
Component-Based Synthesis for Complex APIs ;基于组件的复杂API合成方法
1-1min 概述:
摘要:论文提出了一种基于组件的程序合成方法,使用类型导向的算法和Petri网来表示API组件之间的关系。给定目标方法签名,通过Petri网的可达性分析来合成程序。工具叫SYPET,实验显示它比现有工具更高效。
方法动机:现有组件合成方法只能处理少量组件(5-20个),但真实API有数千个方法;且需要逻辑规范,但API很少正式指定。论文使用类型作为规范的代理,处理大规模API。 方法设计:构建Petri网,其中位置对应类型,变迁对应方法。通过可达性分析找到路径,生成草图,然后用SAT求解器完成草图。包括Petri网构建、可达性分析、草图生成和完成。
对比:与INSYNTH和CODEHINT对比,SYPET能合成更多程序。还对比了基于超图的方法,Petri网更优。 实验:使用多个Java API,从在线论坛和GitHub收集任务。SYPET在30个基准测试中全部成功,平均时间短。 开源:工具叫SYPET,可用。
2-IDEA :
-
1)从“穷举程序结构”到“合并等价行为” ;
-
2)从“行为空间”而非“语法空间”的维度进行剪枝 ;
-
3)使用紧凑的Petri网表示法来对API中的方法之间的关系进行建模;
-
4)我们还将SYPET与INSYNTH和CODEHINT两种最先进的综合工具进行了比较,证明了SYPET可以在更短的时间内综合出更多的程序。
3-方法
1. 自底向上枚举
-
是什么:不从完整的程序开始猜想,而是从最基本的组件(输入参数、常量)开始,逐步将它们组合成越来越大的、有意义的程序片段。
-
怎么做: 基础:初始的片段就是所有的输入参数和常量。 迭代组合:在每一轮,算法尝试将已有的片段,通过调用组件库中的某个API方法进行组合,生成新的、更大的片段。新片段的数据类型由其调用的API的返回值决定。
-
示例:假设有API:
concat(String a, String b) -> String,trim(String s) -> String,输入是String x。 第1轮片段:x(输入) 第2轮:trim(x)(用x调用trim) 第3轮:concat(x, x),concat(x, trim(x)),trim(trim(x))... 如此递推。
2. 行为摘要
-
是什么:这是压缩搜索空间的关键数据结构。它不为每个程序片段存储其具体的语法树(即具体是怎么由哪些子片段调用哪个API组成的),而是存储一个映射表:
输入示例 -> 输出值。 -
为什么:在基于示例的合成中,我们判断一个程序片段是否有用的唯一标准,就是它在给定的输入输出示例上是否表现正确。因此,只要两个片段在所有当前示例上计算结果完全一样,它们对于后续的搜索就是完全等价的、可以互换的。
-
示例:继续上面的例子,假设输入示例
x = " hi "。 片段A:trim(x)-> 计算结果为"hi"片段B:trim(trim(x))-> 计算结果也为"hi"那么,对于这个输入,A和B的行为摘要都是{" hi " -> "hi"}。尽管它们结构不同,但当前行为相同。
3. 等价合并
-
是什么:在自底向上枚举生成新片段时,立即计算它的行为摘要,并检查是否已经存在一个具有完全相同行为摘要的片段。如果存在,就丢弃这个新生成的结构,复用已有的那个片段。
-
效果:这实现了行为空间的“去重”。搜索树不会在“结构不同但行为相同”的分支上继续分裂,而是将所有这些分支收束到同一个行为节点上。这从根本上避免了组合爆炸。
-
示例:接上例。 当算法生成片段B
trim(trim(x))时,会计算其行为摘要{" hi " -> "hi"}。 发现与已有的片段A的行为摘要完全相同。 关键操作:算法不会将B作为一个新的、独立的片段加入待扩展池。相反,它会记录“B这个结构等价于A”。后续所有想用B去组合其他片段的地方,都会直接用A来代替。
4-Petri网
Petri网是一种用于建模并发系统和资源流的形式化工具,由Carl Adam Petri在1962年提出。在论文《Component-Based Synthesis for Complex APIs》中,Petri网被用作核心模型来表示API组件之间的关系,以支持程序合成。以下将基于论文第3节“Primer on Petri Nets”的内容,详细解释Petri网的定义、组成部分和工作原理。
