

[CVPR2025] MambaVision: A Hybrid Mamba-Transformer Vision Backbone 一种混合Mamba-Transformer视觉主干
[CVPR2025] MambaVision: A Hybrid Mamba-Transformer Vision Backbone
一句话介绍:
1-1:一种专门为视觉应用量身定做的新型混合Mamba-Transformer骨干网MambaVision;
1-2:核心贡献:1)重新设计Mamba公式,以增强其高效建模视觉特征的能力。2)通过一个ablation study 消融实验,论证了将Vision Trans-formers (ViT) 和 Mamba相结合的可行性。
1-3) idea:
- 原Mamba的核心贡献是一种新颖的选择机制,它能够在硬件感知的情况下对长序列进行高效的输入相关处理;
- 然而,Mamba的自回归公式虽然对需要顺序数据处理的任务有效,但在受益于完整感受野的计算机视觉任务中面临限制:
- (1) 与顺序重要的序列不同,图像像素不以同样的方式具有顺序依赖性。相反,空间关系往往是局部的,需要以更并行和更综合的方式加以考虑。因此,这导致处理空间数据的效率低下;
- (2) 像MAMBA这样的自回归模型逐步地处理数据,限制了其在一次前向传递中捕获和利用全局上下文的能力。相比之下,视觉任务往往需要了解全局背景,才能对局部地区做出准确的预测。
1-4:结果表明:在Mamba体系结构的最后一层配备自我注意块大大提高了其捕获长范围空间依赖的能力。
- MambaVision在ImageNet-1K上实现了SOTA的帕累托前沿,在准确率和吞吐量方面均优于纯Transformer、CNN以及基于Mamba的模型。如在ImageNet-1K上,MambaVision-B达到84.2%准确率,同时吞吐量显著高于可比模型。
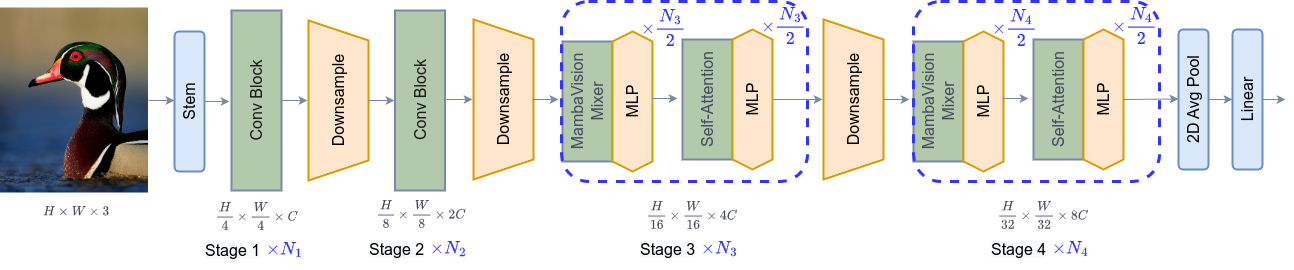
基于这些发现,我们引入了一系列具有分层体系结构的MambaVision模型[见下图],以满足各种设计标准。
- 前两个阶段采用残差卷积块实现快速特征提取;
- 第三和第四阶段则同时使用MambaVision模块与Transformer模块。
- 末层的Transformer模块能够恢复丢失的全局上下文信息,并捕获长程空间依赖关系。
1-5:数据集DATASET:
-
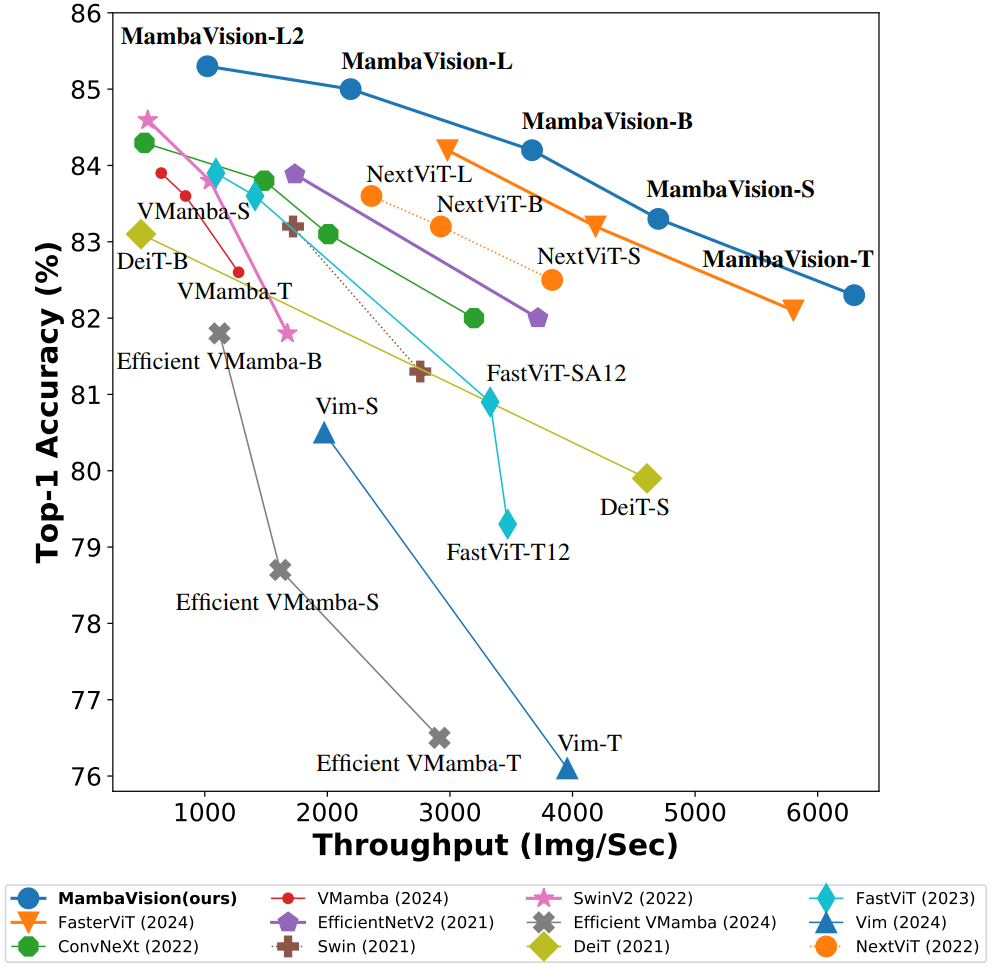
1)[见下图] 对于ImageNet-1K数据集的分类,MambaVision变体在精确度和吞吐量方面都达到了最先进的(SOTA)性能。
-
