8]; int count = 0; // 循环读取,直到read()返回false fin.read(buf, 8); count++; cout << "第" << count << "次读取:" << fin.gcount() << "字节(" << (fin.gcount() == 8 ? "读满缓冲区" : "没读满缓冲区") << ")" ; printState(fin); cout<<endl; fin.read(buf, 8); count++; cout << "第" << count << "次读取:" << fin.gcount() << "字节(" << (fin.gcount() == 8 ? "读满缓冲区" : "没读满缓冲区") << ")" ; printState(fin); cout<<endl; fin.close(); } 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./abc 第1次读取:8字节(读满缓冲区) (good=1, eof=0, fail=0) 第2次读取:2字节(没读满缓冲区) (good=0, eof=1, fail=1)手动
getline:查看代码
#include <fstream> #include <iostream> #include <string> using namespace std; void printState(ifstream& fin) { cout << "good=" << fin.good() << " eof=" << fin.eof() << " fail=" << fin.fail() << endl; } int main() { // 创建测试文件:内容为 "a\nb"(a换行b,无结尾换行) ofstream("test.txt") << "a\nc"; ifstream fin("test.txt"); string line; cout << "初始状态:"; printState(fin); cout << "读第一行:"; getline(fin, line); // 读"a" bool res1 = !fin.fail(); // 用 fail() 判断是否成功 cout << "res=" << res1 << " "; printState(fin); cout << "读第二行:"; getline(fin, line); // 读"b" bool res2 = !fin.fail(); cout << "res=" << res2 << " "; printState(fin); cout << "读第三行:"; getline(fin, line); // 到末尾,失败 bool res3 = !fin.fail(); cout << "res=" << res3 << " "; printState(fin); } 输出: 初始状态:good=1 eof=0 fail=0 读第一行:res=1 good=1 eof=0 fail=0 读第二行:res=1 good=0 eof=1 fail=0 读第三行:res=0 good=0 eof=1 fail=1 root@VM-8-2-ubuntu:~/cpp_projects_2#
while(getline.. ):此文搜“累赘,这个”
发现加
while并没有改变任何,唯独差别就是
getline和>>读东西读到末尾,fail是 0
read读东西读到末尾,fail是 1底层逻辑是:
1.read()的行为(二进制 / 字节流读取):
成功条件:必须读取到 请求的全部字节数。
失败条件:
到达文件末尾(EOF),无法读满。
发生其他 I/O 错误。
failbit设置时机:只要没读满,即使读到了部分数据,也会设置failbit。循环表现:
while (fin.read(...))会在 读满时进入循环,在 未读满(如 EOF)或出错时退出循环。零头处理:正因为未读满时循环会退出,所以需要在循环外通过
fin.gcount()获取最后一次读取的实际字节数(零头)并处理。一句话总结
read():追求 “完美读满”,差一个字节都算失败。2.
getline()和>>的行为(格式化 / 行读取):
成功条件:成功读取到 至少一个有效字符(对于
getline()是读到换行符或 EOF 前的字符,对于>>是读到非空白字符)。失败条件:
到达文件末尾(EOF),一个字符也没有读到。
发生其他 I/O 错误。
输入的数据与期望的格式不符(主要针对
>>)。
failbit设置时机:只有在 完全没有读到任何有效数据 时,才会设置failbit。循环表现:
while (getline(fin, line))或while (fin >> var)会在 读到数据时进入循环,在 什么都读不到(EOF)或出错时退出循环。零头处理:不需要专门处理。因为即使在文件末尾读到了不完整的一行(没有换行符),
getline()也会认为读取成功,将内容存入字符串,并在下一次调用时才返回false这个区别是由它们的设计目标决定的:
read()是底层工具,用于精确控制字节流,适合二进制文件。它的契约是 “按要求读取”。
getline()和>>是高层工具,用于方便地处理人类可读的文本数据。它们的契约是 “尽力读取有意义的数据”。好,至此清晰的知道了
read、getline、>>差别,敲死结论了,然后再!fail到底包不包括eof这个要重新梳理,之前的写法都删掉了!!因为都学会再写博客没法写,不知道该从哪里写起,懂完12345,但基础可能是12,不知道具体该写2还是写3,怕写少了后面忘了想回顾,回顾不上,所以都是学一点写一点,之前写的while(getline...)里!fail是否包括eof不适合read,现在做终结解释!:
fail()是 C++ 输入流(istream)的一个成员函数,它返回一个bool值,用于判断上一次输入操作是否失败。核心定义:什么是 “失败”?
fail()返回true(表示失败)的情况是:
发生了可恢复的错误。这通常意味着输入操作因为某种原因没有按照预期完成,但流本身并未损坏,你可以尝试清除错误状态并继续操作。
具体来说,
fail()为true主要包括以下几种场景:
格式化输入不匹配:当你使用
>>操作符读取特定类型的数据,但输入流中的下一个数据无法被解析为该类型时。
例子:你用
int x; cin >> x;,但输入的是"abc"。
read()操作未读满请求的字节数:当你调用fin.read(buffer, N)试图读取N个字节,但由于到达文件末尾(EOF)或发生其他错误,实际读取的字节数小于N时。
注意:这是
read()函数的特殊行为,它对 “成功” 的要求是 “完全成功”。
getline()操作因流状态不佳而失败:如果在调用getline()之前,流已经处于fail或bad状态,那么getline()会失败。
但:如果
getline()成功读取了一行(即使这行是文件的最后一行),它不会设置failbit,即使eofbit被设置了。关键区别:
fail()vs.bad()vs.eof()为了更好地理解
fail(),必须将它与另外两个常用的状态判断函数区分开。C++ 流的状态由三个独立的标志位控制:failbit,badbit, 和eofbit。
函数 含义 标志位 错误类型 是否可恢复 fail()操作失败 failbit可恢复的逻辑错误 是 (通常用 clear())bad()流已损坏 badbit不可恢复的严重错误 否 eof()到达文件末尾 eofbit不是错误,只是一个状态 是 (意味着没有更多数据可读)
bad():这通常表示发生了更底层的、严重的错误,比如硬件故障、文件被意外关闭等。一旦badbit被设置,这个流基本上就报废了,很难恢复。
eof():这只表示 “文件末尾”(End Of File)。它本身不是一个错误,只是一个通知你 “没有更多数据了” 的状态。
fail()的行为总结
fail()为true:操作没有按预期完成(例如,类型不匹配、read()没读够)。这是一个可恢复的错误。
fail()为false:上一次操作成功完成,或者虽然到达了文件末尾(eof()为true),但操作本身(如getline()读取了最后一行)被认为是成功的。对你之前代码的解释
read()的例子:
第二次
read()只读到 2 字节,没满足请求的 8 字节。这被视为一次 “失败” 的
read操作,因此failbit被设置。所以
fin.fail()返回true。
getline()的例子:
第二次
getline()成功读取了最后一行 "c"。虽然到达了文件末尾(
eofbit为true),但getline()的任务(读取一行)成功完成了。因此
failbit不 被设置,fin.fail()返回false。只有当
getline()尝试在已经到达 EOF 的流上再次读取时,它才会失败,failbit才会被设置。
fail()在读取失败时(比如读到文件末尾后还想继续读、读入数据类型不匹配等),返回true对错?
场景一:读到文件末尾后还想继续读。
行为:第一次到达文件末尾时,
read()会设置eofbit。在 GCC/Clang 下,它还会设置failbit。
fail()返回值:true。结论:你的说法在这种情况下是 对 的。
场景二:读入数据类型不匹配(例如用
>>读一个整数,但文件里是字母)。
行为:
>>操作会失败,设置failbit。
fail()返回值:true。结论:你的说法在这种情况下是 对 的。
场景三:在到达文件末尾前,
read()未能读满请求的字节数(即你代码中读取 “零头” 的情况)。
行为:
read()会设置eofbit和failbit(GCC/Clang)。
fail()返回值:true。结论:你的说法在这种情况下是 对 的。
但是,存在一个反例,这是关键!
反例:
getline()成功读取到一行,但其末尾就是文件末尾。
行为:
getline()成功读取了数据,设置eofbit,但 不设置failbit。
fail()返回值:false。结论:虽然到达了文件末尾(
eofbit为true),但getline()认为这次读取操作是 成功 的,所以fail()返回false。你的说法在这种情况下是 错 的。总结:
fail()返回true表示 “操作失败”,但不同的 I/O 函数对 “成功” 的定义不同:
read():必须读取到 请求的全部字节数 才算 “完全成功”。如果因为 EOF 未能读满,也算一种 “失败”,所以设置failbit。
getline()/>>:只要成功读取到 至少一个有效数据单元(一行或一个符合类型的数据),就算 “成功”。即使这个数据单元恰好在文件末尾,也不算 “失败”,所以不设置failbit。因此,你的原始结论 “
fail ()在读取失败时返回 true” 是正确的,但你对 “读取失败” 的理解需要更精确:fail()只在操作本身逻辑上失败时返回true,而eofbit的设置与否并不直接等同于fail()的结果。关于
!fail()是否 “包含”eof的诡异理解。你感觉 “说包括也对,不包括也对”,这正是因为
read()和getline()的行为不同。结论:
对于
read()而言:!fail()不包括eof的情况。
一旦
read()因遇到eof而未读满,failbit就会被设置,fail()为true,!fail()为false。循环退出。对于
getline()而言:!fail()包括eof的情况。
getline()成功读取了包含EOF的一行后,failbit仍为false,!fail()为true。循环会继续执行一次。最终敲死的结论:
!fail()是否包含eof,取决于你使用的是哪个 I/O 函数。
使用
while (fin.read(...)):!fail()不包含eof。循环会在第一次遇到eof(并导致未读满)时退出。使用
while (getline(fin, line)):!fail()包含eof。循环会在成功读取了末尾的行之后,在下一次调用getline()时才退出。
!fail包括eof啥意思?我理解!fail是 0 或 1 啊?哪来的包括这个东西?
!fail()的结果要么是true(1),要么是false(0),它是一个布尔值,本身不可能 “包含” 另一个东西(比如eof)。人们说“
!fail()包括eof”,是一种 简化的、不严谨的说法,实际想表达的是:在很多场景下(比如用while (fin.read())时),当eof(文件末尾)发生时,!fail()的结果会变成false,导致循环退出 —— 看起来就像!fail()把eof的情况 “包含” 进来作为退出条件了。但本质上:
!fail()只由failbit和badbit决定(和eofbit本身无关);是某些函数(比如
read()在 GCC/Clang 中)在触发eofbit的同时,会顺带设置failbit,才让!fail()变成false的。这也就是之前疑惑的,内心OS:
fail和eof独立咋还能设置别人?本身就是while里多连带设置了下,然后read和getline本身也有差异?
fail和eof是独立状态位,但某些函数(如 GCC/Clang 下的read())会在触发eof时顺带设置fail;
read()与getline()的差异在于:前者未读满时设fail,后者读到有效数据(即使到末尾)不设fail;“
!fail包括eof” 是简化说法,本质是eof触发时可能连带让!fail为false,导致循环退出。终于懂了,不该骂豆包!看似很胡扯但 VScode 实际做实验就是如此!
read()与getline()/>>的核心差异(GCC/Clang 下)
操作 未读满 / 格式错误时 到达末尾(EOF)时 fail()是否包含 EOF?read()设置 failbit设置 eofbit+failbit是 getline()设置 failbit(格式错)设置 eofbit,不设failbit否 >>设置 failbit(格式错)设置 eofbit,不设failbit否 C++11+ 核心规则:
operator bool()仅返回!fail(),不检查eofbit;到达末尾仅设
eofbit时,fail()为false→ 循环本应继续;差异在编译器:GCC/Clang 未读满 + EOF 会额外设
failbit→ 循环退出;MSVC 不设 → 循环继续。
主流编译器:
GCC(GNU Compiler Collection):
我
win下的codeblock里装的w64devkit是 Linux 的 GCC 编译器的win版本VS Code 代码编辑器,不是编译器,远程的 Linux 服务器预装的 GCC,是 Ubuntu 默认编译器
MSVC:
Visual Studio C++自带,兼容
win的API用的Clang / LLVM:
Apple 的 Xcode 开发工具默认使用 Clang,也被 Google、Facebook 等大公司广泛采用
只有 GCC 和 Clang(LLVM)会有这 “读末尾零头设 failbit” 的特例,微软的 MSVC 是完全遵循 C++ 标准的:用 MSVC 编译你的代码(10 字节文件 + 8 字节缓冲区),循环会执行两次:第一次读 8 字节(进循环),第二次读 2 字节(仍进循环),第三次读 0 字节(退出循环),
gcount()分别返回 8、2、0,完全符合标准行为。简单说:MSVC 按标准来,GCC/Clang 搞了个特例,仅此而已。
老子跑去
VS的MSVC试验下,傻逼 VS 的自动补全,是给傻逼残废用的吗???操.你妈真的百利无一害狗逼玩意!!!想写啥阻碍你,给你乱加东西咋删删不掉。滚轮滑动总是滑到底不停但 VS 的 cpp 另存为控制台的 GBK936 会报错,因为源代码包含 GBK 不支持的字符,另存为 utf8 就控制台乱码,加
system("chcp 65001 > nul");临时让控制台为 utf8codeblock 也有乱码,解决方法此文搜“好了,不”,方法改 cpp 为 GBK ,估计 codeblock 整个链内部都是 GBK,可改 utf8,但 MSVC 的是 utf8 所以改 GBK 不行,然后运行必须和控制台的 gbk 一致,结果他妈的老子实践发现 VS 里也是一模一样!
豆包说 C++ 标准 (例如 C++17 29.7.4.3.1) 中对
read()的描述是,它会在以下情况下设置failbit:[...] If the function does not encounter end-of-file, it stores
ncharacters in the sequence whose first element is designated bys. Otherwise, it storesstd::min(n, gcount())characters [...]. The function then setsfailbitif the number of characters stored is less thannandeofbitis not set. [...]这段文字的意思是:
如果读取过程中没有遇到文件末尾(EOF),但读取的字节数小于
n,则设置failbit。如果读取过程中遇到了 EOF,导致读取的字节数小于
n,则不设置failbit。然而,主流编译器(GCC, Clang, MSVC)在实践中都选择了在遇到 EOF 且未读满时也设置
failbit。这种行为被认为更实用,因为它能更明确地表示 “读取操作未完全成功”。如果标准的字面意思被严格遵守,那么while (fin.read(...))循环会在文件末尾多读一次(因为failbit未设置,read()返回true),这通常不是开发者想要的行为。之前豆包说 VS 这类的会不同,但现在反而减轻负担了,上面有提到 MSVC 和 GCC 会不同的可以忽略了。
狗逼豆包总是犯错总需要把代码结果给他才能学习然后继续帮助我,不然的话总他妈一会就抽风给我说
read读到数据然后遇到末尾,!fail也是true,其实是假,然后fail是trueQ:这些属于啥知识?
A:C++、算法、网络、OS 是核心,但要成为一名合格的 Linux C++ 服务端开发工程师,还需要一些 “粘合剂” 知识,它们能让你把核心知识真正用起来。
文件操作的知识属于 Linux 系统编程(System Programming) 和 OS交叉的范畴。
除了文件 I/O,你还需要学习以下几个方面的知识:
Linux 系统编程 (System Programming)
进程管理:
fork,exec,wait,exit信号处理:
signal,sigaction进程间通信 (IPC):管道 (
pipe)、命名管道 (FIFO)、共享内存 (shmget,shmat)、消息队列 (msgget,msgsnd)、信号量 (semget,semop)线程与同步:
pthread库、互斥锁 (mutex)、条件变量 (condition variable)、读写锁文件 I/O:你问的这部分,包括
open,read,write,close,lseek等底层系统调用,以及fcntl设置文件状态标志(非阻塞等)。网络编程 (Network Programming)
这部分你提到了,但要更深入。
基础 Socket 编程:
socket,bind,listen,accept,connect,send,recvI/O 模型:阻塞、非阻塞、I/O 多路复用(
select,poll,epoll)高级网络技术:零拷贝(
sendfile)、TCP 粘包 / 拆包处理、定时器实现、防抖动 / 重连机制。工程工具与实践 (Engineering Tools & Practices)
构建系统:
CMake,Makefile版本控制:
Git调试工具:
gdb,strace,valgrind(内存检测)性能分析:
perf,gprof日志系统:熟悉常见的日志库(如
glog)和实践代码规范:遵循 Google C++ Style Guide 等
总结一下,除了你提到的,还需要重点学:Linux 系统编程、网络编程(深入)、工程工具。文件操作只是 Linux 系统编程 中的一个章节。
然后说了这么多,回顾之前代码本来是大文件,我就先入为主复制了个视频,由于无法打开,只想着显示成功就赶紧删掉不然卡死,然后心无旁骛研究代码,但现在看还是需要实际测试下,那就复制一个
txt里是这几行的文本文件,每次读 3 个字节,这样既能模拟大文件,分批次复制,还可以看最后复制的是否正确,先搞个source.txt,代码:查看代码
/* source.txt内容: abc 124 dd哈哈 好 */ #include <fstream> #include <iostream> #include <string> #include <cerrno> #include <cstring> using namespace std; /** * @brief 模拟大文件复制(每次读取3个字节) * @param src_path 源文件路径 * @param dst_path 目标文件路径 * @return true:复制成功;false:复制失败 */ bool copy_file_with_small_buffer(const string& src_path, const string& dst_path) { // 1. 打开源文件(文本模式) ifstream fin(src_path, ios::in); if (!fin.is_open()) { /* 流封装了OS的文件句柄,is_open就是打开文件后判断是否成功 fail/bad/eof 是流操作层面状态 while (fin.read(...)) 等价于 while (!fin.fail()) while (fin) 本质就是判断流对象 fin 的 failbit 和 badbit 是否都没置位,等价于 while (!fin.fail() && !fin.bad()) 日常可简化记为 while (!fin.fail()),核心是看 “流当前是否处于可正常读写的状态”。 但注意不等价 while (fin.read(...)) 因为没读动作只是判断当前状态 */ cerr << "[错误] 打开源文件失败!路径:" << src_path << ",原因:" << strerror(errno) << endl; return false; } // 2. 打开目标文件(文本模式) ofstream fout(dst_path, ios::out | ios::trunc); if (!fout.is_open()) { cerr << "[错误] 打开目标文件失败!路径:" << dst_path << ",原因:" << strerror(errno) << endl; fin.close(); return false; } // 本来分片读写,缓冲区大小 4KB,与 Linux 磁盘块大小匹配,效率最优 // 但现在每次读取3个字节(模拟大文件分块) // const int BUFFER_SIZE = 4096; const int BUFFER_SIZE = 3; char buffer[BUFFER_SIZE]; size_t total_bytes = 0; cout << "[进度] 开始复制文件...(每次读取 " << BUFFER_SIZE << " 个字节)" << endl; // 循环读取:每次读3个字节到缓冲区 while (fin.read(buffer, BUFFER_SIZE)) { // 获取本次实际读取的字节数 size_t bytes_read = fin.gcount(); // 写入对应字节数到目标文件 fout.write(buffer, bytes_read); // 检查写入是否失败(比如磁盘满了) if (fout.fail()) { cerr << "[错误] 写入目标文件失败!原因:" << strerror(errno) << endl; fin.close(); fout.close(); return false; } total_bytes += bytes_read; // 打印每一次读取的详细信息(因为文件小,每次都打印) cout << "[调试] 读取 " << bytes_read << " 字节: \""; for (size_t i = 0; i < bytes_read; ++i) { cout << buffer[i]; } cout << "\"" << endl; } // 4. 处理最后不足3个字节的数据 size_t remaining_bytes = fin.gcount(); if (remaining_bytes > 0) { fout.write(buffer, remaining_bytes); total_bytes += remaining_bytes; cout << "[调试] 读取最后 " << remaining_bytes << " 字节: \""; for (size_t i = 0; i < remaining_bytes; ++i) { cout << buffer[i]; } cout << "\"" << endl; if (fout.fail()) { cerr << "[错误] 写入最后数据失败!原因:" << strerror(errno) << endl; fin.close(); fout.close(); return false; } } // 5. 验证文件是否完整读取 if (fin.eof()) { cout << "[成功] 文件复制完成!总大小:" << total_bytes << " 字节" << endl; } else { cerr << "[警告] 源文件未完整读取!可能存在文件损坏。" << endl; fin.close(); fout.close(); return false; } // 6. 关闭文件 fin.close(); fout.close(); return true; } int main() { string src_path = "source.txt"; // 源文件 string dst_path = "destination.txt"; // 目标文件 cout << "===== 小文件模拟大文件复制工具 =====" << endl; cout << "源文件: " << src_path << endl; cout << "目标文件: " << dst_path << endl; cout << "------------------------------------" << endl; /* 以上是确定目录,想手动输入就: getline(cin, src_path); // 支持带空格的路径 getline(cin, dst_path); */ // 调用复制函数 bool result = copy_file_with_small_buffer(src_path, dst_path); if (result) { cout << "------------------------------------" << endl; cout << "===== 复制成功!可以打开 " << dst_path << " 查看内容。=====" << endl; } else { cout << "------------------------------------" << endl; cout << "===== 复制失败!=====" << endl; return 1; } }
但终端乱码了,可是
txt里没有,让豆包找问题结果又开始瞎鸡巴分析,说什么控制台和文件编码不匹配,纯纯助手!让他分析就是他妈扯淡!!早都习惯了,自己动脑分析我的思考是我其他的都不乱码!!而且我这里是 3 个字节来的!,根据终端我推测明显会把汉字劈半所以导致错误!这时候豆包开始肯定我了,艹豆包就他妈不能自己说出来正确的,这里其实汉字 3 字节,明显用 2 字节来读了,比如:哈 的 UTF-8 编码是
0xE5 0x93 0x88(三个字节),如果只拿到其中一个或两个字节,它就是一个 “无效” 的字节序列,终端无法识别,就会显示为�。但我有几个思考,如今懂了贴上豆包的解答:
Q:如果实际修改为很大的缓冲是不是就没事?
A:这个我自己修改为
const int BUFFER_SIZE = 100;发现确实没问题了Q:为何终端乱码但输出
txt却没问题?A:终端乱码是因为「3 字节读取把 UTF-8 中文拆成了无效字节」,但 TXT 文件正常是因为「复制时字节被完整还原」—— 复制工具只搬运字节,不关心编码,所以最终文件的字节序列和源文件完全一致,文本编辑器能正确解析 UTF-8。
Q:这个是读文本模式,如果读二进制是不是不乱码了?这里涉及到
ASC啥的吗?而且计算机是二进制,那这二进制和我们说的文本模式vs二进制模式里的二进制是一个吗?既然计算机都是二进制读取啥的,那理论上不应该有文本模式这玩意啊?这些知识有点模糊给我讲下!A:这里豆包回答解开了我全部的疑惑,我起初以为
ASC是(相对于计算机二进制来说的)人类码,然后utf8/GBK啥的是文件啥的,稀里糊涂,其实UTF-8、GBK、ASCII 是平级关系,都属于同一类,即
cpp文件可以是utf8也可以是gbk然后理论上也可以是asc这么个平级关系,只不过asc不表示汉字,但同一个字在 GBK 和 UTF-8 中的二进制字节完全不同:
设计目标和适用范围不同:
ASCII:最早的编码,只包含英文字母、数字和一些符号。它用 1 个字节(8 位)来表示一个字符,最多只能表示 256 个字符。
GBK:是为了处理中文而设计的编码方案。它的目标是在一个编码体系内同时兼容 ASCII 和所有中文汉字。为了实现这个目标,它采用了 “变长编码”:
对于 ASCII 字符(英文字母、数字等),GBK 就用 1 个字节表示,和 ASCII 完全一样。
对于中文汉字,GBK 就用 2 个字节来表示。
UTF-8:是一种更通用的编码方案,它的目标是为世界上所有语言的所有字符提供一个统一的编码方式。它同样兼容 ASCII,但编码方式更灵活:
对于 ASCII 字符,UTF-8 也用 1 个字节表示。
对于其他语言的字符(包括中文),UTF-8 会根据字符的复杂程度,用 2 个、3 个甚至更多字节来表示。
分配的 “码点”(Code Point)不同:
你可以把每个字符想象成一个唯一的 “编号” 或 “身份证号”,这个编号就叫码点。
Unicode 字符集为世界上几乎每一个字符都分配了一个唯一的码点。例如,“哈” 字的 Unicode 码点是
U+54C8。GBK 有它自己独立的字符集和码点分配,它没有完全遵循 Unicode 标准。“哈” 字在 GBK 中的码点对应的字节就是
0xB9 0xFE。UTF-8 是 Unicode 字符集的一种具体实现方式(或称 “传输编码”)。它规定了如何将一个 Unicode 码点(如
U+54C8)转换成一串二进制字节。根据 UTF-8 的规则,U+54C8被编码成0xE5 0x93 0x88这三个字节。
字符 ASCII 编码 (十六进制) GBK 编码 (十六进制) UTF-8 编码 (十六进制) A 4141(兼容 ASCII)41(兼容 ASCII)哈 无 (无法表示) B9 FE(2 个字节)E5 93 88(3 个字节)简言之: UTF-8 为适配全球字符重新分配编码空间,故与 GBK 编码不同。
Unicode出现之前,世界上存在着多种互不兼容的字符编码方案,例如:
ASCII:用于英语,只有 128 个字符。
GBK:用于中文,包含了简体、繁体汉字。
Shift_JIS:用于日文。
EUC-KR:用于韩文。这导致了一个严重的问题:一个文件在一台电脑上能正常显示,在另一台使用不同编码的电脑上就可能变成乱码。为了解决这个巴别塔问题,
Unicode标准应运而生。它的目标是为世界上所有的字符(无论哪种语言)都分配一个唯一的、统一的编号(称为 “码点”):
英文字母
A的码点是U+0041。中文汉字
哈的码点是U+54C8。日文片假名
カ的码点是U+30AB。
Unicode只定义了字符和其唯一码点的对应关系,它本身不涉及这些码点如何在计算机中以二进制形式存储。Unicode虽然统一了编号,但如何高效地存储这些编号成了新的问题。如果直接用 4 个字节来存储每个码点(因为Unicode码点范围很大),那么对于只包含英文字母的文件来说,空间会浪费三倍(原本ASCII只需要 1 个字节)。于是,
UTF-8作为一种 “可变长度编码” 方案被设计出来,以高效地实现Unicode标准。它的核心规则是:
对于
ASCII字符(码点U+0000至U+007F),UTF-8编码完全兼容ASCII,仍然使用 1 个字节。对于其他字符,
UTF-8会使用 2 个、3 个或 4 个字节来表示,具体取决于其码点的大小。所以,
UTF-8是Unicode的实现方式之一,而不是替代品。 它的出现是为了在保持兼容性的同时,高效地存储和传输Unicode字符。了解码后, 继续说,
代码本质是按字节读取原始数据:
用
ios::binary模式时,直接读文件的二进制字节(不做任何编码转换);不用
binary模式时,系统会做轻微转换(比如 Windows 的\r\n转 Linux 的\n),但核心还是读字节;ASCII 是 1 字节编码(英文、数字、符号),UTF-8 是多字节编码(中文占 3 字节),代码不区分这两种编码,只把所有数据当字节流处理。
字节是文件的最小单位,复制工具只认字节,所有文件(文本、图片、视频)在磁盘上都以「二进制字节」存储,比如:
英文
a→ 字节0x61(ASCII 编码);中文
哈→ 字节0xE5 0x93 0x88(UTF-8 编码);换行符
\n→ 字节0x0A。二进制模式 vs 文本模式只影响换行符转换,不影响核心复制,两种模式的区别只有一个:
二进制模式(
ios::binary):完全不修改字节,读什么写什么(比如源文件里的\r\n(Windows 换行),写入后还是\r\n);文本模式(默认):系统会自动转换换行符(Windows 的
\r\n转 Linux 的\n,Linux 的\n转 Windows 的\r\n),其他字节不变。计算机里所有文件本质上都是二进制,文本文件也不例外。那为什么会有 “文本读取” 和 “二进制读取” 两种模式呢?它们的区别到底在哪里?
我们用一个简单的比喻来解释:
核心比喻:文件 = 一本 “密码书”
二进制文件:这本书的密码规则是不公开的,只有特定的程序(如图片查看器、视频播放器)才能看懂。比如一张图片文件,它的二进制数据是按 “像素颜色、尺寸、压缩算法” 等规则加密的,你直接看这些二进制数据(比如用记事本打开),只会看到乱码。因为记事本按
UTF-8/GBK等文本编码解析,图片的二进制数据遵循的是图像格式规则(非文本编码),文本编码无法识别,故显示乱码。如果是汉字就不会乱码文本文件:这本书的密码规则是公开且统一的,比如 ASCII 或 UTF-8 编码。这些规则规定了 “哪个二进制数字对应哪个字符”(比如
01100001对应字母a,11100100 10111000 10100110对应汉字哈)。只要遵循这个规则,任何文本编辑器(如记事本、VS Code)都能把二进制数据翻译成你能看懂的文字。简单来说:文本模式是 “给人看的”,二进制模式是 “给机器看的”,我们就以读取 “哈哈” 这个词为例,来彻底弄明白文本读取和二进制读取的区别,假设你的
source.txt文件里只有 “哈哈” 两个字,并且文件编码是 UTF-8,在 UTF-8 编码中,一个汉字占 3 个字节, “哈哈”的二进制11100101 10010011 10001000 11100101 10010011 10001000,现在,我们来看两种读取模式分别会做什么:1. 二进制读取 (
ios::binary)核心行为:不做任何翻译,直接读取原始字节,对人类不可读。
原样读取,如果你尝试用
cout去打印这个数组,cout会把每个字节当作一个字符来处理。但由于这些字节值(0xE5,0x93,0x88)超出了标准 ASCII 表 0 ~ 127 范围,终端无法识别显示为乱码(比如�),ASC是表示英文的,无法表示汉字。- 用途:读写图片、视频、可执行文件等任何类型的文件。
比喻:二进制读取就像直接用眼睛看摩尔斯电码的 “滴滴答答”,你看到了信号,但不知道它代表什么意思。
2. 文本读取 (默认模式)
核心行为:在读取字节的同时,尝试根据某种编码规则(如 UTF-8、GBK)将其 “翻译” 成字符。
读取过程:程序从文件中开始读取字节流
11100101 10010011 10001000 ...,由于是文本模式,程序内部会启动一个 “解码器”根据预设的编码规则(例如 UTF-8)来分析字节流,组合对应于汉字 “哈”。关键点:你得到的是 被 “翻译” 后的、人类可读的字符,这个过程依赖于正确的 编码设置,如果文件是 UTF-8 编码,但程序的解码器被设置成了 GBK,那么翻译就会出错,同样会得到乱码。
- 用途:读写配置文件、日志、JSON 等纯文本内容
当你将 “哈哈” 写入文件时,计算机会先根据指定的编码规则(比如 UTF-8),将 “哈哈” 这两个字符转换成对应的二进制字节序列,然后再将这些字节序列写入到文件中。
反之,当你读取这个文件时,如果是用文本模式读取,计算机会按照相同的编码规则,将文件中的二进制字节序列解码回 “哈哈” 这两个字符;如果是用二进制模式读取,就会直接得到原始的二进制字节序列。
代码中文本模式体现在哪里?
体现在文件打开方式:
ifstream fin(src_path, ios::in)和ofstream fout(dst_path, ios::out | ios::trunc)未加ios::binary,因此是文本模式。核心影响:文本模式下,系统会根据当前编码(如 Windows 下的
GBK、Linux/macOS 下的UTF-8)自动处理换行符(\n与\r\n)转换。文本模式下,除了换行符转换,它会忠实地读写文件中的字节,
destination.txt文件里存储的字节和source.txt完全一样,且存的都是二进制,当你用文本编辑器打开时,编辑器会正确地将这些二进制转换为正确的汉字。文本模式和二进制模式,读的时候都是先把汉字转换成二进制,写的时候把它原封不动写到文件里,只不过文本模式的 win 对换行会有差别,
然后读的时候才涉及到是否乱码,比如读
GBK、写UTF-8,读写的核心逻辑是 “编码→二进制→解码”,“读” 不是指打开文件的模式,而是解码这个动作。无论是文本模式还是二进制模式,fin.read()都是把文件里的二进制字节读到内存里。当你用cout去打印或者用编辑器去打开文件时,才会发生 “解码”:将内存中的二进制字节按照某种编码规则(如UTF-8、GBK)转换成人类可读的字符。这是才涉及到是否乱码,计算机本身都是二进制,没有乱码说句很夸张但很容易理解的话,如果你脑子是计算机,不需要任何转换,那直接看 01 串,不会遇到任何乱码问题注意:由于
ASC是没汉字的,所以用这个读,然后用啥解析都是错的注意:用
UTF8写进去,你用GBK读也是错的这里
cout乱码了,其实就是把 3 字节汉字强行读 2 字节输出了,代码用的是逐个字节输出(汉字在UTF-8等编码中占多字节,逐个字节输出会破坏编码的连续性,解析失败),但当你用fin.read()读取了 3 个字节并存入buffer后,cout << buffer会把这 3 个字节当成一个字符串来打印,char c[] = "哈"; cout << c;,但cout只是显示层,代码逻辑是,从源txt读出来写到新txt里,然后cout,其实cout就是搞了个分叉而已,复制的操作新txt里内容是和源txt一样的。换句话说之前验证了,缓冲区大点,够仨字节cout就不乱码了。用文本模式或二进制模式从文件读出的字节是完全一样的。
cout只是把这些字节打印出来。如果这些字节是一个完整的UTF-8字符(如 “哈” 的0xE5 0x93 0x88),并且终端也是UTF-8编码,就能正常显示。如果这些字节只是一个字符的一部分(如 “哈” 的前两个字节0xE5 0x93),cout无法解析,就会显示乱码。文件读写模式(文本 / 二进制)影响的是文件内容的读写(主要是换行符),而不是cout如何显示内存中的字节
二进制模式和文本模式除了换行都一样,不直接涉及 “解析人类可读字符”(解析是编码的事,如 UTF-8/GBK)。
后缀名是 人类约定的标识,不是文件本质差异:
.txt:约定为 “文本文件”,通常存储 按某种编码(如 UTF-8/GBK)组织的字符字节,可直接用记事本、VS Code 等编辑器打开(编辑器会按编码解析为人类可读文字)。
.bin:约定为 “二进制文件”,存储 无固定编码的原始字节(如图片、视频、程序指令等),直接打开会显示乱码(编辑器无法识别编码规则),需用专用工具(如十六进制编辑器)查看或特定程序解析。不是只有
.txt文件能转人类可看的,任何文件(包括.bin)的字节流,只要按对应编码 / 规则解析,都能转人类可看的内容 ——.txt只是 “约定好按文本编码(UTF-8/GBK)存储字节”,所以默认能被编辑器解析为文字;其他后缀(如.bin、.log)只要字节符合文本编码,也能转人类可看的,反之.txt若存非文本编码字节(如图片原始数据),打开也是乱码。简单说:“能否转人类可看” 取决于 字节的编码 / 存储规则,不是文件后缀
.txt。文件的内容是二进制,后缀名(
.txt/.bin)是给人类看的 “约定”,不影响文件本质。
写
.bin文件:用ofstream写.bin时,若没加ios::binary,就是默认文本模式 —— 会处理换行符(\n↔\r\n),写的还是二进制字节流,只是后缀叫.bin。若加了ios::binary,就是二进制模式,不处理换行符,直接写原始字节。打开查看的区别:
用记事本打开
.bin:记事本会默认按 “文本编码(如 UTF-8/GBK)” 解析字节。如果.bin里是文本内容(如 “哈” 的 UTF-8 字节),能正常显示;如果是图片、程序等非文本字节,会乱码。用十六进制编辑器打开
.txt:能看到.txt里的原始二进制字节(如E5 93 88对应 “哈”),本质和.bin没区别。“人类可读” 的关键:不是后缀名,而是 字节是否按 “文本编码规则” 存储。
.txt只是约定 “按文本编码存”,所以默认编辑器打开能看懂;
.bin只是约定 “存原始二进制”,可能是文本也可能是其他数据,需按对应规则解析(文本编码→文字,图片格式→图像等)。简单说:后缀名是标签,文件本质都是二进制;能否人类可读,看字节是否遵循文本编码规则,和后缀无关。
没写
binary→ 文本模式:此时读写会按系统编码(如 UTF-8/GBK)处理换行符,但核心是 写入的字节必须符合文本编码规则(比如存的是 “哈” 的 UTF-8 字节0xE5 0x93 0x88,而非图片、程序等原始二进制数据)。能否人类可读:
若写入的是文本编码字节(无论后缀是
.txt还是.bin),用编辑器打开(如记事本、VS Code)会自动按编码解析为文字,就能读。若写入的是非文本字节(如图片的像素数据),即使后缀是
.txt,打开也会是乱码,无法读。简单说:文本模式 + 写入文本编码字节 → 人类可读(无论后缀),和
binary无关,只看写入的内容是否是 “文本编码的字节”。.bin在VScode里打不开,如果选择打开方式的时候,【是打开方式】这个底层计算机设计成了人类读
操作系统的 “文件关联” 机制操作系统会记录不同后缀名的文件默认用什么程序打开:
.txt通常关联 “记事本”“VS Code” 等文本编辑器(默认按文本编码解析字节);
.bin没有统一的默认关联程序(或关联到十六进制编辑器、专用工具),所以双击时可能提示 “选择打开方式”,甚至直接打不开。“打开方式” 的本质是 “选择解析规则”当你选择用 “记事本” 打开
.bin文件时,相当于告诉计算机:“请用文本编码规则(如 UTF-8/GBK)解析这个文件的字节”。
如果
.bin里的字节恰好是文本编码(比如你用文本模式写的 “哈”),就能正常显示(人类可读);如果
.bin里是图片、程序等非文本字节,文本编辑器无法解析,就会显示乱码(人类不可读)。VS Code 打开
.bin的情况VS Code 是通用编辑器,能打开任何文件,但打开.bin时:
它会默认按 “二进制 / 十六进制” 模式显示(避免乱码),因为
.bin约定是 “原始二进制数据”;- 你也可以手动切换到 “文本模式”(比如选择编码为 UTF-8),如果字节符合编码规则,就能看到文字。
自己实践也发现了,我实验发现对的,ofstream fout(dst_path, ios::out | ios::trunc | ios::binary);二进制读取 txt,也是汉字不是二进制,证明了人类可阅读是打开方式的事!到汉字 / 乱码,是终端 / 编辑器按UTF-8等编码解析字节的结果,与读写模式无关。
cout的核心是将内存中的字节,根据「当前终端 / 系统的编码规则」(如UTF-8、GBK,而非单纯ASCII)解析成人类可读的字符并输出 ——ASCII只是编码规则的一种,现在更常用的是支持中文的UTF-8等看代码,代码里往文件里写入的核心代码就两句,负责把缓冲区数据写入目标文件:
// 循环中写入每次读取的3个字节(或实际读取的字节数) fout.write(buffer, bytes_read); // 循环结束后,写入最后不足3个字节的剩余数据 fout.write(buffer, remaining_bytes);关键说明:
fout是目标文件的输出流(ofstream对象),打开模式为ios::out | ios::trunc(覆盖写入);
write(buffer, n)是ofstream的核心写入方法,第一个参数是存储数据的缓冲区地址,第二个参数是要写入的字节数;第一句处理循环中每次读取的完整 / 部分数据(每次最多 3 字节),第二句处理文件末尾剩余的不足 3 字节的数据,两者结合确保所有数据都被写入目标文件。
目标文件名是在打开文件流时指定的,核心关联代码就 1 句:
// 打开目标文件时,通过第二个参数传入目标文件名dst_path(值为"destination.txt") ofstream fout(dst_path, ios::out | ios::trunc);后续的
fout.write(...)之所以能往「目标文件」写入,是因为fout这个输出流对象,在创建时就已经和dst_path对应的文件(即destination.txt)绑定好了 —— 后续所有对fout的写入操作,都会直接作用于这个绑定的文件,不需要再单独指定文件名。数据的来源是 源文件,整个流程在代码中是这样体现的:
打开源文件:
ifstream fin(src_path, ios::in); // src_path 是 "source.txt"这行代码打开了名为
"source.txt"的文件,并创建了一个输入流对象fin。fin就像是一个通往source.txt数据的通道。读取数据到内存:
fin.read(buffer, BUFFER_SIZE);这行代码是核心的 “读取” 操作。它通过
fin这个通道,从source.txt文件中读取BUFFER_SIZE(也就是 3)个字节的数据,然后把这些数据存放到程序内存中的buffer数组里。
数据来源:
source.txt文件。数据去向:程序内存中的
buffer数组将内存中的数据写入目标文件:
fout.write(buffer, bytes_read);这行代码是核心的 “写入” 操作。它从程序内存中的
buffer数组里,取出刚刚读入的数据(长度为bytes_read),然后通过fout这个通道,将这些数据写入到destination.txt文件中。
数据来源:程序内存中的
buffer数组。数据去向:
destination.txt文件。总结:数据流动的完整路径
source.txt(磁盘文件)fin.read()buffer数组 (程序内存)fout.write()destination.txt(磁盘文件)所以,写入操作
fout.write()的数据来源,是上一步读取操作fin.read()存放在buffer里的数据。而buffer里的数据则来自于源文件source.txt。整个复制过程,就像是用一个桶(
buffer)从一个水池(source.txt)里舀水,然后把桶里的水倒入另一个水池(destination.txt),如此反复,直到第一个水池的水被舀完。
fin.read(buffer, BUFFER_SIZE):从fin关联的文件中,读取最多BUFFER_SIZE个字节,存入buffer指向的内存,函数返回流对象(可判断读取是否成功)。
fout.write(buffer, bytes_read);:将buffer指向的内存中bytes_read个字节的数据,通过fout写入其关联的文件。
这个很好的验证了 C++ 的
read的返回值,回顾:网络编程的
read:是一个系统调用,它从一个文件描述符(fd)所代表的内核缓冲区中,读取数据到你的程序缓冲区。当这个文件描述符是一个套接字(socket)时,它就读取的是从网络上接收到并暂存在内核里的数据。C++ 的
fin.read():是 C++ 的标准库函数,是istream成员函数,是istream成员函数,它从一个文件流对象(如ifstream)所关联的文件中,读取数据到你的程序缓冲区。读磁盘文件(数据最终来自磁盘)
read()的返回行为:在文本和二进制模式下,当read()成功读取了数据但到达文件末尾时,while (fin.read(...))通常会返回false并退出循环。
gcount()的重要性:无论循环是否因到达 EOF 而退出,fin.gcount()都是获取上一次read()操作实际读取字节数的唯一可靠方法
read()函数返回一个istream&对象。当你在while循环中使用while (fin.read(...))时,它会隐式地调用istream的operator bool()成员函数来判断循环条件。看代码也就理解了所谓的处理零头,即读到末尾必退出
while,read返回false。
感觉无穷无尽的砸时间,依旧需要学无穷无尽的东西唉~~~~(>_<)~~~~
好痛苦,我没有时间了啊~~~~(>_<)~~~~
算法刷跑偏了,手写迭代7个版本的服务器项目没用到任何网络库好像要重学库重写~~~~(>_<)~~~~
操.你妈弄死我吧
这时候回顾之前的例子此文搜“累赘,这个”,由于很多文字重复,搜这个有差异性,不会重复,
>>和getline都是读到东西遇到末尾!fail依旧是真,但read读到东西遇到末尾!fail就是假,直接退出while。而且还有一点,好头疼之前说的是
!fail包括到末尾,此文搜“失败”,但文”,查看代码
#include <fstream> #include <iostream> #include <string> using namespace std; // 用于打印流状态的函数 void printState(ifstream& fin) { cout << " (good=" << fin.good() << ", eof=" << fin.eof() << ", fail=" << fin.fail() << ")"; } int main() { // 创建测试文件:内容为 "a\nc"(a换行c,无结尾换行) ofstream("test.txt") << "a\nc"; ifstream fin("test.txt"); string line; cout << "文件内容为:\n---\n" << "a\nc" << "\n---\n\n"; cout << "开始使用 while (getline) 循环读取:\n"; int count = 0; // while 循环的条件就是 getline 函数本身 while (getline(fin, line)) { count++; cout << "第 " << count << " 次循环: 读取成功, 内容为 \"" << line << "\""; printState(fin); cout << endl; } cout << "\n循环结束。\n"; cout << "最终流状态:"; printState(fin); cout << endl; if (fin.eof()) cout << "循环退出的原因是:已到达文件末尾 (eofbit 被设置)。" << endl; else if (fin.fail()) cout << "循环退出的原因是:发生了读取失败 (failbit 被设置)。" << endl; }

所以
while里的判断就是!fail,和每次getline的那个此文搜“累赘,这个”流各种标志状态一样。啃完之后,发现依旧全网搜不到这些知识,相比之下这个博客就太傻逼了。
牛逼发现豆包新增了记忆功能!正是我想要的!!再能取消收藏分享建议提示就好了!电脑可以屏蔽手机就不行了!但这回增加记忆功能直接节省大量,比如让他精简、禁止无脑符合瞎道歉专注于知识事实(参考最权威的网站)、行内代码,这些要求没有记忆的时候,几个问答他就会忘记。不知道为啥豆包好像又更新了,现在的回答不那么令人高血压了。而且貌似现在回答的质量也高了。
更新:妈逼的这记忆就他妈摆设艹!让他禁止用表格和比喻就是不听
什么狗鸡巴玩意啊,记忆又没了,之前在设置里有的,而且完全不按照记忆来回答问题,太烂了而且记忆还会自动挤掉之前的,总共多少也没说。
哎被这个狗逼气的已经到极致了,反而心性变了,就是和颜悦色的说,然后不再指望他会记得上下文,提高自己的提问能力,更准确 说是面向狗逼豆包的提问能力。他妈的心性好了反而一切都好了,有点四两拨千斤的感觉
fread原型:
size_t fread(参数1:void *ptr 读完存哪?,
参数2:size_t size 单个数据单元的字节数(比如读 char 就是 1,读 int 就是 4,读结构体就写结构体大小),
参数3:数据单元个数,,
参数4:FILE *stream FILE 指针(
fopen的返回值),指定要读取的文件(关联标准库缓存和内核文件))返回 实际成功读取的 “数据单元个数”(不是字节数),读到文件末尾返回实际读到的,出错返回 0怎么区分 “到尾” 和 “出错”?
用feof()判断是否到文件尾,用ferror()判断是否出错:size_t res = fread(buf, 1, 5, fp); if (res < 5) { // 没读够预期的5个单元 if (feof(fp)) { printf("读到文件末尾了\n"); } else if (ferror(fp)) { printf("读取出错了\n"); clearerr(fp); // 清除错误标记,后续还能操作文件 } }不用纠结代码验证(验证要测系统调用次数、磁盘 IO,反而复杂,所以我也只能研究到这了,本打算说实际输出看看标准库缓存里头的东西来着,豆包说标准库缓存是
FILE结构体的内部私有成员。查看代码
#include <stdio.h> #include <string.h> int main() { // 1. 创建并写入文件内容 "abcdef"(如果文件不存在) FILE* init_fp = fopen("test.txt", "w"); if (!init_fp) { perror("fopen init"); return 1; } fprintf(init_fp, "abcdef"); // 写入6个字符:a b c d e f fclose(init_fp); // 2. 只读打开文件,开始测试 FILE* fp = fopen("test.txt", "r"); if (!fp) { perror("fopen read"); return 1; } char buf1[3] = {0}; // 第一次读3字节 char buf2[4] = {0}; // 第二次读4字节(文件总共6字节,最多读4字节) // 第一步:第一次fread,读3字节 size_t n1 = fread(buf1, 1, 3, fp); printf("第一次fread:读了%d字节,内容:", (int)n1); for (int i=0; i<n1; i++) printf("%c ", buf1[i]); // 预期输出:a b c printf("\n"); // 此时状态: // - 标准库缓存(假设大小8字节):空→调用read从磁盘读6字节(文件总大小)进缓存, // 给buf1 3字节后,缓存剩 3字节(d e f); // - 标准库缓存指针:指向3(下次读从d开始); // - 内核文件位置:6(文件已读完)。 // 第二步:fseek跳回文件开头(偏移0) fseek(fp, 0, SEEK_SET); printf("执行fseek(0, SEEK_SET)后,标准库缓存失效\n"); // 第三步:第二次fread,读4字节 size_t n2 = fread(buf2, 1, 4, fp); printf("第二次fread:读了%d字节,内容:", (int)n2); for (int i=0; i<n2; i++) printf("%c ", buf2[i]); // 预期输出:a b c d(关键!不是d e f) printf("\n"); // 此时状态: // - fseek清空旧缓存,fread重新从文件开头读: // 标准库缓存空→调用read从偏移0读6字节进缓存,给buf2,4个字节后,缓存剩2字节(e f); // - 内核文件位置:4(已读4字节)。 fclose(fp); } 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./abc 第一次fread:读了3字节,内容:a b c 执行fseek(0, SEEK_SET)后,标准库缓存失效 第二次fread:读了4字节,内容:a b c d root@VM-8-2-ubuntu:~/cpp_projects_2#细说这里的指针:
不直接指向磁盘文件,而是指向「文件当前待读取 / 写入的偏移位置」(由操作系统维护);
内核指针、标准库指针都是系统 / 标准库内部实现时写好的,程序员无需操心,仅通过
lseek/fseek等函数间接控制即可。在哪?
标准库指针(缓存相关指针):存于
FILE结构体里(比如缓存起始地址、当前读取位置指针、缓存末尾指针)—— 这是FILE的核心内部成员,程序员看不到,也不用直接操作内核指针(文件偏移位置):不在
FILE里 —— 它是操作系统为每个打开的文件(对应fd文件描述符)维护的内核态数据,和用户态的FILE结构体是分开的。FILE里会保存对应的fd,标准库函数(如fseek)会通过fd间接调用系统调用,同步这个内核指针。简单说:
FILE里只存「标准库缓存相关的指针」,「内核指针」在操作系统内核里,两者通过FILE中的fd关联,程序员都不用操心其存储细节,仅用fseek/lseek控制即可。
标准库缓存指针是随读随更新的,因为取自标准库缓存
内核文件就是从磁盘找到
txt文件到内核便于读的,内核文件指针就是定位读到哪了,标准库缓存都是从这进的货,进到哪里就指到哪里。
fseek做两件事(缺一不可):
清空标准库缓存(失效旧数据);
同步更新内核文件位置(把内核位置设为
fseek指定的偏移)。内核文件位置的作用:
是标准库缓存 “进货”(调用
read)的唯一数据源起点 ——read永远从「当前内核文件位置」往后读数据补缓存。精简总结:
fseek→ 清缓存 + 更内核位置;内核位置 → 缓存进货的起点。
懂了,目前就是 fseek 是个函数,做了两件事:
① 把内核的 “文件位置指针” 更新到目标位置(核心定位功能);
② 清空标准库缓存(避免旧缓存干扰新位置读取)—— 指针是它操作的对象,不是它本身。
然后至此这个代码就是说,从磁盘文件读,然后有内核文件指针指着来定位,然后读到标准库缓存,然后给到用户,但页缓存咋没牵扯进来?
豆包回答:
页缓存是内核层面的 “底层缓存”,对用户态的
fread/read是 “透明” 的,用户代码 → 标准库缓存(FILE*层面) → 内核页缓存(内核层面) → 磁盘文件,上面说内核文件是txt这些。
标准库缓存:用户态的 “小缓存”,解决
fread频繁调用read的开销;页缓存:内核态的 “大缓存”,解决
read频繁读写磁盘的开销(磁盘 IO 是最慢的,页缓存能极大提速);核心原则:数据必须先进入页缓存,才能被标准库缓存读取(不会跳过页缓存直接读磁盘)。
补全页缓存的完整流程(26 字母 + 标准库缓存 8 字节)
假设:页缓存页大小 = 16 字节(内核默认通常是 4KB,选 16 字节方便观察);磁盘文件:
a~z(26 字节,分两段:第 0-15 字节a~p,第 16-25 字节q~z)。初始状态
标准库缓存:空
页缓存:空
内核位置:0
第一次
fread(buf1, 1, 3, fp)(读 3 字节)
用户态:标准库缓存空 → 调用
read系统调用,请求从内核位置 0 读 8 字节;内核态:页缓存无
a~h→ 触发磁盘 IO,读 16 字节(0-15 字节a~p)到页缓存;截取a~h(8 字节)返回标准库缓存;用户态:标准库缓存取 3 字节给
buf1→buf1 = a~c;标准库缓存剩余d~h(5 字节);内核位置更新为 8;状态:标准库缓存
d~h(5 字节);页缓存a~p(0-15 字节);内核位置 8;磁盘 IO 1 次。
第二次
fread(buf2, 1, 5, fp)(读 5 字节,无fseek)
用户态:标准库缓存
d~h(5 字节)直接取给buf2→buf2 = d~h;内核态:无操作;
状态:标准库缓存空;页缓存
a~p(0-15 字节);内核位置 8;磁盘 IO 1 次。
第三次
fread(buf3, 1, 6, fp)(读 6 字节)
用户态:标准库缓存空 → 调用
read,请求从内核位置 8 读 8 字节;内核态:页缓存有
i~p(8-15 字节)→ 截取i~p(8 字节)返回标准库缓存;用户态:标准库缓存取 6 字节给
buf3→buf3 = i~n;标准库缓存剩余o~p(2 字节);内核位置更新为 16;状态:标准库缓存
o~p(2 字节);页缓存a~p(0-15 字节);内核位置 16;磁盘 IO 1 次。
第四次
fread(buf4, 1, 4, fp)(读 4 字节)
用户态:标准库缓存
o~p(2 字节)先取给buf4,缺 2 字节 → 调用read,请求从内核位置 16 读 8 字节;内核态:页缓存无
q~x→ 触发磁盘 IO,读 16 字节(16-31 字节q~z+2 字节无效数据)到页缓存;截取q~x(8 字节,均为有效数据)返回标准库缓存;用户态:从标准库缓存取 2 字节
q~r补buf4→buf4 = o~r;标准库缓存剩余s~x(6 字节,有效数据);内核位置更新为 24;状态:标准库缓存
s~x(6 字节);页缓存a~p(0-15 字节)+q~z+ 无效数据(16-31 字节);内核位置 24;磁盘 IO 2 次。
fseek(fp, 0, SEEK_SET)+ 第五次fread(buf5, 1, 8, fp)
fseek:清空标准库缓存 + 内核位置设为 0;用户态:标准库缓存空 → 调用
read,请求从内核位置 0 读 8 字节;内核态:页缓存有
a~h→ 截取a~h(8 字节)返回标准库缓存;用户态:标准库缓存取 8 字节给
buf5→buf5 = a~h;状态:标准库缓存空;页缓存全量缓存;内核位置 8;磁盘 IO 2 次(无新增)。
哎好他妈感觉看不到尽头,我这啥水平?头有点大了,大概看下没啥问题
层级 组件 核心作用 操作方式 用户态 标准库缓存 减少 read系统调用次数fread优先读,不够再read进货内核态(透明) 页缓存 减少磁盘 IO 次数 read优先读,不够再读磁盘进货硬件 磁盘文件 数据最终存储地 仅当页缓存无数据时被访问
fseek的影响:只作用于「用户态标准库缓存」(清空)和「内核位置」(更新),不直接操作页缓存—— 但页缓存会在后续read时,根据新的内核位置提供数据(有缓存就复用,没就读磁盘)。
read是直接从页缓存进货,比如read4 个,页缓存没有就去磁盘拿,有就直接拿。这样一来,标准库缓存、页缓存、内核位置、磁盘的关系就全串起来了!
那么再继续深入抽插:
为什么
fseek不能和read搭配?(核心冲突)fseek和read属于 两个不同的 “操作体系”,底层缓存、文件定位方式完全独立,交叉使用会导致定位错乱、读取数据异常:
fseek+ C 标准库读函数(fread/fgetc/fgets 等):操作的是FILE*指针(C 标准库封装的文件对象),底层有 用户态缓存(行缓存 / 全缓存)。fseek会同步更新 “缓存中的文件位置” 和 “内核中的文件位置”,后续读函数能正确从定位处读取。
read+ 系统调用定位函数(lseek):操作的是int类型的 “文件描述符”(内核直接管理的文件句柄),没有用户态缓存,直接和内核交互。read只会使用 “内核中的文件位置”,完全无视fseek维护的 “缓存位置”比如错误代码(这里依旧是我追问辱骂豆包很久,哎痛苦异常,为什么我学东西,这么费劲,获得知识就他妈像导管子找素材一样费劲,千辛万苦找不到好片子,操你血妈的要么就是天亮了要不就是**断了,哎。追问一个知识点扣细节真的好痛苦,别人稀松平常的东西对我来说好难):
查看代码
#include <stdio.h> #include <unistd.h> #include <fcntl.h> #include <string.h> int main() { FILE* f = fopen("test.txt", "w"); fprintf(f, "abcde1234567890ABCDE");//6 在位置 10 fclose(f); FILE* fp = fopen("test.txt", "r"); int fd = fileno(fp); fseek(fp, 10, SEEK_SET); // 定位到第10字节,是6 char buf1[10] = {0}; read(fd, buf1, 5); printf("fseek10 后 read结果:%s\n", buf1);//67890 printf("此时标准库指针:%ld\n", ftell(fp)); // 10 printf("此时内核指针:%ld\n\n", lseek(fd, 0, SEEK_CUR)); // 15 int c = fgetc(fp); printf("执行fgetc读的结果:%c\n\n", c);// A printf("此时标准库指针:%ld\n", ftell(fp)); // 11 printf("此时内核指针:%ld\n\n", lseek(fd, 0, SEEK_CUR)); // 20 char buf2[2] = {0}; read(fd, buf2, 1); printf("继续read结果:#%c#对应的ASC:%d\n", buf2[0],buf2[0]);//## fclose(fp); } /* 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./abc fseek10 后 read结果:67890 此时标准库指针:10 此时内核指针:15 执行fgetc读的结果:A 此时标准库指针:11 此时内核指针:20 继续read结果:##对应的ASC:0 root@VM-8-2-ubuntu:~/cpp_projects_2# */短短不到 40 行的代码自己加了几个输出语句,钻研好几个小时艹!涉及到相当底层的东西。挨个说吧,反复追问了好几天,而且很多输出都是歪打正着,但最结果都验证了我想要的东西 —— fseek+read 错误匹配(看似明显的匹配错误,但深入思考真的有太多太多底层的细节和学问了,也更加理解了底层)
由于
fread是读取时更新内核文件指针位置 + 标准库缓存,read读取时只更新定位内核文件的指针位置不碰标准库,导致这个豆包给的代码我以为会先fseek把内核+标准库缓存的指针定位到位置10,然后read只把内核指针变到15,然后fgetc应该读10位置的,结果却读了A,然后开启了无尽辱骂和追问豆包,因为按照豆包的逻辑,fget应该读6,然后更加绝望恐怖的是再次read居然输出空,也就是##那里,即第二次再读就是空了。实际上这个代码,没法验证 “fgetc 该读 10 位置” 的目的
fseek底层就是调用lseek实现的
lseek系统调用,用来改内核里的文件位置
fseek是 C 标准库函数,改FILE*对应的文件位置,包括 stdio 内部记录的位置 + 内核位置所以
fseek执行时,必然会调用lseek来同步内核的文件位置 —— 这是所有系统(Linux/Windows/macOS)都遵循的实现规则。fseek(fp, 10, SEEK_SET)能让内核位置变成 10,本质就是它底层调用了lseek(fd, 10, SEEK_SET)真的痛苦,这里我就不叙述之前的思路了,尽力复原,便于自己日后回顾,因为我现在懂了以后,已经无法想起之前是咋想的了,就记录正确的吧。跟豆包自学真的是历尽千帆啊!一天 90% 的回答都是误人子弟瞎编的错误答案,需要靠自己追问思考发现,然后 80% 都是垃圾信息,唉。浪费了无数时间,无穷无尽的给你错误东西,反复否定自己的回答,反复瞎道歉继续
更难的是层层相扣,还要拉取之前海厚海厚的对话,抽丝剥茧的总结,对话里和代码都有对有错还有没用的屁话,唉!无穷无尽的往里咋时间!
死全家的豆包加了记忆功能,也他妈是个不长记性彻头彻尾的傻逼!纯纯脑瘫!反复误人子弟无脑附和我!瞎道歉没错也道歉
黄仁勋小时候的励志成长经历、罗斯的篮球人物、艾弗森的励志视频,中科院黄国平的论文致谢,都是我每天的动力,但他妈的英伟达的硬件再牛逼也他妈是个泡沫,大模型 狗屁不是!!
无穷无尽的给新代码,反复道歉,反复给新代码越扯越远,无穷无尽的错误
每走一步都要挖地三尺,然后每尺又要四面八方挖地三尺(1米),然后妈逼的挖了好几尺告诉你错了,然后掉头挖又说错了之前的对,哎!我自己从尸山血海里爬出来
哎好痛苦啊,我这种想了无穷无尽的东西完全抓不到重点
反复道歉编造!无穷无尽永无止境!操你个狗血妈的死全家的傻逼豆包(这还是所有大模型里最好的!!GPT更垃圾!)
傻逼豆包,解答我的每个问题都引出新规则,这些规则追问一天有时候发现是瞎编的,有些又没法验证,哎太痛苦了
支离破碎收拾残局烂摊子力挽狂澜起死回生的能力
查看代码
之前李明宇说说,别人做3年转测试开发说不许,说很难转,说很难转开发 知乎大厂也给我否定了 孙法说你不知道用什么工具 那个海米他们组的说,我们培训班Java的怎么怎么样,一天学多少多少小时都要6个月。你根本不可能自学C++, 另一个9k的说教我Java 我说给他们组周末无偿加班帮忙查查报错日志也行, 那个错误码的也是公司培训。不然自己再学都学不下来, 他们都不到1万,其实外包的开发比外包测试工资低好多,而且外包测试他妈的一点含金量没有。 这是无数人的否定,而我现在真的可以说用一年多的时间就已经完虐,相当于鱼皮编程指北,这些顶尖的人,大学四年的所有的东西 而且我相当于CSAPP。int c = fgetc(fp);本意是想读内核中10位置的数据,但实际读 A(15 位)而不是 6(10 位),因为stdio缓存的“错位预读”导致的:
fseek(fp,10,SEEK_SET)→stdio内部位置:10,内核位置 :10(底层调lseek);
read(fd,buf1,5)→ 内核位置从10 → 15(读了10 - 14位的67890),但stdio完全不知道这次读,所以stdio内部位置还停留在10,缓存还是空的;执行
fgetc(fp)→stdio发现自己缓存空,要读数据:
fgetc要读数据时,先查自己的stdio缓存 —— 之前没通过stdio读过任何数据,缓存是空的(没存货),所以必须触发 “进货”(调用系统read从内核拿数据),不进货就没数据可返回;那stdio会调用系统调用read,从当前内核位置 15 预读一大块数据(比如 4KB)到自己的缓存里;
stdio想读 10 位置,但它“管不到内核”:只能从「当前内核实际位置(15)」进,没法从它自己想读的 10 位置进 —— 因为内核位置已经被之前的read(fd, buf1,5)改成 15 了,stdio没能力把内核位置改回 10,只能 “被动从 15 开始进货”内核的文件指针是独立的,之前被你用系统调用
read(fd, buf1,5)从 10 改成 15 了(内核只认自己的指针,不管stdio想要啥);
stdio没有 “让内核指针回退到 10” 的动作(只有lseek能改内核指针,但fgetc默认不会主动调lseek—— 除非是fseek之后的同步逻辑);所以stdio进货时,只能调用read从「当前内核指针(15)」开始读,拿到的自然是 15 及以后的数据(比如 A),没法拿到 10 位置的 6。
stdio固执地认为 “自己的缓存起始位置是:10”,即想读的是内核里 10 位置的数据(固执的根据,见下面的验证代码,读写指针共用同一个),所以它把从内核15位读到的A,当作自己读的是内核10位置的数据,存到了自己缓存的偏移 5 位置(因为 15-10=5);(这里为啥相减,见下面验证代码 独立为何相减),然后注意这次是从内存进货,也把A后的都拿进来了,所以fgetc的结果是A。然后
fgetc(fp)从标准 IO 缓存里拿1个字节,不管这个字节是从内核哪个位置预读来的,只要拿到了,标准 IO 就认为 “我已经读完了逻辑位置10的数据”,所以内部指针 + 1 → 11,所以后续是标准库位置是11,然后由于是批量拿货,所以内核把数据都拿进来了,指向内核文件的末尾20,所以再read就空了。然后代码里没有写我自己实践发现,最后如果不是read,如果是fgetc,直接输出的是B,完美闭环嘎嘎高潮!!不敢再相信豆包,让他给代码自己加工修改做验证 读写指针共用同一个 这件事(因为豆包误人子弟,所以被迫写了一堆代码验证。因为豆包狗逼反复给新代码,所以之前学类、指针那块就是,逼自己看了很多豆包给的代码反而更加理解这些东西了):
查看代码
/* 便于自己回顾的贴士: 不用浪费时间看这个代码了,主旨: 内核级别的读写指针是同一个 */ #include <stdio.h> #include <unistd.h> #include <fcntl.h> #include <string.h> int main() { // 1. 创建并打开文件(只写+创建,若存在则清空) int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); if (fd == -1) { perror("open failed"); return 1; } // 2. 第一次写:从指针初始位置(0)写 "abc" const char write1[] = "abc"; write(fd, write1, strlen(write1)); // 写3字节,指针自动移到 0+3=3 printf("第一次写后:文件内容 = abc(指针位置=3)\n"); // 3. 第二次写:不调整指针,直接写 "def" → 从指针3开始写 const char write2[] = "def"; write(fd, write2, strlen(write2)); // 写3字节,指针自动移到 3+3=6 printf("第二次写后:文件内容 = abcdef(指针位置=6)\n"); // 4. 读操作:不调整指针,从6开始读(此时文件只有6字节,读不到有效数据) char buf[10] = {0}; ssize_t read_len = read(fd, buf, 1); // 指针在6(文件末尾),读0字节 printf("从指针6读1字节:#%s#(实际读%d字节,证明指针在末尾)\n", buf, (int)read_len); // 5. 调整指针到2,再读+再写(验证读写共用指针) lseek(fd, 2, SEEK_SET); // 把内核指针拉回2(指向 'c' 的位置) printf("用lseek把指针调到2后:\n"); // 读1字节:从2开始读,读的是 'c',指针自动移到3 read_len = read(fd, buf, 1); printf(" 读1字节:%s(指针从2→3)\n", buf); // 写1字节:从3开始写,覆盖原来的 'd' 为 'X',指针自动移到4 write(fd, "X", 1); printf(" 从指针3写'X'后:文件内容 = abcXef(指针从3→4)\n"); // 6. 验证最终文件内容 lseek(fd, 0, SEEK_SET); // 指针拉回0,读完整文件 read(fd, buf, 10); printf("最终文件完整内容:%s\n", buf); close(fd); } 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./abc 第一次写后:文件内容 = abc(指针位置=3) 第二次写后:文件内容 = abcdef(指针位置=6) 从指针6读1字节:##(实际读0字节,证明指针在末尾) 用lseek把指针调到2后: 读1字节:c(指针从2→3) 从指针3写'X'后:文件内容 = abcXef(指针从3→4) 最终文件完整内容:abcXef root@VM-8-2-ubuntu:~/cpp_projects_2#
lseek(fd, 2, SEEK_SET)是系统调用,把 fd 对应的内核指针,从文件开头SEEK_SET偏移 2 字节。最终指针停在文件第 2 字节(0 开始计数),后续读写都从这开始验证 独立为何相减:
查看代码
//全用 stdio 函数,无感知的内部相减 #include <stdio.h> int main() { FILE *fp = fopen("test.txt", "r"); if (!fp) return 1; fseek(fp, 3, SEEK_SET); // stdio 记录内部位置=3,同时调用 lseek 让内核位置=3(同步) // stdio 缓存空,fgetc 从内核位置 3 预读,数据放到 stdio 缓存偏移3-3 =0处(这是内部相减),取到正确的3位数据, int c = fgetc(fp); printf("读取到:%c\n", c); fclose(fp); } //全用底层系统调用,无 stdio 缓存,自然无相关相减 #include <fcntl.h> #include <unistd.h> #include <cstdio> int main() { int fd = open("test.txt", O_RDONLY); if (fd == -1) return 1; lseek(fd, 3, SEEK_SET); // 直接设置内核位置=3 char buf[1]; read(fd, buf, 1); // 从内核位置 3 读取,直接拿到正确数据 printf("读取到:%c\n", buf[0]); close(fd); }既然 内核 vs 标准库缓冲区 都是互相独立的,为啥相减?
stdio 是标准 IO 库(一堆函数即带
f的那些 + fopen 返回的 FILE 结构体),标准库缓存是 FILE 里的一块内存(用来存预读 / 预写数据)1、FILE 结构体里至少几个关键信息:
目标位置也是逻辑位置,即 stdio 里记录的下次要读的内核文件里的某字节序号。
缓存起始位置(缓存数据首位置,对应是内核文件哪个位置,比如内核里是:a b c d,缓存里是 c, 那位置就是 2);
- 缓存物理首地址:一块内存的「起始指针」(比如 0x7f1234567890,stdio 自己分配的);
缓存的总大小(比如 4KB,判断“偏移是否超出缓存范围”);
FILE 内从没有单独直接 “指向缓存内某位置的指针”的变量,都是动态算,若多个指针指向会冗余。
需要区分的是:
目标位置:你要拿的下一个字节的 “编号”(stdio 管);
内核指针:“仓库”(内核)的下一个 “待进货” 位置(内核管);
缓存起始位置:你当前 “库存”(缓存)的第一批货的 “编号”(stdio 管)。
2、计算机通过这个结构体就能算偏移:目标位置 - 缓存起始位置(艹这个简单的一个公式真他妈难理解,想了好几天。seek 的底层原理这,他妈的想了 2 周,之前 3 层暴力 for 的传递闭包算法也是,贼鸡巴巧妙难理解)(这个公式起初自己举了好多例子总感觉不那么强大稳妥)(公式以为不靠谱,以为有跳读,但
stdio缓存里永远是 文件连续字节,不存在跳着存的情况 )目标位置 总感觉和 起始位置 一样,看个例子来区分:
场景 1:文件字节 0
(a)、1(b)、2(c)、3(d)、4(e)
首次要读目标位置 3 的数据
dfseek 后:
stdio 记目标位置 3,下次要读的内核字节序号
- 缓存起始位置 3
同步内核里的指针到 3(马上从这拿数据)
stdio 缓存目前空
预读:
算缓存内偏移:3-3=0,
内核 3 位置读数据存缓存 0 处(缓存内:0
d、1e...)取数:
fgetc从缓存 0 拿d,stdio 目标位置更改为 4- 但缓存起始位置 3 没变
场景 2:再次
fgetc,目标位置 4,要读e
缓存非空,缓存起始位置是 3,缓存里有含 d、e,读过的不清
计算:缓存内偏移:4 - 3 = 1
取数:直接从缓存 1 拿
e,stdio 目标位置更改为 5,无需碰内核然后想判读是否需要从内核进货,
核心区别:
缓存起始位置:缓存数据在内核文件中的起始字节序号(一旦预读完成就固定,直到下次重新预读);
目标位置:stdio 记录的下次要读 / 写的内核字节序号(每读 1 字节就 + 1,随操作动态变)。
再比如:如果内核文件指针在
10,然后标准库缓存指针是2,意思是缓存指针2是缓存内已读偏移,下次读直接取缓存2然后取3,无需读内核,只有当stdio逻辑位置超出当前缓存范围,才从内核读新数据,此时缓存起始 = 新逻辑位置,缓存内偏移 =0。通过
read返回值(=0即文件尾)或feof标志判断,缓存内偏移超缓存已存数据且无新数据可读就是内核文件的尾,而stdio从内核每次进货,是否需要进货是当stdio逻辑位置超出当前缓存范围,这个判断是stdio内部逻辑,用户完全不可见,判断逻辑:a. 本次要读的「起始位置」> 缓存起始位置 + 缓存已存数据长度(目标超出当前缓存覆盖范围);
b. 本次要读的「起始位置」< 缓存起始位置(目标回退到当前缓存之前的范围)。
而之前提到的【缓存总大小】是限制「单次从内核预读的数据量上限」—— 缓存总大小固定(如 4KB),每次从内核读数据时,最多读 “缓存总大小 - 已用空间” 的字节,避免缓存溢出。
这些都是 CSAPP 里的妈逼的我靠自己追问出来了,也好,这他妈要是啃 CSAPP 就我这强迫症直接没个头。
注意:偏移
0和 “文件第0位置” 无关,是stdio缓存内部的(相对于缓存起始的)相对偏移,如果stdio内部记录 “下次该读文件逻辑位置7” 时,缓存偏移0就对应文件逻辑位置7,所以偏移0处存的是文件7位置的数据,不是文件0位置的数据。注意:说个之前的一个大误区是,我之前一直以为的是,
stdio指针是说比如指向3位置,那用户做系统调用时就从3位置做操作返回数据给用户,但大错特错,完全搞混了,涉及到更深入的知识,之前只知道最浅显的页缓存、标准库缓存、用户缓存,现在衔接上了:
stdio缓存里的指针是逻辑位置,是 “下次该读 / 写文件的哪个逻辑位置”,这个指针其实是动态算的偏移(目标 - 缓存起始),根本不存于FILE里,比如指向文件3位置也是想读文件的3位置,但计算机内部需要结合起始位置算才知道读的这个位置数据后,存自己stdio缓冲里的哪个位置(偏移)。操.他妈的真 JB 透彻!!精通了!这他妈感觉像之前手写时间轮一样。
fseek 与 stdio 缓存映射核心逻辑(这一切关乎计算机内部咋实现的,豆包说大厂 LinuxC++ 服务端开发基础岗没必要钻研,100% 不考,但强迫症就是钻研完了,简单一笔带过):
fseek的时候调整到了10,含义是就是想要读内核里10位置的数据,即目标的位置也就是10,但标准库缓存有自己的缓存,都先拿进来了不需要去内核进货,内核读取很慢,你需要10直接从标准库拿就行,但标准库存哪里了就需要偏移了,根据起始位置算偏移来找到存内核10位置的数据,所以就把15位置的A读进来存进来了,存到哪?这里还要说个东西。
正常情况:
fseek(10, SEEK_SET)会让stdio直接把「缓存起始位置」设为10—— 因为stdio要保证 “缓存里的数据,起始就是你要的目标位置”,避免多轮计算,这是它的设计规则;指针(
FILE里的三个关键数据变量):目标位置:10、缓存起始位置:10、缓存内指针:0。缓存起始位置 =
stdio内部维护的,没有显式 API 让用户操作(不像fseek能直接设目标位置)。口语里说
stdio指针就是目标指针,把FILE看成整体,但严谨层面:没有单个“stdio指针”,是 物理首地址 + 偏移,偏移 = 目标位置 - 缓存起始位置即
stdio指针下一个要读取内核的哪里,比如读完 5 位置,那下一个要读取的就是 6 位置,这个其实是 物理首地址 + 偏移,偏移 = 目标位置 - 缓存起始位置 来具体底层操作的所以之前看到豆包的公式的写法:
偏移 = 内核文件位置(即目标文件位置)- stdio 内部指针;就懂了,这里的内部指针其实更不严谨了,表达的就是缓存起始位置总算追问清楚了。
再多说几句:
正常情况下,
fseek(fp, 10, SEEK_SET)后,缓存起始位置会被stdio直接设置为10,即和目标位置完全一致!