4-1 Petri网的基本定义
根据论文中的Definition 1,一个Petri网是一个五元组 N=(P,T,E,W,M0),其中:
-
P是位置(Places)的集合,用圆圈表示,代表资源或状态(如类型)。
-
T是变迁(Transitions)的集合,用实心条表示,代表事件或操作(如API方法调用)。
-
E⊆(P×T)∪(T×P)是边的集合,连接位置和变迁。
-
W是边的权重函数,指定资源消耗或生产的数量。
-
M0是初始标记(Initial Marking),表示每个位置初始的令牌数量(令牌用点表示,代表资源实例)。
-
![]()
4-2 关键概念与工作原理
-
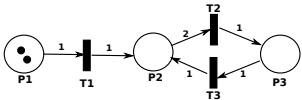
标记(Marking):标记 M是一个从位置到令牌数量的映射。例如,Figure 4的初始标记 M0为 P1↦2,P2↦0,P3↦0,表示P1有2个令牌,其他位置无令牌。
-
变迁触发(Firing Transitions):变迁能否触发取决于其输入位置的令牌是否足够(满足权重条件)。触发后,会消耗输入位置的令牌,并生产输出位置的令牌。例如,Figure 4中的变迁T1需要至少1个P1的令牌(因为边权重为1),触发后消耗1个P1令牌,生产1个P2令牌。
-
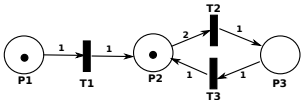
可达性(Reachability):核心问题是判断能否通过一系列变迁触发从初始标记到达目标标记 M∗。例如,如果目标标记是 P1↦0,P2↦0,P3↦1,则序列T1、T1、T2是可行路径。
![]()
-
k-安全性(k-Safety):如果Petri网在任何可达标记中,每个位置的令牌数不超过k,则称为k-安全的。例如,Figure 4的Petri网是2-安全的,因为令牌数最大为2。这对于确保可达性分析终止至关重要。
4-3在论文中的应用
在SYPET方法中,Petri网被特化用于API合成:
-
位置对应类型(如int、String),变迁对应API方法(如getX)。
-
克隆变迁(κ) 允许令牌复制,模拟变量重用(如Figure 6中的κ_D)。
-
通过可达性分析找到方法调用序列,再通过草图完成生成代码。
4-4 petri网 详解
好的,我们来对这篇论文中关于Petri网的核心描述进行一次深入浅出的详细解读。Petri网是这篇论文方法论的心脏,理解它是理解整个合成过程的关键。
一、Petri网是什么?一个直观的比喻
首先,让我们抛开形式化定义,用一个物流仓库的比喻来理解Petri网:
-
仓库货架(Places,位置):存放不同种类的货物(例如,A区放轮胎,B区放发动机)。在论文中,每个“货架”对应一个数据类型,比如
String、Point2D、Area。 -
货物(Tokens,令牌):货架上具体存放的货物数量。一个货架上有3个轮胎,就是有3个令牌。在合成中,令牌代表可用的、该类型的变量或值。初始时,令牌由输入参数提供。
-
装配线(Transitions,变迁):一条生产线,它从特定货架收取原材料(输入),加工后产出成品放到另一个货架(输出)。在论文中,每条“装配线”对应一个 API方法。例如,
getX()方法需要消耗一个Point2D类型的“原材料”,产出一个double类型的“成品”。 -
运输单(Edges & Weights,边和权重):规定了从货架到装配线需要多少原材料,以及成品运往哪个货架。权重就是所需原材料的数量。
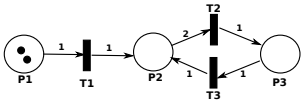
论文中的Figure 4就是一个简单的Petri网示例:
在这个图中:
-
P1, P2, P3 是货架(位置)。
-
T1, T2, T3 是装配线(变迁)。
-
P1货架上的两个点代表有2个令牌。
-
T1装配线需要从P1拿1份原材料(边权重为1),加工后送1份成品到P2。
二、论文如何将API合成问题“翻译”成Petri网问题?
