爬虫爬当当网书籍信息
拖了好久的一个爬虫
先上代码 文字慢慢补
update(2018-5-7):加了出版社= =
updata(2018-6-29):啥都加了 https://github.com/general10/duangduang
首先我们是要爬取当当网书籍信息
在当前页面可以获取的是书名 评论总数 价格 折扣
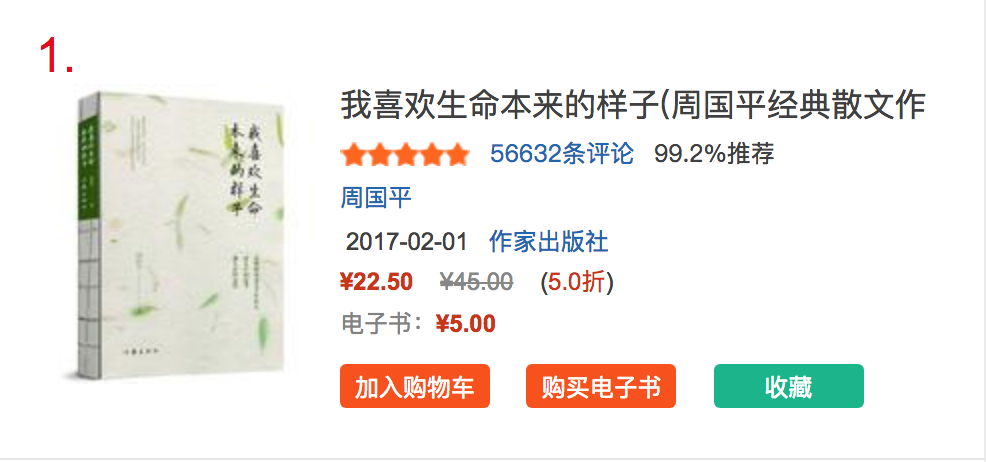
这几个数据都很好处理
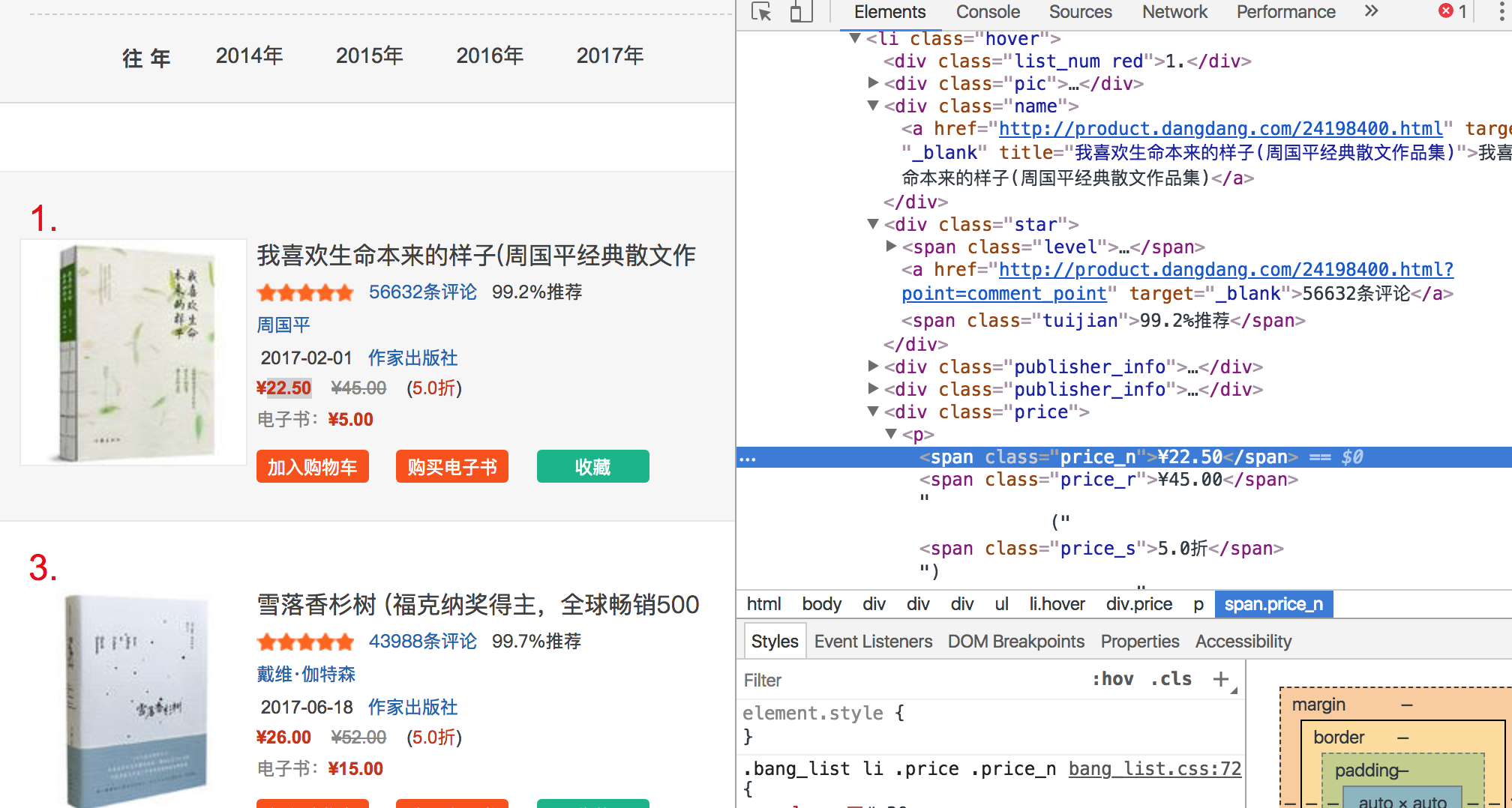
直接就在html里 抓出来就可以了
.text是获取内容 []是获取属性= =
1 bookname = data.find_all('div', attrs={'class': 'name'}) 2 bookstar = data.find_all('div', attrs={'class': 'star'}) 3 bookprice = data.find_all('div', attrs={'class': 'price'}) 4 bookoff = data.find_all('span', attrs={'class': 'price_s'}) 5 6 7 bookname[i].find('a')['title'] + " " # 书名 8 bookprice[i].find('span').text[1:] + " " # 价格 9 bookoff[i].text[:-1] + " " # 折扣 10 bookstar[i].find('a').text[:-3] + " " # 评论数
在书名的url里我们可以获取到好评 中评 差评 好评率
(其实上一步可以获取好评率 那个小星星是有填充的)
我们可以在检查里看到
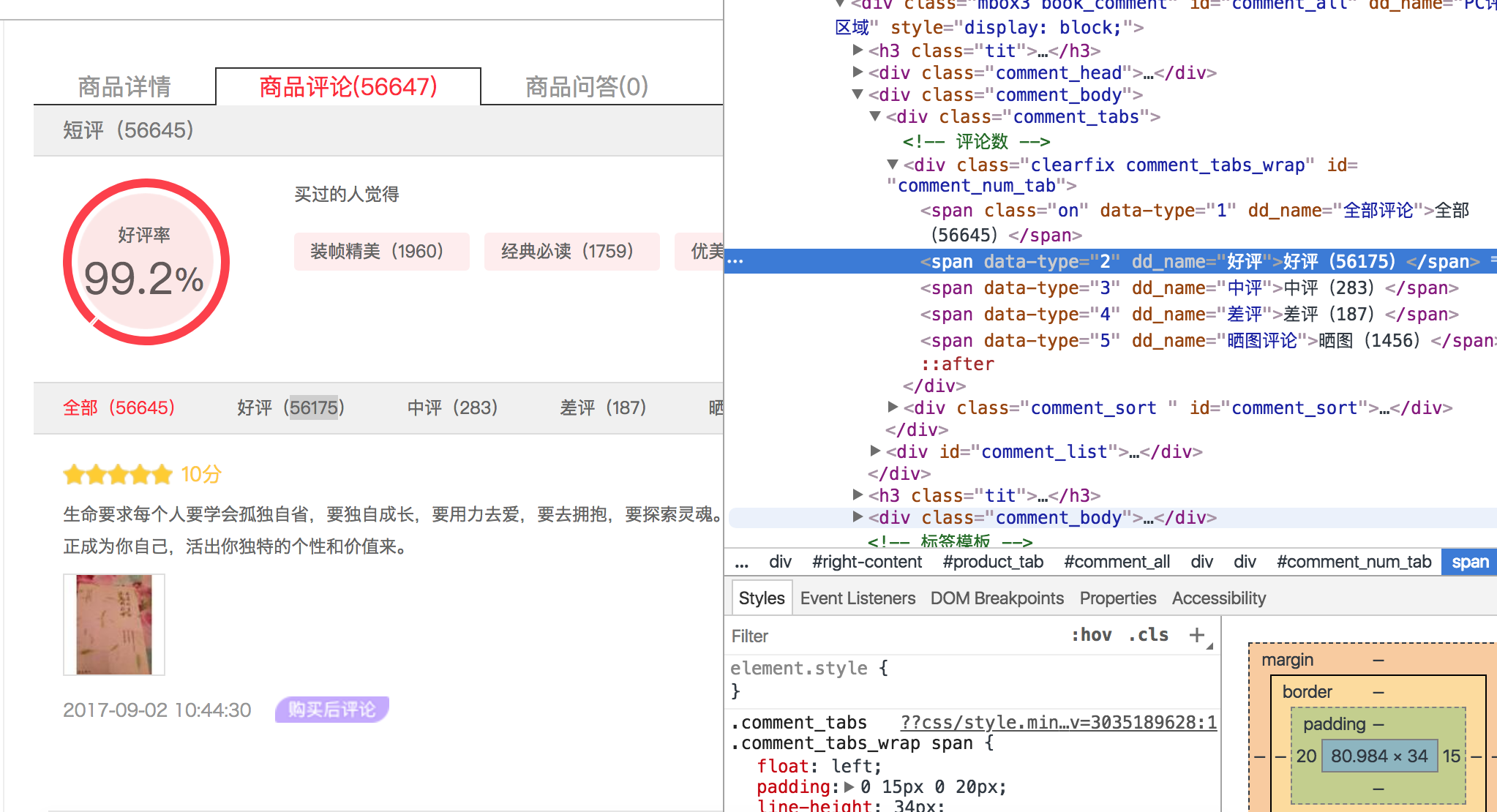
但是我们在网页源代码里是看不到评价的
因为评论这部分是ajax异步获取的
然后我们打开F12
在post请求里找评论的post
看一下这个preview的内容大概可以确定这个请求是评论的请求
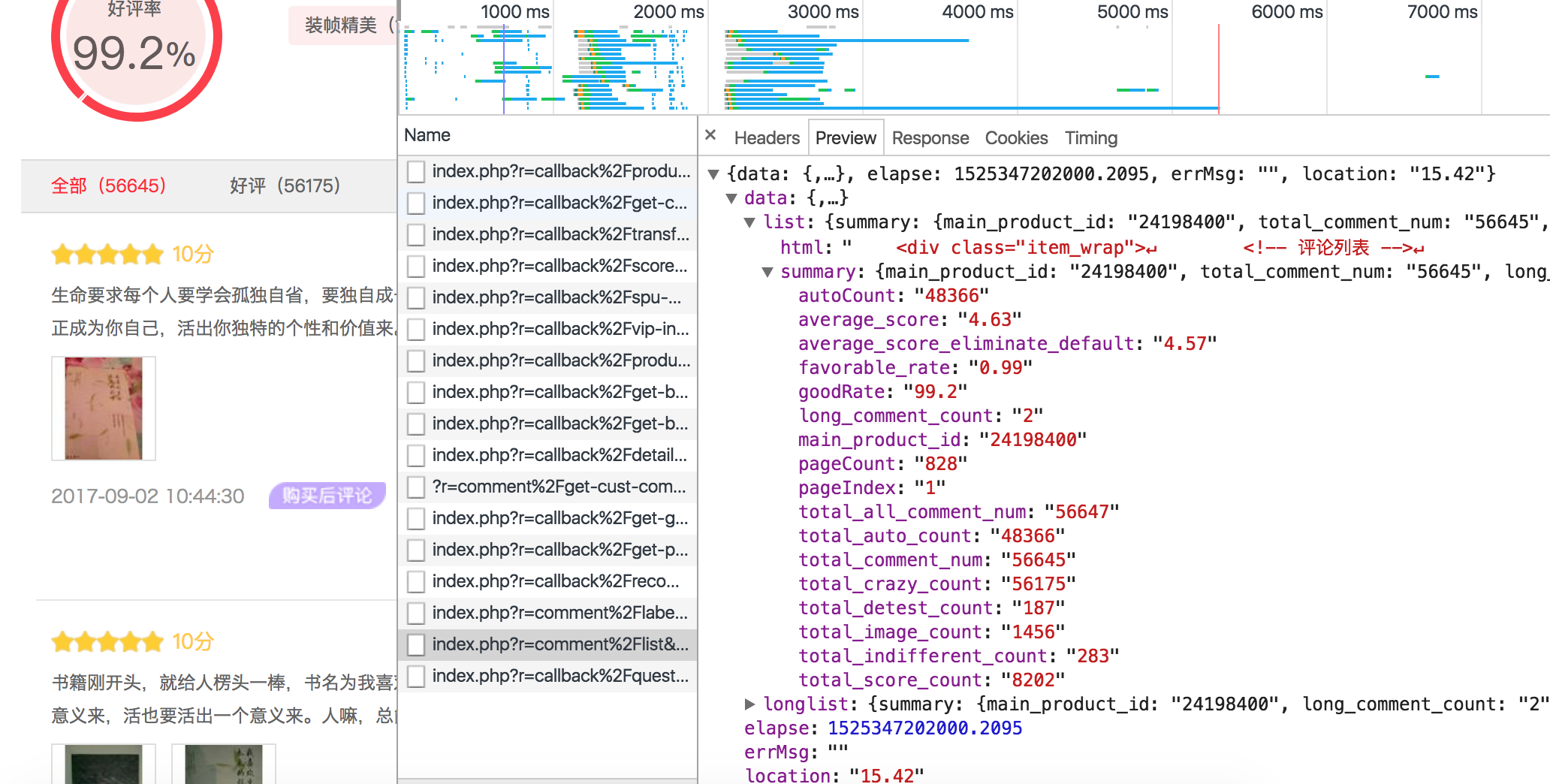
然后我们看header下的Request URL

这个url可以通过productId categoryPath mainProductId 这三个参数来确定
这三个参数可以在网页源代码里通过正则表达式匹配出来
1 def getId(html): 2 id = {} 3 ma = re.search(r'"productId":"[\d]+"', html) 4 id['productId'] = eval(ma.group().split(':')[-1]) 5 ma = re.search(r'"categoryPath":"[\d.]+"', html) 6 id['categoryPath'] = eval(ma.group().split(':')[-1]) 7 ma = re.search(r'"mainProductId":"[\d.]+"', html) 8 id['mainProductId'] = eval(ma.group().split(':')[-1]) 9 return id
