

PPAL基于OPENMMlab平台,深度高级包装
❀ 目的是将PPAL中的核心主动学习代码挖出来运用
先学习了OpenMMlab这个平台,比较难顶
原来是做目标检测的转化为分类
❀ 加油
--将PPAL的主动学习核心置换到CLUE上
。
❀ PPAL 不确定性和多样性采样的核心 run_sl_coco.py的逻辑
传参 导入 from mmdet. import ...
import argparse
cfg = Config.fromfile
def get_start_round 判断从那个轮次开始
实例化不确定性采样和多样性采样
uncertainty_sampler = builder_al_sampler(cfg.uncertainty_sampler_config)
diversity_sampler = builder_al_sampler(cfg.diversity_sampler_config)
def round 主要的 训练、评估、推理和主动学习的完整管道
❀ B站113个视频 每个10分钟
Gra-CAM很好用 一个模型 一张训练图片 不同类别在图上的注意力可以被画出。
也是可解释性的一个很好的解释。
还可以从图像中看出有偏无偏的差异。(护士医生 论文链接https://arxiv.org/pdf/1610.02391
比如从轴承数据角度去分析哪里是注意力,这不就是领域知识内嵌
❀ B站这个视频更关注于神经网络底层 比如拼接cat 层数 特征 这类论文也是我之前很少涉猎的 应该多练。
我现在仔细读懂其代码,然后将其核心主动学习代码换入CLUE中。加油!
2/19
openmmlab视频教学 也侧重于底层神经网络的实现 比如层数 特征cat 这些都是我之前没有涉及的 应该补全
2025/3/11
你在担心什么啊 关注当下 把这篇论文的代码写出来! 以后一篇一篇积累。
2025/3/12
vscode远程连接 调试成功 明天看下具体的流程 就是uncertainty diversity 的过程,开始换程序!
明天要看一下 采样的用到的是哪个特征做后续 相当于我要把什么连在什么上面
2025/3/20
PPAL两阶段 第一阶段和第二阶段怎么连接 第一阶段筛选多少点给第二阶段
对生的那种渴望 无比强烈
年轻人 要有咬定青山不放松的精神
random函数需要置换 怎么换来着???忘记记录了 搞定了
2025/3/27
train_command
'python -m torch.distributed.launch --nproc_per_node=1 --master_port=12345
tools/train.py
configs/coco_active_learning/al_train/retinanet_26e.py
--work-dir work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1
--launcher pytorch
--cfg-options labeled_data=work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/annotations/labeled.json
unlabeled_data=work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/annotations/unlabeled.json
data.train.ann_file=work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/annotations/labeled.json'
eval_command
eval_command
'python -m torch.distributed.launch --nproc_per_node=1 --master_port=12345
tools/test.py configs/coco_active_learning/al_train/retinanet_26e.py
work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/latest.pth -
-work-dir work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1
--launcher pytorch --eval bbox --eval-option "classwise=True" > work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/eval.txt'
unlabeled_infer_command
unlabeled_infer_command
'python -m torch.distributed.launch --nproc_per_node=1
--master_port=12345
tools/test.py
configs/coco_active_learning/al_inference/retinanet_uncertainty.py
work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/latest.pth
--work-dir work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1
--launcher pytorch --format-only --eval-options "jsonfile_prefix=work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/unlabeled_inference_result"
--cfg-options unlabeled_data=work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/annotations/unlabeled.json
data.test.ann_file=work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/annotations/unlabeled.json'
diversity_infer_command
'python -m torch.distributed.launch --nproc_per_node=1 --master_port=12345
tools/test.py
configs/coco_active_learning/al_inference/retinanet_diversity.py
work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/latest.pth --work-dir work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1
--launcher pytorch --format-only --eval-options "jsonfile_prefix=work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/diversity_inference_result" --cfg-options unlabeled_data=work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/annotations/uncertainty_new_labeled.json data.test.ann_file=work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/annotations/uncertainty_new_labeled.json model.bbox_head.total_images=9461 model.bbox_head.output_path="work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/image_dis.npy" '
after training command
你的 train.py 代码的训练部分发生在:
模型构建:build_detector(cfg.model, train_cfg, test_cfg)
数据集构建:build_dataset(cfg.data.train)
调用 train_detector:真正的训练在 train_detector 内进行。
可见training阶段是没有主动学习采样的!!
