Flink的窗口类型详解
无限数据流的统计问题
今天给大家分享一下Flink的Windows。Hive的窗口函数其实跟MySQL的差不多,因为他们都是基于离线数据的聚合。Flink的windows和Hive的窗口函数不完全一样。
离线数据处理好理解,数据已经落地在一张表里,咱可以通过partition by,按照某个字段进行分区,通过order进行排序,通过between进行范围限定,然后通过LEAD、FIRST_VALUE等进行定位,最后通过sum、avg等聚合函数进行计算。这就像计算图片中有多少个植物一样清晰明了。实在不行,咱硬数也是能行的。
但是Flink里的数据是个流,数据压根就不会落地,这咋进行计算啊?这是一个“无限游戏”啊!好比你得算一下植物大战僵尸里被射出多少颗豌豆子弹一样。非要计算,就只能永远计算一个不断增大的累计数而已。
除非咱能像截图一样,让数据停下来,然后咱再一颗一颗去数,否则根本没法算清楚范围内有多少颗豌豆子弹。这根本没法分析啊!
Flink的窗口类型
Flink是怎么解决这个问题的呢?很简单,设置一个固定的观察窗口,不停的计算窗口内的豌豆子弹数就可以了。这样就把无限数据流,变成有限数据块了。这样问题就解决了。

但是,有个问题,怎么划分窗口的范围呢?也就是说,如何切割窗口呢?几个办法:
1、用时间切割窗口,每过N秒记为一个window,即TimeWindow;
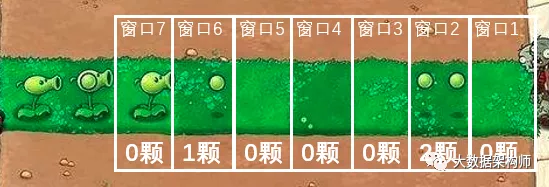
2、用数据量切割窗口,每N个数据记为一个window,即CountWindow;

3、用session切割窗口,数据流中断N秒记为一个window,即Sessionwindow;

4、不限定,从一开始到现在不断累计计算,即global window。这种状态下,Flink并行度只能为1。
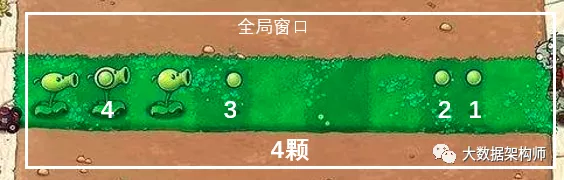
另外,对于TimeWindow和CountWindow,分别还有两种细分类型:滚动窗口和滑动窗口。
滚动窗口就是一个固定区间(时间或者数量),不断滚动,区间严格分离,不会重复。
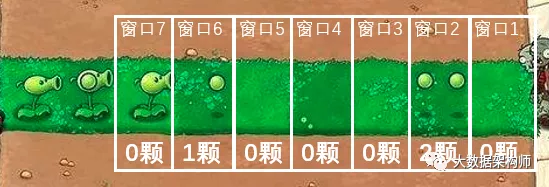

滑动窗口顾名思义,就是窗口区间是可以拖动的,所以会重复。

对了,针对数据本身,Flink还设置了keyed和non keyed两种windows,这是为了后续处理用的。其实就是解决你是否要区分子弹类型的:
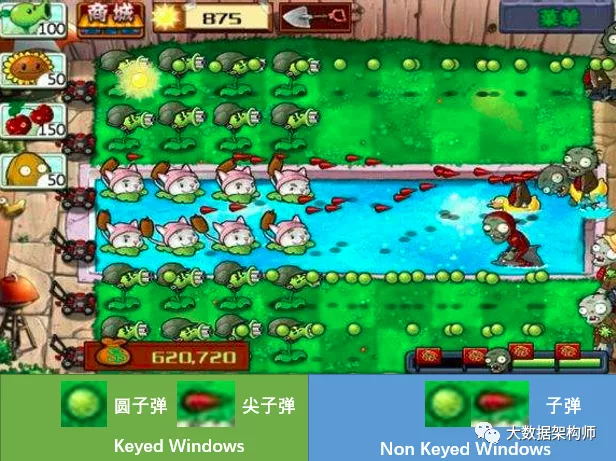
如果用了keyed windows,Flink会把相同key的数据发送到同一个task里进行处理,这样并行度就高了。
如果用了Non Keyed Windows,那么所有数据都会放在一个task里操作,并行度也就只能为1了。
总结
Flink的窗口按切割方式、是否有key值、滑动还是滚动三个维度,分为以下几种情况:
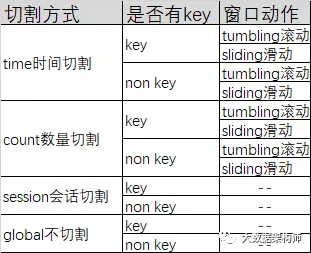
基本上这些窗口就能满足所有业务需求了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号