然后拼接url之后下载url内容
1 def getCommentUrl(id): 2 return 'http://product.dangdang.com/index.php?r=comment%2Flist&productId={productId}&categoryPath={categoryPath}&mainProductId={mainProductId}&mediumId=0&pageIndex=1&sortType=1&filterType=1&isSystem=1&tagId=0&tagFilterCount=0'.format( 3 productId=id['productId'], categoryPath=id['categoryPath'], mainProductId=id['mainProductId'])
url内容是个json
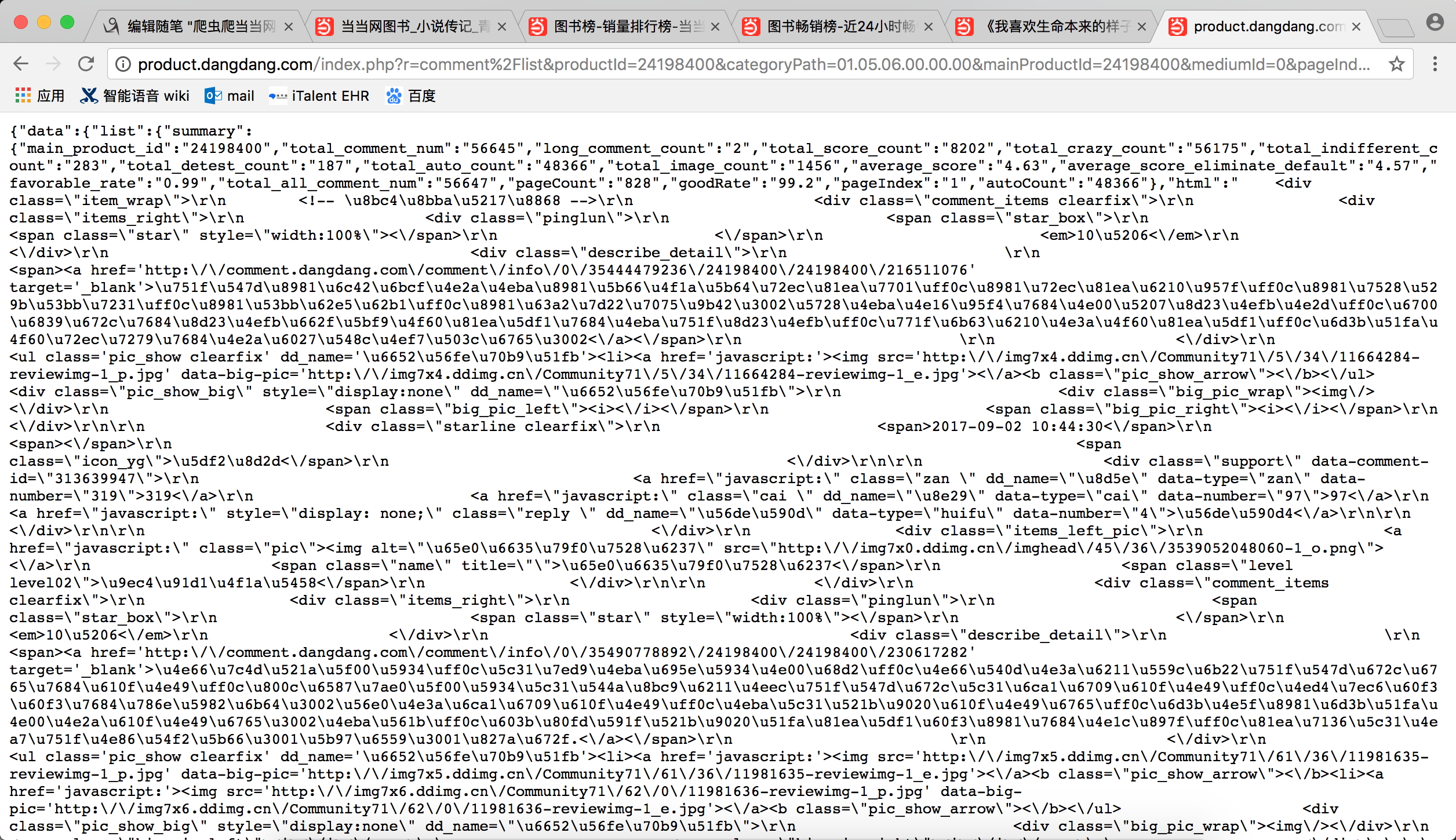
格式化一下之后就容易看得多了
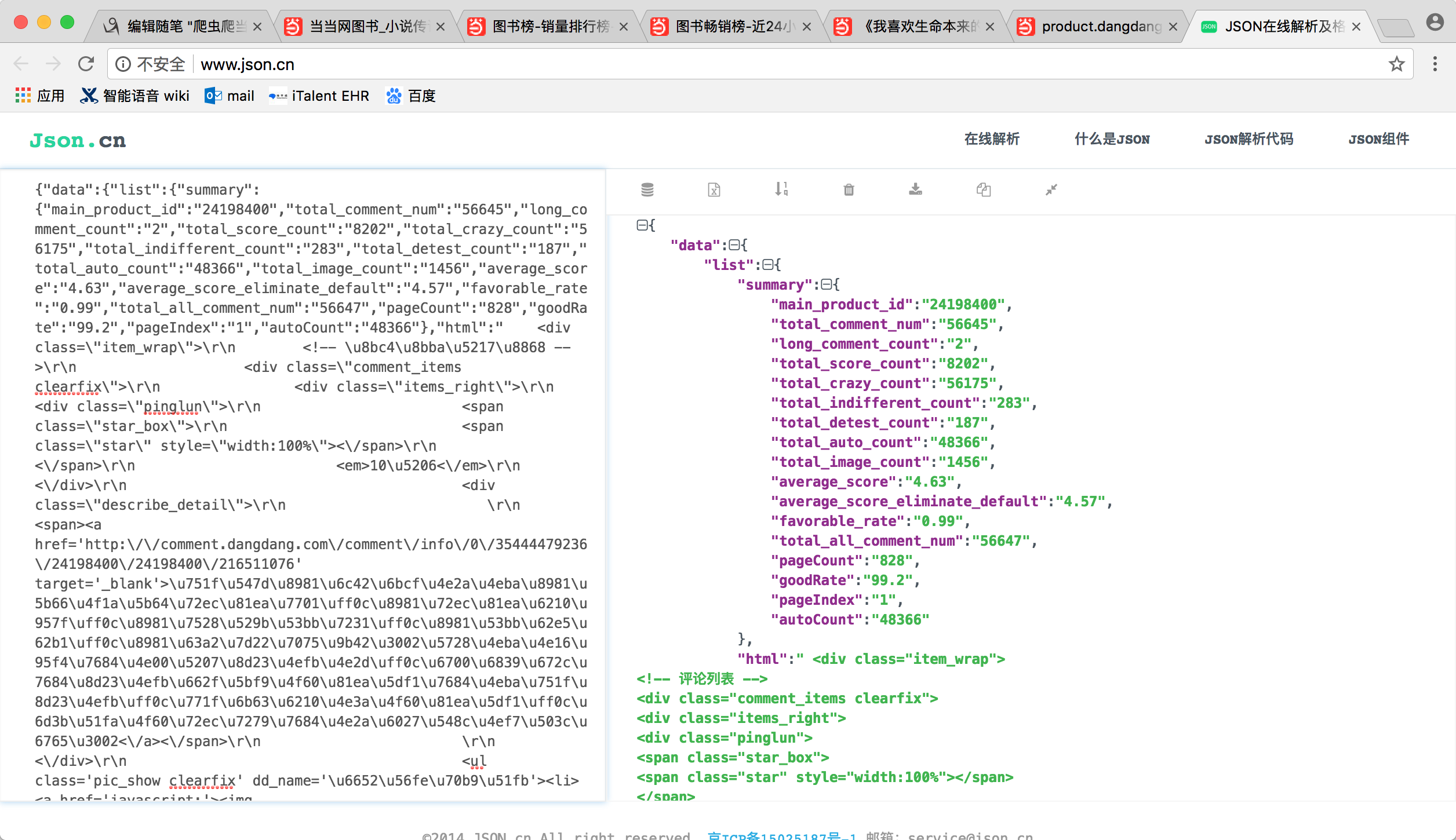
直接用py自带的json解析工具解析一下就好了
1 def getCommentCount(url): 2 html = urllib2.urlopen(url).read() 3 4 # 用正则表达式获取对应id 5 id = getId(html) 6 7 # 拼接ajax对应的url 8 json_url = getCommentUrl(id) 9 10 # 获取url对应的json 11 json_html = json.loads(getJsonText(json_url)) 12 13 # 获取评论数 14 summary = json_html['data']['list']['summary'] 15 comment= {} 16 comment['好评'] = summary['total_crazy_count'] # 好评数 17 comment['中评'] = summary['total_indifferent_count'] # 中评数 18 comment['差评'] = summary['total_detest_count'] # 差评数 19 comment['好评率'] = summary['goodRate'] # 好评率 20 return comment
最后是写入excel
.write(行, 列, 内容)
