
Java Programming 【Chapter 8_QA】
1、如何理解如下代码?
比如:
minCapacity怎么突然冒出来,这是什么?变量多了容易绕进去
另外这个return; 啥也没返回,该如何理解,这样也能行吗?
if (oldCapacity >= minCapacity) { return; }

1. minCapacity 是什么?它怎么冒出来的?
- 来源: minCapacity 是 ensureCapacity 方法的参数,由调用者传入。比如在 add 方法中,ensureCapacity(size + 1) 传入了 size + 1,表示“至少需要容纳当前元素个数加 1”的最小容量。
- 作用: 它是扩容时的一个“需求阈值”。ensureCapacity 的任务是确保数组容量至少达到 minCapacity,如果不够就扩容。
- 为什么会冒出来: 在动态数组中,添加元素时需要检查空间是否足够。size + 1 代表新元素要加入的位置,如果数组长度(oldCapacity)小于这个需求,就得扩容,而 minCapacity 就是这个“需求”的具体值。
- 不绕的思路: 把它想象成一个“最低要求”。比如你有 10 个座位(oldCapacity),但来了 11 个人(minCapacity = size + 1),不够就得加座椅。
2. if (oldCapacity >= minCapacity) { return; } 怎么理解?return 啥也没返回也能行?
- 逻辑: 这段代码检查当前数组长度 oldCapacity 是否大于等于 minCapacity。如果够用,就直接 return,结束方法,不做任何扩容。
- return 啥也没返回: 这里 ensureCapacity 是一个 void 方法(没有返回值),所以 return; 只是表示“方法到此结束,不用再往下执行”。它不像有返回值的函数需要返回具体数据,void 方法的 return 只是个退出信号。
- 为什么能行: 在 Java 中,void 方法可以有 return; 来提前结束执行,这是合法的。意思是“当前条件满足,不需要扩容了,赶紧走人”。如果不满足条件,才会继续执行后面的扩容逻辑。
- 通俗比喻: 就像你去超市买东西,货架上有足够商品(oldCapacity >= minCapacity),你就直接回家(return;);如果不够,才去仓库拿(扩容)。
3. 避免绕进去的建议
- 聚焦核心: minCapacity 是“需求”,oldCapacity 是“现有”,比较两者决定是否扩容。别被变量名吓到,重点看逻辑。
- 逐步拆解: 每次看到新变量,先问“它从哪来?干嘛用?”——minCapacity 从参数来,代表扩容的最小需求。
- 方法作用: ensureCapacity 只是个辅助工具,服务于 add,理解它单独的功能就行。
总结
- minCapacity 是扩容的“目标容量”,由调用者提供,确保数组能装下新元素。
- return; 在 void 方法中是正常退出,没返回值也没问题,意思是“够用就不动”。
2、为什么红框处还必须写上<U, V>?

为什么必须写 <U, V> 在方法名之前?
-
编译器需要知道
U和V是类型参数:- 如果不写
<U, V>在方法名之前,编译器会认为U和V是未定义的类名或变量名,而不是泛型类型参数。 - 例如,
public static Pair<U, V> makePair会让编译器报错,因为U和V未声明。
- 如果不写
-
泛型方法的语法规则:
- Java 泛型方法的语法要求类型参数必须放在方法名之前,例如:
public static <U, V> Pair<U, V> makePair(U first, V second) { return new Pair<>(first, second); }
- 这样写时,编译器会知道
U和V是泛型类型参数,并且会在方法调用时被具体的类型替换(如makePair("Hello", 123)会推断U=String,V=Integer)。
- 避免歧义:
- 如果允许
public static Pair<U, V> makePair这样的写法,编译器无法区分U和V是类型参数还是其他东西(比如静态变量或类名),导致语法混乱。
- 如果允许
public static <U, V> Pair<U, V> makePair(U first, V second) { return new Pair<>(first, second); }
<U, V>在方法名之前:声明U和V是泛型类型参数。Pair<U, V>作为返回类型:指定返回的Pair对象的泛型类型。
错误的写法
public static Pair<U, V> makePair(U first, V second) { // 错误!U 和 V 未声明 return new Pair<>(first, second); }
- 编译器会报错,因为
U和V没有在方法名之前声明为类型参数。
总结
- 泛型方法的类型参数必须显式声明在方法名之前(如
<U, V>)。 - 返回类型中的
<U, V>只是引用这些类型参数,不能替代方法名前的声明。 - 这样设计是为了让编译器能正确识别泛型类型,并确保类型安全。
3、如下代码的写法比较奇怪乍一看,如何理解?