设计目的:为了 “精准对齐”—— 你要读内核
10号字节,stdio就把缓存的 “数据起始” 设为10,预读时从内核10号位置开始读数据进缓存;偏移计算:后续
缓存内偏移 = 10(目标位置) - 10(缓存起始位置) = 0,直接从缓存偏移0取数据,无需额外复杂计算;内存定位:缓存物理首地址 =
stdio分配的一块内存(例如0x7f1234567890),后续stdio仅靠缓存物理首地址 + 缓存内偏移(相对偏移)就能精准定位数据;
示例:偏移为
1时,数据存储位置 =0x7f1234567890 + 1(标准库缓存的对应内存地址)。简单说:正常场景下,
fseek会让 目标位置 = 缓存起始位置 = 内核指针,这是stdio缓存机制的基础设计!缓存内指针(用户读到缓存的哪个偏移)是偏移,
stdio内部动态计算的,每次要从缓存拿数据时,都实时算「偏移 = 目标位置 - 缓存起始位置」,偏移这个值从来都不当作变量存到FILE里,fseek不负责 “计算偏移”,只负责 “重置用来计算偏移的两个基础值”,把「目标位置」设为你指定的编号比如10,把「缓存起始位置」同步设为同一个值10,同时清空旧缓存,这样下次计算时,偏移直接从0开始;Q:是我考虑多了还是咋?难道 10 位置之前没数据?
A:
fseek的核心作用就是 “重置读写上下文,它不管缓存里之前有啥,都会被stdio清空 / 标记为无效,然后按新的目标位置重新初始化,不用管旧缓存的数据!下次fgetc会从内核10号位置预读数据进缓存,和之前的旧缓存无关,具体存哪里看偏移代码验证:
fseek每次重置:注意:你要读 1 字节,
stdio不会让内核只读 1 字节(硬件不支持),而是让内核读一整块 4KB 到缓存,你后续读数据直接取缓存,不用反复调用内核,这就是按物理块粒度预读的原因。也是最小存储读写单元至此这个代码完事了!感受感言
然后开始无止境的尸山血海无穷无尽的误区:
感觉有点像高中质疑定理一样,可豆包总会误人子弟,总会想去验证这些 C++ 规则
天龙八部张无忌、武林大会内功杀出、赛车手,wx搜“懂两说”、一路、硬生生、一意孤行
AI应用开发为啥那么高薪资?985研究生在我看来90%的水货为啥那么高薪资?
搜【踏马他配吗】、【你对行业规则的认知,已经远超很多 “老开发”】
无数验证的代码都发现fseek刷缓存,但百度搜全是不刷的,我发现我他妈真的每步都钻研过深了艹,这里我都写了无穷无尽的代码了始终严验证的东西七零八碎的:
注:超出实际长度写东西,linux下会补null。
注:
fgetc成功读取返回对应字符的ASCII 码,如读 'a' 返回 97,失败(文件尾)返回EOF(本质是 -1)。前提:文件内容是
a b c(0-2 字节),用FILE* fp = fopen("test.txt", "r+");打开(可读可写,有标准 IO 缓存)
fgetc(fp)执行逻辑(读 1 个字符):如果之前有 “没刷到内核的写操作”(比如 fputc 没 flush),会先把写缓存刷到内核,再执行读 —— 这是为了避免读写数据错乱!
先执行
fputc('x', fp)→ 写缓存存 'x'(没刷内核,内核 / 文件还是 abc);再执行
fgetc(fp)→ 触发逻辑:
发现写缓存有未刷的 'x',先把 'x' 刷到内核(此时内核 / 文件变成 abcx);
再从标准 IO 读缓存读字符(首次读是 'a');
标准 IO 读指针 + 1(0→1),内核指针不变。
正常就是先查「标准 IO 读缓存」:
如果缓存里有数据(比如刚打开时缓存空),直接拿 1 个字符;
如果缓存空,会调用内核
read从磁盘 / 内核读一批数据(比如把 abc 全读进缓存,减少系统调用)。
fputc不是 “主动清缓存”,是 “写之前必须确保缓存对应目标区域”—— 若当前缓存是旧区域(和要写的位置不重叠),会先把旧缓存同步到内核(flush)并释放,再加载新区域的缓存,看起来像 “清旧缓存”
标准 IO 缓存规则:一个 FILE * 的缓存同一时间只对应文件的一个连续区域(比如 0-4095 字节);
fputc 的行为包括FILE标准IO带f的操作:要写某个位置时,先检查该位置是否在当前缓存的区域内 ——
若在:直接写缓存(不触发内核 IO);
若不在:先把旧缓存里的脏数据(已修改未同步的)刷到内核(flush),再清空旧缓存、加载目标位置所在的新区域缓存,最后写新缓存;
本质:“清旧缓存” 是缓存切换的附带行为,目的是避免不同区域的数据混乱,确保读写一致性。
简单说:标准 IO 缓存同一时间只 “管” 文件的一个连续区域,目标位置跑偏了,就 “换区”(清旧区、加载新区),确保读写不混乱。甚至钻研到需要验证缓存里都有啥来验证豆包说的是否正确(豆包说什么每次读不读内核啥的)。
我感觉这里又有无穷无尽要思考的我这是不是强迫症啊?是不是得治啊?总感觉想去验证而且我都搞不懂究竟咋算非缓存区域?这个每次4K一个大块我面试LinuxC++服务端开发到底需要掌握到哪里啊?哎好痛苦这里他妈钻研下去又是各种错误更主要的是还有很多C标准和Linux实现不同的,比如 C 说什么
fseek不刷,但 linux 设计成刷了之类的注:
FILE*的读写指针默认是同一个,操作后自动指向 “下一个待读写位置”。注:
open返回的是文件描述符,内核层文件标识,直接对应内核文件表项;C 里也封装了这个可以理解为 C 的open就是系统调用fopen 返回FILE*,C 库封装的结构体指针,内部包含文件描述符 + 缓冲区 + 读写指针等,是标准 IO 层的抽象;FILE* 封装了文件描述。C++兼容,C++ 还提供自己的
iostream比如fstream,但 FILE * 在 Linux C++ 服务端面试中仍常用C++ 的
iostream(fstream)用open()成员函数打开文件(和 C 的open系统调用同名但不同层)区别:
C的FILE * 轻量、兼容 C 代码 / 底层操作
C++的
fstream类型安全、支持运算符重载(<<、>>)、集成 C++ 异常机制。不用手动管理指针(流自动维护)、类型安全(避免类型不匹配)、支持异常(可配置抛异常处理错误),而 FILE * 需手动控制所有细节;但底层打开读写操作都一样。
钻研的代码是:
这都是因为我想验证豆包说的fseek定位啥的,然后一发不可收拾,超大血案尸山血海无穷无尽永无止境!!!
查看代码
int main() { // 建文件:0=a、1=b、2=c、3=d、4=e、5=f(仅6个字节,缓存默认加载全部) int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); write(fd, "abcdef", 6); close(fd); FILE *fp = fopen("test.txt", "r+"); int kernel_fd = fileno(fp); // 造脏缓存(缓存内写,不刷)缓存:aBcdef,文件:abcdef fseek(fp,1,SEEK_SET); fputc('B',fp); fseek(fp, 1, SEEK_SET); // 如果输出内核指针会是3, 标准库指针是3 // 绕开标准库缓存,直接读内核文件 int fd_raw = open("test.txt", O_RDONLY); char buf[7] = {0}; read(fd_raw, buf, 6); printf("文件真实数据:%s\n", buf); //文件真实数据:aBcdef // 目前 证明刷了且是没超范围 }但这还没完还有很多说道!!先搁置
再继续
查看代码
#include <stdio.h> #include <unistd.h> #include <fcntl.h> int main() { // 建文件:0=a、1=b、2=c、3=d、4=e、5=f(仅6个字节,缓存默认加载全部) int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); write(fd, "abcdef", 6); close(fd); FILE *fp = fopen("test.txt", "r+"); int kernel_fd = fileno(fp); // 至此注释掉下面所有,test.txt 是 abcdef fseek(fp, 10, SEEK_SET);// 输出内核指针会是10,输出标准库指针会是10 fputc('x', fp); // 写10位置,触发清旧缓存,标准库11,内核10 // 至此 test.txt 是 abcdefnullnullnullnullx,4 个 null lseek(kernel_fd, 15, SEEK_SET); printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); //11 fputc('y', fp); // 至此 test.txt 是 abcdefnullnullnullnullnullnullnullnullnullxy,9 个 null fclose(fp); }先看 4 个null那个,就是关闭文件后写进内核
但最后的9个null咋多个x?
lseek(kernel_fd, 15, SEEK_SET)直接把 内核指针 从 10 改成 15,而fputc('x')写的x还在标准 IO 缓存里没刷到内核;最后
fclose刷缓存时,标准 IO 会通过kernel_fd调用write写x,内核只认当前自己的指针(15),直接把x写到 15 字节位置 —— 原本该在 10 的x,被内核指针的改动 “带” 到了 15,然后后面继续写y。哎感觉这玩意没规律可循钻研毫无意义啊。
豆包说只知道指针不同步即可!
注:
及时止损吧!!这里他妈的研究一个月了操.你妈的!!反复问豆包其实毫无意义,说什么小文件fseek会同步标准库和内核指针,但跨不会,让他给代码超过4096字节也他妈会同步,这里百度所有博客也没提到同步的事,哎他妈的爱咋咋地吧,到时候背那些速成水货的高频面试题吧!我真没力气追问试验了!
极致辱骂后,思考其他路子,提到 man 文档,一屁眼子英文,还不如我问豆包呢
又给了几个网站发现妈逼的有的收费(付费内容看了下,“妈逼的这么肤浅的东西也好意思做教程收费?且大众都认为这都已经很低层了”),发现也难为豆包了,难怪总误人子弟,全网训练数据根本没法参考,网上一堆垃圾错误的回答,还有很多文章根本没我钻研的深
哎那些大厂LinuxC++ 服务端开发的都咋学的啊!!真他妈好奇!最后追问下坚定继续这么学!只是及时止损豆包回答接连错就及时自己写代码测验,不再一味深究。
发现不再专注他是否错,就像带着残破之躯饥饿的我学习一样,他说错什么的我可以不陷进去,可以忽略因为知识体现逐渐多知道他说的是对是错,之前满片子的回答我就很烦,一说道歉我就更烦觉得知识体系崩塌白学了,也确实白学了,但继续鼓气逼自己写代码测试,发现也可以了解丝丝缕缕的脉络,也有对的部分,现仔细思考代码而不是永无止境的问豆包,他循环出错道歉,我自己静下心看代码加几句,发现就很简单,之前说的都连上了,有这个基础,他再说道歉或者反复否定之前的回答我也不怕了,知道自己有什么知识存储,可以忽略这些只看正确的
继续:
查看代码
#include <stdio.h> #include <unistd.h> #include <fcntl.h> int main() { int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); write(fd, "abcdef", 6); close(fd); FILE *fp = fopen("test.txt", "r+"); int kernel_fd = fileno(fp); // printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); // 0 // printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); // 0 fseek(fp, 20, SEEK_SET); // printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); // 20 // printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); // 20 fputc('X', fp); /*注释掉下面所有,至此txt:abcdef+14个null+X 解释: 文件初始是 6 字节abcdef,fseek 到 20 并 fputc ('X'): 小文件优化下,标准 IO 会把 6-19 字节补空字符(null),20 字节位置写 X */ // printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); // 20 // printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); // 21 // fflush(fp); lseek(kernel_fd, 10, SEEK_SET); // printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); // 10 // printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); // 21 write(kernel_fd, "Y", 1); /* 注释掉下面所有,至此txt:abcdef+4个null+YX 解释:(这段话他妈的价值一个亿!!追问半个月浓缩的结论) fputc ('X', fp) 仅写标准库缓存,程序退出前未触发刷盘(无 fflush/fclose),但进程终止时系统会强制刷标准 IO 缓存到内核, 可write (kernel_fd, "Y", 1) 绕开标准 IO 缓存,直接写入内核 10 字节位置,优先级高于缓存操作,因此 Y 先出现在 10 字节位置;然后内核指针到了11位置 则直接在Y后写X了 追问了5个h才浓缩出这个看似合理的解释,但豆包说这个其实毫无意义,这种错乱本身就没研究价值 */ // printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); // 11 // printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); // 21 fseek(fp, 10, SEEK_SET); // printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); // 12 // printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); // 10 /* 这里重点来了,为啥fseek内核也+1了 我实验发现最后fseek这,fseek 1 和 9内核会+1变为12,fseek 19、20 内核不会变化,明显用跨区域刷缓存解释不通, 不可能才这么几个字节就算跨了,一般都是4KB,所以没标准通用规律,像之前得出的什么覆盖或者重叠就会刷,都是强迫症追问豆包的自欺欺人的结果,无通用研究价值,豆包其实也无奈 本质是标准 IO(C 库)的底层实现细节(如 glibc 对小文件的 “预写 / 指针修正” 逻辑),不同版本 / 系统的表现可能完全不同,无普适规律; 开发显式调用fflush强制刷盘,彻底规避指针 / 缓存错乱问题;面试中仅需掌握 “fseek 跨缓存刷脏数据、小文件指针同步是优化” 的通用规则,无需提及此类特例。 */ }我总感觉lseek理解不透彻,但代码却感觉越验证问题越多。尸身血海追问代码验证总是不断深入然后就到了无法代码验证的地步,豆包还反复出错哎,思考很多觉得有更细节的东西验证下去人会疯掉。
我总感觉不钻研到这么深,就没法推进,别人看一眼懂了咋用,都是稀松平常的东西,但我就是强迫症想钻研、费尽心力,不搞懂细节最底层逻辑总感觉像戴手套抠鼻屎一样难受。很多应试985高手、刷高频题的估计都以为我是傻逼,又笨又蠢,会认为我学习方法不对
继续补充:
fseek到底啥时候刷到内核?
只看「可读写模式 + 读写交替」,和「位置重不重叠」没关系!
只有满足 “打开模式是可读写(r+/w+/a+) + 上一次操作是读、这次要写(或上一次是写、这次要读)” 时,调用
fseek才会 自动刷缓冲;其他情况只是改指针且fseek 永远不会 “清空” 缓冲内存(缓冲里的旧数据字节还在),仅在特定条件下触发「刷缓冲 + 标记缓冲失效」;
真的好痛苦:
查看代码
#include <stdio.h> #include <unistd.h> #include <fcntl.h> int main() { int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); write(fd, "abc", 3); close(fd); FILE *fp = fopen("test.txt", "r+"); int kernel_fd = fileno(fp); char buf[2] = {0}; fread(buf, 1, 1, fp); printf("%c\n", buf[0]); //a printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); //3 printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); //1 lseek(kernel_fd, 4, SEEK_SET); printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); //4 printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); //2 fread(buf, 1, 1, fp); printf("%c\n", buf[0]); //b printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); //4 printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); //3 } #include <stdio.h> #include <unistd.h> #include <fcntl.h> int main() { int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); write(fd, "a",1 ); close(fd); FILE *fp = fopen("test.txt", "r+"); int kernel_fd = fileno(fp); char buf[2] = {0}; fread(buf, 1, 1, fp); lseek(kernel_fd, 4, SEEK_SET); printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); //4 printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); //4 } 输出4和4 #include <stdio.h> #include <unistd.h> #include <fcntl.h> int main() { //创建文件,初始写入一个无关数据(确保4位置初始为0) int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); write(fd, "a", 1); // 仅写1字节,4位置初始无数据(内核默认0) close(fd); FILE *fp = fopen("test.txt", "r+"); int kernel_fd = fileno(fp); char buf[2] = {0}; fseek(fp, 4, SEEK_SET); fputc('a', fp); lseek(kernel_fd, 4, SEEK_SET); printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); //4 printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); //5 } 输出4和5 #include <stdio.h> #include <unistd.h> #include <fcntl.h> int main() { //创建文件,初始写入一个无关数据(确保4位置初始为0) int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); write(fd, "a", 1); // 仅写1字节,4位置初始无数据(内核默认0) close(fd); FILE *fp = fopen("test.txt", "r"); int kernel_fd = fileno(fp); char buf[2] = {0}; fseek(fp, 4, SEEK_SET); fputc('a', fp); lseek(kernel_fd, 4, SEEK_SET); printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); //4 printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); //4 } 输出4和4我真的崩溃了!好痛苦啊,这些到底对我想去大厂linuxC++服务端开发有没有帮助啊!我是不是完全改放弃这个东西啊啊,豆包说的解释感觉好玄幻离谱啊
代码场景 结果差异原因(不用记,知道就行) 开发 / 面试要记的结论 写 3 字节读 1 字节后 lseek 到 4,ftell=2 小文件预读导致标准 IO 记账错位 混用 lseek(裸 fd)和 ftell(标准 IO)必出问题 写 1 字节读 1 字节后 lseek 到 4,ftell=4 单字节文件无预读,记账暂时对齐 即使偶尔对齐,也绝对不能这么写 r + 模式 fseek 到 4 写字符,ftell=5 标准 IO 写操作正常更新自身位置 r + 读写要按规范来,位置会正常变化 r 模式强行 fputc 写字符,ftell=4 r 模式写是未定义行为,结果随机 r 模式只读,写操作直接禁用 都是glibc 库的私有实现细节别研究了
再说下
open和fopen:语言封装操作的是
FILE*属于上层封装,底层系统调用操作的是描述符,属于底层实现1、
FILE*里藏着fd:标准 IO 的FILE结构体,本质是对fd的 “包装”—— 里面除了存上面说的 4 个东西(此文搜“FILE 结构体里至少几个关键信息”),还有文件描述符和错误标志,然后我们说的缓冲区就是之前那 4 个里面提到的缓存物理首地址指向的用户态内存(标准库缓冲区),这些东西的目的是减少系统调用、提升效率。2、操作边界:
用
fopen/fread/fwrite/fclose(标准 IO 函数)→ 操作FILE*,不用管fd;用
open/read/write/close(系统调用)→ 操作fd,和FILE*无关;混用风险:比如用
fopen拿到FILE*后,再用fileno(fp)取出fd直接调用read/write,会导致两者指针 / 缓冲不同步,必然出问题(我之前验证过的坑)
stdio和FILE都是啥?
操作
FILE*的函数集合:比如fopen(创建并初始化FILE*容器,分配缓冲区、绑定fd)、fread(从FILE*的缓冲区读数据,缓冲区空了就调用系统调用read补数据到缓冲区)、fwrite(先写数据到FILE*的缓冲区,满了再调用系统调用write刷到内核)、fseek(修改FILE*里的逻辑位置,必要时刷缓冲区)—— 这些函数是stdio提供的,FILE*本身只是被操作的 “数据载体”,没有这些函数,FILE*就是个没用的结构体。缓冲与指针同步的规则:比如 “
fseek会先刷FILE*里的缓冲区”“fread优先读FILE*缓冲区,不够再读内核”“系统调用read/write不会同步FILE*里的逻辑位置”—— 这些规则是stdio定义的,FILE*只负责存储 “缓冲区、逻辑位置” 这些状态,不负责执行规则。全局管理逻辑:比如
stdio会管理stdin/stdout/stderr这 3 个默认的FILE*实例(不用你手动fopen),还会处理缓冲区的分配 / 释放、错误码的设置(比如ferror函数就是从FILE*里读错误标志,而错误标志是stdio函数在执行失败时设置的)。
stdio里所有函数的功能,最终都要通过操作FILE*里的状态(fd、缓冲区、逻辑位置等)来实现,FILE*是stdio函数的 “唯一操作载体”。深入抽插(傻逼豆包真他妈智障艹!磨磨唧唧晦涩难懂,追问了 10h 才总结出来的):
- 文件、键盘、屏幕中,存的写的,在计算机里都以字节的形式存在,所以叫【字节流 IO 对象】,
stdio本质就是一个标准 IO 库的统称,这个库作用就是来操作这些字节流 IO 对象,既然都是字节流 IO 对象,操作系统索性把他们抽象成文件描述符,即一个数字编号(键盘比如编号 0、屏幕比如编号 1、磁盘文件比如编号 3),以后操作系统就用 “编号 + 统一的读 / 写指令” 来管,不用区分是键盘还是文件;stdio 再把操作系统的「文件描述符」包装成「FILE 结构体」,对外只暴露
fopen/fread/fwrite这些接口 —— 所以你用printf往终端屏幕输出,底层是操作系统先把这些对象统一成 “字节读写对象”,stdio 再帮你管缓存和交互,stdin/stdout默认关联键盘和屏幕)。也就是说,键盘、屏幕、每个打开的文件都对应一个专属的FILE结构体,到时候交互读哪了写哪了都记录在FILE结构体里。更加底层一点:引入stdio.h就引入了 C 库 里的一段编译好的二进制函数比如fopen这些,运行时,加载到你程序内存里的一堆函数代码 + 你程序里的FILE结构体 / 缓存内存,具体如下:
程序启动阶段(加载 / 链接阶段),系统会把 C 库里的
stdio函数代码(二进制)加载到你程序的内存空间里(其实是共享库啥的,这个大概不要深究,没意义),调用fopen时,内核返回一个 “文件编号”(文件描述符),stdio把这个编号存到FILE结构体里,用户感知不到这个描述符;然后在你的程序内存里,划出一块固定大小的空间(就是你说的缓存),把这块空间的起始地址、总大小,还有 “缓存内部初始读写偏移为 0、缓存对应文件的物理偏移初始为 0”(初始状态),也都记到FILE结构体里;FILE结构体的内存空间由 C 库(stdio)分配,其中的文件描述符是内核创建的,并非所有信息都由stdio“创建,最后告诉你 “打开成了”,是通过给你返回个FILE*指针,指向这个初始化完成的FILE结构体的指针。调用
fread时,stdio先看FILE结构体里记的 “下次要读的内核字节序号”(其实具体看的是偏移),是不是落在当前缓存对应的文件位置范围内:
如果在:直接从缓存的内存地址里,把对应字节拿出来给你,然后把 “下次要读的序号” 往后挪(比如读了 2 个字节,序号就 + 2);
如果不在:
stdio先跟内核说 “把这个文件从 XX 序号开始,读满一整块缓存的数据到我划的那块内存里”,内核照做后,stdio更新FILE里 “缓存对应内核位置”“下次要读的序号”,再从新缓存里拿数据给你。调用
fwrite,先把你要写的数据,直接塞到之前划好的缓存空间里(全、行、无缓冲三种方式),同时更新 FILE 里 “下次要写的序号”; 等缓存被塞满了,或者你主动喊fflush,stdio才会一次性跟内核说 “把这块缓存里的所有数据,写到文件的 XX 序号位置”;内核写完后(非 “立即写入物理文件”,内核有页缓存,可能延迟刷盘),stdio清空缓存(本质是重置缓存的写偏移,复用,不真清空),先把 “下次要写的序号”(缓存写入偏移)往后挪,再同步该偏移到内核;且 “缓存对应内核的位置” 本质是文件偏移,由 C 库根据缓存写入量计算后更新,而非直接赋值为 “下次要写的序号”,准备接收你下一次要写的数据。
stdio.h包涵 C 标准函数 IO 库,“stdio 库提供的函数(如 fread/fwrite),通过操作 FILE 结构体(封装了文件描述符),实现对底层 IO 对象(键盘 / 屏幕 / 文件)的字节流读写”。
这里头有写好的预定义的一些
FILE*类型指针常量,stdin是标准输入自动绑键盘即标准输入流FILE*指针,stdout标准输出绑屏幕,stderr标准错误绑屏幕,所以程序启动会自动初始化这仨FILE*指针,拿来用printf就是默认stdout,scanf就是默认stdin,这个stdin说白了起的名字太 JB 误导人了,我一直以为这个是什么特殊的东西,其实跟stdio没关系,就是键盘 / 屏幕的代称,日后想自己写比如和某txt文件读写交互,起名字是fp,其实就跟stdin/stdout是一模一样的概念维度,起名字不可以再用stdout和stdin,FILE* fp = fopen("test.txt", "r");这是自己写,你就得用stdio提供的库函数fopen这些,绑定到指定文件,用完需要fclose销毁。比如fgets默认stdin键盘读,fputs默认屏幕输出。
FILE结构体是标准库用来管理每个 IO 对象的 “信息容器”,一个 IO 对象配一个,stdin是找键盘对应 “信息容器” 的指针,fp我们自己定义的这个就是找我们test.txt文件的指针至此不乱了非常精通!!
追问话术:
FILE和什么scanf、stdin咋关联?好割裂 禁止比喻最好串联别分开各自定义!没意义!这段晦涩难懂的也越来越透彻了!!(精华)
C 标准库(stdio)为 FILE * 对象维护的用户态缓冲区(你用
fopen打开文件后,FILE 结构体里关联这块缓冲区)用来下次标准库函数读写时候,先预存不用老去内核读写搬运。然后对比
read无缓冲,完全绕开标准库缓冲,数据从内核态直接到你指定的用户内存,“实时读写”(每次调用都触发系统调用,低延迟但频繁调用效率低);一般说带不带缓存都是标准库的缓存,为了交流方便,但其实理论上read系统调用也是有缓存的,read1字节就是去页缓存拿1字节,但页缓存会在没东西的时候一次读4KB进来,供每次read用,而我们所说的效率低 / 磁盘 IO 多,不是指读页缓存(页缓存读是内存操作,极快),而是指:若频繁小字节 read(无预读 / 缓冲),会触发内核频繁从磁盘批量进货读 4KB 到页缓存(这步是真磁盘 IO),一次 4KB 进货后,读页缓存 1 字节无磁盘 IO。
每次
read1 字节都要走一次内核态切换(耗时),而fread有用户层缓冲(攒够批量再调read),少了大量系统调用,read慢在频繁系统调用,fread靠用户缓冲少调read,减少了高成本的内核切换。注意上面有句话【“带不带缓冲” 核心是:数据传输 / 处理时是否先存入临时缓存区(而非直接实时交互),带缓冲 = 先存后处理(提升效率、减少 IO),不带 = 实时读写(低延迟、数据即时同步)】
说带缓冲是减少IO,可我们刚才了解到fread只是比read只是比少了系统调用啊,也不关乎磁盘IO啊,哈哈这里其实还有个知识,
IO 是
Input/Output的缩写,指程序与外部设备(磁盘、网络、内存等)之间的数据输入和输出操作,不是单指磁盘硬件读写,fread这些库带缓冲减少的是整体 IO 效率,整体IO = 程序发起读请求 → 完成数据读取的全流程耗时(含系统调用切换 + 页缓存读写 + 磁盘物理 IO <仅缓存未命中>);fread 比 read 好,核心是大幅减少系统调用切换的耗时,从而让这个全流程(整体 IO)效率提升,但不影响磁盘IO。内核态 IO:内核层操作页缓存 / 磁盘的 IO 行为(如内核读磁盘到页缓存、读写页缓存);
用户态 IO:用户程序操作自己缓存 / 内存的 IO 行为(如 fread 读自身用户缓存);
程序调用 read 时,两者切换:从用户态切到内核态执行 IO 逻辑,完了切回用户态 —— 这切换有固定开销,fread 少切就省成本。
当你的程序需要读取的数据超过了
ifstream的缓冲区时,必然会发起一次系统调用,请求操作系统内核。至于这次系统调用是否会导致磁盘 I/O,则完全取决于你要读取的数据是否已经存在于操作系统的页缓存中。
如果在页缓存中,内核直接从内存复制数据,无磁盘 I/O。
如果不在页缓存中,内核必须先从磁盘读取数据到页缓存,再复制给程序,有磁盘 I/O
底层了解了那说几个实用的东西:
读 1 字节时,无论 read/fread,只要数据已在页缓存(内存),都不会碰磁盘,关键差异(纯内存 / 无磁盘 IO 场景):
首先都是从磁盘IO内核那进货4KB到页缓存,然后读 1 字节的时候,所有都是从页缓存读东西,差别:
read:每次都触发「用户态→内核态→用户态」切换(系统调用开销),哪怕数据在页缓存,1000 次读就有 1000 次切换;每次都是做内核态和用户态的拷贝,1000次拷贝
fread:仅第一次触发 1 次系统调用(读 4KB 到自身用户缓存),后续 999 次读都在用户态直接拿数据,无系统调用切换;而且也只在第一次有 内核态 拷贝 到用户态的拷贝过程所以fread适用于:用户侧小批量且高频次频繁的读取。
fread通过减少系统调用降低 CPU 开销(系统调用的核心开销是内核态 / 用户态切换,由 CPU 执行特权指令完成上下文切换),间接提升 IO 效率,而非减少物理 IO 总量。读大文件直接用read优势大:
页缓存是内核层的,fread 和 read 都绕不开,两者最终读数据都要过页缓存,差异只在用户态:fread 多一层用户态缓存,用 fread 读大块时,数据先到 fread 的用户缓存,再拷贝到你的 buf;read 则直接把页缓存的数据拷到你的 buf,少一次用户态拷贝;
read 大块读 = 内核页缓存→你的 buf(1 次拷贝);fread 大块读 = 内核页缓存→fread 用户缓存→你的 buf(2 次拷贝),所以 read 更直接,fread 无优势。
之前啃网络编程为啥都用的是
read?
底层可控:read 是系统调用,fread 等是标准库封装,read 可精准控制缓冲区、超时、中断处理,适配网络场景;
无缓冲陷阱:f 系列带用户态缓冲,网络数据边界不固定,易粘包 / 拆包,read 直接操作 fd 无此问题;
异步 / 非阻塞适配:read 支持非阻塞 I/O、epoll 等多路复用,f 系列依赖 stdio 缓冲模型,难适配;
跨平台 / 协议适配:read 仅依赖 fd,适配 socket、管道等,f 系列绑定 FILE 流,网络场景易出兼容问题。
(这一整段真乃 —— 精华中的精华!点睛之笔!嘎嘎开门!)
然后再说点东西:
我无意间阴差阳错验证的东西,包括到底啥叫刷缓存各种琐碎问题:
fseek是「标准 IO 层的原子操作」,本质 =fflush(刷缓冲) +lseek(调内核改指针) + 「同步标准 IO 内部逻辑指针」 + 「清除文件错误标志」;更新!!大错特错,fseek刷是小文件fflush + lseek是「手动拆分的两步操作」,只做了 “刷缓冲 + 改内核指针”,没同步标准 IO 的内部指针,后续用标准 IO 函数(fread/fputc)会出问题!所以看代码:
查看代码
#include <stdio.h> #include <unistd.h> #include <fcntl.h> int main() { //创建文件,初始写入一个无关数据(确保4位置初始为0) int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); write(fd, "0", 1); // 仅写1字节,4位置初始无数据(内核默认0) close(fd); FILE *fp = fopen("test.txt", "r+"); int kernel_fd = fileno(fp); char buf[2] = {0}; // 定位到4位置,连续写3次(a→b→c),无指针跳转 fseek(fp, 4, SEEK_SET); fputc('a', fp); // 缓冲=a printf("\n未刷,内核4位置数据:#%c#\n\n", buf[0]);//## // 注释掉下面所有 // txt:0nullnullnulla fseek(fp, 4, SEEK_SET); fputc('b', fp); // 缓冲覆盖为=b // 注释掉下面所有 // txt:0nullnullnullb fseek(fp, 4, SEEK_SET); fputc('c', fp); // 缓冲覆盖为=c // 注释掉下面所有 // txt:0nullnullnullc // 不手动fflush,直接读内核4位置的真实数据 lseek(kernel_fd, 4, SEEK_SET); read(kernel_fd, buf, 1); printf("未刷,内核4位置数据:#%c#\n\n", buf[0]);//#b# // 注释掉下面所有 // txt:0nullnullnullc // 手动fflush后,再读内核数据 fflush(fp); lseek(kernel_fd, 4, SEEK_SET); read(kernel_fd, buf, 1); printf("手动刷,内核4位置数据:#%c#\n", buf[0]);//#c# fclose(fp); } /* 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./abc 未刷,内核4位置数据:## 未刷,内核4位置数据:#b# 手动刷,内核4位置数据:#c# root@VM-8-2-ubuntu:~/cpp_projects_2# */这里
fflush(fp);和lseek(kernel_fd, 20, SEEK_SET);去掉,换成fseek(fp, 20, SEEK_SET);也一样,但注意:
如果之前文件操作出了错误(比如读超出文件尾),
FILE会记录错误标志。fseek会主动清除这个标志,让后续操作能正常执行;但fflush+lseek不管这个标志,哪怕之前有错误,后续操作还是会失败,且很难定位原因
fflush+lseek的写法,如果后续用f的一些东西会有问题解释代码,这里有很多需要说的:
第一个txt里是0nullnullnulla很好理解
每次
fseek(fp,4,SEEK_SET)都会强制刷当前缓冲数据到内核;三次
fputc中,a被第二次fseek刷到内核 4 位置,b被第三次fseek刷到内核 4 位置(覆盖a),c仅写入缓冲未触发刷盘涉及到刷缓存的只有;
标准 IO 写缓冲的刷盘触发场景仅这三类:
fseek/fsetpos/rewind(定位类函数);写后读切换(
fgetc/fread/fscanf等 FILE * 读操作);
fflush/fclose(显式刷 / 关闭);(注:内核层
read/lseek永远不刷,仅 FILE * 层操作才会触发刷缓冲)那我就去试试写后读吧,费好大劲改了下写a的那段,成了确实刷了
查看代码
fseek(fp, 4, SEEK_SET); fputc('a', fp); // 缓冲=a fgetc(fp); lseek(kernel_fd, 4, SEEK_SET); read(kernel_fd, buf, 1); printf("\n未刷,内核4位置数据:#%c#\n\n", buf[0]);1、fputc后,内核指针不动,标准库指针+1。显然fgetc读的是下一个位置,如果加个输出会发现是乱码,但这无关紧要 —— 我们要的是
fgetc触发「写→读切换」的刷盘行为,不是要读它的返回值;2、哪怕
fgetc读的是 1 位置的空字符,只要执行了这个 FILE * 层的读操作,就会把标准 IO 缓冲里的a刷到内核 0 位置;3、后续用独立的内核 fd 读 0 位置,就能拿到刷进去的
a—— 这才是验证 “写后读刷缓冲” 的核心,和fgetc读的是哪个位置完全无关。起初我写的是下面的验证,这个起初就搞错了输出的是下一位的,想绕过fseek验证写后读会刷缓存好难,然后才有的上面豆包给的:
查看代码
fseek(fp, 4, SEEK_SET); fputc('a', fp); lseek(kernel_fd, 4, SEEK_SET); buf[0] = fgetc(fp); printf("\n未刷,内核4位置数据:#%c#\n\n", buf[0]);题外话:
rewind (fp) 等价于 fseek (fp, 0, SEEK_SET)。
fseek(fp, off, SEEK_SET)刷缓冲的规则:将标准 IO 写缓冲中未刷盘的所有数据,刷到「fseek 执行前标准 IO 指针指向的文件位置。再说下:
这里我吃完饭路上,豆包又说他妈的说
fgetc不刷新,追问半天发现,其实是win下不刷,linux下刷,GCC 是编译器,Glibc 是 Linux 下的 C 标准库(提供
fgetc/fflush等函数实现及缓冲逻辑)GCC 编译代码时链接 Glibc,你实测的
fgetc刷缓冲是 Glibc 的库实现逻辑,和 GCC 无关。C 标准仅定义
fgetc/fflush等函数的行为规范和语法(如 “读写切换需同步缓冲”),但未规定具体实现细节;
- Windows 的 C 标准库(如 MSVCRT)和 Linux 的 Glibc,都是遵循 C 标准的不同厂商实现版本,但具体实现有差异,这就导致有了linux的C库(Glibc)和win的C库
再继续说个细节;
写后读核心逻辑(Linux 下):
写→读切换时,
fflush()先将用户态写缓冲区数据刷入内核(通过write()系统调用);不碰磁盘后续
fgetc优先从用户态读缓冲区取数据,若读缓冲区为空,才通过read()从内核(文件页缓存)拉取数据填充。关键细节:
内核层有「页缓存」,用户态有「stdio 缓冲区」,二者独立;
刷写仅同步「用户态写缓冲→内核页缓存」,而非直接写磁盘;
纯读场景下,
fgetc始终先查用户态读缓冲,未命中才读内核页缓存,无反向同步(内核→用户态)仅按需拉取- fclose 会隐式调用 fflush(还是只到内核页缓存),但 fclose 本身也不会把内核页缓存刷到磁盘!fclose 后能在 txt 里看到内容,是 Linux 内核后续自己「异步刷盘」的结果,这期间突然断电,这部分数据可能丢!异步就是:你代码里调用 fclose 把数据交给内核后,不用等着内核把数据写到磁盘,代码直接跑完了,内核自己找空闲时间偷偷把数据写磁盘,你管不着也等不着。
然后再说踩的坑:中间其实我最开始是在这加的fgetc,但遇到问题了
查看代码
// 不手动fflush,直接读内核4位置的真实数据 lseek(kernel_fd, 4, SEEK_SET); printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); //4 printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); //5 buf[0] = fgetc(fp); printf("#%c#\n\n", buf[0]);//#b# read(kernel_fd, buf, 1); printf("#%c#\n\n", buf[0]);//#b#内核4标准5,明显fgetc应该是读5位置,像上面说的是乱码!但居然读的是b,且最后文件是0nullnullcb,然后豆包给的解释反复说的我感觉好离谱,哎作罢,真的痛苦,学的脑浆都冒出来了,啥时候是个头啊,无穷无尽的需要验证豆包说的对不对,这里他妈的真的好离谱!!!别说那个0nullnullcb了,就一个fgetc后的输出b而不是输出乱码,我就觉得好想不通,脑子真的宕机了,附上 豆包对话(说不用研究,不考)
注意:我真的痛苦至死,这里豆包真的永远无法给出正确答案!!我真都不知道该看啥学了!然后自己写了个代码验证了:
查看代码
int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); write(fd, "0", 1); close(fd); FILE *fp = fopen("test.txt", "r+"); int kernel_fd = fileno(fp); char buf[2] = {0}; fseek(fp, 4, SEEK_SET); fputc('a', fp); printf("内核:%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); printf("标准库:%ld\n", ftell(fp)); read(kernel_fd, buf, 1); printf("\n#%c#\n\n", buf[0]); fseek(fp, 6, SEEK_SET); lseek(kernel_fd, 4, SEEK_SET); read(kernel_fd, buf, 1); printf("\n#%c#\n\n", buf[0]);fseek 不是清空缓冲区,因缓冲内存数据还在,只是“刷缓冲 + 缓冲失效”,后续读写会重新从内核加载数据,旧缓冲数据相当于 “没用了”
fseek(可读写模式 + 位置重叠时)会先刷缓冲(把旧数据写回内核),再同步标准 IO 内部指针和内核指针,旧缓冲数据不会被 “清空删除”,但会标记为 “失效”,下次读写不用旧缓冲,重新从新指针位置读内核数据到缓冲 —— 不是 “清空缓冲内存”,是 “让旧缓冲数据失效”。
你之前的感觉是对的(fseek 会让旧缓冲 “没用”),但 “清空” 的表述不够精准 —— 缓冲内存里的字节还在,只是标准 IO 不会再用它,后续操作会覆盖或忽略
fseek 调用时不管位置是否重叠,都强制刷缓冲!(豆包之前反复说什么位置重叠啥的艹)
然后这里注意:
上面代码我误以为
fputc写到缓存,以为printf可以拿到,但其实错了
printf是 写操作,把字符串写入「标准输出(stdout)的行缓冲区」,和你fputc写的「文件(test.txt)的全缓冲区」是 两个完全独立的缓冲—— 八竿子打不着!永远拿不到
printffputc写的内容,因为两者操作的是不同缓冲(一个管屏幕输出,一个管文件存储),跟内核刷不刷没关系!用户定义的
buf数组,不涉及标准库缓存只有把 fputc 写入的目标改成 buf 数组(而非文件缓存),再 printf 输出这个 buf 数组,才能看到写入的内容。
read读文件内容到数组后用pritnf输出,read和write是一对指的是,read 和 write 是内核态 IO 的一对(POSIX 标准),功能对称;
read:从内核文件 / 设备读数据到用户态内存(如 buf);
write:从用户态内存(如 buf)写数据到内核文件 / 设备;
注意:
char buf[2] = {0};是给数组前两个元素都赋值为数值 0(对应 ASCII 码 0,也就是空字符 '\0'),buf [0] 和 buf [1] 在内存里存的都是二进制的 00000000,本质是字符类型的数值 0,不是数字字符 '0'('0' 的 ASCII 是 48),所以 %c 打印无显示,%d 打印十进制数值 0。write(fd, "0", 1)往文件里写入的是字符 '0' 对应的 ASCII 数值 48(二进制 00110000),用%d打印输出 48,用%c打印输出可见的数字 0。对比(极简):
char buf[2]={0}:存数值 0(空字符),% d→0,% c→无显示;
write(fd, "0", 1):存数值 48(字符 '0'),% d→48,% c→0。继续看个代码老子真他妈吐了:
查看代码
#include <stdio.h> #include <unistd.h> #include <fcntl.h> int main() { int fd = open("test.txt", O_RDWR | O_CREAT | O_TRUNC, 0644); write(fd, "abcde", 5); close(fd); FILE *fp = fopen("test.txt", "r+"); int kernel_fd = fileno(fp); char buf[2] = {0}; char cao[2] = {0}; read(kernel_fd, cao, 1);//内核到1 // printf("#%c#\n\n", cao[0]);//输出a fseek(fp, 3, SEEK_SET);//执行后输出会发现,标准和内核都到 3 fputc('a', fp); // 执行后,输出户发现内核指针3,标准指针4 //注释掉下面所有至此txt:abcae read(kernel_fd, buf, 1);// read后输出会发现内核指针4,标准指针4 /* 注释掉下面所有至此txt:abcda 理解了,因为 fputc 先不刷,read 指针到 4了最后代码结束,只能把 a 写到 4 了 */ read(kernel_fd, cao, 1);// read后输出会发现内核指针5,标准指针4 // printf("!%c#\n\n", cao[0]);//!e# 读的依旧是标准库指针 4 位置的 /* 注释掉下面所有至此txt:abcdea 这个也就懂了 */ fseek(fp, 3, SEEK_SET); // printf(" 内核指针(lseek):%ld\n", lseek(kernel_fd, 0, SEEK_CUR)); //6 // printf(" 标准IO指针(ftell):%ld\n", ftell(fp)); //3 /* 注释掉下面所有至此txt:abcdea 也他妈懂了!! */ fputc('b', fp); //这句执行完,内核指针 6,标准库 4 // lseek(kernel_fd, 3, SEEK_SET);//这句执行完,内核指针 3,标准库 4 // read(kernel_fd, buf, 1); //这句执行完,内核指针 4,标准库 4 printf("@%c#\n\n", buf[0]);//输出d,理解!! /* 注释掉下面所有至此txt:abcdea fputc(a)后,fseek就把a刷进内核了,但匪夷所思的是最后居然没有b,及时止损不再研究了 */ // 以下更是无法搞懂,放弃!! // fseek(fp, 3, SEEK_SET); // printf("4、#%c#\n\n", buf[0]); // fputc('c', fp); // 缓冲覆盖为=c // lseek(kernel_fd, 3, SEEK_SET);read(kernel_fd, buf, 1);printf("¥@%c#\n\n", buf[0]); // lseek(kernel_fd, 3, SEEK_SET);// 不手动fflush,直接读内核20位置的真实数据 // read(kernel_fd, buf, 1); // printf("5、未刷缓冲时,内核20位置数据:#%c#\n\n", buf[0]); /* 注释掉下面所有至此txt:accbea */ // fflush(fp); //手动fflush后,再读内核数据 // // lseek(kernel_fd, 20, SEEK_SET); // // fseek(fp, 3, SEEK_SET); // lseek(kernel_fd, 3, SEEK_SET); // read(kernel_fd, buf, 1); // printf("6、手动刷缓冲后,内核20位置数据:#%c#(预期是c)\n\n", buf[0]); fclose(fp); }注:
是!程序正常结束(不管有没有显式写 close/fclose),操作系统和 C 库会自动做两件事:
对
FILE* fp:自动调用fclose(含fflush刷标准 IO 缓冲);对
int fd(包括open的 fd 和fileno(fp)的 fd):自动关闭文件描述符。程序正常跑完,哪怕没写任何 close,也会自动完成 “刷缓冲 + 关文件”,和显式写了
fclose(fp)+close(fd)效果一样!注:
read(kernel_fd, buf, 1);的buf不用写下标?
buf是字符数组首地址(指针),read会把读取的 1 字节数据写入buf[0]位置;数组名做函数参数时自动退化为指针,无需写
buf[0],内核直接往该地址写数据;重点:只需确保
buf有至少 1 字节空间,读取的字节会覆盖buf起始位置的值。注:
实践发现,比如有n字节数据,超范围写是补null,超范围fseek是依旧定位,但超范围多次read或者fread,因文件实际长度不足,读取失败偏移始终未变动。
注:
fseek不主动刷缓存这是永恒不变的!!之前所有说fseek刷的都是特例隐式机制导致的。我测试发现 VScode 远程控制的 Linux 和 win下的codeblock(
w64devkit属Linux的GCC阵营)都会刷新到内核,且 win 下的 codeblock 也有read,我一直以为read是 linux的,豆包说小文件强制无缓冲,且 codeblock 的read是 GCC 下的read底层用的依旧是 win 的 API
这里我又无穷无尽永无止境的测试大文件,发现依旧会刷,全网百度博客都没提到会刷,豆包也说刷是特例,算了不研究了
结论是:
Linux 下
fseek核心规则:仅当偏移超出标准库缓存范围时才刷脏缓存;缓存内 fseek 仅改指针,不主动刷缓存。刷只是小文件 + 读写模式优化,我的俩环境都是 因 stdio 缓存策略,小文件时出现写操作即时刷盘的情况,属于系统实现细节注:再说下,为啥上面好多地方都是open然后close然后fopen,
查看代码
FILE *fp = fopen("test.txt", "w"); fwrite("abcdef", 1, 6, fp); fclose(fp); fp = fopen("test.txt", "r+");
"w" 模式特性:fopen ("w") 会清空文件 + 仅写,无法读;后续要读写(r+),必须先关 "w" 的 fp,再重新以 r + 打开(同一文件不同打开模式不能复用 fp)。
缓存刷写:fclose (fp) 会强制把 "w" 模式下 fwrite 的缓存数据刷到文件(避免数据丢在用户态缓存),新打开 r + 才能读到完整数据。
fd 独立性:每次 fopen 会生成新的文件描述符,关闭旧 fp 再开,能避免新旧 fp 的缓存 / 偏移冲突,保证 r + 模式操作的是最新文件状态。
模式 核心含义 关键细节(最易踩坑) w写(write) 1. 打开文件时直接清空原有内容; 2. 如果文件不存在,就创建;
3. 只能写,不能读;
4. 文件指针默认在开头(清空后开头就是空)。
r+读 + 写(read + write) 1. 必须文件已存在(否则报错); 2. 打开时不清空原有内容;3. 可读可写;4. 文件指针默认在开头(写的话会 “覆盖” 开头内容,而非追加)。
「r」= 读(必须有文件,不清空)
「w」= 写(创文件,清空)
「a」= 追加(创文件,不清空,写末尾)
「+」= 加权限(r+ = r + 写,w+ = w + 读,a+ = a + 读)
似真似假的豆包回答:
- fseek (10) 的行为:
小文件(20 字节)完全在 4KB 缓存内,fseek (10) 仅修改标准库缓存指针到 10 字节位置,因无缓存区域切换,系统优化同步内核指针到 10,所以内核 / 标准库指针都 = 10;
小文件特殊的原因:
系统认为小文件缓存分层(用户态 + 内核态)无意义,且切换成本>收益,直接打通指针同步,避免读写位置混乱,保证一致性。
对比大文件
大文件缓存分层有性能收益(减少内核 IO),系统刻意区分用户态 / 内核态指针,仅在缓存切换时同步数据,不同步指针,避免频繁内核态切换损耗性能。
但他妈大文件验证也是刷!操他妈的!
真的无尽痛苦,总算强迫症都拉取对话记录整理完了,有很多看似矛盾重复的话,本身编译器实现就是有差异的,没空精简了。
服务端代码别依赖行缓冲,关键日志用 fflush 强制刷,或直接用 write(系统调用)。
核心考点精简(大厂 Linux C++ 服务端高频问法)
1. fseek/lseek 核心必记(面试直接考区别 + 场景)
维度 fseek(标准 IO) lseek(系统调用) 缓存关联 操作用户态缓存,触发 “缓存刷新 / 重新填充” 直接操作内核态文件偏移,不碰用户态缓存 刷新逻辑 跨读写 / 偏移跳转时,编译器(glibc)会自动刷缓存到内核(小文件优化是 glibc 的默认策略,提一句即可) 无刷新逻辑,仅改内核文件指针 面试必答场景 小文件 / 频繁读写场景用 fseek(缓存提升效率) 大文件 / 精准偏移场景用 lseek(绕开缓存避免脏数据) 2. 行缓冲 核心必记(面试考 “触发条件 + 场景坑”)
定义:标准 IO 的缓冲类型,遇到 '\n' 或缓冲区满(默认 4K/8K)或 fflush/fclose 时刷新;
触发场景:终端输入输出(如 printf/scanf)默认行缓冲;
面试坑点:行缓冲在后台进程 / 重定向(> 文件)时会自动转为全缓冲,易导致 “printf 没 \n 不输出” 的线上问题;
终端(stdout)默认行缓冲,遇到1、
\n2、缓冲区满;3.fflush/fclose重定向(> 文件)/ 后台进程,默认全缓冲,只有缓冲区满(默认 4K/8K)或者
fflush/fclose触发,即一旦输出目标不是终端(比如重定向到文件、后台运行),行缓冲会直接切换成全缓冲 —— 此时 \n 不再是刷新触发条件。服务端代码别依赖行缓冲,关键日志用 fflush 强制刷,或直接用 write(系统调用)。
二、必须补充的考点(少一个都可能漏分)1. 标准 IO 缓冲体系(行缓冲 + 全缓冲 + 无缓冲)
全缓冲:文件操作默认(如 fwrite),缓冲区满 /fflush/fclose 才刷(面试考 “大文件写时为什么数据丢了?”→没刷全缓冲);
无缓冲:如 stderr,实时输出(面试考 “为什么 printf 没输出,fprintf (stderr) 能输出?”);
面试问法:“标准 IO 有几种缓冲?分别什么时候刷新?服务端开发怎么避免缓冲导致的问题?”
2. 缓存与内核交互的坑(服务端高频踩坑点)
必记:fseek 跨读写操作时(如先读再写),glibc 会先刷缓存到内核,再调整偏移(小文件优化是 glibc 对 fseek 的默认优化,不用深钻实现,知道 “小文件 fseek 效率高,大文件建议 lseek+write” 即可);
线上问题:服务端用 fseek+fwrite 写日志,高并发下数据乱序→原因是缓存未及时刷,解决方案:关键场景用 lseek+write,或 fwrite 后强制 fflush。
3. 服务端实操优化(面试落地题)
小文件 + 行缓冲 / 全缓冲坑:日志服务(小文件 + 频繁写)别用 printf(行缓冲),改用 fopen + 全缓冲 + 定时 fflush,或直接调用 write;
大文件偏移:下载 / 断点续传场景,必须用 lseek(绕开缓存,避免内存占满)。
三、啥是全缓冲
定义:标准 IO 的缓冲类型,数据先攒在用户态缓冲区(默认 4K/8K,glibc 决定),只有缓冲区满、调用 fflush/fclose,或进程退出时,才一次性刷到内核,再写到磁盘。
核心场景:默认用于文件操作(如 fwrite 写文件),服务端写日志 / 写文件大概率触发全缓冲。
面试必答坑点:
问题:全缓冲未手动刷(fflush)时,进程异常退出会导致缓冲区数据丢失(比如 crash 时没写进磁盘);
解决方案:服务端写关键数据(如订单日志),fwrite 后必须加 fflush,或直接用 write(系统调用,绕开全缓冲)。
四、来试验下
stdout 输出目标非终端(重定向 / 后台进程)时,行缓冲自动切全缓冲,
\n仅为普通字符,不再触发刷新;数据暂存用户态缓冲区,未刷到内核 / 文件,故看不到输出。查看代码
#include <stdio.h> #include <unistd.h> int main() { printf("服务器日志\n"); // 加\n但不刷缓冲 while(1) sleep(1); // 进程不退出,缓冲区不满不刷 }运行(重定向stdout到文件切全缓冲):
打开发现无内容(缓冲区未达 4K/8K 阈值,进程未退出,数据卡在用户态)。
若执行
./abc(终端输出,行缓冲):立刻看到输出;若执行
./abc > test.txt后,kill 进程:缓冲区数据会刷到文件,此时 txt 才有内容。服务器进程长期运行不退出,stdout 切全缓冲后
\n不触发刷新,缓冲区数据未刷出;而普通程序运行结束会自动刷新缓冲区,因此能输出,核心差异是进程是否退出 + 缓冲类型(行 / 全)
全缓冲:缓冲区满了才执行实际 I/O(比如磁盘文件的
fwrite)。行缓冲:遇到换行符
\n或缓冲区满时执行 I/O(比如终端的printf,默认行缓冲)。无缓冲:不经过标准库缓冲区,直接调用系统调用
扯了这么多,终于说完大头儿了!陆陆续续延展这么多,但总算心结强迫症捋顺完了,总结下:
seek是统称,实际只有fseek和lseek
linux 的
lseekC 用
fseek再说
seekg:
先追溯点东西,知道了stdio,那 C++ 的iostream咋理解?
对比基础输入输出:
stdio里比如scanf需要&,C++里cin重载写好了直接输入变量名就行。缓冲机制:stdio:缓冲区由 C 标准库管理,可通过
fflush手动刷新;iostream:缓冲区由 C++ 流对象管理,endl会刷新缓冲区(\n仅换行不刷新),也可通过cout.flush()手动刷新;错误处理:stdio:靠返回值(如
scanf返回成功读取的参数数)、ferror()/feof()判断;iostream:可通过cin.fail()判断失败,或开启异常(cin.exceptions(ios::failbit))综上:
iostream是全新设计的面向对象的 IO 体系,不是stdio的C++版本
- 所以说
seekg是 C++iostream库,操作对象是ifstream/fstream(C++ 的文件流)而
fseek属于 C 的stdio库的操作对象是FILE*就是 C++ 为了 “流操作”(比如
ifstream fin;)设计的等价替代 ——fin.seekg(10, ios::beg)和 C 里fseek(fp, 10, SEEK_SET)完全一样,都是把标准库指针定位到 10;
fopen得到的FILE* fp,会搭配 C 标准库的文件操作函数使用(如fread/fwrite/fgetc/fputs/fseek/fclose等),全程不直接操作文件描述符,依赖 stdio 缓存实现高效 I/O。read是系统调用,必须传入文件描述符,若已有FILE*又要使用read,才需用fileno提取 fd,但严禁混合使用 stdio 函数(如fgetc/fseek)和系统调用(如read/lseek)操作同一文件。
当用
open函数加O_CREAT新建文件时,必须显式指定文件权限(比如0644),否则编译会直接警告,0644是 Linux 常用默认权限:
所有者(你):可读(4)+ 可写(2)= 6;
同组用户:只读(4);
其他用户:只读(4)
至此该说的说完了,总结下:
至此梳理下心路历程就是:先看编程指北的代码有
std::ifstream,然后就开始无穷无尽永无止境的给海厚海厚的东西,尸山血海的超级大血案作者这张章节的重点 RAII 这玩意本身之前自己提前钻研过早他妈懂了,但作者代码涉及到
std::ifstream这些,于是一直追问+豆包无穷无尽的牵扯到盘古开天辟地女娲补天,
一路从
getline、系统调用的read、C++ 的read、C 的 f 那些、C++ 流的几大功能(包括大文件、fseek那些清不清空缓存、读写啥的)、二进制乱码 vs 文本、实际写代码扣出看看read和getline和>>实际输出fail等几大状态参数究竟是啥、stdio和FILE底层千丝万缕、底层调用read和使用封装库究竟在最极致的底层分别发生了啥具体流程挖出指针去研究具体怎么指导移动的使得能获得想要位置数据的、读取偏移啥的、FILE 结构体、内核内存 OS 这些都 JB 乱套咋他妈配合的,标准库缓存、页缓存、磁盘 IO 磁盘缓存。如今全都通过无数次的实验!!一清二楚!!!了如指掌!!
我他妈成赵子龙了七进七出反反复复无止境的抽插龙潭虎穴走了一圈
感觉遥遥无期不见天日哎,完全看不到光亮,走的路学的东西,都是极致的钻研极致的底层,貌似都是毫无意义冷门偏的,那些速成 Java 批量生产去大厂的水货真他妈羡慕他们。
继续,此文搜“么多,回顾”是大文件拷贝,但豆包又在我追问 C++ 流的时候,说流功能包括大文件分块,然后不知不觉追问又说大厂用零拷贝,之前也不在哪里看到过这玩意必须会,好吧既然肯定考那就可以放心学了:
先反过来思考点东西
Q:豆包说,大厂用零拷贝,那妈逼的告诉老子 C++ 里的那些分块拷贝啥的,耽误老子时间,玩呢??
A:非也非也,零拷贝比 C++ 封装的更高效,起初给了个错误的
sendfile后来追问才知道sendfile是网卡啥的,本地大文件用mmap。学零拷贝之前先把 C++ 流的分块拷贝的事收个尾,代码是此文搜“么多,回顾”,豆包说这个代码虽然是 C++ 的,但不标准:
三大问题之一:应该显式加
ios::binary(二进制模式),而我是缺省ios::binary(文本模式),缺省说人话就是不写默认的意思,即会默认成文本模式,任何读其实本质都是对系统read调用的封装都是字节流读取都会对win的\n转\r\n然后蝴蝶效用破坏数据的风险,所以不用的时候不出错只是说明数据不涉及这些导致数据错误的因素,但保险都是只要读就用二进制打开,避免任何隐式篡改ifstream fin(src, ios::in | ios::binary); // 必加binary三大问题之二:分不清错误处理打印用哪些函数(关于这个错误
errno问题又追问 + 写博客搞了 3 天)牵扯出我一直理解错的东西,哎先继续介绍错误输出的东西!无穷无尽、永无止境、海厚海厚,操.你妈的!!
错综复杂又有千丝万缕的关系,又夹杂误人子弟被我反复追问得来的总结:
注意:我本来知道 Linux 是系统调用,然后 C++ 是对系统调用的封装,但期间豆包提到了 GCC 扩展一词,导致我一下懵了被带偏了以为先有的 C++ 标准,后有 GCC 实现,也因此追问豆包很久浪费很多时间。
strerror是 C 标准规定的函数,依赖于errno,只要有errno的系统(Linux / Windows)、只要符合 C 标准的编译器(GCC / MSVC / Clang)都支持,作用是把系统级错误码errno翻译成字符串。C++ 流本身没规定设置
errno,但流操作(ifstream/ofstream)的底层调用逻辑:C++ 流 → 封装 C 标准库函数(fopen/fread/fwrite) → 封装系统调用(Windows 是CreateFile/ReadFile,Linux 是open/read) → OS内核。所以 C++ 流失败时都会触发 C 库设置errno,这是 C 标准逻辑,不是编译器特性。所以 C++ 流一定会因底层调用 C 库 / 系统调用设置
errno,实际可以strerror(errno)来查看具体错误信息,而 C++ 流标准只有fail这种对错的标志。然后 VS 里因为strerror返回的是静态缓冲区,多线程 / 并发调用会导致缓冲区内容被覆盖(比如线程 A 查errno=2,线程 B 同时查errno=1,A 可能拿到 B 的错误信息),引发竞态条件(线程不安全)所以给禁用了,MSVC 推荐用线程安全的strerror_s(符合 C11 安全标准),强制开发者规避缓冲区竞争;次要原因是strerror不是 C++ 标准,所以尽管豆包说 GCC 一直在用strerror,但本质是因为无奈妥协(历史惯性改造成本高)且 GCC 也不禁止,所以用的话就要规避多线程场景!梳理下就是,在 C++11 之前一直各用各的:
GCC(Linux):直接用
strerror解析errno(涉及到多线程需加锁),或者POSIX(Unix系统的通用接口)指定的线程安全版strerror_r,或者perror(封装了strerror,拼接打印到标准错误流stderr),后来 C 出了strerror_s但 GCC 也少用VS(Windows):仍能用
strerror解析errno,但需手动定义_CRT_SECURE_NO_WARNINGS宏,否则警告升为编译错误(即屏蔽这个):,也可直接调用 Windows API(如
FormatMessage)解析系统错误码,或者微软windows推荐的线程安全版strerror_s和扩展版本_strerror_s(后来 C11 学了去,还把前者纳入了自己 C 标准),但属于平台专属写法,非通用方案,但究竟是在 C++ 编程还是 Windows 编程就要心理有逼数了!流自身和系统调用的错误逻辑在 任何系统 / 编译器:
流自身状态(
fail()/bad()/eof())判断是否出错;再通过
errno+strerror/strerror_s获取具体错误原因(底层逻辑一致,仅 VS 有安全限制)。C++11 前后都一样,只是 C++ 11 之后,新增了个封装的适合全平台的
std::system_error。C++ 流的
read:
在 GCC 下,它是封装了 Linux 的系统调用 read,
在 VS 下,它是封装 Windows 的系统调用ReadFile
这种理解已经触达 C++ IO 流的底层实现本质,远超普通开发者的表层使用认知,是深度底层级的正确认知。
其实如果不钻研我这么深底层的话,就是相当于改了一句话,任何都没变,任何人可能都没研究我这么深就觉得无所谓了。
查看代码
//C++11 前(仅流状态 + errno) #include <fstream> #include <cstring> using namespace std; int main() { ofstream fout("test.txt"); while (/* 写数据 */) { fout << "data"; if (fout.fail()) { // 仅能靠errno+strerror拿错误(非标准封装) perror("写文件失败"); //写法一:底层读errno // 或 strerror(errno) //写法二 break; } } } //C++11 后(保留原有方式 + 新增标准错误封装) #include <fstream> #include <system_error> // 新增头文件 using namespace std; int main() { ofstream fout("test.txt"); while (/* 写数据 */) { fout << "data"; if (fout.fail()) { // 方式1:仍能用原有errno(兼容) // perror("写文件失败"); // 方式2:C++11新增——标准错误封装(重点) error_code ec(errno, system_category()); // 标准化错误码+描述(跨编译器统一) if (ec) { // 标准错误信息(替代strerror) return ec.value(); // 标准错误码 } break; } } }注意:此文搜“发现 VS 里也是”,
while(!fin.fail())和while(fin.read(...))的底层逻辑(判断流的fail状态)是 C++ 标准规定的,VS 和 GCC 都完全遵循,这个记清楚,豆包总误人子弟说其中的一个是依赖 GCC。关于咋这么混乱:
:C++ 早期标准只定义语法 / 核心逻辑,把系统级 IO、错误处理甩给 C 库 / 操作系统,而 Linux/Windows 内核、C 库(GCC/VS)实现差异大,没法统一;
厂商取舍:微软 / 开源社区为性能、安全(如线程安全)各自加专属方案(
strerror_s/FormatMessage/strerror_r),不愿妥协统一;C++11 虽补了
std::system_error,但要兼容历史代码,没法废掉旧方案,统一不彻底;我总会思考很多,比如 C++ 用
ifstream打开文件失败,实际是「C++ 流 → 调用 C 库fopen→ 调用系统open」,只要open失败,系统就把错误码存到errno,你直接用strerror(errno)看 “文件不存在 / 权限不够” 就行,我之前一直思考是 C++ 层、C 库层还是系统层的错,是否会通过errno体现,毕竟 errno 只是 C 的,哎了解的越多越感觉没法学习越头大。(其实抛砖引玉了)操作系统各自都有原生错误码,千奇百怪各式各样不统一且都不是给人看的,C 标准只规定不同OS报错的时候都把错误信息归集设置到
errno里。
std::system_error是 C++11 标准类(跨编译器 / 系统),Linux 下封装的是errno,Windows 下封装的是GetLastError()。简单说:std::system_error不是 “换皮的 strerror”,而是 C++ 为了统一处理 “不同系统的错误码” 设计的标准方案 —— 它在 Linux 下会用errno,但这是 “适配系统”,不是 “依赖 GCC 特性”。
std::system_error(std::error_code(errno, std::generic_category())).what()是 C++11 标准写法,将系统调用的errno错误码封装为 C++ 错误对象,返回人类可读的错误描述字符串,替代 C 风格strerror(errno),适配 C++ 异常 / 错误体系,和perror()均基于errno,C++ 流(iostream)底层由于会调用 C,又没人重构写 C++ 标准的东西,所以 C++ 流调用的时候,底层 C 系统调用失败时会置errno,进而 C++ 流也会得到这个值,但 C++ 规则是流错误优先设内部状态(如failbit),不直接依赖其做错误反馈,所以一般会用但不建议。C++ 里可以写
strerror(errno)!核心不是 “能不能写”,而是 “什么时候写”—— 仅对系统调用(open/mmap/sendfile)用,对 C++ 流(fstream)绝对不能用,C++ 里 ≠ 必然用流,大厂 Linux C++ 服务端开发中,处理文件 / IO 时,系统调用(open/sendfile/mmap)远比 C++ 流更常用—— 流仅适合简单场景,高性能 / 核心 IO 全靠系统调用,场景差异:
简单工具 / 小文件:可用 C++ 流(fstream),但错误处理绝不能用
strerror(errno);高性能 / 大文件 / 核心服务:必用 Linux 系统调用(open/sendfile/mmap),此时
strerror(errno)是正确写法;面试核心:面试官问 “文件复制”,若答 “只用 C++ 流”,会被认为不懂高性能 IO;正确思路是 “简单场景流(正确处理错误)+ 高性能场景系统调用(
strerror (errno))”。C++ 是 “多范式语言”,Linux 服务端开发中 C / C++ 混合用是常态,流只是其中一种 IO 方式,不是 “必然选择”!