1 sheet1.write(page * 20 + i + 1, 0, page * 20 + i + 1) 2 sheet1.write(page * 20 + i + 1, 1, bookname[i].find('a')['title']) 3 sheet1.write(page * 20 + i + 1, 2, bookprice[i].find('span').text[1:]) 4 sheet1.write(page * 20 + i + 1, 3, bookoff[i].text[:-1]) 5 sheet1.write(page * 20 + i + 1, 4, bookstar[i].find('a').text[:-3]) 6 sheet1.write(page * 20 + i + 1, 5, data['好评']) 7 sheet1.write(page * 20 + i + 1, 6, data['中评']) 8 sheet1.write(page * 20 + i + 1, 7, data['差评']) 9 sheet1.write(page * 20 + i + 1, 8, data['好评率']) 10 wb.save('test.xls')
result
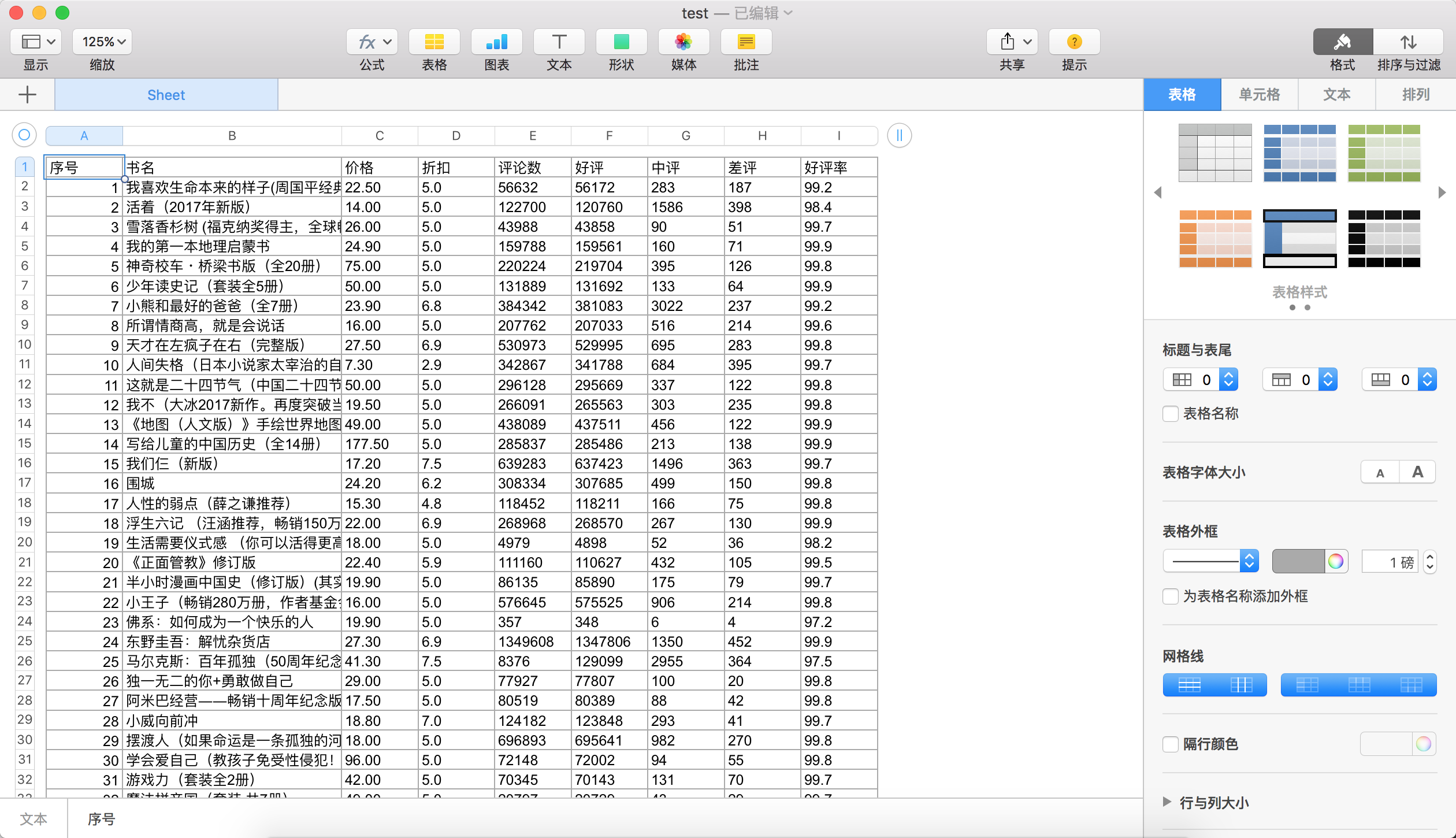
all code
(这个是一开始的)


1 # -*- coding: utf-8 -* 2 3 import urllib2 4 import xlwt 5 from bs4 import BeautifulSoup 6 from datashape import json 7 import re 8 import json 9 import requests 10 11 12 def getJsonText(url): 13 try: 14 r = requests.get(url, timeout=1) 15 r.raise_for_status() 16 r.encoding = r.apparent_encoding 17 return r.text 18 except: 19 print '获取失败' 20 return '' 21 22 23 def getId(html): 24 id = {} 25 ma = re.search(r'"productId":"[\d]+"', html) 26 id['productId'] = eval(ma.group().split(':')[-1]) 27 ma = re.search(r'"categoryPath":"[\d.]+"', html) 28 id['categoryPath'] = eval(ma.group().split(':')[-1]) 29 ma = re.search(r'"mainProductId":"[\d.]+"', html) 30 id['mainProductId'] = eval(ma.group().split(':')[-1]) 31 return id 32 33 def getCommentUrl(id): 34 return 