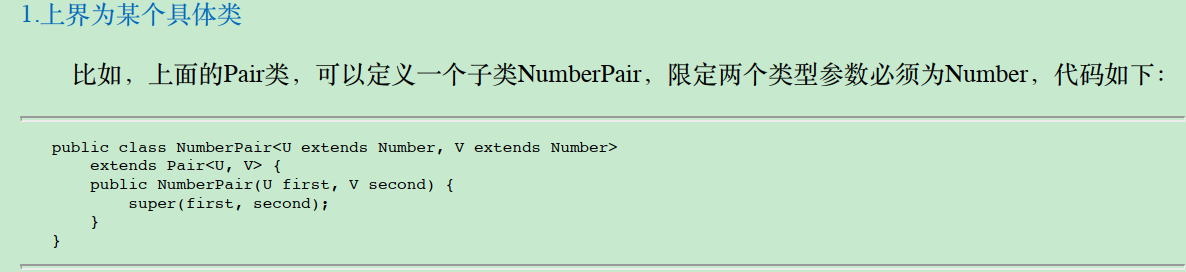
这段代码定义了一个名为 NumberPair 的泛型类,它继承自 Pair 类。
NumberPair 类有两个类型参数 U 和 V,这两个类型参数都扩展自 Number 类。
这意味着 NumberPair 类只能用于存储继承自 Number 类的类型,如 Integer, Double, Float 等。
下面是对代码的详细解释:
public class NumberPair<U extends Number, V extends Number> extends Pair<U, V> { public NumberPair(U first, V second) { super(first, second); } }
- 泛型类的定义
public class NumberPair<U extends Number, V extends Number>
NumberPair是一个泛型类,带有两个类型参数U和V。U extends Number表示U必须是Number类或其子类。V extends Number表示V也必须是Number类或其子类。
- 继承关系
extends Pair<U, V>
NumberPair继承自Pair类。Pair类也是一个泛型类,具有相同的类型参数U和V。
- 构造函数
public NumberPair(U first, V second) { super(first, second); }
- 构造函数接受两个参数
first和second,它们的类型分别是U和V。 - 调用了父类
Pair的构造函数super(first, second),将first和second传递给父类。
- 用途:
-
NumberPair类专门用于存储两个数值类型的对象。- 由于
U和V都扩展自Number,所以可以保证存储的对象都是数值类型。
- 示例用法:
NumberPair<Integer, Double> numberPair = new NumberPair<>(10, 20.5); System.out.println(numberPair.getFirst()); // 输出: 10 System.out.println(numberPair.getSecond()); // 输出: 20.5
总结来说,NumberPair 类通过限制类型参数的范围(即只能是 Number 类或其子类),提供了更强的类型安全和更好的代码可读性。
