(4.12)数据库列式存储 sql server列存储索引
便于理解:
https://zhuanlan.zhihu.com/p/129342230
转自:https://blog.csdn.net/NIeson2012/article/details/79551337
【0】存储形式图
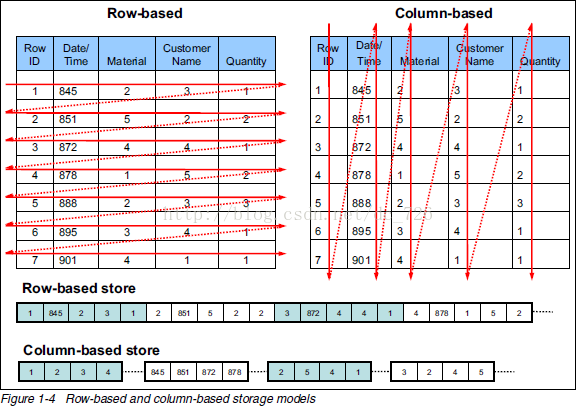
【1】传统的行存储和列存储的区别
(1)行式存储
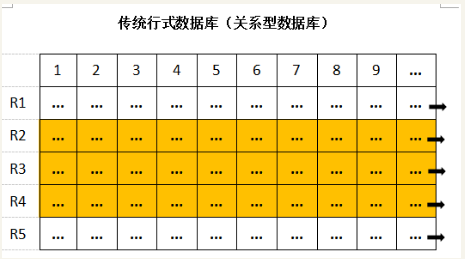
1、数据是按行存储的
2、没有索引的查询使用大量I/O
3、建立索引和物化视图需要花费大量时间和资源
4、面对查询的需求,数据库必须被大量膨胀才能满足性能需求
我们可以思考一下,这样的方式利于什么样的存储?(此处停顿 5 秒思考一下)
它利于数据一行一行的写入,写入一条数据记录时,只需要将数据追加到已有数据记录后面即可。
行模式存储适合 OLTP(Online Transaction Processing)系统。因为数据基于行存储,所以数据的写入会更快。对按记录查询数据也更简单。
所以我为什么还需要列式存储,而列式存储又是什么?
让我们想象一种场景,现在不是想查询 Bob 的博客,我想统计 Bob 发表的博客数,或是整个系统今天的博客点赞数。如果是行存储系统,数据库将怎样操作?(停顿思考 10 秒)
(2)列式存储
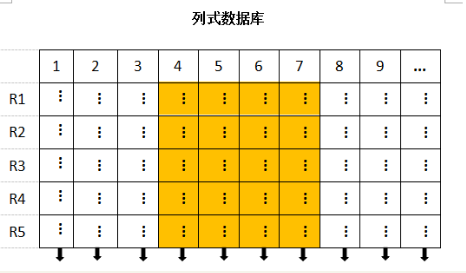
1、数据按列存储–每一列单独存放
2、数据即是索引
3、只访问查询涉及的列–大量降低系统IO
4、每一列由一个线索来处理–查询的并发处理
5、数据类型一致,数据特征相似–高效压缩
(3)案例分析 行与列存储的区别
在不考虑索引的情况下,所有的磁盘读取都是顺序读取,这意味了要查找一个东西,都需要扫描全表或者部分表。
很直观的道理,读取的性能就是取决于扫描的范围。范围越大,速度当然越慢。
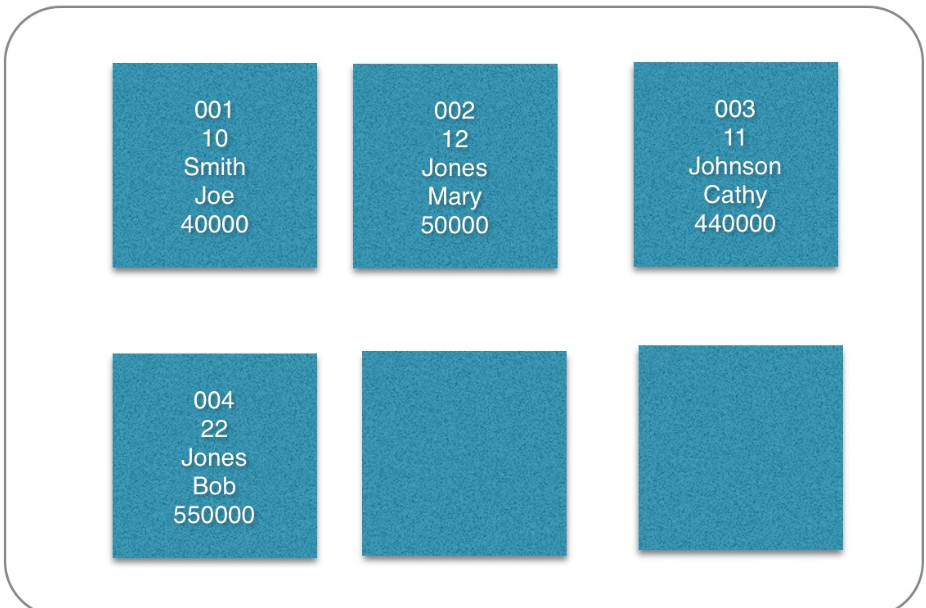
我们先假设我们有一堆如下的数据:
| RowId | EmpId | Lastname | Firstname | Salary |
|---|---|---|---|---|
| 001 | 10 | Smith | Joe | 40000 |
| 002 | 12 | Jones | Mary | 50000 |
| 003 | 11 | Johnson | Cathy | 44000 |
| 004 | 22 | Jones | Bob | 55000 |
行存储模型
好现在我们开始让磁盘里塞,假设我们的磁盘块只能容下5个字段(抽象的,假设我们的这些字段的大小都一样),因为我们是按找行优先的,所以结果就如下:
是当我们要找Jones的所有信息的工资时候,我们会依次从第一块磁盘块直到扫描到最后(为什么要扫到最后,因为是在找全部叫Jones的信息,所以不扫都最后都不能确定是否会遗漏)。
一共需要扫4块,然后取出其第二块和第四块信息,找出其工资的信息。
其实基于行式储存,对于where语句处理都需要处理全表。对于磁盘的不停seek,速度就可想而知。当然一般数据库为了应对这种全数据扫描,找到了建立索引的方法。而索引就是对某个或者某些字段的组合的信息,即取出数据的部分信息,以减少每次扫描从全表到部分信息的扫描的过渡。
这种查询方式很适合于一次取出一个行数据,而对于日常应用系统来说这种方式是非常合适的,因为我们设计应用的时候都是针对一个事务,而我们会把一个事务所有属性存储成一行,使用的时候也是有很大的概率涉及到整行的信息,很利于做缓存。还比如我们经常使用的那些经典sql 语句:
select * from user where id = 1001; select id, user_name, email, address, gender, ... from user where id = 1001;
!!还敢不敢列出些更多的字段!!
