

爬虫Scrapy框架运用----房天下二手房数据采集
在许多电商和互联网金融的公司为了更好地服务用户,他们需要爬虫工程师对用户的行为数据进行搜集、分析和整合,为人们的行为选择提供更多的参考依据,去服务于人们的行为方式,甚至影响人们的生活方式。我们的scrapy框架就是爬虫行业使用的主流框架,房天下二手房的数据采集就是基于这个框架去进行开发的。
数据采集来源:‘房天下----全国二手房’
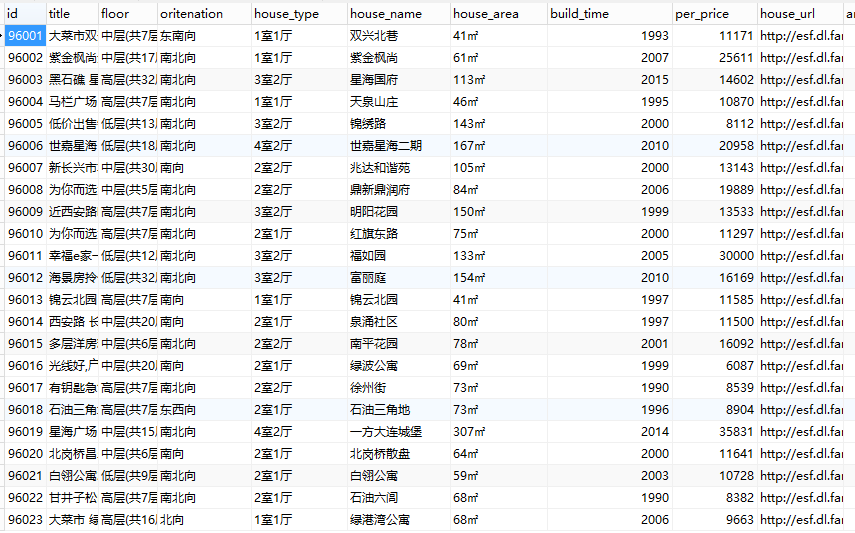
目标数据:省份名、城市名、区域名、房源介绍、房源小区、户型、朝向、楼层、建筑面积、建造时间、单价、楼盘链接
数据库设计:province、city、area、house四张表
爬虫spider部分demo:
获取省份、城市信息和链接
1 #获取省份名字,城市的链接url 2 def mycity(self,response): 3 #获得关键节点 4 links = response.css('#c02 > ul > li') 5 for link in links: 6 try: 7 province_name=link.xpath('./strong/text()').extract_first() 8 urllinks=link.xpath('./a') 9 for urllink in urllinks: 10 city_url=urllink.xpath('./@href').extract_first() 11 if city_url[-1]=='/': 12 city_url=city_url[:-1] 13 yield scrapy.Request(url=city_url,meta={'province_name':province_name,'city_url':city_url},callback=self.area) 14 except Exception: 15 pass
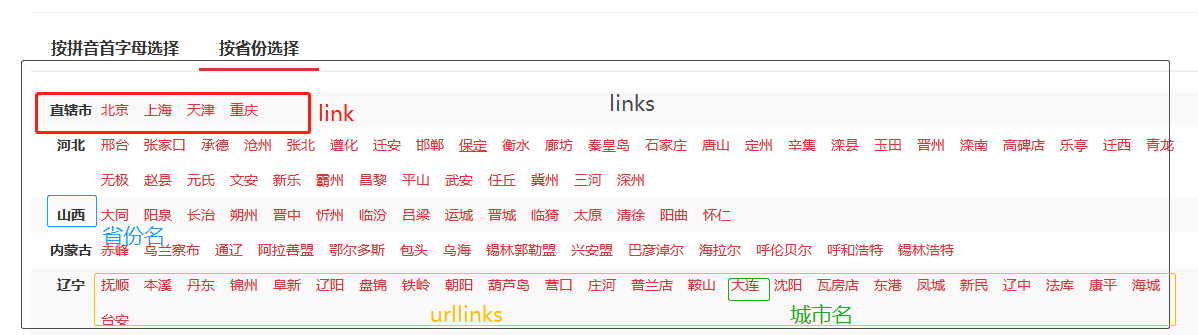
获取区域的链接url和信息


1 #获取区域的链接url 2 def area(self,response): 3 try: 4 links=response.css('.qxName a') 5 for link in links[1:]: 6 area_url=response.url+link.xpath('@href').extract_first() 7 yield scrapy.Request(url=area_url,meta=response.meta,callback=self.page) 8 except Exception: 9 pass

