
C++:菜鸟教程-AI工具、乱码问题、数据类型、定义和声明、进制、跨行等杂七杂八术语
安装AI工编程助手FItten Code,发现真牛逼啊,尤其那个注释生成代码,感觉我之前刷题就像在农耕时代,这样人不会变傻吗?用多了人容易傻掉
进而试了下感觉太崩溃了,世界观崩了,我把Oulipo的题目描述发给他,直接给我一个代码,提交后居然真的AC了,而且响应速度超级超级巨快啊,这也太逆天了吧。
以后面试不直接太多人作弊了吗?什么各种leetcode周赛,这太容易骗分骗名次了吧。
把昨天的codeforces A题复制发个他,真tm给了个一个代码,响应速度也太快了吧,1ms级别感觉是,而且还有讲解。
这也太容易搅乱刷题算法竞赛圈了啊。
这JB还用啥程序员啊
Q:VS和Vs Code区别
A:Vs是一个功能非常全面的开发工具集,提供强大的调试功能、集成数据库管理工具、支持UML建模等等。这些功能对于大型项目、企业级开发来说,可是非常有用的。
而VS Code是轻量级的源代码编辑器,虽然也能通过插件扩展一些功能,但在一些方面还是比不上VS的。如:VS Code的调试功能可能就不如VS那么强大,特别是在处理复杂项目和多线程调试的时候。
总的来说:
如果你正在开发大型、复杂的企业级项目,Visual Studio会是一个更好的选择;
如果你是一个个人开发者,或者正在进行小型项目的开发,追求开发效率和轻量体验,那么Visual Studio Code会是一个更理想的选择。
Question:
类和结构体有啥区别
百度技术大牛的GPT回答Answer:
访问权限:
- 类(class)的成员默认是private(私有的),这意味着它们只能在类内部被访问。
- 结构体(struct)的成员默认是public(公开的),这意味着它们可以在任何地方被访问。
你可以把类想象成一个“高级盒子”,这个盒子里的东西(成员)默认是藏起来的,别人看不到也摸不着(private)。如果你想让别人看到或摸到盒子里的某个东西,你得明确地说出来(把成员声明为public)。
而结构体呢,就像是一个“透明盒子”。盒子里的东西默认是大家都能看到的(public)。如果你想藏起某个东西,你得特意去声明(把成员声明为private)。
再来说说继承。如果一个“高级盒子”里又放了一个“高级盒子”(类继承类),那么里面的东西默认还是藏起来的,除非你特别说明。但如果是“透明盒子”里放了一个“盒子”(不管是高级的还是透明的,结构体继承结构体或类),那么里面的东西默认还是大家都能看到的。
至于用途嘛,类通常表示有复杂行为和属性的东西,比如人、动物之类的。
而结构体则更常用于表示一些简单的数据结构,比如点、线、面之类的,但这只是我们的一种习惯用法,并不是C++语言强制规定的。
Q:有点别扭,为什么1里放2,是1继承2,不是2继承1呢
A:
想象一下,你有一个工具箱(父类),里面放满了各种工具(成员)。现在,你想打造一个新的工具箱(子类),但这个新工具箱不想从零开始,而是想基于现有的工具箱进行扩展和定制。于是,你把旧工具箱里的工具都拿出来,放到新工具箱里,然后再添加一些新的工具或改进一些现有的工具。
在这个过程中,新工具箱(子类)继承了旧工具箱(父类)的所有工具(成员),并且还可以添加或改进这些工具。但反过来想,旧工具箱(父类)可不会去继承新工具箱(子类)里的任何东西,因为新工具箱是在旧工具箱的基础上创建的,而不是相反。
所以,回到你的问题上,“高级盒子1里放了一个高级盒子2”被解释为高级盒子1(子类)继承了高级盒子2(父类)的特性和行为,是因为子类是在父类的基础上进行扩展和定制的。子类可以获取父类的所有public和protected成员,并可以添加或重写这些成员来实现自己的特定行为。
Q:类和结构体访问权限不同有什么必要性吗?就用结构体不行吗
A:暂时理解不了,学多态的时候再看看


1 这个问题问得好!在C++中,类和结构体访问权限的不同设计确实有其必要性,这主要体现在封装、隐藏内部实现和保护数据等方面。 2 3 首先,封装是面向对象编程的一个核心概念。它允许我们将数据和操作数据的函数组合在一起,形成一个独立的实体。通过封装,我们可以隐藏对象的内部实现细节,只暴露必要的接口给外部使用。这样不仅可以提高代码的安全性,还可以减少外部代码对内部实现的依赖,从而降低维护成本。 4 5 在C++中,类提供了很好的封装机制。类的成员默认是私有的(private),这意味着它们只能在类内部被访问。如果你想让外部代码访问某个成员,你需要显式地将其声明为公有的(public)。这种设计有助于我们更好地控制对数据的访问,从而保护数据的完整性和安全性。 6 7 相比之下,结构体的成员默认是公有的(public)。虽然结构体也可以用于封装数据和函数,但由于其成员默认是公开的,因此它提供的封装性相对较弱。这可能会导致外部代码能够直接访问和修改结构体的内部状态,从而破坏数据的完整性和安全性。 8 9 当然,你可能会说:“那我用结构体的时候,都显式地把成员声明为私有的不就行了?”确实,这样做可以在一定程度上模拟类的行为。但是,结构体缺乏类所提供的一些更高级的功能和灵活性。特别是当涉及到继承和多态时,类的优势就更加明显了。 10 11 继承允许我们基于现有的类创建新的类,并继承其属性和方法。通过继承,我们可以实现代码的重用和扩展。而多态则允许我们使用统一的接口来调用不同实现的方法。这有助于我们编写更加灵活和可扩展的代码。 12 13 综上所述,虽然结构体在某些情况下可以替代类使用,但类提供了更高级的功能和灵活性。特别是当涉及到封装、继承和多态时,类通常是更好的选择。
注释:
Q:
中文乱码:
纯纯死妈玩意,
真难受,一个乱码,全网都找不到对的,一下午就搞这个问题了
一直没解决,VS里ctrl+f5没问题,cygwin里就乱码,且是输出cpp文件就乱码,本身诸如ls -la的中文就正常
