
安卓-本地asr语音识别-将非流式处理成流式-应用层面简单处理转换
背景
众所周知,目前开源的asr语音识别引擎,有些是支持流式识别的,有些是不支持流式识别的。
流式识别的优势在于:人可以一直说,麦克风一直监听,识别文字结果一直输出,适合长时间机器对话、以及对话打断等。
而非流式的特点则是:输入一段完整的语音,提交给asr,让它一次性完整输出结果。
安卓平台,开源提供可用demo的本地语音识别中:
一些支持流式处理的语音识别有:vosk、sherpa-ncnn、sherpa-mmn
一些非流式的语音识别有:pytorch-Wav2Vec2、onnx-funasr、Whisper.cpp
如果要做本地ai对话,遇到效果好的asr,但又不支持流式处理,不能直接拿来,这个就需要处理成流式处理。
有多种科学的方案:
1.找到流式处理的demo
2.找不到流式demo时、找其它语音的实现demo:c++、rust等流式处理demo,移植为安卓工程
3.实在不支持流式处理时,改造asr算法让其支持流式处理,参考文档:流式语音识别原理和实现思路
思考
作为小小的开发仔,算法移植和修改引擎都太漫长不确定了。不过可以从应用层面做一个比较折中的办法:
将持续的录音数据,按静音(没有人说话)作为分割,将每次说话的数据,打包成一次完整的语音,将有说话的完整语音提交给asr识别,就这样拆成一段段的间歇性识别。
静音识别
人在不说话时,话筒里剩下的只是幅度很小的背景噪声;只要把这阵子信号的能量(或幅值)算出来,再跟一条经验门限比大小,能量低于门限就判为静音。整套流程全部在时域完成,无需解码、也无需频域变换,因此运算量极小,适合实时通话、录音降噪等场景。
pcm格式导出波形图
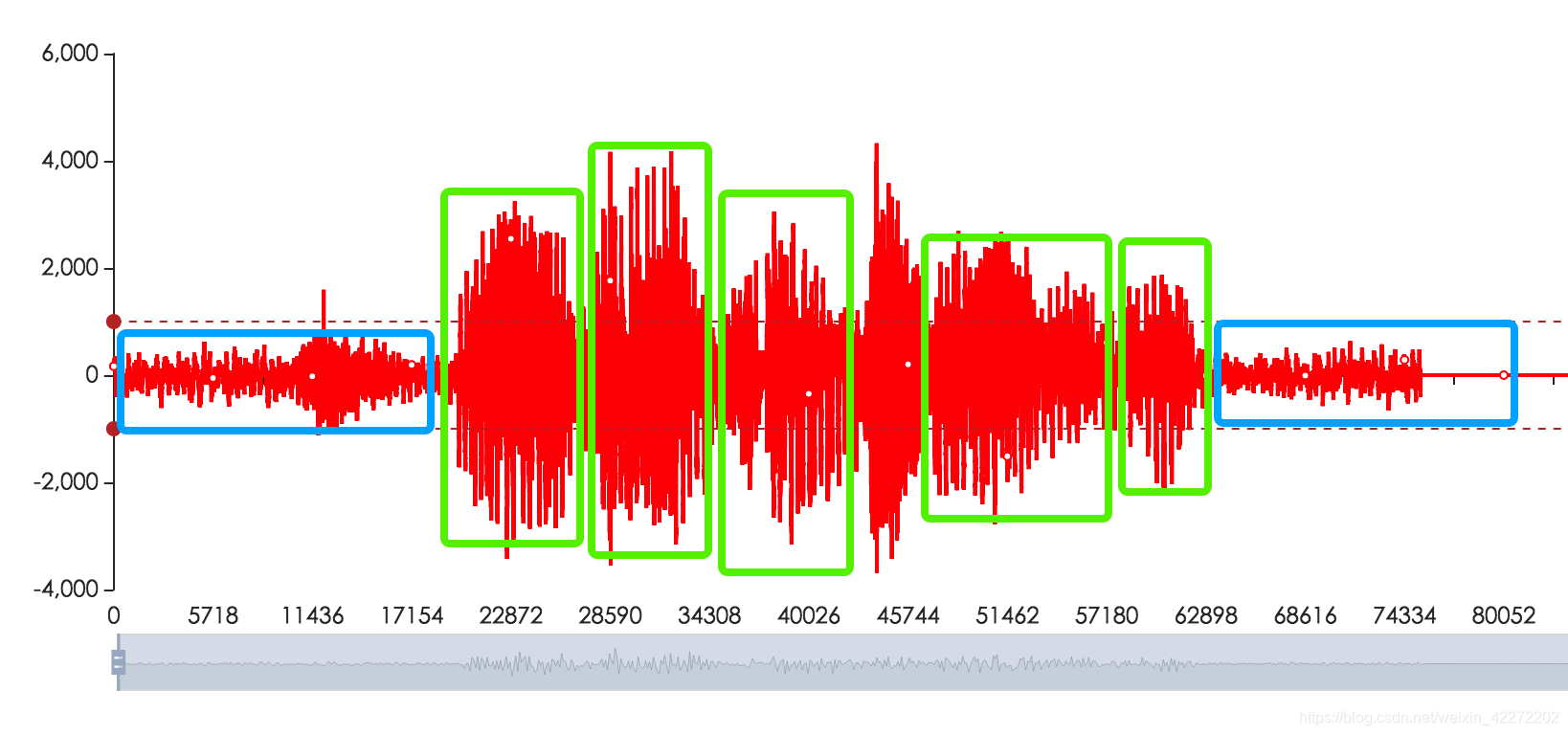
参考空语音识别原理
代码实现:
参考判断PCM音频为静音
判断静音代码:
public class SilenceDetector {
/** 默认 -40 dB 门限 */
private static final double DEFAULT_SILENCE_DB = -40.0;
/** 工具类禁止实例化 */
private SilenceDetector() { }
/**
* 判断整段 PCM 是否全是静音
*
* @param pcmBytes 16-bit 小端、单声道 PCM 数据
* @param sampleRate 采样率,如 16000
* @param frameMs 定义每一帧总时长(毫秒数),建议 20 ms
* @param silenceDb 判定门限,单位 dB
* @return true 静音,false 至少有一帧超过判定门限,为说话中
*/
public static boolean isSilence(short[] pcmBytes,
int sampleRate,
int frameMs,
double silenceDb) {
return isSilence2(pcmBytes, 0, pcmBytes.length, sampleRate, frameMs, silenceDb);
}
/**
* 判断整段 PCM 是否全是静音
*
* @param pcmBytes 16-bit 小端、单声道 PCM 数据
* @param sampleRate 采样率,如 16000
* @param frameMs 定义每一帧总时长(毫秒数),建议 20 ms
* @param silenceDb 判定门限,单位 dB
* @return true 静音,false 至少有一帧超过判定门限,为说话中
*/
public static boolean isSilence2(short[] pcmBytes,
int dataOffset,
int dataLength,
int sampleRate,
int frameMs,
double silenceDb) {
int frameSamples = sampleRate * frameMs / 1000;
double thresholdLinear = Math.pow(10.0, silenceDb / 20.0);
int frames = dataLength / frameSamples;
if (frames == 0) return true; // 数据太短
for (int f = 0; f < frames; f++) {
double sumSq = 0.0;
int off = f * frameSamples;
for (int i = off; i < off + frameSamples; i++) {
short v = pcmBytes[dataOffset + i];