❀❀然后eval_command主要是在single_gpu_test函数,我看了下,也没有主动学习步骤!!那么就应该在后续的unlabelled_infer_command eval跑完了 如下
❀❀ 跳过了unlabelled_infer_command ,然后开始diversity_infer_command
warnings.warn(
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 9461/9461, 16.4 task/s, elapsed: 577s, ETA: 0s----> Inference on diversity data time: 0:10:16
❀❀
然后开始diversity_sampler
进入到k_centroid_greedy这个函数 获得2365个中心点
====这次运行又运行unlabeled_infer_command
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 115922/115922, 13.9 task/s, elapsed: 8356s, ETA: 0s----> Inference on unlabeled data time: 2:30:28
然后不确定性筛选样本
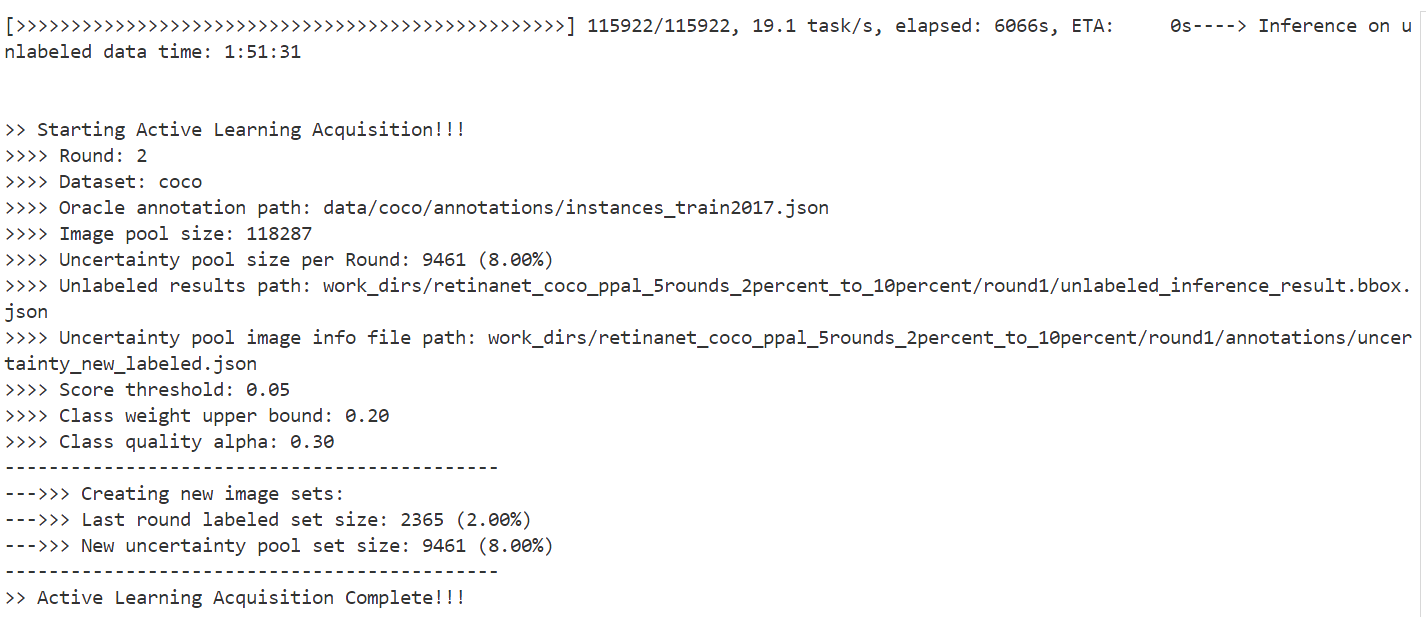
Starting uncertainty Active Learning Acquisition!!!
Round: 2
Dataset: coco
Oracle annotation path: data/coco/annotations/instances_train2017.json
Image pool size: 118287
Uncertainty pool size per Round: 9461 (8.00%)
Unlabeled results path: work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/unlabeled_inference_result.bbox.json
Uncertainty pool image info file path: work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/annotations/uncertainty_new_labeled.json
Score threshold: 0.05
Class weight upper bound: 0.20
Class quality alpha: 0.30
--->>> Creating new image sets:
--->>> Last round labeled set size: 2365 (2.00%)
--->>> New uncertainty pool set size: 9461 (8.00%)
Active Learning uncertainty Acquisition Complete!!!
然后开始运行diversity_infer_command
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 9461/9461, 15.9 task/s, elapsed: 597s, ETA: 0s----> Inference on diversity data time: 0:10:36
按理说应该运行diversity_sampler.
Starting Active diversity Learning Acquisition!!!