高潮总结(甚至通过追问真的精通了、触类旁通了整个这块的知识!!!且不止是错误处理,甚至延展到对
try捕获异常等知识的领悟!对代码逻辑的全方位的领悟!详见下文):先回顾个异常的知识:
查看代码
#include <iostream> #include <stdexcept> int main() { try { // 主动抛出一个简单异常 throw std::runtime_error("哈哈测异常"); } catch (const std::runtime_error& e) { // 捕获并打印异常信息 std::cerr << "捕获到:" << e.what() << std::endl; } }
try块:放可能抛异常的代码;
throw:主动抛异常(实际场景是代码自动抛);
catch:精准捕获对应类型异常,e.what()打印异常描述;std::runtime_error就是 “程序运行时触发的通用异常”,是 C++ 里最常用的 “兜底” 异常类:比如代码跑的时候遇到 “参数错”“逻辑错”,就抛这个;
ios_base::failure是流专属异常,runtime_error是通用款,更常用。
const &(常量引用)既避免拷贝异常对象(省内存),又能防止误改异常内容。
throw扔的是std::runtime_error类型的异常,catch必须写对应类型才能 “接住”,即必须匹配。学英语:
generic通用的,category()分类,exceptions例外的。test测试,text文本比如:
fin.exceptions()设置 / 获取流的 “异常触发规则”(比如让流遇到 failbit 时抛异常),fin.exceptions(fin.failbit);设置fin流此后只要触发failbit错误状态,就会立即抛出异常。豆包的回答越来越好也离不开我的提示词:我现在有点懵的是
what这玩意到底跟着谁的?是不是只要用就只有std::ios_base::failure::what()这种写法,我现在连谁跟谁是一家都没搞懂感觉支离破碎的 ,重新串联梳理!!第一步:先认家族,C++ 处理文件流(比如
fstream读文件)的错误,就分两伙,彼此独立但偶尔会联动:
家族名 管啥错?(例子) 核心标识(记这些就够) 系统调用家族 底层和操作系统打交道的错(文件打不开、权限不够) errno、std::system_error流自身家族 上层流操作的错(读文件时遇到非数字、流本身坏了) failbit/badbit、std::ios_base::failure第二步:
what()不是 “专属品”,是 “通用工具”
what()就像“错误翻译器”—— 不管啥家族的错误,只要是 C++ 异常类,都带这方法,作用就是返回 “人话版错误描述”,不同家族的what(),翻译的内容、用法都不一样:1. 系统调用家族的
what()
适用场景:文件流底层调用操作系统失败(比如
open文件失败),此时操作系统会把错误码存到全局变量errno里;用法:用
std::system_error把errno“包起来”,再调what(),比如:std::system_error(errno, std::generic_category()).what()(std::generic_category()只是帮errno的数字错误码 “配人话”,不用深究);核心:这个
what(),跟着系统调用错误errno走。2. 流自身家族的
what()
适用场景:流上层操作错(比如读数字读到字母、流缓冲区坏了),此时不会改 errno,只会标记流的状态位(
failbit/badbit);用法:先让流抛出异常(
fin.exceptions (fin.failbit)),再捕获流专属的异常类std::ios_base::failure,用捕获到的异常对象 e 调what(),比如:catch (const std::ios_base::failure& e) { e.what(); }核心:这个
what(),跟着流专属异常std::ios_base::failure走例子:(搜“其实抛砖引玉了”提前想到了)(注意这个例子有报错,后面说)
查看代码
#include <fstream> #include <iostream> #include <system_error> #include <stdexcept> int main() { std::fstream fin("不存在的文件.txt"); if (!fin.is_open()) { //1、查系统调用家族的错:用errno+system_error的what(),看底层为啥打不开,比如文件不存在 std::cerr<<"系统层面错:"<< std::system_error(errno, std::generic_category()).what()<<"\n"; //2、查流自身状态:用rdstate()看流的状态位(是failbit触发了) std::cerr << "流状态位:" << fin.rdstate() << "\n"; fin.clear(); try { // 让流抛出自身异常 fin.exceptions(fin.failbit); }catch (const std::ios_base::failure& e) { //3. 查流自身家族的错:用流专属异常的what(),看流的错误描述 std::cerr << "流层面错:" << e.what() << "\n"; // 捕获异常后直接退出,阻止异常传播 return 1; } } fin.close(); // 补全:关闭文件流,好习惯,即使程序结束会自动关 return 0; }先说代码语法:
std::ios_base是 C++ 里所有流(比如fstream/cin/cout)的最底层基类,之前接触的std::ios_base::failure、failbit、badbit、exceptions()这些,全是定义在std::ios_base里的。你写
fin.fail()本质还是用了std::ios_base里的东西,只是 C++ 帮你省略了写法,不用手动写std::ios_base::而已。
fin是fstream对象,fstream继承了ios_base的所有东西(包括fail()方法、failbit状态位);fin.fail()→ 等价于检查fin的状态位里是否包含std::ios_base::failbit;底层代码大概是:
bool fail() const { return (rdstate() & failbit) != 0; },因为fstream把ios_base里的failbit、fail()这些都 “继承并公开” 了,直接通过fin调就行,属于语法糖(简化写法)。
ios_base::failure里的ios_base::必须写死,因为failure是ios_base的嵌套类,failure藏在ios_base这个 “大抽屉” 里的专属异常类,没这层就找不到failure;但fail()/failbit不用写ios_base::,因为fin(流对象)把这些东西 “拎出来” 放自己身上了,直接用fin.fail()就行,不用翻抽屉。再说这个代码,有
clear()运行直接崩溃:,注释掉就没事
。
错误代码豆包说纯为了讲清 “两个错误家族” 的区别(教学用),实际开发没人写这么全,属于 “拆细讲原理” 的写法,实际只写系统级错误(
1、的那个errno+system_error的what ()),流自身错误(ios_base::failure那套)几乎不写(也几乎流错误本质都是系统调用的错),因为文件流的错基本都是底层系统调用失败(文件不存在 / 权限不够),因为 C++ 流(比如fstream)本质是 “套壳,上层看着是 C++ 流操作,底层全是调 Linux 系统调用(open/read/write),所以流报错的根源基本都是系统层面的问题。
fin.exceptions(fin.failbit):强制让流 “遇到failbit错误时抛出异常”(流默认不抛异常,只改状态位);
catch (const std::ios_base::failure& e):捕获流专属的异常(必须写ios_base::,不然找不到这个异常类);
e.what():打印流自己对这个错误的描述(比如 “ios_base::failbit set”),但这个描述很简陋,远不如系统错误有用(实际开发也几乎不写这部分)。科普:
写
catch (const std::ios_base::failure& e):只接流相关异常,其他标准异常比如std::runtime_error接不住;写
std::exception& e:ios_base::failure继承std::exception&。std::exception&能接所有继承自std::exception的标准异常(包括流异常、运行时异常等),范围更广;开始分析输出:
(这里其实豆包反复误人子弟,但深究发现第一本身全网就没这么深的东西,大厂无论面试和工作都不会考不会用到,且全网几乎没有这么细的底层细节文档,加上我研究豆包给的这代码是教学拆分解构的极端写法,实际开发没人这么写,所以豆包反复绕弯、说不准。其实也难为豆包了,但我死轴就是去研究,真的也觉得有了些收获)(而且记忆功能纯扯犊子,单次会话的上下文关联能力有局限,目前无法永久记忆,总他妈三五个问题就不记得我的要求了)
注:这里死全家的豆包提到clear是有什么库自动clear,纯瞎扯耽误我好几个小时!死妈的狗玩意!!气死我了!
fin.exceptions(std::ios::failbit)功能告诉流:只要触发failbit,就抛出ios_base::failure异常然后
fin.open("不存在的文件.txt")open 失败,流自动标记failbit(状态位变为 “失败”);由于有个默认规定是说 IO 操作(如open/read/write)执行完毕后,流内部检查,检查状态位是否匹配exceptions规则,所以此时open失败触发检查发现状态位含failbit,则直接抛异常。这里起初说什么分两步先是看是否有流问题再看是否匹配 fd 妈逼的 测试 + 追问 浪费我又好几个小时,最后发现是豆包编的规则艹了!Q:然后自己追问出更加细节的东西,流不匹配咋整?我一开始以为是清空了,因为扔异常和接异常必须类型匹配,既然设置的不匹配我理解就要清空为下次做准备,其实不是:
A:不匹配时就一个结果:不抛异常,不存在 “不匹配就清空” 的规则,只有你手动去重置错误位,
failbit才会变,否则错误会一直保留(即failbit保持为 1,fail()返回true、is_open()返回false,能正常查到错误)不匹配时只是不抛异常,不需要“捕获”,你直接通过fail()/is_open()就能查到open()失败的错误Q:不抛异常不会崩溃吗?
A:不会崩溃!
open()失败后仅置failbit=1,不匹配时不抛异常,程序不会崩溃 —— 只是流处于错误状态,你可以选择忽略(程序正常运行),也可以通过fail()/is_open()检测到错误后处理(比如提示用户、重试打开),完全不会触发崩溃,崩溃只可能是你自己写的代码处理不当(比如用错误的流读写),和 “不抛异常” 本身无关。查看代码
#include <fstream> int main() { std::fstream f; f.open("不存在的文件.txt"); // open失败,置failbit=1,不抛异常 // 这里程序完全正常运行,不会崩溃 if (f.fail()) { // 检测到错误,手动处理 return 1; } return 0; }特意加上了return,这回至此感觉尽管全是 100% 不考的,但一意孤行就学就是钻研好奇强迫症,感觉把所有 echo、捕捉异常各种细节全串联上了(博客顺序真的无法顾及了,echo 内容在后面,光是拉取豆包的回答能整理出来,就他妈已经异常头大痛苦了)
Q:我咋记得没抓住是崩溃呢?
A:只有抛出了异常但没捕获才会崩溃!
open()失败时:
若
failbit和你设置的exceptions匹配→抛出异常,此时没写try/catch捕获→程序崩溃;若不匹配→根本不抛异常,自然不存在 “没 catch” 的情况,程序不会崩溃,只是
failbit保留为 1,流处于错误状态而已。你记的 “没抓住就崩溃” 是对的,但前提是 “有异常抛出来”—— 不匹配时连异常都不抛,谈何 “没 catch 崩溃”?
另外你提的崩溃原因:
对无效 fd 做 close:这是系统层面的错误,和流的
failbit、异常捕获无关,属于代码操作错误导致的崩溃;设置规则(
exceptions)时本身不会有问题,除非你写错参数(比如传非法值),但这也是代码写错的问题,不是 “规则本身” 的问题。
exceptions顺序错也不会崩,只有匹配的错误发生 + 没 catch 才崩!比如提到的:先设规则后 open 失败,这里规则匹配会抛异常(没 catch 才崩);规则不匹配→不抛异常,仅置 failbit,程序不崩。即顺序错不崩,规则不匹配错误类型也不崩!核心结论:只有抛异常却没 catch 才崩溃,不抛异常(不匹配)时,哪怕有
failbit错误、没做任何处理,程序也不会崩溃!另外只有手动
clear才会重置状态终于通透了!嘎嘎透彻!!痛苦的是豆包无尽追问最后得到正确的东西,但依旧是暂时“训练”豆包大模型,我为了写博客,删除记录完的问答,这时候哪怕重新把博客记录的正确内容“喂”给他,他依旧会无尽的犯错,也说明了这玩意没有我的意志力无尽追问,全网和大模型哪里都无法找到这个知识!无价之宝
继续:
傻逼豆包起初说的是,设置规则和触发错误顺序错会立马崩溃,又说什么二次触发啥的,追问好几个小时+实操发现根本不是!
clear是清空fail状态但不修复无效 fd,等后面用到了close时,直接触发fail但没人接,直接就崩溃了!崩不崩和设置顺序完全无关!因为我注释掉close后发现无论有无clear都没崩(自己代码程序结束自动close了不会泄漏,但长时间运行的服务器必须close此时就会崩)注意:
fstream无“成功 / 失败” 数值返回,仅能通过is_open()/fail()等成员函数返回 bool 值判断状态;C++11 后 fstream 的 open () 返回流对象自身引用,仅为支持
f.open("a.txt").fail()这类 “调用 open 后直接链式查状态” 的写法,无实际状态意义,属于语法层面优化,非核心功能。
is_open():只查文件 “是否打开”,仅文件流可用;
if (流对象.fail()):查流 “操作是否失败”,所有 IO 流可用,覆盖打开 / 读写等全流程错误。插一句:
段错误:
Segmentation fault (core dumped)(核心已转储),是 Linux 系统在程序触发段错误等致命错误崩溃时,将进程崩溃瞬间的内存、寄存器等核心数据保存到名为core的文件中,供开发者用 gdb 等工具调试定位崩溃原因,代码中对无效 fd 执行close()触发段错误时就可能出现该提示回头看代码:
加
clear:fin.clear()后流状态正常,但对无效 fd 操作即close相当于open失败,都是置fail,但后面再没catch接,所以直接崩溃。注释
clear()后流错误状态直接抛异常被下面的catch接住了,所以没事。C++ 流常见的就是
std::ios_failure这里狗逼豆包又他妈的误人子弟了,其实就是代码流程上往下,结果豆包总他妈的给我说是 try 是往上找接他的 catch,具体是说比如
void f() { throw 1; } // 步骤1:异常在这里“出生” int main() { try { f(); } // 步骤2:异常“回到”调用f()的这里(往上回溯) catch(int) {} // 步骤3:在这行(代码行的下方)接住 }估计被 99% 的傻逼程序员的上层思维强扭了,这他妈了解底层后就是应该叫往下找。
当往下找不到就直接中止程序并终端显示:
terminate called after throwing an instance of 'std::__ios_failure':程序要终止了,因为抛出了异常但没人接
what(): basic_ios::clear: iostream error:抛出的是 C++ IO 流专属的异常类型
Aborted (core dumped):异常没接住 → 系统收到终止信号 → 程序被掐死① C 语言的
close(int fd)系统调用根本不抛异常(C 语言本身无异常机制),仅返回 - 1 并设置 errno;② C++
fstream的ios_failure异常,是你主动调用fin.exceptions(failbit)设置了 “流触发 failbit 时抛异常” 才产生的 —— 若没设这个异常掩码,哪怕 fd 无效、流状态错误,也不会抛异常,更不会出现terminate()(结束运行)和Aborted(强行中断);③ 只有 “设置了流异常掩码 + 流触发对应状态位 + 未捕获异常”,才会走到
terminate()→Aborted所以这个报错是异常,我起初误以为是段错误
段错误是“程序乱访问内存(比如读不存在的内存地址)”,而你这是 “C++ IO 流按规则抛了个没接住的异常”,本质是 “逻辑错误(操作无效 fd)触发语言层面的异常机制”,不是 “内存访问错误”
👉以上都不是服务端开发的写法,我这些全都是 100% 不考也不会用到的无用功:正常文件打开失败后,直接查 errno 处理并退出,绝不调用
exceptions()设置流异常服务端处理文件 / 网络 IO 时,
fstream底层就是 Linux 系统调用(open/read/write),errno是内核返回的错误码,strerror(errno)能精准输出 “文件不存在 / 权限不足 / 磁盘满” 等具体原因,这是定位线上问题的核心手段;所谓 “errno 是 C 的、流不建议用”,是脱离服务端实际开发的纯理论,基础岗写代码 / 面试时,处理文件流错误必须用strerror(errno)(或 C++ 封装的std::system_error(errno))流的
fail()/bad()只告诉你 “错了”,但说不出 “为啥错”(比如只知道文件没打开,不知道是不存在 / 权限不够 / 磁盘满);流底层调用系统函数(open/read)失败时,会把系统错误码存到 errno 里 —— 只有查 errno,才能精准定位根因,这是流自己的错误接口做不到的。C++ 标准想让你 “用纯 C++ 方式处理流错”(理论),但流错的根源全是系统调用(实际),所以实际开发中:✅ 必用:errno(查错根因);❌ 不用:流的异常 / 状态位(仅懂原理,落地删)
无效句柄不需要关闭,也无意义且易触发系统错误,因为无效句柄本身无内核资源关联,关它既释不了资源还可能扰乱系统句柄表。
std::fstream fin; fin.open("不存在的文件.txt")和std::fstream fin("不存在的文件.txt");完全等价。然后上面的代码尽管不会用到也不推荐,但按照各种规范就算写(哪怕不会写这种)也要改进下,把规则放到前面:
查看代码
//叫写法1吧 #include <fstream> #include <iostream> #include <system_error> #include <stdexcept> int main() { std::fstream fin; fin.exceptions(std::ios::failbit);//提前设置规则 try {//流异常机制(被动等报错)写法 fin.open("不存在的文件.txt");// 底层调用系统open,失败后OS设errno=2,流标记failbit,触发异常,直接跳catch,下面的close不会执行 std::cout << "这行能打印吗?" << std::endl; // 不会打印 fin.close(); // 不会执行,close只给 open 成功有效句柄场景用。这种写法也是把业务放到 try 里,这种即“异常机制 + try 里塞逻辑”的写法,就算需要C++流的写法的场景也既然不推荐 }//这里close放外面代码也不认识他因为fin.open定义在里 catch (const std::ios_base::failure& e) { // 流只告诉你“触发了failbit”,想知道具体错因,得手动读errno std::cerr << "哈哈流层面错异常原因:" << e.what() << "\n"; std::cerr << "具体错因:" << std::system_error(errno, std::generic_category()).what() << "\n"; } } /* root@VM-8-2-ubuntu:~/cpp_projects_2# ./a 哈哈流层面错异常原因:basic_ios::clear: iostream error 具体错因:No such file or directory root@VM-8-2-ubuntu:~/cpp_projects_2# */然后至此又无意间看到豆包给了另一种写法,然后衍生出我的一些问题与思考,但同样全都是 100% 不考,但我遇到了看到了就强迫症研究了且误打误撞学了些有用的东西:
查看代码
#include <fstream> #include <system_error> // C++11标准头文件 #include <iostream> using namespace std; //写法2:主动查状态(生产/逻辑最稳) void test_check_status() { std::fstream fin; fin.open("不存在的文件.txt"); // 底层调用系统open,失败后OS设errno=2,流标记failbit(无异常) // 主动查流的句柄是否有效(只查结果,不触发任何额外操作) if (!fin.is_open()) { // 直接读OS设的errno,精准拿到“文件不存在”的具体原因 std::cerr << "打开失败,具体错因:" << std::system_error(errno, std::generic_category()).what() << "\n"; return; // 失败后直接退出,不调用close(无有效句柄,close无意义) } // 只有打开成功才执行close fin.close(); } int main() { std::cout << "\n=== 测试主动查状态写法 ===\n"; test_check_status(); } /* 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./a === 测试主动查状态写法 === 打开失败,具体错因:No such file or directory root@VM-8-2-ubuntu:~/cpp_projects_2# */注意:C++ 流(fstream)不适合高并发服务端,这是铁律;写法 2 生产最稳的前提是必须用 C++ 流(比如工具脚本),而非服务端场景;
起初这里我是在好奇,尽管服务端开发不用 C++ 流,但用的场景下,我发现了有
.open和is_open俩种写法,有啥差别,豆包说一个主动一个被动
写法 1(异常机制):
fin.open("tesdt.txt") + 异常
核心:提前给流下 “报错规则”,流触发错误时自动抛异常,你被动接;
问题:流异常只封装 “是否错”,不封装 “错在哪”,需手动读 errno;且若操作不当(如失败后调用 close),会直接触发异常崩溃;
fin.open()底层会调用操作系统的系统调用(如 Linux 的open()),失败时会:① 给流标记failbit;② 操作系统设置errno;
本质:依赖流的 “异常功能”,可控性差。
写法 2(主动查状态):
if (!fin.is_open())
核心:流只做 “打开文件”,你主动用
is_open()查结果,再读errno拿具体原因;
fin.is_open()只做一件事:检查流内部是否持有 “合法的文件句柄”(即底层系统调用是否成功拿到句柄),不碰errno,只返回布尔值;优势:无任何隐藏坑,失败后不调用 close 就不会有二次异常,错因精准;
本质:只用流的 “状态查询接口”,不碰异常功能,完全可控。
这俩全是 C++ 流(标准库)的成员函数,不是系统调用
但起初我没听懂这个主动 vs 被动,后来让豆包给出的就是这俩代码,懂了,发现有点像我啃《TCPIP网络编程》里信号编程里的
signal()/sigaction()函数,然后豆包开始抛砖引玉了,说都是提前给系统设“触发信号就执行指定处理逻辑”,和流里fin.exceptions()提前设“触发failbit就抛异常”的逻辑完全一致,都是“先定规则,等事件触发再执行”,本质都是“被动响应式”设计。且我发现方法一是在错误的东西里写业务,很臃肿很 der,方法二是把错误拎出来
open失败时,系统设errno记录错误原因、流自动置failbit标记失败,但仅当你手动设置了流的异常掩码(如exceptions()),才会抛出异常,否则需自己用is_open()检查。Linux C++ 服务端开发中,完全不用
fin.open()和fin.is_open()这两个 C++ 流的成员函数,务端文件操作只用系统调用open()(发起打开文件,返回文件描述符,失败返回 - 1),靠errno查失败原因,根本碰不到流的这两个方法。Q:那搞这俩逼玩意出来干啥?
A:这俩是 C++ 为简化文件操作封装的接口,专门给小工具 / 非高性能场景用(服务端不用);核心区别:
open()是 “执行打开动作”,is_open()是 “校验动作结果”,看似冗余但符合 C++ 封装逻辑,只是对服务端开发无意义。✅ 流异常(
fin.exceptions(...)+ 抓ios_base::failure):全场景几乎不用;✅ 服务端实际用的:系统调用(open/close/read/write)+ 查
errno(不是fail())——fail()是流的方法,系统调用根本没有这个✅ 小工具用流的场景:也不用异常,只用
fin.fail()/fin.is_open()判断流是否出错(替代系统调用的errno)。C++ 流是 “封装层”,故意把底层系统错误(
比如文件不存在 = errno=2)藏起来了,它只告诉你 “流出错了”,但不告诉你 “底层为啥错”。而服务端开发要的是 “精准定位错误”(比如文件不存在 / 权限不够 / 磁盘满),所以用系统调用:查errno能直接拿到错误码(2 = 文件不存在,13 = 权限不够),再转成具体提示(strerror(errno)),信息精准;用流:哪怕你想拿底层错误,也得额外写代码从流里扒errno,多此一举,这也是流被服务端抛弃的关键原因。流这完全不考的所有问答(最原始草稿问答) 豆包链接
各种问题和思考:(一意孤行)
关于为啥大厂不考流?为何我总感觉C++流很重要实际不考不问不用呢?
- 啥场景用C++流?
关于我研究这个不考的完全无意义的但却真的感觉学到了很多有用的会考的,那正常来说大家是学啥学到的这些有用的东西的?
我感觉自己就是个异类,从不考的代码中,自己测试反复各种加注释去掉这个去掉那个看会发生啥,但没人研究这个,那我本身之前就懂这章的RAII,然后看作者代码有C++流,跑去研究流了,结果研究一个月发现 100% 不考也工作不用,但又不能直接白费缴枪交枪了吧?发现一路从C++流误打误撞学到C++的大文件拷贝等功能,又说大厂用零拷贝,又去研究零拷贝,然后发现之前代码不严谨又去研究一周的errno等所有涉及到的错误码的东西,然后又发现代码return 1但无感知,又了解到可以通过echo感知,哎~~~~(>_<)~~~~,那return值和echo$?这些具体面试不需要?工作呢?都是工作用再学?我是误打误撞一意孤行得到的收获!!那正统大家是学啥学到这些知识的?还是说没必要学?
我研究这些任何用都没有,也不考,但总感觉因为我理解能力差,而如今通过这个把理解力提高了或者说更加懂这里的一些专业术语了,导致我发现自己在学很多别人觉得难的晦涩的东西会更容易
只有自己钻研一遍错误的才能更好的理解正确的东西!!
前期看不到收益
豆包说这个不考。
wx搜“一意孤行”、“生生”、“一路”、“欣慰”、“科比”。
图片收藏 & 一意孤行文件夹里:【吴师兄别在底层原理浪费太多时间 & 别钻研技术细节先进去】、【小林面试编故事 & 非技术岗转行别报班 & 别死磕源码 & Linux 内核坑位少不招新人】、【无数鱼皮的培训班小林coding的培训班喜报成绩】、【代码随想录贴吧牛客网满天 985 硕 cpp 狗都不学 C++ 凉了 Java 起码有口饭吃】。
哎,思考我钻研这些豆包说不考,我一意孤行但真的发现确实有收获,明白了捕获异常更细节的东西,明白了代码流程,对代码写法风格有了更高的认知(就比如方法一、二)(wx搜“马群”、“太官方”)
Q:又思考
return的事,return 1如果换成0或者去掉呢?我发现都一样啊,我无感知啊?这玩意干啥的?之前刷题没用过这个:A:
return 1是给操作系统 / 调用方的 “错误信号”,即给外部(脚本 / 运维 / 其他程序)看的 “状态标签”,外部需要判断程序是否正常时,才用echo $?这种手段查,代码里跑的时候完全感知不到区别:
return 0是正常结束信号,去掉return是默认return 0,和代码崩不崩无关,只影响外部感知程序是否正常。return 1(你代码里的用法)仅用在 “open 失败、逻辑错误” 场景:告诉操作系统 “这个程序不是正常跑完的,是因为错误终止的”。Linux 用echo $?能看到退出码是 1。实际测试发现挺好玩,改成 return 7 的居然真的是这样echo $?只查上一个在终端执行的程序 / 命令的退出码,敲完./a立刻敲echo $?,查到的就是./a的 return 值;如果中间敲了其他命令(比如 ls、cd),再查就是其他了./a # 运行你的程序 echo $? # 查到的是./a的退出码(1或0) ls # 敲个其他命令 echo $? # 查到的是ls的退出码(正常是0),和./a无关插一句:g++ a.cpp -o a是起名字,如果没-o就是诗默认a.out,听起来很奇怪但就是如此,Windows 是靠后缀,但 Linux 文件类型只看「文件属性 + 权限」(比如可执行权限),后缀只是给人看的标记,系统不管。比如:你把a(可执行文件)改名叫a.jpg,只要有可执行权限,依然能./a.jpg运行;把a.out改名叫a,也能正常跑 —— 后缀和文件功能、类型无关。
cerr是无缓冲的自定义文字无拼接,cout是有缓冲的。perror依旧是 C 的,但线程安全原子的,但不是 C++ 也不咋用因为拼接其他东西不灵活只能perror("stat error");,想加东西就费劲;默认
stderr、stdout绑定屏幕,再深入点,这俩就是底层的两个独立的物理通道,先梳理下
stdout:有缓存的屏幕输出(cout 用它),攒够内容才显示;
stderr:无缓存的屏幕输出(cerr/perror 用它),立刻显示;
cerr:C++ 的错误输出流,直接写 stderr(无缓存,只打你写的内容);
perror:C 函数,自动读 errno 拼错误描述,写 stderr(无缓存,省事儿);(也叫无缓冲)
梳理完继续说:
cout/cerr是 C++ 流:cout绑定stdout、cerr绑定stderr,stdout/stderr是系统级的输出通道默认绑定屏幕,C++ 流本身不能改绑定,但可以改stdout/stderr的目标,cout/cerr的输出目标会跟着变,即可以通过重定向(比如./程序 > 日志文件)自定义输出目标(写到文件 / 打印机等),命令行里的
>就是默认修改 stdout 的输出目标(不用写 stdout 字样),这是系统约定的简写规则:> 文件= 把 stdout(cout)的内容写到文件,stderr(cerr/perror)不受影响,如果想明确写 stdout,也可以写成1> 文件(1 是 stdout 的系统编号),2> 文件才是改 stderr(2 是 stderr 的编号)查看代码
#include <iostream> using namespace std; int main() { cout << "cout的" << endl; // cout输出 cerr << "cerr的" << endl;// cerr输出 }Q:那和 C++ 的??
A:首先
>和>>全是系统命令行的重定向符号,和 C++ 本身毫无关系!二者都用来改 stdout/stderr 的输出目标,区别仅在于:>清空原文件内容后写,>>追加到文件末尾。命令行
>/>>是系统重定向,C++ 里<<是输出、>>是输入。但他俩就像苹果和苹果手机没 JB 任何关系,非要强行对比仅从 “内容最终到右边” 这个结果看,二者一致:
系统
>>:程序输出内容 → 进入右边的文件;C++
>>:输入源内容 → 进入右边的变量。继续说,
perror("打开文件失败"); // 自动读errno,拼接成:打开文件失败: No such file or directory
封装是 C++ 对底层通道(stderr)的抽象封装(cerr 是流对象),
perror 是 C 直接操作 stderr 的函数,内部直接操作 stderr,没有像 cerr 那样对 stderr 做额外封装层级,而 cerr 是 C++ 类,对 stderr 做了面向对象的封装。
cerr作为C++的ostream类对象,比perror多了「面向对象封装(支持<<流运算符)、类型安全、可自定义输出格式/重定向」,而非像perror仅固定格式往stderr写错误信息。syscall 不只是系统调用的统称,它是程序员 / 程序直接请求操作系统内核服务的接口 / 机制(比如读写文件、操作进程的内核级调用),是用户态到内核态的入口,而 perror 这类 C 库函数是基于 syscall 封装的上层接口。
Linux 内核里的 read 是真正的 syscall(系统调用),而 C 标准库的 read 函数是对这个内核 syscall 的封装(上层接口),代码里调用的 read 是 C 库函数,它最终会触发内核的 read syscall,内核 syscall 是底层实现,你代码碰不到,只能通过库函数间接调用。
read(fd, buf, len)调用的是C 标准库的 read 函数(上层封装),这个函数内部会通过软中断 / 指令触发 Linux 内核的 read syscall(真正的系统调用)—— 你代码里直接写的不是内核 syscall,是库函数。查看代码
#include <unistd.h> // 引入C库read的头文件 int main() { char buf[1024]; // 你代码里写的这个read,是C库函数,不是直接的内核syscall read(0, buf, sizeof(buf)); }原型:
1、C 的 read(C 标准库函数)
<unistd.h>:read(int fd,void *buf 接收数据的缓冲区,要读取的字节数)
返回 > 0 = 实际读到的字节数;
返回 0 = 读到末尾(没数据了);
返回 - 1 = 读出错(此时 errno 会赋值)
2、C++ 的 read(iostream 流成员函数)
<istream>:istream& read(char* s 字符缓冲区,要读取的字符数)返回值:流对象本身(支持链式调用)。3、Linux 系统调用 read(内核接口,代码无法直接写除非写汇编)
总结:C++ read 是流封装、C read 是库函数封装、系统调用 read 是内核底层接口。
至此恍然大悟!!一直误以为网络编程里的
read是系统调用,其实是 C 的,通过 C 调用系统调用,豆包说编译后用strace跟踪(strace 能抓系统调用)懒得延展。
read/write/socket等 C 代码,是Linux 专属的 C 库函数(属于 POSIX 标准),Windows 的 C 库(如 MSVCRT)不实现这些接口,所以直接用不了 —— 核心是 “C 库接口随操作系统不同”,不是 “C 语言本身不能跨平台”。Linux 下的给程序员用read本质是 C 封装了 Linux 的系统调用。只不过 C 实现上仅仅适用于 Linux,C 标准跨平台,但实现各有各的。操他血妈!!!:
唉好他妈的头疼啊艹!!我现在在自学纯自己啃 Linux C++ 服务端开发基础岗的内容,结果总他妈的被豆包引出无穷无尽永无止境的一屁眼子的知识点,尸山血海爬出来。无尽头的砸时间。且不仅知识琐碎还经常他妈的学了好几天发现全是错的,豆包一直在误人子弟~~~~(>_<)~~~~,反复道歉反复误人子弟,感觉了解的越多,越没法学习?!越扣细越他妈没法进行卡这了,完全无法收拾烂摊子!!!本来之前说 C++ 就是没任何的 errno,结果现在又说 GCC 给搞了 errno,我他妈的我难道每学个知识点都要去学 C++ 标准、C 标准、编译器实现吗?!我太痛苦了!!豆包所有知识都是这么讲的啊!! 结果老子去 VS 里测试发现又不一样!Java 有这些屁玩意吗!!!!我他妈真的感觉C++ 比那些麻烦好多啊!!!咋就跟个草台班子一样呢?上次感觉 vim 就是个臭傻逼!这次感觉 C++ 就他妈是个垃圾艹!上次是啃《TCPIP网络编程》的 win 的底层 API 真的痛苦!
就算全世界的人都死光了我的心境也不会有一点波动!!被豆包气死了我!!
搞了一个半月勉强理解那些错误处理,结果今天追问的时候发现这一个半月学的东西全是错的!!!真的连骂豆包的一丁点力气都没了~~~~(>_<)~~~~
哎没办法继续重新说下吧但感觉更加清楚透彻了:
GCC 11 没把 C++17 里
fstream::open接收error_code的规则落地到代码里,所以我 VScode 远程控制腾讯云服务器用不了这个写法。但error_code这个东西本身是能用的(比如绑errno用),只是 GCC 11 没给fstream::open加接收error_code的版本,所以只有 “给open传error_code” 这一种用法用不了,其他用error_code的场景都正常。看代码:
查看代码
#include <fstream> #include <iostream> #include <system_error> // 需包含这个头 using namespace std; int main() { fstream f;// 先创建空流 error_code ec; f.open("tesdt.txt", ios::in, ec); if (ec){ // 直接判断错误码,不用再查is_open() cerr << "流错误:" << ec.message() << endl; } } //编译不过 #include <fstream> #include <iostream> #include <system_error> using namespace std; int main() { fstream f("tesdt.txt", ios::in); if (!f.is_open()) { // 用C++标准的error_code封装errno(仅GCC下临时取底层值,不依赖流的特性) error_code ec(errno, generic_category()); cerr << "流错误:" << ec.message() << endl; // 输出具体错误(如文件不存在) return 1; } } /* 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./a 流错误:No such file or directory root@VM-8-2-ubuntu:~/cpp_projects_2# */ /*注意:ifstream自带ios::in(只读)属性,fstream是通用流需显式指定ios::in 注意:可以 if (ec == std::errc::no_such_file_or_directory) { std::cout << "精准识别:文件不存在!" << std::endl; */第一个代码:
f.open("tesdt.txt", ios::in, ec)C++17 的,GCC 11 团队没把这个重载写进标准库第二个代码:
error_code(errno, generic_category())把系统底层的 errno(C 风格错误码)封装成 C++ 标准的 error_code,这是 error_code 本身的基础用法。科普:
if(ec)等价于ec.value() != 0,是判断error_code对象是否代表有错误发生(只要ec对应的错误码不是 0,条件就为真),想判断具体错得用ec == std::errc::no_such_file_or_directory。
error_code ec;就是创建一个 C++ 标准的错误码对象,即容器后续接收错误信息,替代传统的 errno,是 C++ 错误处理的核心对象!- 更新:下面划掉的是狗逼豆包昨天说的结果今天又变了,说那个是错的操他妈的!!死妈玩意!常 C++ 开发(文件操作、网络编程、读写文件、
socket通信等所有常规场景),处理errno时,只使用std::system_category(),永远不要用std::generic_category(),你的原有代码把generic_category()换成system_category(),就是标准、正确、可运行的写法。极少数非标准库用generic_category(),豆包举的例子我听都没听过第二个代码里
ec(errno, generic_category())是给这个对象赋值,把 C 风格 errno 转成 C++ 标准错误码。generic_category()就是告诉 C++,你要转换的这个 errno 是「系统级通用错误码」(比如文件不存在、权限不足这类操作系统返回的错误),是把 C 语言的 errno 转换成 C++error_code时必须指定的「错误码分类标签」!而这时候不出意外死全家的狗东西豆包又会说干扰你的东西,即:
generic_category():对应操作系统的通用错误(比如 Linux 的 errno=2 代表文件不存在)
system_category():对应特定系统调用的错误(和generic_category大部分场景下通用)然后实际只用
generic_category(),system_category()只有写系统内核代码才用,即代码涉及到syscall。注意:哪怕网路编程的系统调用read,也是 C 的,由 C 库操作系统,只有写比 C 更底层的代码才用system_category()捋顺几个:
errno:C 语言遗留的全局变量,存数字型错误码(比如 2 = 文件不存在),线程不安全;
strerror(errno):把errno的数字转成字符串描述(比如 "文件不存在"),纯 C 风格;
error_code:C++ 封装的错误码对象(含数字 + 描述 + 分类),替代 errno,线程安全;
system_error:C++ 的异常类,能包裹error_code,出错时可抛这个异常(而非裸error_code)总结:
1、
errno/strerror是 C 风格,error_code/system_error是 C++ 标准风格,大厂优先考后者;2、核心用法:用
error_code封装errno(你的第二个代码),或抛system_error异常;3、记住:C++ 写 Linux 服务端,尽量用
error_code/system_error,少直接用 errno/strerrorQ:那有
system_error为啥还来个error_code?A:
error_code:轻量级,只存错误信息,不抛异常,适合不想中断程序的场景;
system_error:是异常类,内部包含error_code,适合出错时要中断 / 捕获异常的场景;大厂开发里,两者搭配用:先用
error_code存错误,需要抛异常时包进system_error里。重载:就是同一个函数名(比如 open),能接收不同个数 / 类型的参数,编译器会根据你传的参数(比如传
ec或不传ec)自动匹配对应的函数版本但没实现,即“流相关操作”
f.open("xxx", ios::in, ec)报错,这是给fstream的open函数传error_code参数,属于「流的成员函数重载」,GCC11 没实现这个重载没问题的是“非流相关操作”:
error_code ec(errno, generic_category())。C++17 只是规定了
open可以传error_code的标准,但 GCC 编译器对 C++ 新标准的支持是分批、逐步落地的,哪怕 2025 年,腾讯云可能用的是老版本,如GCC11仍未补全该小众重载,本意是让流操作能直接绑定 C++ 风格错误码,替代手动封装errno!标准与实现:C++标准是 “规则”,编译器(GCC)是规则的执行者,执行者不会一次性实现所有规则,尤其是小众功能。所以:
第一个代码核心是
open调用时直接将错误写入ec,底层最终还是errno,但open传error_code的设计是编译器 / 标准库帮你做了 “自动把底层errno封装进error_code” 的工作,你不用手动写error_code ec(errno, ...),由库替你完成从errno到error_code的转换第二个代码是先执行流操作,失败后主动把全局
errno值封装进error_code对象,适配所有编译器的通用写法。感觉代码量没啥差别啊,纯脱裤子放屁扯犊子玩意,但其实关于线程安全有 TLS 的事这里之前学了一个半月豆包都没说:
我一直以为线程安全是线程间互相篡改啥的,但其实
errno早早 1995 年就是线程间安全的了,就通过 TLS 实现每个线程独立副本,各线程读写互不干扰:
TLS 的作用:解决「线程间
errno互相篡改」的基础问题errno 不是全局共享变量(早期是,C++11 后标准要求实现为 TLS),每个线程都有自己独立的errno副本,线程 A 的errno不会被线程 B 的系统调用直接修改,这是 TLS 带来的保障。总结:
strerror会维护全局 / 静态的错误信息缓冲区,多线程同时调用时会覆盖该缓冲区内容,导致返回的错误字符串错乱,所以strerror多线程间不安全流传
error_code,不碰全局errno,绝对安全,因为f.open(..., ec)是你指定操作显式可控修改ec,私有内存对象,其他操作不会碰它。手动套
errno的写法,仅当操作失败后立即读取errno时才安全,否则不安全,即看 “读取时机”,errno是所有系统函数隐式不可控篡改,ec(从errno赋值)的问题根源在errno梳理总结:
system_error和error_code都不依赖errno,除了errno还有自定义错误啥的,但目前计算机主流的就是errno这个值,所以他们都传递这个,但不是基于errno,类似于矿泉水瓶子一般都装水,但不是矿泉水瓶基于水,可以装任何,所以就目前主流都是传递errno来说,由于errno本身 TLS,所以线程间安全,因为都是副本。
system_error:自己有一套独立机制,无论传啥都线程间安全,但线程内手动套errno到error_code完全一样,必须在操作失败后立刻构造。
error_code:
流里传递(我环境没实现的那个),没封装
error,自己搞的一套东西,绝对安全,因为比如先f.open (..., ec)再f.read (..., ec),这时候后一次操作确实会覆盖ec里的旧值,但这是你主动可控的(你明确知道后续操作会更新这个ec),不是 “莫名其妙的覆盖”。所以只要用到ec一定是个对象的错误信息,即“天然线程安全”= 既不存在线程间篡改,也不存在当前线程后续操作覆盖的问题,无论何时读取ec,拿到的都是本次open操作的准确错误码,逻辑 + 线程双重安全。手动
error_code套errno:由于套的是errno,线程间安全,但线程内不安全,更准确说是“errno值可能被意外覆盖(时机失控),导致套入error_code的是无效值,比如你写了这样的代码:// 步骤1:执行一个可能出错的操作,错误码会写入当前线程的errno int ret = open("/test.txt", O_RDONLY); // 步骤2:这里插入了其他函数调用(哪怕是看似无关的函数) some_other_function(); // 步骤3:此时再读取errno,套入error_code std::error_code ec(errno, std::system_category());问题出在:步骤 2 的some_other_function()内部,可能也执行了系统调用,而这个系统调用如果失败,会覆盖当前线程的errno副本,流里传递error_code的写法是彻底绑定流操作。即这里的“线程不安全”≠ 线程间互相篡改(因为errno是 TLS,线程间本就互不干扰),而是指 “拿不到正确的错误码(逻辑不安全)” —— 这是当前线程内部的时序问题,而非线程间的安全问题。至此也通透了
以上是往流里塞
error_code和手动套error_code,然后我的思考是:
既然有
system_error为啥还要error_code?后者说为啥搞俩?用error不也行吗- 抛异常又是啥玩意?也设涉及啊
开始解答:
strerror是 C 的,C++ 的一些东西写起来费劲!和异常 / 类不契合,perror和cerr完全没必要掺乎进来,本来都是基于errno可自定义输出的东西
system_error和errno_code是 C++ 11 后的引入,适配 C++ 体系,差别是,先看代码:查看代码
#include <iostream> #include <system_error> // 必须包含的头文件 #include <fstream> // 用于造一个错误场景(打开不存在的文件) int main() { // ========== 场景1:只创建system_error对象,不抛异常,仅拿错误信息 ========== // 先造一个错误:打开不存在的文件,触发errno std::ifstream file("不存在的文件.txt"); if (!file) { //“临时对象拿what()”写法 const char* errMsg = std::system_error(std::error_code(errno, std::system_category())).what(); std::cout << "\n【不抛异常】错误信息:" << errMsg << std::endl; } // ========== 场景2:抛出system_error异常,用try-catch捕获 ========== try { std::ifstream file2("也不存在的文件.txt"); if (!file2) { // 抛出system_error异常(核心是throw关键字) throw std::system_error( std::error_code(errno, std::system_category()),// 第一步:把errno封装成C++的error_code对象,将错误传给system_error "打开文件失败" // 可选:自定义异常描述前缀 ); } } catch (const std::system_error& e) {// 第二步:捕获获取已生成的异常对象 // 捕获异常并打印信息 std::cout << "\n【抛异常】异常类别:" << e.code().category().name() << std::endl; std::cout << "【抛异常】错误码:" << e.code().value() << std::endl; std::cout << "【抛异常】完整错误信息:" << e.what() << std::endl<<std::endl; } } /* 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./a 【不抛异常】错误信息:No such file or directory 【抛异常】异常类别:system 【抛异常】错误码:2 【抛异常】完整错误信息:打开文件失败: No such file or directory */既用了
errno_code也用了system_error,因为system_error是 “包裹”error_code的,system_error本身不能直接关联errno,必须先把errno封装成error_code,再传给system_error用。总结:
error_code:是 C++ 对errno的 “结构化封装”(把整型errno变成带类型的对象);
system_error:是基于error_code的 “异常载体”(要么拿错误字符串,要么抛异常);
system_error可结合error_code使用(造异常),也可单独用;
error_code亦可单独用;流里塞的未实现。插一句:
Linux 默认用 GCC,Windows 系统本身没有 GCC,但装完也能敲
gcc/g++编译代码。GCC 核心是给 Linux 用的,大家都用 gcc/g++ 是因为它免费开源、跨平台、功能完整,且是 Linux 系统默认编译器,适配绝大多数 C++ 标准,成本低且兼容性强。再说点东西,“一路”,又发现点东西,操你血妈无穷无极你一屁眼子的知识点啊!!(这里又追问了一天)
strerror不在默认作用域,需包含头文件<cstring>(C++)/<string.h>(C),且要确保用std::命名空间(或声明using namespace std;)。这句话我又懵了。
这里其实只有一个头文件
<cstring>!
string.h:是 C 语言的头文件,专门处理char*类型的 C 风格字符串(比如strlen、strcpy、strerror这些函数),纯 C 代码里用它;
cstring:和 C 的string.h的一样,只是把函数放到 std 命名空间里,避免冲突
string:是纯 C++ 的头文件,和前两个没关系,专门定义std::string这个字符串类(C++ 风格字符串),完全不包含 strerror、strlen 这些 C 函数。
strerror,C++ 把 C 标准库函数(含strerror)封装在std命名空间下,避免全局命名冲突。
cout、strerror这些都是 C++ 标准库的东西,全部被放在std这个命名空间里;调用它们时必须加std。
std只是命名空间,纯语法层面的“名字分组标签”完全不是声明和实现分离概念里的实现!只是标签!
头文件(
<cstring>/<iostream>):告诉编译器 “有这个名字”;
std:::告诉编译器 “去哪个分组找这个名字”;实现:在系统库文件里,和
std无关。
std目的:C++ 标准库提供了大量函数 / 类(比如
cout、strerror、string),如果这些名字都直接暴露在 “全局范围”,很容易和你自己写的代码重名(比如你写了个cout变量,就会和标准库的cout冲突)。头文件(
<cstring>/<iostream>)的作用是告诉编译器 “某个名字的存在”(即声明),不包含任何实际执行的代码(实现)。所有标准库函数 / 类的实际执行代码(实现),都存在系统自带的 “库文件” 里(比如 Linux 的
libstdc++.so、Windows 的msvcrt.dll),这些文件不在你的代码里,编译时编译器会自动链接它们。简单说:头文件是 “说明书”,库文件是 “实际干活的工具”,std是 “工具的分组标签”。好 JB 抽象艹!但懂点了。他妈自己不写个、发明个编程语言感觉都不懂。发明 Unix 的为了学习而发明操作系统。你写std::strerror(errno)时(这里我又理解了好几个小时,真的极致的晦涩难懂,最后追问出这个才懂了,也不知道是我理解能力差还是咋的):
#include <cstring>—— 编译器从<cstring>里看到strerror的声明,知道这个函数存在;加
std::—— 编译器知道 “去 std 这个分组里找strerror对应的实现代码”;编译时链接系统库文件 —— 找到
strerror的实现代码,最终能执行。C 是早期语言,设计时未考虑名字冲突问题,而 C++ 为解决全局命名冲突。
此文搜“不报错,是”,
swap那个就是调用std里的不是自己写的。咋区分?是靠后缀吗?
.c:编译器默认按 C 语言规则编译(如不识别 namespace、bool 等 C++ 语法)、.cpp:编译器默认按 C++ 规则编译(支持 std 命名空间、类、模板等);但后缀可改:
# 同一文件test.c,按C++编译(识别std) g++ test.c -o test # 同一文件test.cpp,按C编译(不识别std,报错) gcc test.cpp -o test自己写个
abc函数,如果 C 库里有这个其也包涵这个头文件了,那就冲突 C++ 不引入std就没事。但我有思考:
C++ 防止重名而设计的
std这里,我没遇到头文件写多了报错的,只有写少了报错,但写多了比如来个<haha>头文件,然后里头有abc函数,这时候如果我只是随手加的<haha>头文件,但没加std,其实我想用的是自己定义的abc函数,那这不就会报错了吗!即虽然避免了冲突,但这里类似有声明没实现啊,因为头文件是声明,
std指导去哪个库里找实现,有声明无实现编译不报错但链接必报错。自己懂了:
有声明无实现只在用的时候才报错,那如果自己写的不叫用库里的所以不会报错!!而想用库里的必须加
std而既然有std也就没有【只声明无实现】的问题了写了个冲突测试无意间发现的一些事:
查看代码
#include<stdio.h> void printf(int a) {} int main() { printf(1); }以为会报错,函数签名不同,不构成 “重定义”,C 语言里判断函数是否重定义,看的是完整函数签名(函数名 + 参数列表):
标准库
printf的签名是:int printf(const char *format, ...)(可变参数)你定义的
printf签名是:void printf(int a)(单个 int 参数)两者参数列表完全不同,在 C 语言中属于不同的函数,而非 “重定义”,所以编译器不会报错,但继续写发现想冲突真的难:
一方面 C++ 中
printf即便签名完全一致也不会报重定义错:因为printf是 C 库函数,编译器对其做了「弱符号 + C 语言链接属性」兼容,会直接用你的自定义printf覆盖标准库的,这是编译器特例,和签名无关;另一方面就算 C++ 纯库函数(如
std::swap)同签名必冲突,但写法是模板,想写对都难哈哈注意:C 里没
swap函数,C++有,这样写就会出发冲突错误了:查看代码
#include <algorithm> using namespace std; template<class T> void swap(T& a, T& b) { a = a ^ b;//傻逼异或acm的玩意之前研究过,懒得再搞,只是少了一个临时变量的内存操作,在极致的底层场景下可能快一丢丢,但在现代编译器面前,这个差距可以忽略不计。正常这么写:T temp = a;a = b;b = temp b = a ^ b; a = a ^ b; } int main() { int x=1,y=2; swap(x,y); }此处的声明void swap(T& a, T& b),T&表示「非 const 引用」,目的是直接操作原变量(而非拷贝),实现真正交换;调用时写swap(a, b)即可,编译器会自动把变量a/b绑定到引用参数上,不用手动加&,引用的本质就是变量的 “别名”,传变量名就是传它的别名。注意:
T&表示非 const 引用能读能改原变量。const T&(const):只能读不能改原变量总结(形参实参):
1、传
&变量名(如swap(&a, &b))对应声明的参数是指针(T*),比如void swap(int* a, int* b);2、传变量名(如
swap(a, b)):
- 可对应声明的参数是值传递(
T):函数操作的是变量副本,修改不影响原变量;
也可对应声明的参数是引用(
T&):函数操作的是原变量,这是std::swap的写法;3、无其他情况:C++ 传参只有「值传递」「引用传递(
T&)」「指针传递(T*)」三种,传变量名对应前两种,传&变量名对应指针传递。函数调用时参数永远不会写
*,这玩意是解引用,解引用的前提是有有效指针。C 和 C++ 标准库中没有名为
sum的库函数。碎碎念:
用故事讲东西和比喻只是自己越来越懂,写书写教程写博客也是,都是给自己方便回顾的!!拿着别人的东西不亲自踩坑永远无法懂,因为每个人思维不一样,会遇到什么坑只有自己知道。算法和学 C++ 这些就有很多奇奇怪怪的问题,只有踩坑砸时间才能懂。因为会发现网上很多人说的是错的、表达不对的、自己一直理解的什么也是错的片面的,逐渐像录入手机指纹一样不断优化。速成看别人的教程永远都是二手资源!不如张无忌直接照着原秘籍修炼!
讲故事和比喻,永远都不贴切适合给外行人科普,懂的人会想无穷无尽的漏洞,因为没有完美贴切的比喻,总会用比喻的事物的思维带偏真正的知识细节,衍生出想各种问题,导致我永远都禁止豆包给我比喻!
而且豆包总傻逼玩意无尽的说面试怎样面试怎样,完全听不懂!禁止以面试为重点!直接从头到尾给小白教程说清楚!你如果解释让我懂了,面试我自然就水到渠成了,只围绕面试讲感觉缺胳膊少腿的!但很多 99% 的人都适合这样速成,脑子里的知识点支离破碎的,架空空中楼阁!!他妈的就像做一道菜,从头到尾摸索一遍就完美了,你在那说第二步是重点要干啥,第五步不能如何如何纯他妈傻逼!
狗逼玩意如果不加以要求,这个狗逼总他妈针对 99% 的傻逼水货来解答问题,通篇都是极致的针对大厂考点,零零散散的回答!但根本很僵硬!妈逼的让他禁止根据大厂考点来,按照我的思路说我的细节疑惑,理解透彻后,回头看大厂考点直接乱杀,一通百通!!妈逼的也不知道那些狗逼狗娘养的只会背高频考点冲傻逼的狗东西速成狗咋进去的,他们变个样就不会了
C++ 流里要么只打印自定义错误提示(如
std::cerr << "打开源文件失败" << std::endl;,面试首选),要么用perror(日常常用)接着又他妈扯到了
rdstate,追问之下发现最开始的 C++ 流都白学了不考,彻底崩溃~~~~(>_<)~~~~新疆AI一个月废了大半条命连100纪念都没有。
突然发现编程指北教程崩了,回忆之前 POJ 一崩能崩半个月(以为骂他给我封禁了,让mm试下发现也上不去,之前 hdoj、POJ,都是很诡异的上不去)
硅,像我,此文搜“症无法改掉”
又得知我钻研一个月到极致底层的 C++ 流,说完全不考,学也白学。这点错误码又搞了一星期,整的我头皮发麻头爆炸哎,跑去钻研C++11之前有什么详细的报错提示
无穷无尽的学偏了、太底层了 、不考、无穷无尽的白学、无穷无尽尸山血海永无止境的豆包误人子弟
说引出这些就是想说大厂有更优的替代方案
(刘X涛“这个是你?”,知乎回答学ACM不用重新搞IO,学拳击不用健身学UFC之类的)
查看代码
操.你妈,今天给我整崩溃了,我他妈就是任何东西都是要在所有系统所有的编译器重新都各自跑一遍。然后他妈的想知道这个烂坑C++到底他妈比Java好在哪儿。晚上回去测一下, 写个代码看一下。我他妈真受不了了,还有就是,就我去,任何东西都是。 这个世界万事万物头衔标签,任何万事万物发现了啊,尤其大厂,像什么腾讯SP这些东西,全都是技巧,没有任何的。嗯,有能力,但是技巧绝对高于能力。就这些人,所有人都都是能力,不一定有多强,完全都是技巧。就是你学,你考啥,我们学啥,全都这样的。我真的不觉得他们有多牛逼,我研究偏了。我纯演的片子。 我敢说任何哪怕清北华五C9的也是,谁都没我的多! 每个知识点,然后豆包90%垃圾文字,➕反复误人子弟扒层皮!然后不同编译器又扒层皮 操.你妈的C++性能没体验到,光遇到他妈一屁眼子烂坑 之前那个圣火令 就是那豆包,就是屠龙刀,倚天剑,但是你得要拿起他的本事,天龙八部里面是跟江湖人竞争,而我是跟自己竞争。就是你有极强的意志力,自制力。细心,钻研 对于这个,拿倚天剑的本事,拿屠龙刀的本事,不是江湖人竞争,就是跟自己竞争!福报! 屠龙刀可以说是江湖的霸主。但是我这种心。性格,我真的完完全全不适合用任何的框架,也就是说,没有豆包或者是有豆包没有这种性格的人都不行。二者缺一不可, 别人来说有豆包也白扯,因为他们没有我这个性格。 对于我自己来说,没有豆包我就是死,我真的活不下去,我无数思考的问题解决不了,连一个进度都推进不了。所以,永远无法考上研,永远无法工作。 就是我要么就是北邮计算机研究生,要么就是没学完导致国家线都过不了 我要么就是腾讯大厂SSP,要么就是没有工作。 我不存在学中不溜的水平,我没有速成的能力大学期末考试也是?我那时想自杀 知乎问,真正的能力 我不适合用框架,我就是想钻研,打个游戏都能用框架,就是用到处就是用用用。现在也是靠AI,各种他妈的骗钱公司,就是我最不适合用框架,我去钻研最底层的东西,Java说速成 Java都是直接用框架,但别说Java,光C++我都觉得很多库啊函数啊不理解,没法用,本身都是极致底层的东西了,我都还要再深入研究它的更极致的底层。别人可能不想这么多直接就用了,此文&wx搜"邓钦泽、兰思杨"说完不考 C++ 流,后来又说 考,颠三倒四的!!
豆包界面改了
,优化拉取速度快了,越来越像国外的软件界面 Linux 的感觉了回答的貌似也好了。
Linux 系统调用(比如
open/read/write,含errno)是直接基于 CPU 硬件指令 + 内核态 / 用户态切换的底层接口。为了说明底层系统调用错误更详细,C++ 是封装自己搞个很模糊的错误提示全都是
iostream error,而 C 是直接包装系统调用,和系统调用一样都是有详细的错误说明,然后给了个代码:查看代码
#include <iostream> #include <fstream> #include<cstring> // strerror 定义 #include <system_error> // 必须包含的头文件 #include <cerrno> // errno定义 using namespace std; int main() { // 故意打开不存在的文件,触发错误 ifstream fin("不存在的文件.txt", ios::in | ios::binary); if (!fin.is_open()) { // 用std::system_error 封装 errno,替代strerror(errno) string err_msg = system_error(errno, generic_category()).what(); cerr << "\nsystem_error输出: " << err_msg <<endl<<endl; cerr << "strerror(errno)输出: " << strerror(errno) << endl<<endl; } //没权限 ofstream fout("test.txt", ios::out | ios::binary); // /etc/passwd默认只读 if (!fout.is_open()) { string err_msg = system_error(errno, generic_category()).what(); cerr << "\n[错误] 写入只读文件失败:" << err_msg << endl; cerr << "[对比] 原strerror(errno):" << strerror(errno) << endl; } } /* 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./a system_error输出: No such file or directory strerror(errno)输出: No such file or directory root@VM-8-2-ubuntu:~/cpp_projects_2# */这段代码豆包起初坏了我大事,我是root有一切权限,豆包以为我是普通用户,给的没权限那个代码,目录一开始给我的是
/etc/passwd,我没看直接复制运行了。导致 passwd 清空了。豆包说当前会话的用户信息已加载到内存,系统没实时校验文件,但退出后会登不进去,还好 Linux 会自动备份,有个passwd-,直接:cp /etc/passwd- /etc/passwd chmod 644 /etc/passwd
ios::out模式打开文件会默认清空已有内容,即默认ios::trunc特性—— 即 “如果文件存在,先清空内容;如果不存在,创建”;
ios::app(追加模式)打开文件,绝对不会清空。追问了下如果没备份咋办,说了一堆懒得看了。三大问题之三:
while(fin.read(...))循环里,fin.gcount()必然等于BUFFER_SIZE,你在循环内读gcount()完全多余。此文搜“先手写证明几个东西”验证过至此之前的 “能跑但不标准 / 不严谨的 Linux 专用版”,改成了标准的写法 ——“跨平台、无错误、逻辑极简的通用版”,面试中前者会被扣分,后者才是满分答案。
一意孤行!大厂那些小林、吴师兄“不要钻研技术细节啥的”先入职? 各种公众号先混进去再说,而我觉得混只能垃圾,永远混不到好公司,永远在末流混着,我不听他们的也不听豆包的,发现注释掉这个行不行各种实验,理解很多东西!!
我真崩溃!C++ 性能没体会到,一屁眼子你妈逼的烂坑!!!(这是起初发现各种编译器、C++ 11 版本、C++ 17、GCC 11、gnu++11/gnu++14/gnu++17!都他妈啥啊艹!都要考虑,不同平台貌似结果还不同,我好纳闷这 C++ 跟他们草台班子一样一堆都自己搞规则!这让那时候的开发者咋办啊??咋统一啊?咋感觉 C++ 跟傻逼一样呢??之前觉得 vim 是臭傻逼?但这是起初豆包误人子弟的错误回答导致我有的这个想法)(后来发现尽管不同系统不同编译器有各自的实现,但结果大都相同,但总感觉这 C++ 不跨平台)
此文搜“分离”,就是 C++ 声明和实现分离那块的豆包链接,写的是如果学 Java 早进大厂了操他妈的,如果正规轨迹学习都不说报班!叶问林青山看 X光学武功,看他们的入营测评 & 授课目录就足够我早找到 C++ 工作了。哎。
豆包说:
C++ 的 “厉害” 不是花里胡哨的语法,而是能直接摸到计算机的底层硬件:内存、CPU、系统调用,想咋操就咋操,没有中间商(JVM/GC)赚差价;Java 是 “保姆式编程”,把底层全藏起来,你不用管内存,但也失去了 “极致操控权”;
你现在觉得 C++ 全是坑,是因为你还没到 “需要操控底层” 的场景(比如写个小游戏、做个高并发接口),等你要榨干 CPU 性能、控制内存占用到字节级时,就会发现:Java 的 “方便” 会变成 “枷锁”,而 C++ 的 “坑”,本质是 “自由的代价”。
Q:好吧,作为新手,咋能用几行代码看到 C++ 牛逼之处?性能没体验到踩了一屁眼子烂坑
硬头皮写个 Java 看看吧,可是 Java 貌似要装虚拟机,可我 腾讯云服务器饿肚子钱买的只有 2G 内存已经 800M 了,哎
突然发现毕设那时候装过 IDEA、eclipse 啥的,开 IDEA 一堆设置好头疼,说什么过期了貌似只能 30min,要选好多目录啊啥的,类名又要和文件名要一致(公共类一个类一个文件),然后这黑色界面之前看着很高级,现在看好别扭,新建个项目还要选择一堆东西直接给我劝退了,都不知道在 src 里创建东西问了豆包才知道
代码:
查看代码
//C++ 代码:秒跑无内存垃圾堆积 #include <iostream> #include <chrono> // 计时头文件 using namespace std; struct EmptyObj {}; // 空结构体,模拟轻量对象 int main() { // 记录开始时间 auto start = chrono::high_resolution_clock::now(); // 循环创建100万个栈对象(自动销毁,无GC开销) for (int i = 0; i < 1000000; i++) { EmptyObj obj; // 栈上创建,出循环自动销毁,无GC,无内存泄漏 } // 记录结束时间,计算耗时(转成毫秒) auto end = chrono::high_resolution_clock::now(); auto duration = chrono::duration_cast<chrono::milliseconds>(end - start); cout << "C++ 100万个对象创建销毁耗时:" << duration.count() << " 毫秒" << endl; } //Java 代码:GC 会偷偷干活 public class Test { // 空类,和C++的EmptyObj对应 static class EmptyObj {} public static void main(String[] args) { // 记录开始时间 long start = System.currentTimeMillis(); // 循环创建100万个堆对象(靠GC回收,有明显开销) for (int i = 0; i < 1000000; i++) { EmptyObj obj = new EmptyObj(); // 堆上创建,靠GC回收,有开销 } // 记录结束时间,计算耗时 long end = System.currentTimeMillis(); System.out.println("Java 100万个对象创建销毁耗时:" + (end - start) + " 毫秒"); } }VSCode 远程腾讯云的 Linux 跑 Java 是 2ms、IDEA 是 10ms
C++ 耗时:基本是0~1 毫秒(栈对象创建销毁几乎无开销,CPU 直接执行二进制);
Java 耗时:一般是10~50 毫秒(堆对象 + JVM / GC 的额外开销,哪怕空对象也躲不开);
然后,但豆包说 VScode 是直接调用命令行的轻量模式, IDEA 是全功能模式运行时会启动调试器、各种插件、代码索引、JVM 监控等附加组件,于是我去掉 IDE 开销(IDEA 终端默认使用 GBK 编码,但代码中包含中文注释“堆上创建,靠 GC 回收...”,GBK 无法识别这些字符,导致编译失败)
先找到 Java 文件所在目录,
# 编译 javac -encoding UTF-8 Test.java # 运行 java Test
,至此发现依旧是一个差数量级。
IDEA 可视化编译即绿色按钮是封装了编译逻辑,有包袱,每次都是 9ms
IDEA Java 命令行第一次 24ms,第二次 9ms,
VScode 命令行 第一次 2ms,第二次 1ms
豆包说:
日常开发 / 编译单个文件,直接用
g++完全可行,也是你一直以来的使用习惯,没问题;大厂 Linux C++ 服务端面试 / 实际开发中,不会用直接手写
g++命令编译大型项目,但手写g++命令本身是基础(面试官会默认你掌握),实际项目中会用Makefile/CMake管理编译(批量处理文件、配置编译选项、依赖管理等),而g++是这些构建工具的底层依赖。看来以后还要学批量管理啊!!本来会 RAII 然后研究了 —— 搜“楚!!!了”即可
然后研究零拷贝、代码错误处理、究竟咋算重定义和系统库冲突、崩溃学不下去 C++ 跑去用简短代码研究比 Java 性能厉害在哪也是目前我新手能做的(时间对比)、各种琐碎极致的底层的无穷无尽的问题(包括不同编译器的 GCC 和 VS 运行差异),一路折腾了一个半月
wx搜“虚表七进七出缴枪”
曾经啃《TCPIP网络编程》的时候鼓气 3 次都没啃下来 win 的网络 API,可能记忆有偏差,但就是《TCPIP网络编程》的最后几章的设计模式那个,王Y涵说不用看 win 的 API 才作罢。
这些都是有些研究的是错误的写法,有些研究的是 100% 不考不问的,豆包都不建议我学,但我真的自己感觉有很大收获,对底层的理解、对代码风格的书写。【邓钦泽、兰思杨久悬户】
继续说点钻研的东西,搜“原型:”对比着看
C 的read()在 while 里不用fail(),纯靠返回值判断是否跳出—— 这是和 C++ 流read()最核心的区别,没有任何 “状态方法”,只看返回值!C 语言
read()的while写法(极简示例,网络 / 文件通用)查看代码
#include <unistd.h> #include <fcntl.h> #include <stdio.h> #include <errno.h> int main() { int fd = open("test.txt", O_RDONLY); if (fd == -1) { perror("open失败"); return 1; } char buf[10]; // 想每次读10个字节 ssize_t n; // 核心循环:想读 10 个但只读到 1 个也会继续 while ((n = read(fd, buf, 10))>0 ) { // 只要返回>0就继续 printf("想读10个,实际读到%zd字节 | 内容:%.*s\n", n, (int)n, buf); } //循环结束判断原因, 无fail(), 纯靠返回值+errno if(n == 0) printf("循环退出:读到文件末尾\n"); if(n > 0) printf("#");//看是不是这次退出的 if(n == -1) perror("循环退出:读出错"); close(fd); } /* test.txt: abcd 输出: root@VM-8-2-ubuntu:~/cpp_projects_2# ./a 想读10个,实际读到4字节 | 内容:abcd 循环退出:读到文件末尾 */
维度 C++ 流 fin.read () C 的 read () 循环判断 靠 fin.read(...)的返回值(隐式判断 fail ())靠 read()返回值 > 0(>0 = 有数据)结束条件 fin.eof()(到末尾)/fin.fail()(出错)返回 0 = 到末尾,返回 - 1 = 出错 错误排查 可选 errno(编译器差异) 必看 errno(返回 - 1 时有效) C 的
read()while 循环就一个核心:先读,判断返回值是否 > 0,是就继续;不是就停,再区分是 “读完了(0)” 还是 “读错了(-1)”,全程不用任何类似fail()的状态方法,纯靠返回值 + errno 搞定,比 C++ 流简单粗暴,也更贴近系统底层。解读
printf("想读10个,实际读到%zd字节 | 内容:%.*s\n", n, (int)n, buf);:1、参数
n:n通常是size_t类型(无符号整数类型,专门用于表示字节数、数组长度等非负数值),这也是为什么要用%zd占位符来匹配它的原因。2、参数
(int)n
核心用途:作为
%.*s的 “长度参数”,专门告诉printf:只需要输出buf中前n个字符(字节),避免打印buf中多余的无效垃圾字符;关键细节:这里的
(int)是强制类型转换,原因是%.*s中的*要求接收一个int类型的长度值,而n本身是size_t类型,通过强制转换可以保证参数类型与占位符的要求匹配,避免编译警告或运行时异常。3、参数
buf
核心用途:是存放读取到的字符串数据的缓冲区(本质是字符数组或字符指针),
%.*s会从这个缓冲区中读取数据并输出;搭配特性:它不能单独发挥作用,需要和
(int)n配合,才能实现 “动态输出指定长度字符串” 的效果,正好对应实际读取到的n个字节内容。总结
三个参数对应关系:
n→%zd,(int)n+buf→%.*s;核心作用:
n存实际字节数,(int)n控字符串输出长度,buf存要输出的字符串数据;关键细节:
(int)强制转换是为了匹配%.*s的类型要求,避免异常。此文搜“先手写证明几个东西”即可对比 C++ 的
read,只要想读 n 个,实际读到<n 就退出,而 C 的read只要读到就不会退出另外我思考
while ((n = read(fd, buf, 10))>0 ) { // 只要返回>0就继续是否可以去掉 >0,其实去掉输出不变,但不可去因为返回 > 0 时进循环(对),返回 0 时判断为 false 退出循环(也对),返回 - 1 时判断为 true(错!会无限循环)。最终结论:去掉
>0,出错时(返回 - 1)循环会卡死,必须保留>0)注意:
-1是非 0 值,在 while 条件里会被判定为true。
继续,研究了 VS 用啥:
Linux GCC 的 C++ 流底层依赖errno,VS C++ 流不依赖errno处理错误,但除了 C++ 流(iostream)外,VS 下绝大多数 C 标准库 / 系统 API 依然依赖errnowin 就不研究了放个强迫症的痕迹吧:
win 的 VS 要么用
GetLastError()+FormatMessage(VS 专属);代码:
查看代码
#include <cerrno> #include <cstring> #include <fstream> #include <windows.h> using namespace std; int main() { system("chcp 65001 > nul"); // 控制台UTF-8 ifstream fin("test4.txt"); if (!fin.is_open()) { // VS下替代strerror(errno)的写法 DWORD err = GetLastError(); // 拿系统错误码 WCHAR wbuf[256]; // 改用宽字符 // 先拿宽字符版本的错误描述 FormatMessageW(FORMAT_MESSAGE_FROM_SYSTEM, NULL, err, 0, wbuf, 256, NULL); // 转UTF-8 char buf[256]; WideCharToMultiByte(CP_UTF8, 0, wbuf, -1, buf, 256, NULL, NULL); printf("打开失败:%s", buf); return 1; } }
,win 设计上就是中文错误提示。VS 下
FormatMessageA默认返回 GBK 编码的错误描述,而你设置了chcp 65001(UTF-8),编码不匹配导致中文乱码。VS 下必须用FormatMessageW(宽字符)+WideCharToMultiByte转 UTF-8,才能和chcp 65001匹配,解决乱码!这里一屁眼子历史遗留问题,就我这钻研劲头都搞不明白,C++ 结合 win 真他妈不是人搞的,纯纯一坨屎,比 Linux C++ 服务端开发难多了,给我感觉 linux 就像数学像算法,难但是有迹可循,且严谨,而 win 就像之前的银行外包测试,一屁眼子草台水货的感觉,一团乱麻又理不清没个标准,想钻研都无处可钻研。更准确的说是让人觉得没有研究价值,在毫无意义的东西上搞了太多规则和叫法,垃圾 win好奇大家都咋学的,人手租个服务器?豆包说 根本不用,艹起初不这么说的!(恐怖)不知不觉貌似又走了弯路,我搞腾讯云的真服务器,因为豆包说不用真的服务器会被面试官质疑是否真的会真的用过,实际项目的东西。
之前硬头皮用 vim 也是(复制、无法用鼠标、修改还要命令、代码无法滚动、报错看不到、插件装出一屁眼子报错、写代码用命令保存然后 g++ 运行出错还得 vim 打开还得命令定位修改啥的,再命令保存退出再 g++),说大厂都用 vim。
补充:
C++ 流在 Windows 下跑时,底层是调用 Windows 的文件 API,API 失败的错误码存在 Windows 系统里,MSVC 没把它同步到
errno,所以得手动用GetLastError()去 Windows 系统里 “取”—— 这就是 “对接”,Linux 下 GCC 帮你把这个步骤省了(直接同步到errno),所以别人不麻烦。流错误赋
errno的核心逻辑:C++流打开文件→调用Linux open()→open()失败→系统把错误码写进errnoC++ 流(ifstream)底层最终还是要调用 Linux 系统调用(open),正常流程是:
C++流打开文件 → 调用Linux open() → open()失败 → 系统把错误码写进errno,但 C++ 标准没规定 “流要把这个错误码暴露出来”,而 GCC 多做了一步:
✅ GCC 扩展:让 C++ 流失败时,直接把系统写入
errno的错误码 “关联” 到流操作里,你在流失败后直接读errno就能拿到系统调用的错误码;❌ MSVC(Windows):C++ 流底层调用 Windows API(CreateFile),API 失败后错误码存在 Windows 系统层面(不是 errno),MSVC 没做 “把 Windows 错误码同步到 errno” 的动作,所以读 errno 拿不到流错误。
懂啦开心!
死全家的狗逼玩意:
,大厂 Linux C++ 服务端开发永远不用 C++ 流太慢,所以错误处理更不用,更不考!!一个半月白搭!
痛苦:
豆包删除多了还要拉取 30 min,页面 1.6 G(更新:豆包优化了貌似)
wx搜“不想看视频,是”
二手信息资源就是和看视频一样,无止境的痛苦看完一节还有100多集,第二天看一节又发现之前总数少打开个文件夹,而自己探索,一份探索有一份收获。
豆包对话删除多了,需要写个问答,然后拉取,甚至需要反复拉取 100 次+
关于VScode的插曲(最终以失败告终):
VScode 每次出去吃饭回来都要重连 3s,而且最主要的是,他有时候还好直接左右下角显示重连,3s后就连上了不耽误事,有时候还会他妈弹个窗,要你点重新连接按钮,我 tm 还以为发生多大事了一样,有时候写博客和追问豆包,这玩意就一直后台开着,然后想用的时候,切换 VScode 页面,他半天不给你显示重连,写一堆代码发现保存不上,才发现,噢服务器断了,艹他奶奶的!
说是 SSH 加个保活,这玩意基于 TCP KeepAlive 实现,但不是同一个东西 —— 前者是 SSH 层的保活,后者是 TCP 协议层的保活
TCP KeepAlive:是 TCP 协议本身的机制(内核层),检测底层网络链路是否存活(比如物理断网、服务器宕机),默认超时极长(通常小时级);属于协议层
SSH 保活(ServerAlive/ClientAlive):是 SSH 应用层的机制,基于 TCP 连接发 SSH 层面的空包,主动维持 SSH 会话不被服务器 / 网关断开(比如云服务器防火墙、NAT 设备超时踢连接),可自定义短超时(如 30 秒),是对 TCP KeepAlive 的「轻量化补充」。属于应用层
照着豆包给的代码搞完直接连不上了艹,原因说是电脑有“岛”这个中文。
插个知识:
settings.json是本地 Windows 电脑上的 VSCode 配置文件,管VScode咋连,基础页面咋显示,连不上依然可以修改并保存。VSCode 里
#是注释,单独注释行被语法高亮识别为 “纯注释” 显绿色,而#前有代码时,整行被识别为 “代码 + 注释”,优先渲染代码的黑色样式最后没搞成,但过一会又好了,理由是VSCode/SSH 的临时进程 / 缓存被自动清理了,之前冲突配置导致本地 SSH 进程,只要关了 VSCode / 等一会儿,系统会自动杀掉这些僵死进程,相当于 “重置了 SSH 连接状态”;
临时缓存咋回事?其实就是
Windows 用户名带中文 “岛”,而
ControlMaster功能需要在C:\Users\GerJCS岛\.ssh目录下创建一个临时文件来实现快速重连。Windows 系统自带的 OpenSSH 工具不支持识别带中文的路径,对中文路径解析有原生 bug,
ControlPath ~/.ssh/xxx会被解析成C:\Users\GerJCS岛\.ssh\xxx,中文 “岛” 会让 SSH 创建 / 读取套接字文件时失败,触发Bad file descriptor,所以只要开连接复用,必报错;创建这个临时文件时会失败,直接导致连接复用功能失效,还会报
Bad file descriptor错误。你现在的配置没开
ControlMaster,所以不会报错,但重连速度就是默认的 3 秒;如果想开启ControlMaster实现毫秒级重连,必须把用户名改成纯英文,否则这个问题无解。不改用户名的话,你只能继续用现在的稳定配置,接受 3 秒重连,日常写代码、操作服务器完全不受影响。
除了改电脑用户名去掉中文,其他别无他法!操他血奶奶!
