Day019 集合 ArrayList和一点单链表双链表
ArrayList集合
-
默认初始化的容量是10;(底层 先创建了一个长度为0的数组,当添加第一个元素的时候,初始化的容量是10.)
-
集合底层是一个Object[]数组
-
构造方法:
new ArrayList();
new ArrayList(20);
-
ArrayList集合的扩容:
-

-
ArrayList集合的扩容:
增长到原容量的1.5倍
ArrayList集合底层是数组,优化:尽可能少扩容,因为数组扩容效率比较低,建议在使用ArrayList集合的时候预估计元素的个数,给定一个初始化的容量(这是ArrayList比较重要的优化方式)
-
数组的优点:检索效率比较高(每个元素占用空间大小相同,内存地址是连续的,知道首元素内存地址,然后知道下标,通过数学表达式计算出元素的内存地址,所以检索效率最高)
-
数组的缺点:随机增删元素效率比较低,向数组末尾添加元素,效率还是高的
另外数组无法存储大数据量(很难找到一块非常巨大的连续的内存空间)
-
面试官经常问的问题?
-
-
这么多的集合中,使用哪个集合最多
-
答:ArrayList集合,因为往数组末尾添加元素,效率不受影响。
-
另外,我们检索|查找某个元素的操作比较多
-
-
ArrayList不是线程安全的
linkedList
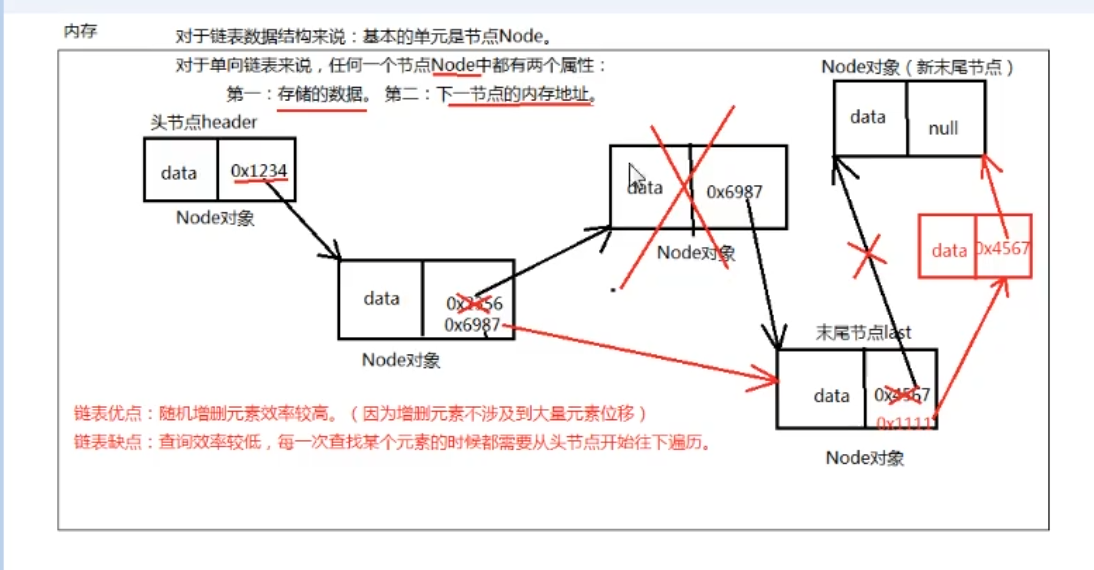
对于链表数据结构来说:基本的单元是节点,
每一个节点Node都有两个属性,一个属性是存储的数据
一个是下一节点的内存地址
-
链表优点:随机增删元素效率较高。(因为增删元素不涉及到大量的元素位移)、
所以随机增删元素的时候不会有大量元素位移,因此随机增删效率比较高,
在以后的开发中,如果遇到了随机增删集合中元素的业务比较多的时候,建议使用LinkedList
-
链表 缺点:查询效率较低,每一次查找某个元素的时候都需要从头节点开始往下遍历
不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头节点开始遍历,直到找到为止,所以ArrayList用的比LinkedList多。
![image-20210517203034065]()
LinkedList集合底层也是有下标的
注意:ArrayList之所以检索效率比较高,不单纯是因为有下标的原因,是因为底层数组发挥的作用,
LinkedList集合照样有下标,但是检索、查找某个元素的效率比较低,因为只能从头节点开始一个一个遍历
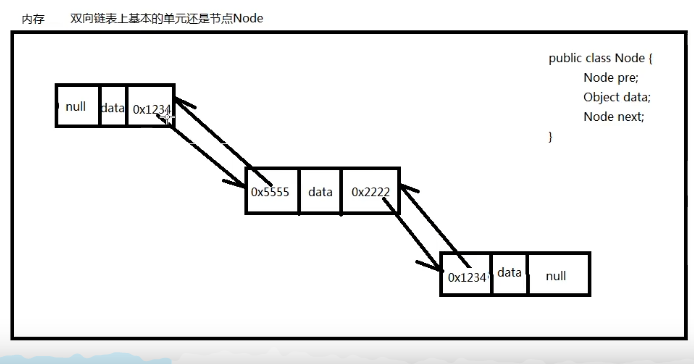
双向链表
基本单元还是节点Node
三部分:数据,上节点的内存地址,下一节点的内存地址
头尾节点是null

 浙公网安备 33010602011771号
浙公网安备 33010602011771号