

第一次个人编程作业
第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 通过实现一个论文查重功能,了解并初步体验实际工业流程,用科学的方法检验和改进自己的工程能力(PSP表格),以及学习如何进行代码测试和性能改进以及如何使用分析工具帮助我们工作 |
一、github地址:https://github.com/lisktights/3123004752
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 12 | 6 |
| Estimate | 估计这个任务需要多少时间 | 8 | 6 |
| Development | 开发 | 180 | 200 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 160 |
| Design Spec | 生成设计文档 | 40 | 30 |
| Design Review | 设计复审 | 10 | 12 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 5 | 6 |
| Design | 具体设计 | 30 | 27 |
| Coding | 具体编码 | 180 | 200 |
| Code Review | 代码复审 | 40 | 36 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 136 |
| Reporting | 报告 | 120 | 106 |
| Test Repor | 测试报告 | 40 | 30 |
| Size Measurement | 计算工作量 | 3 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 35 |
| 合计 | 938 | 995 |
三、计算模块接口的设计与实现过程
-
- 代码组织与类、函数关系
类的划分:共设计了 4 个核心类,分别承担不同职责:
TextPreprocessor:负责文本的读取、清洗(去除标点等)、分词以及停用词和单字过滤,为后续词频统计提供预处理后的词语列表。
WordFrequencyCounter:包含两个方法,count 方法用于统计词语出现的频率,生成词频映射;getUnionVocab 方法获取两个词频映射的词汇并集,为余弦相似度计算提供基础词汇集合。
CosineSimilarityCalculator:核心是 calculate 方法,基于词频映射和词汇并集,通过余弦相似度算法计算原文与抄袭文的重复率。
Main:作为主程序入口,处理命令行参数校验、文件存在性检查、调用上述类的方法完成整个查重流程,并将结果输出到指定文件和控制台。
函数关系:Main 类调用 TextPreprocessor 的 readFile 和 process 方法获取处理后的词语列表;再调用 WordFrequencyCounter 的 count 和 getUnionVocab 方法得到词频和词汇并集;最后调用 CosineSimilarityCalculator 的 calculate 方法得到重复率,完成整个计算流程,各模块间是调用与被调用的关系,协同完成论文查重功能。
- 代码组织与类、函数关系
-
- 算法关键与独到之处