'http://product.dangdang.com/index.php?r=comment%2Flist&productId={productId}&categoryPath={categoryPath}&mainProductId={mainProductId}&mediumId=0&pageIndex=1&sortType=1&filterType=1&isSystem=1&tagId=0&tagFilterCount=0'.format( 35 productId=id['productId'], categoryPath=id['categoryPath'], mainProductId=id['mainProductId']) 36 37 def getCommentCount(url): 38 html = urllib2.urlopen(url).read() 39 40 # 用正则表达式获取对应id 41 id = getId(html) 42 43 # 拼接ajax对应的url 44 json_url = getCommentUrl(id) 45 46 # 获取url对应的json 47 json_html = json.loads(getJsonText(json_url)) 48 49 # 获取评论数 50 summary = json_html['data']['list']['summary'] 51 comment= {} 52 comment['好评'] = summary['total_crazy_count'] # 好评数 53 comment['中评'] = summary['total_indifferent_count'] # 中评数 54 comment['差评'] = summary['total_detest_count'] # 差评数 55 comment['好评率'] = summary['goodRate'] # 好评率 56 return comment 57 58 def main(): 59 wb = xlwt.Workbook() 60 sheet1 = wb.add_sheet("Sheet") 61 sheet1.write(0, 0, unicode('序号', "utf-8")) 62 sheet1.write(0, 1, unicode('书名', "utf-8")) 63 sheet1.write(0, 2, unicode('价格', "utf-8")) 64 sheet1.write(0, 3, unicode('折扣', "utf-8")) 65 sheet1.write(0, 4, unicode('评论数', "utf-8")) 66 sheet1.write(0, 5, unicode('好评', "utf-8")) 67 sheet1.write(0, 6, unicode('中评', "utf-8")) 68 sheet1.write(0, 7, unicode('差评', "utf-8")) 69 sheet1.write(0, 8, unicode('好评率', "utf-8")) 70 71 for page in range(25): 72 73 