【Python爬虫】: Scrapy工程的创建和使用(爬取糗图百科)
一.创建一个Scrapy工程
首先我们创建一个名为project_name的scrapy工程:
scrapy startproject project_name
在子目录下生成一个名为first的爬虫文件:
(base) F:\computer\scrapy_learn>scrapy genspider first www.xxx.com Created spider 'first' using template 'basic'
执行工程(生成爬虫文件之后才可以执行工程):
scrapy crawl spiderName(创建爬虫文件的那个名字,这里应该写为刚才的first)
现在我们依靠刚才创建的scrapy文件来爬取网站,并进行数据解析!
二.小试牛刀:使用Scrapy爬取糗图百科
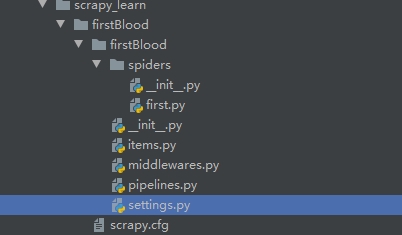
我们创建的Srapy工程目录如下:
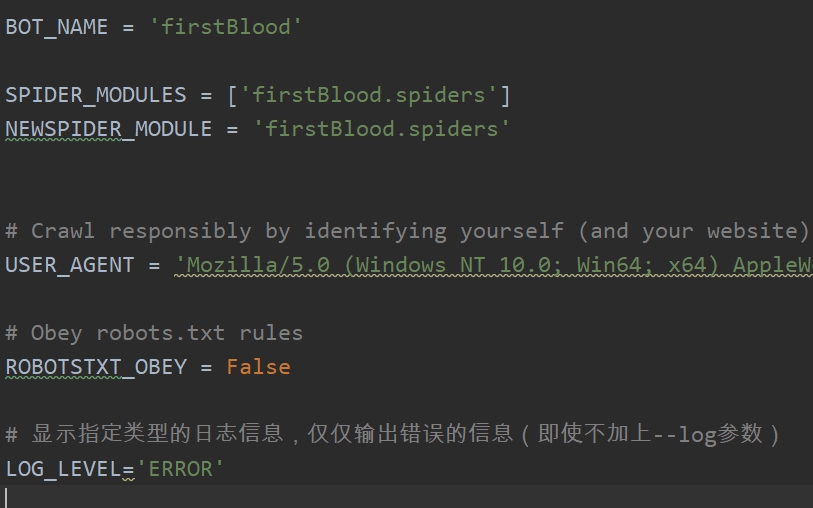
为了能够开始爬取数据,我们需要更改setting文件当中的一些配置,我们需要更改的有:
- User-Agent:更改成你的chrom浏览器的名称
- ROBOTSTXT_OBEY:更改为Flase,如果遵循robots协议,保留为原来的TRUE,则很多数据无法抓取
- LOG_LEVEL:增加LOG_LEVEL参数,并修改为‘ERROR’,这样就可以在爬取数据最后的数据解析当中,只输出错误的信息,而不输出没用的日志信息
修改后的settings.py的代码如下所示:
同时修改first.py文件,在parse处对数据进行解析,在__init__处配置参数,最后的代码如下所示:
import scrapy class FirstSpider(scrapy.Spider): #爬虫文件的名称:爬虫源文件的一个唯一标识 name = 'first' #允许的域名:用来限定start_urls列表中哪些url可以进行请求发送 #allowed_domains = ['www.baidu.com'] #起始的url列表:该列表当中存放的url会被scrapy自动发送请求 start_urls = ['https://www.qiushibaike.com/text/'] #用来进行数据解析的:response参数标的是请求成功后对应的响应对象 def parse(self, response): #start_urls里面有多少个url。就调用这个方法多少次 author=response.xpath('//div[@id="content"]//h2/text()').extract() content=response.xpath('//div[@id="content"]//div[@class="content"]/span/text()').extract() for i in author: print(i) break for i in content: print(i) break
在命令行输入:
scrapy crawl first
输出:
净心居士
胖丫把自己打扮的从来没有漂亮,说要和闺蜜逛街去。我想她闺蜜又不是不认识,又吃饭又可以AAB了。
代码思路解析:
- 首先配置爬虫的文件名为'first'
- 配置我们需要爬取的网站url
- 查看网站源代码,确定使用xpath的表达式是什么(这里发现所有的内容和作者名称均在id="content"这个div块级元素下,然后写好scrapy自带的xpath表达式,类似于lxml的etree进行导入,得到selector对象,使用extract函数可以将selector对象当中的data,也就是实际文字当中的字符串)如下所示:

4.我们仅仅打印其中的一作者和其content,这样整个糗图百科的笑话就被我们爬取下来啦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号