2)在MS Coco和ADE20K数据集上的对象检测、实例分割和语义分割等下游任务中,MambaVision在表现出良好性能的同时,超越了同等规模的主干网络。
具体工作
1)系统地重新设计了Mamba块,使其更适合视觉任务。
2)提出了一种混合体系结构,它由我们提出的公式(即MambaVision Mixer和MLP)以及Transformer块组成。
具体地说,我们研究了不同的集成模式,比如以等参数的方式将变压器块添加到早期层、中间层、最终层以及每一层L。
3)介绍了MambaVision模型,该模型由多分辨率结构组成,并利用基于CNN的残差块来快速提取更大分辨率的特征。
ABLATION study
1)此基准配置在所有指标上都达到了不太理想的性能,ImageNet Top-1准确率为80.9%(-1.8%),MS Coco box AP为44.8(-1.6),掩码AP为40.2(-1.6),ADE20K Miou为44.2%(-1.4)。
2)然后,我们将SSM分支(Vv1)中的因果卷积替换为规则卷积层,这提高了所有指标的性能。
3)随后,我们在保持Mamba原有的选通机制而不是级联的同时增加了Conv2层,结果ImageNet Top-1的准确率为81.3%,MS Coco box AP为45.3,MASK AP为41.0,ADE20K MIUU为45.7%。
4)最后,实现串联(concat)导致了所有指标均大幅提升,对于MS CoCo,ImageNet Top-1的收益为+1.0%,Box AP和MASK AP的收益分别为+1.1和+0.8,对于ADE20K,MIUU的收益为+0.9%。这些结果验证了我们的假设,即连接两个分支(SSM和非SSM)的输出使模型能够学习更丰富的特征表示,并增强全局上下文理解。
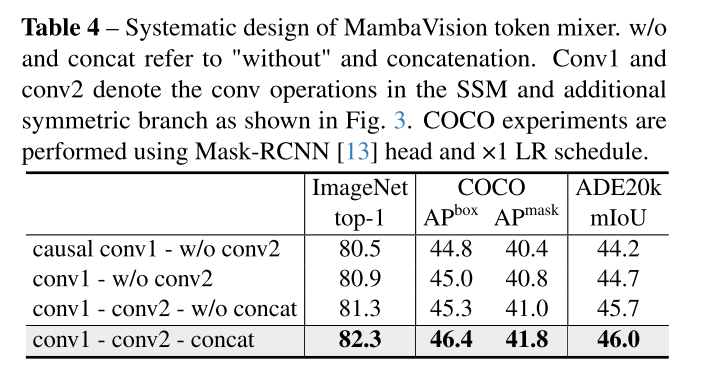
表4 “Systematic design of MambaVision token mixer”
论文中对Token Mixer微观设计的消融实验。该表系统性地比较了不同Token Mixer设计变体在多项任务上的性能,以验证MambaVision块重新设计的有效性。
- 实验设置:基于MambaVision-T架构(参数量31.8M),在ImageNet-1K分类、MS COCO目标检测/实例分割(使用Mask R-CNN头)和ADE20K语义分割任务上评估。
- 行列结构:
- 行:表示4种渐进式设计变体:
- 基线:使用原始Mamba的因果卷积(causal conv1)+ 无对称分支(w/o conv2)。
- 变体1:将因果卷积替换为常规卷积(conv1)+ 无对称分支(w/o conv2)。