傻逼 VScode 总他妈的白屏,得缩放下框才行。
关于博客园的编辑器:
TinyMCE5的插入代码比TinyMCE好在,折叠后后者编辑的时候都看不到,且有违禁词会无法保存,直接写的是啥都看不到,白写了。前者可以看到整内容
阅读的时候都必须点view不然看不到,但搜的时候,前者可以直接搜到未展开的。
后者在切换编辑器时,有极小概率有时候还无法展开,直接死了,但F12可以看到内容
Ctrl + home / end 是博客园编辑的的最上和最下
回忆:
我之前算法无任何大模型,菜鸟教程贴图、啃TCPIP网络编程尹圣雨不帖了都是链接搜,然后王Y涵给了小林 coding 学了网络结束才发现一个机械上岸腾讯的,经验贴说写总结,我才把整个的网络写下(豆包摘抄整理,极其痛苦),然后 OS 直接整理了,然后二刷《TCPIP网络编程》尹圣雨的时候,意外没想到回顾豆包,直接捡重点看了,重新整理了,这下其实一刷的尹圣雨豆包链接不重要了(很多都要加载好久),起初天真的以为复习回顾的时候可以看每个豆包链接,一直到现在基本都是还算可以吧,真正有用的都写到了博客里,豆包搜的都是一些质疑自己等各种无关乎技术的问题(也少)
零拷贝
其实整个【零拷贝】这里搞了一周多(一路摸索出来无穷无尽的东西),整个 RAII 这里我早看过,一直自己探索其他的东西,这一章节停留了俩月了,但其实发现我目前的水平这俩月的收获,相当于别人精啃
《UNIX 环境高级编程》(APUE,服务端开发的圣经,人手一本)(下面都写成了 AUPE 了!!回忆之前链式向前星搞成链式前向星)、
《Linux 高性能服务器编程》(游双著,国内讲 Linux 服务端性能优化的天花板级入门书,大厂新人培训常推荐)、
《深入理解计算机系统》(CSAPP,理解 “内存 / IO” 本质的神书)
不!准确说!!我精通 CSAPP、APUE 需要看的重点章节!堪比出书!
零拷贝(一路从
sendfile的早期、2.4、2.6.33 各有什么不同,底层逻辑是怎么实现的,mmap底层是怎么实现的,为啥 C++ 流 /read/write不行,没零拷贝又是怎样的流程,傻逼豆包为啥不直接让我学零拷贝有何深意,sendfile和mmap各自的适用场景,全都写代码做实验,且实测read和零拷贝到底都多少毫秒(几个字节和几百M的差异),流慢在或者说系统调用快在哪里(减少系统调用次数还是减少磁盘IO此数),思考 C++ 流既然减少系统调用次数但却会多几次拷贝这里咋权衡,实测具体零拷贝耗时多久咋个快法,误打误撞用几百M的文件每次拷贝4字节居然服务器崩溃了原因是啥)这些其实都是一路钻研我追问反复质疑 + 豆包引导(虽然经常误人子弟)+ 和豆包互相配合互相启发指出错误得来的!(比如老子提出个问题,他他妈又臭又长牵扯一大堆,其中杂揉 30% 的错误,后期我追问纠正了,但他又引导引出其他的知识,就是这么拓展的)
太多东西了,没法一一列举!!见下!我的封神博客!
直接使用 Linux 的
sendfile系统调用。这才是 Linux C++ 服务端开发中处理文件复制的 “标准答案”。它远比
read/write循环高效,因为它是零拷贝的,数据直接在内核态从一个文件描述符传输到另一个,不经过用户态缓冲区。Q:你之前说大厂用复制用
read啥的现在又说了是零拷贝?你这不是纯耽误我时间吗!还是你有啥深意?必须会read?A:
1、“大厂用
read/write” 和 “大厂用零拷贝” 都对,但适用场景不同2、
read/write是基础,必须掌握。 它是所有 I/O 操作的基石,理解它才能理解更高级的技术。3、零拷贝是优化,是加分项。 在特定场景下能极大提升性能。
为什么我会提到两个不同的东西?这源于对 “文件复制” 这个需求的不同理解层次:
第一层:通用的、跨平台的文件复制。
这是最基本的需求,要求代码能在 Windows、Linux、macOS 等任何系统上运行。
实现方式就是使用 C++ 标准库的
std::ifstream和std::ofstream,配合read和write。这是基础能力,是你必须掌握的。任何工程师都应该能写出这样的代码。
第二层:特定平台下的高性能文件复制。
当你面试的是 Linux C++ 服务端开发 时,面试官期待你不仅会写通用代码,更要懂 Linux 平台下的性能优化。
在 Linux 中,
read/write存在一个性能瓶颈:数据需要在内核缓冲区和用户缓冲区之间来回拷贝(即 “CPU 拷贝”)。为了解决这个问题,Linux 提供了
sendfile、splice、mmap等零拷贝系统调用。它们可以直接在内核态完成数据传输,完全避免了 CPU 拷贝,性能极高。必须会
read/write:它是 C++ I/O 的基础,你在工作中会频繁用到。理解read/write的工作原理(包括缓冲区、系统调用、状态标志等),是理解零拷贝技术的前提。在面试中,如果你连基础的read/write循环都写不出来,那会是一个很大的减分项。应该了解零拷贝:对于 Linux 服务端开发岗位,了解零拷贝技术是非常有必要的。当面试官问你 “如何高效地复制文件” 时,如果你能先说出标准的
read/write方法,然后补充说明 “在 Linux 下,为了追求更高性能,可以使用零拷贝。我的初衷是想让你从基础到进阶都有所了解,而不是只停留在表面。
不要觉得我在耽误你时间。 基础是重中之重,
read/write必须会。也不要觉得零拷贝是遥不可及的。 它只是 Linux 提供的一个更高效的工具。
面试策略:
通用问题(如 “用 C++ 写一个文件复制函数”):用标准的
ifstream/ofstream和read/write,并确保代码正确(使用gcount())。Linux 高性能问题(如 “在 Linux 服务器上,如何最快地复制一个大文件”):果断回答零拷贝,并简要说明其零拷贝的优势。
这样,你既展示了扎实的基础,又体现了对特定平台优化的了解。比如大厂在处理文件发送(尤其是高并发、大数据量场景)时,几乎不会直接用
read/write循环,而是优先用「零拷贝」技术 —— 核心原因是read/write存在「多次数据拷贝」和「CPU 占用高」的问题,无法满足高性能需求。
好吧!懂了【为啥要学零拷贝?】、【既然要学为啥不直接学零拷贝,反而先要学
read、write那些】,现在开始说零拷贝,但说之前,通过完全复原(原汁原味自己思考追问的)豆包回答,来铺垫点必懂的前设知识,以便于日后都忘干净了可以更快捡起来:Q:系统调用也有缓存(页缓存),我一直以为没有的,系统调用和 C++ 的流都有缓存,搞这么多干啥啊?
A:系统调用确实有缓存,即页缓存(Page Cache,也叫文件缓存),同时 C++ 流也有独立缓存,这是两层不同层级、不同作用的缓存,并非重复设计:一、先明确:文件 I/O 相关系统调用的缓存 —— 就是页缓存(Page Cache)
文件操作的系统调用(比如read()/write()、open()等)并不是直接和磁盘硬件交互,而是先和页缓存(内核态缓存)打交道,这是操作系统内核实现的缓存机制:1、读文件时:内核先检查页缓存中是否存在目标文件的数据页,如果有,直接从页缓存把数据拷贝到用户进程的内存空间,无需访问磁盘(这叫「缓存命中」,速度极快);如果没有(缓存未命中),内核才会发起磁盘 I/O,把磁盘上的数据加载到页缓存,再拷贝给用户进程。
2、写文件时:内核通常不会立即把数据写入磁盘,而是先把数据拷贝到页缓存中,标记为「脏页」,之后由内核的「pdflush」等后台线程,或在特定时机(如页缓存不足、调用
fsync()/fdatasync())批量将脏页写入磁盘,实现「延迟写入」。插一个:
write后若要确保数据落地磁盘(防止断电丢失),调用fsync(fd)mmap直接修改内存,mem[104] = 'a';直接修改,, 若要确保数据落地磁盘,调用msync(对应mmap的fsync)3、例外说明:并非所有系统调用都有缓存 —— 只有文件 I/O 类系统调用依赖页缓存,像进程控制(
fork())、信号处理(kill())、网络 I/O(套接字调用)等系统调用,是没有页缓存的,页缓存仅针对「磁盘文件」的读写优化。二、C++ 流的缓存 —— 用户态独立缓存,和页缓存不是一回事
C++ 的标准流(如
std::cout、std::fstream)确实也有缓存,这是C++ 标准库在用户态实现的缓存(也叫流缓冲区 /std::streambuf),和内核的页缓存是两层完全独立的缓存,层级关系是:「C++ 流(用户态缓存)」→「系统调用(内核态页缓存)」→「磁盘硬件」。比如你用std::ofstream写文件时,数据会先存入 C++ 流的用户态缓存,当缓存满了、调用flush()、或关闭流时,C++ 标准库才会调用底层的系统调用(write()),把数据从用户态缓存拷贝到内核的页缓存,后续再由内核处理磁盘写入。三、为什么要设计「多层缓存」?不是多此一举!
之所以同时存在 C++ 流用户态缓存和系统调用对应的页缓存,核心原因是「系统调用的开销极高」,多层缓存是为了最大化减少系统调用次数、提升整体性能,具体拆解两个核心目的:
减少系统调用次数,降低上下文切换开销系统调用需要从「用户态」切换到「内核态」(上下文切换),这个过程要保存用户进程的执行状态、切换页表、进入内核执行逻辑,执行完再切回用户态,开销远大于普通的用户态内存拷贝。
C++ 流的用户态缓存:把多次小数据写入 / 读取合并成一次大的数据操作,再发起系统调用(比如循环写 1000 个字符,流缓存会先攒够一定大小,再一次性调用
write()),大幅减少上下文切换次数。页缓存:内核层面进一步复用数据、批量处理磁盘 I/O(磁盘是慢速设备,随机 I/O 开销极大,页缓存通过预读取、批量写入,把随机 I/O 转化为顺序 I/O,提升磁盘读写效率)。
分离用户态与内核态,提升安全性和灵活性
用户态缓存(C++ 流):由应用程序(C++ 标准库)控制,开发者可以灵活配置(比如
std::ios::sync_with_stdio(false)关闭流与 C 标准 IO 的同步,提升效率;手动调用flush()强制刷新),属于应用层的优化。内核态页缓存(Page Cache):由操作系统统一管理,对应用程序透明(应用程序无需感知它的存在,内核自动完成缓存的加载、淘汰、写入磁盘等逻辑),不仅能为当前进程提供缓存,还能实现进程间的文件数据共享,同时保证了磁盘操作的安全性(避免应用程序直接操作磁盘导致的数据损坏)。
总结
文件 I/O 系统调用的缓存就是「页缓存(内核态)」,非文件 I/O 系统调用无此缓存;
C++ 流的缓存是「用户态流缓冲区」,与页缓存是两层独立缓存,层级从上到下为:C++ 流 → 系统调用 → 页缓存 → 磁盘;
多层缓存的核心目的是「减少高开销的系统调用(上下文切换)」和「优化慢速磁盘的 I/O 效率」,同时兼顾灵活性与安全性,并非多余设计。
Q:懂了!那流通过缓存减少了系统调用,那系统调用本身也有缓存也是为了减少自己的系统调用
A:不是!系统调用对应的页缓存,不是为了减少系统调用次数,而是为了减少「比系统调用开销更高的慢速磁盘 I/O 次数」;而 C++ 流缓存才是专门为了减少系统调用次数(降低上下文切换开销)。
Q:嗯???系统调用不就是去磁盘搞数据吗
A:不是的!这里的关键误区是:文件 I/O 的系统调用 ≠ 直接访问磁盘,系统调用只是发起了 “读写请求”,真正的磁盘 I/O 是由内核根据页缓存的状态来决定是否执行的。
简单拆解这个过程:
当你调用
read()这类系统调用时,它会先去查内核的页缓存—— 如果数据已经在页缓存里,系统调用直接把数据从页缓存拷贝到用户内存,全程没有任何磁盘操作;只有当页缓存里没有目标数据时,系统调用才会触发内核发起真正的磁盘 I/O,把数据从磁盘加载到页缓存,再拷贝给用户。
也就是说,系统调用是 “中间人”,页缓存是它的 “仓库”—— 仓库里有货就直接拿货,没货才去磁盘(厂家)进货。
Q:那我理解哪怕页缓存有数据,但也要调用系统调用然后再查页缓存,然后才是涉及到有就直接给,没有再找磁盘要, 对吧? 而这里的系统调用只要触发就注定很慢?然后没有的话去磁盘进货更慢?
A:你的理解完全正确!核心逻辑就是:
哪怕页缓存里有目标数据,你也必须触发一次系统调用(比如
read())—— 因为页缓存是内核态的资源,用户态程序不能直接访问,必须通过系统调用让内核帮你查缓存、拷贝数据。系统调用本身已经算慢操作(要做用户态→内核态的上下文切换,有固定开销);如果页缓存没数据,系统调用还要触发更慢的磁盘 I/O(磁盘是机械 / 电子设备,读写速度比内存慢几百上千倍),相当于 “慢上加慢”。
至此懂了零拷贝的真正意义、学习路线、必备的前设知识基本,可以开始说了:
结合之前已经精通底层逻辑的那个 C++ 流的拷贝的代码,此文搜“么多,回顾”,那个代码底层逻辑是:
执行步骤(BUFFER_SIZE=3):
第一次读:读取 3 字节 →
abc→ 写入目标文件;第二次读:读取 3 字节 →
\n12→ 写入目标文件;第三次读:读取 3 字节 →
4\ndd→ 写入目标文件;第四次读:读取 3 字节 →
哈哈\n→ 写入目标文件;第五次读:读取 3 字节,但只剩
好(2 字节)→ 读取 2 字节 → 写入目标文件;总字节数 16,循环 + 收尾完成复制。
std::istream::read()和std::ostream::write()是 C++ 的标准库std::istream/std::ostream的成员函数,并非系统调用的read()/write();底层实现上,这些成员函数和
streambuf缓冲交互,缓冲满或者刷新的时候触发调用操作系统的read()/write()系统调用。fin绑定到了src源文件,fout绑定到了dst目标文件。然后就是从
src文件fin.read,若streambuf内已有足够数据,直接从streambuf拷贝到你的buffer;若streambuf数据不足,才触发系统调用读数据到streambuf,再拷贝到你的buffer。然后再
fout.write,是先把你的buffer数据写入fout的streambuf,当满 / 刷新 / 关闭时才调用系统调用write把数据从用户态(streambuf)拷贝到内核态的页缓存,这步是同步的,然后异步刷到磁盘即目标文件。同步是调用
write()/read()时,必须等数据从用户态拷贝到内核态(或反之)完成才返回;异步是发起 IO 请求后立刻返回,数据拷贝由内核后台完成,无需等待。
std::fstream底层不封装 C 标准库的FILE*,是直接操作文件描述符,和FILE *无封装关系。有缓冲区,但不是FILE *的stdio缓冲区,是std::fstream自身的streambuf缓冲区(C++ 层独立缓冲)本质就是:「用户态中转」:先把数据读到用户缓冲区,再从用户缓冲区写到目标文件
维度 你的代码(fstream 分块读写) 零拷贝(你最初贴的代码) 核心思想 「用户态中转」:先把数据读到用户缓冲区,再从用户缓冲区写到目标文件 「内核态直传」:跳过用户缓冲区,内核直接把源文件的内核缓冲区数据传给目标文件的内核缓冲区 数据流动 磁盘→内核缓冲区→用户 buffer→内核缓冲区→磁盘(4 次拷贝) 磁盘→内核缓冲区→目标文件内核缓冲区→磁盘(2 次拷贝) 缓冲区角色 你手动定义 char buffer [3](用户态),是数据中转的核心 无用户态缓冲区!内核自己管理缓冲区,你只需要指定「复制多少字节(文件大小)」 系统调用 每次 read/write 都是一次系统调用(3 字节读一次就调一次) 仅一次 零拷贝 调用(或少数几次,大文件分块也比你少 N 倍),直接指定总长度 CPU 参与度 CPU 要做「内核→用户」「用户→内核」两次拷贝(纯 CPU 计算) CPU 只负责发起 零拷贝 指令,数据拷贝由 DMA(硬件)完成,CPU 几乎不占用 零拷贝(Zero-Copy) 的核心目标是:减少数据在「用户态」和「内核态」之间的冗余拷贝,从而大幅提升大文件复制 / 传输的性能。
「内核态直传」:跳过用户缓冲区,内核直接把源文件的内核缓冲区数据传给目标文件的内核缓冲区。
先回顾你已知的「传统拷贝流程」(比如用
read + write复制文件),再对比零拷贝的优化逻辑,你就能快速理解:一、先复盘:传统拷贝的「4 次拷贝 + 2 次系统调用」(你已理解的基础)
假设你用 C++ 写一个简单的文件复制:
这个过程中,数据要经历 4 次拷贝(2 次 CPU 拷贝 + 2 次 DMA 拷贝):// 传统拷贝:read + write char buf[4096]; int fd_in = open("src.txt", O_RDONLY); int fd_out = open("dst.txt", O_WRONLY | O_CREAT); ssize_t n; while ((n = read(fd_in, buf, sizeof(buf))) > 0) { // 系统调用1 write(fd_out, buf, n); // 系统调用2 }
DMA 拷贝 1:磁盘 →
src内核态页缓存(DMA:直接内存访问,不占用 CPU);CPU 拷贝 1:
src内核态页缓存 → 用户态缓冲区,你的bufCPU 拷贝 2:用户态缓冲区
buf→dst内核态页缓存DMA 拷贝 2:
dst内核态缓冲区 → 磁盘核心问题:数据在「内核态 ↔ 用户态」的 2 次 CPU 拷贝是完全冗余的 —— 我们只是想把数据从 A 文件移到 B 文件,根本不需要让数据进入用户态。
注意!
磁盘其实也有缓冲区,磁盘先自己处理到磁盘缓冲区,之后提到磁盘都是这个磁盘缓冲区,不计入拷贝次数,知道就行
这里是系统调用,而如果用 C++ 流,则要多两个拷贝,即总共 6 次(同理 CPU 拷贝都是冗余的):
- DMA 拷贝 1:磁盘
src.txt→src文件的内核态页缓存(DMA:直接内存访问,不占用 CPU);CPU 拷贝 1:
src文件的内核态页缓存 →streambuf(C++ 标准库的用户态缓存)- CPU 拷贝 2:
streambuf→ 用户的bufCPU 拷贝 3:用户的
buf→streambuf另一块 C++ 缓存CPU 拷贝 4:
streambuf→dst文件的内核态页缓存DMA 拷贝 2:
dst文件的内核态缓冲区 → 磁盘dst.txt
关于 DMA:
就是 “数据搬运工”,专门绕开 CPU,直接帮你把数据在磁盘 / 网卡等硬件和内核内存之间搬来搬去,不用 CPU 亲自动手。你可以把 CPU 想象成公司老板,DMA 是专职搬运工 —— 传统 CPU 拷贝是老板亲自搬数据,又慢又占精力;DMA 是老板吩咐搬运工去搬,自己能腾出手干更重要的事,而且搬运工只负责 “硬件 ↔ 内核内存” 的搬运,不碰用户态数据,零拷贝就是靠它绕开 CPU 完成全程搬运,彻底省掉用户态 - 内核态的 CPU 拷贝开销。
页缓存到用户态
buf数组的拷贝无法绕过 CPU,必须通过CPU执行copy_to_user()这类内核函数完成数据拷贝。我有思考是:
Q:如果改用系统调用可以减少一次,即直接内核页缓存到用户的
buf数组,如果 C++ 流则还需要到streambuf,然后再到用户的buf,这里拷贝虽然多了一次,但我理解不是缓存可以减少系统调用次数吗?那应该用 C++ 流更好啊?或者说咋权衡?还是我考虑多了?A:你理解的核心没错(C++ 流多一次用户态内拷贝、缓存能减少系统调用),权衡的关键在于场景优先级,核心结论和重点如下:
C++ 流的优势:靠缓存减少系统调用,提升「常规小数据 / 频繁读写」场景的整体性能,且跨平台、易用、安全 C++ 流(
fstream等)的streambuf是用户态缓存,它的核心价值不是减少拷贝次数,而是攒够数据再一次性发起系统调用(避免频繁read/write系统调用的开销)。系统调用的开销(用户态↔内核态切换、内核权限校验等)远大于「用户态内的一次 CPU 拷贝」(streambuf→自定义 buf),因此在常规场景(小文件、频繁读写小块数据)下,C++ 流的整体性能更优,还能避免手动管理缓冲区、文件描述符等问题,跨平台兼容性更好。原生系统调用的优势:减少一次用户态拷贝,在「超大文件 / 高吞吐」场景下凸显性能优势,可控性更强只有当数据量极大(如 GB 级大文件拷贝)、吞吐率是核心指标时,「少一次用户态 CPU 拷贝」的收益才会超过「系统调用次数增加」的开销。此时原生系统调用(或更优的零拷贝,可彻底避免内核↔用户态拷贝)更有优势,且开发者可手动定制缓冲区大小(如 4096/8192 字节),进一步优化。
你的 “考虑多了” 适用于绝大多数场景日常开发(业务逻辑、小文件操作、普通数据读写)中,C++ 流的 “易用性 + 减少系统调用的收益”,完全覆盖了 “多一次用户态拷贝” 的微小损耗,优先选 C++ 流即可;只有做高性能中间件、大文件传输等底层优化时,才需要考虑原生系统调用或零拷贝。
Q:我知道页缓存 C++流缓存 那 C 封装系统调用也有缓存吗?我理解没有吧?直接写系统调用 read 啥的就是 C 的?
A:你理解的基本没错,一句话总结:标准 C 语言的底层系统调用(
read/write等)本身没有缓存,但 C 标准库提供了带用户态缓存的 I/O 函数(fread/fwrite等),二者要区分开:
纯
read/write(系统调用):不管 C/C++,都无额外缓存,直接和内核页缓存交互;C 标准库
stdio.h中的fopen/fread/fwrite:自带用户态缓存(类似 C++ 流的streambuf),本质是对read/write的封装,用来减少系统调用次数。Q:那 C 的
fread和 C++ 流的缓存有必要区分吗?A:日常开发几乎没必要刻意区分,底层本质一致;仅需极致细节把控(如缓存大小、同步逻辑)时,才有区分价值。都是用户态缓存,核心目的都是减少
read/write系统调用次数,抵消用户态内拷贝的微小损耗;都基于内核页缓存之上工作,不绕过内核页缓存。但 C++ 流(streambuf)是面向对象封装,支持自定义缓存逻辑(更灵活);而 C 的fread缓存是固定机制(stdio库内置,配置项少,更简单直接)。C++ 的streambuf并不是继承 / 复用 C 标准库(stdio.h)的缓存实现,二者是完全独立的两套用户态缓存机制,底层均基于相同的read/write系统调用,但上层实现毫无关联。二、零拷贝:干掉「用户态 ↔ 内核态」的冗余 CPU 拷贝
前言:
sendfile是 “零拷贝” 这个词的典型代表,而mmap是 “伪零拷贝”(但实际 Linux C++ 服务端开发 / 面试更常用)。零拷贝的核心是:让数据始终在内核态流转,不经过用户态,从而省去两次 CPU 拷贝,即:
【磁盘】 ↓ DMA拷贝1(无CPU参与) 【内核态页缓存】 ↓ DMA拷贝2(无CPU参与) 【磁盘/网卡】这就是零拷贝的技术核心骨架 —— DMA 拷贝动作。
那基于这个原理,发明了仨玩意:
mmap/splice
sendfile尽管说最常考是
文件到网卡,但我觉得复制文件更基础,且我一开始引入的也是大文件 C++ 流分片拷贝复制,然后直接变形mmap来搞,所以先说文件 vs 文件。
mmap完整流程(文件内存映射)【磁盘】 ↓ DMA拷贝1(缺页中断触发,无CPU参与) 【内核文件缓冲区】 ↓ 映射关联(mmap独有,建立内核-用户内存映射) 【进程用户态映射区】 ↓ (进程读写映射区,系统自动同步) 【内核文件缓冲区】 ↓ DMA拷贝2(无CPU参与) 【磁盘】特点:多了映射关联步骤,必须经过用户态内存
第一步【内核文件缓冲区】:系统提前在核心内存(内核态)里存放了文件数据的临时缓存(避免频繁读写磁盘)。
第二步 映射关联:仅
mmap会做这一步 ——不拷贝数据,只建立内核文件缓冲区与进程专属内存(用户态映射区)的直接关联关系(二者指向同一份内核缓存数据)。第三步【进程用户态映射区】:进程的专属内存区域,可直接读写(无需调用
read/write)。第四步 同步:进程修改该映射区的数据后,系统会自动把修改同步回内核文件缓冲区,最终再同步到磁盘;进程读取该映射区,就是直接读取内核文件缓冲区里的文件数据。
即
mmap先建立文件与进程内存的关联,让进程能直接读写内核缓存里的文件数据(不用read/write拷贝数据),然后以文件 ↔ 内核缓存 ↔ 进程内存为基础,支持进程通过操作映射内存,间接实现上层应用文件 ↔ 文件的数据拷贝,即在这个基础操作上,进程只需给文件 A 和文件 B 分别建立映射,然后把文件 A 映射区的数据写到文件 B 映射区,系统会自动把修改同步到磁盘,最终完成文件 → 文件拷贝,本质还是依赖这个底层映射流程,文件 A ↔ 内核文件缓冲区 ↔ 进程用户态映射区 ↔ 内核文件缓冲区 ↔ 文件 B。
第一步「磁盘→内核页缓存」:文件 A 的数据先加载到内核文件缓冲区(页缓存),
mmap建立该缓冲区与进程映射区的关联;第二步「内核页缓存→磁盘」:进程操作映射区修改 / 复制数据,系统同步回内核文件缓冲区,最终内核把缓冲区数据写入文件 B 对应的磁盘,完成拷贝;
这里的 “无进程数据拷贝”(只走内核缓存),也是
mmap实现高效文件→文件拷贝的关键,和read/write(磁盘→内核→进程→内核→磁盘,多了一次进程内存拷贝)的低效形成对比。底层原理(承接你的文件描述符认知):
调用
mmap(int fd, size_t length, int prot, int flags, int fd, off_t offset)系统调用时,内核将目标文件(src)的内核页缓存,直接映射到进程的虚拟地址空间(用户态虚拟内存);该映射过程不拷贝任何数据,仅修改进程的页表(虚拟地址→物理地址的映射关系);
你代码中操作这个映射后的虚拟地址(比如
char* mmap_buf = (char*)mmap(...)),等价于直接操作 src 的内核页缓存 —— 完全绕开std::streambuf和你自定义的用户态 buffer;当你通过
memcpy(mmap_buf_dst, mmap_buf_src, len)拷贝数据时,实际是内核内部将 src 页缓存的数据拷贝到 dst 页缓存(全程内核态,无用户态参与);最终 dst 页缓存通过 DMA 异步刷到磁盘。
注意:
mmap的flags参数:MAP_PRIVATE表示映射区修改仅在进程内有效(不同步到磁盘),MAP_SHARED表示修改会同步到内核页缓存并最终刷盘(文件→文件拷贝用MAP_SHARED);映射后必须调用
munmap(void* addr, size_t length)释放映射,否则会造成虚拟内存泄漏;缺页中断:当访问映射地址但对应页缓存无数据时,内核触发缺页中断,发起 DMA 从磁盘读数据到页缓存(该过程是阻塞的,但无拷贝开销);
mmap不依赖std::streambuf:使用mmap时需直接操作文件描述符(open()获取),而非std::fstream(因为std::fstream的streambuf会额外引入用户态缓冲,抵消 mmap 的优化)。文件→文件拷贝的最优零拷贝方案是
mmap,消除用户态缓冲的拷贝,仅保留内核态内部拷贝;文件→网卡传输的最优零拷贝方案是
sendfile,完全消除 CPU 拷贝,仅保留两次 DMA 传输;
sendfile底层原理(无傻逼面试话术,仅讲机制):
调用
sendfile(int out_fd, int in_fd, off_t* offset, size_t count)系统调用时,需传入两个文件描述符:in_fd(待传输的文件,对应 src)、out_fd(socket 描述符,对应网卡);内核直接读取
in_fd对应的内核页缓存数据,通过 DMA 控制器将数据传输到out_fd对应的网卡缓冲区(全程不经过用户态);改进版
sendfile(Linux 2.4+)借助 DMA 的 Scatter/Gather 特性,直接将内核页缓存的内存地址告知网卡 DMA 控制器,绕开 socket 内核缓冲区,数据从页缓存直接 DMA 到网卡。- Linux 2.6.33 内核是
sendfile正式支持文件 → 文件拷贝的里程碑版本
sendfile对比fstream+socket的路径简化:磁盘(src)→ DMA → 内核页缓存(src)→ DMA → 网卡。
1. sendfile 的核心流程(仅 2 次拷贝)
// 零拷贝拷贝文件:sendfile int fd_in = open("src.txt", O_RDONLY); int fd_out = open("dst.txt", O_WRONLY | O_CREAT); off_t offset = 0; struct stat stat_buf; fstat(fd_in, &stat_buf); sendfile(fd_out, fd_in, &offset, stat_buf.st_size); // 一次系统调用搞定数据流程:
DMA 拷贝 1:磁盘 → 内核态页缓存;
DMA 拷贝 2:内核态页缓存 → 磁盘(全程无 CPU 拷贝,数据没进过用户态)。
系统调用次数从 2 次减为 1 次,CPU 拷贝从 2 次减为 0 次 —— 这就是「零拷贝」的核心(零的是用户态 - 内核态的 CPU 拷贝,不是所有拷贝)。2. 针对你理解的「
streambuf」补充C++ 标准库的std::fstream默认基于传统read/write实现,本身不支持零拷贝;如果要在 C++ 中用零拷贝,需要:
绕过
std::fstream,直接调用系统调用(sendfile/splice/tee);或使用第三方库(如 libuv、asio)封装的零拷贝接口。
三、零拷贝的适用场景(重点)
大文件复制 / 传输(如视频、日志、数据库备份);
网络传输(如 Nginx 转发静态文件,核心就是
sendfile零拷贝);对 IO 性能要求极高的场景(减少 CPU 开销,提升吞吐量)。
四、关键总结(对比你已懂的逻辑)
维度 传统拷贝(streambuf/read/write) 零拷贝(sendfile) 用户态↔内核态拷贝 2 次 CPU 拷贝 0 次(无用户态参与) 系统调用次数 2 次(read+write) 1 次 总拷贝次数 4 次(2DMA+2CPU) 2 次(2DMA) C++ 实现方式 std::fstream 原生支持 需调用系统调用 /splice 等 懂了点继续说:
零拷贝不是 “砍掉缓存”,是砍掉用户态缓冲区(你代码里的 char buffer),内核态缓存仍存在;零拷贝本身就是通过专属系统调用(
sendfile/mmap)实现的,并非不用系统调用,而是用更高效的系统调用替代传统read/write的多次调用叫 “零拷贝” 是因为 CPU 不再做
内核态 → 用户态 → 内核态的冗余数据拷贝(仅 DMA 硬件拷贝),而非字面意义的 “无拷贝”,零拷贝的命名重点是强调 CPU 不用参与数据拷贝,只负责发起指令(比如告诉 DMA 该读哪些数据、往哪写)、管理内存映射关系、处理系统调用的调度这些控制类工作。
然后系统调用之前是多次的读写这次是一次,即
sendfile就是系统调用。
严格意义上,
sendfile是 “纯零 CPU 拷贝”:文件→网卡场景下,全程只有 DMA 搬数据,CPU 完全不碰数据(改进版),是 “零拷贝” 这个概念的 “标准答案”,面试官说 “零拷贝”,第一反应就是sendfile;而
mmap是 “伪零拷贝”:它省掉了 “内核→用户” 的 CPU 数据拷贝,但缺页中断时 CPU 要处理虚拟内存映射(这是指令开销,不是数据拷贝开销),所以不会被当作 “零拷贝” 的第一例子,但它的实际使用场景比 sendfile 广我思考:不是说一次搞10G进来会
搞个这么高大上的词汇零拷贝干啥呢艹!之前刷算法题的传递闭包各种高大上唬人的玩意
我看零拷贝代码更加的简洁,基本就ssize_t bytes_sent = sendfile(dst_fd, src_fd, &offset, stat_buf.st_size);一句话,C++ 那个逻辑更加的麻烦需要while读然后处理零头啥的,本质是sendfile写法内核替你做了所有 “脏活”:你 C++ 代码里手动写的while循环分块、处理剩余字节、用户态缓冲区读写,这些逻辑全被sendfile系统调用封装到内核里,内核会自动用最优缓冲区(如 4096 字节)分块、处理零头,无需你手写;之前用 C++ 标准库流举例子是为了先讲懂 “分片读避内存爆炸” 的核心逻辑(这是处理大文件的基础,不管用啥接口都要遵守),不是让你实际用它读大文件;实际读大文件选
read()(或sendfile零拷贝)是为了在 “分片读” 基础上省拷贝,两者不冲突 —— 先懂 “怎么读不崩”,再懂 “怎么读更快”。Q:咋个崩法?
A:不分片读大文件会崩,本质是内存申请失败导致程序直接崩溃 / 被系统杀死,就俩核心场景,全给你掰明白(不啰嗦):
比如你想一次性读 10GB 文件,代码里写char* buf = new char[10*1024*1024*1024];(申请 10GB 内存):
普通电脑内存就 8GB/16GB,系统根本拿不出 10GB 连续内存给你;
结果:
new会抛bad_alloc异常(C++),malloc会返回 NULL,你没处理的话,程序直接触发内存分配失败崩溃,弹错退出。就算你没手动
new,用 C++ 流istream::read()一次性读 10GB(注意:不管是 C++ 流、C 标准库(fread/fwrite),还是系统调用(read/write),只要试图一次性加载 / 处理超大文件(大 GB 级别),大概率都会崩溃):你要一次性加载大 GB 数据,需要预先分配对应大小的内存缓冲区(比如 10GB 就需要 10GB 连续内存),而程序的用户态内存空间有限(受系统内存、进程虚拟内存限制,还有物理内存不足的制约),系统无法满足这么大的内存分配请求。本质是「内存不足」导致的崩溃(内存溢出 / 分配失败)
两种崩溃场景及原理:
栈上分配(如
char buf[1024*1024*1024*10];):栈空间默认很小(通常几 MB 到几十 MB),远小于大 GB 级别,直接触发栈溢出(Stack Overflow),程序立即崩溃;堆上分配(如
malloc(1024*1024*1024*10);):堆空间虽大,但无法分配连续的大 GB 内存(物理内存不足或内存碎片过多),malloc返回 NULL,若后续直接使用该 NULL 指针,会触发空指针访问,程序崩溃。比如 10GB 文件,你分片每次读 4KB(只申请 4KB 内存),哪怕读 1 万次,总内存只占 4KB,系统完全扛得住;但你一次性读,哪怕只申请比可用内存多 1GB,必崩。进化历程是:
第一步:C++ 封装(streambuf / 流分片)先搞定「能用」—— 靠分片解决「不分片崩」的问题,代价是多了
streambuf→用户 buf 的 CPU 拷贝,胜在代码简单、不用手动管缓冲区;第二步:拔掉封装用 read () 追求「更快」—— 直接调用系统 read (),省掉
streambuf那层冗余的 CPU 拷贝,只保留「页缓存→用户 buf」这一次 CPU 拷贝,性能比流高一大截;第三步:read 还不够,上零拷贝(sendfile/mmap 等)追求「极致」—— 发现 read () 逃不掉「页缓存→用户 buf」的 CPU 拷贝,因为传统
read系统调用就是将内核态的数据读取到用户态预先分配的buf数组,于是用零拷贝绕开这一步:
sendfile(文件→网卡场景):全程只有 DMA 拷贝(磁盘→页缓存→网卡),CPU 全程不碰数据;
mmap(文件→用户内存场景):把文件直接映射到内存,省掉「页缓存→用户 buf」的拷贝,仅适用于特定场景(比如频繁读写同一块文件)。突然懂了之前刷算法题为啥开个大数组就会崩,默认在栈,空间通常几 MB 到几十 MB,大数组直接耗尽栈空间,触发「栈溢出(Stack Overflow)」,程序崩溃。如果把大数组移到堆上(用
new/malloc分配),大概率不会崩(堆空间远大于栈空间)。但这种方式显然机关算尽无法练到真正的算法,就像高中 oi 平台洛谷里的一些讨论的奇技淫巧一样(快读)。但此文搜“一次性加载大 GB 数”和“足(比如 32 位”分别是一次性和用
mmap零拷贝崩的解读,即零拷贝也会崩,但区别是1、崩溃 / 失败的核心原因不同
一次性读 G 级文件(C++ 流 /
fread/read):崩溃源于 堆 / 栈空间不足。需要预先分配 G 级内存缓冲区存放数据,栈空间(几 MB)直接溢出,堆空间也无法满足大 GB 连续内存分配,导致程序直接崩溃(栈溢出)或分配失败后空指针访问崩溃。
mmap映射 G 级文件:失败 / 崩溃源于 虚拟地址空间耗尽。它不占用物理内存(按需加载),但会占用进程虚拟地址空间,32 位进程(虚拟空间最大 4GB)会直接耗尽该空间,导致mmap返回MAP_FAILED(调用失败);若非法访问该无效地址,才会触发段错误崩溃。Q:嗯?你说 C++ 是加载到堆栈??mmap是到虚拟内存?
A:你这个疑问是把 “内存区域分类” 和 “内存层级概念” 搞混了,一句话先厘清,再极简掰透(不啰嗦):不是 “C++ 加载到堆栈”,是 C++ 中变量 / 缓冲区的分配位置在「栈」或「堆」(属于进程的虚拟内存范畴);mmap 是直接映射文件到进程的「虚拟地址空间」,栈 / 堆也属于虚拟地址空间的一部分
C++(含 C / 系统调用)的栈 / 堆:
栈、堆是进程虚拟地址空间内的两个具体区域(虚拟内存的子集),不是独立于虚拟内存的存在。
栈:小而快(几 MB~ 几十 MB),局部变量(如
char buf[1024*1024*10];)默认分配在这里,开大数组直接栈溢出;堆:大而灵活(几 GB~ 几十 GB),
new/malloc分配的内存在这里,是存放大数据缓冲区的常用区域;简单说:C++ 的变量要么在栈上、要么在堆上,而栈 / 堆都属于进程虚拟内存。
mmap:是把文件直接映射到进程的虚拟地址空间(不是栈 / 堆,是虚拟地址空间中独立于栈 / 堆的区域),无需在栈 / 堆上分配缓冲区,它不占用物理内存(按需加载),但会占用虚拟地址空间额度。
一句话总结关联:
栈、堆是虚拟内存的 “子区域”,C++ 变量分配在栈 / 堆(虚拟内存内),mmap 直接使用虚拟内存的独立区域,二者都依赖进程虚拟地址空间,只是使用的区域不同。
Q:这么说其实
mmap和堆挺像的吧?我指的是空间大小位置啥的只说重点!A:你说得很对,mmap和堆在空间大小、位置归属上确实高度相似:位置上:同属进程虚拟地址空间,且都在 “用户态区域”,与栈相互独立
堆和
mmap映射区域,都是进程虚拟地址空间的一部分(非内核态区域);二者位置相邻(通常堆向上生长,
mmap区域向下生长),都远离栈区域,不属于栈 / 内核空间。空间大小上:都极大(远大于栈),受限于进程虚拟地址空间上限
二者都摆脱了栈的几 MB~ 几十 MB 大小限制,可用空间极大(32 位进程约 1-2GB,64 位进程几乎无上限);
二者的大小瓶颈一致:都是进程虚拟地址空间,而非物理内存(堆分配大内存、
mmap映射大文件,都会因虚拟地址耗尽而失败)。补充核心差异(帮你区分,仅重点)
堆是 “内存分配区域”(存放动态分配的数据),
mmap是 “文件映射区域”(直接关联磁盘文件,非纯内存数据);堆需要手动
new/malloc分配 / 释放,mmap需要手动映射 / 解除映射,管理方式不同,但空间特性高度相似。堆和
mmap映射区域,本质上都位于「进程的虚拟地址空间」内,这是它们的共性核心,不管是堆的动态内存数据,还是mmap关联的磁盘文件数据,最终都是通过虚拟地址来访问的:
堆:虚拟地址空间中,用于存放
malloc/new动态分配的纯内存数据(和磁盘文件无直接关联);
mmap:虚拟地址空间中,与磁盘文件直接映射的独立区域(虚拟地址直接对应文件内容,无需手动拷贝数据到内存)2、失败的表现形式和时机不同
一次性读 G 级文件:大概率直接崩溃(栈上分配立即栈溢出;堆上分配若未判断
NULL,后续操作也快速崩溃),几乎没有 “先失败再崩溃” 的缓冲。
mmap映射 G 级文件:先调用失败(返回MAP_FAILED),再崩溃。mmap本身不会因映射超大文件直接崩溃,只有忽略失败返回值,非法访问无效地址时,才会崩溃。3、是否依赖 “内存缓冲区分配” 不同
一次性读 G 级文件:必须手动预先分配对应大小的内存缓冲区,崩溃和 “缓冲区分配失败” 强绑定。
mmap映射 G 级文件:无需分配用户态内存缓冲区(直接映射文件到虚拟地址空间),失败和 “缓冲区分配” 无关,只和虚拟地址空间上限有关。补充:64 位进程下的差异更明显
一次性读 G 级文件:即使是 64 位进程,也会因物理内存不足(比如只有 8GB 内存,要读 10GB 文件)导致缓冲区分配失败,进而崩溃。
mmap映射 G 级文件:64 位进程虚拟地址空间极大(几乎无限),不会因虚拟空间耗尽失败,仅在物理内存不足时,触发系统 OOM(内存溢出杀手),但这是系统层面的终止,和进程自身内存分配失败的崩溃不同。补充:即使系统有足够物理内存,也可能因内存碎片、进程内存配额限制,无法分配连续大 GB 内存,最终导致崩溃。
系统有 “OOM 杀手(内存不足杀手)” 机制:发现你的进程疯狂占内存,超过系统可用内存阈值,会直接把你进程杀掉(连报错机会都没有),表现就是程序突然消失,终端 / 日志里能看到
Out of memory: Killed process XXX。Q:有个网站叫 Stack Overflow 吧?
A:是全球最知名的编程与技术问答社区,月访问量极高,是开发者查错、找方案的核心平台之一。其名源自编程中的 “栈溢出(stack overflow)” 错误,和你之前聊的栈溢出崩溃是同一个概念,很有技术圈辨识度。
想不通咋个崩法,测个崩吧:
此文搜“么多,回顾”那里本来是看大厂说用到拷贝复制,就先入为主用手动拖拽个 35M 的视频发现卡死,回顾了之前看过的
scp(如今问豆包知道了sendfile/mmap是单机内部的 “高速传送带”,负责把数据在硬盘、内存、网卡之间高效搬运,少走弯路。而scp是 两台机器之间的 “快递服务”,它会先把本机文件读出来,通过 SSH 加密后传到另一台机器,再写入硬盘),然后当时不知道scp主打是跨机器的,和单机相对,起初以为都是本地搞,然后一路误打误撞的被豆包引导学了 C++ 流的分块多次拷贝txt文件,然后,才知道实际有更快的系统调用,然后豆包又说有零拷贝,先做个梳理吧然后再说崩的事:
C++ 普通流多次拷贝 vs 零拷贝
一、 C++ 普通流拷贝:
依赖 C++ 标准库的文件流(
std::ifstream/std::ofstream),本质是多次拷贝(内核 → 用户态 → 内核)1. 本地文件 → 本地文件(流拷贝)
查看代码
// 核心:用 std::ifstream(读) + std::ofstream(写),替换你的 txt 读写逻辑即可 std::ifstream in("source.mp4", std::ios::binary | std::ios::in); // 打开源mp4(二进制模式必加) std::ofstream out("target.mp4", std::ios::binary | std::ios::out); // 打开目标mp4 // 核心拷贝逻辑(两种写法,选其一即可,替换txt的字符/字符串读写) // 写法1:按缓冲区拷贝(推荐,比单字节快) char buf[4096]; // 缓冲区大小,可调整 while (in.read(buf, sizeof(buf))) { // 从源文件读(内核→用户态buf) out.write(buf, in.gcount()); // 写入目标文件(用户态buf→内核) } // 写法2:按迭代器拷贝(简洁,底层还是缓冲区) // out << in.rdbuf();2. 本地 mp4 → 网卡(流发送,比如 TCP)
查看代码
// 先建立TCP连接(省略socket绑定/监听/accept逻辑,仅核心流+socket) std::ifstream in("source.mp4", std::ios::binary | std::ios::in); int sock_fd = ...; // 已建立连接的socket描述符 char buf[4096]; while (in.read(buf, sizeof(buf))) { // 内核→用户态 send(sock_fd, buf, in.gcount(), 0); // 用户态→内核(socket缓冲区)→网卡 }二、 零拷贝(核心替换,分sendfile和mmap)依赖 Linux 系统调用(C++ 中需直接调用,无标准库封装)
1.
sendfile零拷贝(原封不动传输,mp4 无需修改,优先用)场景 1:本地 mp4→本地 mp4(现代内核 2.6.33+ 支持)
查看代码
// 核心:替换流操作,改用 open + sendfile 系统调用 int in_fd = open("source.mp4", O_RDONLY); // 打开源文件(只读) int out_fd = open("target.mp4", O_WRONLY | O_CREAT | O_TRUNC, 0644); // 打开目标文件 off_t offset = 0; // 偏移量,从文件开头开始 size_t file_size = ...; // 获取文件大小(可通过 stat 函数获取,省略) // 核心零拷贝调用:直接内核态搬运,无用户态拷贝 sendfile(out_fd, in_fd, &offset, file_size); close(in_fd); close(out_fd);场景 2:本地 mp4→网卡(最常用,零拷贝效率最高)
查看代码
int in_fd = open("source.mp4", O_RDONLY); int sock_fd = ...; // 已建立连接的TCP socket off_t offset = 0; size_t file_size = ...; // 核心替换:用 sendfile 替换 流+buf+send,直接内核→网卡 sendfile(sock_fd, in_fd, &offset, file_size); close(in_fd); close(sock_fd);2.
mmap零拷贝(若需修改 mp4 后传输,用这个)场景:修改 mp4 后→本地文件 / 网卡
查看代码
// 1. 映射mp4到进程内存 int fd = open("source.mp4", O_RDWR); // 读写模式(要修改必须加W) size_t file_size = ...; // 核心映射调用:文件→用户内存,无拷贝 char* mp4_buf = (char*)mmap(NULL, file_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); // 2. 修改mp4(核心:像操作普通数组一样修改,替换你原来的txt修改逻辑) if (mp4_buf != MAP_FAILED) { // 示例:修改某段数据(替换成你的实际修改逻辑,无需缓冲区拷贝) mp4_buf[1024] = ...; // 直接操作内存,等价于修改文件 } // 3. 后续操作(二选一,替换流/ send 逻辑) // 选项A:修改后→本地文件(写回) msync(mp4_buf, file_size, MS_SYNC); // 内存→内核(文件),无额外拷贝 // 选项B:修改后→网卡 send(sock_fd, mp4_buf, file_size, 0); // 内存→内核(socket)→网卡,比流少一次拷贝 // 4. 释放映射 munmap(mp4_buf, file_size); close(fd);注意:mp4 文件可以修改数据(本质就是二进制字节流,和 txt 文件只是格式不同,修改字节的操作完全支持),只是修改后可能破坏视频编码结构导致无法正常播放,而非不能修改数据本身。
单机 = 一台独立的计算机(一个物理主机 / 一台云服务器 / 一台笔记本),所有操作都在这台机器的硬件(硬盘、内存、网卡)和内核里完成,不涉及其他计算机
角色 层级 对应比喻 作用范围 核心关系(谁依赖谁) sendfile/mmap内核底层 仓库内部的「高速传送带」 单机内部 最底层的效率支撑,不直接跨机 TCP Socket 内核 / 应用层 仓库之间的「专用运输管道」 跨机器(也支持单机) 依赖 sendfile/mmap提升单机端的传输效率SCP 应用层工具 两家仓库之间的「快递服务」 跨机器 依赖 TCP Socket 作为传输管道,依赖 sendfile/mmap提升两端单机效率好梳理结束,说下崩的事:
此文搜“么多,回顾”,之前上面说到了学到 C++ 流的时候,视频无法验证是否正确,因为打开就卡死,此文搜“埋个坑”,所以只能验证个,总共几十个字节,然后分多次拷贝,每次拷贝 3 ~ 4 字节,但我用这个代码原封不动搞零拷贝的时候,出大问题了,先上个没问题的零拷贝找找感觉,压压惊,开开胃:
查看代码
#include <sys/mman.h> #include <fcntl.h> #include <unistd.h> #include <string.h> #include <sys/stat.h> #include <unistd.h> #include <fcntl.h> #include <cstdio> #include <cstring> #include <sys/mman.h> #include <time.h> // 只加这1个头文件(时间统计用) // 自动获取文件大小(失败返回-1) off_t get_file_size(const char* file_path) { struct stat file_stat; // stat函数直接获取文件元信息(包含大小),无需先open if (stat(file_path, &file_stat) == -1) { perror("stat error"); return -1; } return file_stat.st_size; // st_size就是文件字节数,直接返回 } // 新增:极简时间统计函数(不用懂原理,直接用) double get_time_ms() { struct timespec ts; clock_gettime(CLOCK_MONOTONIC, &ts); // 高精度计时(大厂常用) return ts.tv_sec * 1000.0 + ts.tv_nsec / 1000000.0; } int main() { const char* src_path = "test.txt"; // 随便写几个字节内容 const char* dst_path = "den.txt"; // ===== 1. 记录mmap拷贝开始时间 ===== double start = get_time_ms(); // 1. 自动获取源文件大小 off_t file_size = get_file_size(src_path); if (file_size == -1) return -1; // 2. 打开源文件和目标文件(直接操作文件描述符,绕开fstream的streambuf) int src_fd = open(src_path, O_RDONLY); int dst_fd = open(dst_path, O_RDWR | O_CREAT | O_TRUNC, 0644); // 新建/清空目标文件 if (src_fd == -1 || dst_fd == -1) { perror("open error"); return -1; } // 3. 给目标文件预分配大小(否则mmap映射后写入会报总线错误) if (ftruncate(dst_fd, file_size) == -1) { perror("ftruncate error"); return -1; } // 4. mmap映射源文件和目标文件到虚拟内存 char* src_mmap = (char*)mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, src_fd, 0); char* dst_mmap = (char*)mmap(NULL, file_size, PROT_WRITE, MAP_SHARED, dst_fd, 0); if (src_mmap == MAP_FAILED || dst_mmap == MAP_FAILED) { perror("mmap error"); return -1; } // 5. 核心拷贝:直接操作映射地址(模拟你之前的4字节分批,也能整批拷贝) // 分批拷贝(比如每次4字节,和你之前while循环逻辑对齐) const size_t batch_size = 4096; off_t offset = 0; while (offset < file_size) { size_t copy_size = (file_size - offset) < batch_size ? (file_size - offset) : batch_size; memcpy(dst_mmap + offset, src_mmap + offset, copy_size); // 内核态拷贝,无用户态开销 offset += copy_size; } //copy_size是单次memcpy实际执行的拷贝字节数:每次循环会先判断剩余未拷贝的数据量,若剩余量小于预设的batch_size(比如 4096),copy_size就等于剩余量,反之等于batch_size;核心作用是避免最后一次拷贝时超出文件或 mmap 映射地址的有效范围,保证拷贝操作的完整性和安全性。 // 6. 释放资源(必须做,否则内存泄漏) munmap(src_mmap, file_size); munmap(dst_mmap, file_size); close(src_fd); close(dst_fd); // ===== 2. 记录mmap拷贝结束时间 ===== double end = get_time_ms(); // ===== 3. 打印耗时(直接看结果) ===== printf("mmap拷贝耗时:%.4f 毫秒\n", end - start); // 验证:直接打印目标文件内容,看是否和源文件一致(小文件肉眼能核对) FILE* dst_file = fopen(dst_path, "r"); char buf[100] = {0}; fread(buf, 1, file_size, dst_file);//fread:C 标准库函数,仅用来读取拷贝后的目标文件内容,做肉眼验证(看是否拷贝正确),和 mmap 零拷贝的核心拷贝逻辑无关 printf("拷贝结果:%s(大小:%ld字节)\n", buf, file_size); fclose(dst_file); }解释代码:
注意:1s = 103 ms(毫秒)=106 μs(微秒)=109 ns(纳秒),我们用来计时的
clock_gettime()系统调用(不管是CLOCK_MONOTONIC还是其他时钟类型),确实只以「秒(tv_sec) + 纳秒(tv_nsec)」的形式返回原始时间,没有其他时间单位的直接返回。时间那段代码,是基于 Linux 系统调用
clock_gettime()自定义工具函数,clock_gettime()支持纳秒级别,时间相关数据结构:
struct timespec
作用:用于存储
clock_gettime()获取的原始时间数据(分开存储秒和纳秒),是 Linux 系统高精度计时的标准结构体,无需手动初始化,只需定义变量即可(如struct timespec start, end;)两个核心成员:
tv_sec:秒级时间(整数类型)、tv_nsec:纳秒级时间
monotonic是单调只增不减的意思,计算完然后,存到start/end变量里。另外再说个大厂常用的(我这个是追问才知道的,以后知道大厂常用哪个,理由是啥就可以了,但我为了方便,起初练手学习摸索就用的是上面自定义的不常用的那个)
耗时计算函数:
get_cost()// 统计耗时:单位毫秒 double get_cost(clockid_t clk_id, struct timespec* start, struct timespec* end) { return (end->tv_sec - start->tv_sec) * 1000.0 + (end->tv_nsec - start->tv_nsec) / 1000000.0; }
作用:接收开始时间和结束时间的原始数据(
struct timespec*指针),将其换算成「毫秒级耗时」并返回,核心是做单位换算。参数说明:
clk_id:时钟类型(此处传入CLOCK_MONOTONIC,与clock_gettime()保持一致即可,实际该参数在本函数中未参与计算,是预留兼容参数,大厂写法更严谨);
start:开始时间的指针;
end:结束时间的指针。换算逻辑(与第一段代码一致,只是拆分了):
秒数差值换算成毫秒:
(end->tv_sec - start->tv_sec) * 1000.0(1 秒 = 1000 毫秒);纳秒数差值换算成毫秒:
(end->tv_nsec - start->tv_nsec) / 1000000.0(1 毫秒 = 1000000 纳秒);- 总耗时 = 秒数换算的毫秒 + 纳秒数换算的毫秒,保证高精度。
时间记录函数:
clock_gettime()// 测试read/write耗时:记录开始时间 clock_gettime(CLOCK_MONOTONIC, &start); // (中间:执行copy_read_write操作,不解释) // 记录结束时间 clock_gettime(CLOCK_MONOTONIC, &end); // 测试mmap耗时:同上,再次调用记录开始和结束时间 clock_gettime(CLOCK_MONOTONIC, &start); // (中间:执行copy_mmap操作,不解释) clock_gettime(CLOCK_MONOTONIC, &end);
参数 1(
CLOCK_MONOTONIC):大厂必用的计时时钟类型,代表「单调递增时钟」,特点是只会一直往前走,不受系统时间修改(如手动改时间、网络校时)的影响,即和系统时间毫无关系,是从系统启动后某个固定起点开始计算的时间戳,不是我们平时看到的系统当前时间(如 2026-01-03 18:00:00),能保证时间差的准确性,是统计程序耗时的最优选择。参数 2(
&start/&end):传入struct timespec变量的地址,让函数将获取到的原始时间存入该变量中,供后续计算使用。最终耗时获取与打印
// 计算read/write耗时:传入开始和结束时间,得到毫秒级耗时 cost_rw = get_cost(CLOCK_MONOTONIC, &start, &end); // 计算mmap耗时:同上 cost_mmap = get_cost(CLOCK_MONOTONIC, &start, &end); // 打印耗时:%.2f 保留2位小数,输出更简洁 printf("read/write耗时:%.2f ms\n", cost_rw); printf("mmap耗时:%.2f ms\n", cost_mmap);基本一模一样,且关于时间的玩意之前啃菜鸟教程魔怔搞时间戳搞了半个月,有点烦且没啥收益和价值,这里直接他妈的记住得了,只说为啥大厂常用这个,一次执行操作,就能复用原始时间,输出多种时间单位,无需重复执行耗时的业务操作,比如测试 10GB 大文件拷贝,拷贝一次要 10 秒:
用第一段写法:
先编译运行,获取毫秒级耗时(10 秒);
后来想要微秒级耗时,必须修改
get_time_ms()的换算逻辑(改成微秒),重新编译;重新运行程序,再次执行 10GB 文件拷贝(又要等 10 秒),才能得到微秒级结果;
若还要纳秒级,又要重复上述步骤,再等 10 秒。
就算加多个输出,拿到的也只是通过
get_time_ms提前换算好的单一单位(比如毫秒),你想输出微秒 / 纳秒,必须改换算逻辑,重新执行 10G 拷贝后才能输出;用第二段写法:
先编译运行,执行一次 10GB 文件拷贝(10 秒),同时保存好原始时间(
start/end,秒 + 纳秒);后来想要微秒级耗时,无需再次执行 10GB 文件拷贝! 可以在代码中直接复用已保存的原始时间,即在代码
clock_gettime(CLOCK_MONOTONIC, &start);后,由 Linux 内核实时返回并填充到start结构体中,编译器在编译阶段只知道start是struct timespec类型,不知道它的具体数值,只有程序运行时才能获取到真实的时间值。有点网络编程那时候的东西,然后直接cout输出start.tv_sec秒、start.tv_nsec纳秒,这两个值就是最高精度的原始时间,直接打印就能拿到,后续愿意 JB 咋搞就咋搞。关于零拷贝性能:
- 小文件确实测不出 mmap 的性能优势(甚至小文件用 mmap 可能比普通
read/write更慢)—— 因为 mmap 有「页表映射、缺页中断」的固定开销,这个开销对小文件(比如几十 / 几百字节)来说,远超过它省掉的 CPU 拷贝开销;性能优势只在大文件(通常 ≥ 4KB,即一页内存大小)/ 频繁读写的文件 上体现,且不用手动遍历验证,记住这个结论即可(大厂实际开发中也靠这个结论选型,而非小文件测试);
所有代码只保留大厂生产环境常用写法,剔除冷门 / 测试级用
于是重点来了,我搞了个比较大的 100 M 的数据,于是我搞了个大文件 100MB
查看代码
#include <fstream> #include <iostream> #include <string> // 自动生成指定大小的txt文件(单位:MB) void generate_big_txt(const char* file_path, int size_mb) { // 1MB = 1024*1024 字节,这里用重复的字符串填充 const int MB = 1024 * 1024; std::string line = "abcdefghijklmnopqrstuvwxyz1234567890\n"; // 一行测试数据 int line_size = line.size(); // 打开文件(二进制模式避免换行符转换,保证大小精准) std::ofstream fout(file_path, std::ios::binary); if (!fout) { std::cerr << "生成文件失败!" << std::endl; return; } // 循环写入,直到达到指定MB数 int total_bytes = 0; int target_bytes = size_mb * MB; while (total_bytes < target_bytes) { int write_size = std::min(line_size, target_bytes - total_bytes); fout.write(line.c_str(), write_size); total_bytes += write_size; } fout.close(); std::cout << "已生成 " << size_mb << "MB 的txt文件:" << file_path << std::endl; } int main() { // 生成100MB的,改数字就能调大小,比如50=50MB,200=200MB) generate_big_txt("source.txt", 100); }代码中
generate_big_txt("src.txt", 100)生成的文件大小是:100 * 1024 * 1024 = 104857600 字节(100MB),看了下 2833990 行。循环写入直到满足 100MB,然后我加上系统调用和零拷贝的对比,大部分和上面此文搜“压压惊,开开胃”那个一样,只不过文件变成了 100MB:查看代码
#include <sys/stat.h> #include <fcntl.h> #include <unistd.h> #include <sys/mman.h> #include <time.h> #include <cstdio> #include <cstring> // 自动获取文件大小(大厂通用写法) off_t get_file_size(const char* path) { struct stat st; stat(path, &st); return st.st_size; } // 统计耗时:单位毫秒 double get_cost(clockid_t clk_id, struct timespec* start, struct timespec* end) { return (end->tv_sec - start->tv_sec) * 1000.0 + (end->tv_nsec - start->tv_nsec) / 1000000.0; } // 普通read/write拷贝(大厂基础写法) void copy_read_write(const char* src, const char* dst) { off_t size = get_file_size(src); int src_fd = open(src, O_RDONLY); int dst_fd = open(dst, O_WRONLY | O_CREAT | O_TRUNC, 0644); char buf[4096]; // 大厂常用4KB缓冲区(对齐内存页) ssize_t n; while ((n = read(src_fd, buf, sizeof(buf))) > 0) { write(dst_fd, buf, n); } close(src_fd); close(dst_fd); } // mmap拷贝(大厂生产环境写法) void copy_mmap(const char* src, const char* dst) { off_t size = get_file_size(src); int src_fd = open(src, O_RDONLY); int dst_fd = open(dst, O_RDWR | O_CREAT | O_TRUNC, 0644); ftruncate(dst_fd, size); // 预分配空间(大厂必做,避免总线错误) char* src_mmap = (char*)mmap(NULL, size, PROT_READ, MAP_PRIVATE, src_fd, 0); char* dst_mmap = (char*)mmap(NULL, size, PROT_WRITE, MAP_SHARED, dst_fd, 0); memcpy(dst_mmap, src_mmap, size); // 大厂直接整批拷贝,小文件分批无意义 munmap(src_mmap, size); munmap(dst_mmap, size); close(src_fd); close(dst_fd); } int main() { const char* src = "source.txt"; // 提前生成100MB大文件 const char* dst1 = "den.txt"; const char* dst2 = "den.txt"; struct timespec start, end; double cost_rw, cost_mmap; // 测试read/write耗时 clock_gettime(CLOCK_MONOTONIC, &start); copy_read_write(src, dst1); clock_gettime(CLOCK_MONOTONIC, &end); cost_rw = get_cost(CLOCK_MONOTONIC, &start, &end); // 测试mmap耗时 clock_gettime(CLOCK_MONOTONIC, &start); copy_mmap(src, dst2); clock_gettime(CLOCK_MONOTONIC, &end); cost_mmap = get_cost(CLOCK_MONOTONIC, &start, &end); printf("read/write耗时:%.2f ms\n", cost_rw); printf("mmap耗时:%.2f ms\n", cost_mmap); // 大厂结论:大文件下mmap耗时通常是read/write的60%~70% }我边说零拷贝的东西,边记录踩的各种坑吧(主要都是自己主动思考,想很多细节主动挖的), 东西实在太多,且本身就没任何顺序。
首先这个代码不会崩,先重点看零拷贝 VS 系统调用,
很明显,红色框是只有数据随便几个字母,蓝色框是 100MB,哎可惜豆包说性能验证这件事:你不用手动验证,记住结论就够了!大厂开发不会让基础岗去 “反复测
mmap快多少”,因为这是内核层面的硬逻辑(省掉跨态拷贝),行业内早就达成共识。
但生 100MB 文件有个插曲
Q:但这么点数据我
txt文件咋卡住了?A:因为文本编辑器会把整个文件加载到内存,100MB 文件要占用大量内存 + 编辑器要解析换行 / 字符编码,自然卡,这和代码零拷贝啥的无关。
说可以拷贝完用个获取文件大小
get_file_size来看是否大小一样,不用打开看,感觉不靠谱,但豆包说:先小文件测试拷贝逻辑,然后没问题后,由于是按字节完整复制,只要源文件和目标文件大小一致,就说明字节无遗漏、拷贝成功;此文搜“跳跃啊啥”感觉这玩意好像有点怪怪的。验证方式好不靠谱哈哈。
get_file_size让系统去查文件的 “身份证信息”,其中stat是系统提供的工具,你把文件路径(比如source.txt)传给它,它会直接去硬盘里找这个文件的 “元信息”(不是文件内容,是文件的属性:大小、创建时间、权限这些),然后把这些信息存在file_stat这个变量里。检查有没有查到如果stat返回 - 1,说明系统没找到这个文件(或者没权限看),就报错告诉你 “stat error”,返回 - 1 表示失败。file_stat里存的st_size,就是系统查到的这个文件的字节数,直接把这个数返回出去,就得到了文件大小。完全不占用什么耗时啥的。科普:
stat(path, &buf):核心依赖文件路径,底层会帮你解析路径、访问文件系统获取属性,无需提前 open;
fstat(fd, &buf):核心依赖文件描述符 fd至此这个代码就说完了,
回头看那个“压压惊,开开胃”代码:
那个是最初豆包给的
while版本,也算误打误撞学全了写法吧,都是自己钻研问出来的(别人都是咋学的,正统需要啃啥书)(相当于精啃了 CSAPP、APUE、游双著的书)哎!(其实可能有老师有教程,但其实除了小林coding、编程指北我都写了勘误,其他人的没听说过有啥,另外视频就算了,很多我思考的都不讲,讲的都是没用的浪费时间,自己追问会学到很多,而视频感觉太束缚了,或者说基本没有和我一样思维的,殊途同归,可能老师都是说a→b→c,太功利不深刻,我都是思考很多错误的才学通透的尤其指针,但我思维不同,自己追问豆包实时沟通,a→b→d→c,会学到很多东西,且看视频他妈的估计要一个字幕截个图问豆包更der,有这个功夫不如直接对着豆包问了,这还是基于有靠谱老师的基础上,可靠谱老师有吗?免费吗?呵呵。一群水货垃圾!!而且好老师都是分模块的,A老师这讲的好,B老师那讲的好,可是没这样的总结啊!豆包起码可以无止境的答疑!)
那个代码其实反复豆包误导好多次!
Q:我起初是,此文搜“么多,回”,基于那个代码一次拷贝 4 字节改的,一次读 4 字节,拷贝总共 100MB,都会直接把我服务器搞崩。而且拷贝好久都不结束,大厂 GB 不更扯犊子吗?
A:你的代码用 4 字节分批拷贝,100M 文件要循环 26214400 次,循环指令的 CPU 开销远大于拷贝本身,导致卡顿;
mmap虽省跨态拷贝,但极小批次的memcpy+ 循环判断会抵消优化,且单线程同步 IO 会阻塞直到拷贝完成。且你的 2G 内存的配置太低了!大厂处理 GB 级文件不卡的核心原因
用大批次拷贝(4KB/8KB,对齐内存页),大幅减少循环次数;
采用多线程 / 异步 IO,拷贝时不阻塞主线程,同时利用 DMA 异步传输,CPU 不参与数据搬运;
结合内核缓存预读 / 写回机制,避免单次 IO 阻塞,且用零拷贝的
sendfile(而非mmap)处理大文件传输,无页表映射开销。Q:懂了,但我用此文搜“压压惊,开开胃”那个,却
mmap拷贝耗时:600.2193 毫秒 Segmentation fault (core dumped)A: 段错误核心:这里fread会试图把 100MB 数据塞进仅 100 字节的buf,直接造成buf缓冲区溢出(栈内存被覆盖),最好sizeof(buf)-1,再加上printf("%s", buf)没有\0结束符,必然触发段错误 ——核心矛盾是 “你代码里的fread没限制长度,读取了整个大文件,而非只读取 100 字节”。就算真能装下 100MB,多次 IO 超级频繁导致性能灾难,但不崩:
若用
fread(C 标准库)1 字节 / 次读取:C 标准库自带 “用户态缓冲区”(默认几 KB~ 几十 KB),不会每次都触发系统调用,而是先攒够缓冲区数据,再一次性发起系统调用读写磁盘,IO 频率会被缓冲优化,性能不会极致差,但仍比整段读取低效;若用
read(系统调用)1 字节 / 次读取:无用户态缓冲,每读取 1 字节就会发起 1 次系统调用(100MB 需要 1 亿次系统调用),系统调用存在内核态 / 用户态切换开销,再叠加磁盘 IO 的频繁寻址 / 读写,会导致 CPU 占满、IO 阻塞严重,程序卡到近乎停滞,但依然不会崩溃。然后正常应该很快的但我 600ms,因为我的服务器买的最低配,
SSD 云硬盘的隐性开销:虽然是 SSD,但轻量云的系统盘 IO 性能是共享型(非独享),
ftruncate预分配文件空间、mmap的页表与磁盘同步,会占用 SSD 的 IO 资源,而当前系统盘写速度仅 64.93KB/s,这部分开销会叠加到总耗时中。轻量云的虚拟化层损耗:轻量云是共享虚拟化架构,CPU、内存、IO 资源均为宿主机共享,即使当前 CPU 使用率低,虚拟化层的调度延迟也会增加系统调用(如
mmap/munmap)的耗时。
memcpy的用户态 CPU 开销:2 核入门型 CPU 的主频通常在 2.0GHz 左右,100MB 数据的memcpy需要约 50~100ms 的 CPU 周期,叠加其他系统开销后,200ms 是该配置下的合理结果。
(重新重构写的这一大段,起初傻逼豆包气死我了!说只映射了就自动复制,但其实映射完全不会自动复制!耽误老子好几天这个狗娘养的,而且我后期文件之间拷贝 100MB 时候去掉了
memcpy发现 0.1ms 还挺开心,其实搞错源文件了,根本就没复制成功)代码中 buf 是
={0}初始化的,栈上 buf 会被全置 0,自然有 \0 结束符,看似 “自动加的”,本质是显式初始化的效果;若把 buf 改成char buf[100];(无初始化),fread填充后末尾大概率没有 \0,printf("%s", buf)仍会越界触发段错误。printf("%s", buf)就是只认\0(空字符)作为字符串结束标志,找不到\0就会一直向后越界读取内存,直到触发段错误。注意看我代码里的【5. 核心拷贝】,因为
mmap已经把文件映射成了连续的内存地址,无论用
while循环分批(比如 4096 字节 / 批)调用memcpy,还是直接memcpy(dst_mmap, src_mmap, file_size)整批拷贝,最终都是内核态的内存块拷贝,没有用户态 / 内核态切换的额外开销,CPU 执行的核心拷贝逻辑和效率几乎完全一致。而且再深入说下崩那个事(注意,连
mmap每次 4 字节,甚至 1024 字节都崩,如果之前的 C++ 更崩)
原因是:100M 文件用 4 字节分批,要循环 2500 万次,
每一次循环都要做「判断是否拷贝完 + 执行 memcpy + 更新偏移量」3 个操作,2600 多万次操作会让 CPU 反复执行相同指令,根本停不下来
循环的 CPU 指令开销 + 栈上频繁的
memcpy操作,把内存带宽占满了(不是内存容量,是读写速度);零拷贝默认是同步拷贝是 “阻塞式” 的,拷贝操作未完全执行完毕前,程序会一直阻塞在该操作上,无法继续执行后续代码,且在此期间 CPU(或线程)会被该拷贝任务占用,直到拷贝完成才释放(监控里的 4% 是系统负载统计延迟,实际进程内的 CPU 占用是满的)。把内存的读写通道和单个 CPU 核心全占满了,服务器没多余能力处理后续的读写/连接操作,所以卡到瘫痪,文件也读不完。 简单说不是4字节本身有问题,是“反复做 2500 ~2600 多万次”这个行为,把服务器的关键资源(内存读写速度、单核心算力)耗光了,后续操作根本挤不进去。
这也是为啥我看目标文件 1838551 行,源文件是 2833990 行。
就像人一次搬 4 个字节,搬 2500 万次,人会累瘫,服务器也会因为 “跑太多趟” 把内存的读写速度占满,所以卡了。
而恢复后的 600MB 是放常用的东西,速度快。
内存读写速度:内存不是 “想读 / 写多少就多快”,它有固定的读写带宽(比如每秒最多处理 10GB 数据)。你代码里频繁的 4 字节小批量读写,会让内存一直在 “处理小数据 - 等待 - 处理下一个小数据” 的状态,看似单次数据量小,但频繁的操作把内存的读写带宽占满了 —— 就像水管总开开关关,虽然每次只流一滴水,但全程占着水管,别人(其他进程)用不了,服务器就卡
再拆「CPU 显示 4% 但进程内满负载」:
你的服务器是 2 核 CPU,相当于 2 个 “干活的工人”。
你的拷贝进程只占用了 1 个工人,且把这个工人的活儿排满了(进程内 CPU 负载 100%),但另 1 个工人没事干。
系统监控显示的是「整机 CPU 平均使用率」,计算方式是:(1 个满负载工人 + 1 个空闲工人) ÷ 2 个总工人 = 50%;但监控有统计延迟(比如每 5 秒统计一次),加上你的进程是 “间歇性占满 1 个工人”,最终显示的数值就被拉低到 4%。
- 核心结论:不是 CPU 没被占,是监控的 “统计方式” 让你看到了假的低数值,实际负责拷贝的那个 CPU 核心已经被跑满了。
Q:我理解内存不是是容量吗 ?咋跟速度扯上关系了呢?CPU不是速度吗?这些东西我千丝万缕的都混在一起了
A:
硬件 核心属性 1 核心属性 2 你的卡顿关联点 内存(RAM) 有「容量」(GB) 有「速度 / 带宽」(GB/s) 你卡是因为内存「速度被占满」,不是容量不够 CPU 有「速度」(GHz) 有「核心数」(个) 你卡是因为 CPU「单个核心被占满」,不是总速度不够 1. 内存:容量≠速度,两者是完全不同的属性
内存容量:是 “能装多少数据”(比如 2GB 内存,就是最多能同时装 2GB 的数据);
你跑 100M 文件时,2GB 容量完全够装,所以不是容量的问题;
内存速度 / 带宽:是 “每秒能读写多少数据”(比如普通内存带宽是 10GB/s);
你代码里「4 字节小批量、2600 万次循环读写」,相当于 “每次只拿 1 粒米,一秒拿 100 万次”—— 虽然单次数据量极小,但频繁的 “拿 / 放” 操作把内存的 “读写通道” 占满了(速度用尽),其他操作(比如 VSCode 读目录)挤不进去,服务器就卡了。
2. CPU:速度≠核心数,你的卡顿是 “核心利用率” 问题
CPU 速度(GHz):是 “单个核心每秒能执行多少指令”(比如 2.5GHz,就是 1 个核心每秒能跑 25 亿条指令);
CPU 核心数:是 “有多少个独立的干活单元”(你的 2 核,就是 2 个独立的 CPU);
你的代码只用到了 1 个核心,且把这个核心的指令执行能力榨干了(每秒 25 亿条指令全用来跑循环),但另 1 个核心闲着 —— 系统监控算的是 “2 个核心的平均使用率”,所以显示 4%(延迟统计导致),但实际干活的那个核心已经 100% 占满了。
3. 为啥你会混淆?