打算看看windows的cmd里输出是啥情况,结果也是乱码,证明不是cygwin的问题
又用codeblock新建了个cpp,fn+f9可以正常输出中文,cmd和cygwin里也正常。
检查cmd和codeblocks的编码格式都是windows936,即GBK
936代表简体中文GBK编码,65001代表UTF-8编码,
在简体中文环境下使用936编码时,命令提示符可以正确显示中文字符;
而在UTF-8编码下,无论是显示还是输入中文字符都可以正常进行。
此外,执行一些文件操作时,如文件名含有中文字符,若使用936编码有可能会出现乱码现象,而使用UTF-8编码则几乎不会出现该问题。
但是对于codeblock的cpp文件,cygwin里设置成UTF-8没问题,GBK就乱码。
VS2022查看编码格式:
VS2022没有“高级保护”,改成了“另存为”,右下角保存里可以看编码格式
尝试很多都不行,用户home下:C:\cygwin64\home\GerJCS岛下的.bash、.bashrc、,inputrc,都翻来覆去改了个遍,看说windows可能不认zh_CN.UTF-8的这种写法,加不加双引号,大写小写,试了十几遍
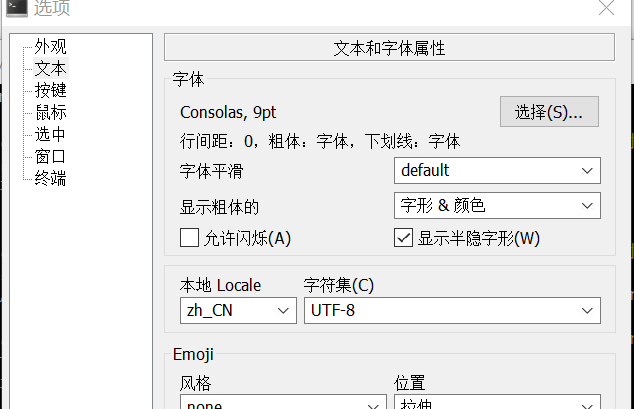
cygwin的右键option也更改了文本下的字体和本地Locale字符集,各种组合又试了十几遍都不行,VS的AI又说按照sudo命令包,尝试安装也没整懂感觉走入误区了,又去倒腾说代码改成这样
1 #include <iostream> 2 #include <locale> 3 using namespace std; 4 5 int main() { 6 // 设置本地化环境为简体中文 7 locale loc("chs"); 8 cout.imbue(loc); 9 10 cout << "第三方" << endl; 11 return 0; 12 }
但ctrl+f5可以,可是cygwin里exe文件报错,无语崩溃死
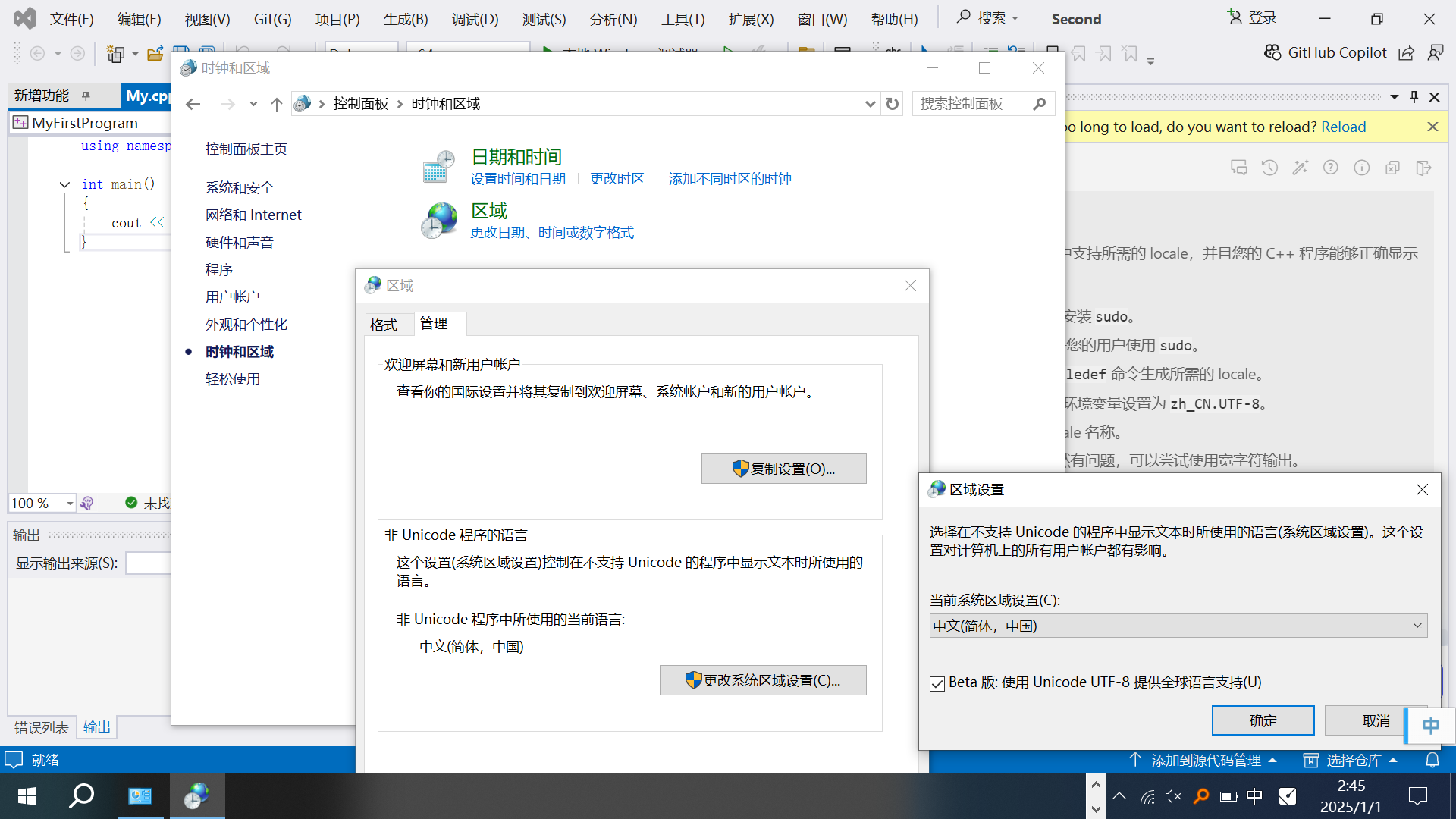
VS的AI又说试试更改时区:
控制面板选择类别,进入时钟区域,管理,把那个beta勾上重启就好了,
cygwin是
但codeblock的fn+f9又不行了,过了一会又莫名其妙的好了。
但cmd和cygwin执行都不行
VS自己ctrl+f5也乱码
然后自己改乱了,由于没-o指定,所以改完总是去执行./main,但其实应该是./a
最后codeblock也好了,setting里的Editor,第一个,Encoding setting选择utf-8
发现codeblock无论怎么改,只会影响自己fn+f9的是否乱码,而cmd和cygwin里始终是对的,而且codeblock里改成错的即时生效,但改成正确的需要重启生效,但codeblock的控制台的目录又乱码了。真玄学,把时区改回去吧,codeblock好了。cmd和cygwin也都可以。
