
C++:结构体、vector、队列、链表、哈希表、映射map、简述回顾O(logn)复杂度、哈希表和桶排序里的“桶”、set
好奇怪不知道为啥唯独这个标题有目录
C++ 结构体(struct)
基础知识:
1、数据项:
指的是数组或结构体中存储的具体数据,在数组里是相同类型的单个数据,在结构体里则是不同类型的单个数据,它们是构成数组和结构体这些数据集合的基本元素。
2、结构体(structure),用于定义结构体,它告诉编译器后面要定义的是一个自定义类型。
3、
-
访问权限:与 class 类似,你可以在 struct 中使用 public、private 和 protected 来定义成员的访问权限。在 struct 中,默认所有成员都是 public,而 class 中默认是 private。
4、
关于: ->和 .,这节讲了
之前博客里搜“到这想到了几个问题”提前问了豆包
5、关于typedef上面的两段内容:
—— 指向结构体的指针
—— 结构体作为函数参数
简化两个代码,进行理解
#include <iostream>
#include <string>
using namespace std;
struct Books{
string title;
int book_id;
// Books(string t, int id)
// : title(t), book_id(id) {}
};
void printBookInfo(const Books& book) {
cout << "书籍标题: " << book.title << endl;
cout << "书籍 ID: " << book.book_id << endl;
}
int main(){
Books Book1;//("C++ 教程",12345);
Book1.title="C++ 教程";
printBookInfo(Book1);
}
/*以上指向结构体的指针
以下结构体作为函数参数*/
//#include <iostream>
//#include <cstring>
//using namespace std;
//void printBook( struct Books book );
//struct Books{
// char title[50];
// int book_id;
//};
//int main(){
// Books Book1;
// strcpy( Book1.title, "C++ 教程");
// Book1.book_id = 12345;
// printBook( Book1 );
//}
//void printBook( struct Books book ){
// cout << "书标题 : " << book.title <<endl;
// cout << "书 ID : " << book.book_id <<endl;
//}①
- 如果函数参数使用了 const 修饰,在函数内尝试更改传入对象会导致编译报错,因为 const 表明该对象在函数内不可修改。
- 不写 const 时,函数内部可以对传入的对象进行修改,因为没有了只读限制。
②
Books& book这种写法是引用传递,引用作为对象的别名,在函数调用时直接使用对象名传入即可,引用传递避免了对象的复制,提高效率。
具体解释:
对引用传递里的形参操作,就是对传递进来的实参操作
上述代码的指向结构体的指针部分,即上部分的那段代码,如果printBookInfo不是const,则可以book.title = "新的书名";改变传入对象Book1.title的值
好处:
void printBook( struct Books book )这种就叫值传递(struct可以省略),复制了对象。且在这个函数里对book的修改不会影响main函数中的Book1Books& book表示book是Books类型对象的引用,对book的操作实际上就是对传入的Books对象本身进行操作。
③
Books(string t, int id) : title(t), book_id(id) {}是Books结构体的构造函数,用于创建Books对象时初始化成员变量,使用成员初始化列表的方式对title和book_id成员变量进行初始化。(string t, int id)是参数列表,冒号后title(t), book_id(id)是成员初始化列表,将传入参数t和id分别赋给title和book_id。
构造函数:
对于这里的构造函数,可以不写
但如果写了构造函数,即为有参构造函数,那创建Book1时候用无参形式Books Book1;会出错,要这样Books Book1("C++ 教程",12345);,Books Book1 后括号内可以直接写初始化值来调用构造函数初始化对象。因为有参构造函数会让默认构造函数(即无参构造函数)不再自动生成,若无额外提供无参构造函数,使用 Books Book1; 会编译报错,也就无法先默认构造对象再进行成员赋值初始化
结构体里有构造函数时候,下面主函数main里创建的时候,必须有初始化。而没构造函数的时候,初步初始化都行。更严谨的说法:
在 C++ 里,结构体有构造函数时,若构造函数无默认参数则创建对象时必须按构造函数要求初始化,若有默认参数可不显式初始化;结构体无构造函数时,可进行默认初始化(如默认构造,成员有默认值等)、值初始化(如用 {} 语法)等初步初始化方式,但不是仅局限于初步初始化,也可按需后续赋值等操作。
对于结构体:
struct 在 C 和 C++ 里都叫结构体,在创建该类型时,C 里称该类型的结构体变量,C++ 里一般叫对象或者实例。
④
- 与之前代码的区别在于此代码使用字符数组存储标题,并且
printBook函数采用值传递,会复制一份对象副本进行操作,而之前代码使用std::string和引用传递,引用传递直接操作原对象,避免了复制开销。
之前也遇到过忘记了,更加理解构造函数。
—————————————————————— C++ vector 容器 ———————————————————————
C++ vector 容器(之前刷题的时候被不得已总用这玩意,没深究过)
for (int element : myVector) {
std::cout << element << " ";
}element要素是随便起的变量名。
myVector.erase(myVector.begin() + 2); // 删除第三个元素
———————————————————— C++ 数据结构 —————————————————————————
C++ 数据结构
关于
struct Person {
string name;
int age;
};
Person p = {"Alice", 25};
cout << p.name << endl; // 输出 Alice这里出现了跟之前不同的初始化
首先明白,这属于聚合初始化,Person是聚合类型,Person p = {"Alice", 25};通过花括号列表按成员声明顺序依次给name和age赋值,是一种简洁的初始化结构体对象方式,不同于显式构造函数初始化。
聚合类型是结构体的一种,如果用户没自定义构造函数,无私有或受保护非静态数据成员、无基类、无虚函数这些条件的结构体就是聚合类型,
而若结构体里有构造函数Person(string n, int a) : name(n), age(a) {},则不是聚合类型,就要用Person p("Alice", 25);;
若有默认构造函数Person() = default;,可Person p;后再逐个成员赋值;
若有带默认参数构造函数Person(string n = "Bob", int a = 20) : name(n), age(a) {},可按需传参如Person p1; 意思是你没有提供任何实参,那么编译器会使用这些默认值来初始化对象 p1。所以 p1 的 name 成员会被初始化为 "Bob",age 成员会被初始化为 20。这就相当于调用了 Person p1("Bob", 20);。
类class和struct结构体一样,只不过更强大,支持继承、封装、多态等特性
妈逼的这教程这牛逼,要不是我之前刷过算法题懂一些,真看不懂,讲的太跳跃了,也没啥思维连贯性,都要自己脑海里整理,不过对我来说是最好的了,我只需要指路人
关于单向链表
struct Node {
int data;
Node* next;
};
Node* head = nullptr;
Node* newNode = new Node{10, nullptr};
head = newNode; // 插入新节点这段代码定义了一个名为
Node的结构体,包含一个整数成员data和一个指向下一个Node类型对象的指针next,接着声明了一个指向Node的指针head并初始化为nullptr表示链表为空,然后使用new运算符动态分配一个Node对象,将其data成员初始化为 10,next指针初始化为nullptr,并让指针newNode指向该对象,最后将head指向newNode,也就是把新创建的节点作为链表的头节点,完成了新节点的插入操作,此时链表中有一个节点,其数据为 10。