url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-%d' % (page+1) 74 get = urllib2.urlopen(url).read() 75 data = BeautifulSoup(get, 'lxml') 76 77 bookname = data.find_all('div', attrs={'class': 'name'}) 78 bookstar = data.find_all('div', attrs={'class': 'star'}) 79 bookprice = data.find_all('div', attrs={'class': 'price'}) 80 bookoff = data.find_all('span', attrs={'class': 'price_s'}) 81 82 for i in range(20): 83 bookurl = bookname[i].find('a')['href'] 84 data = getCommentCount(bookurl) 85 print (str(page*20+i+1) + " " 86 + bookname[i].find('a')['title'] + " " # 书名 87 + bookprice[i].find('span').text[1:] + " " # 价格 88 + bookoff[i].text[:-1] + " " # 折扣 89 + bookstar[i].find('a').text[:-3] + " " # 评论数 90 + data['好评'] + " " # 好评数 91 + data['中评'] + " " # 中评数 92 + data['差评'] + " " # 差评数 93 + data['好评率'] + " " # 好评率 94 ) 95 96 sheet1.write(page * 20 + i + 1, 0, page * 20 + i + 1) 97 sheet1.write(page * 20 + i + 1, 1, bookname[i].find('a')['title']) 98 sheet1.write(page * 20 + i + 1, 2, bookprice[i].find('span').text[1:]) 99 sheet1.write(page * 20 + i + 1, 3, bookoff[i].text[:-1]) 100 sheet1.write(page * 20 + i + 1, 4, bookstar[i].find('a').text[:-3]) 101 sheet1.write(page * 20 + i + 1, 5, data['好评']) 102 sheet1.write(page * 20 + i + 1, 6, data['中评']) 103 sheet1.write(page * 20 + i + 1, 7, data['差评']) 104 sheet1.write(page * 20 + i + 1, 8, data['好评率']) 105 wb.save('test.xls') 106 107 main()