这种做法在某些情况下非常有用,特别是在处理数值数据时,可以避免类型错误和不一致的情况。
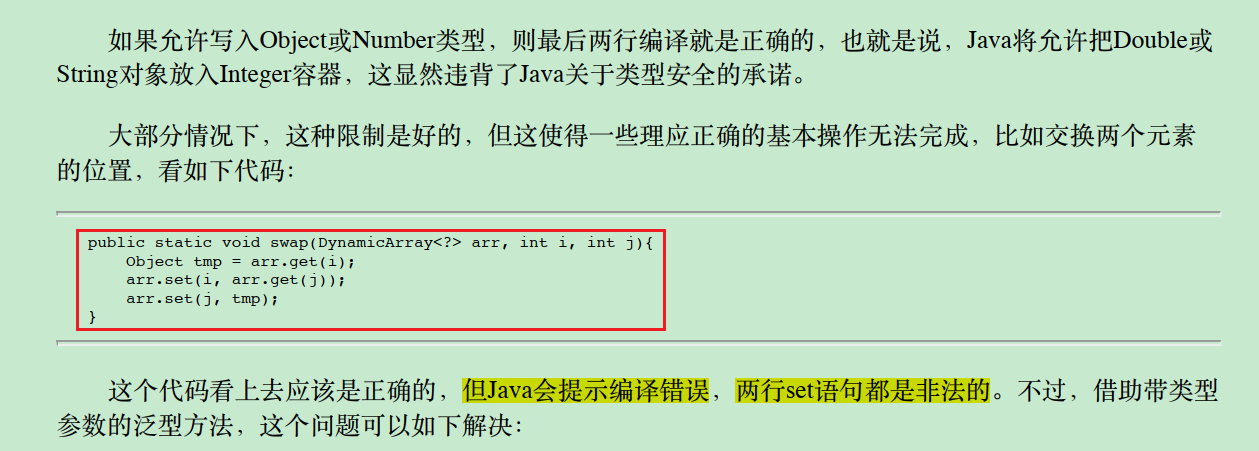
这个代码会报错的原因是因为 Java 的类型系统不允许在不安全的上下文中进行类型转换。
具体来说,DynamicArray<?> 是一个未知的泛型类型,编译器无法确定其具体类型,因此无法保证类型安全。
在代码中,arr.set(i, arr.get(j)) 和 arr.set(j, tmp) 这两行代码试图将元素从一个位置移动到另一个位置。
但由于 arr 的类型是 DynamicArray<?>,编译器不知道 arr.get(i) 和 arr.get(j) 的确切类型,因此无法确定这两次赋值是否合法。
为了解决这个问题,可以使用带类型参数的泛型方法来确保类型安全。例如,可以将 swap 方法改写为:
public static <T> void swap(DynamicArray<T> arr, int i, int j) { T tmp = arr.get(i); arr.set(i, arr.get(j)); arr.set(j, tmp); }
这样,编译器就可以确保 tmp、arr.get(i) 和 arr.get(j) 都是相同的类型 T,从而保证了类型安全。
5、为什么基础类型无法直接继承 Object? 什么是包装类?为什么有了基础类型后,还需要引出个这么个概念?有何作用?
-
为什么基础类型无法直接继承 Object?
基础类型(如 int、double 等)是 Java 中的原始数据类型,它们是由 JVM 直接支持的简单数据结构,设计目的是高效存储和操作基本值。这些类型在内存中以固定大小的二进制形式表示,不具备对象的特性(如方法或状态)。而 Object 是 Java 中的所有类的根类,对象类型必须支持继承、方法调用等特性。基础类型无法满足这些要求,因此无法直接继承 Object。Java 编译器在处理泛型时需要统一类型为 Object,这也是基础类型不能用作泛型的原因。 -
什么是包装类?为什么需要包装类?有何作用?
包装类是 Java 为每个基础类型提供的一个对应对象类型,例如 Integer(对应 int)、Double(对应 double)等。它们的作用是将基础类型“包装”成对象,使其具备对象特性(如可以作为方法参数、存储在集合中等)。为什么需要?