真正的算法题,都是最朴素的招式,我刷邝斌专题都没用过指针,双端队列更是没用过
然后打codeforce的GoodBye2024就他妈给我干的心灰意冷,全是数学和DP,仿佛邝斌都是模板题
╮(╯▽╰)╭~~~~(>_<)~~~~╮(╯▽╰)╭
双端队列
deque<int> dq;
dq.push_back(1);
dq.push_front(2);
cout << dq.front(); // 输出 2
dq.pop_front();在双端队列
deque里,front指的是队列的头部,也就是最前面的位置。dq.push_front(2)是在头部插入元素 2,dq.front()用于获取头部元素(这里就是 2),dq.pop_front()是删除头部元素;与之对应的另一端是尾部,dq.push_back(1)是在尾部插入元素 1 ,可使用dq.back()获取尾部元素,用dq.pop_back()删除尾部元素。
哈希表
英文名叫:Hash Table
C++里用的时候是:unordered_map
映射
这玩意就是我之前刷题的时候用的map
放在一起说,以下都是现问的豆包,现学的热乎的
刷题跟学这些玩意完全是两种感觉,刷题的时候不想深入研究vector和map这些,甚至咋都不能熟练用,而现在学这些的时候,不想去回忆算法
哈希表和映射知识点:
举个例子:
#include <iostream>
#include <map>
#include <string>
#include<unordered_map>
using namespace std;
int main() {
std::unordered_map <std::string, int> myMap;
myMap["gb"] = 1;
myMap["fd"] = 2;
myMap["ab"] = 3;
for (const auto& pairr : myMap)
std::cout << "Key: " << pairr.first << ", Value: " << pairr.second << std::endl;
cout<<"\n\n"<<endl;
std::map<std::string, int> myMap1;
myMap1["bb"] = 1;
myMap1["cd"] = 2;
myMap1["ab"] = 3;
for (const auto& pair : myMap1)
std::cout << "Key: " << pair.first << ", Value: " << pair.second << std::endl;
}输出
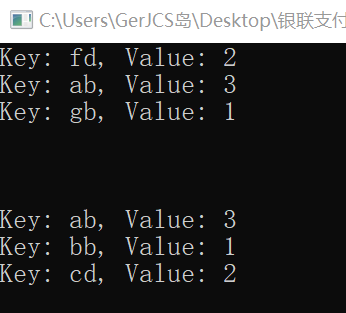
这段代码上部分是哈希表,下部分是map,即映射
map的输出是按照键的顺序(当键是像 int、double、char 这类基本数据类型时,std::map 会按照数值大小或者字符的 ASCII 码值进行排序。对于自定义的类可以重载比较符,来定义用类里的哪个成员变量为参照做排序比较,这里记得刷带权最短路还是啥用过,那个重载weight的)
这里pairr是自己随便定义的变量名,为了区别于std::pair
注意用哈希表unordered_map需要用std且引入头文件<unoredered_map>
之前博客提过,搜“不能直接用”
关于 O(1) 和 O(logn) ,参考博客

O(1):
O(logn):
O(logn)表示对数时间复杂度。这里的对数通常是以 2 为底,但在大 O 表示法中,对数的底数不影响复杂度的量级。当输入规模
n增加时,算法的执行时间会随着n的对数增长。常见的具有 O(logn) 时间复杂度的算法有二分查找,它每次将搜索范围缩小一半。

set集合
set仅存储单一元素,元素本身就是键且唯一,map存储键值对,通过键来关联值,查找时set关注元素存在性,map更侧重通过键获取对应的值。
###:
未曾清贫难成人,不经磨砺永天真
一群滥用的傻逼玩意,难怪总崩溃妈逼的
呵呵曾经的我


组长,你们都成家了我留下来吧,呵呵,刚到新疆,一个人硬刚公司仨区域老大,房子耗子房东耍无赖,12345民警社区,警察110住建部,都tm一群傻逼废物,呵呵,曾经无比稚嫩,如今才工作一年,有了别人10年的经历阅历,有了引以为傲的阅历,可是又怎样呢?