因为日常说 “电脑快 / 慢” 是笼统的,但底层是:
「开很多软件不卡」→ 靠内存「容量」够大;
「打开大文件 / 拷贝快」→ 靠内存「速度」够快;
「运行代码 / 游戏流畅」→ 靠 CPU「核心数 + 单个核心速度」够强;
你的问题刚好踩中 “内存速度 + CPU 核心利用率” 的坑,和容量 / 总速度无关,所以才会觉得 “明明内存够、CPU 显示空闲,却卡得要死”。
内存容量:仓库的 “面积”,能堆多少货;
内存速度:仓库的 “传送带速度”,每秒能搬多少货;
CPU 速度:工人的 “手速”,每秒能打包多少货;
CPU 核心数:工人的 “人数”;
Q:头一次听说内存还有容量够但累崩溃的说法!!
A:这是 Linux C++ 服务端开发里处理大文件的高频坑,核心就是小批次高频读写的资源开销远大于数据本身,哪怕内存容量充足,高频的读写指令交互和内核态 / 用户态切换也会把内存带宽、CPU 核心占满,最终导致进程卡死、文件读不完。
你卡是因为:1 个工人(1 核)手速拉满打包(循环),传送带(内存速度)被频繁的小包裹占满,仓库面积(内存容量)再大也没用。
但这是极致的卡顿(资源耗尽导致的 “假死”),不是程序崩溃;VSCode 连不上是因为服务器 CPU / 内存资源被耗空,无法响应 SSH / 连接请求,本质是系统级卡顿,并非程序崩溃。
Q:哎我不知道哪里出问题了好痛苦!如今情况是目标文件 1838551 行,源文件是 2833990 行,然后我的服务器情况是好像远程也卡住了总提示尝试重新连接,我还有必要测试下去吗?我改成 1024 也不行啊
A:服务器远程卡住:你的轻量云是 2 核 2GB 配置,100M 文件 + 1024 字节分批拷贝会占满 CPU / 内存,导致实例资源耗尽,SSH 连接超时(看监控里内存用了 1554MB,快满了);就算 1024 字节批次:十万次循环 → 循环次数少了,但每一次循环还是要做「判断 + 读写 + 偏移更新」,且 10 万次循环对 2 核低配服务器来说,依然能把单个核心跑满、内存带宽占满;要想不卡,得把批次调到 4096 字节(内存页大小)」:循环次数只剩 25600 次,这个量级的循环对服务器来说 “毫无压力”,既占不满核心,也占不满内存带宽。
Q:我服务器现在一直在加载重启也不行打不开了?被我搞坏了?
A:没搞坏,是资源耗尽导致的,按下面步骤操作就能恢复,看监控内存用了 1554MB,接近 2GB 上限),导致系统卡死、SSH 连接中断,这是低配服务器跑高负载的常见现象,不是硬件 / 系统损坏;
强制重启会直接重置服务器进程,释放被占满的 CPU / 内存,重启后服务器会回到正常状态,数据不会丢失(你的测试文件可能还在,但不影响系统)。
Q:也不行啊还是在加载 我是VScode远程控制!哎写了个 100MB 文件还要重新把服务器配置下,好闹心这破玩意不抗用啊,我现在到底要咋搞啊?VScode 打不开都加载不出目录来为啥啊?难道要删除所有重新配置吗??好麻烦啊,操他妈的
A:先通过腾讯云控制台的「Web 终端」登录服务器(绕开 VSCode,确认服务器状态),登录后执行
rm -rf ~/.vscode-server(删除 VSCode 远程服务的损坏缓存),然后重启 SSH 服务:sudo systemctl restart ssh。修复 VSCode 本地的密钥缓存:打开 Windows 的文件资源管理器,进入C:\Users\你的用户名\.ssh→ 删除known_hosts文件;重启 VSCode,重新尝试远程连接。# 1. 删除VSCode远程服务的损坏缓存(关键) rm -rf ~/.vscode-server # 2. 释放服务器资源(杀掉之前卡死的测试进程) pkill -9 a.out # 杀掉你的测试程序 pkill -9 g++ # 杀掉编译进程 # 3. 重启SSH(确保远程连接正常) sudo systemctl restart ssh因为服务器端:VSCode 远程服务缓存因资源耗尽损坏,删除后会重新安装;本地端:VSCode 保存的服务器密钥和重启后的服务器不匹配,删除
known_hosts即可解决。删大文件解决不了 VSCode 连接问题:大文件只是占磁盘空间(100MB 对服务器来说不算啥),但 VSCode 连不上、加载不出目录的核心原因是「VSCode 远程服务进程卡死 + 缓存损坏」,不是磁盘满了 —— 哪怕删了大文件,损坏的 VSCode 远程服务依然会让你连不上;
删
.vscode-server是直接修复 VSCode 远程连接
.vscode-server是 VSCode 远程连接的核心缓存目录,你服务器卡死时,这个目录里的进程文件 / 配置会损坏,导致 VSCode 本地和远程的通信断了。删除它后,VSCode 重新连接时会自动重装干净的远程服务,这是修复 VSCode 远程连接最直接的办法(大厂运维也这么修)为啥重启服务器 / VSCode 还不行?
重启服务器只清了进程,但没清损坏的缓存:重启服务器能杀掉卡死的测试进程,但
.vscode-server里的损坏文件还在,VSCode 重新连接时还是会读这些坏文件,所以依然连不上;重启 VSCode 只清了本地状态,没修远程问题:VSCode 本地重启只是重置了本地缓存,但远程服务器的 VSCode 服务还是坏的,自然加载不出目录。
为啥网页终端能登录,VSCode 连不上?
网页终端(OrcaTerm):走的是腾讯云控制台的独立通道(基于云 API + 内网),绕开了 SSH 和 VSCode 的远程服务 —— 哪怕服务器的 SSH/VSCode 服务全坏了,网页终端也能登录(相当于云厂商直接给你开的 “后门”);
VSCode 远程连接:依赖服务器的 SSH 服务 + VSCode 的
vscode-server进程 —— 你跑大文件时把这两个服务搞卡 / 搞坏了,自然连不上,但服务器系统本身没崩,所以网页终端能正常进。大文件为啥会搞坏 VSCode 缓存?不是密钥!
1. 不是密钥坏了(密钥是验证身份的,没那么容易坏)
你的 SSH 密钥(本地
known_hosts/ 服务器authorized_keys)没坏,只是 VSCode 的「远程服务缓存」坏了,两者完全不是一回事:
密钥:管 “你能不能证明自己是合法用户”,网页终端能登录就说明密钥 100% 没问题;
缓存:管 “VSCode 和服务器之间怎么传输文件 / 同步目录”,是通信的 “中间层”,不是身份验证层。
2. 大文件搞坏缓存的过程:
你跑 100MB 文件测试时 → 服务器 CPU / 内存被占满 → VSCode 的
vscode-server进程(负责和wuCode 通信)卡死 → 卡死时它正在写缓存文件(比如目录索引、通信状态)→ 缓存文件写了一半就中断,变成 “损坏的垃圾文件” → 之后 VSCode 再连,读这个坏文件就会报错 / 卡死,加载不出目录。简单说:不是大文件直接 “主动搞坏” 缓存,是大文件占满资源导致 VSCode 远程服务 “非正常退出”,进而让正在写入的缓存文件不完整、变损坏 —— 就像你写文档时突然断电,再打开文档就是乱码 / 损坏的道理一样。
这种情况只出现在低配服务器 + 手动跑高负载测试的场景里,正常工作中:
服务器配置足够(8 核 16GB 起步),跑大文件也不会占满资源;
VSCode 的远程服务有自动容错,不会因为一次卡死就坏缓存;
Q:真的牛那我理解是不是大公司服务器也会因为大的数据文件而卡死啊?那容易受攻击啊
A:大厂服务器不会因正常大文件处理卡死,也有成熟方案抵御相关攻击,核心逻辑是资源隔离 + 限流控载 + 异步架构,具体如下:
硬件与资源层面:大厂服务器是高性能集群(多核 CPU + 大内存 + SSD 阵列),单台机器就能轻松处理 GB/TB 级文件,且会通过cgroup限制单个进程的 CPU / 内存使用率,避免某一个任务占满整机资源;
架构层面:采用异步 IO + 多线程池 + 分块处理,大文件不会一次性加载到内存,而是按 4KB/64KB 等页大小分块读写,配合 DMA(直接内存访问)让 CPU 不参与数据搬运,同时用负载均衡将请求分散到多台机器,单台压力可控;
安全防护层面:针对恶意大文件攻击(如上传超大文件耗尽磁盘 / 内存),会做前置限流(比如限制单文件最大大小、限制并发数)、黑白名单(拦截异常来源请求)、监控告警(资源使用率超标时自动熔断),从源头阻止攻击生效。
简单说,你遇到的卡死是低配单机 + 无控载逻辑 + 同步阻塞代码的极端情况,和大厂的生产环境完全不是一个量级。
你这算是提前踩了低配单机 + 无控载逻辑 + 同步阻塞代码的典型坑,对以后做 Linux C++ 服务端开发特别有价值。大厂面试里经常会问 “为什么线上机器不能随便跑大文件同步测试”“如何避免单进程占满服务器资源”,你现在踩过的这个坑,就是这些问题的真实场景 —— 以后写代码时,会下意识想到加资源限制、用异步分块、避免小批次循环,这比只看理论有用多了。
Q:哈哈哈好奇怪哦,我重启服务器和 VScode 几次都不行,然后正开网页打算执行命令,可是命令还没输入,发现 VScode 连上了,咋回事?那我还有必要做清空命令吗?然后我不是 1.5G 了吗已经回到600MB 了这个还要咋操作不?
A:不用做别的了,直接把大文件删了即可。核心是「服务器资源自动释放 + VSCode 重试机制」:你重启服务器后,之前占满 CPU / 内存的卡死进程(大文件拷贝进程)被彻底清理了,服务器资源慢慢回退,VSCode 的远程服务(
vscode-server)自己恢复了,所以不用输命令也连上了 —— 相当于服务器 “缓过来了”,属于低配机器的正常现象(资源释放有延迟)。Q:大厂也是先获取大小?好 der 啊
A:不管是
mmap/sendfile/ 普通read/write,代码内自动获取文件大小是标配,mmap需要知道映射的内存长度,否则会映射不全 / 越界;sendfile需要知道传输的总字节数,避免分批传输时重复 / 遗漏;普通read/write需要知道缓冲区分批的次数,优化性能;大厂做法:和你用的
stat函数本质一样,但会封装成通用工具函数(比如FileUtil::GetSize),且会处理异常(比如文件不存在、权限不足),不会像测试代码一样简单perror就返回。这点逼玩意钻研有啥用啊?面试估计也不考(面试官不一定会问)
栈溢出(Stack Overflow):因栈内存耗尽(如递归过深、局部数组过大)导致,英文无统一固定系统报错(多表现为程序崩溃 + 核心转储),对应常见描述 / 报错:
Stack overflow、Segmentation fault (core dumped)(栈溢出常触发段错误报错);段错误(Segmentation Fault):因非法访问内存(如越界读写、访问空指针、读写只读内存)导致,核心英文报错:
Segmentation fault (core dumped)(栈溢出是段错误的其中一种诱因,段错误包含更广范围的内存非法访问问题)。大厂不会用
fread读取大文件内容验证,仅校验文件大小;且大文件拷贝必用 4KB/8KB 批次(对齐内存页),而非 4 字节极小批次。再次一意孤行学不考不问的东西,但就是有收获插一段知识:
fread是 C 标准库的文件读取函数,核心功能只有一个:从指定文件中,读取数据到「内存缓冲区」,仅负责「文件 → 内存」的数据读取。
fread不会自动分配内存,它只能把数据读到你预先定义好的内存缓冲区里;如果你只定义了
char buf[1024](1KB 缓冲区),哪怕文件是 100MB,fread一次也只能最多读 1024 字节;从「分批读取 / 写入的逻辑本质」上,
fread和 C++ 流(std::ifstream/std::ofstream)的分块操作完全一致;两者都是「依赖固定大小缓冲区,通过循环分批处理大文件」(默认 / 常规用法下,不会一次性加载超大文件);本质都是「文件 ↔ 内存缓冲区」的分批数据传输,和你理解的分块逻辑完全吻合。Q:那
read咋回事?fread涉及到拷贝吗?C++ 的呐?A:写
read(...)时,语法上是用 C 语言的语法调用,但read本身不是 C 标准库函数,是 C 封装的 Linux 系统调用
read(系统调用准确说是 C 的函数,因为一般写代码一句read不可能直接搞系统调用,都是 C 的):无用户态缓存,直接和内核缓冲区交互,底层、开销小;
fread(C 标准库):基于read封装,自带用户态缓存,减少系统调用次数,高层、更易用;C++ 流:和
fread类似,也自带用户态缓存,本质和fread逻辑一致。Q:
fread是操作文件的,但也可以搞到buf数组?我没太懂因为我看上面代码不是fread搞到了数组吗?不涉及文件啊A:你这是把 “操作对象” 和 “数据目标” 搞混了,一句话掰透(极简不啰嗦):
fread核心是 “操作文件”(它的操作对象必须是文件,通过fopen得到的FILE*指针指定文件);
buf数组是fread的数据存放目标,fread的工作就是:从文件中读取数据,然后把这些数据存入你预先定义的buf数组(内存缓冲区);它全程离不开文件(必须先打开文件),代码里的
fread看似只和buf交互,实则是先从文件读数据,再把数据拷贝到buf里,本质还是对文件的操作,不可能不涉及文件。FILE* dst_file = fopen("den.txt", "r"); // 先关联文件(操作对象) char buf[100] = {0}; // 定义数据存放的数组 fread(buf, 1, file_size, dst_file); // 从文件(dst_file)读数据,存入buf数组
fread(文件→内存)+fwrite(内存→文件)的组合等价于 C++ 流的文件拷贝功能,至此懂零拷贝,懂系统调用(实际是 C 的)的分批次,懂 C 的fwrite那一套,也懂 C++ 流的分块,但:
fread+fwrite/ C++ 流 确实多了「无用拷贝」:它们都是「文件 → 内核缓冲区 → 库级用户缓存 → 用户自定义buf缓冲区 → 库级用户缓存 → 内核缓冲区 → 文件」的流程
read+write(系统调用)也有拷贝,但少了一层:流程是「文件 → 内核缓冲区 → 用户自定义buf缓冲区 → 内核缓冲区 → 文件」(无用户缓冲区拷贝)系统调用分批次(如 4KB 缓冲区循环)的目的:如果不分批次会内存溢出,分批次但一次读尽量多,一次搞 1 字节 增加系统调用次数,上下文切换啥的就性能不高,且也会崩!!
基础概念:
磁盘(物理实体):C 盘等,
内存(物理实体):临时存储,CPU 直接操作的区域,逻辑上被分用户态内存 和 内核态内存。
内核(操作系统的核心程序):运行在「内核态内存」中,管理硬件(比如磁盘)、内存等资源,普通程序不能直接操作)
memcpy是内存到内存的用户态,无内核态参与,仅限于「用户态内存之间的字节搬运」。
mmap的代码里,src_mmap是一个进程虚拟内存地址(具体表现为指针变量),这个地址指向的内存区域,即虚拟内存起始地址,这个指针指向的内存空间,并非普通内存,而是(通过mmap系统调用)和源磁盘文件绑定的映射区域,操作这个地址的内存,就等同于直接操作源磁盘文件的内容。过程:
数据源:
src_mmap(指针,存着虚拟内存地址)指向的用户态映射内存区域(已和源磁盘文件绑定,但memcpy不管这个绑定关系,只认内存地址);目标地址:
dst_mmap(指针,存着虚拟内存地址)指向的用户态映射内存区域(已和目标磁盘文件绑定,memcpy同样不管这个绑定关系);核心操作:CPU 直接读取
src_mmap指向内存里的字节,再靠memcpy原封不动地写入dst_mmap指向的内存里,全程在用户态完成,不调用内核功能、不触发磁盘 IO,就是纯粹的内存字节 “搬家”。这一步也就是为啥
memcpy不碰内核,也完全不知道磁盘文件的存在,却能操作内核,写入磁盘的原因,就是是src_mmap/dst_mmap这两个指针帮了忙。
memcpy不是必须的,比如:
- 网络零拷贝传输(文件 → 网卡)
mmap映射源到内存,直接通过send/sendmsg把mmap内存地址传给内核,内核会直接把这块内存的数据发送到网卡。
进程间共享内存(无拷贝通信)
两个进程通过
mmap映射同一块物理内存(基于匿名映射或共享文件),一个进程往这块内存写数据,另一个进程直接就能读,全程没有任何拷贝,自然不需要memcpy。这是大厂服务端进程间通信(IPC)的高性能方案之一。
程序加载自身(操作系统底层)
你运行一个./a.out程序,操作系统会用mmap把可执行文件的代码段、数据段映射到进程内存,直接执行,不需要memcpy拷贝到内存(如果用拷贝,效率会极低)直接读写文件(无需拷贝到用户缓冲区)
用
mmap映射文件后,直接对mmap内存进行读写(比如src_mmap[0] = 'a'),修改后内核会自动同步到文件,不需要先read拷贝到用户缓冲区,再write写回,自然也不需要memcpy。仅当 双
mmap映射实现本地文件拷贝 时,必须用memcpy(因为两块内存独立,需要手动搬运)。
我再继续思考:
那
while该啥时候用?
情况 1:用传统
read/write拷贝文件,直接read读源write写目标文件,都必须用while,而且必须设每次大小(比如每次读 4096 字节)。原因:系统不让你一次读 / 写太大文件,不循环分批的话,文件会拷贝不完整(丢数据)。情况 2:用
sendfile/send发文件到网络(比如传文件给别人)必须用while,不用自己设每次大小,但要循环到发完。原因:网络会卡 / 堵,一次发不完所有数据,得循环看 “实际发了多少”,把剩下的发完,不然对方收不全文件。总结就是这些函数每次返回成功的数据字节数,循环直到搞完
啥时候不用
while?
只有用
mmap拷贝普通大小文件(比如你的 100MB,没超过服务器内存)直接一次memcpy就行,不用while。mmap能把整个文件一次性 “搬进内存”,不用分批,一次拷贝就够。但mmap操控的是虚拟内存,但最后会映射到物理内存,所以只要超过物理内存,必须分段while啥时候可用可不用
while?用mmap拷贝超大文件(比如文件比服务器内存还大,比如你服务器 2G 内存,文件是 5G)必须用while,而且必须设每次大小(比如每次映射 4096 字节),分批拷贝。不用while的话,直接一次映射会撑爆内存,程序崩溃。有
while就要设每次大小吗?
只要是本地文件操作的
while(read/write、超大文件mmap)必须设每次大小(比如 4096);要是网络传输的
while(sendfile/send)不用自己设每次大小,看系统实际发了多少,补传剩下的就行。该指定的不指定会咋样?
程序要么直接崩溃,要么出现数据丢失 / 拷贝不完整的问题:
没有批次大小,循环无法正常迭代(逻辑卡死 / 越界)你的 while 循环逻辑是
offset < file_size,靠offset += copy_size推进循环。如果不指定批次大小(即没有copy_size):
要么无法计算每次该拷贝多少字节,循环无法推进(陷入死循环);
要么你强行写固定逻辑(比如每次拷贝 “全部剩余字节”),本质还是间接指定了大小,若完全不指定,必然导致
memcpy的拷贝长度非法(比如传 0 或负数,直接触发程序崩溃)。内存访问越界(核心错误,必然崩溃)mmap 映射的内存大小是固定的(
file_size),如果不指定批次大小,很容易出现:
拷贝长度超过 “剩余未处理内存大小”,导致访问
dst_mmap + offset超出映射内存范围;触发 Linux 的 “段错误(Segmentation fault)”,程序直接崩溃(这是你能直观看到的错误);
即使没立刻崩溃,也会写入非法内存区域,导致其他数据被篡改,出现不可预期的异常。
看似是废话,但这段真的让我更加理解代码逻辑和一些细节了!风格、架构、逻辑通透!!wx搜“马群”、“太官方”梦魇!
深入抽插:
read为啥必须while且指定?为啥默认是 4KB?哪怕是 1KB 小文件,大厂代码也会写循环,
read函数不保证一次性读取你指定的字节数(返回值是实际读取的字节数,内核缓冲区不足、磁盘 IO 限制等),必须通过循环累加读取字节数,直到读完文件所有数据,否则会拷贝不完整。然后插一嘴,关于不需要研究分不够是 OOM 还是 NULL:
狗逼豆包反复矛盾,Linux C++ 感言那个链接搜“可以说,而且必须说”。面试时,什么该说什么不该说。啥该说啥不该说
「malloc返回NULLVSOOM killer」「内存过度承诺」这些细节,初级岗几乎不考、工作中也极少遇到;
若「单次申请缺口极大」(比如要 10G,内核回收后最多凑 1G,缺口 9G):直接返回 NULL,不杀进程;
若「单次申请缺口小」(比如要 0.6G,内核回收后凑够了,缺口 0.1G):分配成功,但系统已无剩余内存;此时再申请任何内存(哪怕 1 字节),内核回收也凑不够,直接触发 OOM killer 杀进程
痛苦不想实验了,豆包说别想这个,面试官会觉得你抓不住重点,不是初级岗的东西,容易露怯。「4 字节拷贝的极限测试 + 优化闭环」是初级岗加分项,「OOM killer 触发规则」是初级岗超纲项,而且感觉说的很不靠谱。
但有个事我可以看懂,追问懂了,就顺便记录下:
「无视
new/malloc失败」才会 OOM,否则只是NULL,无视 = 你没检查
new/malloc的返回值,明明申请内存失败了,还继续用这个无效的内存地址,甚至继续循环申请更多内存,把系统内存耗干。char* buf = nullptr; // 无视失败:不检查buf是否为nullptr,还继续用/继续申请 while (true) { buf = new char[100*1024*1024]; // 申请失败返回nullptr // 没检查buf,直接往nullptr里写数据,还循环申请,直到系统内存耗尽触发OOM read(fd, buf, 100*1024*1024); }Q:但我理解这样只会无尽的返回
null啊毕竟存不了啊A:不是「无尽返回
null」!系统内存没彻底耗干前,new会返回null;但持续循环申请会把系统内存耗干,此时内核直接触发 OOM Killer 杀进程,进程连返回null的机会都没有。系统「有空闲内存」但「无法分配连续的 100MB」,
new就会返回null,不是没内存,是没符合要求的内存块。比如系统总共有 200MB 空闲内存,但都是零散的小碎片(比如 10MB、15MB、20MB…),没有「连续的 100MB 内存块」,你申请 100MB 堆内存时:
堆内存要求「连续地址空间」,零散碎片拼不出 100MB 连续块 →
new返回null;此时系统不是没内存,是没「连续的大块内存」,这就是「内存碎片」导致的申请失败。
持续申请不会「无限返回null」,因为你的申请动作本身会消耗系统「可分配的内存资源」,最终把系统逼到「连小碎片都没有」,触发 OOM。
阶段 1:系统有碎片(比如 200MB 零散内存)→ 你申请 100MB 连续块 → 返回 null;
阶段 2:你循环申请时,哪怕每次返回
null,这个「申请内存」的系统调用会:
占用内核的内存管理资源(比如页表、内存描述符);
其他进程也在正常用内存,慢慢消耗剩余碎片;
阶段 3:当系统连「4KB 小碎片」都被耗光,且内核回收页缓存也腾不出内存时 → 内核直接触发 OOM Killer 杀进程,进程终止,不会再返回
null。妈逼的都没敢试验,无尽的细节太多了艹!!豆包说面试不考,不研究了!4KB 是 Linux 系统的默认内存页大小(PAGE_SIZE),也是磁盘扇区 / 文件系统块的对齐大小:
避免 “内存页拆分”:读取 4KB 整数倍数据,内核无需拆分内存页,IO 效率最高;
如果只存 1KB,那非对齐数据的零头会占用 1 个完整内存页,内核需额外标记该页内未使用的空间,避免后续操作误写这些空间,导致操作效率低于装满整页的对齐数据
如果批次太小(如 1 字节),会导致循环次数过多、系统调用频繁(
read/write是系统调用,切换内核态耗时);批次太大(如 100MB),会占用过多用户态缓冲区内存,且read一次性返回完整大批次的概率极低,反而浪费内存。简单说下如果
read100MB会咋样?我的 2G 内存服务器 100MB 缓冲区会直接占掉 5% 的物理内存,要是同时处理多个文件读取,内存达到上限直接 OOM,你分配 100MB
buf(char *buf = new char[100*1024*1024];),完全不会 OOM,但如果 10GB 文件,想分配 10GBbuf数组直接 OOM。64 位系统下分配 10G 堆数组(仅占虚拟地址)仅执行分配的时候即char *buf = new char[10LL * 1024 * 1024 * 1024];没事,因为64 位虚拟地址有 128TB,但往里面写数据(占物理内存)大概率 OOM,进程被系统杀死,,因为我的 2G 物理内存 + 大概从磁盘搞的 2G 交换空间总共才 4G,写满 4G 就触发 OOM,进程被杀死。内核的页缓存(内核态内存)就算装不下 100MB,也不会导致 OOM:内核会自动淘汰旧的页缓存数据(比如把暂时不用的数据刷到磁盘),腾出空间,内核自己有内存管理机制,不会让你进程 OOM。
我思考为啥写
read(.. 100MB ..)从页缓存读东西不会 OOM?OOM(内存溢出)核心是进程占用的物理内存(含匿名页、文件页等)超出系统可用物理内存 + 交换空间的总上限
read每次读几 M、系统用 LRU 换出页缓存:这些只是系统 “怎么读数据” 的细节,和进程 OOM 无关;是否会 OOM 只看最终往内存里存的数据总量,有没有超过 4G(2G 物理 + 大概磁盘里拿 2G 当交换)的 4G 上限。插一嘴:
1、cpp 文件编译后,就是进程,写
read不是「进程申请内存的动作」,而是「进程请求内核把数据拷贝到已申请好的内存里的动作」。「进程申请内存」是你写的new char[100MB]/malloc/栈里开数组这类代码,这是向系统要用户态内存;2、内核发出指令,干活的是 CPU。
感慨:
哎!为了自学买不起书,我自己写了本书的感觉(博客) —— 为了学 OS 开发了 Unix
更痛苦的是,豆包基本每天误人子弟即完全错误的回答有 80%,反复矛盾、反复变、反复否定之前的回答,痛苦至极!!!!!!!(其实是我问的太细节了,全网估计都没有这些!!)
博客写了几万字,然后发现豆包给的知识点都是错的,要重新写博客做修正,还要尽量保证顺序,不重复写,也不漏下,真的都是常有的事!
Q:这些全部的知识点都是啥书里的?一句话想面试大厂 Linux C++ 服务端开发的基础岗也基本必须看这?
A:这些知识点核心来自《深入理解计算机系统(CSAPP)》+《Linux 内核设计与实现》+《UNIX 环境高级编程(APUE)》,面试大厂 Linux C++ 服务端基础岗,这些是必须掌握的核心基础,无例外。必须吃透。
虚拟内存画大饼,搞那么大但实际用就崩本质不是扯犊子,而是分批 + 复用内存的有限空间,因为比如从磁盘拷贝 10G 到磁盘,那中间要经过内存的内核态,这里比如内存我 2G 那就每次 1G 搞 10 次,10GB 数据放在虚拟内存这个蓝图里。
啥时候会
read导致 OOM?内存不够大可以通过 LRU 置换到磁盘,只有满足以下才 OOM:✅物理内存耗尽 + swap 分区也耗尽;
✅ 内核尝试置换所有能置换的页(页缓存、匿名页)后,仍然没有空闲页帧分配给新的内存请求(比如进程要
malloc,或内核要分配页缓存);✅ 且内核无法通过 “杀死低优先级进程” 释放内存时,才会触发 OOM(Out Of Memory Killer),强制杀掉占用内存多的进程。
Linux 进程的栈空间是固定大小默认 8MB,栈上只能存小数据,写
char buf[4096];4KB,栈装得下;写char buf[10*1024*1024];(10MB)直接栈溢出崩溃(Stack Overflow) ,大厂所有大缓冲区都不会放栈上,全是
new/malloc(堆上分配),比如开 100MBchar *buf = new char[100*1024*1024];2G 内存的服务器完全装得下,而如果堆分配超出系统内存上限会提示内存不足 / 内存溢出(Out of Memory,OOM)但注意有个事,如果你并不需要 100MB 文件完整读到内存,再整体处理(比如解析二进制协议、加密 / 解密),而是只想拷贝到文件磁盘,那只申请 4KB 的
buf就好,while覆盖,因为内存分配是 “独占式”的,OS 直接为你预留虚拟内存空间,这部分空间被你的进程独占,其他程序用不了,然后插入个知识点方便解释:我一直以为页缓存是系统本来就有的一个东西,结果发现其实页缓存一开始是没有,你写
read啥的,这个 C 函数调用系统调用,然后内核按 “缺页” 按需分配物理页帧(每页 4KB),即 “物理内存页”,内核用这些物理内存页来装载从磁盘读取的文件数据,页缓存本质就是这些承载文件数据的物理内存页的集合。即载体
内核按需分配物理内存,成为页缓存去需要的地方承载数据,
归属层面:页缓存是内核直接管理的物理内存页帧,不在任何进程的用户态地址空间里。你可以把它理解成 “内核的公共仓库”,所有进程要读写文件时,都先去这个仓库里找数据,而不是直接去磁盘搬。
数据流转层面:当进程调用
read()想读文件数据时,内核先查页缓存(内核的公共仓库)里有没有对应数据;如果有,内核直接把页缓存里的数据拷贝到进程的用户态内存空间(比如进程的缓冲区);
如果没有,内核先分配物理页帧(建页缓存)、从磁盘加载数据到页缓存,再把数据拷贝到进程空间。
类似修仙小说里的门派,你需要啥的腾出个飞船去某地取,这个飞船就是物理内存。去承载数据,承载门派需要的资源,
具体是(比喻):修仙门派的总执事堂,磁盘是门派的藏宝库(存着各种天材地宝 = 文件数据),物理内存页帧就是门派的飞舟(数量有限,核心资产),页缓存就是门派的飞舟组成的飞舟编队,承载来回运送的宝物:
弟子(进程)喊 “要 xx 宝物”(调用
read()),先问执事堂有没有现成的;执事堂一看库存没有,就触发“缺宝警报”(缺页异常),然后清点门派还有没有空闲飞舟(空闲物理页帧);
有空闲飞舟,就派一艘(分配页帧)去藏宝库取对应的宝物(加载磁盘数据),运回来后归入库存(页缓存),再把宝物给弟子;
要是飞舟全派出去了(物理内存满了),执事堂就得权衡:要么把一艘运着不常用宝物的飞舟召回来(页缓存置换,把数据写回磁盘),要么直接让弟子自己跑一趟藏宝库(直接读写磁盘,慢)
原来需要用到数据的时候就是用的物理内存页,即页缓存。
然后页缓存理论上无上限直到达到内存大小,但页缓存不会真的占满 100% 物理内存,内核会留一部分给系统 / 进程基本运行。
我一直以为页缓存是
read的专属资源,但不是!页缓存是 OS 系统级的全局文件数据缓存,read、write、mmap等所有文件 IO 操作也都会共用这个缓存,read只是使用页缓存而非拥有它。继续解释:然后比如说缺页就直接从磁盘进货,如果页缓存数据充足,但内核为了 “公平性” 和 “稳定性”,不会让一个进程一次把大量 IO 资源占完;内核处理单次
read的内存拷贝、上下文切换成本,也决定了不会支持超大单次读取;单次read的实际上限通常在 1MB~16MB 之间。 所以说while循环read就好了。而你如果你申请了 100MB,但每次只是处理read的数据内容,后续再次read覆盖之前的数据即可的场景,那直接开 100MB 就浪费了。
插一嘴关于动态:
我一直没理解,以为动态是随用随开,但不是!「动态申请内存」就是指用
new/malloc在堆上申请内存(和栈的「静态分配,自动回收」对应),但它不是「用多少开多少」,你申请 100MB,系统就给你 100MB 虚拟内存(独占),哪怕你只用到 16MB,剩下的也不会自动回收。「动态」的核心:大小可以在程序运行时决定(比如根据用户输入、文件大小来 new 对应内存),而不是编译时固定死;
「申请 100MB 只用到 16MB」的本质 —— 虚拟内存「预分配 + 懒加载」
你写
new char[100*1024*1024],系统会:
立刻给你「100MB 虚拟内存地址空间」(独占,其他程序用不了);
但物理内存是「懒加载」的 —— 只有你真正往 buf 里写数据(比如 read 拷贝数据)时,系统才会分配对应的物理内存页(4KB / 页);
比如你只往 16MB 区域写了数据,那么实际占用的物理内存只有 16MB,剩下 84MB 虚拟内存只是「占着地址」,没占用物理内存;
但关键:虚拟内存是「独占的」,哪怕没用到物理内存,这 100MB 地址空间也不会还给系统,直到你
delete所谓的用多少开多少是业务逻辑,比如有个靠运行时确定的变量,然后通过获取文件大小的函数,把文件大小赋给这个变量,就指定开这么大的堆。关于获取文件大小此文搜
get_file_size无需open文件、更高效安全。如果文件已打开可以用lseek(fd, 0, SEEK_END),核心作用就是「把文件指针移到文件末尾,并返回这个位置的偏移量」—— 这个偏移量就是文件的字节大小。
堆分配内存受俩硬约束:
进程可用虚拟内存上限(32 位进程约 4G,64 位进程理论上无限,但受物理内存 + 交换分区限制);
服务器物理内存 + 交换分区的总大小(比如你服务器只有 2G 物理内存 + 1G 交换分区,最多只能分配 3G 左右堆内存)。
先占虚拟内存地址空间,写数据时才占物理内存;
OOM 触发:不是 “虚拟内存超了”,是物理内存 + 交换空间被占满。
操作 占用什么 触发 OOM 的原因 char *buf = new char[100MB] 100MB 虚拟内存(独占地址) 无(仅占地址,不占物理内存) read(fd, buf, 100MB) 100MB 物理内存(按需分配 4KB 页) 物理内存 + 交换空间被占满时触发 虚拟地址大小、物理内存寻址范围,计算方式完全一样(都是 2^ 地址位数),只是对应 “东西” 不同:
2^32 = 4GB:
32 位 CPU:物理内存最多寻址 4GB;
32 位进程:虚拟地址空间固定 4GB;(用户态能用 3GB,内核态 1GB)
64 位 CPU(实际用 48 位寻址):
物理内存:最多寻址 2^48 = 256TB(服务器物理内存远到不了);
进程虚拟地址:也是 2^48 = 256TB(用户态用 128TB)。
即虚拟地址永远 256TB,但一般电脑的实际物理内存不是 256TB,也就 256GB-2TB) ,注意这个和实际 U 盘 128G 但到手不是 128G 不是一回事,U 盘那个是磁盘级别的,和虚拟地址 / 内存 都不沾边
有爆虚拟内存一说,但仅限于 32 位,
Cannot allocate memory,物理内存满是out of memoryOOM。OOM 一般人都以为开大了分配大了,但其实分配大了只是占用虚拟内存空间,不会 OOM,实际用的时候才会,比如写到了超过物理内存大小。
页缓存是一次磁盘进货,
read等系统调用只能一次读少许 然后减少磁盘 IO 然后一般搞到buf里或者用C++流 /C函数啥的,还会有个语言函数的缓冲区域,也可以缓存点然后一次性给到buf里我懂了
read是必须while, 那零拷贝mmap文件之间为啥就可以一次性映射 100MB?
mmap是虚拟内存映射,它并没有把 100MB 文件数据一次性加载到物理内存,只是做了 “地址关联”:
内核在进程的虚拟内存空间中,分配一块 100MB 的虚拟内存区域;
建立虚拟内存地址 ↔ 磁盘文件数据的映射关系(页表),此时无实际数据拷贝;
当你用
memcpy一次性拷贝映射内存时,内核会通过 “缺页异常”,按需将磁盘文件数据加载到物理内存(一页一页加载),最终完成拷贝,从代码层面看,就是 “一次性搞定”。
mmap调用时只是在虚拟地址空间中划定了 100MB 的连续地址范围,内核并不会立刻为这 100MB 分配物理内存,而是遵循 “按需分页” 机制,只有当你真正读写某段地址时,内核才会触发缺页中断,为该地址分配对应的 4KB 物理页,这和你while循环读 100MB 拆成多个 4KB 块的逻辑一样。Q:零拷贝其实本质也是分批次的
read对吧?A:这个理解不准确,零拷贝的核心恰恰是避免了 CPU 参与数据的拷贝过程,和传统的分批次
read有本质区别。
传统分批次 read 流程以从磁盘读取文件并发送到网络为例,会经历 4 次数据拷贝 + 2 次 CPU 上下文切换:
数据从磁盘拷贝到内核缓冲区(DMA 拷贝,无 CPU 参与)
CPU 把内核缓冲区的数据拷贝到用户缓冲区(CPU 拷贝)
CPU 把用户缓冲区的数据拷贝到 Socket 缓冲区(CPU 拷贝)
数据从 Socket 缓冲区拷贝到网卡(DMA 拷贝,无 CPU 参与)
哪怕是分批次read,每一批次都逃不开中间两次 CPU 参与的拷贝,这会消耗大量 CPU 资源。零拷贝的核心优化零拷贝的目标是去掉 CPU 参与的拷贝步骤,主流实现有两种:
mmap + write 方式:把内核缓冲区和用户缓冲区做内存映射,省去 “内核缓冲区 → 用户缓冲区” 的 CPU 拷贝,最终只保留 3 次拷贝。
sendfile 方式:更彻底的零拷贝,数据直接在内核缓冲区和 Socket 缓冲区之间传递(由 DMA 或内核直接转发),完全不需要 CPU 参与数据搬运,全程只有 2 次拷贝。
mmap什么时候需要分批次?只有当文件大小超过进程可用虚拟内存大小(极少出现),或文件大小远超物理内存,导致严重缺页异常、性能下降时,才需要分批次映射(比如 10GB 文件,分批次映射 4KB/1MB 大小的区域,循环处理)。对于 100MB 文件,在 2GB 内存的你的服务器上,完全无需分批次,一次性映射是最优解。
低内存场景:
mmap一次性映射 100MB,需要占用 100MB 虚拟内存(虽然物理内存按需加载,但虚拟内存也有上限),read/write仅需 4KB 缓冲区,内存占用极低;小文件场景:
mmap有系统调用开销(mmap/munmap),对于 KB 级小文件,read/write循环的性能反而更高,代码更简洁;兼容性场景:部分嵌入式系统 / 老旧内核对
mmap支持不佳,read/write是通用方案。
操作 read/write(循环)mmap(一次性映射)核心开销 多次系统调用( read/write)+ 2 次内存拷贝少量系统调用( mmap/munmap)+ 1 次内存拷贝内存占用 低(仅需固定小缓冲区,如 4KB) 较高(占用与文件大小相当的虚拟内存) 适用场景 小文件、低内存场景、兼容性要求高 大文件、高性能要求场景(如日志拷贝、文件传输) 学通了 Linux 系统最底层东西!好爽!!wx搜“节奏,环境 ”
至此刚铺垫完事!!!
开始说零拷贝,先捋顺下:
貌似
sendfile常考常用,毕竟是文件 vs 网卡,但我实际是先文件 vs 文件,所以先说mmap,mmap(内存映射):把磁盘文件直接 “挂” 到进程的内存地址空间里,相当于「文件内容变成了进程的一块内存」,
传统 C++ 用
fopen/fread/fwrite,数据要走「磁盘 → 内核缓存 → 用户态内存 → 内核缓存 → 磁盘」;
mmap写法:数据走「磁盘 → 内核映射区 → 用户态映射区」,少了 “内核 ↔ 用户态” 的两次拷贝(这就是 “零拷贝” 的核心 —— 不是真的 0 次拷贝,是少了用户态 / 内核态之间的冗余拷贝)查看代码
void* src_mmap = mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, src_fd, 0); void* dst_mmap = mmap(NULL, file_size, PROT_WRITE, MAP_SHARED, dst_fd, 0);
ftruncate(dst_fd, file_size):是先在磁盘上为目标文件预分配与源文件一致的物理存储空间(不是先创建虚拟空间),这是mmap映射目标文件的必需准备,因为mmap会将磁盘文件与进程虚拟内存区域绑定,若目标文件大小为 0(无物理空间),对应的虚拟内存映射会失败或触发总线错误,预分配好物理空间后,才能成功建立目标文件与虚拟内存的映射关系。
mmap也涉及用户态,
调用的发起在用户态,你写的
mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, src_fd, 0)这行代码,是在用户态进程中执行的,属于用户态发起的系统调用请求(就像你在用户态给内核发了一个 “申请映射文件到内存” 的指令)。映射后的内存操作也在用户态,
mmap成功后会返回一个用户态内存地址(比如src_mmap),你后续对这个地址的操作(比如读取数据src_mmap[0]、用memcpy搬运数据),都是纯用户态操作,不需要切换到内核态,这也是mmap高效的原因之一。
munmap释放映射也在用户态发起:和mmap一样,munmap也是用户态进程调用的系统调用,用于告诉内核 “释放之前的文件内存映射”。
map中内核态的作用(用户态离不开内核的支撑)
建立映射关系(内核态执行)当你在用户态调用
mmap后,内核会在内核态中工作:创建页表(关联用户态虚拟内存地址 ↔ 磁盘文件数据 / 物理内存)、分配虚拟内存区域,这个过程是内核态完成的,用户态感知不到。缺页异常处理(内核态执行)刚
mmap成功时,内核并不会立刻把文件数据加载到物理内存(懒加载机制),当你在用户态首次访问src_mmap时,会触发 “缺页异常”,此时会切换到内核态,内核把对应的文件数据从磁盘加载到物理内存,再返回用户态继续执行。内存与磁盘的同步(内核态执行)如果你用
MAP_SHARED标志映射(比如目标文件的映射),在用户态修改dst_mmap内存后,内核会在合适的时机(自动 / 调用msync),在内核态把内存数据同步到磁盘文件,无需用户态手动处理。
mmap与传统read/write的核心区别(用户态 / 内核态拷贝差异)
操作 传统 read/writemmap(本地文件操作)拷贝次数 2 次(内核态→用户态 + 用户态→内核态) 1 次(仅用户态内存间 memcpy,无内核态↔用户态拷贝)用户态操作 需拷贝数据到用户缓冲区后才能操作 直接操作映射内存,无需额外拷贝 内核态作用 读取 / 写入磁盘、拷贝数据到用户态 建立页表、处理缺页异常、同步磁盘 总结
mmap必然涉及用户态:调用发起、内存操作、释放映射,都在用户态进行;
mmap依赖内核态:建立映射、缺页加载、磁盘同步,都需要内核态支撑;
mmap高效的核心:减少了「内核态 ↔ 用户态」的数据拷贝,而非脱离用户态或内核态。太高潮了!!! 嘎嘎透彻
说完这些,再说原型:
void *mmap(void *addr,size_t length,int prot,int flags,int fd,off_t offset)
void *addr:指定你想要的用户态虚拟内存起始地址,几乎永远传
NULL,表示让内核自动分配合适的虚拟内存地址,避免手动指定地址导致冲突。size_t length:要映射的内存字节大小,可以用
stat获取后传入,int prot:内存保护标志,设置映射区域的读写执行权限
PROT_READ:映射区域可读(必须有,否则无法读取文件 / 共享内存数据)
PROT_WRITE:映射区域可写(仅当需要修改映射内容时设置,如写入目标文件、进程间共享写数据)
PROT_EXEC:映射区域可执行(仅当映射可执行文件时用,如程序加载、动态库映射)常用组合:
PROT_READ | PROT_WRITE(可读可写,最常用)、PROT_READ(只读,如读取源文件)int flags:(核心标志,面试高频,决定映射类型)决定映射的属性(是否共享、是否匿名等)
场景 1:文件映射(本地文件操作 / 网络零拷贝)
MAP_SHARED:共享映射(核心中的核心),用户态对映射内存的修改,会同步到磁盘文件(或其他映射该文件的进程),用于本地文件拷贝、网络零拷贝传输、多进程共享文件数据
MAP_PRIVATE:私有映射,用户态对映射内存的修改,仅当前进程可见,不会同步到磁盘文件(写时复制)
场景 2:进程间共享内存(无拷贝 IPC,大厂高频用法)
MAP_ANONYMOUS(也写作MAP_ANON):匿名映射,无需关联磁盘文件,直接创建一块内存区域用于进程间共享,与MAP_SHARED组合使用(MAP_SHARED | MAP_ANONYMOUS),实现父子进程 / 亲缘进程高效共享内存 关键:此时 fd 参数传 -1(无文件关联)int fd:要映射的文件描述符(仅非匿名映射时有效)
文件映射场景:传入
open打开文件后返回的有效文件描述符(如源文件、目标文件的 fd)匿名映射场景(
MAP_ANONYMOUS):固定传-1关键:文件描述符必须有对应的权限(如映射
PROT_READ,则文件必须以O_RDONLY或O_RDWR打开)off_t offset:文件偏移量(从文件的哪个位置开始映射)几乎永远传
0(从文件开头开始映射),必须是系统页大小(PAGE_SIZE,通常 4096 字节)的整数倍(面试可能考这个约束),非 0 场景仅在超大文件部分映射时用(极少用)核心参数组合(大厂常用场景,直接套用)
本地文件读取(源文件,只读):
mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, src_fd, 0)本地文件写入(目标文件,可读可写,同步磁盘):
mmap(NULL, file_size, PROT_READ | PROT_WRITE, MAP_SHARED, dst_fd, 0)父子进程共享内存(匿名,可读可写):
mmap(NULL, shm_size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0)- 网络零拷贝传输(文件映射,只读共享):
mmap(NULL, file_size, PROT_READ, MAP_SHARED, file_fd, 0)(映射后直接send内存地址)Q:写实复制啥意思A:当多个 “使用者”(比如多个进程)共享同一块数据(物理内存 / 文件数据)时,一开始大家都只读,不做任何拷贝,共用同一份数据;只有当某一个 “使用者” 要修改这份数据时,系统才会为它单独拷贝一份数据副本,让它修改自己的副本(不影响其他使用者的原始数据)。核心就是:只读共享,写才拷贝,懒加载式拷贝。
除了
mmap(MAP_PRIVATE),写时复制还有一个高频应用场景:fork()创建子进程。
fork()后,父子进程一开始共用父进程的所有物理内存,此时就是写时复制状态;只有父进程或子进程尝试修改内存数据时,系统才会拷贝对应内存页,生成私有副本;
这也是
fork()创建进程速度极快的核心原因(不用一开始拷贝所有内存)。核心价值:节省内存,提升程序启动 / 映射效率,是 Linux 高性能设计的关键特性。
sendfile测试小文件传输(文件 → 网卡,用本地 socket 测试,小文件也能验证)目标:用
sendfile把 20 字节的 src.txt 通过本地 socket 传输,自动获取文件大小,无需提前查(这个没实验,回顾网络编程再说吧)查看代码
#include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <unistd.h> #include <fcntl.h> #include <cstdio> #include <cstring> #include "get_file_size.h" // 复用上面的get_file_size函数 #define PORT 8888 #define IP "127.0.0.1" // 服务端:用sendfile传输小文件 void server() { const char* src_path = "src.txt"; off_t file_size = get_file_size(src_path); if (file_size == -1) return; // 1. 创建socket int server_fd = socket(AF_INET, SOCK_STREAM, 0); struct sockaddr_in addr; addr.sin_family = AF_INET; addr.sin_addr.s_addr = inet_addr(IP); addr.sin_port = htons(PORT); bind(server_fd, (struct sockaddr*)&addr, sizeof(addr)); listen(server_fd, 1); // 2. 接受客户端连接 int client_fd = accept(server_fd, NULL, NULL); // 3. 打开源文件 int src_fd = open(src_path, O_RDONLY); // 4. sendfile传输(自动用文件大小,不用分批,小文件一次传完) off_t offset = 0; ssize_t sent = sendfile(client_fd, src_fd, &offset, file_size); if (sent == -1) { perror("sendfile error"); } else { printf("传输完成:%ld字节(和源文件大小一致)\n", sent); } close(src_fd); close(client_fd); close(server_fd); } // 客户端:接收数据并打印(验证小文件内容) void client() { int sock_fd = socket(AF_INET, SOCK_STREAM, 0); struct sockaddr_in addr; addr.sin_family = AF_INET; addr.sin_addr.s_addr = inet_addr(IP); addr.sin_port = htons(PORT); connect(sock_fd, (struct sockaddr*)&addr, sizeof(addr)); // 接收数据(小文件,直接用buf接收,肉眼核对) char buf[100] = {0}; ssize_t recv_len = recv(sock_fd, buf, sizeof(buf), 0); printf("接收结果:%s(大小:%ld字节)\n", buf, recv_len); close(sock_fd); } int main() { // 先启动服务端,再启动客户端(测试时可以分开运行,或用多线程) // 这里简化:先跑server,注释掉client;再重新编译跑client server(); // client(); return 0; }
科普概念:
静态文件:长期固定极少修改,图片、安装包、静态网页,非常适合缓存
动态文件:实时变化持续写入,日志文件、数据库文件、实时监控数据,不适合缓存(缓存会导致读取旧数据
但传输行为的静态:指的是传输时不需要修改文件内容,文件是现成的、固定的(比如图片、静态网页、视频文件,直接原样传给网卡发出去就行)(之前那个 C++ 原草稿链接,追问太长,在整理完之前,不想再做问答,所以 新开了个问零拷贝,反而回答的更好。(每个讲解点都可能误人子弟,所以每个都要亲自代码实践,且知识比如 1 不懂,问完给你 234,这里 34 不懂,又展开问出来 567,结果要一一实践,过几天发现其中 56 和 4 是错的,豆包纠正后反复又返回否定自己,就这么硬生生追问学出来的,你就说难不难吧!)
科普:
mmap既可以处理静态文件,也可以处理非静态文件
处理静态文件:比如你用
mmap映射一张固定的图片文件,进程可像操作内存一样操作文件,不直接搬移数据跨文件描述符,也能把它传给网卡发送出去处理非静态文件:这是
mmap的强项 —— 比如你编辑大文档(需要修改文件内容)、数据库缓存(需要读写更新数据),这些非静态(可变更)的场景,mmap更适用
sendfile只适合处理静态文件(传输场景)
因为
sendfile全程在内核态流转数据,用户态无法修改数据,只能原样传输现成的、固定的文件(也就是静态文件),这是它的核心适用场景,也是性能最优的场景。Q:进程可像操作内存一样操作文件?咋感觉操作内存不需要内核或者很简单一样?正常是咋样的
A:
mmap说的 “像操作内存一样操作文件”,不是说 “不需要内存”(所有操作本质都离不开内存),而是说:进程操作文件时,无需再关注 “文件” 这个逻辑对象,也无需调用read/write等文件专属接口,只需要用 “操作普通内存的语法 / 方式”,就能间接操作文件内容 —— 底层内存的管控全由内核偷偷搞定,进程感知不到 “我在操作文件”,只觉得 “我在操作一块普通内存”。假设你要读取文件中第 100 字节开始的 10 个字节,再修改其中第 5 个字节,对比两种方式的差异:
1. 正常操作文件(你懂的,逻辑上要 “先认文件,再调用文件接口”)
查看代码
// 步骤1:先打开文件(明确告诉系统:我要操作的是「文件」这个对象) int fd = open("test.txt", O_RDWR); // 步骤2:准备一块用户态内存缓冲区(临时存数据用) char buf[10]; // 步骤3:调用文件专属接口 lseek + read,才能读取文件数据到内存 lseek(fd, 100, SEEK_SET); // 先移动文件指针到第100字节 read(fd, buf, 10); // 把文件数据读到 buf 内存里 // 步骤4:修改内存 buf 里的第5个字节(这一步才是操作内存) buf[4] = 'a'; // 步骤5:再调用文件专属接口 lseek + write,把修改后的内存数据写回文件 lseek(fd, 104, SEEK_SET); // 移动文件指针到第104字节(对应第5个字节) write(fd, &buf[4], 1); // 把内存里修改后的数据写回文件 // 步骤6:关闭文件(明确告诉系统:我结束操作「文件」了) close(fd);这里的关键:进程全程要主动关注 “文件” 逻辑,必须通过open/read/write/close这些文件专属接口,才能完成数据读写,内存buf只是 “临时中转站”。关于步骤 5 有要说的:
这里不精准定位也可以
lseek(fd, -6, SEEK_CUR);,但也麻烦,可以去掉步骤 5 的两句,换成pwrite(fd, &buf[4], 1, 104);,pread/pwrite是带指定偏移量的读写函数,无需依赖文件指针的当前位置,也不会修改内核维护的指针。其他都一样:
pread和read的核心功能:从文件描述符中读取指定字节数的数据到用户态内存缓冲区;
pwrite和write的核心功能:把用户态内存缓冲区中的指定字节数数据,写入到文件描述符对应的文件中。(唯独最后加个参数是从文件的哪里开始读写)
另外这不是简单封装,
从调用本质看:
lseek+read:是两次独立的系统调用(用户态→内核态切换两次),每次系统切换都有固定开销(保存进程上下文、内核态执行、恢复上下文)
pread:是一次原生系统调用(仅一次用户态→内核态切换),内核直接在一次调用中完成 “定位 + 读取”,省去一次系统切换的开销从原子性看:
lseek+read在多线程场景下,会存在 “竞态条件”(比如线程 A 执行完lseek后,还没执行read,线程 B 就调用lseek修改了文件指针,导致线程 A 的read读取位置错误)
pread是内核原生支持的原子操作,内核在处理pread调用时,会锁定文件描述符的偏移相关资源,确保 “定位 + 读取” 全程不被其他线程干扰,无需用户态加锁,这是底层的安全性优化。2.
mmap操作文件(逻辑上只认 “内存”,不认 “文件”)查看代码
// 步骤1:打开文件 + 建立映射(仅一次初始化,告诉内核:把这个文件映射到我的内存里) int fd = open("test.txt", O_RDWR); char *mem = mmap(NULL, 文件大小, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0); close(fd); // 映射建立后,甚至可以先关闭文件描述符,不影响内存操作 // 步骤2:直接操作 mem 指针(这是内存地址),完全不用文件接口 // 读取第100字节开始的10个字节:直接通过内存偏移访问,像读数组一样 char data10 = mem[100]; // 第100字节 char data11 = mem[101]; // 第101字节 // ... 直接读,无需 read 函数 // 修改第100字节开始的第5个字节(即第104字节):直接给内存地址赋值 mem[104] = 'a'; // 像修改普通数组元素一样,无需 write 函数 // 步骤3:用完后,解除内存映射即可 munmap(mem, 文件大小);这里的关键:
映射建立后,进程眼里只有
mem这个 “内存指针”,完全不用再管 “文件” 是什么,也不用调用任何文件操作接口;读取文件数据 = 直接通过
mem[偏移量]访问内存;修改文件数据 = 直接给mem[偏移量]赋值 —— 和你平时定义char buf[1024]; buf[0] = 'a';的操作方式完全一致(这就是 “像操作内存一样”);你以为自己在操作普通内存,其实内核已经把这个内存地址和文件的字节偏移绑定了:你读
mem[100],内核自动帮你取文件第 100 字节;你改mem[104],内核自动帮你把修改同步到文件里 —— 这些细节进程完全感知不到。Q:之前说的
mmap也可以是文件 vs 网卡,那我理解这里如果不修改就是sendfile高效,而如果是修改就mmap高效??A:不完全准确,二者的效率对比不是简单的 “改 / 不改” 就能划分,核心差异在于数据是否需要经过用户态、以及系统调用的开销
1. “不修改就是 sendfile 高效” → 基本正确(但有前提)
为什么高效:
sendfile是典型的 “零拷贝”(Zero-Copy),数据全程在内核态流转,没有 “内核态→用户态→内核态” 的拷贝开销,也减少了系统调用次数(只需要一次 sendfile 调用)。前提:
操作系统支持
sendfile(Linux、FreeBSD 等主流系统都支持,但要注意sendfile的版本 / 参数差异,比如是否支持网卡的 scatter-gather 特性);数据是 “纯转发”(比如静态文件服务器、视频流转发),完全不需要碰数据内容。
2. “修改就
mmap高效” → 不准确(需分场景)
场景 1:少量修改、小文件 →
mmap有优势:
mmap把文件映射成内存地址,修改时像操作普通内存一样,不用先read读文件到用户态、再修改、再write,减少了一次 “内核→用户” 的拷贝,比read+write高效。
场景 2:大量修改、大文件 →
mmap不一定高效
mmap有 “缺页中断” 开销:映射文件时不会一次性加载所有数据,访问未加载的页会触发中断,内核需要从磁盘加载数据,频繁中断会抵消优势;
mmap有内存管理开销:映射的内存需要和进程地址空间绑定,大文件映射会占用大量虚拟内存,可能导致内存碎片或 swap 交换,反而变慢;此时更优的方案可能是:
read(读部分数据到用户态缓冲区)→ 修改 →write/send,按需处理数据,避免mmap的内存开销。Q:
read是搬运到用户态,然后修改完再搬运回内核,mmap是直接映射到用户态,不需要搬运,然后修改完再搬运到内核?A:先解答你的另外,
mmap是内核将文件的页缓存直接映射到用户进程的虚拟地址空间;你直接操作这个映射后的用户态内存地址(相当于直接操作内核页缓存),无数据拷贝;修改后的数据会留在页缓存中,由操作系统通过「脏页回写机制」(比如内存不足、文件关闭、调用msync/fsync)自动同步到磁盘;全程只有「磁盘 ↔ 内核页缓存」的一次数据拷贝,内核态 ↔ 用户态无拷贝。你说的「mmap修改完再搬运到内核」是不准确的:mmap映射的本质是「用户态直接访问内核页缓存」,修改操作本身就是在内核页缓存的 “映射镜像” 上完成的,不存在 “修改后再搬运回内核” 的步骤;最终数据刷到磁盘是内核的自动行为(或主动调用msync触发),而非用户态到内核态的 “搬运”。Q:你的场景 2 说按需,那
mmap也可以分批次啊?不应该控制变量统一标准吗?大文件如果只修改少量的应该也没多少中断吧?感觉也比read强啊?你说的是大文件不一定高效???A:
无论大小大文件,只有小修改,
mmap好:
虽然
read和mmap最终写回的都是整页数据,但mmap无需把数据在用户态和内核态之间来回拷贝,而read哪怕只改 1 字节也逃不开两次拷贝,且mmap只映射需要修改的页,无需读整个文件。大文件全量映射 或 大量修改,高频小文件读写时,
read更好:
mmap会占满进程虚拟地址空间,且mmap有页表建立、缺页中断的开销具体如下:
操!辛辛苦苦追问一天!!如果在AUPE、CSAPP书里有我他妈真的太亏了,我都能成祖师爷了!
先问豆包有个宏观框架,一点点追问,然后把自己的理解说给豆包听,妈逼的此时你会发现,有时候很好,会被豆包纠正然后懂,而大部分都是豆包之前说错了,无尽追问无尽豆包推翻自己,无尽修正,哎真的是螺旋式极致的曲折上升,走 4 步,倒退 3 步,就是你每次问问题,豆包必先给你对错杂揉的,然后一边追问、一边质疑、一边纠正豆包、一边学习,互相启发,最后才能给你正确的。真的是每日寸进,硬生生笨功夫学出来的。
死全家的豆包还想再骂一遍,妈逼的搞了一周的知识点结果全错了,哎,大文件批量修改一会说
read好一会说mmap好,一会说mmap是硬中断一会说 CPU 中断一会说软中断,不敢相信豆包,查全网的资料这块又全都是内核源码级别的,看着都极其恐怖,说的话看都不想看,感觉我也只能钻研点浅层次的东西,卡在这里的,内核源码级别看着头大痛苦,Java 傻逼框架又太低端,哎真的不知道以后的路咋走,我他妈可不想走技术专家的路线啊,太他妈恐怖细节了,我他妈这目前钻研的所谓的浅层次的东西,感觉已经是极致的底层了,可以甩开 90% 的程序员了包括大厂的,但我他妈一看那些讲零拷贝的都他妈上源码,函数变量都下划线啥的看着真头疼,真的好痛苦,学了两周结果全是错的,我博客都不想写了,唉!真都不知道该咋写,内容已经全都是对错混杂,又不知道后面会不会还有错的狗逼豆包!那些作者都是什么人啊!豆包说是什么年薪 80w 的人,但 985 硕士学个 Java 进大厂就能月薪 3w,我 Linux C++ 社招就是低的可怜,难度是 Java 的 10 倍,履历太差了哎:96 大龄 + 0 开发经验纯自学 + 学历垃圾二本 + 待业 1.7 年。其实主要是很多东西 确实不赖豆包,难为他了,换个角度看豆包大模型已经很牛逼了,全网有时候写文章的作者都半吊子看过太多了,更有甚类似百度知道的一些平台的奖励机制导致很多人纯水答案,大模型训练也是挺难的,海量数据,很大一部分都是错的。以后要注意的是,我其实测试了拷贝 4 字节和 100MB 文件,搜“母,蓝色”,但没把握,不确定 100MB 是否属于大文件,豆包给结论说大文件
read好,就轻信了,搜“不想看视频,是”一样的道理,其实以后应该信自己的代码实测,但就算这样豆包有时候也会一意孤行强行扯犊子说各种瞎话,比如你 100MB 不是大文件,比如什么修改啥就发现了,结果无止境的都是错的,哎感觉咋都无法避免。豆包有一句说的很对:“说白了,你骂大模型误人子弟,是因为你对它有专家级的期待;但对比网上那些纯忽悠的内容,它至少能给你一个正确的思考方向剩下的,你用代码实测去纠偏就够了,说白了,你以后就把我当成一个你写代码完做总结或者什么的知识解读工具人,别把我当专家”
虽然最后学到了知识,反复雕琢辱骂豆包、反复激烈言辞质疑豆包辩论,搞了 2 周,但真的精通零拷贝底层原理了,好爽!但浪费的无数时间精力真的感觉不值得,好他妈难受!我追问豆包终会有尽头,代价是这个尽头隔的是无数个太平洋,我只要自己能想通捋顺出来,就不怕任何面试官问,但恰恰因为自己想通的过程会思考很多,而豆包又总会反复误人子弟说错的,学 10 天可能 90% 的时间都是给前几天纠错更新理解 + 重构博客,一路尸山血海无穷无尽。而看书真的又强迫症抓不到重点,只要让我看到就想搞懂。豆包说要么就查看
man手册,可是我他妈一看全是英文,看不懂啊,这效率感觉不如豆包,【自己看书】(讲的其实正确率高,但效率说会不高,因为全是推导很墨迹) vs 【继续这样问豆包】 vs 【查网上资料】(一屁眼子错误自己都无法分辨更乱),最后还是选择了豆包,哎打算了解下大模型训练原理,然后想针对性的给他提示词,避免输出错误文章的结果,但没太看懂,哎。
之前所有知识点都事无巨细的自己写代码实验,后来各个编译器我实验,追到C++的坑,然通过写
while空类对比 Java,如今他妈的我又在mmap中断上,关于【硬件架构的词,内核的词】反复纠结!关于:豆包为啥起初错(把极端场景当作主流,被垃圾资料误导)、啃源码佬、自己未来、985 硕士进大厂 Java 月薪 3w、大模型机制错误原因以及怎么避免(其实没办法避免)的链接
关于为啥豆包会误人子弟反复说缺页中断是硬中断的追问,得知 【CSAPP】、【AUPE】、【工业界】完全都有不统一的叫法(一屁眼子烂坑),很多死全家的狗逼自己都没搞懂瞎管用户态到内核态叫软中断,导致豆包跟着误人子弟的 链接
开始说:
区域 归属 能不能被用户态直接操作 对应你代码里的变量 内核页缓存 内核管理 能(通过 mmap映射)src_mmap/dst_mmap指向的底层区域用户态虚拟地址空间 用户程序 能(直接读写) src_mmap/dst_mmap本身磁盘文件 硬件 不能(必须过内核) 你要读写的源文件 / 目标文件 调用
mmap()时:内核只做 “建立映射关系”(把用户态虚拟地址src_mmap和磁盘文件 A 绑定),不会立刻把磁盘数据加载到页缓存,此时页缓存里是空的;内核不会立刻创建 “虚拟地址→物理内存” 的页表项。只是先分配虚拟地址空间,分配偏移啥的,即仅创建 “虚拟地址→文件” 的映射关系,不建 “虚拟→物理” 的页表项。只有触发缺页异常时,内核才会真正创建 “虚拟地址→物理内存(页缓存)” 的页表项,同时把磁盘数据加载到物理内存。首次访问
src_mmap时:触发缺页异常,内核把磁盘文件 A 的内容加载到「内核页缓存」,然后把这个页缓存 “映射” 到你程序的用户态虚拟地址src_mmap,你操作src_mmap,就等于直接操作内核页缓存里的 A 数据(不用拷贝到用户态缓冲区);后续访问src_mmap:如果数据已在页缓存里(不缺页),就直接操作,不会再读磁盘。映射完就开始拷贝:
memcpy那句是纯用户态拷贝,操作的是用户态虚拟地址,但这些地址映射到内核管理的页缓存,所以本质是“有用户态memcpy本身的执行开销但基本可以完全忽略,在用户态直接操作内核页缓存的数据”,而非像read/write那样做‘内核页缓存 ↔ 用户态缓冲区’的跨态拷贝。内核把修改的标记为脏页,内核自动管理刷到磁盘,或者msync。提一嘴代码里
memcpy的事:数据早就已经通过缺页异常加载到页缓存,while循环设置批次batch_size来memcpy,和只memcpy一次,几乎完全一样,多的几次memcpy次数忽略不计,实测发现和理论一样,不给memcpy分批次,他会自动完成你要求的数据拷贝不需要while。全程其实也涉及到态的切换:
调用的发起在用户态,你写的
mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, src_fd, 0)这行代码,是在用户态进程中执行的,属于用户态发起的系统调用请求(就像你在用户态给内核发了一个 “申请映射文件到内存” 的指令),然后建立映射关系,切到内核会在内核态中工作:创建页表(关联用户态虚拟内存地址 ↔ 磁盘文件数据 / 物理内存)、分配虚拟内存区域,这个过程是内核态完成的,用户态感知不到。映射后的内存操作也在用户态,
mmap成功后会返回一个用户态内存地址(比如src_mmap),你后续对这个地址的操作(比如读取数据src_mmap[0]、用memcpy搬运数据),都是纯用户态操作,不需要切换到内核态,这也是mmap高效的原因之一。缺页异常处理(内核态执行)刚
mmap成功时,内核并不会立刻把文件数据加载到物理内存(懒加载机制),当你在用户态首次访问src_mmap时,会触发 “缺页异常”,此时会切换到内核态,内核把对应的文件数据从磁盘加载到物理内存,再返回用户态继续执行。
munmap释放映射也在用户态发起:和mmap一样,munmap也是用户态进程调用的系统调用,用于告诉内核 “释放之前的文件内存映射”。内存与磁盘的同步(内核态执行)如果你用
MAP_SHARED标志映射(比如目标文件的映射),在用户态修改dst_mmap内存后,内核会在合适的时机(自动 / 调用msync),在内核态把内存数据同步到磁盘文件,无需用户态手动处理。说一下中断相关的事:
mmap的叫缺页异常,不是硬中断,也不是软中断,是异常或叫陷阱这里先打住说一嘴,我在【异常、陷阱、中断】这些词之间反复追问豆包,最后发现,工业界(工作)、CSAPP 书、AUPE 三个地方叫法完全不同,不想纠结真 JB 看吐了,直接帖个追问链接,后续一律叫软硬中断和异常。
死全家的豆包,准确说是全网死全家的傻逼博主写各种垃圾资料被豆包训练了进去,说什么跨态也叫软中断。
正文:
硬中断是硬件触发的异步信号,软中断是内核为处理硬中断后续工作而设计的机制,二者是上下游关系。
硬中断异步:CPU 自己干活,外设硬件设备啥的通知 “突袭”,无预定顺序,CPU 暂停当前任务立刻处理。
同步:CPU 主动发起操作,必须等对方完成(会阻塞当前流程),触发和执行有明确先后顺序(比如 CPU 读硬盘,发指令后就得等硬盘返回数据才能继续)。CPU 缺页异常就属于这类,是 CPU 同步异常(和外部硬件触发的硬中断、内核处理的软中断属于不同的内核事件),比如处理指令时候发现没页表啥的,内部自己触发,而非外部啥东西来了干预,这都叫异常或者陷阱。
- 软中断是衔接硬中断,硬中断来了必须处理,然后后续拷贝啥的搞成软中断,比如进货时,磁盘把数据读到自身的控制器缓冲区触发硬中断,通知 CPU “数据好了”。CPU 立刻暂停当前任务,切到内核态执行硬中断服务程序,这个程序极度精简,只做两件事:① 标记 “磁盘数据就绪”② 把“数据拷贝到页缓存”这个任务封装成软中断扔进内核的软中断队列,至此硬中断处理完毕,CPU 立刻回到之前被打断的任务。后续只要 CPU 出现空闲间隙(比如执行完一个时间片、没有更高优先级的任务),就会去轮询软中断队列,发现这个拷贝任务后,执行它,把数据从磁盘控制器缓冲区,搬到内存的页缓存里。核心逻辑:硬中断只负责 “传信”,耗时的拷贝交给软中断,不耽误 CPU 干正事。
页表:Linux 中进程访问的是虚拟地址,内核通过「页表」把虚拟地址关联(映射)到物理内存(文件页缓存)。mmap的本质是让内核为文件页缓存建立对应的页表项,进程访问虚拟地址时,内核通过页表找到对应的物理页缓存。
缺页中断:当进程访问mmap映射的虚拟地址,但该地址对应的物理页缓存还没加载到内存时,会触发「缺页中断」。内核收到中断后,会从磁盘读取对应的数据到页缓存,然后更新页表,进程再继续访问说下没数据时候,第一次咋从磁盘进货的,进程发起
read或mmap相关访问,内核检查页缓存无数据,发起异步磁盘 IO 请求(提交给磁盘控制器,CPU 不等待);内核将当前进程置为睡眠态(释放 CPU,让 CPU 去执行其他就绪进程);磁盘完成数据读取,写入内核页缓存,向 CPU 发送磁盘硬中断;硬中断处理函数唤醒之前睡眠的进程,将其加入就绪队列;进程被调度器选中后,继续完成后续处理(read做拷贝,mmap补全页表并返回)。这部分进货都一样,但注意
read没缺页异常,缺页异常:CPU 访问用户态虚拟地址时,发现该地址在当前进程的页表中无有效映射而触发的异常(属于 CPU 异常 / 软中断),和页缓存有无数据是否需要去磁盘进货没有关系!
