(1.3)DML增强功能-Apply、pivot、unpivot、for xml path行列转换
深入了解行列转换请参考另一篇文章:https://www.cnblogs.com/gered/p/9271581.html
总结:
1.apply一般形式

--基本形式 SELECT a FROM dbo.LargeTable AS LT--实际表 CROSS APPLY dbo.split(LT.Name,':')--自定义表值函数,处理以某个字符分隔的数据,把这些数据,返回一张表 WHERE a <> '' --去掉结果表中a字段为空的数据
2.pivot与unpivot一般形式
(1)pivot

(2)unpivot

--pivot基本形式 select * from table a pivot (max(行值) for 需要转换的列 in (转换值1,转换值2)) b --必须要别名否则报错
--unpivot基本形式
SELECT USERID,USERNO,tType=attribute FROM (select * from tbl_列转行测试)a UNPIVOT ( 转之后的值列名 FOR 转了之后的列所在列名 IN(列名A, 列名B,列名C) ) AS UPV --必须要别名否则报错
3、详细操作
1.Apply
其分为两类CROSS APPLY和 OUTER APPLY
(1)CROSS APPLY
--基本形式 SELECT a FROM dbo.LargeTable AS LT--实际表 CROSS APPLY dbo.split(LT.Name,':')--自定义表值函数,处理以某个字符分隔的数据,把这些数据,返回一张表 WHERE a <> '' --去掉结果表中a字段为空的数据
--原理过程
--APPLY的执行过程,它先逻辑计算左表表达式(以上的LargeTable表),然后把右表达式(以上的自定义表值函数Split)应用到左表表达式的每一行。实际是把外部查询的列引用作为参数传递给表值函数。
--split函数 SELECT * FROM dbo.split('581::579::519::279::406::361::560',':') ALTER Function [dbo].[Split](@Sql varchar(8000),@Splits varchar(10)) returns @temp Table (a varchar(100)) As Begin Declare @i Int Set @Sql = RTrim(LTrim(@Sql)) Set @i = CharIndex(@Splits,@Sql) While @i >= 1 Begin Insert @temp Values(Left(@Sql,@i-1)) Set @Sql = SubString(@Sql,@i+1,Len(@Sql)-@i) Set @i = CharIndex(@Splits,@Sql) End If @Sql <> '' Insert @temp Values (@Sql) Return End
案例演示
【1】原始数据

【2】运行之后获得的数据

(2)OUTER APPLY
场景:有个供货商表(Supplier)和供货商产品表(Products),我们要取每一个供货商中单价最高的两个产品。
供货商表:

供货商产品表:

首先,我们创建一个自定义表值函数(dbo.fn_top_products),该函数根据供货商ID返回单价最高的两个商品。 好,前期的数据都已经准备好了,下面让我们试试用OUTER APPLY形式来查询,会出现什么结果。
- IF OBJECT_ID('dbo.fn_top_products') IS NOT NULL
- DROP FUNCTION dbo.fn_top_products;
- GO
--根据供货商ID获得单价最高的两件商品
CREATE FUNCTION dbo.fn_top_products (@supid AS INT) RETURNS TABLE AS RETURN SELECT TOP(2)Id AS ProductId,ProductName,UnitPrice FROM dbo.Products WHERE SupplierId = @supid ORDER BY UnitPrice DESC GO
执行以下语句:
SELECT S.id AS SupplierId,S.CompanyName,UnitPrice FROM dbo.Supplier AS S OUTER APPLY dbo.fn_top_products(S.id) AS P
执行结果如下:

注意最后为NULL的记录,reed公司因为没有商品,所以单价为NULL了。
如果用CROSS APPLY形式,执行以下查询:
SELECT S.id AS SupplierId,S.CompanyName,UnitPrice FROM dbo.Supplier AS S CROSS APPLY dbo.fn_top_products(S.id) AS P
生成的输出结果如下:

大家看出OUTER APPLY和CROSS APPLY的区别了吧。
2.pivot 行转列
--基本形式 select * from table a pivot (max(行值) for 需要转换的列 in (转换值1,转换值2)) b
直接贴图吧:数据可以到另一篇文章去看https://www.cnblogs.com/gered/p/8696473.html

之所以很多地方为NULL是因为pivot和unpivot会把除 pivot()括号内的字段都作为分组项,所以如果想实现如下图效果。

则需要先做一个子查询或CTE来把相关字段给筛选出来,代码如下(或可以用case when做行转列直接group by 指定字段)
select * from (select 学生姓名,成绩,课程名称 from tbl_Student) a pivot (max(成绩) for 课程名称 in (语文,数学,英语,政治)) b
结果如下:

3.unpivot列转行
一般形式:
SELECT USERID,USERNO,tType=attribute
FROM (select * from tbl_列转行测试)a
UNPIVOT
(
转之后的值列名 FOR 转了之后的列所在列名 IN(列名A, 列名B,列名C)
) AS UPV --必须要别名否则报错
举例如下:

注意,这句话unpivot同样适用:之所以很多地方为NULL是因为pivot和unpivot会把除 pivot()括号内的字段都作为分组项
4.一个应用场景与FOR XML PATH应用
(1)group_concat
首先呢!我们在增加一张学生表,列分别为(stuID,sName,hobby),stuID代表学生编号,sName代表学生姓名,hobby列存学生的爱好!那么现在表结构如下:

这时,我们的要求是查询学生表,显示所有学生的爱好的结果集,代码如下:

SELECT sName,
(SELECT hobby+',' FROM student
WHERE sName=A.sName
FOR XML PATH('')) AS StuList
FROM student A
GROUP BY sName
) B
结果如下: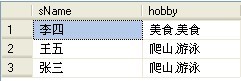
分析: 好的,那么我们来分析一下,首先看这句:
WHERE sName=A.sName
FOR XML PATH('')
这句是通过FOR XML PATH 将某一姓名如张三的爱好,显示成格式为:“ 爱好1,爱好2,爱好3,”的格式!
那么接着看:
SELECT sName,
(SELECT hobby+',' FROM student
WHERE sName=A.sName
FOR XML PATH('')) AS StuList
FROM student A
GROUP BY sName
) B
剩下的代码首先是将表分组,在执行FOR XML PATH 格式化,这时当还没有执行最外层的SELECT时查询出的结构为:

可以看到StuList列里面的数据都会多出一个逗号,这时随外层的语句:SELECT B.sName,LEFT(StuList,LEN(StuList)-1) as hobby 就是来去掉逗号,并赋予有意义的列明!
(2)最佳实践案例
SELECT STUFF((SELECT ','+字段名 FROM 表名 for xml path('')),1,1,'')

(3)列转行

----------------------------------------------------------------
--> 测试数据[huang]if object_id('[huang]') is not null drop table [huang]go create table [huang]([a] nvarchar(4),[b] nvarchar(10))insert [huang]select 'X1','1,4,8' union allselect 'X2','2' union allselect 'X3','3,6' union allselect 'X4','7' union allselect 'X5','5'--------------生成数据--------------------------select a.[a], SUBSTRING(a.[b],number,CHARINDEX(',',[b]+',',b.number)-b.number) as [b] , b.number from [huang] a,master..spt_values b where b.number >=1 and b.number<=len(a.[b]) and b.type='p' and substring(','+a.[b],b.number,1)=','
--演示代码
select * from master..spt_values
where type='p'
order by number
----------------结果----------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号