这是论文最核心的洞察。作者将“合成一个程序”的目标,巧妙地映射为“在Petri网中从初始状态到达目标状态”的问题。
-
构建网络:
-
对于API库中的每个方法,都在Petri网中创建一个变迁(Transition)。
-
方法的参数类型成为指向该变迁的输入边,边的权重等于该类型参数的数量。
-
方法的返回类型成为从该变迁指出的输出边,通常权重为1(因为一个方法返回一个值)。
![]()
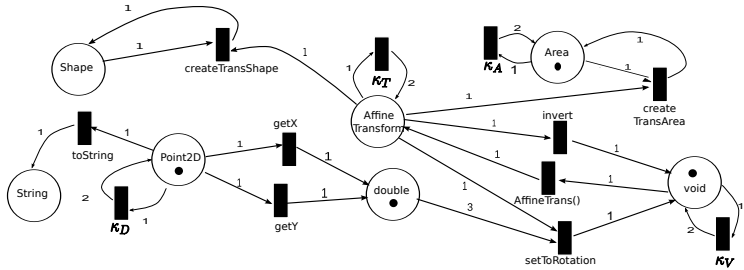
以Figure 6为例,看
getX方法:-
它需要一个
Point2D类型参数(从Point2D位置到getX变迁有一条权重为1的边)。 -
它返回一个
double类型(从getX变迁到double位置有一条边)。
-
-
设定初始与目标状态: 初始标记(Initial Marking):由你要合成的方法的输入参数决定。比如,要合成
rotate(Area obj, Point2D pt, double angle),那么初始状态就在Area,Point2D,double这三个“货架”上各放1个令牌,其他货架为空。 目标标记(Target Marking):由方法的返回类型决定。对于rotate方法,目标状态是在Area货架上放1个令牌,其他所有货架(除void外)都为空。这强制要求合成程序必须消耗掉所有输入并产生预期的输出。
三、关键创新:为什么需要“克隆变迁”?
在普通的编程中,一个变量可以被多次使用。例如,点 pt既可以调用 pt.getX(),也可以调用 pt.getY()。但在基础的Petri网模型中,一个令牌被消耗后就没有了。
为了解决这个矛盾,论文引入了特殊的 克隆变迁(κ)。
-
对于每种类型,都有一个对应的
κ_类型变迁。 -
这个变迁的规则是:消耗1个该类型的令牌,产生2个该类型的令牌。这相当于复制了一个变量。
-
如图Figure 6中的
κ_D,它消耗1个Point2D令牌,产生2个。这样,一个pt变量就可以被复制,分别用于调用getX和getY。
四、从“网络运行”到“程序合成”:可达性分析
现在,合成问题变成了一个规划问题:从初始标记开始,通过触发一系列变迁(包括API方法变迁和克隆变迁),最终能否到达目标标记?如果能,触发的是哪些变迁?
-
寻找路径(可达性分析):算法会搜索一个变迁序列。例如,一个有效的序列可能是:
κ_D(复制Point2D) →getX→getY→new AffineTransform→setToRotation→createTransformedArea。 这个序列的最终结果,就是在Area货架上产生了一个令牌,达到了目标状态。 -
路径到草图(Sketch Generation):找到的变迁序列直接对应了方法调用的顺序。忽略克隆变迁后,我们就得到了一个程序骨架(草图):
#1 = #2.getX(); // 对应 getX #3 = #4.getY(); // 对应 getY #5 = new AffineTransform(); // 对应 new AffineTransform #6.setToRotation(#7, #8, #9); // 对应 setToRotation #10 = #11.createTransformedArea(#12); // 对应 createTransformedArea return #13;
这里的
#1, #2, ...是待填充的“坑”(holes),代表参数应该用哪个变量。 -
填充草图(Sketch Completion):最后,使用SAT求解器来解决这些“坑”的填充问题,约束条件是类型必须匹配且所有变量都必须被使用。最终就能生成如图Figure 3所示的完整、正确的代码。
五、总结:Petri网在此项工作中的巨大优势
| 传统方法(如图搜索) | 论文方法(Petri网) | 优势 |
|---|---|---|
只能处理单输入单输出的方法链(如 a.b().c()) | 能自然建模多参数方法(如 setToRotation(angle, x, y)需要3个输入) | 表达力更强 |
| 难以处理同一个变量的多次使用 | 通过克隆变迁优雅地解决了变量复用问题 | 更贴合命令式编程的语义 |
| 搜索空间容易无限膨胀 | 通过k-安全性等理论工具可以证明搜索空间有界,确保算法终止 | 可扩展性更好 |
总而言之,论文通过Petri网将复杂的程序合成问题,转化为一个具有成熟理论支持和高效算法(如ILP)的“状态可达”问题。这种建模使得合成器能够系统性地、可扩展地探索由成千上万API组件构成的巨大搜索空间,从而实现了对复杂API的自动化编程。
5-demo
我们用一个更复杂的例子,目标是合成一个程序,其功能是“去除字符串首尾空格并在末尾加!”。假设我们的规范是:
-
输入示例:
(“ hello ”) -
输出示例:
(“hello!”)