VS里Ctrl+f5第一次不行,我修改几个其他汉字又行了,难道没变化是不编译吗??好诡异啊这软件
现在又回到了最开始的问题,cygwin和cmd乱码,VS里面ctrl+f5正常
最后吃饭的时候无奈刷了下手机用Chrome查了下,第一个文章就解决了我的问题,搜索完整关键词是“cygwin执行g++VS里cpp文件输出中文乱码”
直接
g++ -finput-charset=UTF-8 -fexec-charset=GBK your_program.cpp -o your_program.exe
因为windows是GBK,而VS是UTF-8。
完美解决。
最后总结下:
win10系统
cmd编码格式:属性石936GBK,其实也没法改
cygwin编码格式啥都行,我是zh_CN utf-8 consolas
codeblock的setting的Editor,Encoding setting是WINDOWS 936(只能管自己IDE里面的事),fn+f9正常。cmd运行exe文件正常。cygwin运行exe正常
VS编码格式默认UTF-8 65001(只能管自己IDE里的),ctrl+f5正常,cmd执行用上面的语句正常,cygwin里用上面的语句执行正常
注意:搞过的再输入直接就是正常的,如果其他cpp每次都需要这句话:g++ -finput-charset=UTF-8 -fexec-charset=GBK your_program.cpp -o your_program.exe,并不是默认永远都是UTF-8读取,GBK输出了
在测试发现:只需要-fexec-charset=GBK 也可以。但如果将cygwin里改成字符集是GBK就不行不许fexec弄
原理:
-
编译时选项 vs 运行时终端设置:
-fexec-charset=GBK:这是编译器选项,影响编译器如何在生成的目标文件中存储字符串字面量的编码格式。- 命令提示符设置:这是运行时终端的设置,影响命令提示符如何处理和显示程序的输出字符。
-
具体区别:
-fexec-charset=GBK:- 编译阶段:编译器将 UTF-8 编码的字符串转换为 GBK 编码,存储在目标文件中。
- 运行阶段:程序输出 GBK 编码的字符串,需要 GBK 编码的终端来正确显示。
- 命令提示符设置:
- 终端阶段:命令提示符以 GBK 编码显示程序的输出字符。
- 输入阶段:命令提示符以 GBK 编码处理输入的字符。
我的理解:-fexec-charset=GBK 是生成目标文件的编码,一般读不会出错,都是utf-8,就是生成目标文件的时候会弄错,所以需要GBK说明一下,比如utf-8方式读取的888对应GBK编码就是999,那目标文件如果按照utf-8来搞,最后就会弄错,按照GBK来搞就没事。
而cmd或者cygwin里设置的显示字符集的编码格式感觉也没啥用,只是显示问题,但显示好像都兼容,目标文件才是关键。不打算研究太深,强行解释的通自圆其说就这么滴吧。