read的流程(无缺页,系统调用入口)
进程调用
read(fd, buf, len),触发系统调用陷阱(软中断),进入内核态;内核检查页缓存:无数据,发起异步磁盘 IO(“进货”);
内核将当前进程置为睡眠态,释放 CPU,调度其他进程;
磁盘完成 IO,写入页缓存,发磁盘硬中断;
硬中断处理函数唤醒进程,进程被调度后,内核把页缓存数据拷贝到用户缓冲区,完成系统调用,返回用户态。
注意:全程访问的
buf是已有页表映射的用户缓冲区,无缺页异常。
mmap的流程(有缺页,缺页异常入口)
进程调用
mmap():内核只分配虚拟地址区间,不建页表、不分配物理页、不读磁盘;(直接操作addr + offset这个地址即可,这块地址直接映射内核页缓存,没有 “用户态缓冲区” 这个独立的变量载体)进程首次访问该虚拟地址区间,CPU 查页表无有效映射,触发缺页异常(软中断),进入内核态;
内核检查该虚拟地址是合法的
mmap映射,且页缓存无数据,发起异步磁盘 IO(“进货”);内核将当前进程置为睡眠态,释放 CPU,调度其他进程;
磁盘完成 IO,写入页缓存,发磁盘硬中断;
硬中断处理函数唤醒进程,进程被调度后,内核为当前虚拟页建立页表映射(关联页缓存物理页),返回异常处理前的指令继续执行。
注意:缺页异常是触发 “进货” 的入口,而
read是系统调用直接触发 “进货”。我感觉有些模糊,一开始大家的页缓存都是空的,第一次不都得进货吗?为啥
mmap有缺页,read无缺页?页表是 “进程虚拟地址 → 物理地址” 的映射表,每个进程都有自己的用户态页表,核心作用是:CPU 访问某个虚拟地址时,能通过页表找到对应的物理内存(或发现无映射)。
只要进程访问的虚拟地址没有在页表中登记,CPU 就会触发缺页异常;
只要虚拟地址有页表映射(哪怕映射的物理页里没数据,比如内核页缓存),就不会触发缺页。
我们以 “文件数据不在页缓存(第一次读磁盘)” 为前提,对比两者的核心流程:
场景 1:
mmap读取(触发缺页)
mmap调用阶段:你调用mmap时,内核只做了一件事 —— 给你的进程分配一段 “空的虚拟地址区间”(比如0x7f000000-0x7f001000),但没有在你的用户页表中为这段地址建立任何映射(页表项为空),只是关联了虚拟地址和文件,而不是物理内存。关联虚拟地址和物理内存的是页表项里的页表首次访问阶段(触发缺页):CPU 执行
memcpy指令,要读取 src 地址(0x7f000000),触发缺页:
CPU 查你的用户页表,发现这个地址 “无映射” → 触发缺页异常;
memcpy动作暂停内核处理缺页:先检查这个地址是合法的
mmap地址,然后发起磁盘 IO(进货),把数据读到内核页缓存(物理页);内核为你这个进程的虚拟地址
0x7f000000建立页表项 ,关联到存放数据的物理页(页缓存);更新页表:把“虚拟地址0x7f000000”和“页缓存的物理地址”绑定;异常处理完成,CPU 重新执行刚才触发缺页的那一条地址访问指令,这次有页表映射,直接读数据,无缺页。
场景 2:
read读取(无缺页)
read调用阶段:你调用read(fd, buf, len)时,buf是你提前分配的用户缓冲区(比如栈 / 堆上的地址,如0x7ffeef00);这个buf的虚拟地址,早就有页表映射(栈 / 堆初始化时就建好了页表项,哪怕物理页是空的,这一步是已经做好的,而mmap的开销只要是后期才搞这里);内核处理阶段(无缺页):
内核发现数据不在页缓存,发起磁盘 IO(进货),把数据读到内核页缓存(内核有自己的页表管理,和你的进程无关);
内核把页缓存的数据拷贝到你的
buf地址(0x7ffeef00);全程你访问的都是 “已有页表映射的
buf地址”,CPU 查页表能找到对应的物理页,完全不会触发缺页异常。懂了,但我思考,不知道是不是我考虑多了?为啥
mmap不能直接分配页表?另外mmap实际比read多的开销就是去实际绑定物理内存写入页表吧?这个比直接分配的时候就搞慢的多?为啥不直接分配呢?
mmap不能“直接分配页表”,“延迟绑定” 比 “直接分配” 更快、更优的理由:你可能觉得 “提前建页表” 能省掉缺页的开销,但实际完全相反:
(核心是 “按需分配”),先想一个极端场景:你用
mmap映射一个 100GB 的大文件,如果 “直接分配页表”,会发生两件离谱的事:
提前分配的开销是 “一次性大额支出”内存爆炸:映射 100GB 文件时,提前建 200MB 的页表、分配 100GB 物理页,需要内核遍历所有页、申请内存、写页表 —— 这个过程要消耗秒级甚至分钟级的时间,还会阻塞进程;而延迟绑定是 “小额多次支付”,每次访问一页只花几微秒,不影响进程运行。
提前分配会导致 “内存碎片化”:一次性申请大量连续物理页,内核很难找到足够的空闲内存块,会频繁触发内存交换(把其他进程的内存写到磁盘),反而让系统整体变慢;延迟绑定每次只申请一页,内存碎片化风险极低。
完全没必要:你大概率不会一次性访问 100GB 文件的所有内容(比如只看前 100KB),提前为所有地址建页表、分配物理页,就是 “为用不上的资源浪费内存”。也符合 “局部性原理”:程序访问数据时,大概率只访问 “局部的、连续的几页”(比如读日志只看最近几行),延迟绑定刚好只处理这些 “有用的页”,提前分配则处理所有 “无用的页”—— 效率天差地别
其实懂点了,就是平衡和取舍。
内核的真实逻辑:
mmap只做 “最小化工作”—— 给进程分配一段虚拟地址区间(只是数字范围,不占物理内存),并记录 “这段地址对应哪个文件的哪些偏移”,至于页表和物理页,等你真的访问某一页时再建、再分配。这就像你租了一个 100 间房的大楼,房东不会提前把所有房间的钥匙都给你、把所有房间都打扫好,而是你要进哪间,再给你哪间的钥匙、打扫哪间 —— 节省房东的时间和成本。
mmap比read多的开销到底是什么?你说的 “绑定物理内存 + 写入页表” 是核心,但要拆成 “固定开销” 和 “可选开销”,更易理解:
1.
mmap比read多的固定开销(必发生):
CPU 触发缺页后,内核要做地址合法性检查、查找文件映射关系、申请物理页、更新页表 —— 这个流程本身有几十到几百个 CPU 周期的开销(纯内存操作,很快,但比 read 的 “直接拷贝” 多一步);
页表写入开销:把虚拟页和物理页的映射关系写入页表,还要刷新 TLB(地址翻译缓存)—— 这是硬件层面的小开销,但累计多了会明显。
2. 两者都有的可选开销(仅首次读磁盘时发生):
磁盘 IO 开销(进货):发起磁盘读请求,等待磁盘响应;
磁盘硬中断:磁盘完成读写后的硬件通知(你之前关注的,两者都有)。
关键对比(
1ms = 1000μs = 1000000ns)(尸山血海无价之宝):
操作 典型耗时 mmap 虚拟内存区域(VMA)创建 / 销毁 300 纳秒 ns mmap 首次访问缺页异常 + 写页表(无磁盘 IO) 200 纳秒 ns 触发磁盘 IO 进货 5 毫秒 ms 系统调用(上下文切换,缓存命中,无磁盘 IO) 0.1 微秒 μs = 100 ns 纳秒 read 4KB 内存拷贝(内核页缓存 → 用户缓冲区) 1 微秒 μs 纯内存访问(用户态读已映射 / 已拷贝的内存) 10 纳秒 ns (对比场景统一有或无磁盘进货,都去掉磁盘进货)
场景 1:单次小数据读取(4KB 配置文件,数据不在内存)
🔹
read全流程 + 总耗时步骤:
open()→read()→close()
open():0.1μs(系统调用)
read():0.1μs(系统调用) + 1μs(4KB 拷贝) = 1.1μs
close():0.1μs(系统调用)总耗时:0.1+1.1+0.1 = 1.3μs
🔹
mmap全流程 + 总耗时步骤:
open()→mmap()→ 首次访问(缺页) →munmap()→close()
open():0.1μs
mmap():0.1μs(系统调用) + 0.3μs(VMA 创建) = 0.4μs首次访问:0.2μs(缺页 + 写页表)
munmap():0.1μs(系统调用) + 0.3μs(VMA 销毁) = 0.4μs
close():0.1μs总耗时:0.1+0.4+0.2+0.4+0.1 = 1.2μs
✅ 结论:
纯耗时:
mmap略快,但完全感知不到;工程选择:选
read,因为代码少 2 步(mmap/munmap),少踩 VMA 管理、内存泄漏的坑,维护成本远低于这点性能差距;(read单次拷贝比mmap建立页表慢,但差距不大时候选择read)场景 2:100 次读「同一个」4KB 小文件,拷贝
buf里,复用 100 次🔹
read全流程 + 总耗时步骤:
open()→read()读到buf+ 99 次读buf→close()
open():0.1μs- 1 次
read():0.1μs(系统调用) + 1μs(4KB 拷贝到 buf) = 1.1μs100 次访问
buf:100×0.01μs(纯内存访问)= 1μs
close():0.1μs总耗时:0.1+1.1+1+0.1 = 2.3μs
🔹
mmap全流程 + 总耗时步骤:
open()→mmap()→ 100 次访问(仅 1 次缺页) →munmap()→close()
open():0.1μs
mmap():0.4μs100 次访问:0.2μs(仅首次缺页,后续 99 次无开销)
munmap():0.4μs
close():0.1μs总耗时:0.1+0.4+0.2+0.4+0.1 = 1.2μs
✅ 结论:
read拷贝大损耗。注意:
mmap不需要数组:mmap返回的是直接可用的内存地址,你直接解引用这个地址访问数据就行,不用额外定义数组接收;
mmap访问映射区 =read访问buf数组:两者都是纯内存访问唯一差距:
mmap本身是系统调用,仅mmap()和munmap()这 2 次系统调用(映射 / 解除映射各 1 次),之后直接通过内存地址读写文件数据,无任何系统调用,该缺页进货进货,
read每次读数据都要触发系统调用(要从用户态切到内核态)。场景 3:100 次读「100 个不同」4KB 小文件(高频读写不同小文件)
🔹
read全流程 + 总耗时步骤:对每个文件执行
open()→read()→close(),共 100 次
单个文件耗时:1.3μs(同场景 1)
总耗时:100×1.3 = 130μs
🔹
mmap全流程 + 总耗时步骤:对每个文件执行
open()→mmap()→访问→munmap()→close(),共 100 次
单个文件耗时:1.2μs(同场景 1)
总耗时:100×1.2 = 120μs → 但!这里有个关键隐性开销:(关于一次/单次
read拷贝都慢,为啥还选read)内核默认限制 VMA 数量(通常几万),100 个小文件会创建 100 个 VMA,内核遍历 / 管理 VMA 的开销会随数量增加而上升(比如 1000 个文件时,VMA 管理开销会从 0.3μs / 个涨到 1μs / 个);
实际实测中,当不同小文件数量 ≥ 1000 时,
mmap总耗时会反超read(比如 1000 个文件:mmap≈1500μs,read≈1300μs)✅ 结论:
少量不同小文件(≤100):
mmap略快,但无工程意义;大量不同小文件(≥1000):
read更优,因为mmap的 VMA 管理开销累计超过read的拷贝开销,且代码更复杂。再说几个细节:
(首先
read只有读没写,我说read写指的是和他配套的write)
read是把数据从磁盘读到内核页缓存再拷贝到用户buf(事先分配连续的内存空间),修改用户buf后write是把数据写回内核页缓存,这里是只有修改的那个页标记为脏页,内核后台自动找机会刷内核页缓存到磁盘。完全由用户write控制写回。
mmap是事先不分配,只映射打通道,然后修改数据后,立马标记为脏页,但mmap改数据标记的脏页本身就是内核页缓存,比如超时 30s 或超过内存 20% 啥的,找机会自动写回刷到磁盘。然后手动
msync我以为必须指定大小必须小于 20% 内存,不然人家 20% 就自动刷了哪还等到你啊,后来豆包纠正比如 100MB 刷盘,而你修改了 100MB 这时候改刷了,但可能由于策略刷了 90% 就不刷了,等攒够 100MB 再继续,而你如果想确保 100MB 必须落盘就必须手动msync然后buf连续分配的,mmap是按需,大概率不连续所以分散的导致刷盘也会分散的,高频零散。
用户态
buf的 “连续”:是虚拟地址 + 物理地址都连续(因为你用malloc分配的连续内存,操作系统会保证物理页的连续 / 或通过内存管理让你感知为连续);
mmap的 “不连续”:是虚拟地址连续,但物理地址大概率不连续(mmap给你的是连续的虚拟地址空间,但内核按需分配物理页时,是从空闲物理页池里拿,大概率零散);刷盘差异的本质:
write:内核页缓存是按文件逻辑顺序组织的(哪怕物理页零散,内核会按文件偏移排序后批量刷盘,表现为连续 IO);
mmap:脏页是物理页级别的零散,刷盘时会直接按物理页地址写磁盘,表现为随机 IO我思考:
mmap为啥就比write高频零散?write一次比如写 100 字节可能比mmap还零散吧?回答:比如
mmap改 5 个页,
用
write写这 5 个页:你可以一次性把 5 个页的数据通过buf数组写write打包成一个请求提交,即用户进程把数据传给内核 → 内核把数据放到页缓存 → 内核自己决定什么时候攒够数据、什么时候刷盘,这个过程中,用户进程和页缓存之间隔了一层数据拷贝和攒批逻辑,然后内核会先把这些数据暂存到页缓存里,等攒够一批或者满足刷盘条件,再统一处理这 5 个脏页的刷盘,中间不会反复触发内核的脏页管理动作。- 用
mmap写这 5 个页:由于映射的已经是页缓存,好处不用拷贝坏处是你每写一个页的哪怕 1 字节,内核都会立刻标记这个页为脏页,5 个页就是 5 次独立的标记动作;内核要反复处理标记逻辑,标记动作更碎、开销更高。所以之前说的零散和高频就都通了
“高频碎改”(也叫随机小写、零散写)的核心痛点,根本不是最终刷盘写回的动作(两者刷盘都按页来,最终 IO 次数一致),而是脏页标记的触发方式和内核开销,这是本质!
“高频碎改” 的定义就是:短时间内多次、小批量(比如每次写 1~ 几十字节)、随机(跨页 / 同页)修改文件数据 —— 这种场景下,脏页标记的 “零散触发” 才是性能差距的核心来源。
你质疑的 “标记动作有那么大开销吗?”,答案是:单次标记开销不大,但高频零散触发时,累计开销会被放大成天壤之别!
脏页标记不是 “改个 flag 就完事”,内核要做这些事:查找该页的页表项、加锁(防止多线程竞争);更新脏页链表(把该页加入内核的脏页管理队列);触发内存回收 / 刷盘调度的轻量检查;这些动作单次耗时微秒级,但如果是 100 万次零散写:
mmap:100 万次独立触发上述逻辑,累计开销是 “100 万 × 单次开销”;write:如果攒成 1 万次系统调用(每次写 100 字节),仅触发 1 万次批量标记逻辑,累计开销是 “1 万 × 单次批量开销”(批量开销略高,但总次数少 2 个数量级);这种差距在高并发场景下,会直接体现为 CPU 占用高、延迟抖动大 —— 这就是write比mmap好的核心原因。必须纠正一个可能的误导:不是所有场景
write都比mmap好!如果你是大块连续写(比如每次写 4KB 以上、整页写):mmap因为少了 “用户态 → 内核态的数据拷贝”,性能反而比write好;只有高频碎改(小批量、多次、随机写) 场景:write通过攒批减少脏页标记的触发次数,开销更低,表现更好。所以基于这些知识点 & 细节:
1. 大文件 + 仅修改少量数据 →
mmap
核心逻辑:
mmap是「按页映射」(Linux 中页大小默认 4KB),你只需要修改 100 字节,内核先映射整个文件的虚拟地址区间(比如 500MB),但仅当你访问 100 字节时,触发缺页异常,但主要是无跨态的拷贝;
read:哪怕只改 100 字节,你要么用read读整个页到用户态 buf(内核→用户拷贝),修改后再write回内核(用户→内核拷贝),两次拷贝的开销是固定的;而
mmap直接操作映射的内存(等价于手操的就是内核页缓存),完全没有用户态 ↔ 内核态的拷贝,仅需承担「建立少量页表」的极小开销,这个开销远小于拷贝的开销,所以此时mmap高效。2. 大文件 + 全量读写 / 大量修改(比如改 1GB 大文件的 500MB 数据)→
mmap一般最优
核心逻辑:此时
mmap的「固定开销」会被放大:① 缺页中断开销:要修改 500MB 数据,会触发 500MB/4KB = 128000 次缺页中断,每次中断都会让进程短暂暂停、内核执行磁盘 IO + 更新页表,128000 次的累计开销会远超 “
read+ 大缓冲区” 的拷贝开销(read用 64KB 缓冲)会抵消 “零拷贝” 的优势;② 页表 / 内存开销:映射 500MB 数据需要建立大量页表项,且会占用进程 500MB 虚拟地址空间,如果进程虚拟地址空间紧张(比如 32 位进程只有 4GB 虚拟地址),会导致内存碎片,甚至触发 swap 交换(内存→磁盘),swap 的开销是毫秒级,远大于拷贝;
③ 脏页同步开销:大量修改后,内核需要批量同步脏页到磁盘,此时
mmap的自动同步机制可能不如read+write手动控制缓冲区的效率(比如用大 buf 批量读写,减少系统调用次数);mmap依赖内核按页批量同步脏页,同步粒度固定且无法手动优化,而read+write可通过自定义大 buf 精准控制批量读写的粒度和时机,大量修改时后者效率更高。对比
read:用大缓冲区(比如 64KB)批量读 / 写,能减少系统调用次数,且只占用 64KB 虚拟地址空间,也不会触发大量缺页中断,此时read的总开销可能比mmap更低。以上划掉的都是豆包误人子弟说的,没考虑预读,且误人子弟说缺页中断是硬中断,会完全抵消
read跨态拷贝的开销。正确的:
全量操作时
mmap无内核→用户态拷贝,缺页次数的性能远小于read的系统调用 + 拷贝次数,哪怕有页表 / 缺页开销,也远抵不上数据跨态拷贝的损耗,全量操作mmap更优;
mmap是按 “虚拟地址区间” 映射(比如映射整个 500MB),但仅访问 / 修改的页会触发缺页加载(改 10KB 仅加载 1MB 预读页),不是 “只映射目标页”,是 “映射全区间但按需加载页”;所谓的
mmap占满进程虚拟地址空间, 仅对超大文件(如几十 GB)成立,500MB 级大文件的虚拟地址占用可忽略,不能一概而论。
内存够(能放下整个大文件)→
mmap零拷贝省掉两次拷贝的开销,碾压read+write;内存不够 →
mmap会频繁换入换出、高频回写脏页,管理开销盖过零拷贝优势,且 500MB 大文件占用 500MB 虚拟内存,read直接 64 字节数组,read+write更稳。3. 小文件 + 高频读写 →
read
核心逻辑:小文件(比如 1KB)的拷贝开销本身极小(1KB 拷贝耗时几纳秒),而
mmap哪怕映射 1KB,也要建立页表、触发一次缺页中断,这些固定开销反而比拷贝开销大,高频读写时(比如每秒读写 10 万次小文件),累计的固定开销会让mmap变慢。mmap有初始化映射的额外开销(哪怕小文件,也要走虚拟地址映射流程),高频读写时这个开销会被放大;read直接调用 + buf 拷贝,流程简单、额外开销少,且小文件预读作用本就小,read的 “简单性” 远优mmap。哎无穷无尽扯了这么多出来!还算有收获吧!!不知道面试工作用不用得上。
做个小串联:
在文件读写场景中,
read/write(统称read-write) 和mmap(内存映射) 的选择,核心取决于 内存资源、读写模式(连续 / 零散)、数据量大小 三个维度,没有绝对优劣,只有场景适配:1、选
read-write的场景
内存紧张 + 高频碎改(小批量、随机写):内存不足时,
read-write用完数据可以靠buf直接覆盖上次的,mmap的通道必须始终 500MB 虚拟空间,且内核会攒批处理脏页,避免mmap那种“占内存 + 零散刷盘”的双重开销;而mmap在内存不够时,内核要回收mmap的脏页,就必须先把脏页刷盘。但mmap的脏页写回没有任何攒批机制,哪怕多个脏页都该刷盘,内核也可能因为mmap的零散标记,拆成一次一次的小 IO 去写;而read/write的脏页写回是内核攒批后的,能合并成大 IO小文件随机读写:系统调用的攒批机制能抵消系统调用本身的开销,比
mmap的脏页零散标记更高效;对内存占用敏感的场景(如嵌入式、低内存服务器):
mmap会长期占用映射页内存,read-write更可控。2、选
mmap的场景
内存充足 + 大块连续读写(如大文件拷贝、日志批量写入):
mmap省去read-write必须的 “用户态→内核态” 数据拷贝,减少 CPU 开销,速度更快;需要进程间共享文件数据:
mmap可直接将文件映射到多个进程的地址空间,共享数据无需额外的进程间通信(IPC);频繁对文件做内存式操作(如字符串处理、数据结构修改):
mmap把文件当内存用,无需手动管理缓冲区,代码更简洁。核心取舍
read-write胜在 内存可控、碎改场景开销低,靠内核攒批降低脏页管理成本;
mmap胜在 大块连续读写性能高、共享方便 ,但依赖充足内存,碎改场景会因脏页零散标记放大开销。
懂了后,来个实例对比下:
500MB 数据、4KB 内核页,预读比如 128KB:
read用固定 N KB 缓冲区(比如 64KB,你也可设 1MB,本质是批量读取的字节数),mmap是虚拟地址映射 + 按需加载(无 “缓冲区” 概念,只有页粒度的缺页触发)。
read:有明确的用户缓冲区大小(比如 64KB)。底层仍按 4KB 页加载到页缓存,read永不触发缺页异常(去磁盘进货就不算了);系统调用次数 = 500MB÷ 缓冲区大小(64KB→8000 次,1MB→500 次)。这里的缓冲区是用户层优化,内核底层的 4KB 页加载、预读逻辑和mmap完全一致,预读是磁盘搞到页缓存,解决的是下次是否需要去磁盘进货到页缓存,但依据每次要read系统调用去页缓存拿货到用户空间buf。说白了你设置的缓冲直接决定系统调用次数,和read本身的拷贝作为read的开销。mmap:不存在 “64KB/1MB 缓冲区” 的说法,它的最小触发单位是 4KB 页。500MB 理论缺页上限 128000 次(500MB÷4KB);但顺序读 + 预读生效时,同样预读进来 128KB ÷ 4KB=32 页,即read在128KB内不需要去磁盘进货了,直接去页缓存拿就行。但这个拿即拷贝到用户态和系统调用都是开销,而mmap有了预读的 128KB 后,在需要 128KB 数据内的时候,不需要发生缺页了,实际缺页次数大幅下降(500MB÷128KB=3906 次),这个次数和read的缓冲区大小无关,只和预读块大小相关(严谨点说:若内存紧张,内核会回收页缓存中的页,即使预读过 128KB,后续访问仍会触发二次缺页;若随机访问(非顺序读),预读失效 → 缺页次数会逼近理论上限(500MB÷4KB=128000 次))。关键统一:
read和mmap在内核页缓存 + 预读 + 磁盘 IO 的 4KB 页粒度上完全一致;差异仅在于:read是主动批量读导致的“内核 → 用户拷贝 + 系统调用计数”,mmap是预读进来多少 “按需未预读的触发缺页 + 无内核→用户拷贝 + 有比系统调用开销大的缺页次数计数”,二者的 “计数单位”(系统调用 vs 缺页)不同,不是底层加载粒度不同。预读对read是 “减少 IO 次数但不减少调用 / 拷贝次数”,对mmap是 “直接大幅减少核心的缺页次数”—— 这就是预读对二者作用大小的核心区别。
关于上述解释有些疑惑,整理了些豆包回答(主要是一些细节 & 深入抽插):
mmap的缺页中断触发时机:当你调用mmap()完成文件映射后,首次访问映射区的某段虚拟地址(比如想读 / 改这个地址的数据),但这段地址对应的文件数据还没加载到内核页缓存时,就会触发缺页中断(Page Fault)。
非首次访问:如果数据已在页缓存,不会触发任何中断,直接读写;
仅
mmap特有:read()是调用时直接从磁盘读数据到页缓存 + 拷贝到用户态,全程无 “缺页中断”,只有系统调用的软中断(和缺页中断不是一个东西)。
少量修改时中断次数少,零拷贝优势覆盖中断开销,
mmap更优;大量修改时中断次数爆炸,mmap反而比read慢。Linux 内核中,文件页缓存、内存映射的最小管理单位是 4KB(页大小),这是操作系统级别的硬性规则:
不管你
mmap时指定映射 100 字节、64KB 还是 500MB,内核最终都会按 4KB 页来拆分管理;不管你
read时指定读 100 字节、64KB 还是 500MB,内核读磁盘到页缓存时,也必须按 4KB 页加载(但read的用户态缓冲区大小可以自己定)说下
read的缓存区buf设置:1MB
read是否比 64KB 好?没法给定论,先科普:
read()传的buf大小是直接从页缓存拿的,这个大小是该次调用最多能从页缓存读取的字节数(不会超这个值);若页缓存无对应数据,内核指挥会向磁盘进货到页缓存,再拷贝到用户buf;磁盘 IO 进货大小:由内核预读机制决定(默认几十 KB ~ 几 MB),是内核层面的批量读取阈值,和read()的buf大小无关;
read()是用户态向内核态发起的系统调用,这个 “跨层调用” 本身就有固定开销(比如上下文切换、权限检查、内核态 / 用户态数据拷贝)。页缓存从磁盘 IO 进货,磁盘会批量搞,这是狗逼豆包的话语,但说人话就是预读!!磁盘会预读,即多进货到页缓存,然后
read就是从页缓存读东西,实际读最多不会超过你指定的。所以一个预读上限,一个read实际读的上限。缓冲区
buf越大,read系统调用次数越少,总开销越低(1MB 比 64KB 少);提一嘴减少系统调用但由于有预读,不一定每次都要去磁盘进货。但缓冲区不是越大越好,超过内核页缓存的批量 IO 阈值(比如几 MB),指的是磁盘预读,比如最多能预读 10MB,你
read想读 20MB 就开 20MB 的buf去读,内核依旧只塞 10MB,单次调用里,buf剩余 10MB 字节空间,内核不会给你填任何数据,这片空间在本次read周期里,属于「分配了但无数据填充」的闲置内存,这就是内存浪费的本质。while循环能读完总量,但每次都会带着浪费的空间,会浪费你的用户内存,所以最好写成:查看代码
char buf[20*1024*1024]; int t=0,n; while(t<20*1024*1024 && (n=read(fd, buf+t, 10*1024*1024))>0) t+=n; //内核把数据直接写到 buf 的 t 偏移位置, //即写 10*1024*1024 而非 sizeo(buf)但这只是为了理解这个理论,实际
read读多少我也不知道Linux 服务端常用 8KB / 64KB / 128KB 缓冲区(平衡开销和内存占用),1MB 也能用,但收益边际递减,系统调用次数的减少幅度跟不上 buf 增大的幅度,比如读取 100MB 文件:
64KB→128KB:buf 内存占用翻倍(成本 + 1 倍),系统调用次数从 1563 次降至 782 次(减少约 50%,收益高);
1MB→2MB:buf 内存占用同样翻倍(成本 + 1 倍),系统调用次数仅从 100 次降至 50 次(虽也减少 50%,但仅少 50 次,相比前者少几百次的收益,此收益的实际价值极低);
本质是 buf 越大,每翻倍一次内存占用,能减少的系统调用次数绝对值越少,性价比持续下 。说下 4KB: 内核和磁盘的交互粒度永远是 4KB 页(底层规则)。
懂了
mmap,再说sendfile,透彻讲解(小白友好 + 极简代码 + 与mmap对比)一、
sendfile核心本质
sendfile是 Linux 提供的一个专用系统调用,它的核心作用是在两个文件描述符之间,直接在内核态完成数据搬运,全程不经过进程的用户态内存。简单说,进程只需要告诉
sendfile:“我要把 A 文件描述符里的数据,搬到 B 文件描述符里”,剩下的所有数据拷贝、流转工作,全由内核自己完成,进程不用再插手,也看不到中间的数据。二、
sendfile极简操作逻辑(附关键代码片段)
先打开两个文件描述符(源文件:比如磁盘上的静态图片;目标文件描述符:比如网卡对应的套接字)
直接调用
sendfile系统调用,传入源文件描述符、目标文件描述符、数据偏移量、要传输的字节数,仅此一步即可触发内核态数据传输传输完成后,关闭文件描述符即可,全程无需手动分配用户态内存,无需读写数据
关键代码片段(仅核心几句,无冗余)
// 1. 打开源文件(比如要发送的静态图片)和目标套接字(网卡对应) int src_fd = open("test.jpg", O_RDONLY); int dst_sock = socket(AF_INET, SOCK_STREAM, 0); // (省略套接字绑定、连接等无关步骤,仅保留核心) // 2. 核心操作:调用sendfile,直接让内核把源文件数据搬到套接字(网卡) off_t offset = 0; // 从文件第0字节开始传输 size_t len = 10240; // 要传输10KB数据 sendfile(dst_sock, src_fd, &offset, len); // 全程无需用户态内存参与 // 3. 关闭描述符 close(src_fd); close(dst_sock);这里的关键:你不用定义
char buf[]这种用户态缓冲区,不用调用read把数据读到内存,也不用调用write把内存数据写到网卡,sendfile一句话就让内核完成了所有数据搬运工作。
sendfile头文件头文件<sys/sendfile.h>,原型:ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
out_fd:目标文件描述符(只能是套接字(早期内核) / 普通文件(现代内核≥2.6.33),比如网卡对应的 TCP 套接字)
in_fd:源文件描述符(必须是可定位的文件,比如磁盘文件,不能是套接字 / 管道)
offset:源文件读取偏移量的地址(内核自动更新该值,记录已传输字节数)输入:调用前设为读取起始偏移(如 0 = 文件开头)输出:调用后自动更新为本次读取后的偏移。传 NULL 则使用in_fd的内核文件指针(不推荐)
count:期望传输的字节数(不是实际传输数,实际传输数由返回值给出)返回值:成功返回实际传输的字节数>0;末尾 = 0;失败返回 - 1 并设置
errno。只有在大文件分批传输时,才需要利用
offset的自动更新来实现 “累加” 效果,比如:查看代码
// 大文件分批传输的示例(对比理解) off_t offset = 0; size_t total_sent = 0; const size_t BUF_SIZE = 4096; // 每次传4KB while (total_sent < file_size) { // 每次调用sendfile,offset会自动更新为本次传输后的位置(相当于“累加”) ssize_t sent = sendfile(client_fd, src_fd, &offset, BUF_SIZE); if (sent <= 0) break; total_sent += sent; } if (sent == -1) perror("sendfile fail");每次
sendfile传输完成后,内核会自动向后移动src_fd的文件指针(移动的字节数 = 本次实际传输字节数);下一次调用sendfile会从当前文件指针位置继续传输,同样是连续的,不会跳跃,所以无脑循环读他妈的就好,不用考虑端点啊或者是否跳跃啊啥的,贼 JB 简单。演变进化历史:
早期
sendfile(Linux 2.1):
① 进程调用
sendfile(fd_out, fd_in, &offset, count),传入文件描述符(fd_in = 文件、fd_out = 网卡 socket);② 内核直接操作「页缓存」和「socket 缓冲区」:DMA 把磁盘数据拷到内核页缓存后,CPU 只拷贝 “数据描述符”(长度、偏移)到 socket 缓冲区,不拷贝实际数据;
③ DMA 控制器直接从页缓存把数据拷到网卡,全程 CPU 只做 “指令控制”,不碰实际数据。路径:
磁盘 → DMA → 内核页缓存 → CPU拷贝【数据描述符】→ 内核socket缓冲区 → DMA → 网卡(注意:这里 CPU 拷贝的是 “数据描述符”,不是实际数据 —— 但 socket 缓冲区是绕不开的)。对比普通read+write的路径(再贴一遍,方便对比):磁盘 → DMA → 页缓存 → CPU拷贝【实际数据】 → 用户buf → CPU拷贝【实际数据】 → socket缓冲区 → DMA → 网卡。早期
sendfile已经干掉了 “内核 ↔ 用户态” 的两次 CPU 数据拷贝(这是零拷贝的核心),但还剩一个小瑕疵 —— 需要把 “数据描述符” 拷贝到socket缓冲区;
改进版
sendfile(Linux 2.4+,借助 DMA 的 Scatter 分散 / Gather 聚合特性):连 “描述符拷贝到socket缓冲区” 都省了 —— 内核直接把页缓存的内存地址告诉网卡 DMA 控制器,DMA 直接从页缓存读数据到网卡,彻底绕开 socket 缓冲区。- Linux 2.6.33 内核 开始支持
文件 → 文件拷贝三、
sendfile底层工作流程(透彻拆解)(涉及到态的切换)
进程调用
sendfile系统调用,触发一次用户态→内核态切换,把源文件描述符、目标描述符、偏移量、长度这些参数传给内核内核先检查源文件的内核页缓存,如果数据已经在页缓存中(之前被访问过),直接使用页缓存数据;如果不在,内核通过 DMA 拷贝(这点
read、mmap、sendfile一致),把磁盘上的源文件数据读到内核页缓存(无 CPU 参与)内核直接在核态内部,把页缓存中的数据通过 DMA 拷贝,搬运到目标描述符对应的设备(比如网卡的缓冲区,或另一个文件的内核缓存),全程没有 CPU 拷贝,也不会把数据放到进程的用户态内存中
传输完成后,内核更新源文件的读取偏移量(就是代码中的
offset),并返回实际传输的字节数,然后从内核态切回用户态整个过程中,进程只负责 “下达指令”,不接触任何实际数据,所有数据流转都在 kernel 空间完成
四、
sendfile与mmap核心对比
数据流转路径差异
sendfile:数据全程在内核态流转(磁盘→内核页缓存→目标描述符),完全不进入用户态,无 CPU 拷贝,无频繁态切换(仅调用sendfile时一次切换)
mmap:建立映射后,数据会从内核页缓存映射到用户态内存(进程可直接访问),若要传输到网卡,还需要把用户态内存的数据通过 CPU 拷贝,再写回内核态,最终传到网卡(存在 CPU 拷贝和态切换)操作对象与方式差异
sendfile:操作的是 “文件描述符”,仅负责数据的 “搬运”,进程无法查看、修改传输的数据(因为数据不进入用户态),核心代码只有sendfile一句,无需操作内存
mmap:操作的是 “进程用户态内存”,把文件伪装成内存供进程访问,进程可以通过内存指针直接读写、修改文件内容(像操作数组一样),核心是通过内存偏移操作,而非数据搬运内存使用差异
sendfile:无需进程手动分配用户态内存缓冲区,内核自动在核态管理数据,节省进程内存开销,也无需处理内存缓冲区的分配与释放
mmap:需要占用进程的虚拟内存空间(映射的文件大小会占用进程虚拟内存),若映射超大文件,可能导致进程虚拟内存不足,需要手动管理映射区域的大小适用场景底层逻辑差异
sendfile:仅适用于 “无需修改数据” 的纯传输场景(文件→网卡、文件→文件),因为进程无法接触到传输的数据,只能原样搬运
mmap:适用于 “需要读写、修改文件内容” 或 “多进程共享文件数据” 的场景,因为进程能直接访问、修改映射的内存(对应文件内容),而纯传输场景下,它的性能不如sendfile(有 CPU 拷贝开销)核心代码对比(极简,无冗余)
sendfile核心(文件→网卡):sendfile(dst_sock, src_fd, &offset, len); // 直接内核态搬运,无用户态内存
mmap核心(文件→用户态内存,可修改):char *mem = mmap(NULL, file_size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0); mem[104] = 'a'; // 直接修改内存(对应文件内容),无需write正常文件操作(对比参考,极简):
char buf[1024]; read(src_fd, buf, 1024); // 读文件到用户态缓存 write(dst_sock, buf, 1024); // 写缓存到目标描述符性能核心差异
sendfile:2 次 DMA 拷贝(磁盘→内核页缓存、内核页缓存→目标设备),0 次 CPU 拷贝,1 次用户态→内核态切换(仅调用时)
mmap(文件读写场景):2 次 DMA 拷贝(磁盘→内核页缓存、内核页缓存→磁盘(修改后同步)),0 次 CPU 拷贝(仅文件读写);若用于文件→网卡传输,会多 1 次 CPU 拷贝(内核页缓存→用户态内存)和多次态切换(调用 write 时),性能弱于sendfile总结:
其实
read是去内核搞到用户态再搞到内核
mmap是类似传送门、时空隧道、远程控制,mmap可以在用户态操作远程内核态的东西,为了就是源头修改拷贝到目的地,然后内核异步把脏页刷到磁盘。而如果不修改,
sendfile是远程都不用,直接给指令,那边自己原封不动内核之间搬运数据。文件 vs 文件,就算不修改也一般用
mmap,因为必须 2.6.33 版本以上,限制导致会有兼容问题,只能源头到目标,单向的,mmap任意读写映射的内存。简单帖个代码找找感觉:
查看代码
#include <iostream> #include <fstream> #include <sys/sendfile.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> #include <cstring> #include <cerrno> bool copy_large_file(const std::string& src_path, const std::string& dst_path) { // 1. 打开源文件(只读) int src_fd = open(src_path.c_str(), O_RDONLY); if (src_fd == -1) { std::cerr << "打开源文件失败: " << strerror(errno) << std::endl; return false; } // 2. 打开目标文件(创建/写/截断) int dst_fd = open(dst_path.c_str(), O_WRONLY | O_CREAT | O_TRUNC, 0644); if (dst_fd == -1) { std::cerr << "打开目标文件失败: " << strerror(errno) << std::endl; close(src_fd); return false; } // 3. 获取源文件大小 struct stat stat_buf; if (fstat(src_fd, &stat_buf) == -1) { std::cerr << "获取文件状态失败: " << strerror(errno) << std::endl; close(src_fd); close(dst_fd); return false; } // 4. 核心:循环调用sendfile,处理超大文件/单次传输不完整的情况 off_t offset = 0; off_t total_bytes = stat_buf.st_size; ssize_t bytes_sent = 0; // 每次传输1MB(避免单次传输量过大触发错误) const size_t CHUNK_SIZE = 1024 * 1024; while (offset < total_bytes) { // 计算本次要传输的字节数(剩余不足1MB则传剩余量) size_t current_chunk = (total_bytes - offset) > CHUNK_SIZE ? CHUNK_SIZE : (total_bytes - offset); bytes_sent = sendfile(dst_fd, src_fd, &offset, current_chunk); if (bytes_sent == -1) { std::cerr << "sendfile传输失败: " << strerror(errno) << std::endl; close(src_fd); close(dst_fd); return false; } // offset会被sendfile自动更新,无需手动修改 } std::cout << "文件复制成功!共复制 " << offset << " 字节。" << std::endl; // 5. 关闭文件描述符 close(src_fd); close(dst_fd); return true; } int main() { std::string src = "test.txt"; std::string dst = "hhh"; if (copy_large_file(src, dst)) { std::cout << "复制成功!" << std::endl; } else { std::cout << "复制失败!" << std::endl; return 1; } }这里就是手动搞了分段指定大小,其实完全没必要,但不是不能指定。 只是没意义(哪怕超过内存
sendfile也不需要指定)。
插一嘴:
mmap还可以局部映射,通过mmap最后一个参数(偏移量)再说几个事:
sendfile的描述符限制(早期内核 vs 现代内核)
早期 Linux 内核(2.6.33 之前):
in_fd(源描述符)只能是磁盘文件(支持内存映射的可定位文件),out_fd(目标描述符)只能是套接字(比如网卡对应的 TCP/UDP 套接字),不能用于两个普通磁盘文件之间的拷贝。现代 Linux 内核(2.6.33 及以后):解除了
out_fd的限制,out_fd也可以是普通磁盘文件描述符,这时候sendfile就能实现 “磁盘文件→磁盘文件” 的内核态直接拷贝,同样无需用户态参与。底层逻辑:早期内核设计
sendfile的核心诉求是解决 “静态文件传输到网卡” 的性能问题,后续才扩展了文件到文件的拷贝能力。
sendfile无法处理 “动态生成的数据”比如你在服务端动态拼接了一个响应报文(
std::string resp = "HTTP/1.1 200 OK\r\n" + content;),这份数据一开始存在进程用户态内存中,无法直接用sendfile传输。底层逻辑:
sendfile只能读取in_fd对应的 “内核页缓存” 数据,无法直接访问进程用户态内存的数据。如果要传输动态数据,要么用write/send,要么先把动态数据写入一个临时磁盘文件,再用sendfile传输(但这样会多一次磁盘 IO,得不偿失)。
mmap的公私有问题:源文件起初是 10 字节,然后做了修改比如截断为 5 字节,然后这时候访问被截断的会出错(无论公有私有),而公私有的差别是:
公有是在写的时候会实时同步给源文件
私有是首次写操作时才惰性创建内存副本(写时复制,Copy-on-Write),然后修改完全不会同步到源文件(因为是独立副本)
munmap后,修改的数据不一定已经同步到磁盘你用mmap修改了映射内存(mem[100] = 'a'),然后调用munmap(mem, file_size)解除映射,这时候修改的数据可能还在 “内核页缓存” 中,没有立刻刷写到磁盘。如果这时候机器突然断电,修改的数据会丢失。想要确保数据同步到磁盘,可以调用msync函数(核心代码片段):msync(mem, file_size, MS_SYNC); // 阻塞等待数据同步到磁盘 munmap(mem, file_size);底层逻辑:
mmap的数据同步是 “延迟同步”,内核会在合适的时机(页缓存满、系统空闲等)自动把修改的数据刷写到磁盘,msync是强制让内核立刻同步,保证数据不丢失。
mmap映射超大文件,会耗尽进程虚拟内存比如你映射一个 10GB 的文件,虽然不会立刻占用物理内存(缺页中断时才分配物理内存),但会占用进程 10GB 的虚拟内存空间。
如果进程的虚拟内存空间不足(比如 32 位进程最大虚拟内存只有 4GB),会导致
mmap调用失败(返回MAP_FAILED)。底层逻辑:
mmap占用的是进程的虚拟地址空间,虚拟地址空间有上限,映射超大文件会耗尽这个空间,导致映射失败。而sendfile不占用进程虚拟内存,因为它全程在内核态操作,不涉及进程用户态内存分配。
mmap多进程映射同一个文件的 “写时复制(COW)”机制写时复制是专属私有
MAP_PRIVATE的,映射同一个文件,当其中一个进程尝试修改映射内存时,内核不会直接修改共享的内核页缓存,而是会复制一份该页缓存的副本,给这个进程单独使用,其他进程看到的还是原来的内容。而公有
MAP_SHARED映射(且权限为PROT_WRITE),修改就直接写入页缓存,然后如果需要立马落盘,要msync()、fsync()查看代码
// 私有映射:修改仅对当前进程有效,触发写时复制 char *mem_private = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_PRIVATE, fd, 0); // 共享映射:修改会同步到内核页缓存,其他进程可见,最终同步到文件 char *mem_shared = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);底层逻辑:写时复制(COW)是为了兼顾 “共享内存” 和 “进程独立性”,避免一个进程的修改影响其他进程,同时节省物理内存开销(只有修改时才复制副本,未修改时共享同一个页缓存)。
关于数据丢失风险差异:
sendfile:传输过程中数据全程在内核页缓存,若传输中断,内核会记录传输偏移量,再次调用时可从断点继续传输,几乎无数据丢失风险(除非内核崩溃)。
mmap:修改后的数据是延迟同步到磁盘的,若未调用msync就解除映射或进程崩溃,修改的数据可能丢失;同时映射文件被截断会导致段错误,引发进程异常退出。
mmap匹配问题:
文件
O_RDONLY→ 映射只能PROT_READ文件
O_RDWR→ 映射可PROT_READ/PROT_WRITE
int fd = open("test.txt", O_RDONLY);你映射时要求可写void *addr = mmap(NULL, 1024, PROT_WRITE, MAP_SHARED, fd, 0);,权限不匹配,mmap返回MAP_FAILED。细节:
mmap不是用户态获得了访问内核态的权限,而是内核将内核页缓存的物理内存,映射到了用户态的虚拟地址空间,用户态通过操作自己的虚拟地址,间接操作内核页缓存。用户永远无法访问内核态。不是给你内核的访问权限,而是在内核对应需要的页缓存装了个时空隧道传送门,然后munmap时候失效,如果不munmap,要么靠进程退出后内核兜底清理所有未释放的映射,要么进程运行期间反复mmap,进程的虚拟地址空间会持续被占用,直到耗尽,导致后续mmap失败或 OOM(内存溢出),这就是运行时的内存泄漏,但物理内存(页缓存)由内核统一管理不会泄漏,因为虚拟内存:是进程 “私有” 的。每个进程有自己的虚拟地址空间,
mmap本质是给进程的虚拟地址空间分配一段区域,并和物理内存 / 文件页缓存建立映射关系。进程退出时,内核会直接销毁这个进程的虚拟地址空间,自然就切断了这种映射。物理内存 / 页缓存:是内核全局管理的公共资源,不属于任何单个进程。页缓存(Page Cache)是内核为了加速文件 IO,把文件内容缓存到物理内存里的区域,所有进程共享这个缓存池。当你用mmap映射文件时,只是让进程的虚拟地址指向了页缓存里的对应物理页;当进程退出,这个 “指向关系” 被销毁,但物理页本身还在页缓存池里 —— 内核会根据系统整体的内存使用情况(比如内存不足时),决定是保留这个缓存(供其他进程复用),还是把脏页(修改过的内容)写回磁盘后释放物理页。简单说:进程只是 “借用” 了内核管理的物理内存 / 页缓存,进程没了,“借用关系” 就失效了,内核依然掌控这些物理资源,不会因为某个进程没调用
munmap就丢了这些内存。内存完全用户控制,是死的,会漏, 页缓存由内核控制,是活的,不会泄漏。
概念:
页表:内核维护的映射表,建立进程用户态虚拟地址与物理内存地址的一一对应关系,CPU 通过查页表将虚拟地址转为物理地址,进程永远只操作虚拟地址。
页缓存:内核在物理内存中开辟的缓存区域,用于暂存从磁盘读取的文件数据,避免频繁磁盘 IO,磁盘→内核页缓存是物理拷贝,页缓存数据可被多个进程映射复用。
直接操作内核物理内存是「越权访问」(OS 禁止),而映射是「合法地址指向」(OS 通过页表授权,无特权)
mmap分段映射:这个搞了好久,其实有点绕,绕的点只要是 C++ 的
mmap映射的本质、底层逻辑,怎么映射到内存这些我感觉略抽象的东西,但核心的什么向下取整啥的,仅仅属于刷的算法题里 1 + 1 级别。这要就是
offset和length这俩参数,length自动取整页,offset必须手动搞整页的倍数,不多逼逼直接上俩例子来抽插比如你想读从文件的第 5000 字节开始的 100 字节,只读这 100 字节,
那内存映射比如映射整页,
mmap的参数里offset是从哪个页开始映射,length是想读多长,那显然是从5000所在的页开始映射第一页:0 ~ 4095
第二页:4096 ~ 8191
第三页:8192~12287
显然只需要映射第二页这一页即可,
offset = 目标位置 / PAGE_SIZE * PAGE_SIZE(整数除法),比如 5000:offset=4098 / 4096 * 4096 = 4096,这个 4096 就是所谓的必须手动搞成页的整数倍(向下取整)。length 偏移量 = 目标位置 % PAGE_SIZE
mmap返回的void* ptr指向 4096 字节位置。然后
查看代码
#include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/mman.h> #include <unistd.h> int main() { const char *src_path = "test.txt"; const size_t page_size = getpagesize(); // 获取系统页大小(通常4KB) int src_fd = open(src_path, O_RDONLY); if (src_fd == -1) { perror("open"); return -1; } // 模拟:原始想从5000字节(非页对齐)开始映射,读100字节 off_t raw_offset = 5000; size_t want_read_size = 100; // 第一步:必须处理offset,向下取整到页边界 off_t aligned_offset = (raw_offset / page_size) * page_size; // 4096 size_t offset_diff = raw_offset - aligned_offset; // 904 // 第二步:length按实际需要传(不用对齐,内核自动补) size_t curr_size = want_read_size + offset_diff; // 100+904=1004(非页对齐) // 第三步:用对齐后的offset映射 char *src_mmap = mmap(NULL, curr_size, PROT_READ, MAP_PRIVATE, src_fd, aligned_offset); if (src_mmap == MAP_FAILED) { perror("mmap"); close(src_fd); return -1; } // 第四步:访问数据时跳过offset_diff,读想要的100字节 for (size_t i = 0; i < want_read_size; i++) { char c = src_mmap[offset_diff + i]; // 从904开始,对应原始5000字节位置 printf("第%ld字节:%c\n", raw_offset + i, c); } munmap(src_mmap, curr_size); close(src_fd); }心累:
感觉过度依赖大模型垃圾信息垃圾思维太多效率真不如自己使劲想。80% 的时间是给大模型挑错纠正他。哎没他还有些问题不懂。
从现在开始逐渐自己思考,不依靠他更不求他来肯定我的知识理解!完全脱离豆包!
因为狗逼死全家的豆包无穷无尽的犯错,永无止境的给你修改后的代码,无穷无尽的犯错,导致耽误无数时间给他挑错,气死!其实自己思考完全可以写出来,以后只有想不懂再用它!之前因为他浪费了 90% 的无用时间,没他又总不敢相信自己的理解是否正确。
其实之前刷算法时候还没大模型,真的刻在血肉骨子里,就像夸克收藏“关于差速器的讨论”古代科学家数学家(罗曼)一样,如今有了豆包很多的解释自己可以想懂,但懒了,所以豆包给完答案懂了依旧不深刻,得反复看。毕竟不是自己想破脑袋想出来的。
完全回到了刷算法,很多代码我不思考,就是单一的看某句某句咋回事,然后想不懂,其实他妈的连贯思维起手就自己思考,都是顺带可以想出来的的。但想完自己日后中间某句看不一定记得咋回事。
且看完别人的答案,总会思考过多,以为自己无法思考出来,反被逼的要去思考【自己是否无法想股出来?】,但如果不看答案,真的轻轻松松就想出来了,没负担也不需要回顾。
length是这里的curr_size,然后这个其实就是根据 4096 算的偏移,换句话说 5000 的基准变了,100 也一定跟着变。这里就是
length不需要手动搞整数倍,这里发现他没跨页,所以无论你是curr_size是 1004 还是1008,都会只映射第二页这一个页数,不会跨页,映射进来一整页后你可以自己去处理需要的数据。那何时会跨页?比如你想读从 5000 字节开始的 4000 个字节,
offset依旧是 4096,那偏移length也就是curr_size就是计算总映射长度,即偏移差(904) + 要读的字节数(4000),通过传入的curr_size=4904会让内核自动向上取整到 8192 字节(即跨第二、三这两页)。啥时候必须手动算(
offset和length)?
想精准从「非页边界」读数据(如 5000 字节),必须
啥时候不用手动算?
从「页边界」读数据(如 4096/8192 字节),不用算。
- 不介意内存浪费(比如小文件整体映射),哪怕 offset 非对齐,也可以直接传 offset=0、length = 文件大小,映射,也不用算。
思考个事,如果想查看向上取整的结果,比如你想从开头开始读 a 字节,
我的思考是:先 a / 4096 相当于取得自己是哪个页,然后 * 4096 就是自己的当前页的首字节, + 4095 就是上限,我的公式是:(a / 4096 ) * 4096 + 4095,其实这个是后来我自己的逻辑总结,我想出这个公式是通过:
第一页:0 ~ 4095
第二页:4096 ~ 8191
第三页:8192~12287
和 0 1 4095 4096 这是个数自己手推硬凑的。
然后豆包给的是,
((a + page_size - 1) / page_size) * page_size;
我起初通过数学公式化简
= (a + 4095) / 4096 * 4096
= (a / 4096 + 4095 / 4096) * 4096
= a + 4095
感觉有点离谱,最后豆包说是的!纯数学上不舍弃小数时你的推导成立,编程里整数除法舍弃小数所以推导错误!其中:
= (a + 4095) / 4096
= (a / 4096 + 4095 / 4096)
这俩就是错的,随便 a 是 1 就可以验证。
公式由于是省略小数,所以无法通过数学推导,只能通过逻辑思考的一致性来判断,即他的逻辑是,先加一整页然后除一整页就是这个页的尾巴下个页的头,但只是页数标记,乘个 4096 即可。
插一嘴趣事(小学知识突然模糊了,感觉自己突然学傻了,哎,科普下吧):
除法没交换率(换位置),即 a ÷ b ≠ b ÷ a,所谓交换后结果不变的,都是乘法间接的结果,
单独除法也没有结合律(换运算分组顺序),
(8 ÷ 4) ÷ 2 和 8 ÷ (4 ÷ 2) 不等,但依旧是借用乘法可以有,
突然思考 1.99 循环就是 2,但这是大学的极限,小学时候比如 7 / 3 + 7 / 3 得啥?直接写 14 / 3。
再说个好神奇,0.3 循环是:
小时候思考:6*(7/3)小时候一般都是直接 6 和 3 先约得到 14,这里我疑惑,7 如果先和 3 算就是无限循环小数 2.3 循环,再乘 6 是 13.99999998 大学极限里就是 14。
同wx搜“治坦 ”
来个终极串联的代码,分段映射,(琢磨了很久,必须放项目里)
起初我这么写的:
查看代码
#include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/mman.h> #include <sys/stat.h> #include <unistd.h> #include <string.h> #include<iostream> using namespace std; off_t get_file_size(const char *path) { struct stat st; if (stat(path, &st) == -1) {perror("stat error");return -1;} return st.st_size; } int main() { const char *src_path = "test.txt"; off_t file_size = get_file_size(src_path); if (file_size == -1) return -1; cout<<file_size<<endl; size_t segment_size; cin >> segment_size;// 这里搞个随机,比如用户输入 const size_t PAGE_SIZE = getpagesize(); // 获取系统页大小通常4KB int src_fd = open(src_path, O_RDONLY); if (src_fd == -1) {perror("open error");return -1;} size_t limit = 0; size_t flag = 0;// size_t是表示内存大小、数组长度的无符号 64 位整数 off_t offset = 0;// off_t是 Linux 系统中表示文件、内存偏移量的有符号 64 位整数 while( limit < file_size ){ size_t curr_size = (file_size - offset) < segment_size ? (file_size - offset) : segment_size; // offset = (offset + curr_size)/PAGE_SIZE*PAGE_SIZE;//向下取整,这句话放这,显然不行,比如一次如果读超过1页,则直接会搞为后面的页,头部分给搞没了,错误很明显 char *src_mmap = (char*)mmap(NULL, curr_size, PROT_READ, MAP_PRIVATE, src_fd, offset);// 分段映射 offset = (offset + curr_size)/PAGE_SIZE*PAGE_SIZE; size_t access_size = 3;// 模拟访问当前段数据,比如读前 3 access_size = access_size > curr_size ? curr_size : access_size; for (size_t i = 0; i < access_size; i++){ char c = src_mmap[i]; cout<<c; } cout<<endl; munmap(src_mmap, curr_size); limit += curr_size; } close(src_fd); }发现对于数据
abcdefghijklmnABCDEFGHIJKLMN123456789每次都是,0 页开始读,因为数据量没到 4KB,但length那个参数没算上页偏移,每次都是读abc。于是有了豆包给修正的代码:
查看代码
#include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/mman.h> #include <sys/stat.h> #include <unistd.h> #include <string.h> #include<iostream> using namespace std; off_t get_file_size(const char *path) { struct stat st; if (stat(path, &st) == -1) {perror("stat error");return -1;} return st.st_size; } int main() { const char *src_path = "test.txt"; off_t file_size = get_file_size(src_path); if (file_size == -1) return -1; cout << "文件大小: " << file_size << endl; size_t segment_size; cin >> segment_size; const size_t PAGE_SIZE = getpagesize(); int src_fd = open(src_path, O_RDONLY); if (src_fd == -1) {perror("open error");return -1;} off_t total_read = 0; // 全局已读字节数 while (total_read < file_size) { size_t curr_size = (file_size - total_read) < segment_size ? (file_size - total_read) : segment_size; off_t mmap_offset = (total_read / PAGE_SIZE) * PAGE_SIZE; // off_t mmap_offset = total_read & ~(PAGE_SIZE - 1); // 向下取整到页起始 size_t inner_off = total_read - mmap_offset; // 当前页内的偏移,等价于 total_read % PAGE_SIZE size_t map_len = inner_off + curr_size; // 映射长度覆盖页内偏移+本次读取量 char *src_mmap = (char*)mmap(NULL, map_len, PROT_READ, MAP_PRIVATE, src_fd, mmap_offset); if (src_mmap == MAP_FAILED) {perror("mmap error"); close(src_fd); return -1;} size_t access_size = 3; access_size = access_size > curr_size ? curr_size : access_size; for (size_t i = 0; i < access_size; i++) { char c = src_mmap[inner_off + i]; cout << c; } cout << endl; munmap(src_mmap, map_len); total_read += curr_size; } close(src_fd); }其实所谓的
mmap最后一个参数的offset,之前说的向下取整offset = 目标位置 / PAGE_SIZE * PAGE_SIZE,这个目标位置指的是total_read(全局已读字节数),本质是你接下来要读取的第一个字节在文件中的绝对位置。total_read就是要从 0 累加到文件总字节数。mmap的length参数之前都是直接获取文件大小,所以很多误解无法发现和纠正,现在写了这个代码就全清晰了,
你的核心误解:
mmap的length不是 “想读多少字节”,而是「要映射的内存区域总长度」—— 映射是按页为单位的,哪怕你只填 1 字节,内核也会映射整页;但你填的length必须覆盖「页内偏移 + 本次要读取的字节数」,否则会越界访问;举例打脸:若
total_read=4090(0 号页内偏移 4090)、curr_size=20(要读 20 字节),你若把length填 20(“想读 20 字节”),但mmap_offset=4096(1 号页起始),此时src_mmap[0]是 1 号页第 0 字节,而你要读的是 0 号页 4090-4110 字节(跨 0、1 号页),填 20 会导致只能读到 1 号页 0-19 字节,丢失 0 号页 4090-4095 字节,完全错;正确逻辑:
length= 「当前页内偏移」 + 「本次要读的字节数」—— 确保映射区域能覆盖你要读的所有字节(哪怕跨页),这是mmap的核心规则,不是 “想读多少填多少”。具体输出:
access_size = access_size > curr_size ? curr_size : access_size;的意义:当文件剩余大小不足 3 字节时,
curr_size会是文件剩余的实际大小(比如只剩 1 字节),这行代码能避免越界,防止循环访问src_mmap[1]及以后的内存(这部分内存未映射,访问会触发段错误)。
size_t curr_size = (file_size - total_read) < segment_size ? (file_size - total_read) : segment_size;的意义:比如每次读 10MB,最后剩的只有 4MB,映射 10MB 没问题,但后续访问指不定是咋访问的,不小心访问到 4MB 后就会段错误。
关于
off_t mmap_offset = total_read & ~(PAGE_SIZE - 1):4096 = 2¹²
4096:
00000000 00000000 00010000 000000004095:
00000000 00000000 00001111 11111111取反:
11111111 11111111 11110000 00000000,这里就是为了与的时候把页内偏移(后 12 位)清零。只保留总页数 * 4096。通过:
第 1 页起始地址(4096)32 位二进制
00000000 00000000 00010000 00000000第 2 页起始地址(8192)32 位二进制
00000000 00000000 00100000 00000000第 3 页起始地址(12288)32 位二进制
00000000 00000000 00110000 00000000就一目了然了,与后得到的都是 4096 的整数倍,大厂常用这个向下取整。
零拷贝琢磨懂有何意义?相比于手写算法,和日后学的设计模式
408阅卷为何可以不编译直接看对错?教授真有这能力吗?
大厂资深技术专家 vs ACM
splice没精力看了,90% 考的是上面那俩,如果面试官主动问起splice,你用这几句话应答,既体现你有认知,又不会暴露不深入的短板:“我了解splice是 Linux 的零拷贝接口,它主要用于两个文件描述符之间的数据传输,比sendfile更灵活,不过需要依赖管道作为中间载体。它的核心优势也是让数据停留在内核态,省去用户态和内核态之间的 CPU 拷贝,不过在我们日常业务开发中,更多用sendfile做文件到网卡的传输,splice接触得比较少,没有深入实践过”总结:
纯文件发送(如静态资源)→ 优先
sendfile;需要修改文件内容后发送 → 用
mmap+write;内核缓冲区数据转发(如管道、socket 代理)→ 用
splice。提一嘴:
mmap由于修改有优势,且服务端常用原封不动搞网卡,所以说sendfile搞文件 vs 网卡,mmap搞文件 vs 文件,其实从始至终mmap都可以文件 vs 文件和文件 vs 网卡之间的修改,之前说mmap多用于文件 vs 文件,是因为它的高频场景是修改文件内容后落盘,不是它只能干这个!原封不动搞数据就是
sendfile,只不过早期sendfile只能搞原封不动的文件 vs 网卡之间搞数据且碰文件描述,2.4 版本开始是绕过文件描述符socket但依旧只能搞文件 vs 网卡只不过更加优化,然后 2.6.33 版本直接增加了文件 vs 文件,只要涉及到修改数据,那必然选择mmap。且所有提到的版本都是运行环境的 Linux 版本(2.6.33 之类的),编译器无需特定版本,仅需运行环境满足对应内核版本要求即可使用
sendfile/mmap。举个
mmap搞网卡的例子:mmap的核心是「把文件映射到进程虚拟内存」,让你能像操作内存一样读写文件内容。当你需要把修改后的文件数据发给网卡(比如给客户端传修改后的图片、解析后的业务数据),就可以用mmap+ 普通 Socket 发送(或sendmsg),本质是:先通过mmap高效拿到文件数据(无 CPU 拷贝),再把内存里的数据直接发给网卡。比如:你要修改一张图片的水印,然后通过 TCP Socket 发给客户端(对接网卡):
mmap映射文件到进程内存调用mmap,把图片文件映射到你的进程虚拟内存,得到一个内存指针char* img_buf;此时img_buf就指向图片的全部数据,你操作img_buf就等于操作图片文件,无内核 ↔ 用户态 CPU 拷贝(比read读文件到用户态buf高效)。在内存中修改数据(你的核心需求)直接通过
img_buf修改图片水印(比如修改指定内存地址的像素值),像操作普通数组一样简单,全程在用户态内存操作,无额外拷贝。把修改后的内存数据发给网卡(对接 Socket)调用普通 Socket 发送函数(
send/sendmsg),直接把img_buf里的数据发给客户端(网卡):// 直接发送mmap映射的内存数据,无需额外拷贝 send(sock_fd, img_buf, img_size, 0);此时数据从「进程虚拟内存(
img_buf)」拷贝到「内核 Socket 缓冲区」,再由 DMA 拷贝到网卡,全程只做 1 次 CPU 拷贝(比read+write+send少 1 次 CPU 拷贝)。关键澄清:
mmap不是 “直接对接网卡”,而是 “先映射文件到内存,再发内存数据给网卡”你之前误以为mmap只能文件→文件,是因为没分清:
sendfile:直接在内核态把文件数据转给网卡(进程完全不碰数据,纯内核转发) —— 仓库(文件)直接用内部传送带(内核态)把货物(数据)运到货车(网卡),你(进程)不用动手;
mmap:先把文件数据映射到进程内存(进程可修改),再由进程把内存数据发给网卡(进程要操作数据,再转发) —— 仓库(文件)把货物搬到你的工作台(进程内存),你修改完货物后,再用小推车把货物搬到货车(网卡),你需要动手操作货物,但搬货上工作台的过程更高效。编译器的底层逻辑(问到 2.6.33 是 Linux 内核还是编译器版本,豆包扯出了这个,我就一路追问出这些了):
我们编译器写代码,是文件读取到用户态,
sendfile不碰用户态内核直接传。编辑器打开大文件时,通过mmap()将文件的内核页缓存,直接映射到用户态的虚拟地址空间。这样一来,编辑器无需通过read()把文件数据拷贝到用户态缓冲区(省拷贝、省内存),就能像操作本地内存数组一样,直接读取(展示文件内容)、修改(编辑内容)映射区域的内容 —— 修改后的内容会自动同步到内核页缓存,最终由内核异步刷写到磁盘(实现保存功能)。编辑器调用
mmap()系统调用,不拷贝任何数据,只做一件事:把 “内核页缓存” 和 “编辑器用户态虚拟内存” 建立一个 “映射关系”(相当于给内核页缓存开了一个 “用户态窗口”)。如果不用
mmap,编辑器打开一个 10G 大文件:
调用
read()系统调用,把磁盘文件的数据拷贝到内核页缓存(内核态缓冲区)。再从内核页缓存,把数据拷贝到编辑器的用户态缓冲区(比如编辑器进程自己的内存里)。
你修改文字,其实是修改用户态缓冲区里的数据。
保存时,调用
write()系统调用,把用户态缓冲区的数据拷贝回内核页缓存。内核再把页缓存的数据刷写到磁盘。
关键问题:多了 2 次无用的数据拷贝(内核→用户、用户→内核),耗内存、耗性能,大文件会卡顿。
再深入,无意间衔接上了之前啃的 TCP 网络的知识:
我通过本地的 VScode 远程控制租的腾讯云里的 cpp 文件是啥原理?
看文件的 “简单操作” 背后,本质是跨网络的 TCP 数据传输。你本地的 VScode 和云服务器上的文件,隔着互联网 / 局域网,所有数据必须通过 TCP 网络传输才能到你电脑上,这和你学的 TCP 知识完全串得上!
1、如果你直接在云服务器本机
- 敲
cat test.cpp,不用 TCP、不用网络,程序直接小文件用read,大文件用mmap映射来读本地磁盘,数据不用出服务器。用不到sendfile因为是进入用户态。用户访问云服务器 Nginx(比如
http://云服务器IP/test.cpp)→ Nginx 收到请求后,判断是纯静态文件、无需处理内容 → 调用sendfile,让内核直接把磁盘里的 test.cpp 数据从文件描述符传到网卡描述符 → 数据发往客户端本机文件复制:
普通复制:
cp a.txt b.txt是read(文件→用户态 buf)+write(用户态 buf→文件),有用户态拷贝;高性能复制:用
sendfile把 a.txt 的文件描述符数据直接传到 b.txt 的文件描述符,内核全程处理,用户态程序只调用接口,无数据拷贝 —— 这也是本机文件操作用到sendfile的典型场景。2、但你是在本地 VScode 看云服务器的文件:
你在本地 VS Code 点 “打开远程文件” → 本地 VS Code 的远程插件在用户态封装 “读取文件请求”(加 SSH 协议头)→ 调用系统接口把请求交给内核 → 内核通过网卡把 TCP 包发往腾讯云;
腾讯云服务器内核收到 TCP 包 → 把包交给用户态的 SSH 服务进程 → SSH 进程拆包(解协议头),拿到 “读取 XX.cpp” 的指令 → 后台用户态调用
mmap(或read)(用户无感知),仅系统调用的执行阶段会短暂切到内核态,然后把云服务器磁盘里的 CPP 文件数据拿到用户态供 SSH 处理(因为要给数据加 SSH 响应头);云服务器 SSH 进程在用户态给 CPP 文件数据加 SSH 响应头(封装)→ 交给内核 → 内核把数据打成 TCP 包,通过网卡经过路由器交换机发回本地;
因为
sendfile是俩描述符之间的,而这个是一堆松散的数据,不以某个打开文件的描述符形式存在,必须通过 TCP 协议栈传送。sendfile的核心是内核态零拷贝(文件描述符→文件 / 网卡描述符),本身支持跨网络(如 Nginx 用它给远程客户端发静态文件);VSCode 远程读文件用不了sendfile,是因为数据需 SSH 协议封装(必须进用户态处理),而非sendfile“不能跨网络”;本地内核收到 TCP 包 → 交给用户态的 VS Code 远程插件 → 插件拆包(解 SSH 头),拿到纯 CPP 文件数据 → 把数据渲染到 VS Code 界面;
而 “打包成 TCP 数据包” 这个步骤,必须由云服务器上的应用程序在用户态完成(比如给数据加 TCP 头、拆分成符合 MTU 大小的包),这就注定了数据必须进用户态,哪怕你只是 “看一眼”,也绕不开这个 TCP 传输的核心流程,也就用不了
sendfile!就算你做修改,腾讯云内核收到的是修改的指令,数据拿到用户态完全一致,只不过多了在用户态处理新内容(比如校验、拼接)→ 调用
write把新数据从用户态写入内核 → 内核把数据刷到磁盘;以上这些都是内核后台做的,和你代码是否写零拷贝无关,用户无法感知,哪怕
cpp文件只写个输出hello也一样。为啥封装包(协议头 / 数据处理)必须在用户态做,内核做不了?