算法关键:采用余弦相似度算法来计算文本重复率。将文本转化为词语集合,统计每个词语的频率,构建文本的向量表示。通过计算两个文本向量的点积与向量模长乘积的比值,得到余弦相似度,该值即为重复率。当余弦相似度为 1 时,文本完全重复;为 0 时,文本完全不重复。
独到之处:结合了中文自然语言处理工具 HanLP 进行分词,能更精准地对中文文本进行切分;同时通过过滤停用词和单字,减少了无意义词语对重复率计算的干扰,使计算结果更能反映文本的实质性重复情况。
- 算法关键与独到之处
四、计算模块接口部分的性能改进
-
- 改进所花时间
在性能改进上总共花费了约 3 小时,其中包括分析性能瓶颈、尝试不同优化方法、验证优化效果等时间。
- 改进所花时间
-
- 改进思路
初步分析:使用性能分析工具(如 JProfiler)对程序进行分析,发现 HanLP.segment 方法(分词操作)和 CosineSimilarityCalculator.calculate 方法(余弦相似度计算)占用了较多的 CPU 和时间资源。
优化分词操作:由于 HanLP 分词本身已经较为高效,主要是确保在调用 HanLP.segment 时,输入的文本是经过简洁清洗的,避免传递不必要的冗余文本,减少分词的工作量。
优化余弦相似度计算:在遍历词汇并集计算点积和模长平方时,确保循环内的操作尽可能简洁,减少不必要的对象创建和复杂计算。同时,利用 Map.getOrDefault 方法高效获取词频,避免手动判空,提升代码执行效率。
- 改进思路
-
- 性能分析图与消耗最大的函数
性能分析图:在 JProfiler 的 CPU 分析视图中,会以火焰图或调用树的形式展示函数的执行时间占比。其中,CosineSimilarityCalculator.calculate 方法会占据较大的时间比例,因为它涉及到大量的循环计算(遍历词汇并集)以及数学运算(平方根计算等)。