标识符就是变量名
enum WeekDay {//WeekDay是枚举名 Monday,//枚举成员 Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday }; WeekDay today = Monday;//声明WeekDay类型的变量,today是存储枚举类型值的变量
today就是一个枚举变量,它的类型是WeekDay,存储的值是Monday。
开始用豆包:
ASC:
7位编码,2^7=128种不同的状态,足够用来编码所有的英文字母(大写和小写)、数字(0 - 9)、标点符号和一些常用的控制字符。
Unicode 字符集:
最熟知的就是UTF-8,最早期电脑只有英文拉丁文的字符,即ASC,后来有支持中文字符的GB2313,支持日文的某编码但都互不兼容,于是有了Unicode,代表就是UTF-8
宽字符:
变量多次被声明,但不可以多次被定义:
在单个文件内多次声明变量, 源文件example.cpp,其中定义了一个全局变量int global_variable;(这是定义)。
而如果
int a; int a;
就不行,这个叫做变量多次被定义
变量声明的主要目的是告诉编译器变量的类型和名称,但不分配内存空间。
总结:
int a; 这叫变量的定义,分配内存,只能一次
int a = 10; 这叫变量的定义+初始化,分配内存
extern int global_variable; 这叫变量的声明,不分配内存,可以多次
关于函数的声明和定义:
函数头
函数体
把变量作用域里的
#include <iostream> class MyClass { public: static int class_var; // 类作用域变量 }; int MyClass::class_var = 30; int main() { std::cout << "类变量: " << MyClass::class_var << std::endl; return 0; }
发给豆包解释,
有点理解类和结构体区别了,结构体其实比较单一,类可以有封装有选择性的访问,且结构体没有继承并做修改的这种功能
访问结构体的成员变量:结构体名.成员变量
访问类的 :类名::成员变量
但对于protect不太懂,知道public和private了,多态也不太懂,继承也有点懵
这样学的好处就是没开始讲我就通过AI解读代码,提前了解到了很多还没讲的东西,但追问之后还是不懂,先了解下随着时间推移,真正看菜鸟教程那对应继承讲解的时候做铺垫
0xFee:14*16^0+14*16^1+15*16^2(不区分大小写)
0b二进制
0八进制
没前缀十进制
0x十六
u无法符号,l长整型
浮点常量:(感觉菜鸟教程写的一坨屎,仿佛是屁股写的)
由 整数+小数点+小数+指数 组成
怎么表示?