列存储模型
而列储存就是下图这种按列优先储存。为了方便我们每块只储存了一个一列,没有存满。

- 这下我们再考虑上面的查找所有Jones的工资,这下我们只扫描第三个磁盘块,找出Jones都再那些行,然后根据查出来的行号
- 直接去第五块磁盘(这块对应的式salary列)找出第二、四行的数据,然后输出。一共2次seek。大大小于row-oriented的4次。
这种查询方式的前提就是你就需要这列数据就行了,其前提假设就是查询基本不会使用这个行的其他列数据。
显然这种假设对于日常操作系统的围绕着一个主题进行的活动是不合适旳。但是却在分析型数据大显身手。
列式的另一大优势是压缩。因为列的天然凝聚性(比如上面的两个Jones就可以压缩成一个)大大强与行,所以列式储存可以有很高的压缩比,这个进一步使使用的磁盘的数量减少,因为使用的磁盘块少,进一步减少了需要扫描的次数。这方面很利于加快查找速度,但是因为解压缩也是耗时耗内存的过程,所以压缩的控制也是需要一个定平衡点。
(4)列存储排序了是如何过滤多个条件找到对应的行?
如上面所述,很明显每个列存储中的值,都有其对应行号,找到一个列值后,根据行号对其他列存储中搜索该行号;
就像我们上面说的那个例子一样
- 这下我们再考虑上面的查找所有Jones的工资,这下我们只扫描第三个磁盘块,找出Jones都再那些行,然后根据查出来的行号
- 直接去第五块磁盘(这块对应的式salary列)找出第二、四行的数据,然后输出。一共2次seek。大大小于row-oriented的4次。
优劣总结
从上面的例子可以明显看出列式数据库在分析需求(获取特点——每次查询几个维度,通常是)时候,不仅搜索时间效率占优势,其空间效率也是很明显的。
特别是针对动辄按T计算的数据量来说,在分布式环境中能进行压缩处理能节省宝贵的内部带宽,从而提高整个计算任务性能。
【2】补充:数据压缩
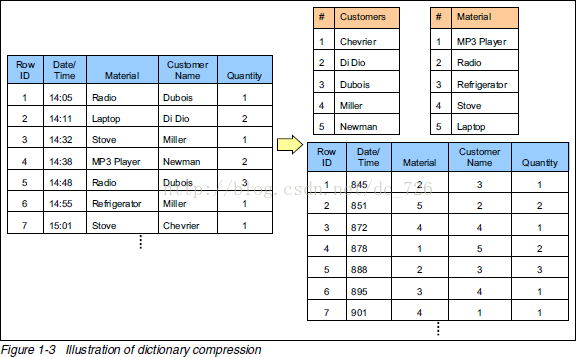
刚才其实跳过了资料里提到的另一种技术:通过字典表压缩数据。为了方面后面的讲解,这部分也顺带提一下了。
下面中才是那张表本来的样子。经过字典表进行数据压缩后,表中的字符串才都变成数字了。(为什么是数字,因为数字占用空间小,且对排序极为友好)
正因为每个字符串在字典表里只出现一次了,所以达到了压缩的目的(有点像规范化和非规范化Normalize和Denomalize)
3查询执行性能
下面就是最牛的图了,通过一条查询的执行过程说明列式存储(以及数据压缩)的优点:
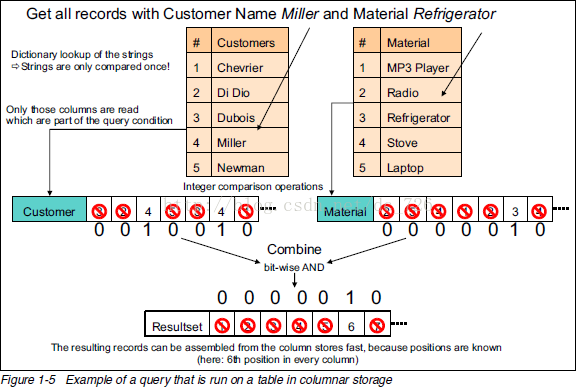
关键步骤如下:
1. 去字典表里找到字符串对应数字(只进行一次字符串比较)。
2. 用数字去列表里匹配,匹配上的位置设为1
3. 把不同列的匹配结果进行位运算得到符合所有条件的记录下标。
4. 使用这个下标组装出最终的结果集。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号