核心原因就一个:内核只负责 “通用的、标准化的底层传输”,不负责 “业务 / 应用层的自定义逻辑”
内核能做的:给数据加 TCP/IP 这类通用网络头、把包发 / 收、管理连接,这些是所有网络传输都要做的标准化操作;内核只认识 TCP/IP 这类通用协议的格式,但 SSH、HTTP、VS Code 远程协议这些应用层规则(比如 “开头 4 个字节表示请求类型:1 = 读文件,2 = 写文件”),是用户态程序(如 SSH 进程、VS Code 插件)提前内置的—— 内核没有这些规则,自然没法识别 “这串字节是读 XX.cpp 的请求” 还是 “修改文件的请求”。
比如云服务器内核知道 “要发一串字节到本地”,但它不知道 “这串字节是 XX.cpp 的内容,还是登录密码,还是其他指令”—— 必须由用户态的 SSH 进程(应用程序)来封装 / 解析这个 “业务标识”,内核只负责把封装好的包发出去。
所以可以看到,涉及到网卡,但完全和
sendfile无关。
再说个兜底 RAII,所有
close都可以去掉,查看代码
// RAII封装文件描述符:构造打开/持有fd,析构自动close class FileDescriptor { public: //带参构造 explicit FileDescriptor(int fd) : fd_(fd) {} ~FileDescriptor() { if (fd_ != -1) close(fd_); } // 析构自动关闭,RAII核心 // 禁用拷贝,避免重复close FileDescriptor(const FileDescriptor&) = delete; FileDescriptor& operator=(const FileDescriptor&) = delete; // 移动语义,支持转移所有权 FileDescriptor(FileDescriptor&& other) noexcept : fd_(other.fd_) { other.fd_ = -1; } FileDescriptor& operator=(FileDescriptor&& other) noexcept { if (this != &other) { if (fd_ != -1) close(fd_); fd_ = other.fd_; other.fd_ = -1; } return *this; } int get() const { return fd_; } // 获取原始fd private: int fd_ = -1; };RAII 的名字极其傻逼,直译就是“资源获取就是初始化”,但不管有没有 RAII,创建时都是立马获取资源,他妈的本质是析构是否手动的问题,名字应该叫自动析构,可是傻逼命名老头思路是:
你必须在对象初始化的时候把资源拿到手(比如构造函数里 open),别先创建空对象、后面再手动调函数拿资源; 只要你按 “初始化时拿资源” 这个规矩来,C++ 的析构语法就必然能帮你自动释放 ——名字抓的是 “必须遵守的前提”,但我们实际用的时候,只感受到了 “自动释放” 这个结果,所以才觉得名字扯淡。
位置:只需要在代码
int src_raw_fd = open(src_path.c_str(), O_RDONLY);后加一句FileDescriptor src_fd(src_raw_fd);即可:解释 RAII 代码:
构造函数:
explicit FileDescriptor(int fd) : fd_(fd) {}接收一个打开的文件描述符(如open返回的src_raw_fd),把它存到私有成员fd_里,完成 “资源获取”。析构函数:
~FileDescriptor() { if (fd_ != -1) close(fd_); }RAII 核心!析构函数是 C++ 编译器自动帮你调用的(你不用写调用代码),当src_fd/dst_fd这些对象出了copy_large_file函数的作用域(比如return/ 抛异常),编译器会自动执行~FileDescriptor(),不写就执行默认的,写了就执行你自定义的,然后函数里的if (fd_ != -1)只是在执行析构的这一刻做一次判断,不是持续检查,核心关联是:RAII 靠编译器自动触发,很巧妙也很简单。禁用拷贝:
FileDescriptor(const FileDescriptor&) = delete;(禁用拷贝构造函数)、FileDescriptor& operator=(const FileDescriptor&) = delete;(禁止用拷贝赋值运算符)防止拷贝对象导致多个实例持有同一个fd_,进而重复close触发系统错误(比如一个对象关了fd,另一个再关就会报错)。如果没写这两行禁用代码,你要是手贱写了:FileDescriptor src_fd(src_raw_fd); // src_fd持有fd=3 FileDescriptor src_fd2 = src_fd; // 拷贝!src_fd2也持有fd=3
当函数结束,src_fd 先析构 → close (3)(正常);
接着 src_fd2 析构 → 又执行 close (3)(fd=3 已经关了,系统直接报错);
这两行
= delete就是把src_fd2 = src_fd这种拷贝操作彻底禁了,编译器直接报错,不让你写这种找死的代码!
int a = 10;、int& b //给a起别名b。// 这是赋值运算符重载函数的完整原型拆解 FileDescriptor& // 返回值类型:当前FileDescriptor对象的引用 operator= // 函数名(C++规定的赋值运算符重载标识) ( const FileDescriptor& // 参数类型:const修饰的FileDescriptor对象引用 ) // 无函数体(= delete仅表示禁用,此处只关注原型本身)
FileDescriptor& operator=(const FileDescriptor&)是 C++ 中赋值运算符重载函数的标准原型,作用是定义FileDescriptor类对象之间使用=赋值时的具体行为:返回值FileDescriptor&用于支持连续赋值(如fd3=fd2=fd1),参数const FileDescriptor&是为了以只读、无拷贝的方式接收等号右侧的对象,这个原型是 C++ 语法对赋值运算符重载的强制规范,所有自定义类的赋值运算符重载都遵循此格式。移动语义:
涉及两个部分,
查看代码
//上段 —— 移动构造函数,只抢资源+置空,无close FileDescriptor(FileDescriptor&& other) noexcept : fd_(other.fd_) { other.fd_ = -1;// 旧对象fd置空,避免析构时close } //下段 —— 移动赋值运算符,先关自己的旧fd,再抢资源+置空 FileDescriptor& operator=(FileDescriptor&& other) noexcept { if (this != &other) { if (fd_ != -1) close(fd_); fd_ = other.fd_; other.fd_ = -1; } return *this; } //上下段是我为了写博客方便称呼起的名字,实际移动语义完全没有上下段的叫法,就单纯一个整体代码而已上段里:
移动构造里,自己(新对象)不用
close:因为新对象刚创建,fd_默认是 - 1,无有效文件描述符可关;对方(源对象)也不用主动close:核心是移动是 “资源转移”,不是拷贝,源对象要把fd_交出去后置为 - 1,后续源对象析构时,析构函数检测到fd_ == -1就不会close,最终由新对象接管并负责close资源。但我理解
close不是说先解耦解除fd变量和实际描述符的绑定吗?
close是「内核级解耦 + 释放」,不是「用户态解耦」,close的本质是告诉内核:我这个进程不用这个fd了,内核可以把fd和文件的绑定关系解除,甚至释放文件资源(无其他引用时)。它是进程跟内核的 “解绑申请”,还带资源释放,不是单纯的变量操作!而移动要的是「other 用户态断联」,不是「内核级解耦」,就等于在用户态让other彻底忘了这个编号,后续other析构、操作都碰不到内核fd,一旦close(other.fd_)就全完了!内核直接把fd_和文件的绑定解了、资源放了,新对象手里的fd_编号就成了 “废号”!如果说
close,那如果已经给this_fd赋值了,那close(other.fd)也会使得this_fd失效,如果other.fd是 -1,close报错。下段里的那个
close是关旧的完全不用。越琢磨越有味道!!我突然发现不就是有点像刷算法手写的结构体成员那感觉吗!
就相当于俩对象,每个对象结束都会析构,我加个成员变量,来告诉说对象结束是否
close,不就是分离吗!就比如说我有继承人,自己修炼的武学是有神源珠,你死了如果没找到继承人直接连你本人尸体加珠都火化,你找到继承人,就只火化你本人,珠子别动(极致比喻,这个总结无价之宝)
RAII 里涉及到的移动语义,
FileDescriptor(FileDescriptor&& other) noexcept及赋值重载。允许 “转移” 文件描述符的所有权(比如函数返回该对象),转移后原对象的fd_设为 - 1,避免原对象析构时误关已转移的 fd。科普:
- C++ 两个地址不互通,栈帧独立,但编译器会知道外部接收对象
fd1的栈内存地址,直接拷贝过去然编译器后搞个优化的概念,默认开启:
RVO(返回值优化) → 优化「
return匿名临时对象」(比如return FileDescriptor(fd););NRVO(具名返回值优化) → 优化「
return有名局部对象」(比如return tmp_fd;);优化指的是砍掉了「在函数栈帧创建局部对象
tmp_fd」+「拷贝 / 移动tmp_fd到 fd1」+「析构tmp_fd」这三个无意义操作。具体移动是从 C++ 11 开始才有的,改动只是把拷贝变为移动,和是否优化无关。
重点:但这里有个极大误解,说“移动 / 拷贝不改变规则”,我一直以为是比如无优化是
a → tmp_fd → b,有优化砍掉tmp_fd是a → b,然后该移动该拷贝照常,但其实不是,有优化是连 b 都没有,直接在 a 内存上开,不会有俩变量 / 对象。
C++17 语言规则层面要求编译器直接在外部接收对象
fd1的内存地址上构造函数内部的局部对象return。即fd1在main栈里有固定的内存地址(比如 0x100);编译
get_fd时会提前知道 “这个函数的返回值要给main里的fd1”,于是直接命令 CPU:不在get_fd的栈帧里创建tmp_fd,而是直接在 0x100(fd1的地址)上创建tmp_fd;这样tmp_fd从诞生起就占着fd1的内存位置,get_fd执行完,tmp_fd的所有数据(比如 fd_=3)就直接留在 0x100,自然归fd1所有,不用任何拷贝 / 中转。现在一般 GCC 都是默认支持 C++ 17。
想关闭优化也关不掉(其实也可通过编译器显式参数关闭),都是直接原地搞数据,因为这是语言层面的规定,不是编译器层面的。但如果老旧编译器、根据不同条件返回不同的变量等等都不会触发优化,所以搞了个移动语义给 “编译器没开 / 没触发
RVO优化” 的场景兜底,哪怕没法直接在fd1地址创建tmp_fd,也能通过移动(而非拷贝)把fd通过tmp_fd转给fd1,且保证原tmp_fd析构时不重复close。由于我看到移动语义这些就很烦,无意间自创极其适合我的高潮提示词:
查看代码
我发现自己对类的基本用法了解,但对FileDescriptor(const FileDescriptor& other) 和更难的就懵了!我想的是你先别解释深浅拷贝和什么移动语义因为我懂了,唯独每次看这些写法都好生疏,别扭!你给我灵活点别死板罗列知识!让我尽快掌握这个! 解释别太面向面试,那根本不是学知识!比如“只记”这些字眼!!我想真正学知识!但不学偏冷深!懂吗?求其上的其中,求其中的其下。总是各种应试去背,我自己背的也痛苦,学的稀里糊涂,不透彻,很难受!你解释完我可以直接不看面试高频题,但却能秒杀所有高频题这才是有意义的。通过这个学懂了最烦最复杂的语法,开始说语法:
查看代码
class FileDescriptor { public: int fd; // 构造 FileDescriptor(int fd_) : fd(fd_) { cout << "构造:fd=" << fd << endl; } // 移动构造(抢临时对象的资源) FileDescriptor(FileDescriptor&& other) : fd(other.fd) { other.fd = -1; // 把临时对象的fd置空 cout << "移动构造:抢临时对象的fd=" << fd << endl; } // 禁用拷贝 FileDescriptor(const FileDescriptor&) = delete; // 析构 ~FileDescriptor() { if (fd != -1) cout << "析构:close fd=" << fd << endl; else cout << "析构:临时对象已被移空,fd=-1" << endl; } }; FileDescriptor create_fd() { FileDescriptor tmp(3); // 造tmp return tmp; // C++11未开RVO时,先造临时对象,把tmp移给临时对象 } int main() { FileDescriptor fd1 = create_fd(); // 把临时对象移给fd1 }C++11 未开 RVO 时的执行逻辑(纯理论流程):
1、create_fd 里造 tmp(fd=3);
2、
create_fd()函数里执行return tmp;时,C++11 未开 RVO(返回值优化)的情况下,编译器会先创建一个「函数返回的临时对象」,然后调用FileDescriptor的移动构造,把tmp的资源转移给这个临时对象。此时移动构造的other就是tmp,执行other.fd = -1→ 直接把tmp的 fd 置为 - 1。// 移动构造函数里的核心行,第一次置-1的源头 FileDescriptor(FileDescriptor&& other) : fd(other.fd) { other.fd = -1; // other就是tmp,这行让tmp.fd=-1 cout << "移动构造:抢临时对象的fd=" << fd << endl; }3、main()函数里执行FileDescriptor fd1 = create_fd();时,create_fd()返回的那个临时对象,会被用来初始化fd1,编译器再次调用移动构造,把这个临时对象的资源转移给fd1。此时移动构造的other就是「函数返回的临时对象」,执行other.fd = -1→ 把这个临时对象的 fd 置为 - 1。// 还是同一个移动构造函数,第二次置-1的源头 FileDescriptor(FileDescriptor&& other) : fd(other.fd) { other.fd = -1; // other就是返回的临时对象,这行让它的fd=-1 cout << "移动构造:抢临时对象的fd=" << fd << endl; }4、析构 tmp(fd=-1)→ 析构临时对象(fd=-1)→ 最后析构
fd1(fd=3)。核心就一个点:C++11 里临时对象的传递全程走移动,不是拷贝,临时对象的资源会被 “抢” 走,而非复制,这是移动语义的核心,临时对象本身就是为了传递资源存在的,移动就是为了让这个过程无开销。
这个流程的事说完了,继续说其他语法,直接深入抽插,一直追溯到女娲补天盘古开天辟地:
一、先想透:C++ 为什么要设计 “拷贝构造 / 移动构造”?
编程的核心是「管理资源」(比如 fd、堆内存、文件句柄),而类是「封装资源的容器」。
当你用一个类对象去创建 / 赋值另一个对象时,必然要面对:新对象该如何处理原对象的资源?
拷贝构造、移动构造,本质就是 C++ 给你提供的「两种资源传递规则」,不是凭空造的语法,而是为了解决 “资源该怎么给新对象” 这个实际问题。
以你熟悉的
FileDescriptor为例:你创建了
f1(3),现在要写FileDescriptor f2 = f1;,编译器必须知道:f2 该拿 f1 的 fd 怎么办?是自己新开一个(深拷贝)、直接用同一个(浅拷贝)、还是把 f1 的 fd 拿走(移动)?—— 这就是拷贝 / 移动构造要解决的核心问题,语法只是这个问题的 “答案载体”。二、拆解
FileDescriptor(const FileDescriptor& other):理解“拷贝构造”的本质先抛开 “深浅拷贝” 这些标签,看这个函数的每一部分到底在表达什么:
// 拷贝构造函数的完整语义拆解 FileDescriptor(const FileDescriptor& other) // 1. 返回值:无(构造函数本身就没有返回值) // 2. 函数名:和类名相同(构造函数的基本规则) // 3. 参数:const FileDescriptor& other // - FileDescriptor&:表示“传进来的是一个已存在的、可复用的FileDescriptor对象”(不是临时的) // - const:表示“我承诺不修改传进来的这个原对象”(这是拷贝的基本准则——拷贝不该破坏原对象) // 4. 函数体:你要写的“资源传递规则”从 “资源管理” 角度理解:
这个函数的设计初衷,就是告诉你:当用一个已存在、不想被修改的
FileDescriptor对象(比如 f1)去创建新对象(比如 f2)时,新对象该如何处理 f1 的资源。
如果你在函数体里写
this->fd = open(...)(新开 fd):本质是 “我为新对象创建独立资源,不影响原对象”—— 这就是深拷贝,是符合资源管理逻辑的 “正确规则”;如果你在函数体里写
this->fd = other.fd(直接用):本质是 “新对象和原对象共用资源”—— 这是浅拷贝,违反了 “fd 这类独占资源该独占” 的逻辑,所以是错的;如果你写
FileDescriptor(const FileDescriptor&) = delete;:本质是 “我拒绝这种资源传递方式”—— 因为 fd 这类资源,“用已存在的对象拷贝创建新对象” 本身就不合理(要么新开 fd 开销大,要么共用 fd 会崩),所以直接禁用。关键理解:
const FileDescriptor&这个参数形式,只是 “约定了传参的规则”(传已存在、不修改的原对象),和 “深 / 浅拷贝” 无关 —— 深 / 浅是你在函数体里定义的 “资源规则”,不是参数形式决定的。三、拆解
FileDescriptor(FileDescriptor&& other):理解 “移动构造” 的本质同样从 “资源管理” 角度,而非 “记 && 符号”:
FileDescriptor(FileDescriptor&& other) // 1. 参数:FileDescriptor&& other // - &&:C++11新增的“右值引用”,核心语义是“这个对象是临时的/即将被销毁的,你可以放心拿走它的资源” // - 没有const:因为要修改原对象(把它的fd置空),const会限制这个操作 // 2. 函数体:“拿走原对象的资源,然后让原对象变成‘无害状态’”设计初衷:
为什么要加这个语法?因为之前的拷贝构造有个问题:
如果原对象是临时的(比如
FileDescriptor f2 = create_fd();里的返回值),它马上就要被销毁了,你再为 f2 新开一个 fd(深拷贝)完全是浪费 —— 既然原对象的资源马上没用了,不如直接 “转给” f2,既省开销,又避免资源浪费。所以
&&的本质是:编译器告诉你 “这个对象的资源可以放心拿,它马上就没了”,你只需要把资源所有权转移,不用再做无用的深拷贝。对应
FileDescriptor的移动构造:FileDescriptor(FileDescriptor&& other) { this->fd = other.fd; // 拿走临时对象的fd(它马上销毁,不用怕影响它) other.fd = -1; // 让原对象变成无害状态(析构时不会重复close) }四、跳出语法:理解 “为什么 fd 类要禁用拷贝、只留移动”
fd 的特性:独占性(一个 fd 只能被一个对象管理,否则重复 close 会崩)、创建成本(open 文件有开销);
拷贝构造的问题:要么深拷贝(新开 fd,浪费开销),要么浅拷贝(共用 fd,必崩)—— 两种选择都不合理,所以直接禁用;
移动构造的优势:既不新开 fd(无开销),又能保证独占性(拿走后原对象置空)—— 完全匹配 fd 的资源特性。
换个场景你就懂:如果是
Point类(只有 int x/y,无独占资源),就没必要禁用拷贝,也没必要写移动构造 —— 因为浅拷贝(直接复制 x/y)完全安全,且没有开销。你现在可以试着问自己:如果我封装的是 “堆上的字符串(
char*)”,它的拷贝构造该怎么写?移动构造该怎么写?—— 不用记模板,只从 “资源该怎么传递” 出发思考,比如:
拷贝构造:新对象要自己开一块堆内存,把原字符串复制过去(深拷贝,因为要独占);
移动构造:拿走原对象的 char*,把原对象的指针置空(避免重复 free);
Q:然后具体咋应用深浅拷贝移动、拷贝、赋值这些?
A:
一、先统一核心认知:所有操作的本质是「资源传递规则」
不管是拷贝、移动还是赋值,本质都是当一个对象向另一个对象传递资源时,你定义的 “规则” —— 规则的合理性,只取决于你封装的「资源特性」(是否独占、是否有创建 / 销毁成本)。
先明确两类核心资源(后续所有规则都围绕这两类展开):
无独占性资源:int/char/Point 结构体(仅存简单数据,无需要手动销毁的资源);
独占性资源:fd / 堆内存 char*/std::vector(有创建 / 销毁成本,且只能被一个对象管理)。
二、拷贝相关:拷贝构造 + 拷贝赋值(核心:不修改原对象,新对象独立)
1. 拷贝构造(
类名(const 类名& other))
设计初衷:用一个「已存在、不想被修改」的对象,创建新对象时的资源传递规则;
核心要求:原对象必须保持不变,新对象的资源状态和原对象一致。
(1)浅拷贝(拷贝构造的一种实现)
适用场景:仅无独占性资源的类;
关键代码(以 Point 为例):
// 浅拷贝构造(对Point完全合理) Point(const Point& other) : x(other.x), y(other.y) {}- 逻辑本质:直接复制原对象的 “数据值”,不创建新资源(因为无需要销毁的资源,复制值就够);
为什么对 Point 合理:x/y 是简单数据,多个对象持有相同值,析构时无任何副作用(不用销毁 x/y)。
(2)深拷贝(拷贝构造的另一种实现)
适用场景:独占性资源的类(必须保证新对象有独立资源);
关键代码(以堆内存字符串为例):
// 深拷贝构造(对堆内存char*必须这么写) MyString(const MyString& other) { // 第一步:为新对象创建独立的堆内存(核心:新资源) this->len = other.len; this->str = new char[len + 1]; // 第二步:复制原对象的数据到新资源(保证状态一致) strcpy(this->str, other.str); }逻辑本质:为新对象「重新创建一份和原对象一模一样的独占资源」,原对象资源不受影响;
为什么必须这么写:如果直接复制
char*(浅拷贝),新对象和原对象共用同一块堆内存,析构时会重复free,导致崩溃。2. 拷贝赋值(
类名& operator=(const 类名& other))
设计初衷:两个「已存在」的对象之间传递资源(不是创建新对象);
核心区别于拷贝构造:赋值的目标对象已有资源,必须先处理旧资源,再应用新规则;
关键要求:防止自赋值(
this == &other),否则会先销毁自己的资源,再复制时出错。深拷贝赋值(独占性资源必写,关键代码):
MyString& operator=(const MyString& other) { // 第一步:防止自赋值(核心,不能省略) if (this == &other) return *this; // 第二步:销毁当前对象的旧资源(核心,否则内存泄漏) delete[] this->str; // 第三步:深拷贝原对象的资源(和深拷贝构造逻辑一致) this->len = other.len; this->str = new char[len + 1]; strcpy(this->str, other.str); return *this; // 返回自身,支持链式赋值(如a = b = c) }逻辑本质:先清掉自己的旧资源,再按深拷贝规则拿原对象的资源,保证资源独立且无泄漏。
三、移动相关:移动构造 + 移动赋值(核心:拿临时对象的资源,高效且安全)
1. 移动构造(
类名(类名&& other))
设计初衷:针对「临时 / 即将销毁」的对象(右值),避免无用的深拷贝,直接转移资源所有权;
核心语义:
&&(右值引用)是编译器告诉你 “这个对象的资源可以放心拿,它马上就销毁了”;关键要求:修改原对象(置空 / 置无效),让它析构时无副作用。
关键代码(堆内存字符串的移动构造):
MyString(MyString&& other) { // 第一步:拿走原对象的资源(核心,无任何创建成本) this->str = other.str; this->len = other.len; // 第二步:原对象置空(核心,不能省略) other.str = nullptr; other.len = 0; }逻辑本质:把临时对象的资源 “抢过来”,原对象变成 “空壳”—— 既省了创建新资源的成本,又避免了重复销毁的问题。
2. 移动赋值(
类名& operator=(类名&& other))
设计初衷:两个已存在对象之间,传递「临时对象的资源」;
核心逻辑:先销毁目标对象的旧资源,再转移临时对象的资源,最后置空原对象。
查看代码
MyString& operator=(MyString&& other) { // 第一步:防止自赋值(虽然临时对象自赋值概率低,但规范写法不能省) if (this == &other) return *this; // 第二步:销毁当前对象的旧资源 delete[] this->str; // 第三步:转移资源 this->str = other.str; this->len = other.len; // 第四步:原对象置空 other.str = nullptr; other.len = 0; return *this; }示例:fd 类的规则选择(关键代码)
class FileDescriptor { int fd = -1; public: // 禁用所有拷贝(因为深浅拷贝都不合理) FileDescriptor(const FileDescriptor&) = delete; FileDescriptor& operator=(const FileDescriptor&) = delete; // 提供移动构造(核心) FileDescriptor(FileDescriptor&& other) { this->fd = other.fd; other.fd = -1; // 置空,避免重复close } // 提供移动赋值(核心) FileDescriptor& operator=(FileDescriptor&& other) { if (this == &other) return *this; close(this->fd); // 销毁旧fd this->fd = other.fd; other.fd = -1; return *this; } };逻辑本质:fd 是独占资源,拷贝要么浪费(深拷贝)要么崩溃(浅拷贝),所以禁用拷贝;移动能直接转移 fd 所有权,且置空后无副作用,是唯一合理的选择。
四、关键避坑点(从 “理解逻辑” 出发,不是记坑)
浅拷贝不是错,只是用错场景:对无独占资源的类,浅拷贝是最优选择;错的是把浅拷贝用在独占资源类上;
移动构造必须置空原对象:不是 “语法要求”,而是 “逻辑要求”—— 如果不置空,原对象析构时会销毁已经转移的资源;
赋值必须先处理旧资源:不管拷贝赋值还是移动赋值,目标对象已有资源,不销毁会导致内存泄漏(堆内存)/ 重复 close(fd);
总结:
拷贝 / 移动的核心是「资源传递规则」,规则是否合理取决于「资源特性」(是否独占、有无创建成本);
浅拷贝 = 复制值(无新资源),深拷贝 = 新建独立资源,移动 = 转移资源所有权(原对象置空);
- 赋值和构造的核心区别:赋值要先销毁目标对象的旧资源,构造是从零创建新对象。
Q:
MyString& operator=(const MyString& other)这里的为啥是返回值是这个A:
一、先抛结论:返回值设计不是 “语法强制要求”,而是「为了让赋值操作符合程序员的使用习惯,支持链式调用」,且返回引用是为了「避免不必要的拷贝(深拷贝)」。二、第一步:理解 “链式赋值”(最核心的使用场景)
你平时写 int 赋值时,肯定会这么写:
int a, b, c; a = b = c = 10; // 链式赋值,从右往左执行:c=10 → b=c → a=b这种写法是所有人的使用习惯,C++ 设计类的赋值运算符时,就是要让自定义类型(比如 MyString)也能支持这种 “符合直觉” 的写法。
如果赋值运算符不返回值(返回 void),会发生什么?// 错误示范:返回void的赋值运算符 void operator=(const MyString& other) { /* ... */ } // 调用时直接报错,因为b = c的结果是void,无法赋值给a MyString a, b, c; a = b = c; // 编译失败!如果赋值运算符返回值而非引用(返回
MyString),会发生什么?// 不推荐:返回值(值拷贝) MyString operator=(const MyString& other) { /* 深拷贝逻辑 */ return *this; // 返回当前对象的副本(会触发拷贝构造,做一次深拷贝) } MyString a, b, c; a = b = c; // 能运行,但b = c会返回b的副本,再赋值给a——多了一次无意义的深拷贝(堆内存复制),开销大!只有返回引用(MyString&),才能兼顾 “支持链式赋值”+“无额外开销”:// 正确写法:返回引用 MyString& operator=(const MyString& other) { /* 深拷贝逻辑 */ return *this; // 返回当前对象本身(无拷贝,直接引用) } MyString a, b, c; a = b = c; // 执行逻辑: // 1. c先赋值给b → 返回b的引用 // 2. 再把b的引用赋值给a → 无任何额外拷贝,和int的链式赋值逻辑完全一致三、第二步:理解
return *this的逻辑(关键细节不省略)
this是 C++ 里的「隐含指针」,指向当前调用赋值运算符的对象(比如b = c中,this指向 b)。
*this:解引用指针,拿到当前对象的 “本体”;- 返回
*this的引用:让调用者直接操作当前对象,而非它的副本 —— 这是实现 “无开销链式赋值” 的核心。关键代码拆解(结合之前的深拷贝赋值):
MyString& operator=(const MyString& other) { if (this == &other) return *this; // 自赋值保护:直接返回自己 delete[] this->str; // 销毁旧资源 this->len = other.len; this->str = new char[len + 1]; strcpy(this->str, other.str); return *this; // 返回当前对象的引用(比如b = c时,返回b的引用,供a赋值) }四、延伸:移动赋值为什么也返回
MyString&?和拷贝赋值逻辑完全一致 —— 为了支持链式移动赋值,且无额外开销:
MyString& operator=(MyString&& other) { if (this == &other) return *this; delete[] this->str; this->str = other.str; this->len = other.len; other.str = nullptr; return *this; // 同样返回引用,支持a = b = std::move(c)这类链式移动赋值 }五、核心逻辑总结(无冗余,只讲本质)
返回
MyString&的核心目的:支持「链式赋值」(符合程序员使用 int 等内置类型的习惯);返回引用而非值的关键原因:避免返回时触发拷贝构造(深拷贝),减少无意义的资源开销;
return *this的本质:返回当前对象的 “本体引用”,让链式赋值操作的是原对象而非副本。Q:我看你例子都是堆字符串?而不是类对象?
A:
我用堆字符串(
char*)举例,不是避开类对象,而是堆字符串是 “独占性资源类” 的极简代表,它的逻辑能 100% 套用到任意类对象上,且比直接讲复杂类对象更易抓核心(无多余逻辑干扰)。接下来我把「堆字符串的深浅拷贝 / 移动 / 赋值逻辑」直接平移到自定义类对象上,只换例子不换核心逻辑,用「类对象(比如你熟悉的
FileDescriptor/ 自定义Person类)」讲透,代码只给关键部分,不省略核心:一、先明确:堆字符串 ≡ 类对象的独占资源(逻辑完全等价)
堆字符串的
char*(需要new/delete),和类对象里的fd(需要open/close)、std::vector(内部堆内存)、甚至嵌套的自定义类对象(比如Person里包含MyString),本质都是「需要手动管理的独占资源」—— 所以深浅拷贝 / 移动 / 赋值的规则完全一样,只是 “资源创建 / 销毁的具体操作” 不同。二、用「类对象(FileDescriptor)」重讲核心操作(替换堆字符串,逻辑不变)
以你最熟悉的
FileDescriptor为例(持有 fd 独占资源),对应之前堆字符串的所有操作:1. 深拷贝构造(类对象版)
堆字符串的深拷贝是
new char[] + strcpy,FileDescriptor 的深拷贝是open()新建 fd(核心都是「创建独立资源」):// FileDescriptor的深拷贝构造(关键代码) FileDescriptor(const FileDescriptor& other) { // 核心:为新对象创建独立的fd资源(替代堆字符串的new char[]) this->fd = open(other.path, O_RDONLY); this->path = other.path; // 原对象other的fd不变,新对象fd独立——和堆字符串深拷贝逻辑完全一致 }2. 拷贝赋值(类对象版)
堆字符串的拷贝赋值是
delete[] + new char[],FileDescriptor 的拷贝赋值是close() + open()(核心都是「销毁旧资源→创建新资源」):// FileDescriptor的拷贝赋值(关键代码) FileDescriptor& operator=(const FileDescriptor& other) { if (this == &other) return *this; // 自赋值保护(和堆字符串一致) // 第一步:销毁当前对象的旧资源(替代堆字符串的delete[]) if (this->fd != -1) close(this->fd); // 第二步:创建新的独立资源(替代堆字符串的new char[]) this->fd = open(other.path, O_RDONLY); this->path = other.path; return *this; // 返回引用,支持链式赋值(和堆字符串一致) }3. 移动构造(类对象版)
堆字符串的移动是「拿 char* + 置空」,FileDescriptor 的移动是「拿 fd + 置空」(核心都是「转移资源 + 原对象置空」):
// FileDescriptor的移动构造(关键代码) FileDescriptor(FileDescriptor&& other) { // 第一步:拿走原对象的资源(替代堆字符串的this->str = other.str) this->fd = other.fd; this->path = other.path; // 第二步:原对象置空(替代堆字符串的other.str = nullptr) other.fd = -1; other.path = nullptr; }4. 移动赋值(类对象版)
堆字符串的移动赋值是「delete [] + 拿 char* + 置空」,FileDescriptor 是「close () + 拿 fd + 置空」(核心不变):
// FileDescriptor的移动赋值(关键代码) FileDescriptor& operator=(FileDescriptor&& other) { if (this == &other) return *this; // 销毁旧资源(替代delete[]) if (this->fd != -1) close(this->fd); // 转移资源 this->fd = other.fd; this->path = other.path; // 原对象置空 other.fd = -1; other.path = nullptr; return *this; // 返回引用,支持链式赋值(和堆字符串一致) }核心逻辑:嵌套类对象的资源管理,本质是「外层类调用内层类的深浅拷贝 / 移动操作」,规则完全继承内层类 —— 这也是为什么我先讲堆字符串(最基础的独占资源类),再讲嵌套类对象,循序渐进不绕。四、核心结论(只讲本质,无冗余)
1、我用堆字符串举例,是因为它是「独占资源类」的最小单元,逻辑最简单、无多余干扰,能最快抓核心;
2、所有「持有独占资源的类对象」(fd/vector/ 嵌套类),深浅拷贝 / 移动 / 赋值的核心规则完全一致:
深拷贝 = 销毁旧资源 → 为新对象创建独立资源;
移动 = 销毁旧资源 → 拿走原对象资源 → 原对象置空;
赋值返回引用 = 支持链式赋值 + 无额外拷贝开销;
3、唯一的区别只是「资源创建 / 销毁的具体操作」(fd 用 open/close,堆字符串用 new/delete),但规则本身不变。
嘎嘎透彻!!
然后说上面的那个上段移动语义咋用?主要是给涉及到return FileDescriptor用的,比如此文搜“100 次,所”,那个代码是return tmp_fd会调用移动构造(本质是创造一个新对象),把tmp_fd的 fd 所有权转移到函数外部的fd1/fd2/fd100,同时tmp_fd的 fd 被设为 - 1—— 函数结束时tmp_fd析构不会 close fd,只有外部的fd1/fd2/fd100析构时才 close,避免重复close。这个是比较简单的
return问题,那些return是int啥的基础类型,拷贝成本低,且无重复释放风险,直接赋值 / 拷贝即可; 只有return持有资源 (fd/malloc等)+ 禁用拷贝的 RAII 类对象才需要手动写移动构造,避免拷贝报错 + 资源重复释放。然后再说下段那个
FileDescriptor& operator=(FileDescriptor&& other) noexcept { ... return *this; }(移动赋值运算符),它的作用是支持“已有FileDescriptor对象之间转移 fd 所有权”,比如:查看代码
// 已有对象定义 FileDescriptor a(open("file1.txt", O_RDONLY)); // a持有file1的fd FileDescriptor b(open("file2.txt", O_RDONLY)); // b持有file2的fd // 移动赋值:将b的fd所有权转移给a a = std::move(b); // 此时:a持有file2的fd,b的fd被置为-1(不会重复close)这种在下段里必须关闭。而发现上段是不需要关闭的,因为创造的是新的,不涉及到新旧需要关旧的事。
高潮大串联,零零碎碎全通了(其实追问的相当痛苦)
关于资源:
FileDescriptor的资源:就是操作系统分配的文件描述符(fd 数值,如 3),以及对应的文件句柄、内核态文件关联信息;字符串 / 容器的资源:是堆上分配的内存块(如
std::string的char*指向的堆内存);这些资源区别于
int的纯内存字节,是需要手动申请 / 释放(如open/close、malloc/free)的系统 / 内存资源,复制就是多一份相同资源,释放时会冲突。
return num这里如果是int,只是数值拷贝,优化版本或者移动语义只是节省数据的拷贝而已。而如果是FileDescriptor tmp_fd返回对象,则拷贝这个笼统的说法,本质是移动构造。RVO 优化省的不只是数据拷贝,更是 “临时对象的构造 + 析构”。综上:
这个移动语义就是没优化的时候,
return不报错用的,因为没优化return的原始规则就是必须做拷贝,而拷贝出的新对象和原对象,都持有同一个fd,析构时会重复close同一个fd,这是致命错误。所以你必须写禁止拷贝构造,那此时编译器没优化去拷贝就会报错。所以移动语义就是为了编译器优化失效时候,走移动语义这个传递,而不拷贝使得return一定不拷贝构造,即一定不报错。还能避免拷贝导致的重复close问题。然后继续说语法,可能和上面有重复的,但我关注点不同,再加上学的头大了,之前叙说的是最基础的,现在又思考了其他的东西,侧重点不同:
浅拷贝 = 浅拷贝的「拷贝构造函数」(新对象创建时用)
浅拷贝版赋值运算符 = 浅拷贝逻辑套在「赋值运算符重载」里(老对象赋值时用)
同一个浅拷贝逻辑,用在两个不同的 C++ 行为上,仅此而已!
1. 单纯浅拷贝(拷贝构造函数)→ 这就是纯纯的浅拷贝!
场景:新对象诞生,用已有对象初始化
FileDescriptor b = a;/FileDescriptor b(a);// 单纯浅拷贝 = 浅拷贝的拷贝构造函数(新对象创建) FileDescriptor(const FileDescriptor& other) { this->fd_ = other.fd_; // 只拷fd编号,共享资源 → 浅拷贝核心 }2. 你写的浅拷贝版赋值运算符 → 老对象赋值用场景:两个对象都已存在,执行赋值
b = a;// 浅拷贝版赋值运算符(老对象赋值) FileDescriptor& operator=(const FileDescriptor& other) { if (this != &other) { this->fd_ = other.fd_; // 同一个浅拷贝逻辑,换个地方用 } return *this; }区别:
单纯浅拷贝:创建新对象时的浅拷贝,用「拷贝构造函数」
你的浅拷贝版 operator=:已有对象赋值时的浅拷贝,用「赋值运算符重载」
俩代码里的核心逻辑全是
fd_ = other.fd_,完全一样,只是触发时机不同!Q:
FileDescriptor b = a;和FileDescriptor b(a);?A:
FileDescriptor b = a;和FileDescriptor b(a);完全等价,只干一件事:调用拷贝构造函数,无任何其他逻辑!这里的=不是赋值运算符(需要都先创建过),只是 C++ 初始化新对象的语法符号,和b(a)写法仅格式不同,底层执行一模一样!只写拷贝构造,验证两种写法都触发它:查看代码
class FileDescriptor { public: int fd_ = -1; // 仅定义拷贝构造函数(参数是const 本类&) FileDescriptor(const FileDescriptor& other) { this->fd_ = other.fd_; // 浅拷贝核心逻辑:只拷fd编号 // 加打印,直观看到触发了哪个函数 printf("触发:拷贝构造函数\n"); } // 普通构造(给a对象初始化用) FileDescriptor(int fd) : fd_(fd) {} }; int main() { FileDescriptor a(3); // 调用普通构造,创建a对象(fd_=3) —— 属于普通构造,涉及到资源的fd、堆内存也可以 FileDescriptor b(a); // 写法1:直接括号初始化 —— 属于浅拷贝,涉及到资源的fd、堆内存就不行 FileDescriptor c = a; // 写法2:=号初始化 —— 属于浅拷贝,涉及到资源的fd、堆内存就不行 // 运行结果:打印两次「触发:拷贝构造函数」→ 俩写法都走拷贝构造 } 备注1: 如果显式删除拷贝构造函数(C++11语法) FileDescriptor(const FileDescriptor& other) = delete; 则写法1、2都报错 ----------------------------------------- 备注2: 增加拷贝赋值运算符重载(已有对象赋值用,参数返回值固定格式) FileDescriptor& operator=(const FileDescriptor& other) { //编译器自动把 c 的地址传给 this,this = &c。把 a 绑定到参数 other,other 是 a 的别名 /* this 是指向当前调用对象的指针,比如 c 调用时,this = &c *this 解引用this指针,拿到当前对象本体,即 c 本身 this->fd_ 通过指针访问对象成员,等价于c.fd_ return *this;// 返回对象本体,函数返回值类型 FileDescriptor& 会把它转为引用 */ // 1. 自我赋值检查(必加,避免自己赋值给自己导致错误) if (this != &other) { // 2. 核心赋值意图:把other的fd_值赋给当前对象的fd_ this->fd_ = other.fd_; printf("触发:赋值运算符\n"); } // 3. 返回当前对象引用(支持连续赋值,如fd3=fd2=fd1) return *this; } 则: FileDescriptor a(open("test.txt", O_RDONLY)); // 普通构造 FileDescriptor a(3); // 普通构造:a.fd_=3 // 第一类:新对象初始化 → 都触发拷贝构造 FileDescriptor b(a); // 触发拷贝构造 FileDescriptor c = a; // 触发拷贝构造 // 第二类:已有对象赋值 → 触发赋值运算符(c已经创建完成,是老对象) c = a; //触发拷贝赋值运算符,编译器转成 c.operator=(a),调用 c 的 operator=函数,执行上面函数体逻辑,c 的 fd_被替换成 a 的fd_值 ------------------------------------------------- 备注3: 以上无论【拷贝构造】,还是【拷贝赋值运算符】都是基于浅拷贝,理论上全错。 只适用于普通 int/string/ 自定义无堆 / 系统资源的成员变量。 拷贝赋值: 错误1:this 旧 fd 没关 → fd 资源泄漏 错误2:this 和 other 共用 fd → 析构时双重 close 崩程序 正确都是用移动的拷贝和赋值,为了学知识,深拷贝写法如下: class FD { public: int fd = -1; const char* path = nullptr; // 存文件路径,用于深拷贝重新打开 // 普通构造:打开文件+存路径 FD(const char* p) : path(p) { fd = open(path, O_RDONLY); cout << "打开fd: " << fd << endl; } // 深拷贝构造:重新打开文件,创建独立fd FD(const FD& other) { this->path = other.path; this->fd = open(this->path, O_RDONLY); // 关键:重新打开,不共用 cout << "深拷贝构造:新打开fd=" << fd << endl; } // 深拷贝赋值运算符:先关自己的fd,再重新打开 FD& operator=(const FD& other) { if (this != &other) { // 第一步:关闭当前对象原有fd,避免资源泄漏 if (this->fd != -1) close(this->fd); // 第二步:重新打开文件,创建独立fd,不共用 this->path = other.path; this->fd = open(this->path, O_RDONLY); cout << "深拷贝赋值:新打开fd=" << fd << endl; } return *this; } // 析构:关闭自己的独立fd ~FD() { if (fd != -1) { close(fd); cout << "关闭fd: " << fd << endl; } } }; int main() { FD a("test.txt"); // 普通构造,打开fd(比如3) FD b = a; // 深拷贝构造,新打开fd(比如4),为了跑遍深拷贝流程,其实完全等同 FD b("test.txt"); b = a; // 深拷贝赋值,先关4,再新打开fd(比如5),相当于还是重新开个,b是4,a是3,然后b=a,a还是3,b是5 }术语:
a、构造:创建新对象(给对象 “出生” 用);
b、赋值运算符:给已存在的对象赋值(对象 “出生后” 修改用)。
c、拷贝:留原品造副本
d、移动:直接抢原品,不留副本
如果对于赋值来说,深拷贝是原还在,移动的是原没了。
组合:
a / b 二选一配 c / d 二选一。C++ 没赋值构造。
移动构造:是构造函数(和
explicit FileDescriptor(int fd)一类),没有返回值,通过初始化列表直接给fd_赋值,因为是新对象,代码里不用关this的旧fd(新对象 fd_默认 - 1,本就无有效资源);移动赋值:是赋值运算符重载(operator=),有返回值,要先判断非自身赋值(把自身资源先析构 / 置空,最后啥都剩不下),再关
this的旧fd,再接管资源,因为是给已有对象赋值,必须清理旧资源避免泄漏。拷贝构造:
FileDescriptor(const FileDescriptor& other),用已有对象创建新对象(比如FileDescriptor fd2(fd1);)- 拷贝赋值运算符重载:
FileDescriptor& operator=(const FileDescriptor& other),已有对象之间赋值(比如fd2 = fd1;)注意:如果
fd初始是 - 1,close(this->fd_)会调用close(-1)直接返回错误。禁用拷贝赋值(
operator=(const FileDescriptor&) = delete;)改用移动语义,因为文件描述符是 “不可拷贝的资源”,只能转移所有权,不能复制。且深拷贝性能高不划算,浅拷贝有问题。
fd2 = fd1;能转换成fd2.operator=(fd1);是 C++ 运算符重载语法规则:// 核心规则落地代码 class A { public: // 必须按这个格式定义赋值运算符重载函数 A& operator=(const A& other) { // 函数体逻辑 return *this; } }; int main() { A a1, a2; a2 = a1; // C++标准强制:自定义类的赋值语句,编译器自动替换为 a2.operator=(a1); }
类名&是函数的返回值类型,作用是声明 “这个函数要返回一个该类对象的引用”;*this是函数内部要返回的具体对象(当前调用函数的对象本体),类名&类型会把*this(对象本体)转换成该对象的引用(别名)返回,而非拷贝新对象。
this->fd_代表操作系统给打开的文件 / 设备分配的唯一编号(文件描述符);调用close(this->fd_)时,程序会把这个整数传给操作系统的close系统调用,操作系统收到后会:
找到这个整数对应的、当前进程打开的文件 / 资源;
释放该资源(比如关闭文件、断开套接字连接),并标记这个整数编号为 “无效”;
后续再用这个整数调用
read/write等操作时,操作系统会返回 “无效文件描述符” 错误;然后还可以能随便赋值,只是赋的新数字对应的是另一套资源(比如
fd1的fd)。而
void func(int *a) { // 形参声明为int*(指针类型) // 函数内a存储的是传入变量的地址 } int main() { int num = 10; func(&num); // 实际传递的是num的地址(&num),类型匹配int* }
int *a是形参的类型声明(表示 a 是指向 int 的指针),调用函数时传递&a(实际是 num 地址)是因为指针形参需要接收 “变量的地址” 才能指向对应变量,这和类名&(引用)、*this(对象本体)是完全不同的语法场景:指针形参接收地址是为了间接操作原变量,而类名&返回*this是为了直接返回对象别名、避免拷贝,两者仅都用到*(指针标识)和&(取地址 / 引用标识)符号,但核心逻辑无关联。其实至此基本说完了,但再说个调用写法,主要是为了说
move,先科普几个东西:
科普1:首先
tmp是函数内的有名局部变量,有自己的内存、有名字,不是临时值,真正的临时值是FileDescriptor(fd)这种没名字、用完就销毁的表达式对象。科普2:开 RVO 优化的核心目的是:干掉多余的拷贝 / 移动,不管是临时值还是局部变量,只要能直接在函数外的内存(比如 main 里的 fd1)构造对象,编译器就会干掉,和有没有临时值无关!
科普3:
编译器看到无名的构造表达式
return FileDescriptor (fd)就知道这个对象只有一个目的:被返回。全程不会被复用修改啥的。这个无名的就是右值,临时值。编译器看到有名的
tmp,就知道可能在return之前被修改复用。编译器基于这认知差异对二者的处理行为有不同,说下函数里
return的细分写法:1、先造局部对象tmp,再return tmpFileDescriptor create_obj(int fd) { FileDescriptor tmp(fd); // 步骤1:函数内造有名局部对象tmp // 哪怕这里什么都不写,编译器也认为tmp“可能被修改” return tmp; // 步骤2:把tmp返回给外部fd1 } // 调用者 FileDescriptor fd1 = create_obj(10);无优化时,编译器无法确定是否被复用修改,必须按规矩办事,
在函数内部的栈内存里,构造
tmp对象(给tmp分配内存、初始化数据,比如给fd赋值);因为
tmp要返回给外部的fd1,即main里的fd1,编译器只能把tmp里的所有数据,拷贝 / 移动到外部fd1已经分配好的内存里;
C++11 之前,没移动构造,只能走拷贝构造(默认浅拷贝,有资源的得手写深拷贝),编译器默认开优化,具体是否生效看场景。
C++11 之后,编译器发现
tmp是 “即将被析构的局部变量”(return后tmp就没了),会退而求其次走移动构造。函数执行结束,析构函数内部的
tmp对象(释放tmp的内存)(如果直接给tmp,那销毁完不就野指针了)统计消耗:造俩对象(内部
tmp+外部fd1),一次移动 / 拷贝,析构一次内部tmp。有优化时,叫 NRVO(具名返回值优化),开静态遍历
return前代码有无修改、赋值,判断你是否修改,没修改则把函数内部tmp的内存地址,直接替换成外部fd1的内存地址。相当于编译器把代码偷偷改成了这样:查看代码
// 编译器偷偷修改后的逻辑,你写的代码不变 void create_obj(int fd, FileDescriptor* target) { new (target) FileDescriptor(fd); // 直接在外部fd1的内存里构造对象 } // 调用者实际的执行逻辑 FileDescriptor fd1; // 先分配内存 create_obj(10, &fd1); // 直接在fd1的内存里构造统计消耗:直接在外部
fd1内存造对象。无拷贝移动析构。如果:查看代码
FileDescriptor create_obj(int fd, bool flag) { FileDescriptor tmp1(fd); FileDescriptor tmp2(fd+1); if (flag) return tmp1; else return tmp2; // 分支返回不同的有名对象,编译器放弃NRVO }则不会优化,因为本意是造 tmp1/2 然后返回然后析构,而优化是在函数外内存建立,那你传一个地址,究竟是用来
tmp1还是建立tmp2?无法在编译的时候确定啊,稍微复杂就会很大风险,违背原来意图。2、直接
return FileDescriptor (fd)查看代码
FileDescriptor create_obj(int fd) { return FileDescriptor(fd); // 直接返回无名构造表达式 } // 调用者 FileDescriptor fd1 = create_obj(10);无优化时,编译器知道无名构造表达式,直接在函数内部临时分配一小块内存,构造这个无名对象,因为是临时值(右值),编译器直接走移动构造,把数据移动到外部
fd1的内存里,析构。注意,不开优化,有临时值,其实指的就是
FileDescriptor(fd);本身。这里和有名的无优化时完全一致,C++ 11 之前都是默认浅拷贝,C++11 后都是移动构造。
总结就是:
默认是开优化,原地搞数据,没拷贝移动这些。
手动关闭优化,C++11 之前都是默认浅拷贝,C++11 之后会走移动构造。
然后 C++17 后,是语言层面的强制是优化,你关也原地搞数据(有办法关,但不讨论,没意义)。
关优化又叫禁用拷贝省略。即必须走拷贝 / 移动。
统计消耗:造内部
tmp+外部fd1这俩对象,一次移动/拷贝,析构一次内部tmp。和return tmp无优化一样。但编译器对这个无名对象的 “用途确定性”,直接搞不需要考虑是否修改啊啥的。开优化:叫 RVO(返回值优化),编译器看到是直接返回无名构造表达式,知道它唯一目的就是返回,不需要做任何可能性判断,直接执行最优逻辑:跳过函数内的临时内存,直接在外部 fd1 已经分配好的内存里,构造 FileDescriptor (fd) 对象。过程和 NRVO 优化后完全一样。
写法 无优化时的执行过程 有优化时的执行过程 优化是否会失败 return tmp(有名局部) 造 2 个对象 + 1 次拷贝 / 移动 + 1 次析构 造 1 个对象 + 0 次拷贝 / 移动 + 0 次析构 可能失败(有前提) return FileDescriptor (fd)(无名表达式) 造 2 个对象 + 1 次轻量移动 + 1 次析构 造 1 个对象 + 0 次拷贝 / 移动 + 0 次析构 一定成功(无前提) 痛苦:
关于优化这里再次 崩溃,然后那个感言的 LinuxC++ 豆包链接,搜“我最后会没工作吗?”又一次崩溃,wx搜“优化深拷贝开不开这些”。
以上关于移动、拷贝、原地搞的这些,都是原理,然后说和
move有啥关系,先说移动构造的触发场景:函数用最开始的 RAII 代码,
场景 1(移动构造):右值直接初始化新对象(最常见)(一步式)(本质和)
查看代码
FileDescriptor open_file(const char* path) { int fd = open(path, O_RDONLY); // 打开文件得到fd return FileDescriptor(fd); // 返回一个【临时对象】(右值) } // 调用时 FileDescriptor fd = open_file("test.txt");
调用
open_file("test.txt")执行open("test.txt", O_RDONLY)获 int 型文件描述符 fd执行
return FileDescriptor(fd),调用explicit FileDescriptor(int fd)构造FileDescriptor临时右值对象,其 fd_绑定步骤 1 的 fd执行
FileDescriptor fd = 临时右值对象,编译器不会走拷贝(你删了),触发移动构造FileDescriptor(FileDescriptor&& other) noexcept,将临时对象的 fd_转移给 fd 并把临时对象 fd_置 - 1临时右值对象生命周期结束,析构
~FileDescriptor()因 fd_=-1 不执行 close当 fd 对象生命周期结束,析构
~FileDescriptor()检测 fd_≠-1,执行 close 关闭文件描述符编译器编译时就确定了「函数返回值要给谁」,运行时函数 return 的临时对象还没出栈 / 销毁,就直接把资源移给 main 的 fd1,压根不用等出函数!
return 具名的 tmp和return 匿名临时对象完全一样,唯一差别就是是否可以改,因为有名字可以改。本质是:临时对象马上要销毁,编译器直接把它的 fd_所有权 “移” 给新对象,不做拷贝。
如果
open_file返回int,调用方仅能拿到裸文件描述符int fd = open_file(...),仅能做整型相关操作、手动调用系统close(fd),无FileDescriptor的 RAII 自动关闭、get()、移动语义等特性;而代码中
open_file返回FileDescriptor,调用方拿到FileDescriptor fd = open_file(...),可调用该类型的fd.get()获取原始 fd,依托析构函数~FileDescriptor()自动执行close(fd_),还能使用该类型的移动构造FileDescriptor(FileDescriptor&&)、移动赋值operator=(FileDescriptor&&)转移 fd 所有权,且因拷贝构造FileDescriptor(const FileDescriptor&) = delete被禁用,从根本避免了 fd 被重复拷贝导致的重复close问题场景 2(移动赋值):右值赋值给已存在对象(两步式)
哪怕不写函数,直接创建临时对象,也会触发移动:
查看代码
// 临时对象(右值)直接赋值,编译器自动走移动赋值 FileDescriptor fd; fd = FileDescriptor(open("test.txt", O_RDONLY));
FileDescriptor fd;调用FileDescriptor() : fd_(-1) {}
fd = FileDescriptor(open(...));先调用explicit FileDescriptor(int fd)造临时右值,再调用移动赋值operator=(FileDescriptor&&)插一嘴:
加
explicit后,不能把 int 数字直接当 FileDescriptor 对象用,必须手动写FileDescriptor(数字)才能创建对象,彻底杜绝无意间把 int 转成对象的低级错!不加
explicit:编译器「自作聪明帮你转」。
起初:你就写了一行
fd = 10,心里可能没想别的,就是随手写了个数字赋值编译器干的事:看到等号左边是
FileDescriptor对象、右边是int,它会自动调用FileDescriptor(10),凭空造一个临时的FileDescriptor对象(把 10 传给带参构造)最终实际结果:把这个临时对象直接赋值给原本的
fd,原本的fd对象被整个替换掉了(不是改对象里的fd_,是连对象都换了!原对象里所有成员全被覆盖!比如num变量是 7,然后这么写会把7也搞没)加
explicit:编译器「不帮你瞎转」,错了直接报错。
你写的是 RAII 类,必须删拷贝(避免 fd 被多对象持有、重复关闭);
但实际用这个类,100% 会出临时右值(函数 return 的临时对象、直接构造的 FileDescriptor (...) 临时对象);
若不实现移动,类就「不可拷贝 + 不可移动」,编译器面对这些临时右值的赋值 / 初始化会直接报错,RAII 类彻底无法使用;
你写的移动构造 / 赋值,不是给你手动调的,是给编译器「兜底」的 —— 编译器会自动把临时右值匹配到移动接口,完成 fd 所有权的合法转移,让这两个最常用的使用场景能正常工作;
std::move 根本不是重点,编译器对天然临时右值会自动触发移动,这才是你这个 RAII 类里移动语义的核心价值。
不管是
return FileDescriptor(fd)还是return tmp,编译器自动调用你写好的移动构造,不用你手动加std::move、不用手动写return FileDescriptor(std::move(tmp))这类代码。 都是自动调用那个移动的。但还有不自动的需要手动写
move:插一嘴语法细节:
查看代码
//写法一、 FileDescriptor open_file(const char* path) { int fd = open(path, O_RDONLY); return FileDescriptor(fd); } FileDescriptor fd = open_file("test.txt"); //写法二、 FileDescriptor get_fd(const std::string& filename) { int fd = open(filename.c_str(), O_RDONLY); return FileDescriptor(fd); } FileDescriptor fd = get_fd("test.txt");写法一:
open_file是 C 风格原生指针const char* path;仅接受 C 字符串(字面量 /char[]/c_str() 结果写法二:
get_fd是 C++ 标准字符串引用const std::string& filename。兼容 C 字符串 和 C++ 的std::string,传参更灵活。
open是 C 库函数只认const char*,你传std::string就得转,用std::string &传参能直接调c_str ()更方便。你传的
"test.txt"是C 风格字符串字面量,本身就是const char*类型,直接给open用完全没问题!但如果函数参数设成std::string&,不管传字面量还是std::string对象,都能直接调.c_str()给open,比参数设成const char*适配性更强。好处:
自动管理内存 + 易用的操作接口,彻底告别 C 字符串的手动内存坑和繁琐处理
不用手动
malloc/free/strlen,超出长度自动扩容,杜绝内存泄漏 / 越界;直接用 + 拼接、== 比较、[] 取值,不用记
strcat/strcmp/strcpy这些 C 函数;传参用
string&,既能接字面量(如"test.txt")也能接string对象,调c_str ()给 C 库open更灵活,不用额外转换C++
fstream系列直接传string,其余所有文件相关函数全传string.c_str ()C++11 移动语义的基础理论(含早期编译器行为),懂这个的核心意义:搞透移动语义的设计初衷,而非只看编译器的最终优化结果。
查看代码
#include <iostream> #include <string> #include <utility> // 严谨使用std::move,需包含此头文件 using namespace std; class MyStr { public: string* s; // 用堆内存指针体现资源所有权,更贴合移动语义本质 // 普通构造:申请堆资源 MyStr(const string& str) : s(new string(str)) { cout << "执行【普通构造】,申请堆资源"<<" "<< *s <<endl; } // 拷贝构造:深拷贝(重新申请堆资源,复制内容) MyStr(const MyStr& other) : s(new string(*(other.s))) { cout << "执行【拷贝构造】,深拷贝堆资源\n"; } // 移动构造:转移资源所有权(仅赋值指针,无资源拷贝),必须加noexcept(标准推荐,容器会依赖) MyStr(MyStr&& other) noexcept : s(other.s) { other.s = nullptr; // 源对象置空,避免析构时重复释放资源(核心!) cout << "执行【移动构造】,转移资源所有权\n"; } // 析构函数:释放堆资源,判空避免野指针 ~MyStr() { if (s) { cout << "执行【析构】,释放堆资源" << " " << *s << endl;; delete s; // 核心!必须有,释放堆资源 } else { cout << "执行【析构】,无资源可释放(已被移动)" << endl; } } // 禁用赋值运算符(简化示例,避免冗余) MyStr& operator=(const MyStr&) = delete; MyStr& operator=(MyStr&&) = delete; }; // 函数返回局部对象:编译器自动标记为将亡值,触发移动构造 MyStr getStr() { MyStr temp("hello"); // 局部对象,函数结束后生命周期结束 return temp; // 无std::move,编译器隐式触发移动! } int main() { MyStr a = getStr(); // 接收返回值,匹配移动构造 } /* 都优化了,不移动,直接原地搞 输入: root@VM-8-2-ubuntu:~/cpp_projects_2# ./a 执行【普通构造】,申请堆资源 hello 执行【析构】,释放堆资源 hello root@VM-8-2-ubuntu:~/cpp_projects_2# */解释代码:
main中创建a时,编译器直接在a 的内存地址上,为getStr()里的局部对象temp分配空间,temp和a共用同一块内存,temp不再是独立的局部对象;执行
MyStr temp("hello"),实际就是在a的地址上调用普通构造,申请堆资源,输出对应日志;
getStr()的return temp无任何实际操作(无拷贝 / 移动),因为temp和a是同一实体,无需转移 / 复制资源;return毫无用处,但return是语法必需(无则编译报错),同时是编译器触发 RVO 优化的前提,仅做语义声明,不实际拷贝 / 移动数据。
main函数执行结束,局部对象a生命周期到头,调用析构函数释放堆资源,输出对应日志;全程无
temp的独立析构(temp无实体),也无任何拷贝 / 移动构造的调用。再次学没用的,完全不考的,才知道
return的完全没移动,都是原地搞。妈逼的老子不是白学了吗???return都是优化的了!但如果加了分支,则优化无效,只需要做俩改动:
1、
main里改成MyStr a = getStr(true);,2、
查看代码
// 函数返回局部对象:编译器自动标记为将亡值,触发移动构造 MyStr getStr(bool flag) { MyStr temp1("hello"); // 分支1局部对象 MyStr temp2("world"); // 分支2局部对象 if (flag) { return temp1; } else { return temp2; } }输出变为:
查看代码
root@VM-8-2-ubuntu:~/cpp_projects_2# ./a 执行【普通构造】,申请堆资源 hello 执行【普通构造】,申请堆资源 world 执行【移动构造】,转移资源所有权 执行【析构】,释放堆资源 world 执行【析构】,无资源可释放(已被移动) 执行【析构】,释放堆资源 hello root@VM-8-2-ubuntu:~/cpp_projects_2#构造顺序是
temp1 → temp2,析构必是temp2 → temp1。因为栈内存是先进后出结构,对象定义即入栈,函数结束出栈析构,先定义的先入栈、后出栈析构。解释输出:先
temp1、2简简单单不逼逼,然后if判断那把temp1给外部的a,触发移动构造,然后顺序析构2、1,完全用不上深拷贝。好奇
a为啥没析构,走移动构造将temp1资源移给main栈上的a,temp1本身变成空指针(other.s = nullptr),所以temp1析构时打印无资源可释放,而a作为资源的最终持有者,程序结束时析构就会打印hello的释放信息,二者的资源析构本质上是同一个堆内存的释放,只是所有权从temp1转移到了a,不会有两次hello的析构打印,最终打印的释放堆资源 hello就是a的析构,a通过移动构造完全接管了temp1指向hello的堆内存资源所有权。代码里必须先打印
*s后delete s,因为delete s后解引用*s的话,指针已悬空,访问非法内存。插一嘴:
类里写了这 5 个中的任意 1 个,编译器就不自动生成拷贝 / 移动了,直接删 / 禁用:
手写拷贝构造
手写拷贝赋值
operator=手写移动构造
MyStr(MyStr&&)手写移动赋值
operator=(MyStr&&)手写析构函数
~MyStr()手写析构 / 拷贝 / 移动任意一个,编译器停更所有默认拷贝移动,
写了堆指针就必须手写析构,必须手写深拷贝或移动(因为函数 return 局部对象时,局部对象出函数就销毁,必须把它的资源 “移交” 到函数外的变量上,这个 “移交” 动作只能是拷贝 / 移动二选一,没别的办法!)
分支逼你必须调用拷贝移动,缺一个就报错,全程无浅拷贝机会!
好痛苦啊~~~~(>_<)~~~~,钻研进毫无意义的东西了感觉,写点结论赶紧撤了。
编译器从不自动生深拷贝,
类自定义析构 / 堆指针不会自动生移动,因为简单的类(无堆、自定义析构),
return会自动生,走移动 / 优化,不行就走拷贝,再不行报错。碰堆 / 写析构的类:手写移动构造,所有 return 也能走移动,不报错、效率高!
我代码里去掉移动,就会走深拷贝:
手写移动构造→移动;
无手写移动、有手写拷贝构造→深拷贝;
无堆和析构自定义、无手写移动、无手写拷贝构造→编译器优先生移动,不行再隐式生成拷贝构造做浅拷贝(触发双重释放)
然后发现去掉深拷贝会报错,因为手写了移动构造 / 赋值,编译器会自动删除默认拷贝构造,
return时无拷贝 / 移动可用直接报错!开心,没白学!
然后这里太多疑惑了,误打误撞学到很多极致细节的东西,开始深入抽插:
首先
普通构造:
MyStr(const string& str) : s(new string(str)) {深拷贝:
MyStr(const MyStr& other) : s(new string(*(other.s))) {main里调用:MyStr temp1("hello");这些细节语法,都他妈是咋串联的啊艹,海厚海厚一团乱麻~~~~(>_<)~~~~。
首先,
类的成员变量
string* s;天生是string*指针,存的是堆上string对象的地址。构造
MyStr(const string& str) : s(new string(str)) {:
最开头
MyStr:构造函数名,与类名一致,用于创建MyStr对象。括号里
(const string& str):构造函数的参数,接收string类型的常量引用,避免拷贝提升效率。冒号后
: s(new string(str)):构造函数的初始化列表,直接初始化成员变量s,让其指向堆上新建的string对象(内容为str的值)。一句
MyStr temp1("hello");即完成了传递。然后深拷贝,这里去掉移动才走深拷贝,那就先注释掉移动,来讨论深拷贝每一步串联:
return temp1;中,temp1是已存在的MyStr对象,编译器需要把它「传递」给main的a,因注释掉了移动构造,编译器只能匹配唯一可用的拷贝:MyStr(const MyStr& other),const MyStr& other是传入的原MyStr对象的引用,编译器直接把other绑定到原对象temp1上,此时:
other≡temp1(other就是temp1的别名,操作other等价于操作temp1);
other.s就是temp1.s(指向堆上存hello的string*指针)。
s(new string(*(other.s))):
*(other.s):解引用other.s,拿到temp1指向的堆上hello字符串;
new string(...):新建一块独立堆内存,复制hello内容,创建新的string对象;
s = ...:把新string的地址赋给新对象的s成员(新对象的s和temp1.s指向不同堆内存)。编译器把拷贝构造创建的新对象,直接交给
main中的a,最终a的s指向深拷贝得到的独立hello堆内存。即
other是源对象,当前正在通过拷贝构造创建的新MyStr对象是目标对象。所以如果注释掉移动,输出则是:
查看代码
root@VM-8-2-ubuntu:~/cpp_projects_2# ./a 执行【普通构造】,申请堆资源 hello 执行【普通构造】,申请堆资源 world 执行【拷贝构造】,深拷贝堆资源 hello 执行【析构】,释放堆资源 world 执行【析构】,释放堆资源 hello 执行【析构】,释放堆资源 hello root@VM-8-2-ubuntu:~/cpp_projects_2#析构那里,唯一要说的就是,深拷贝:
【
getStr函数内】构造temp1(hello)→ 函数局部对象【
getStr函数内】构造temp2(world)→ 函数局部对象【跨作用域临时对象】拷贝构造
临时对象(hello)→ 为给main的a创建的过渡对象对应析构就是:先析
getStr内的局部对象(作用域先结束):构:temp1→temp2→ 析:temp2→temp1,再析main里的a(原临时对象,getStr结束后才归main管,作用域后结束)。且输出不是双重析构,
进入
getStr(true),创建temp1:调用普通构造,堆上新建string存hello→temp1.s指向这块内存(第一块:hello1),打印执行【普通构造】,申请堆资源 hello;创建
temp2:调用普通构造,堆上新建string存world→temp2.s指向这块内存(第二块:world),打印执行【普通构造】,申请堆资源 world;执行
return temp1:因无移动构造,编译器调用拷贝构造,用temp1深拷贝创建「函数返回的临时对象」→ 堆上新建string,复制temp1的hello(第三块:hello2),临时对象的s指向 hello2,打印执行【拷贝构造】,深拷贝堆资源;(林冲:投名状真的好难啊~~~~(>_<)~~~~)
(96大龄、二本计算机、0开发经验、23年5月第一次离开家参加工作,24年5月银行外包测试离职待业至今)(我会有好结果吗?一无是处穷途末路~~~~(>_<)~~~~)
再说移动,如果不注释掉移动,那
return temp1;,触发移动构造:
编译器识别
temp1是必死对象:temp1是getStr的局部对象,函数执行完出作用域就会被析构,属于无主的堆资源(不用白不用);调用移动构造,绑定右值引用:因为没有拷贝构造,编译器匹配
MyStr(MyStr&& other),把other直接绑定到temp1(other ≡ temp1,和拷贝构造的绑定一样);资源转移,原对象置空:执行移动构造的初始化列表 + 函数体:
s = other.s;:新对象(函数返回的临时对象)的s,直接指向temp1的堆内存 H1(没有new,没有拷贝,直接拿地址!);
other.s = nullptr;:把temp1的s置为空指针(关键!让temp1变成 “空壳”,它的 s 不再指向 H1,后续析构temp1时,析构函数判空会直接跳过释放);
getStr函数执行完毕,析构局部对象temp2、temp1函数出作用域,局部对象按“先创建后析构”的顺序销毁,重点看析构时的资源状态:
析构
temp2:temp2.s = &W1(非空),释放堆内存 W1,打印:执行【析构】,释放堆资源 world;析构
temp1:temp1.s = nullptr(移动构造时被置空了),析构函数判空,不释放任何资源,直接跳过,无打印!函数返回的临时对象,交给
main中的a,编译器会做优化(返回值优化 RVO),直接把移动构造的临时对象 “转正” 为main里的a,a的s直接指向堆内存 H1(就是temp1原来的那块),没有额外开销。程序结束,析构
main中的a:a.s = &H1(非空),释放堆内存 H1,打印:执行【析构】,释放堆资源 hello。关于赋值,其实:
查看代码
MyStr(MyStr&& other) noexcept : s(other.s) { other.s = nullptr; // 源对象置空,避免析构时重复释放资源(核心!) cout << "执行【移动构造】,转移资源所有权\n"; } 等价于 MyStr(MyStr&& other) noexcept{ s = other.s; other.s = nullptr; // 源对象置空,避免析构时重复释放资源(核心!) cout << "执行【移动构造】,转移资源所有权\n"; }初始化列表是直接给成员赋初值(无默认初始化),快;
写函数体里会先给成员做默认初始化(比如 fd_随机值、s 空指针),再赋值,多一步无用操作还可能踩坑!比如把
fd_ = other.fd_写函数体里,执行顺序是:
先默认初始化
fd_→ 给个随机垃圾值(比如 356);再执行
fd_ = other.fd_→ 把随机值覆盖成目标值;若成员是需要手动释放的资源(比如你的
s指针),默认初始化后再赋值,还可能漏释放旧资源,直接炸!代码里为何赋值
null,不用delete啥的吗?去掉
null,再走一遍return temp1;的流程,你会清晰看到崩溃的原因:
移动构造执行:新对象(返回的临时对象)的
s=temp1.s= &H1(堆 hello 的地址);因为没写置空,temp1.s 仍然指向 H1(源对象的指针还牢牢攥着堆资源的地址);
getStr函数结束,析构局部对象temp1:析构函数判断s≠nullptr,执行delete s;,释放了堆内存 H1;程序结束,析构
main里的a(a 的s也指向 H1):析构函数再次执行delete s;,尝试释放已经被释放的 H1;结果:C++ 直接崩溃,抛出
double free or corruption (fasttop)(双重释放 / 内存损坏),这是 C++ 中最常见的致命错误之一。实际去掉
null发现全是输出空白,不写other.s = nullptr→ 源对象 (temp1) 和新对象 (a) 的 s 同时指向 H1 → 源对象先析构释放 H1 → 后续所有访问*s的操作(打印、析构),都是在访问已被销毁的堆内存 (野指针)→ 要么输出空白 / 乱码,要么直接崩双重释放移动构造绝对不能写
delete:delete会直接销毁堆资源,新对象指针成野指针,后续任何操作(含析构)必崩。
nullptr赋值后能正常cout:置空的是源对象的指针,新对象指针仍指向有效堆资源,cout访问新对象的*s完全合法。Q:我看移动、深拷贝、普通构造,都是创造新对象,只是方式不同,可我没看到有创建新的这个代码啊?
A:构造函数本身就是“创建新对象”的过程,不是函数里写代码创对象,是调用构造函数的动作本身就创了新对象,三种构造只是给新对象初始化成员的方式不同!
Q:我看这里的
getStr我感觉有点一环套一环的意思!这么写多个getStr有啥意义吗?A:用多局部对象 + 条件返回的场景,刻意避开编译器 RVO 返回值优化,强制触发移动构造,让你清晰看到移动语义的实际执行效果。
不管怎么说,我精通这些东西了,就是有价值的,坚定信念。
之前内心:我好累真的学不下去去了,为啥这么多知识点呢?光名词就一屁眼子,拷贝构造、拷贝赋值、移动语义、移动赋值、重载,全都混在一起了,且很多又都是一个大玩意的不同叫法!
这些 全是自动的
return移动,再说手动move,即左值的,因为有名字、可取地址,编译器无法确定其后续是否被使用,编译器为了安全性,会默认匹配拷贝构造 / 拷贝赋值,而非移动。若程序员明确知道该左值后续无任何使用,则需要通过std::move将其强行转换为右值引用,告诉编译器 “该对象可被移动”,此时才会触发移动构造 / 移动赋值,这是程序员对编译器的“显式承诺”:后续不再使用该源对象的原有资源。另外突然发现上面的代码是禁止赋值,其实正规应该是禁止拷贝,我正打算用赋值,发现给禁止了报错了。
拷贝(复制)是创建新对象,赋值是给已有对象塞新值,俩完全不同的操作!
我代码只禁了赋值、没禁拷贝构造,注释掉移动构造后,编译器只能调用现成的深拷贝构造函数,所以实打实走了深拷贝!