- 变体2:添加对称分支(conv2),但保留原始门控机制(w/o concat)。
- 最终设计:使用常规卷积和对称分支,并通过连接(concat)融合输出。
- 列:性能指标,包括ImageNet Top-1准确率(%)、COCO的框AP(APbox)和掩码AP(APmask),以及ADE20K的平均交并比(mIoU)。
- 行:表示4种渐进式设计变体:
- 关键结果:
- 从基线到最终设计,所有指标逐步提升:ImageNet Top-1从80.5%升至82.3%,COCO APbox从44.8升至46.4,ADE20K mIoU从44.2%升至46.0%。
- 最终设计(卷积+分支+连接)提升最显著,证明对称分支能补偿SSM的序列约束损失,增强特征丰富性和全局上下文捕获。
表4是典型的组件级消融实验,通过控制变量法验证每个微观改进(如卷积类型、分支添加)的贡献。
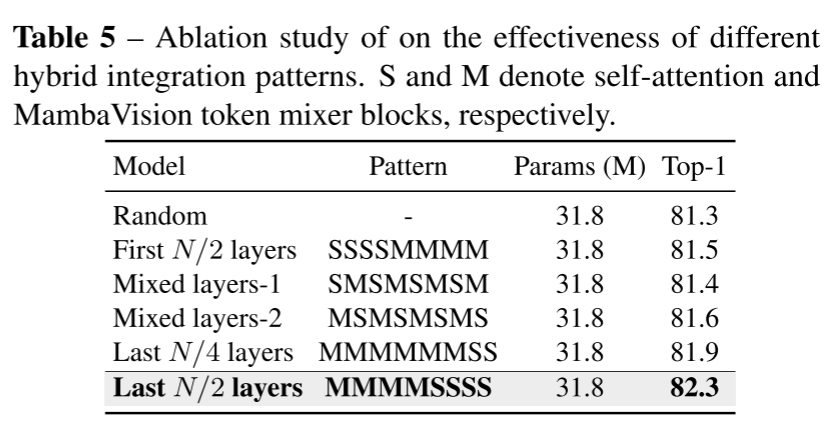
表5 “Ablation study on the effectiveness of different hybrid integration patterns”
进一步的优化发现,将自我注意扩展到每个阶段的最后N/2层的效果最好,达到82.3%,这表明仔细平衡自我注意块和MambaVision层对于最佳表征学习的重要性。
聚焦于Mamba与Transformer块的宏观集成模式消融。该实验探讨如何最佳组合MambaVision混合器(M)和自注意力块(S),以优化架构效率。
- 实验设置:同样基于MambaVision-T(参数量31.8M),在ImageNet-1K上评估Top-1准确率。所有变体保持等参数(31.8M),仅改变Stage 3和4中M和S块的排列顺序。
- 行列结构:
- 行:表示6种集成模式:
- 随机排列(Random)。
- 前N/2层为S,后N/2层为M(SSSSMMMM)。
- 交替模式1(SMSMSMSM)。
- 交替模式2(MSMSMSMS)。
- 最后N/4层为S(MMMMMMSS)。
- 最后N/2层为S(MMMMSSSS)—最优模式。
- 列:包括模式描述、参数量(M)和Top-1准确率(%)。
- 行:表示6种集成模式:
- 关键结果:
- 随机模式性能最差(81.3%),表明任意集成无效。
- 最后N/2层用S块的模式最佳(82.3%),说明自注意力在模型后期能有效捕获长程依赖。
- 最后N/4层用S块也有较好表现(81.9%),但不如N/2层完整。
表5是系统级消融实验,重点研究模块排列对全局上下文建模的影响。