sumSq += v * v * 1.0;
}
//32768.0 是 16-bit 有符号音频样本的最大绝对值(即 Short.MAX_VALUE + 1),用来把 short 采样值归一化到 [-1.0, 1.0) 浮点范围,方便计算 RMS、dB 等。
double rms = Math.sqrt(sumSq / frameSamples) / 32768.0;
if (rms > thresholdLinear) return false; // 有一帧超门限
}
return true;
}
/* 16-bit 小端 → short[] */
private static short[] byteArrayToShortArray(byte[] bytes) {
if (bytes.length % 2 != 0)
throw new IllegalArgumentException("PCM 字节数必须是 2 的倍数");
short[] out = new short[bytes.length / 2];
for (int i = 0; i < out.length; i++) {
int lo = bytes[i * 2] & 0xFF;
int hi = bytes[i * 2 + 1] & 0xFF;
out[i] = (short) ((hi << 8) | lo);
}
return out;
}
/* 最简重载,使用默认参数 */
public static boolean isSilence(byte[] pcmBytes, int sampleRate) {
short[] shorts = byteArrayToShortArray(pcmBytes);
return isSilence(shorts, sampleRate);
}
public static boolean isSilence(short[] pcmBytes, int sampleRate) {
return isSilence(pcmBytes, sampleRate, 20, DEFAULT_SILENCE_DB);
}
public static boolean isSilence2(short[] pcmBytes,int dataOffset,
int dataLength, int sampleRate) {
return isSilence2(pcmBytes, dataOffset, dataLength, sampleRate, 20, DEFAULT_SILENCE_DB);
}
}
使用静音判断代码,分割采集有说话的pcm数据:
int bufferSize = AudioRecord.getMinBufferSize(SAMPLE_RATE, AudioFormat.CHANNEL_IN_MONO, AudioFormat.ENCODING_PCM_16BIT);
AudioRecord record = new AudioRecord(MediaRecorder.AudioSource.DEFAULT, SAMPLE_RATE, AudioFormat.CHANNEL_IN_MONO, AudioFormat.ENCODING_PCM_16BIT,
bufferSize);
if (record.getState() != AudioRecord.STATE_INITIALIZED) {
Log.e(LOG_TAG, "Audio Record can't initialize!");
return;
}
record.startRecording();
short[] audioBuffer = new short[bufferSize / 2];
while (recording) {
int numberOfShort = record.read(audioBuffer, 0, audioBuffer.length);
boolean isSilence = SilenceDetector.isSilence2(audioBuffer, 0, numberOfShort, SAMPLE_RATE);
Log.d("test", "isSilence=" + isSilence);
//采集堆积pcm数据,静音时一次性打包提交给asr识别,识别完成后开始下一轮数据堆积和识别。。。。
}
record.stop();
record.release();
补充
只是提供一种思路,毕竟不是真正的asr流式识别,只是有个流式pcm数据的中间拆分处理过程,需要自己调逻辑调效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号