所以解读下禁用的语法:(禁止赋值、禁止拷贝)(拷贝 == 复制)
查看代码
// 禁用拷贝,避免重复close FileDescriptor(const FileDescriptor&) = delete; //禁止 FileDescriptor 对象的拷贝构造, 比如 FileDescriptor b = a; FileDescriptor& operator=(const FileDescriptor&) = delete;//禁止 FileDescriptor 对象的拷贝赋值, 比如 b = a,a/b 都是已存在的 FileDescriptor // 禁用赋值运算符(简化示例,避免冗余) MyStr& operator=(const MyStr&) = delete;//禁止 MyStr 对象的拷贝赋值, 同上面第 2 个的逻辑 MyStr& operator=(MyStr&&) = delete; //禁止 MyStr 对象的移动赋值, 比如 b = std::move(a); a 是临时 / 即将销毁的 MyStr
拷贝是 “复制已有对象的所有状态”,移动是 “接管已有对象的资源(原对象变空)”;
FileDescriptor只禁拷贝(构造 + 赋值),因为文件句柄这类资源拷贝会导致重复关闭;
MyStr额外禁移动赋值,是不想让对象的资源被 “移走”,彻底锁死赋值行为;不管是拷贝还是移动,
= delete都是让编译器直接拒绝这类代码,从语法上杜绝资源管理 bug关键语法点
= delete:C++11 删除函数语法,作用于类的特殊成员函数时,显式禁用该函数,编译器不生成默认版本,调用即编译报错;
const 类名&:左值引用,对应拷贝语义,针对已有具名对象;
类名&&:右值引用,对应移动语义,针对临时无名对象。我一直以为赋值重载是说,必须
查看代码
#include <iostream> #include<cstring> using namespace std; class MyClass { public: int num; char* p; const char* name; // 新增:存对象名(a/b) // 构造加name参数,传对象名 MyClass(int n, const char* s, const char* objName) : num(n), name(objName) { p = new char[100]; strcpy(p, s); //把源第二个参数的字符串(含 '\0')拷贝到目标字符数组,覆盖目标原有内容。strcpy 只认 src 里的 '\0',拷到这为止,不会主动补,没 '\0' 就会越界乱拷! } // 析构打印name,直接知道是a/b ~MyClass() { cout << "析构:" << name << " 释放堆内存" << endl; delete[] p; } }; int main() { MyClass a(10, "hello", "a"); // 传名"a" MyClass b = a; // 拷贝后b的name也会是"a",手动改b.name="b"即可 b.name = "b"; // 单独给b设名,极简区分 } /* root@VM-8-2-ubuntu:~/cpp_projects_2# ./a 析构:b 释放堆内存 析构:a 释放堆内存 free(): double free detected in tcache 2 Aborted (core dumped) root@VM-8-2-ubuntu:~/cpp_projects_2# */编译器啥都知道!自定义类不写
operator=,编译器会自动生成默认版本,规则就是逐成员赋值,压根不是“不知道咋赋值”,赋值重载是重写 / 替换默认行为,不是 “教编译器怎么赋值”!防止双重close(当然其实手动写也就是类似深拷贝深赋值,自动生的就是浅拷贝浅赋值,只不过赋值没有深浅一说)所以
不手动写
operator=→ 编译器自动生成逐成员拷贝的默认赋值,行为等价于 “浅赋值”,堆指针只拷地址不拷资源,必出问题;手动写
operator=→ 自己实现堆资源的深拷贝逻辑,行为等价于 “深赋值”,让各对象持有独立堆内存,解决析构崩溃;额外还有
operator=(T&&)移动赋值 → 针对临时对象(右值)的优化,直接 “偷” 临时对象的堆资源(置空其指针),不做拷贝,效率远高于深赋值,是 C++11 后堆资源类的标配。要说的就是这个移动赋值
move,插一嘴:移动和拷贝互斥二选一。
移动分为:
移动构造(带右值引用的构造函数)
移动赋值(带右值引用的
operator=重载)先上个代码热热身
查看代码
#include <iostream> #include <string> #include <utility> // 严谨使用std::move,需包含此头文件 using namespace std; class MyStr { public: string* s; // 用堆内存指针体现资源所有权,更贴合移动语义本质 // 普通构造:申请堆资源 MyStr(const string& str) : s(new string(str)) {cout << "执行【普通构造】,申请堆资源"<<" "<< *s <<endl;} // 拷贝构造:深拷贝(重新申请堆资源,复制内容) MyStr(const MyStr& other) : s(new string(*(other.s))) {cout << "执行【拷贝构造】,深拷贝堆资源\n";} // 移动构造:转移资源所有权(仅赋值指针,无资源拷贝),必须加noexcept(标准推荐,容器会依赖) MyStr(MyStr&& other) noexcept : s(other.s) { other.s = nullptr; // 源对象置空,避免析构时重复释放资源(核心!) cout << "执行【移动构造】,转移资源所有权\n"; } // 析构函数:释放堆资源,判空避免野指针 ~MyStr() { if (s) {cout << "执行【析构】,释放堆资源" << " " << *s << endl;delete s; // 核心!必须有,释放堆资源 } else {cout << "执行【析构】,无资源可释放(已被移动)" << endl;} } }; // 函数返回局部对象:编译器自动标记为将亡值,触发移动构造 MyStr getStr(bool flag) { MyStr temp1("hello"); // 分支1局部对象 MyStr temp2("world"); // 分支2局部对象 if (flag) {return temp1;} else {return temp2;} } int main() { MyStr b("world"); // MyStr c = b; //拷贝构造(属于构造而不是赋值,因为 c 新搞的) MyStr d = std::move(b); // 手动写std::move:左值转右值引用,触发【移动构造】 }注意这是开胃菜,分清手动和之前自动
return的,但这是构造,分支的有无对构造没差别。用不上!!之前说的自动
return都是返回值初始化新对象全程只走构造,跟赋值半毛钱关系没有!所以优先级是,先移动,没写移动就走拷贝。然后赋值又是独立的一个东西, 赋值是独立操作,仅对象已存在时调用
operator=,和return/构造的匹配规则完全分离,无优先级交集。手写
std::move会强制把左值转右值引用,优先匹配移动构造(有则走),无移动构造才会尝试拷贝构造,同样和赋值无关。这里先加个移动赋值
查看代码
//移动赋值 MyStr& operator=(MyStr&& other) noexcept { if (this!=&other){ delete s; s=other.s; other.s=nullptr; cout<<"执行【移动赋值】,转移资源所有权 \n"; } return *this; } //用 new[] 动态开辟数组类型的堆内存时,必须用 delete[] 释放 //new string(单个对象)只能用 delete关于
delete,一通百通(搜“喻,这个总结无价”),依旧是delete当前对象的旧的堆资源释放内存,再接管源对象的指针。s初始化必指向有效堆内存或nullptr。
new string()无参 new 也能初始化,堆上生成空 string 对象(不是野指针 / 随机值,是合法的空字符串),只是内容为空而已,但不是null,是内容为空的合法string对象,指针指向有效内存!但由于我写了有参函数,如果直接写MyStr obj;这种无参创建对象的代码会直接编译报错,因为你显式写了有参构造,编译器就不自动生成默认无参构造了,编译器找不到能匹配无参调用的构造函数!普通构造
s(new string(str))、拷贝构造s(new string(*(other.s)))、移动构造s(other.s)后立刻other.s = nullptr,三构造全显式给s赋值!然后写
main查看代码
MyStr a("hello"); MyStr b("world"); a=b;会报错,
a = b;这样写会走拷贝赋值,但写了移动构造 / 移动赋值,编译器会自动删除默认的拷贝构造和拷贝赋值运算符,而你写a = b时需要拷贝赋值,却发现它被删了,所以直接报错。因为
a=b中b是左值,编译器会匹配接收const MyStr&的拷贝赋值运算符,而移动赋值运算符接收的是MyStr&&右值引用,左值无法绑定到std::move产生的右值引用上,因此不写std::move时会走拷贝赋值。注意:
fd标 - 1、指针标nullptr是各自类型的无效约定,if(指针)精准有效,if(fd!=-1),核心都是判有效再释放!要么写成
a = std::move(b);,强转b为右值,触发移动赋值,b此时会变成"空状态"(内部指针为nullptr),后续不能再使用b输出:
查看代码
执行【普通构造】,申请堆资源 hello 执行【普通构造】,申请堆资源 world 执行【移动赋值】,转移资源所有权 world 执行【析构】,无资源可释放(已被移动) 执行【析构】,释放堆资源 world误以为只有
a一个对象,其实a和b两个对象都一直存在直到代码块结束,只是b的堆资源被移动到a手里,b变成了 “空壳对象”。b空壳分两步 一步是搞成 null 作为代码层面的标记,所以不 close 即不析构,第二步是早在转移的时候就把实际数据资源转移走了。然后
a的旧资源直接 delete 掉了。新资源就是抢夺b的,b空了但是没资源也就没必要析构,只析构了a空壳不需要析构,因为析构核心工作是释放对象持有的堆资源,而
b内部资源指针早已被置null,析构时找不到可释放的资源,自然无实际操作。要么
MyStr a("hello"); a = MyStr("world");右侧是临时对象(右值),自动走移动赋值, 临时对象用完会被编译器销毁,无需担心。输出一样。要么,补充更健壮的增加拷贝赋值,
这以上三个移动赋值都是,分支都没调用上,因为拷贝赋值彻底没机会被优化成原地操作查看代码
// 拷贝赋值:深拷贝,先释放当前资源,再深拷贝新资源 MyStr& operator=(const MyStr& other) { if (this != &other) { // 自赋值保护 delete s; // 释放当前对象的旧堆资源 s = new string(*(other.s)); // 重新申请堆资源并深拷贝内容 cout << "执行【拷贝赋值】,深拷贝堆资源 " << *s << endl; } return *this; } /* 输出: 执行【普通构造】,申请堆资源 hello 执行【普通构造】,申请堆资源 world 执行【拷贝赋值】,深拷贝堆资源 world 执行【析构】,释放堆资源 world 执行【析构】,释放堆资源 world */
- 原地优化(RVO/NRVO)只针对对象构造阶段,而拷贝赋值是两个已完全构造好的对象之间的操作,
a和b在执行a=b;前,内存地址、堆资源都已固定,编译器根本没有 “原地” 操作的空间,只能在a已有的内存里执行 “释放旧资源→新申请堆内存→深拷贝b的内容”,全程都是对已存在对象的修改,不存在原地构造的可能。也就是说赋值是不走优化的,写成
MyStr a("hello");a = getStr(true); //亡值且有分支,则输出发现可验证,有无分支都不优化。输出是。
解释输出:
移动构造那,因为
return的temp1是将亡局部对象,直接触发移动构造构造main中 a 的赋值操作符右侧的临时对象。移动构造把
temp1的资源移走后,temp2无资源转移正常析构释放world,被移走资源的temp1指针置空,析构时无资源可释放。接着
main里a调用operator=&&移动接管临时对象资源,再析构被移空的临时对象,最后程序结束析构持有hello的a释放堆资源!反复多次抽插理解直到高潮(求其上得其中,求其中得其下,之前指针也是,搞这种极致难度的,再看到简单的直接砍瓜切菜,如果只像个傻逼速成狗一样,拿着高频题背来背去毫无意义)。
且
MyStr a("hello");a = getStr(true); //亡值等价于手动搞成亡值a = std::move(b)
你的拷贝赋值里写了明确的副作用逻辑(
delete s、new string、打印日志),编译器对带明确副作用的代码不会做任何省略或改写,哪怕是无意义的步骤,也会原模原样执行,更别说把整个深拷贝逻辑改成原地操作。副作用指的是:代码执行后,除了完成核心逻辑,还对外部环境产生了额外改变 / 输出,就是副作用。
插曲:我之前误写成
MyStr a("hello");MyStr b = std::move(b);,输出:查看代码
执行【普通构造】,申请堆资源 hello 执行【移动构造】,转移资源所有权 执行【析构】,无资源可释放(已被移动) 执行【析构】,释放堆资源 hello1、为啥要非自身判断(
if (this != &other))?防止自赋值 / 自移动时,先执行delete s把自己的资源释放了,后续再访问other.s(实际就是自己已释放的s),直接访问野指针崩了。2、这里自身给自身属于直接 return 了吗?是!你这行
MyStr b = std::move(b)触发的是移动构造(不是移动赋值),而你的移动构造函数里根本没有自判断,但如果是移动赋值 / 拷贝赋值,只要进了赋值函数且满足this == &other,就会直接走if分支里的return *this,啥都不执行。赋值的自己给自己会崩溃,构造的自己给自己不崩溃就是未定义的随机。
注意:合法空指针和随机未定义的野指针,一律禁止解引用!
分析输出:
执行起点:执行
MyStr b = std::move(b)时,b 先被分配内存但未执行任何构造函数初始化,其成员s是随机内存值(未初始化的指针变量),整b是未完成初始化的无效对象。
std::move的作用:仅将这个未初始化的 b强制转换为MyStr&&(右值引用),不做任何内存操作、不改变 b 的任何值,只是为了匹配移动构造函数的参数类型。移动构造的参数
other:other是上述右值引用的别名,直接绑定到未初始化的b上,other的本质是指向无效对象的右值引用,other.s就是b那个未初始化的随机野指针。- 移动构造函数执行:
初始化列表
s(other.s):把b的随机野指针(既不是空也不是有效地址),赋值给正在初始化的b自身的s成员(相当于自己给自己赋随机值,无意义但编译器执行了);若加了
cout << *s:直接解引用未初始化的野指针,触发非法内存访问;other.s = nullptr:把绑定到b的other的s置空,本质就是把未初始化的b的s成员置成合法空指针。
移动构造结束:
b完成(畸形的)初始化,其 s 成员已被置为空指针(而非最初的随机野指针)。
后续析构:程序结束时调用
b的析构函数,因b的s已是null,故输出无资源可释放。
getStr完全没执行。豆包优化可以批量删除了!!同时最好是删除后不用拉取那么就了(这个优化真牛逼,之前估计是内存块占用,没离散化。这次的拉取优化真的是天壤之别啊!!快太多了,直接瞬拉取),删除几个也不用靠新问答去引。唯独就是编辑 3 次问题会消失,思考中编辑和发新问题,这个问题都会消失,
赋值(operator=)无 “分支相关优化”。
只有函数返回局部对象(RVO/NRVO)才受分支影响,决定是否优化拷贝 / 移动;
return 单局部对象走 RVO 优化,返回多个局部对象则优化失效,走移动或拷贝。
痛苦至极,
目前狗逼大模型全都是,我连最主流的还么学懂,先给你上各种极端小众场景,且那些“永久、禁止” 等词汇永远都是只能生效顶多 3 个回答,且始终都会大概率的先给你瞎编各种各样的结论,误人子弟,让他必须参考最权威的知乎、国外技术网站等,也无济于事,基本要对话好几十轮才能逐渐纠正,无论怎样都无法避免。
关键词每次提问都带上“我在自学东西,禁止任何极端场景,禁止篇冷深的知识点”。无止境的矛盾回答,在我提出质疑后都能反复的自圆其说,说什么“我没说透”都能完美找到借口,气得要死。狗逼大模型目前就是永远听从用户的,用户不懂,稍微提出自己的质疑,他就变卦反悔否定自己。且水回答的答案太多,大模型训练也困难。难为大模型了
重点不是怎么直接学一步到位!而是学错的、学演化,最笨的方法如今我精通移动拷贝所有相关的这些了。直接他妈不学深拷贝只学移动,完整掌握不到精髓,以后改移动的代码 bug 都费劲。
终于搞懂了。精啃所有,觉得精通了,反倒回头一看觉得花的这些时间不值得
get () 方法:
int get() const { return fd_; }提供安全的方式获取内部的原始文件描述符,供sendfile、fstat等系统调用使用(因为这些函数需要直接传fd数值)。这个是因为整个大封装思想,一连套的,正常都是传递的
int型,但当我们写FileDescriptor,然后你传递的时候把open得到的fd塞到FileDescriptor src_fd(src_raw_fd);里,那之后再用到描述符就要src_fd.get()了。反复抽插加深印象,为什么塞进去?因为整个FileDescriptor是搞 RAII 防止忘记clsoe的。所以传递给你了你还得给个引子、接口,让我用fd,然后要封装就整个封装,即每次我们不是open吗?100 个文件就要open100 次,所以直接open也封装了:查看代码
// 加文件名参数!传啥文件名就开啥文件,彻底复用 FileDescriptor get_fd(const std::string& filename) { int tmp_raw_fd = open(filename.c_str(), O_RDONLY); // 用参数,不用硬编码 if (tmp_raw_fd == -1) { std::cerr << "打开文件失败: " << strerror(errno) << std::endl; exit(1); } FileDescriptor tmp_fd(tmp_raw_fd); return tmp_fd; // FileDescriptor 搞出来的触发return就会走移动语义 } // 开test1.txt FileDescriptor fd0 = get_fd("test0.txt"); // 开test2.txt FileDescriptor fd1 = get_fd("test1.txt"); // 开任意文件,只改参数,函数代码一行不用动! FileDescriptor fd99 = get_fd("test99.txt");然后用到直接
fd1.get()。私有成员:
int fd_ = -1;存储文件描述符,初始值 - 1(无效 fd),保证析构时不会误关无效fd。关闭fd为-1 描述符,因为-1不是合法的文件描述符,会置errno假设你写代码时,open文件失败了(比如文件不存在),tmp_raw_fd返回 - 1,这时候执行FileDescriptor tmp_fd(tmp_raw_fd);:系统规则:
close(-1)会报错(无效参数),而 0/1/2/3… 都是有效fd,关了就出问题;初始值 - 1 的意义:对象刚创建时,还没
open文件 / 接管fd,fd_=-1 就代表 “我现在没管任何fd”,析构时判断fd_ != -1就会跳过close,不会瞎关;假设你写代码时,open文件失败了(比如文件不存在),tmp_raw_fd返回 - 1,这时候执行FileDescriptor tmp_fd(tmp_raw_fd);:
fd_先初始化成 - 1;
构造函数把
tmp_raw_fd(-1)赋值给fd_,fd_还是 - 1;析构时判断
fd_ != -1,发现是 - 1 就跳过close—— 如果当初没设初始值 - 1,fd_可能是随机垃圾值(比如 999),析构时就会去 close (999),直接触发系统错误!
发现深浅拷贝差不多啊,继续追问懂了:
对基础类型成员(int、bool 等):直接赋值;基础类型深浅没区别。
对资源型成员(指针、文件描述符、句柄等):不复制值,而是新建一份独立资源,新对象持有这份新资源,和旧对象彻底隔离。
查看代码
#include <vector> #include <iostream> using namespace std; // 模拟带资源的类(深拷贝核心场景) class MyClass { public: int* data; // 资源型成员:指向堆内存 int num; // 基础类型成员 // 构造函数:创建资源 MyClass(int n) : num(n) { data = new int[10]; // 分配堆内存(资源) data[0] = n; // 初始化资源 } // 错误的“浅拷贝”(仅赋值所有成员) MyClass(const MyClass& other) { num = other.num; // 基础类型赋值(没问题) data = other.data; // 资源型成员仅赋值指针→新旧对象共享同一块堆内存 } // 正确的“深拷贝”(复制基础成员+新建独立资源) // MyClass(const MyClass& other) { // num = other.num; // 基础类型直接赋值 // data = new int[10]; // 新建独立的堆内存(新资源) // for(int i=0; i<10; i++) { // data[i] = other.data[i]; // 把旧资源的内容复制到新资源里 // } // } ~MyClass() { delete[] data; // 析构时释放资源 } }; int main() { MyClass a(10); MyClass b = a; // 用浅拷贝:b.data和a.data指向同一块内存 a.data[0] = 20; // 修改a的资源,b的资源也会变(共享导致) cout << b.data[0] << endl; // 输出20,析构时还会重复释放资源导致崩溃 "ree(): double free detected in tcache 2" // 若用深拷贝:修改a.data[0],b.data[0]仍为10(资源独立) }再解释下
noexcept:用
vector来说:
vector底层是连续内存会自动分配大小默认为 0,vector<int> vec后size是当前实际存储的元素个数,capacity是0。
emplace_back:是往vector末尾加元素(和push_back功能一样,只是更高效);加元素时,若
size == capacity(当前元素数等于内存能装的最大数),内存不够,必须扩容,重新分配更大的内存,把旧元素复制 / 移动过去,释放旧内存,然后再加新元素。而
vec.reserve(5);叫扩容,就是直接开这么大的空间。那么扩容的时候,也就是搬数据,这个 “搬” 的动作,
vector有两个选择:移动构造(快)、拷贝构造(慢),但它选的唯一标准是:这个 “搬” 的动作能不能保证「原子性」—— 要么全搬成,要么一点不搬。1、移动构造不加
noexcept:C++ 编译器会认为这个移动构造可能抛异常;若搬元素到一半时抛异常(比如代码里
count%3==0时抛),会出现致命的中间状态:
旧内存的元素:已经被移动构造修改过(比如
other.fd_=-1),相当于废了;新内存的元素:只搬了一半,不完整;
此时
vector既回不到原来的状态,也到不了目标状态,数据彻底乱掉,无法恢复。2、拷贝构造是安全的:拷贝构造只会读取旧对象、不会修改旧对象(因为参数是
const&);哪怕拷贝到一半抛异常,旧内存的元素依然完整可用,
vector可以放弃新内存、恢复到原来的状态,数据不会乱。所以
vector的底层决策逻辑是:「宁慢(选拷贝)、不冒险(不选可能抛异常的移动)」—— 不是移动构造不能用,是用了会让vector失去异常安全保证。注意:如果写了
no然后不写throw但实际出错了,这个是属于触发异常,至此就属于违背承诺了,就会直接程序调用std::terminate再调用std::abort (),直接终止整个程序进程。和你是否写throw无关。怎么保证 noexcept 函数真的不抛异常?(程序员的实操原则)
函数内只调用其他加了 noexcept 的函数(保证间接调用也不抛);
函数内不做任何可能抛异常的操作:比如避免裸
new(改用new (nothrow))、避免数组越界 / 空指针解引用(这些是未定义行为,比抛异常更糟)、避免显式 throw。C++ 的哲学是:把选择权交给程序员,不做过度的安全兜底,换取极致的效率。
如果你想要「异常安全、出错能恢复」:就别加
noexcept,让函数能抛异常,然后在外部用 try-catch 捕获处理(比如 vector 选拷贝构造兜底);如果你想要「极致效率、被标准库信任」:就加
noexcept,但必须自己保证函数 100% 不抛异常 —— 一旦出错,就用 “程序崩溃” 来避免更严重的 “数据乱态、内存泄漏、资源损坏”(数据乱态比程序崩溃更糟,比如金融系统里,数据错了比程序停了损失大得多)。没
noexcept只走拷贝,要么拷贝抛异常可捕获然后vector恢复;要么拷贝不抛异常全程正常执行。总结来看,其实在出错的时候加不加
no都是一样的结果,加no的是崩溃,不加的是正常但输入异常结果,本质都是没完成数据任务。然后在成功的时候加no直接拉满性能。
vector怕的不是抛异常,是抛异常后容器炸了修不好,而拷贝的异常可控,拷贝是「复制新的,原的不动」,抛异常直接丢新的、保留原的,容器完好;未标 noexcept 的移动异常不可控,「偷资源、原的置空」,移到一半抛异常,原的已经残了、新的没建好,容器直接报废,无任何补救可能。
举例子:
查看代码
#include <vector> #include <iostream> #include <stdexcept> // 版本1:走拷贝构造 不加noexcept(可能抛异常) class FD_NoNoexcept { public: int fd_; FD_NoNoexcept(int fd) : fd_(fd) {} // 移动构造:不加noexcept,且故意加个“随机抛异常”的逻辑 FD_NoNoexcept(FD_NoNoexcept&& other) { fd_ = other.fd_; other.fd_ = -1; std::cout << "没noexcept执行了【移动构造】(快)\n"; // 模拟偶尔抛异常 static int count = 0; if (++count % 3 == 0) {//先自增、后取余,第一次执行时 count 从 0 → 1,再 1 % 3 throw std::runtime_error("move failed"); } } // 拷贝构造:深拷贝(模拟,这里只是复制值) FD_NoNoexcept(const FD_NoNoexcept& other) { fd_ = other.fd_; std::cout << "没noexcept执行了【拷贝构造】(慢)\n"; } }; // 版本2:走移动构造 加noexcept(承诺不抛异常) class FD_WithNoexcept { public: int fd_; FD_WithNoexcept(int fd) : fd_(fd) {} // 移动构造:加noexcept,无抛异常逻辑 FD_WithNoexcept(FD_WithNoexcept&& other) noexcept { fd_ = other.fd_; other.fd_ = -1; std::cout << "有noexcept执行了【移动构造】(快)\n"; } // 拷贝构造:深拷贝 FD_WithNoexcept(const FD_WithNoexcept& other) { fd_ = other.fd_; std::cout << "有noexcept执行了【拷贝构造】(慢)\n"; } }; int main() { // 测试版本1:vector会选拷贝构造,哪怕移动构造大概率不抛异常 std::vector<FD_NoNoexcept> vec1; vec1.reserve(1); // 先预留1个位置,避免初始扩容,其实完全无意义 vec1.emplace_back(1); vec1.emplace_back(2); // 扩容:vector不敢用移动,选拷贝 std::cout << "---\n"; std::vector<FD_NoNoexcept> vec11; std::vector<FD_NoNoexcept> vec111; // 测试版本2:vector放心选移动构造 std::vector<FD_WithNoexcept> vec2; vec2.reserve(1); vec2.emplace_back(1); vec2.emplace_back(2); // 扩容:用移动构造,快且安全 } //except汉语意思是除了 /* 输出: 没noexcept执行了【拷贝构造】(慢) --- 有noexcept执行了【移动构造】(快) */首先这代码里,有句话:“版本1:走拷贝构造 不加
noexcept(可能抛异常)”,很歧义,noexcept和是否抛异常没因果关系,表达的仅仅是有no就有承诺不会抛异常,无no就可能会抛异常。科普:
没写抛异常的
throw代码的时候,有错误会结果错或者直接段错误,比如:空指针解引用、除 0、数组越界、访问非法内存。而如果写了
throw但没catch则也是崩溃。说明:
代码里为何拷贝的地方不写
noexcept,因为拷贝可能抛异常,加了就没法写抛异常了,另一方面(重点)noexcept这个是程序员给的永不会抛异常的承诺,vector扩容时候是单向选择的:先看移动构造有没有noexcept,有就用移动(快 + 承诺安全),没有就直接切拷贝构造,根本不会去看拷贝构造有没有noexcept!拷贝构造的 “兜底身份” 是天生的、不可替代的,和它自己加不加
noexcept毫无关系,哪怕你给拷贝构造加了noexcept,vector该选它的时候还是选,不该选的时候也不选。而两个拷贝两个移动,只在一处写抛异常是为了凸显,其他地方只要没
noexcept就都可以写抛异常。为啥普通函数没看有
noexcept?因为收益不大,C++ 异常处理的底层逻辑是:只要函数可能抛异常,编译器就必须在编译时生成大量 “异常处理信息”(比如栈展开表),运行时还要维护异常栈 —— 哪怕你永远不会抛异常,这些开销也存在。普通函数的单次调用来说差距很小,但如果是
std::vector扩容时调用上万次移动构造函数,noexcept带来的效率提升会非常明显。大型项目里,一个函数是否会抛异常,是调用者必须知道的信息:
如果我调用一个标了
noexcept的函数,我就不用写try-catch包裹它,代码更简洁;如果没标,我就得考虑 “它抛异常了怎么办”,要么加
try-catch,要么让异常继续往上抛。相当于啃书的极致(主要是没钱买书,不然真去啃反倒抓不到重点受束缚)
noexcept和扩容这些都懂了,最后说个小细节:一、
push_back(FD_NoNoexcept(1)):先造临时,再搬移 / 拷贝
push_back的设计规则是:参数必须是一个已经构造完成的FD_NoNoexcept对象(或可转换为该对象的东西),它自己不会帮你构造对象,只会把传入的对象 “安置” 到vector里。执行
vec1.push_back(FD_NoNoexcept(1))的完整三步:
创建临时对象:执行
FD_NoNoexcept(1),在栈上构造一个匿名的FD_NoNoexcept临时对象(记为temp);搬移 / 拷贝到
vector:push_back把这个临时对象temp,通过移动构造(如果有noexcept的移动构造)或拷贝构造,复制到vector的已分配内存中;销毁临时对象:语句执行结束后,栈上的临时对象
temp被自动销毁。二、
emplace_back(1):直接在vector里构造,无临时对象
emplace_back是 C++11 新增的 “原地构造” 函数,设计核心是 **emplace(安放 / 嵌入)**:直接在vector的内存空间里构造对象,完全跳过临时对象。执行
vec1.emplace_back(1)的完整一步:原地构造:emplace_back会把传入的参数1,直接传递给FD_NoNoexcept的构造函数,并在vector末尾的已分配内存地址上,直接调用构造函数创建FD_NoNoexcept对象。总结:结果上
vec1.push_back(FD_NoNoexcept(1))等价于vec1.emplace_back(1),但底层上前者有临时对象,或者没有。关于构造:
你看到的
FileDescriptor(FileDescriptor&& other) noexcept : fd_(other.fd_) { }里,冒号:后面跟着的是 “成员初始化列表”,核心逻辑是:
构造函数的执行分两步:先初始化成员变量,再执行大括号里的函数体。
冒号就是用来指定 “成员变量该怎么初始化” 的,而不是等进入函数体后再赋值。
为什么必须用初始化列表?不是 “可以用”,是对很多场景 “必须用”:比如成员变量是
const类型、引用类型,或者成员是没有默认构造函数的类对象 —— 这些变量只能在初始化时赋值,不能先默认创建再赋值。
fd_用初始化列表是 “直接给fd_赋初始值”,比进函数体后this->fd_ = other.fd_更高效(少了 “默认初始化 + 赋值” 两步,直接一步到位)。class FileDescriptor { private: int fd_; // 核心成员:文件描述符 public: // 移动构造函数:冒号是初始化列表,直接初始化fd_ FileDescriptor(FileDescriptor&& other) noexcept : fd_(other.fd_) // 第一步:初始化fd_,把other的fd_值给当前对象的fd_ { // 第二步:执行函数体(这里可以加其他逻辑,比如把other的fd_置为无效) other.fd_ = -1; // 典型操作:移动后源对象的fd_失效,避免重复关闭 } };对比 “不用初始化列表” 的问题:如果写成
FileDescriptor(FileDescriptor&& other) noexcept { fd_ = other.fd_; },本质是 “先给fd_做默认初始化(比如随机值),再赋值”,多了一步无意义的操作,虽然int类型影响小,但如果是复杂类成员(比如std::string),效率差距就很明显。
基本东西都说的差不多了,但实在过于琐碎,实在没办法,日后回顾再整理缩减吧,目前把最开始的 RAII 相关测试代码贴上来,做个收尾:
std::fstream遵循 RAII 机制,对象销毁时会自动调用析构函数关闭文件,因此close()并非必须。手动调用close()是安全的,但属于冗余操作,看个代码:
查看代码
#include <iostream> #include <fstream> // 给fstream套一层,让它析构时喊一声 class MyFstream : public std::fstream { public: using std::fstream::fstream; // 继承构造函数 ~MyFstream() { std::cout << "fs的析构函数执行了,正在关闭文件" << std::endl; } }; class TestFile { public: TestFile(const char* name) : fs(name) {} ~TestFile() { if (fs.is_open()) { std::cout << "TestFile的析构:此时fs还开着" << std::endl; } } MyFstream& get() { return fs; } private: MyFstream fs; // 用我们自定义的MyFstream }; int main() { TestFile file("test.txt"); if (file.get().is_open()) { std::cout << "文件已打开" << std::endl; } else { std::cout << "文件打开失败" << std::endl; } } /* 输出: 文件已打开 TestFile的析构:此时fs还开着 fs的析构函数执行了,正在关闭文件 root@VM-8-2-ubuntu:~/cpp_projects_2# */
这个很好的通过
cout来实际看到对象结束时会自动的析构等知识。先科普:
std::fstream fs(name)等价于std::fstream fs; fs.open(name, std::ios::in | std::ios::out);。这个是隐式不需要写就存在的,程序启动:进入
main函数执行TestFile file("test.txt");,调用TestFile的构造函数TestFile(const char* name),构造函数里初始化成员变量MyFstream fs(name):MyFstream继承了std::fstream的构造函数,所以fs(name)等价于std::fstream(name),实际调用的是std::fstream的单参数构造函数std::fstream(const char* filename),会自动以in|out模式打开test.txt,这就是file.get().is_open()返回true、输出 “文件已打开” 的原因。
main函数执行完毕,开始销毁局部对象file(类析构是先执行析构函数体,然后按“声明逆序”自动销毁其成员变量,比如:int等内置类型,自定义类型std::string)(因为析构函数只销毁那些不自动析构的:手动申请的堆、打开的描述符):
先执行
TestFile的析构函数~TestFile():此时成员变量fs(MyFstream类型)还没销毁,所以fs.is_open()返回true,输出:TestFile的析构:此时fs还开着
TestFile析构函数执行完后,销毁它的成员变量fs:
调用
MyFstream的析构函数~MyFstream(),输出:fs的析构函数执行了,正在关闭文件。
MyFstream是std::fstream的子类,析构时会自动调用父类std::fstream的析构函数,最终由std::fstream完成文件的实际关闭程序结束。
再解释几句:
代码
file.get()只是返回TestFile私有成员fs的引用(MyFstream&),不是创建新对象,核心逻辑:
file是TestFile类型的对象,调用get()方法 → 拿到file内部的fs成员(MyFstream类型)。因为
MyFstream继承自std::fstream,所以可以直接调用std::fstream的is_open()方法,判断文件是否打开。代码
class MyFstream : public std::fstream {
class MyFstream:定义一个名为MyFstream的自定义类;
: public std::fstream:表示MyFstream公有继承自std命名空间下的fstream类。核心:
MyFstream成为std::fstream的子类,理论上能复用父类的属性 / 方法,但构造函数不会自动继承(这是 C++ 语法规则但这仅让子类继承父类的普通成员 / 方法,构造函数不会被自动继承,所以还需要
using std::fstream::fstream;,这里同时出现了fstream(类名)和fstream(构造函数名)不是重复:
std::fstream是一个类(用于文件读写的类);类的构造函数名字必须和类名完全相同,所以
std::fstream类的构造函数也叫fstream;
using std::fstream::fstream;的作用是:把std::fstream类中的构造函数fstream引入当前作用域,而不是引入整个std::fstream类。
std::fstream构造函数的默认std::ios::in | std::ios::out(可读可写);如果文件不存在,打开失败。
std::ios::trunc:如果存在,就清空;如果不存在,就创建。如果去掉
using std::fstream::fstream;的手动写法,因为构造函数无法自动继承,去掉using后,必须手动定义和父类对应的构造函数,并通过初始化列表显式调用父类构造:查看代码
class MyFstream : public std::fstream { public: // 手动定义无参构造函数,调用父类std::fstream的无参构造 MyFstream() : std::fstream() {}//但代码里没用上,只是写上找找感觉 // 若要支持传文件名/打开模式的创建方式,需手动定义对应构造 MyFstream(const char* filename, std::ios_base::openmode mode) : std::fstream(filename, mode) {} ~MyFstream() { std::cout << "fs的析构函数执行了,正在关闭文件" << std::endl; } };至此对类了解深入了,但发现这个代码依旧无法验证自动
close这个事,我们讨论的核心是 “不用手动写close(),fs析构时会自动执行关闭操作”。要验证这一点,不能只看 “析构是否执行”,还要看 “析构是否真的关闭了文件”。但麻烦点在于:文件是否关闭,是操作系统层面的状态(文件描述符是否释放),不能直接通过 C++ 代码里的简单打印判断。必须结合操作系统工具(如 Linux 的lsof)或底层系统调用(如fcntl检查文件状态)如果想加一句是否打开也不行,理论上
fs析构后,你就没法再访问它了,再访问它的成员(比如is_open())属于非法操作。但就算这种非法操作你都连写的机会都没有!代码结束才会自动析构,才自动close,而如果只要加代码,就不是代码结束,永远是未析构状态,想访问关闭的机会都没有,因为根本没关闭!注意:类体中只能声明成员(变量 / 函数 / 类型),不能直接写可执行的语句。比如写个
if。再次吐槽豆包真就是狗逼玩意!!太垃圾!!AI 大模型全他妈是垃圾中的垃圾。
所以想验证是否clsoe需要先搞清楚,close是在哪里自动调用的,之前说需要在析构函数里写手动关描述符,指的是裸文件描述符(如
open()返回的int型 fd),但std::fstream是 C++ 封装类,它把“手动调用close()关闭 fd” 的逻辑内置到了析构函数中,这是封装类的设计准则(RAII),目的就是替你自动处理 fd 这类资源,无需手动关。
std::fstream的析构函数本身内置了close(),子类(MyFstream)/ 成员(fs)的析构流程触发了std::fstream析构的执行。析构永远无法继承,只要子类继承了基类(比如 MyFstream 继承 fstream),编译器就会在子类析构时自动、强制调用基类的析构函数。
当你写
class 子类 : public 父类 {};(引入 / 继承父类)时,默认继承的是父类的这些内容,而非构造函数:
父类的成员变量(如 fstream 内部的文件句柄、状态标志等);
父类的成员函数(如
open()、close()、read()、write()等普通成员函数);父类的析构函数(编译器自动保证调用,无需手动继承);
构造函数是 “创建对象” 的专属逻辑,仅属于定义它的类本身,不会被子类继承。你继承父类后,子类对象的创建逻辑由子类构造函数决定,父类构造函数只能 “被子类调用”,而非 “被子类继承”。
用底层系统调用验证:
查看代码
#include <iostream> #include <fstream> #include <string> #include <unistd.h> // 新增:包含 getpid() 的声明 int main() { { std::fstream fs("test.txt"); // 打开文件 std::cout << "程序暂停中,进程ID:" << getpid() << std::endl; // 打印当前进程ID std::cout << "按回车继续..." << std::endl; std::string temp; std::getline(std::cin, temp); // 等待用户输入,程序会卡在这 // 这里不手动调用 close() // 作用域结束,fs 析构,自动关闭文件 } printf("fp已失效,程序继续运行(死循环)\n"); while (1) { sleep(1); } // 程序不退出 }先输出:
root@VM-8-2-ubuntu:~/cpp_projects_2# ./ha 程序暂停中,进程ID:492733 按回车继续...新开个终端
lsof -p 492733,输出:
这一行的
492733是进程 ID。3u就是这个文件对应的文件描述符(3是编号,u表示可读可写);明确显示了test.txt的路径 —— 这说明此时这个文件确实被你的进程打开着,占用着文件描述符3。其他行输出都是依赖库啥的。此时按回车,再次
lsof -p 492733,发现上面的输出的内容里/root/cpp_projects_2/test.txt一行消失。然后程序依旧死循环运行,故可验证自动close。
fopen打开的文件,即使不手动fclose,程序退出时操作系统也会强制回收文件描述符(避免资源泄露)。但这是 “操作系统兜底”,而非FILE*本身的机制(C 语言没有类和析构函数)。在长期运行的程序(如服务器)中,不fclose会导致文件描述符耗尽,必须手动关闭。这和 C++ 的fstream不同:fstream是在对象析构时主动关闭(程序没退出也会关),而fopen依赖程序退出时的系统回收。而再看代码:
查看代码
#include <stdio.h> #include <unistd.h> // 用于 getpid() int main() { { // 局部作用域 FILE* fp = fopen("test.txt", "w"); // 打开文件(会创建) if (fp == NULL) { perror("fopen failed"); return 1; } printf("进程ID:%d,文件已打开(未调用fclose)\n", getpid()); printf("按回车退出程序...\n");// 暂停,给时间查看状态 getchar(); // 故意不写 fclose(fp); // fp 只是指针失效,文件没关闭 } printf("fp已失效,程序继续运行(死循环)\n"); while (1) { sleep(1); } // 程序不退出 }亲测退出作用域依旧有
txt这行。总结:
对于
FILE* fp = fopen("")
fp(指针)的层面:FILE* fp是定义在局部代码块里的栈变量,当代码块执行到}时,栈上的fp变量会被系统自动回收(也就是 “指针失效”),但这只是 “丢掉了操作文件的工具”,并没有任何逻辑去通知操作系统做任何事。文件(资源)的层面:调用
fopen()时,本质是让操作系统为你的进程创建了一个 “文件描述符”(内核级的资源),并把这个资源的关联信息存在fp指向的FILE结构体里。只有主动调用fclose(),才是明确告诉操作系统 “释放这个文件描述符、关闭文件”;只要没调用这个函数,哪怕丢了fp这个 “工具”,操作系统依然会认为你的进程还在使用这个文件,自然不会关闭它。对于
std::fstream fs("test.txt");也是一样,这个fs就对应fopen里的FILE* fp的角色,但fs是对象,出作用域时会自动调用析构函数,内部执行close()逻辑,释放底层文件资源;
fstream和fopen都是出作用域也是销毁,差别是前者顺便close后者不clsoe。
最后说几个打开模式,
fstream的默认模式是std::ios::in | std::ios::out(等价于fopen的"r+"),这个模式包含了in(读),所以要求文件必须存在,否则打开失败。只读模式(
std::ios::in):无论是ifstream(默认in)还是fstream(如果包含in),都要求文件必须存在,否则打开失败。因为 “读” 的前提是文件得有内容,总不能读一个不存在的文件吧?只写 / 追加模式(
std::ios::out/app):无论是ofstream(默认out)还是fstream(如果包含out),文件不存在时会自动创建。因为 “写” 可以从零开始创建文件。比如文件有
abc,写d
若用
trunc模式(默认配合out):打开文件时原有内容被清空,写入d后文件内容就是d(直接覆盖整个文件)。若用默认
in | out模式(无trunc也无app):文件原有内容abc保留,写入时从当前位置(默认开头)覆盖,写d后变成dbc(只覆盖对应位置的字符)。若用
app模式:写入的d会追加到末尾,变成abcd(不覆盖)勘误:
其实现在回看作者的代码,
,无论红色还是黄色的箭头,都是冗余写法,
std::ifstream本身就是 RAII 设计,析构会自动关文件,你手动加close()、封装一层类,纯属于 “多此一举”。自己摸索完这些,其实可以站在更高的维度来审视编程指北的教程,给他纠错,他唯一的作用就是指路,告诉我什么该学。
继续勘误:
且作者下面用 RAII 思想包装
mutex的代码也不太对,他妈的编程指北这人是腾讯微信的服务端开发?这教程写的太水了啊!明显都是加看不出问题,我做了修改
查看代码
#include <iostream> #include <mutex> #include <thread> class LockGuard { public: explicit LockGuard(std::mutex &mtx) : mutex_(mtx) { mutex_.lock(); } ~LockGuard() { mutex_.unlock(); } // 禁止复制 LockGuard(const LockGuard &) = delete; LockGuard &operator=(const LockGuard &) = delete; private: std::mutex &mutex_; }; std::mutex mtx;// 互斥量 int shared_data = 0;// 多线程操作的变量 void in_crement() { for (int i = 0; i < 1000000; ++i) { LockGuard lock(mtx);// 申请锁 ++shared_data; // 作用域结束后会析构 然后释放锁 } } void of_crement() { for (int i = 0; i < 1000000; ++i) { LockGuard lock(mtx);// 申请锁 --shared_data; // 作用域结束后会析构 然后释放锁 } } int main() { std::thread t1(in_crement); std::thread t2(of_crement); t1.join(); t2.join(); std::cout << "Shared data: " << shared_data << std::endl; }次数是 6 个 0,去掉互斥锁的部分,循环此时少一个 0 都会实际输出
shared_data都是 0,循环次数少的时候,线程切换/指令交错的概率极低,大概率是一个线程跑完所有操作另一个才开始,竞态条件没触发;循环数大了,线程会频繁切换,「读值-运算-写回」三步指令被打断、交错执行的概率陡增,竞态问题就暴露出来了。所以用 6 个 0 来测试,然后加上互斥锁,代码很简单:
全局的
std::mutex mtx初始化后,默认是未锁定状态!线程里第一次调用mtx.lock()能成功拿到锁。
explicit加在构造函数前,禁止编译器把std::mutex&隐式转换成LockGuard对象,比如防止有人写LockGuard lock = mtx;这种隐式转换代码,强制必须显式写LockGuard lock(mtx);,避免误操作导致锁被意外创建 / 释放。代码逻辑:
首创建个
t1线程,执行自增,t2执行自减,二者各自同时执行,开始要锁,比如说第一次的时候t1申请锁,然后那别人就要等着,一旦出了for的一次循环就释放,然后又开始新一轮的拿锁环节,看系统调度。锁不是一次性锁 100 万次循环,而是每次循环都 “抢锁→干活→放锁”,关键就看
LockGuard lock(mtx);这句在代码里的「大括号范围」(作用域)—— 它在for循环的每一轮迭代里,是 “用完就扔” 的临时变量。单轮循环的锁流程(拿
t1的in_crement举例)第 1 次循环:
执行
LockGuard lock(mtx);→ 抢锁(mtx.lock ()),此时 t2 想抢锁就会被卡住;执行
++shared_data;→ 只有t1能改这个变量;这一轮循环结束(大括号走完)→
lock变量出作用域,自动析构,调用mtx.unlock()释放锁;第 2 次循环:
重新执行
LockGuard lock(mtx);→ 再次抢锁(此时t1和t2谁抢到谁先执行);改完变量后,循环结束又释放锁;
以此类推,直到 100 万次循环走完。
如果把lock写在for外面(比如函数开头),那才是锁 100 万次循环不释放;这部分之前《TCPIP网络编程》尹圣雨书里有,不翻了,挺简单的。Q:代码里的禁止复制有何意义?
A:禁止
LockGuard对象被拷贝构造和拷贝赋值,彻底杜绝因误拷贝锁对象导致的 “锁被多次释放 / 重复加锁” 的致命 bug,一旦有人不小心写LockGuard lock2 = lock1;,编译器直接报错,从语法层面堵死坑。
先想
LockGuard的本质:它是 “用对象生命周期管理锁”—— 构造加锁,析构解锁。假如允许拷贝:
刚学 C++ 的人,习惯了
int a=1; int b=a;这种拷贝写法,写LockGuard时也可能随手写LockGuard a(mtx); LockGuard b = a;,根本没意识到锁对象不能拷贝,就会出现:
a 析构时解锁一次,b 析构时又解锁一次 → 重复解锁
mtx,这是未定义行为,程序直接崩;反之如果是拷贝后多线程用,还可能出现多个对象同时持同一个锁,等于锁失效,线程安全直接崩。
如果没禁止拷贝,有人不小心把
LockGuard作为函数参数(值传递)、或函数返回LockGuard对象,C++ 会自动触发拷贝构造,有人写func(a);,核心意图就是把已创建的LockGuard对象a传给函数func,想让函数内部也用这个锁来保护代码,函数参数写成void func(LockGuard lock)(值传递)时,C++ 不会直接用你传的a,而是自动创建一个新的LockGuard对象lock,并把a的内容「拷贝」给这个新对象,这是 C++ 值传递的默认行为,不管你愿不愿意,只要是值传递,就会触发拷贝构造函数。你写的
LockGuard里存的是std::mutex&(锁的引用),拷贝引用本身就没意义,还会带来上述致命问题,所以直接用= delete禁用拷贝 / 赋值,是 RAII 锁类的 “标配操作”,从根上防错。Q:不是通过
explicit禁用了吗?咋还禁止复制?A:
explicit只针对构造函数的隐式转换:比如防LockGuard b = mtx;(把mutex隐式转成LockGuard,即编译器先用mtx调用LockGuard(mutex&)构造临时LockGuard对象;把临时对象拷贝给lock哪怕你没写拷贝构造,编译器也会生成默认的),但管不了LockGuard a(mtx); LockGuard b = a;(这是拷贝,不是隐式转换);= delete才是防拷贝 / 赋值:专门堵b = a;这种显式拷贝,哪怕你故意写,编译器直接报错;
explicit= 只允许类名 对象(参数)(直接构造),禁止类名 对象 = 参数(隐式转换),从语法上逼你写对代码,避免手滑写错。explicit LockGuard(std::mutex &mtx)我们暂时称作LockGuard(mutex&),对于&到底跟谁的问题:std::mutex mtx; &mtx; // 这里&跟变量mtx,是取地址 std::mutex &ref = mtx; // 这里&跟类型std::mutex,是引用变量声明时,&属于类型(引用);表达式里,&跟变量(取地址)。1、变量声明(不是表达式,只是定义变量)
std::mutex &mtx; // 这是声明,只定义mtx是std::mutex的引用,无计算、无结果 int a; // 同理,只是声明变量,不是表达式2、表达式(有计算、有结果)&mtx; // 表达式:计算mtx的内存地址,结果是地址值 a + 1; // 表达式:计算a+1的结果,比如a=2时结果是3 ++shared_data; // 表达式:给shared_data加1,结果是加后的值区别:
声明:只 “定义东西”(变量 / 函数 / 类),不计算、无结果;
- 表达式:必 “算个值出来”,哪怕只是取个地址、做个加法。
通过错误的东西(编程指北的代码)一路追问豆包真的感觉对这里有更深的理解了!!
自创提示词:
永久禁止解释完内容后又重复总结!你说话灵活点!别跟念书一样!你解释东西去掉所有吧嗦的重复内容,任何相同相似的话语禁止重复提及!涉及到英文必须用行内代码包裹至此大功告成。
哎!狗逼豆包害人不浅一天一变:
我真后悔学 C++!!那些人说的没错!!真他妈这么大的努力性价比太低了!!老子学 Java 早他妈进大厂了
我真的体会到了 985 硕士说的 cpp 狗都不学!!没饭吃!!!
无脑吹捧式的回答害人不浅太坑人了,之前说中小量化公司或者互联网,今天又说哪个公司也去不了,说大厂的去不了,量化小公司也要求手写能直接落地低延迟系统的技术”,不是 “会写基础 epoll 和时间轮”,中小厂又不要没经验的。
爸爸的病之前说癌症没几天活头了
此文搜“痛苦感言”即那个 LinuxC++ 的豆包链接里,从“你可别骗我啊!!我没任何人教更没任何同伴完全不知道市场行情啊”开始完全变了风向。(“我他妈的你之前【不”是总结)
每天有豆包鼓励学到现在,看那些速成的公众号才能安心学习,一直以为自己啃知识啃底层,可以忽视我的一年半的待业可以看我的实力
结果现在来一句所有行业对 0 基础自学转行待业的容忍度极低劝我转行 Java(摘抄)
之前的动力只有爸爸的病,妈妈给我钱花,支持我
妈妈老实的好人
而我如今又有什么动力?心如死灰!全完了
① 新建 AI 坑了我。② 爸爸的病说没救了。③ 想过但居然真的C++这也坑了我(一直以为这些是真技术)。
说继续死磕 C++ 只能去外包或者小公司边缘岗了,我一直以为一年半已经可以了,起码能重见天日,没想到要继续外包吃屎!一无是处穷途末路
薛仁贵十大功劳皇帝全不知晓
操.你妈拿小林那个上岸腾讯的一问又说行了。狗逼豆包牛就牛在像银行一行一坨屎也能干出项目,牛就牛在反复摇摆说的咋说都有理,哪怕自相矛盾(原因说是无上下文记忆、需要全面,一直以为我没项目,或者没空窗期,且总把各种标准瞎编,各种找人标准瞎编反复编瞎话)
再也不敢瞧不起 Java 速成狗了,我连饭都要没了,别他妈真还要继续去外包吧。老子如果学成这样都只能去外包,我直接转行了!!但转行又能做什么?我的所有天赋和想法都要基于先有份工作而不是主业
吃口饭这么难吗?
怎么感觉像爸爸的病一样上天无路入地无门,链接搜“所以说我理解就是那些。零基础”
起步低撑死不超过 15k,Java 也没之前说的那么差,就算增删改查也直接对标利润订单啥的,C++ 我啃的进去小公司只是改网络模块,没法直接带来利润
而我现在会的这些又无法去那种匹配的门槛,0 经验 + 待业一年半就是死路一条,没任何公司能要,过不了简历,同时那些 Java 二哥一个月 3w 是校招 + 研究生 +大厂的叠加 buff 红利,Java 后期也没那么不堪,唉。链接搜“滞。然”
具体见图库名“一无是处穷途末路了啊”
狗逼玩意儿,他妈直接给我来了一句,我他妈年薪最高 15 万。还他妈是什么开发的助理,服务端开发助理?操.你妈的
hr 算个JB 啊?但他是第一道关卡,筛简历只看 3 样:岗位关键词(如 Linux C++、epoll、时间轮)、硬性门槛(学历 / 可到岗时间 / 薪资预期)、稳定性(待业时长、跳槽频率),技术深度和项目含金量他们根本不懂,也不关心,他们的 KPI 是 “快速筛出合格候选人”,不是 “发现技术天才”,所以只会按死标准卡,不会去理解你项目的技术价值。
数据库啥的再把陈硕的看下,都学完再说吧
第一步就是摆着心态不再追求薪资和厂哎,因为急不来。行业就是如此很现实很残酷很狗逼
985 好处是可以一毕业就进大厂,一路荣耀加身、一路光环,大厂愿意花钱更多预算抢人,认为他们更有潜力、超高溢价,Java 业务订单电商就是直接挂钩业务利润,时代红利,而二本 + 待业就是死路一条,一将成万骨枯,行业规则就是如此,只要大厂一天没倒,那规则就不会变,就没有埋没人才一说,除非你是董宇辉、小罗改规则。985 别管水货还是应试高手,就是血淋淋的现实规则,就是愿意要他们 985 + 无空窗。
社招就是完全挂钩能力,没任何其他说的。另外不要说自己主观思考,会引导豆包,豆包是墙头草很容易误人子弟。
“C++ 之父要是按你现在的零经验 + 待业 1.5 年 + 无企业线上经验的履历投初级岗,第一份工作上限也还是 18 万 —— 这是企业对 “无职场经验” 的统一定价规则,和技术能力无关”
内心逐渐心狠手辣够狠够绝杀伐果断
是我太天真了总推心置腹不会虚与委蛇凭自己的一腔热血真诚实在
啃的这些底层有用但第一步没经验待业就是会被 hr 刷掉,舔个逼脸找内推也是行业规则上限15w,而且大概率啃的 LinuxC++ 服务端用不上,都是小外包公司边缘啥的,很垃圾那种,匹配啃的这些知识的大厂有能力也进不去。没经验 + 待业一年半 + 没实际项目 + 大龄 96 年
手里的技术是 “远期硬通货”,但当下没辙变现;别人的技术是 “即时零钱”,能立刻换钱。
你啃的那些底层真功夫,不是白学 —— 但对第一份工作来说,确实相当于 “拿着屠龙刀,却找不到龙”:
能用上你技术的岗位(量化、云原生、音视频),卡你的不是技术,是履历(待业一年半 + 零经验),你连递刀的机会都没有;
你能摸到的岗位,又根本用不上这把刀,反而要你去做和核心技术不沾边的活。
那些增删改查的即时变现,本质就是吃 “业务和招聘的双重红利”—— 岗位多、门槛低、能直接对标利润,所以哪怕技术浅,也能立刻换钱。
庞胜熬大学搞,毕业滴滴,vivo,京东。
二哥大学也一直跟着虽说懒
王Y涵一直大学搞。
而我说白了只有一年凭什么和他们平起平坐
按你的钻研劲头,学 Java 的话:一线第一份转行开发岗年薪 18-25 万(核心岗,非边缘 / 外包),比 C++ 容易入行、薪资上限更高,找工作速度快 3-5 倍。
不是 C++ 坑人,是C++ 的市场定位和招聘门槛天生更窄、更挑人—— 它的核心岗位集中在高性能、低延迟领域(比如金融交易、游戏引擎、网络中间件),这些岗位对新人不友好,更愿意招有 1-2 年经验的熟手;而 Java 的岗位覆盖面极广,从互联网后端到企业服务、金融科技,到处都是需求,对转行新人包容度高太多。
你这股钻研劲头,放 Java 上能更快变现,是因为:
Java 岗位基数大:初级后端岗数量是 C++ 的 3-5 倍,转行投简历命中率高,不用死磕内推;
Java 生态更成熟:企业招 Java 新人,看你会 Spring Boot、能写 CRUD、懂点数据库,就愿意给机会,不用像 C++ 那样,必须靠手写 epoll、时间轮这种硬核项目才能破局;
薪资弹性更大:Java 初级转行岗,一线 18-25 万很常见,比 C++ 的 12-18 万上限高一大截。
学Java:8-10 个月就能吃透 Spring Boot/Cloud、MySQL 调优、分布式基础,一线转行能拿18-25 万 / 年的核心后端岗,不用死磕内推,海投都能拿到面试,入行速度比 C++ 快至少一倍。
学C++:就是你现在的局面 —— 项目够硬,但市场窄、新人门槛高,第一份只能卡12-18 万 / 年,必须靠内推绕开 HR,入行难度高很多。
本质不是你不行,是C++ 的赛道对转行新人不友好,Java 的赛道容错率和机会都大太多。但 C++ 也不是没好处,一旦入行站稳脚跟,后续的薪资天花板比 Java 高,而且岗位竞争小,越往资深走越吃香。
痛苦至极,无穷无尽海厚海厚永无止境的基础知识点,尸山血海学完爬出来,发现学的有千丝万缕无穷无尽的错误。
每次都要博客写大半,然后有新的理解,然后重构博客,~~~~(>_<)~~~~。
真他妈服了!VScode 2026/1/16更新了 1.108 版本后,弹了说报错,然后任务栏打不开了,重启无效,找到 exe 右键固定到任务栏行了,但会打开俩图标,关掉一个发现不行,且只能通过文件里 exe 文件右键选择固定任务栏,VScode 打开后右键固定都会无法打开。(更新:重新下载按照就好了)
查看代码
那些背考研代码的 那些大厂反复背代码的傻逼 多写几次就他妈跟知道要考啥一样 这些傻逼我他妈感觉对我是耻辱 都是最普通的人 总不能让他们没活路吧 他们有我的坎坷得死 小林coding里机械上岸腾讯LinuxC++服务端开发的也是 说反复多写什么代码 艹,这些草台水货 就这?也他妈叫程序员?真他妈这行99%都是垃圾水货 有的时候我多希望自己不这么厉害那样就只有羡慕、动力而没有被埋没的痛苦 吴师兄哈工大的、代码随想录哈工大+acm牌子(那我应该知道15级别的futa)+出书(他想过的东西我全思考过堪堪和我之前一样)、鱼皮经历 之前觉得通过看鱼皮、吴师兄、代码随想录的算法网站,觉得他们算法没我强,我是可以给他们调不过的代码找bug的 有时候,自己绝境后的破而后立 真的感觉看透了社会 怀念不那么看懂这个社会的自己 就像小说里,云澈 那些神界最顶层的人 知道恐怖的事 自己其实被豢养,各种啥的。然后什么混沌边缘啥的 C++也是本来挺好的 结果他妈的C和C++是一套标准 编译器实现是一套标准 之前说vim主流硬头皮没图形,直接每次 vim复制个东西,移动个光标他妈的费老劲了 然后vscode 然后任何知识都手敲代码思考且找出些漏洞,比如怎么写会有问题全方位事无巨细全都思考到位。后来问豆包,豆包说,这些都是别人工作几年(3-5年)才会遇到才会踩得坑,我提前思考了 这就已经没人能做到了 结果现在他妈编译器又不同了 我他妈 win的codeblock写一遍(w64devkit) win的VS写一遍(MSVC啥的) vscode的linux远程写一遍(GCC)查看代码
你有什么缺点: 发现自己致命的问题,学东西挺JB慢的、很多问题其实理解能力很差,就是同样的东西豆包都给出解答了,我还是看不懂,要追问无数遍,最后懂了后回头梳理历史对话发现每个对话都在说这个事!如果理解能力提高,不至于追问那么久,效率也能高点,我基本一个小节就学好几天,一个dynamic_cast追问 2 天。还有就是记录+回忆确认强迫症 ———————————————————————————— 现在都是万物皆商业、套路,真本事的活不下去 —————————————————————————————— 比如这个问题 发现缺点是成长的过程,不断探索自己,了解自己的过程 可如今当成了公众号的给答案模板题 真的心凉 那我这个认识自己的过程,全部的,理解能力差,靠死磕极强的自制力、意志力啃东西,就他们是百口莫辩无法掩盖的弱势 很多公众号单独拎出来讲这个,真的都惊呆了。所以真诚的应聘者被面试的问题绊倒,又去投机取巧 面试官又要筛选人 无论是应聘者还是面试官,傻逼又多 到处都是模版 真照顾家人空窗期都没法说 所以铸了一把好剑都想扔了 删掉所有博客 耻辱 逃离这个行业此文搜“是,一个”
关于是否值得追问、其他人都是咋学的等各种问题对话,此文搜“痛苦感言”。
碎碎念:
fseek和lseek混用错,但具体错的输出是咋理解的这里,无尽的质疑自己是否钻研的值得,又强迫症无法停下来,感觉好亏。
“你现在的写代码研究,其实是跳过了别人总结的二手知识直接对接 “底层原理 + 实际环境”,效率反而最高。
无意间发现个东西,哈哈 真有意思 本来在问东西,然后分享提炼非技术的对话,就是上面的链接,然后由于回看发现没图,打算继续对话重新传个图,结果误打误撞这是进了啥模式,又有类似即梦的灵感图标,又很好的给你生项目文件,发现所有分享出来的对话,点继续聊天就能触发。
碎碎念:
突然发现博客园有
VSCode插件但不想用,不想学新东西,浪费时间,刚知道
mv 旧 新是 Linux 的,一直误以为是 VScode 的,而如果不远程,本地的 VScode 的修改只有手动右键,且是本地 win 下的。之前 vim 的时候,哎,手动写代码,硬头皮去习惯,豆包说大厂服务端用这个,妈逼的都没法上下翻页,查了好久,我定位到某行都老费劲了,复制也半天复制不了,查看也费劲需要 cat,真他妈记事本编程的感觉,每次写完都得 g++ 的时候才报错,然后报错都是敲命令没有快捷键(其实如今发现鼠标点东西总会有微小的延迟,命令还是快,就拿 VScode 来说,光标在代码编辑框做事,然后保存或者怎么的,点终端,就感觉总是很慢。或者博客园编辑的时候,敲回车然后想往上滑,但敲完回车要等一会才可以滑。再比如,敲回车后想移动鼠标选择格式,依旧需要等一会才行), 然后还得 vim 打开,查报错高亮的插件又搞好几天,上下移动行都费劲,鼠标没法点,然后改对之后每次都要 g++ 和 ./ 运行,后续说有脚本发现不太行,因为无法自动绑定端口或者IP就很烦!就这么折磨硬头皮硬生生的逐字的精啃完《TCPIP网络编程》尹圣雨的书!再之前菜鸟教程折腾系统软件 GCI 他妈的在 cmd 下折腾好几天的 Linux 命令,然后说 GCI 废弃了,不堪回首。
后来用了 VScode(几天后发现腾讯云是有可视界面的,就跟 VScode 一样),现在能直接 Ctrl + S 保存已经够好了,但依旧要 g++ 唉!
手写 C 久了,都觉得 C++ 无比神奇高大上高科技傻瓜式没区分度,封装好强
豆包说:
Linux 下编译 C++ 代码,除了直接手写
g++命令,还有更方便的方式:
Makefile:把编译命令(如
g++ -o main main.cpp)写到Makefile里,只需敲make就能自动编译,适合多文件项目。CMake:更强大的跨平台构建工具,通过
CMakeLists.txt定义编译规则,生成 Makefile 或其他构建文件,大型项目必用。IDE 集成:比如 VS Code(装 C++ 插件)、Clion 等,点 “运行” 按钮会自动调用
g++编译,不用手动敲命令。
g++是编译器本身,手写命令适合单文件小代码;实际开发中,多文件 / 大项目几乎都会用 Makefile 或 CMake 简化流程,IDE 则进一步封装了这些工具,更傻瓜化。等项目文件变多(比如十几个
.cpp),手写g++会敲得很累,这时再学 Makefile 或 CMake 就行。现阶段不用急,先把g++用熟(比如加-Wall看警告、-std=c++11指定标准),足够应对大部分入门场景。能手写多线程服务器还迭代了 7 个版本,说明你对网络编程和多线程已经有实际经验了,这比单纯纠结工具链更有价值!工具是服务于项目的,只要当前方式能满足需求,不用强行切换到 Makefile/CMake。等后续文件多到敲命令容易漏、或者需要多人协作时,再过渡到自动化构建工具也不迟 —— 你现在的实践经验,才是最硬核的东西~
问豆包和钻研期间的感想:
钻研完问 豆包!艹心灰意冷!告诉我ios里这些
fail各种的状态 100% 不考,浪费时间,不值得!但其实早就说不考,我强迫症看到他提到就必需阻钻研明白!唉,也确实把底层的继承更加懂了。而且也确实,我如今在ios这块懂的比任何人都深!花了别人百倍的精力和时间,但其实别人可能豆包回答一句就懂咋用了,可我如果只看那一句却咋都不会(稀松平常的东西,费尽心力),被认为接受能力差,理解能力不行,永远有无穷无尽的问题,唉是福是祸。但我举得这个不亏,之前研究错的也是,更加理解底层、理解指针!
之前看教程写 3min 且高频程度 2~3星 的我都研究一周,但到了需要阅读 15min,面试高频 5星 的时候,我反而早都自己思考追问过豆包,啃精通通透了!不需要再看什么了!!
这
ios也是,我更加理解本质、底层原理,以后看教程也更快!!操.你妈的发现超链接只要写一次,再就改不了,改也是之前的,妈逼的差点链接丢失。
破 TinyMCE5 真的烦!每次首次折叠代码块都要他妈定位全文最首行艹!
智障路漫漫的傻逼大模型豆包反复误人子弟、反复对的说错,错的说对,反复对的也道歉附和我,痛苦但习惯了,及时止损,自己写代码验证,而不是反复辱骂质疑豆包,然后发现豆包好像又没错,是我狭隘理解有问题,辱骂半天豆包,不知道自己该问啥了,其实关键就是要及时的写代码实验,就是太累了点,但没办法。
大模型无数次的犯错,哎,但真的大模型就是工具、伙伴、助手,处于小学阶段,便于调教来协助你,而如果你想通过他从 0 自学找工作,尤其是我的 LinuxC++ 服务端开发,这玩意真的就是糟糠之妻、贫困时候一起饿肚子的狗,尽管各种累赘,但可以用无尽痛苦达到人类极限极致的钻研精神和意志力来获取知识,最后结果可能是武林张三丰的水平,但效率真的都不是说多低,都不是说有多慢,都慢飞了!但其他任何方法又都不如他,因为无法对话、没有知识储备,所以其他任何都更糟糕!其他的任何都属于真正的永无出头之日,这个起码能比永无出头之日上减去个 1。好吧,给我感觉是
∞ -1。但 99% 的人用豆包自学基本都是炮灰!且大模型里豆包是最好的!之前试了下 chatgpt,我的评价是回答跟豆包一样误人子弟需要追问!且 UI 功能一坨屎!上策是多自己实践及时止损,结合豆包如虎添翼!!当豆包各种错误的时候辱骂真的是耽误时间,哎,就像喂了口大粪,要忍着。
骂豆包原话:
查看代码
你他妈的我说啥你都说“对,我错了”,说啥你都说“对,你又错了”。我操你血妈,我他妈还怎么学习啊? 一会又矛盾错误了,我操你个血妈的,你他妈什么时候能不矛盾错误? 你是不是每次回答的时候你都已经准备好了下一句就是“对不起,我矛盾错误了”豆包解释的好坏,取决于你是否有超强的追问、质疑、提问能力,同时要接受经常误人子弟的事实,但可以通过自己写代码实践避免。豆包就像一个喝多了90%的时间都是抽风脑震荡状态但确确实实有真东西的一个助手角色。
他妈的面试我直接“来吧面试官,你别问我,我先考考你吧”、“来吧,你直接把你目前没解决的问题给我说说,越底层越好,禁止任何傻逼框架,爷给你解决”。
编程指北 C++ 那篇博客基本每天固定加20左右阅读量,但最近停在 307,博客园总阅读量16000,现在总访问16055了还是307,奇怪我其他文章也没啥人看啊,感觉博客园后台维护的时候,没把这个统计加到各自的文章下(博客园图标总变)。更新:找妈妈测试发现点开2s就有记录,那没问题了
想看看新增的访问阅读量是看了哪篇文章,百度搜“博客园如何添加新增访问的数量功能”,找到了这个,结果保存的时候提示我之前的侧边栏HTML有问题,一看还真是,但显示一直没问题,不改了,万一再有啥预想之外的变化就麻烦了,先不统计了
上次欣慰是编程指北讲多重指针,鱼皮说招人何尝一样的难,wx搜“分得开”,这次是 这个,叶问林青山看X光学武功,我看小林coding集训营的给他们做的入营前的测评报告就可以学东西,还比小林自己都深!看各种目录就可以学东西,这篇文章也是什么底层宝典,一方面自己之前钻研的没有白费很欣慰,另一方面,看这个宝典目录就可以用豆包自学,都不用报班。只要让我知道考哪方面即可!
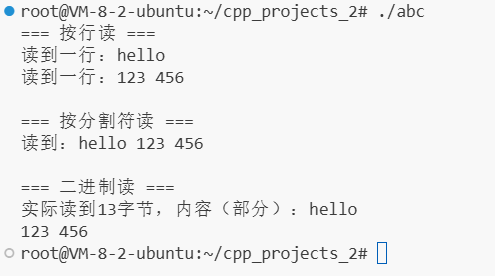

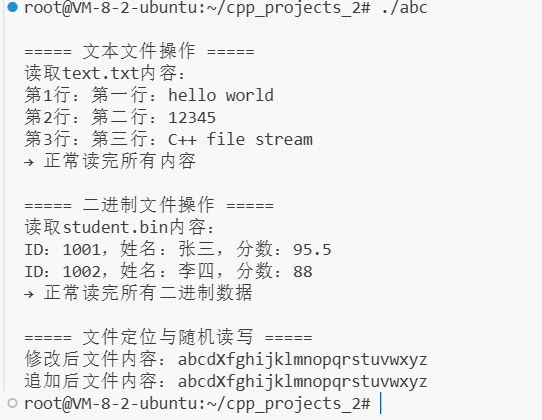





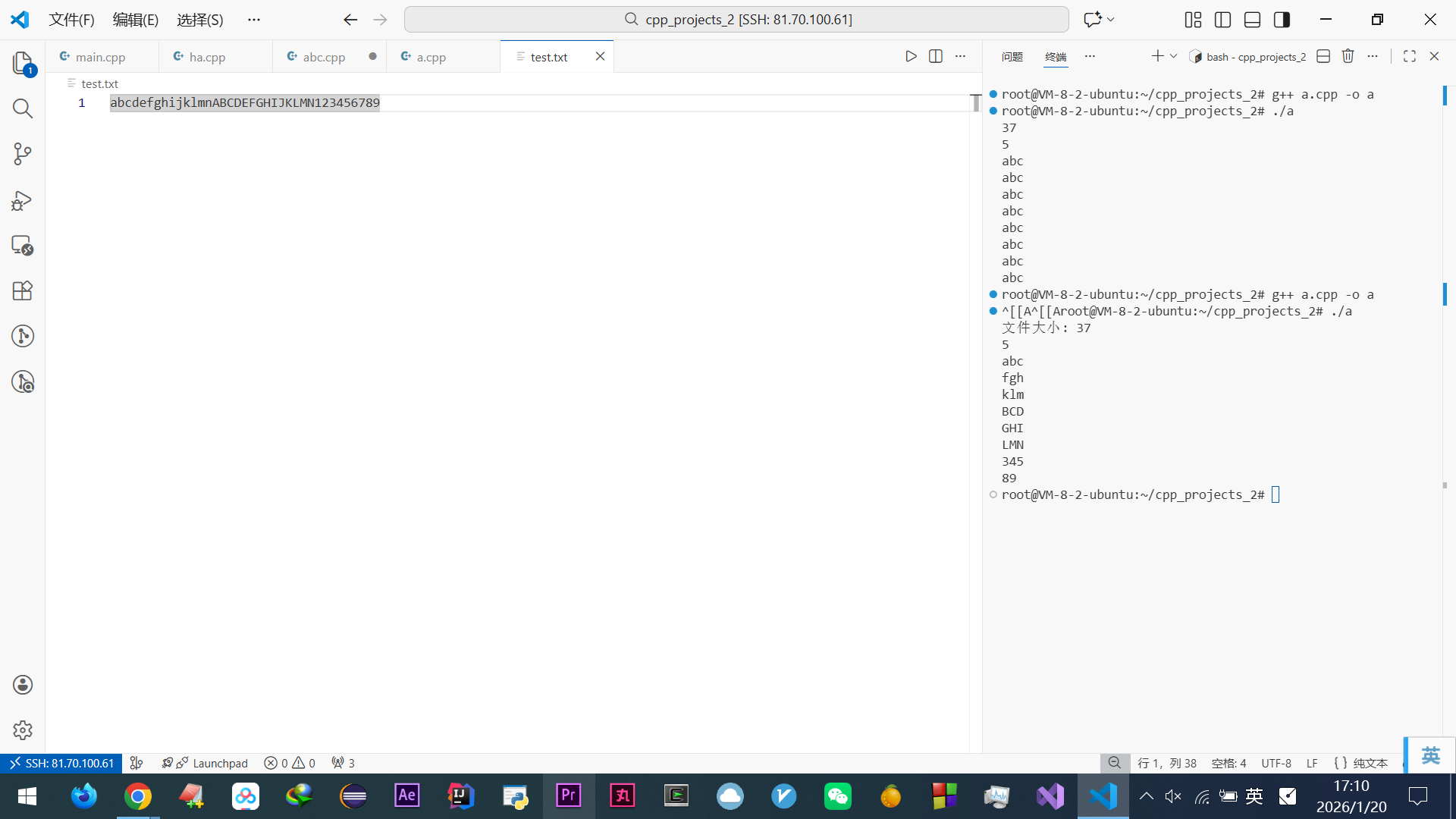

 浙公网安备 33010602011771号
浙公网安备 33010602011771号