在mac里换了点东西才可以用(谁知道为什么
1 # -*- coding: utf-8 -* 2 3 import xlwt 4 from bs4 import BeautifulSoup 5 from datashape import json 6 import re 7 import json 8 import requests 9 10 11 def getJsonText(url): 12 try: 13 r = requests.get(url, timeout=1) 14 r.raise_for_status() 15 r.encoding = r.apparent_encoding 16 return r.text 17 except: 18 print('获取失败') 19 return '' 20 21 22 def getId(html): 23 id = {} 24 ma = re.search(r'"productId":"[\d]+"', html) 25 id['productId'] = eval(ma.group().split(':')[-1]) 26 ma = re.search(r'"categoryPath":"[\d.]+"', html) 27 id['categoryPath'] = eval(ma.group().split(':')[-1]) 28 ma = re.search(r'"mainProductId":"[\d.]+"', html) 29 id['mainProductId'] = eval(ma.group().split(':')[-1]) 30 return id 31 32 def getCommentUrl(id): 33 return 'http://product.dangdang.com/index.php?r=comment%2Flist&productId={productId}&categoryPath={categoryPath}&mainProductId={mainProductId}&mediumId=0&pageIndex=1&sortType=1&filterType=1&isSystem=1&tagId=0&tagFilterCount=0'.format( 34 productId=id['productId'], categoryPath=id['categoryPath'], mainProductId=id['mainProductId']) 35 36 def getCommentCount(url): 37 html = requests.get(url).text 38 39 # 用正则表达式获取对应id 40 id = getId(html) 41 42 # 拼接ajax对应的url 43 json_url = getCommentUrl(id) 44 