消融结果支持:附录G的表S.1显示,窗口大小组合为14和7时,MambaVision-T在ImageNet Top-1准确率(82.3%)和COCO任务性能上最优,吞吐量仅下降0.3%(6298 img/s vs. 6318 img/s),证明该选择在精度与效率间达到Pareto最优。
Table 4 vs Table 5
| 对比维度 | 表4 | 表5 |
|---|---|---|
| 实验焦点 | 微观架构(Token Mixer内部组件设计) | 宏观集成(Mamba与Transformer块排列模式) |
| 优化层级 | 组件级优化 | 系统级优化 |
| 核心验证目标 | 重新设计Mamba块对视觉任务的适用性 | 混合架构中自注意力模块的最优位置 |
| 任务范围 | 多任务评估:• 图像分类• 目标检测• 语义分割 | 单任务评估:• ImageNet分类任务 |
| 解决的核心问题 | 如何改进Mamba块本身 | 如何最佳组合Mamba和Transformer块 |
| 实验性质 | 消融Token Mixer内部组件 | 消融混合架构的模块排列策略 |
| 互补性 | 证明Token Mixer重设计的必要性(微观) | 确定混合架构最优模式(宏观) |
未来启示
-
首个成功将Mamba扩展到ImageNet-21K的视觉架构,MambaVision证明了基于SSM的模型在大规模视觉任务中的潜力,将鼓励更多研究者探索Mamba在视觉领域的应用。
-
MambaVision的成功为"SSM+注意力"混合架构设计提供了可行性证明,未来可能出现更多结合不同序列建模机制的混合模型,推动视觉骨干网络的多样化发展。
BONUS
1-ablation study 消融实验:
Ablate”一词源自医学/生物学,意为“切除、移除”。在研究中,就是**“切除”模型的一部分**,观察功能如何变化。
2- 窗口大小(Window Size)
窗口大小是视觉Transformer中自注意力机制的关键参数,用于控制注意力计算的范围。在标准Transformer中,全局自注意力具有二次计算复杂度,难以处理高分辨率图像。为提升效率,MambaVision采用窗口自注意力,将输入特征图划分为局部窗口,仅在每个窗口内计算注意力,从而降低计算负担。
- 具体定义:窗口大小指定了每个局部窗口的尺寸(如7×7或14×14像素)。例如,窗口大小为7表示将特征图划分为多个7×7的网格,注意力仅在每个网格内进行。
Vision采用窗口自注意力,将输入特征图划分为局部窗口,仅在每个窗口内计算注意力,从而降低计算负担。
- 具体定义:窗口大小指定了每个局部窗口的尺寸(如7×7或14×14像素)。例如,窗口大小为7表示将特征图划分为多个7×7的网格,注意力仅在每个网格内进行。