小数表示,
即小数部分+整数部分:
3.14159
指数表示:
即小数点+指数
314159E-5L,输出3.14159
其中e或E表示乘以十的多少次方,
cout<<"\a"<<endl;
这个太有趣了哈哈
cout<<"#\ #"<<endl; 会警告,想表示一个普通的空格,直接敲一个空格就可以了,而不是使用转义序列形式
空格的 ASCII 码是 32,八进制表示就是 \040
豆包说:反斜杠后应该加符合转义字符规则的字符,单独一个反斜杠后面接回车不符合语法要求
但实际测试可以
代码 cout<<"#\\ #"<<endl; 输出 #\ #
关于跨行:
错误的跨行:str、str1、str2都是错的
#include <iostream> using namespace std; int main() { string str = "This is a long string that should be written in multiple lines"; // 这种写法错误,换行后没有正确续接字符串 string str1 = "A "; string str2 = "A "; cout << str << endl; cout << str1 << endl; cout << str2 << endl; return 0; }
正确的跨行,输出ABC,注意这段代码里可能包涵shift+空格的全角空格,所以会报错\241,删掉重新敲回车即可,详情见下面的惊天细节
#include <iostream> using namespace std; int main() { string str = "A" "B"
"C"; // 这样每行的字符串内容会自动拼接成一个完整字符串 cout << str << endl; return 0; }
正确的跨行
string str = "This is a long string\ that should be written in multiple lines";
输出 This is a long stringthat should be written in multiple lines
正确的跨行,即续行
string s="s\
s";
输出 s s
正确的跨行
string s="s\ s";
输出ss
但注意:两个 '\' 就不行,
string str = "A\\ ";
会输出A,但会有警告 '\040' ,040是空格的八进制,像这种,要么表示续行,单独一个 '\' 后啥也别加,直接加内容
string str = "A\ 内容";
输出 “A内容”
要么想表示输出单个 '\' ,你就把回车去掉
string str = "A\\内容";
输出 “A\内容”
发现惊天细节:
我用的是掌心输入法,shift+空格,切换全角,按空格会占两个字节的宽度,或者是两个空格的宽度,导致全角状态下的空格,会报错 error: stray '\241' in program ,转义字符要么\n\t这些,要么八进制数字范围是 “\000” 到 “\377”。而241虽然在范围内,但不符合预期,
如果字符串双引号内是完整的在一行,那怎么敲回车都没影响了
正确引号的输出
cout << "He said, \"Hello!\"" << endl;
输出 He said, "Hello!"
错误的输出
string str ="s\" //错在了编译器会将第一个双引号后的反斜杠(\)和紧接着的双引号视为一个转义序列,即在 C++ 中,\"用于在字符串中表示双引号字符本身,下一行的s就没正确衔接 s"; string str ="s\" //错在下一行的第一个",就代表str输入结束的,但这后面又有个s,是错误点一。且又是"另起一行没衔接,是错误点二 "s";
正确写法
关于const
跟#define区别,豆包回答:
备注:
###:贴吧ZXP4大佬回复说,官方题解tutorial
###:关于菜鸟教程差评(逐渐读发现翻译真的差劲,之前阅读的时候还一度怀疑自己)、推荐浙大翁恺老师、郝斌老师等视频课程、优达学城
###:新发现个GPT:offer收割机 (优点:可以回答C++不相关的问题,之前技术大牛GPT不行。缺点是问完问题后如果我不理解想再继续问,没法像技术大牛文心GPT那样很好的衔接或者说记住我之前的问题)。但两个都不如FittenCode Chat(有时候也挺智障的),切换页面也可以回答,而百度的GPT必须把GPT放在最前面不能浏览其他页面,有时候手机查Chrome也会有一些意想不到的解决方案。(更新:现在VS的FittenCode Chat好慢 )
###:之前IntelliCode的设置
###:L雪T
###: 昨天贴吧有人说豆包,之前查FittenCode Chat的时候看到过,北邮贴吧提到过,昨天codeforces贴吧有人回复说豆包翻译不错,试试豆包,网页版,文心GPT受不了太恶心了,没停止按钮了。豆包速度快解答还棒
###:看视频没法自己控制,只能按部就班,而看文字到处自己摸索,前期很慢,但提高了学习能力,且后期会很快可以自己控制学习速度,跟着视频学东西就是垃圾,始终很慢且没啥搜索找资料的能力,也没啥学习能力
###:菜鸟教程就好像二手市场淘来的一个全是问题但车里有导航地图的破车,开1km就出点毛病,但由于有导航知道目的地,能带你去目的地,路上遇到的一切问题都得你自己解决
###:贴吧又有人回复我说deepl翻译不错

 浙公网安备 33010602011771号
浙公网安备 33010602011771号