45 # 获取url对应的json 46 json_html = json.loads(getJsonText(json_url)) 47 48 # 获取评论数 49 summary = json_html['data']['list']['summary'] 50 comment = {} 51 comment['好评'] = summary['total_crazy_count'] # 好评数 52 comment['中评'] = summary['total_indifferent_count'] # 中评数 53 comment['差评'] = summary['total_detest_count'] # 差评数 54 comment['好评率'] = summary['goodRate'] # 好评率 55 return comment 56 57 def main(): 58 wb = xlwt.Workbook() 59 sheet1 = wb.add_sheet("Sheet") 60 sheet1.write(0, 0, '序号') 61 sheet1.write(0, 1, '书名') 62 sheet1.write(0, 2, '作者') 63 sheet1.write(0, 3, '出版社') 64 sheet1.write(0, 4, '价格') 65 sheet1.write(0, 5, '折扣') 66 sheet1.write(0, 6, '评论数') 67 sheet1.write(0, 7, '好评') 68 sheet1.write(0, 8, '中评') 69 sheet1.write(0, 9, '差评') 70 sheet1.write(0, 10, '好评率') 71 72 for page in range(2): 73 74 url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-%d' % (page+1) 75 get = requests.get(url).text 76 data = BeautifulSoup(get, 'lxml') 77 78 bookname = data.find_all('div', attrs={'class': 'name'}) 79 bookstar = data.find_all('div', attrs={'class': 'star'}) 80 bookpublish = data.find_all('div', attrs={'class': 'publisher_info'}) 81 bookprice = data.find_all('div', attrs={'class': 'price'}) 82 bookoff = data.find_all('span', attrs={'class': 'price_s'}) 83 84 85 for i in range(20): 86 bookurl = bookname[i].find('a')['href'] 