阿波罗github灌水,香烟瓜子火腿肠,矿泉水,来来来腿收一收
钻研精神
开悟人性
各种
我却为何一直起不来
那几年因为bb得B照顾AI_Zheng,
我那几年走错了
真的永远无法翻身吗,看着这群傻逼玩意小丑一样,开悟了又如何,钻研精神又如何,思考的深又如何,呵呵
一无是处穷途末路,傻逼废物垃圾废人
也无法变现
没钱我不可能向父母要
虽然要就会给,但我要自己想办法
家不回?不,爸爸期望我
必须回去
车自己想办法
其他自己想办法
乌鲁木齐到哈尔滨硬座78h443元,
那个百色性侵的女生,社会就是这样的,没办法,这个男老师最后一点儿惩罚都不会有。这个社会就是这样,你tm就应该就拉他一起去自杀,应该是先弄死他。哪有鸡巴毛善恶对错,操,站在那些统治者的立场就是不要给我惹事情,平息再平息,死个人算什么呀,底层人垃圾的命又不值钱,最好的办法就是底层人的命不值钱,把这件事压下去,这些垃圾人的命不值钱,翻不起什么花浪,压下去又能怎么样呢?呵呵,我看得太透彻了这些
我就是这个底层人,可我也想活着,挣扎着从这个烂泥堆里爬出去
乌鲁木齐硬座回哈尔滨过年,回程的时候,发现好几小时的硬座很满足,只要没百根抽烟臭烟味呛死人,哪怕继续羽绒服车捂头满头大汗,烤炉,强光睡觉伸不开腿,埋汰的车上环境,人也很遭烂,我都可以忍受,甚至觉得很满足,车厢不让吸烟?呵呵哪有什么法制和法律
列车员反应“他说没办法,都不关门”,麻痹的给我耍老油条,我“大哥你说我打12306给你举报一下子你是不是也挺难受?我作为乘客没权利说容易起冲突,你作为列车员吆喝两句起码也算是做了,大家也能注意点,也不是啥大事,”呵呵训的我肺疼,睡觉被呛醒,这群打工的农民工都闻不到了。车上就像一个上世纪美国那个押运黑奴一样,很满足的是,不用铁丝给你穿起来
曾经的我呵呵,做任何事都有闭环,负责,相当靠谱,最后换来了什么,职场、寝室满地吐痰凌晨6点睡觉的汽车厂维族人室友外放大声睡觉,也磨练了我的意志力、屋子里有耗子,被房东坑,硬刚那些部门呵呵有屁用,我组织带团骑行圈呵呵咋样了
痛恨曾经那么善良真诚的我自己,现在看到任何人,都最先想到可以利用的工具,看到犹如曾经的我一样的人最先想到怎么拿捏他,呵呵回不去了
底层垃圾堆里这样太吃亏太吃亏了
过年乌鲁木齐回哈尔滨443硬座,挨饿忍着一切,也要花小一千,给家人买东西,让他们知道我过的很好,我相信自己有翻身之日,公务员体制内?呵呵无非是底层的垃圾变成了国家的走狗而已无知的废物?没有背景干个屁,哪有公平正义,只有绝对的实力才可以摆平一切
清晰的知道社会的运转逻辑,规则。呵呵
好多去年一起玩,滑雪的、骑行的、各种北京土著女生,私聊单独找我玩,赚的多的女生,呵呵不再去回复他们,一年,经历了这么多,而他们还是之前那样玩呢,呵呵,今天还有个女生主动找我要单独和我出去玩,呵呵懒得理会这群人,清晰的知道自己想要什么。路上图书馆各种地方不会因为有女生因为我长得帅总看我而内心心境有任何的波动,清晰的沉淀自己知道自己想要什么、
我想着怎么才可以有投资头脑经商头脑,逢年过节赚这些傻逼韭菜的钱,曾经会因为好几个北京土著女生或许因为我真诚,性格好,长得帅,摄影好,喜欢运动骑行,总约我玩,
会因为很久不联系总有北京土著主动打视频找我玩,
会因为有这些北京女生做朋友哦主动约我而有强烈的虚荣心,炫耀,如今不会了,不会再因为有XX怎样的朋友,而有任何觉得自豪的幼稚想法,独自面对一个人抗,成长磨砺,在外闯荡遇到事处理事说话的气场气质磁场节奏呵呵那些人一辈子不会有跟12345说“我Xx如果你们”
也学会了虚与委蛇,不会再正义的刺头,而是遇到相当大的纠纷争论矛盾最先微笑,心里想着万般手段有机会下死手绝不手软



 浙公网安备 33010602011771号
浙公网安备 33010602011771号