假设组件库是:{trim(s), concat(s1, s2), exclaim(s)},其中exclaim是我们假设的能加“!”的函数。
搜索过程如下:
-
第0层(基础): 片段
s(输入)。行为摘要:{" hello " -> " hello "} -
第1层(单个API调用): 枚举:
trim(s)-> 计算结果"hello"。摘要:{" hello " -> "hello"}。这是一个新行为,保留。exclaim(s)-> 计算结果" hello !"。摘要:{" hello " -> " hello !"}。新行为,保留。concat(s, s)-> 计算结果" hello hello "。摘要:{...}。新行为,保留。 等价合并:本轮无合并,因为行为都不同。 -
第2层(两个API调用): 枚举:算法会用第0、1层的所有片段作为参数,去尝试调用API。 关键点发生:考虑生成
trim(trim(s))。 计算:trim(trim(s))在输入" hello "上,先内层trim得"hello",再trim得"hello"。 行为摘要:{" hello " -> "hello"}。 合并! 这个摘要与第1层的片段trim(s)完全一致。因此,trim(trim(s))被丢弃。算法内部知道,以后任何需要trim(trim(s))的地方,直接用trim(s)替代即可。 生成exclaim(trim(s)): 计算:trim(s)的结果是"hello",然后exclaim("hello")得"hello!"。 行为摘要:{" hello " -> "hello!"}。 检查规范:这与目标输出完全匹配!合成成功。程序就是exclaim(trim(s))。
如果没有“行为摘要+等价合并”,搜索树会疯狂分支:
-
trim(trim(s)),trim(trim(trim(s)))... 都会被当作全新的、有潜力的片段保留下来,并用它们去生成更复杂的组合(如concat(trim(trim(s)), ...)),导致搜索空间指数级膨胀。 -
而有了这个机制,所有在给定示例上等价于
trim(s)的冗余结构(如trim(trim(...(s)...)))都被压缩为一个节点。搜索的宽度被极大地抑制,算法能更快地向“有本质新行为”的方向探索。
5-2 demo总结
这种方法的本质是一种动态规划:
-
自底向上枚举定义了“状态”的生成顺序(程序大小/深度)。
-
行为摘要定义了“状态”本身(输入输出映射,而非程序文本)。
-
等价合并确保了每个独特的“行为状态”只被计算和扩展一次,避免了重复的子问题求解。
它的巧妙之处在于,它将程序合成的正确性语义(由示例定义)无缝地嵌入到了搜索过程的状态定义中,使得剪枝不仅是语法上的,更是语义上的、与目标强相关的。这正是它能够高效处理复杂API合成的根本原因。
6 什么是API?
论文里,API被简化为类型签名 + 行为示例的组件。API vs 函数签名? 这个API的完整契约:
"""
TemperatureConverter API文档
类: TemperatureConverter
温度转换工具类
方法:
1. celsius_to_fahrenheit(celsius: float) -> float
功能: 摄氏度转华氏度
参数: celsius - 摄氏度温度值
返回: 华氏度温度值
异常: TypeError(输入非数字), ValueError(低于绝对零度)
公式: F = (C × 9/5) + 32
2. fahrenheit_to_celsius(fahrenheit: float) -> float
功能: 华氏度转摄氏度
参数: fahrenheit - 华氏度温度值
返回: 摄氏度温度值
异常: TypeError(输入非数字), ValueError(低于绝对零度)
公式: C = (F - 32) × 5/9
3. convert(value: float, from_unit: str, to_unit: str) -> float
功能: 通用温度转换
参数:
- value: 温度值
- from_unit: 原单位 ('celsius'|'fahrenheit'|'kelvin')
- to_unit: 目标单位 ('celsius'|'fahrenheit'|'kelvin')
返回: 转换后的温度值
异常: ValueError(无效单位)
使用示例:
>>> converter = TemperatureConverter()
>>> converter.celsius_to_fahrenheit(100) # 返回 212.0
>>> converter.convert(0, 'celsius', 'kelvin') # 返回 273.15
"""