87 comments = getCommentCount(bookurl) 88 print (str(page*20+i+1) + " " 89 + bookname[i].find('a')['title'] + " " # 书名 90 + bookpublish[i*2].find('a').text + " " # 作者 91 + bookpublish[i*2+1].find('a').text + " " # 出版社 92 + bookprice[i].find('span').text[1:] + " " # 价格 93 + bookoff[i].text[:-1] + "折 " # 折扣 94 + bookstar[i].find('a').text[:-3] + " " # 评论数 95 + comments['好评'] + " " # 好评数 96 + comments['中评'] + " " # 中评数 97 + comments['差评'] + " " # 差评数 98 + comments['好评率'] + "% " # 好评率 99 ) 100 101 sheet1.write(page * 20 + i + 1, 0, page * 20 + i + 1) 102 sheet1.write(page * 20 + i + 1, 1, bookname[i].find('a')['title']) 103 sheet1.write(page * 20 + i + 1, 2, bookpublish[i*2].find('a').text) 104 sheet1.write(page * 20 + i + 1, 3, bookpublish[i*2+1].find('a').text) 105 sheet1.write(page * 20 + i + 1, 4, bookprice[i].find('span').text[1:]) 106 sheet1.write(page * 20 + i + 1, 5, bookoff[i].text[:-1] + '折') 107 sheet1.write(page * 20 + i + 1, 6, bookstar[i].find('a').text[:-3]) 108 sheet1.write(page * 20 + i + 1, 7, comments['好评']) 109 sheet1.write(page * 20 + i + 1, 8, comments['中评']) 110 sheet1.write(page * 20 + i + 1, 9, comments['差评']) 111 sheet1.write(page * 20 + i + 1, 10, comments['好评率'] + '%') 112 wb.save('test.xls') 113 114 main()
(存个图片)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号