Round: 2
Dataset: coco
Oracle annotation Path: data/coco/annotations/instances_train2017.json
Image pool size: 118287
Sampled images per round: 2365 (2.00%)
Unlabeled results path: work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/unlabeled_inference_result.bbox.json
Image distance cache: work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/image_dis.npy
Output label file path: work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/annotations/new_labeled.json
Output unlabeled image info path: work_dirs/retinanet_coco_ppal_5rounds_2percent_to_10percent/round1/annotations/new_unlabeled.json
--->>> Creating new image sets:
--->>> Last round labeled set size: 2365 (2.00%)
--->>> New labeled set size: 4730 (4.00%)
--->>> New unlabeled set size: 113557 (96.00%)
Active diversity Learning Acquisition Complete!!!
然后又training,这应该是更新完数据集
==============现在问题来了 到底两种采样是怎么顺序
==========================我把这个运行到diversity_sampler.py和difficulty_calibrated_uncertainty_sampler.py的痕迹改了 这次能分辨出来了。
目前卡在了三个command对应的头RetinaHeadFeat,RetinaQualityEMAHead,RetinaHeadUncertainty和两种采样 是怎么个流程和对应文章中的公式
周一咖啡馆人好少啊 很安静 希望我的内心更平静一些
❀❀我现在励志将CLUE中active learning 再多一个 PPAL //一定要做到!
看下PPAL主调用程序的逻辑。
run(计数)和run_num(一共多少轮)是什么关系?
1闭门不出,自己静静。2自己刷手机。3躺着乱想 这三点是看似放松实则反刍加重焦虑
4/11我在用源码安装mmcv在自己的电脑上,省点钱
每次发现什么比较困难想要绕过去会发现,根本绕不过去。根本绕不过去=
我现在安装个cuda11.3的系统的吧
4/14 吃了早饭 我整理一下 问题是什么 然后问下闲鱼
好了 放弃在电脑上安装PPAL了 因为PPAL要求cuda是1.1X我的是1.21这样的话,就是太麻烦了。本机的其他虚拟环境就都用不了了。 还是用autodl吧!
那么就继续在autodl上运行 看一看
倾向于到一个好的地方 资源充足的地方做事。在原来那个地方 倒了血霉了。可以控制每天自己这个系统的输入。能让我快乐的两件事 1是学习 2是旅行 3是回馈自己喜欢的人。
4/19 大姨妈
4/20 开始干活 了解hook在openmmlab中的应用 这样就能分清uncertainty diversity 的先后顺序
4/21 干活要Sadi 要实现目标 什么目标 要能把这个程序换上啊! 今天自己写一个hook函数
4/24 感觉遇到了瓶颈 openmmlab也学了 还是不会移代码
4/25 把代码越看越薄!
5/2 每天早上都要思考一下 九点开门太煎熬了!
5/4 终于明白了 整个PPAL流程!train部分都有标签分为A val部分没有标签为B。A里面先取出小部分A1带标签训练模型M0,剩余A2。M0在B上验证。M0在A2推理,用uncetainty sampler采样其中一部分A21。A21使用diversuty sampler采样其中A211.将A211取标签加入A1。获得新的A1',剩余A2'。
开始round=2.....A1'训练M1 M1在A2'推理.....
循环往至
下一步就是把这个想法迁移到CLUE上去。
5/6争取今天搞完!这个迁移!
5/11 找到了应该在哪迁移 迁移哪个函数了 我想比较下 ChatGPT和我编程 哪个更快 哈哈
还是以GPT为基础块 然后缝接的有问题 明天再检查下 问题在哪......
那时候在尚超老师那边编程好愁啊 现在感觉 你全面理解了 就一点点debug就行
5/12 今天完成类别质量计算 算完了。 还要注意一下主动学习中不确定性到多样性,编号要变化。。。。
5/13 今天继续把PPAL sampling statragy 放到CLUE代码中。找到自习室这件事非常棒。但是我理解这些算法通过编程,好慢啊。也有可能是我没熟练 嗯嗯
5/15 搬到了隔壁的公寓,又是元气满满的一天!今天把核心代码换完!
5/20 有点迷失自我了 赶紧换完程序呀
5/22 做个PPT 将我的主动学习阐述以下
5/28 换完了 感觉效果不佳 怎么办?还是继续做下去吧 再研究研究。。
5/30 今天研究下结果为啥不好
6/1 分析下参数 感觉得换个数据集了 部署下cursor
6/4 爸爸生病 然后又玩了两天狼人杀。 根据GPT的指示换个数据吧 把能尝试的都尝试一遍 大量的记录自己记录自己!!
6/10 从珠海回来 吸取了很多创新点 哎呀 早能有这样交流的途径就好了 现在应该怎么办 自己呆着又很焦虑6
6/12 大姨妈停了一天 今天学会cursor
6/18 换数据集 我先把参数换一下
6/20 验证是否具有显著性 然后换数据集 就按照AAAI2025那篇论文的数据集验证吧
6/21 增加budget试试 方法优越性能不能体现 换数据!