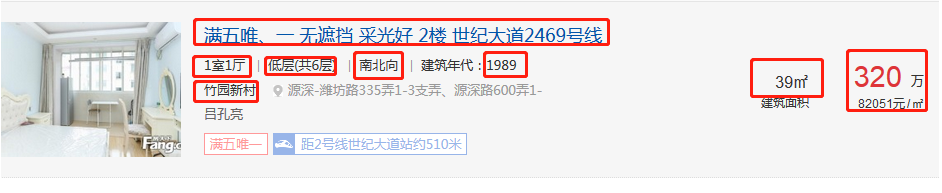
获取楼盘房源的信息
1 def houselist(self,response): 2 item={} 3 city_name = response.css('#list_D02_01 > a:nth-child(3)::text').extract_first() 4 area_name=response.css('#list_D02_01 > a:nth-child(5)::text').extract_first() 5 if city_name: 6 item['city_name']=city_name[:-3] 7 if area_name: 8 item['area_name']=area_name[:-3] 9 links=response.xpath('/html/body/div[3]/div[4]/div[5]/dl') 10 if links: 11 for link in links: 12 try: 13 item['title']=link.xpath('./dd/p[1]/a/text()').extract_first() 14 house_info=link.xpath('./dd/p[2]/text()').extract() 15 if house_info: 16 item['province_name']=response.meta['province_name'] 17 item['house_type']=link.xpath('./dd/p[2]/text()').extract()[0].strip() 18 item['floor']=link.xpath('./dd/p[2]/text()').extract()[1].strip() 19 item['oritenation']=link.xpath('./dd/p[2]/text()').extract()[2].strip() 20 item['build_time']=link.xpath('./dd/p[2]/text()').extract()[3].strip()[5:] 21 item['house_name']=link.xpath('./dd/p[3]/a/span/text()').extract_first() 22 item['house_area']=link.xpath('./dd/div[2]/p[1]/text()').extract_first() 23 item['per_price']=int(link.xpath('./dd/div[3]/p[2]/text()').extract_first()[:-1]) 24 list_url = link.xpath('./dd/p[1]/a/@href').extract_first() 25 item['house_url']=response.meta['city_url']+list_url 26 yield item 27 except Exception: 28 pass
 此时就可以运行scrapy crawl+爬虫名,我们就可以爬取到网站的信息,但是我们如何使用这些数据呢,那就要通过pipelines将数据插入到数据库中。
此时就可以运行scrapy crawl+爬虫名,我们就可以爬取到网站的信息,但是我们如何使用这些数据呢,那就要通过pipelines将数据插入到数据库中。
爬虫pipelines部分demo:
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 import pymysql 8 9 class HousePipeline(object): 10 def open_spider(self,spider): 11 self.con=pymysql.connect(user='root',passwd='123',db='test',host='localhost',port=3306,charset='utf8') 12 self.cursor=self.con.cursor(pymysql.cursors.DictCursor) 13 return spider 14 def process_item(self, item, spider): 15 #插入省份表 16 province_num=self.cursor.execute('select * from home_province where province_name=%s',(item['province_name'],)) 17 if province_num: 18 province_id=self.cursor.fetchone()['id'] 19 else: 20 sql='insert into home_province(province_name) values(%s)' 21 self.cursor.execute(sql,(item['province_name'])) 22 province_id=self.cursor.lastrowid 23 self.con.commit() 24 #插入城市表 25 ##规避不同省份城市重名的情况 26 city_num=self.cursor.execute('select * from home_city where city_name=%s and province_id=%s',(item['city_name'],province_id)) 27 if city_num: 28 city_id=self.cursor.fetchone()['id'] 29 else: 30 sql='insert into home_city(city_name,province_id) values(%s,%s)' 31 self.cursor.execute(sql,(item['city_name'],province_id)) 32 city_id=self.cursor.lastrowid 33 self.con.commit() 34 #插入区域表 35 ##规避不同城市区域重名的情况 36 area_num=self.cursor.execute('select * from home_area where area_name=%s and city_id=%s',(item['area_name'],city_id)) 37 if area_num: 38 area_id=self.cursor.fetchone()['id'] 39 else: 40 sql = 'insert into home_area (area_name,city_id,province_id)value(%s,%s,%s)' 41 self.cursor.execute(sql,(item['area_name'],city_id,province_id)) 42 area_id = self.cursor.lastrowid 43 self.con.commit() 44 #插入楼盘信息表 45 house_num=self.cursor.execute('select house_name from home_house where house_name=%s',( item['house_name'],)) 46 if house_num: 47 pass 48 else: 49 sql = 'insert into home_house(title,house_type,floor,oritenation,build_time,house_name,house_area,per_price,house_url,area_id,city_id,province_id) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)' 50 self.cursor.execute(sql, ( 51 item['title'], item['house_type'], item['floor'], item['oritenation'], item['build_time'], 52 item['house_name'], item['house_area'], item['per_price'],item['house_url'], area_id,city_id,province_id,)) 53 self.con.commit() 54 return item 55 def close_spider(self,spider): 56 self.cursor.close() 57 self.con.close() 58 return spider
采集数据效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号