- 基础类型设计初衷是高效,但它们不支持面向对象的特性(如继承、接口实现),而 Java 的很多高级功能(如集合框架 ArrayList、泛型)要求使用对象类型。
- 有了包装类,可以在需要对象场景下使用基础类型的值,例如将 int 放入 ArrayList 中。
作用:
- 装箱与拆箱:包装类支持自动装箱(将 int 转为 Integer)和自动拆箱(将 Integer 转为 int),简化代码。例如:Integer num = 5;(装箱),int value = num;(拆箱)。
- 泛型支持:如 ArrayList<Integer>,允许在集合中使用整数。
- 附加功能:包装类提供了实用方法,如 Integer.parseInt() 将字符串转为 int,Integer.toString() 将 int 转为字符串。
示例
int primitive = 10; Integer wrapped = primitive; // 自动装箱 int back = wrapped; // 自动拆箱 ArrayList<Integer> list = new ArrayList<>(); list.add(wrapped); // 可以使用包装类存储到集合, 这行代码会报错,有些问题 System.out.println(list.get(0)); // 输出 10,这行代码会报错,有些问题
通过包装类,Java 实现了基础类型与对象类型之间的桥梁,兼顾了性能和灵活性。
6、Java的泛型中的类型擦除的概念和作用、通俗解释、举例说明?再解释下为什么类型擦除会引发一些编译冲突?
泛型中的类型擦除的概念和作用
概念:类型擦除是指 Java 编译器在编译泛型代码时,会将泛型类型信息(例如 <T>)擦除,替换为具体的类型(通常是 Object 或约束类型),生成字节码时不再保留泛型的类型参数。这是一种为了兼容旧代码(Java 1.4 及更早版本)的设计。
作用:
- 确保向后兼容性:旧的非泛型代码可以与新代码共存。
- 提高性能:运行时无需维护复杂的泛型类型信息,减少内存开销。
- 提供类型安全:编译期检查类型,运行时无需再做类型转换。
通俗解释:想象你在写一个“万能盒子”(泛型类),可以装任何类型的东西(T)。编译器在生成最终产品时,会把盒子标签上的“任何类型”擦掉,统一变成一个默认标签(通常是 Object),但它会记住编译时的规则,确保你放进去的东西符合要求。这样,老系统还能用这个盒子,但运行时不会再管具体放了什么。
举例说明
import java.util.ArrayList; public class Example { public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<>(); list.add(5); // 编译时检查类型安全 // list.add("string"); // 编译错误 // 运行时擦除,类型信息丢失 ArrayList rawList = list; // 原始类型 rawList.add("string"); // 运行时可以添加,但不推荐 Integer num = list.get(0); // 运行时需强制转换 System.out.println(num); // 输出 5 } }
- 编译时,ArrayList<Integer> 确保只加 Integer,类型安全。
- 运行时,ArrayList 变成 ArrayList<Object>,类型信息擦除,允许添加 String,但可能导致运行时异常。
为什么类型擦除会引发编译冲突?
类型擦除会导致以下编译冲突:
- 原始类型与泛型类型混用:
- 例如,ArrayList(原始类型)和 ArrayList<Integer> 混用时,编译器无法区分具体类型,可能导致运行时类型转换异常。
- 示例:rawList.add("string") 会污染 list,但编译器不报错。
- 静态方法或字段冲突:
- 泛型类中的静态成员不能使用类型参数,因为类型参数在擦除后不再存在。
- 示例:
class Box<T> { static T item; // 编译错误:不能用 T }
-
- 原因:T 在擦除后消失,静态成员是类级的,无法绑定具体类型。
- 重载方法冲突:
- 擦除后方法签名可能重复,导致编译器无法区分。
- 示例:
class Example { public void method(List<String> list) {} public void method(List<Integer> list) {} // 编译错误 }
- 原因:擦除后两个方法都变成 method(List),签名相同,违反重载规则。
- 类型参数约束冲突:
- 如果泛型方法或类有边界(如 <T extends Number>),擦除后可能导致类型不匹配。
- 示例:运行时无法保证擦除后的类型符合边界约束,可能引发 ClassCastException。
总之,类型擦除虽然提高了兼容性,但也限制了运行时的类型信息使用,需在编码时谨慎处理类型安全问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号