6/22 换SVHN-》mnist时候数据维度无法对齐的问题 ,应该是通道的问题
6/23 继续换数据集 使用svhn->mnist 然后网络是一通道的 是先将svhn降为灰度图 斥巨资 在autodl上买了H800 试试速度能差多少 这可是13块钱小时啊!
6/27 继续换DomainNetDataset数据集,将real->sketch换上。然后再跑一下
6/30 继续换DomainNetDataset数据集,将real->Clipart(easy 是通过transfer accuracy体现的)换上。然后再跑一下
上午在H800上面跑一下 H800太贵了
7/1 DomainNetDataset数据集开始跑了 现在起要增加理解了 增加理解才能分析出来 嘻嘻 我要再看一遍CLUE
7/2 怎么使用不同文件夹下的yml差异如此之大?我要看看区别在哪 参数设置? 今天再把CLUE AADA 看一下 2025顶会的也看一下
超参数作用记录表
7/3 本来我的方法在轴承还小有优势 怎么在DomainNet这么垃圾???是不是超参数啥的不行 我看看 开始跑了 我再看看AADA CLUE这两篇
7/5 DomainNetDataset数据集基本跑出来了 但是很慢 基本4090能同时跑3个终端,
得跑一天呢 这么慢 PPAL在第一梯队 但是不是sota 我理解了这个setting 是不是就能整出新的
7/6 看懂BearLLM 换轴承数据集 换上!!就别先读懂再换 先跑起来再说 这里面自己构造了数据集Hugging Face这个大模型社区
7/8 clue-mme 比ppal-mme高0.4 继续跑DomainNet badge-mme被killed因为太慢了
7/15 今天把easy模式real->clipart实验收集好了。下面要进行hard模式clipart->quickraw 这个实验跑出来(解决了一个小问题 几次报错都是因为数据的问题 再报错就换clean dataset)
7/18 换其他轴承数据集!!!
BearLLM有几个大模型的概念我得弄懂~
7/22 我感觉学是没有用的 我得有目标 具体用才行 直接把BearLLM看懂 换里面的数据集
7/23 跑懂BearLLM 换里面的数据集 cliparttoquickdraw实验结果有一些问题
8/6
8/10 继续学transformer 死脑 快学
8/13 腾表格时候发现 我浮现算法的时候 都是前期精度低于原始的3.4个点 后面几乎一样 人家说的是10次平均 我做的是3次平均 这有什么问题?能是这个原因?
8/16 我靠玩了两天狼人杀 天杀的
8/18 bearing三组实验数据曲线比较抖 是不是因为一次性采样样本数比较少导致的 我也在Domainnet上测试下试一试 对的!你少你也抖!CWRU48k-->CWRU12K跑完了 接下来要跑其他两个
8/20 感觉一个CWRU里面不同频率 不同转速的 不行啊 做不了迁移 做主动学习还行 所以还是得是不同轴承的 属于不同工况
要不要主动学习采样变为0 只看迁移?
为什么轴承抖成狗 域适应时候训练epoch变大 变成100 能好一点 但不多 说明就不需要这么多样本被采样 后期都过拟合了啊!! 就别1采样这么多样本!
能量主动学习域适应 我用上试一试 不行啊 怎么在DomainnetC-->Q上才8.几 说不定是完全没有做过主动学习 再看下 代码读透了 跑上了 目前看起来不是特别差劲 但也很慢 竟然比CLUE还慢 等等看结果 希望好一些 那我就放到代码里 哈哈 也不行啊
我的感悟 不要去强求 复现的一模一样
9/15 再把Transferable-Query-Selection复现一下 龙明盛老师组的代码就是简洁
9/18解决了直接transfer和ft下适配后结果不一样的问题 是测试数据变换的时候带有随机性
看懂了打印出来的各个loss 参数“full”“classifier”
提出了目前所有DA都负迁移吗在轴承上的疑问 那样ADA这个就做不下去了
还是继续将Transfer-Query EADA继续换在CLUE上
9/19 把几个AL方法换了,到了调超参的时候了
10/18 DANN 和MME的区别就是
DANN 有监督损失 (src_s tgt_s)/ 经过GRL后计算domain classifier 的domain loss(src_s tgt_u)/ 经过计算一个target domain的熵最小losss(tgt_u)
MME 有监督损失 (src_s tgt_s)/ /经过GRL 计算一个target domain的熵最大(tgt_u )
原始DANN epoch: 99, accuracy of the MNIST dataset: 0.982400 epoch: 99, accuracy of the mnist_m dataset: 0.890901