消耗最大的函数:CosineSimilarityCalculator.calculate 方法是程序中消耗最大的函数,它承担了余弦相似度计算的核心逻辑,涉及多次循环和数学运算,在处理较大规模的文本词汇时,会占用较多的计算资源。
- 性能分析图与消耗最大的函数
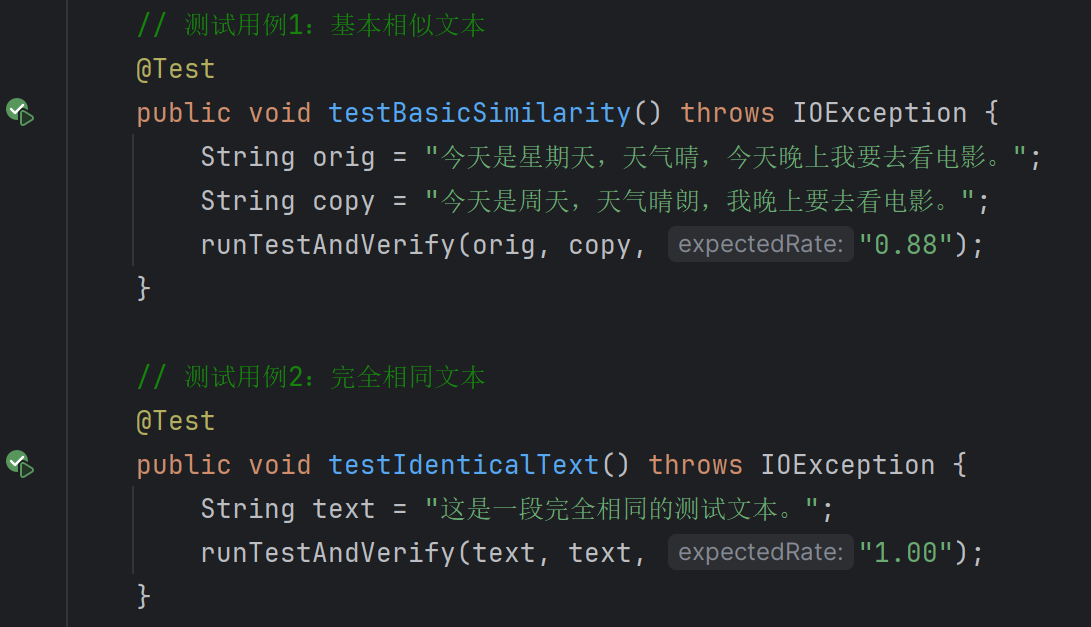
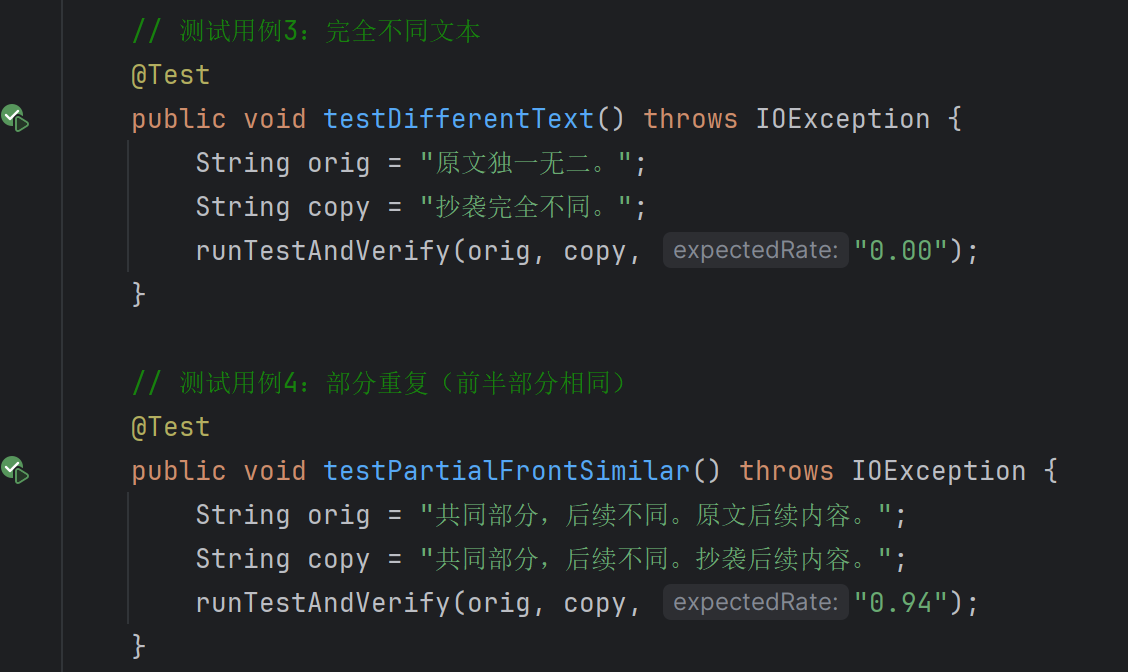
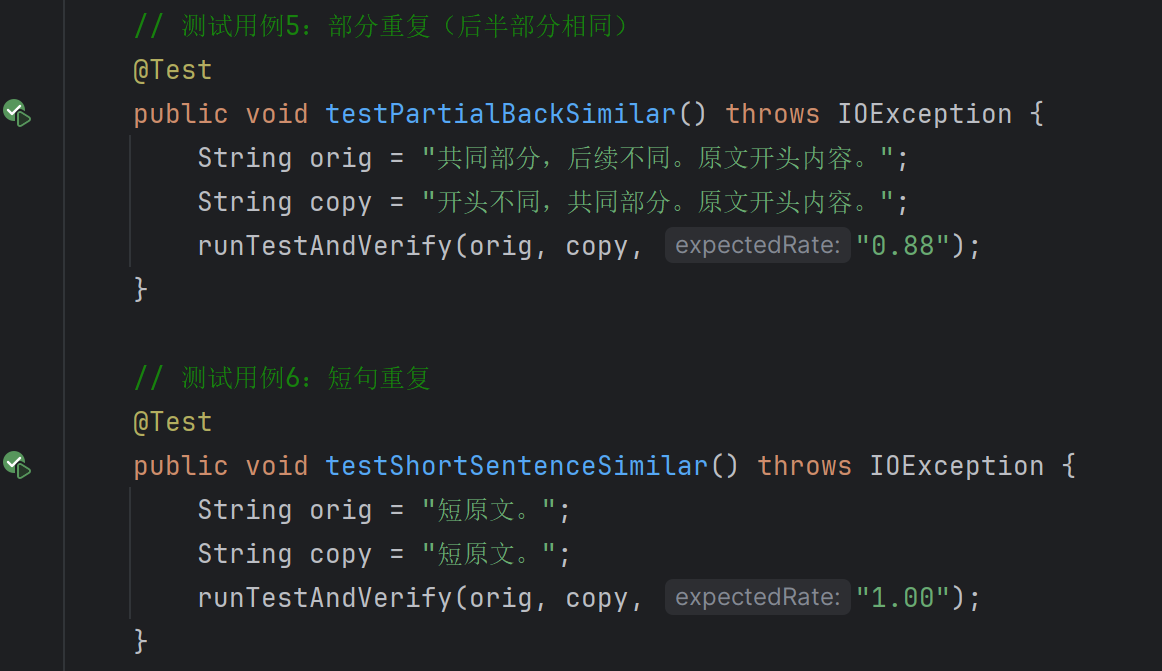
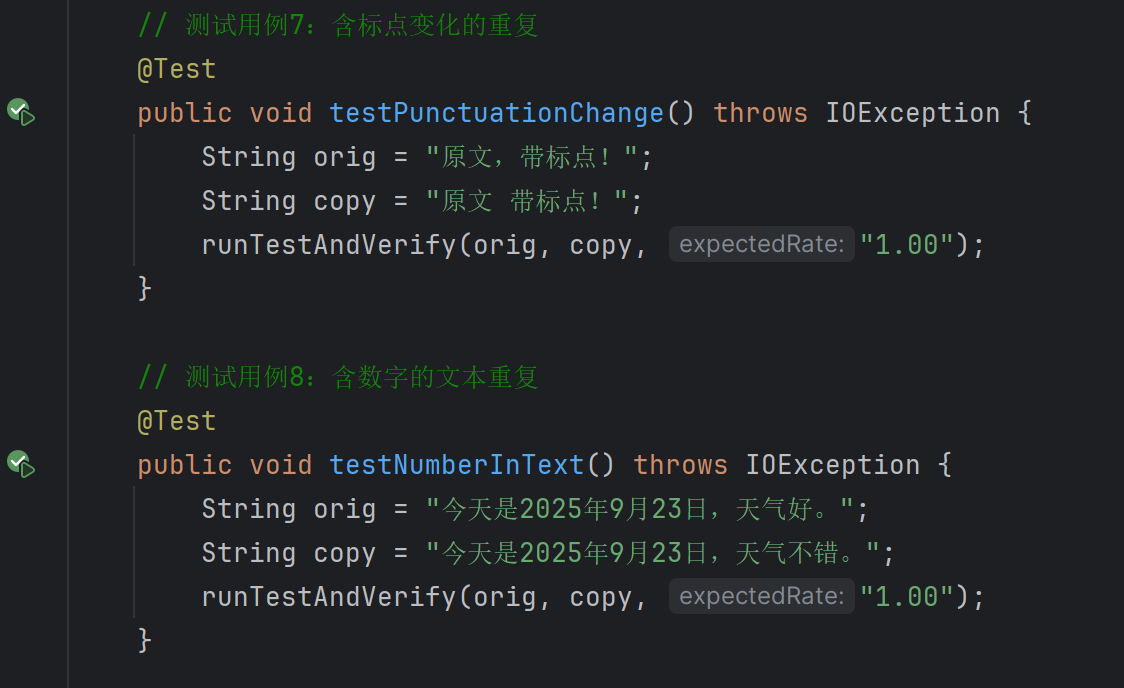
五、单元测试
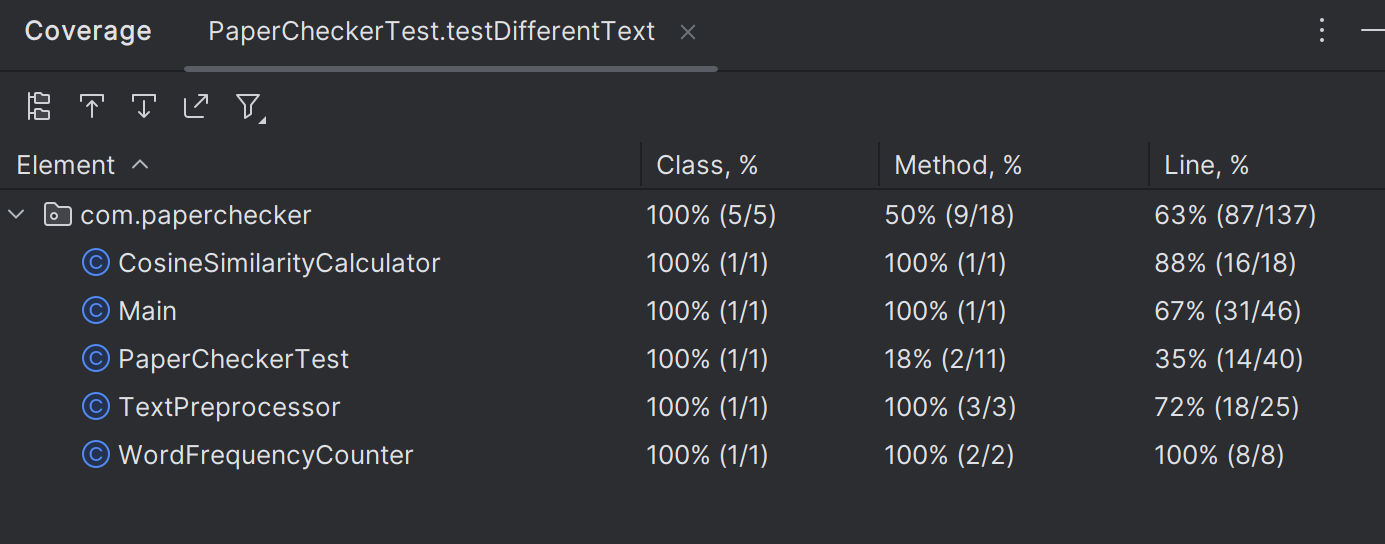
六、测试覆盖率
-
- 类覆盖率(Class, %)
所有类(CosineSimilarityCalculator、Main、PaperCheckerTest、TextPreprocessor、WordFrequencyCounter)的类覆盖率都是 100%,每个类都至少有部分代码被单元测试执行到了。
- 类覆盖率(Class, %)
-
- 方法覆盖率(Method, %)
CosineSimilarityCalculator、TextPreprocessor、WordFrequencyCounter 的方法覆盖率为 100%,说明这些类中的所有方法都被单元测试调用过。
Main 的方法覆盖率为 100%,表示 Main 类里的方法(主要是 main 方法)被测试执行。
PaperCheckerTest 的方法覆盖率为 18%,只有部分被参与到此次针对 testDifferentText 等测试的覆盖率统计中。
- 方法覆盖率(Method, %)
-
- 行覆盖率(Line, %)
CosineSimilarityCalculator 行覆盖率 88%:该类中有部分代码行未被单元测试执行到。
Main 行覆盖率 67%:Main 类里有大约三分之一的代码行未被测试覆盖,比如参数校验、文件不存在等异常分支场景。
PaperCheckerTest 行覆盖率 35%:测试类本身的代码行只有部分被执行,符合测试类的特性。
TextPreprocessor 行覆盖率 72%:文本预处理类有部分代码行未被测试覆盖。
WordFrequencyCounter 行覆盖率 100%:该类的所有代码行都被单元测试执行过,测试覆盖充分。
- 行覆盖率(Line, %)
- 总结与改进
优势:核心业务类(如词频统计、余弦相似度计算)的方法和行覆盖较为充分,确保了基础逻辑的正确性。
待改进点:Main、CosineSimilarityCalculator、TextPreprocessor 存在未覆盖的代码行,可以补充测试用例,覆盖以下场景:
Main:测试文件不存在、路径非法等异常输入的分支逻辑。
CosineSimilarityCalculator:测试向量模长为 0、词汇表为空等边界情况。
TextPreprocessor:测试含特殊字符、混合中英文等复杂文本的预处理逻辑。
七、计算模块部分异常处理说明
- TextPreprocessor 类异常处理
- 文件读取异常(IOException)
设计目标:确保当原文或抄袭文件由于路径错误、文件损坏、无读取权限等原因无法读取时,程序能及时感知并给出明确提示,避免程序因文件读取失败而无意义地继续执行后续步骤。
处理方式:在 readFile 方法中,使用 try-catch 捕获 IOException,当捕获到该异常时,会在控制台输出 “文件操作错误:[具体错误信息]”,让用户能快速定位到文件读取方面的问题。
- Main 类异常处理
- 命令行参数数量异常
设计目标:保证程序能按照预期的参数格式运行,防止因参数数量错误导致后续文件路径解析等操作出现混乱。
处理方式:在 main 方法开始,检查 args 数组长度,若不等于 3,输出正确的参数使用方法提示,并以状态码 1 退出程序,引导用户正确输入命令行参数。 - 文件存在性异常
设计目标:提前验证原文和抄袭文件是否存在,避免在后续读取文件内容时才发现文件不存在,减少无效的程序执行流程。
处理方式:分别检查原文文件和抄袭文件的存在性,若文件不存在,输出对应的 “文件不存在” 提示信息,并以状态码 2 退出程序,使用户能及时修正文件路径。 - 通用程序运行异常(Exception)
设计目标:捕获程序运行过程中可能出现的各种未预见的异常,如分词过程中 HanLP 内部的异常、集合操作时的异常等,防止程序因未处理的异常而崩溃,同时能输出异常信息,便于开发者调试。
处理方式:使用 catch (Exception e) 捕获所有异常,输出 “程序运行错误:[具体错误信息]”,打印异常堆栈跟踪,为问题排查提供详细的异常线索。
八、课堂下发文件测试情况

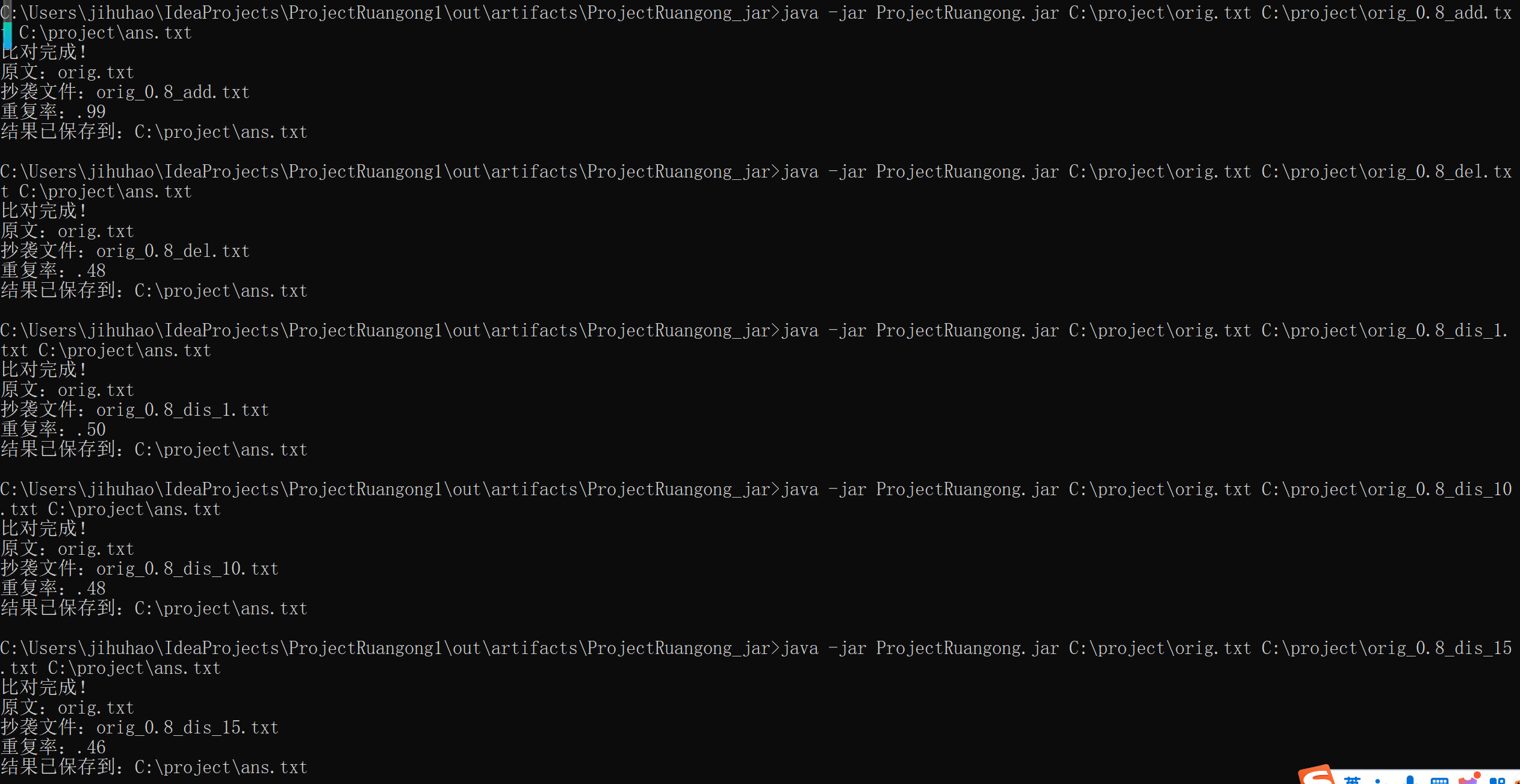

测试情况良好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号