

Java Programming 【Chapter 7_QA】
1、如图所示的三个方法,分别是干啥的?有何作用。

这段代码中涉及了三个方法,分别是 valueOf、parseXXX 和 toString,它们的作用如下:
- valueOf (如 Boolean.valueOf、Float.valueOf)
- 作用:将字符串或基本类型转换为对应的包装类对象。例如,Boolean.valueOf("true") 将字符串 "true" 转换为 Boolean 类型的对象 true,Float.valueOf("123.45f") 将字符串 "123.45f" 转换为 Float 类型的对象。
- 特点:返回的是包装类实例,而不是基本类型。
- parseXXX (如 Boolean.parseBoolean、Double.parseDouble)
- 作用:将字符串解析为对应的基本类型值。例如,Boolean.parseBoolean("true") 将字符串 "true" 解析为布尔型 true,Double.parseDouble("123.45") 将字符串 "123.45" 解析为双精度浮点型 123.45。
- 特点:返回的是基本类型,而不是包装类对象。
- toString (如 Boolean.toString、Double.toString)
- 作用:将基本类型或包装类对象转换为字符串表示。例如,Boolean.toString(true) 将布尔值 true 转换为字符串 "true",Double.toString(123.45) 将双精度浮点数 123.45 转换为字符串 "123.45"。
- 特点:通常用于输出或显示目的。
这三个方法在处理字符串和基本类型转换时各有侧重,valueOf 用于创建对象,parseXXX 用于获取基本类型值,toString 用于生成字符串表示。
下面分别举例说明 valueOf、parseXXX 和 toString 的用法:
1、valueOf
示例:
Boolean bool = Boolean.valueOf("true");
Float floatNum = Float.valueOf("123.45f");
System.out.println(bool); // 输出: true
System.out.println(floatNum); // 输出: 123.45
- 说明:Boolean.valueOf("true") 创建一个 Boolean 对象值为 true,Float.valueOf("123.45f") 创建一个 Float 对象值为 123.45。
2、parseXXX
示例:
boolean bool = Boolean.parseBoolean("true"); double doubleNum = Double.parseDouble("123.45"); System.out.println(bool); // 输出: true System.out.println(doubleNum); // 输出: 123.45
- 说明:Boolean.parseBoolean("true") 将字符串 "true" 解析为基本类型 boolean 的 true,Double.parseDouble("123.45") 将字符串 "123.45" 解析为基本类型 double 的 123.45。
3、toString
示例:
String boolStr = Boolean.toString(true); String doubleStr = Double.toString(123.45); System.out.println(boolStr); // 输出: true System.out.println(doubleStr); // 输出: 123.45
- 说明:Boolean.toString(true) 将布尔值 true 转换为字符串 "true",Double.toString(123.45) 将双精度浮点数 123.45 转换为字符串 "123.45"。
这些示例展示了三个方法在实际使用中的不同场景。
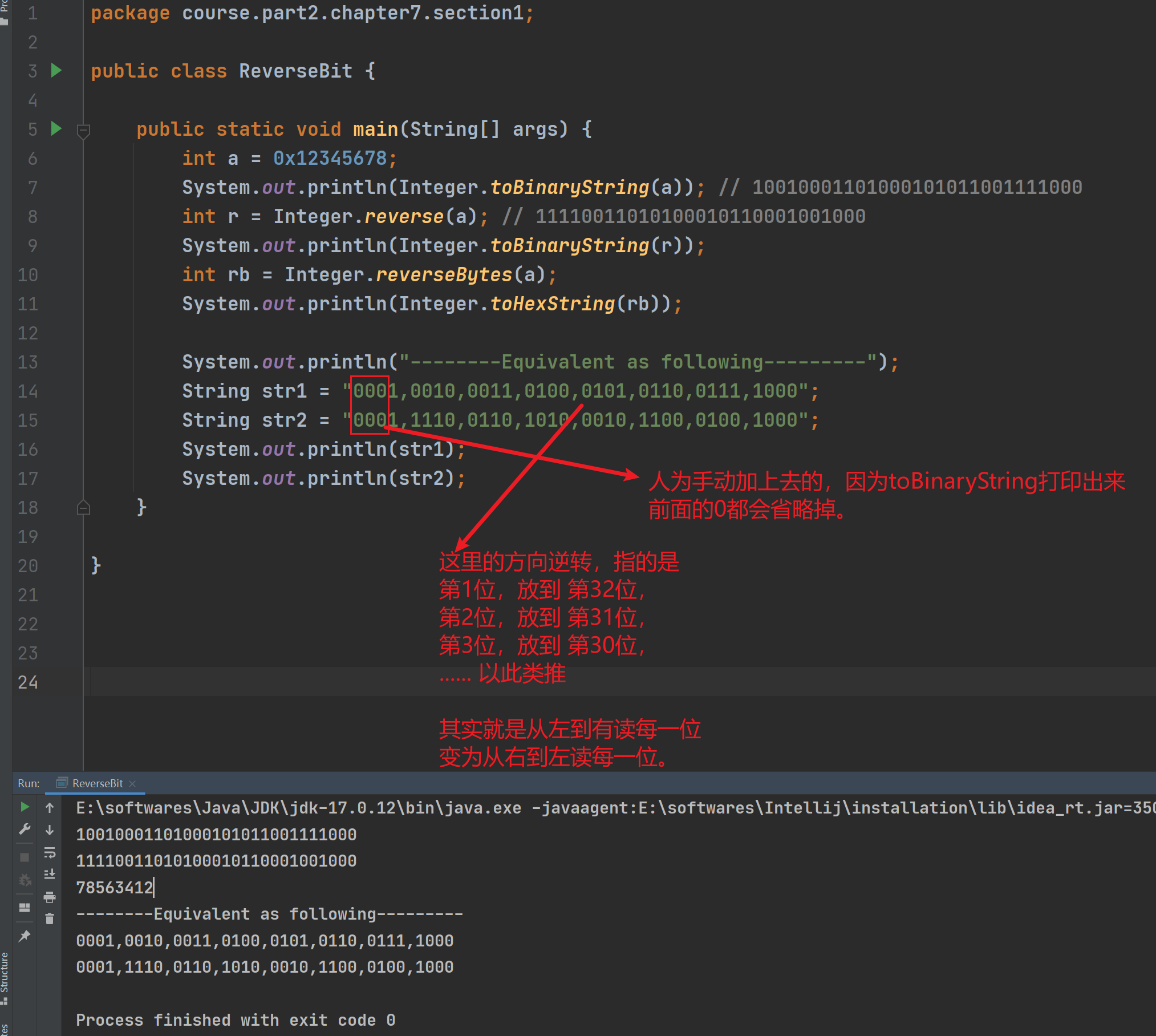
2、如何理解 Integer的【位翻转】结果
参考下图理解即可。
3、Unicode相关知识整理

4、对于如下代码的理解

这段代码是 Java 中处理字符编码的一个小例子,主要是用来计算 Unicode 码点(code point)的数量。让我们一步步简单理解:
背景
- Unicode 码点:就像每个字或符号在电脑里有一个独一无二的“身份证号码”,这个号码叫码点。比如字母 "A" 的码点是 U+0041,表情符号 😊 的码点是 U+1F60A。
- char 类型:Java 的 char 是一个 16 位的数据类型,理论上能表示 0 到 65535 的码点。但有些特殊字符(比如表情符号)需要用一对 char 来表示(称为代理对,surrogate pair)。
- codePointCount:这个方法用来计算一个字符数组中从某位置到某位置的码点数量,而不是单纯的 char 个数。
代码解析
1、定义字符数组:
char[] chs = new char[3]; chs[0] = '马'; Character.toChars(0x1FFFF, chs, 1);
- 创建了一个长度为 3 的 char 数组 chs。
- 把中文字符 "马" 放进 chs[0]。
- Character.toChars(0x1FFFF, chs, 1) 把码点 0x1FFFF(一个超大码点,通常是某种特殊符号)转换为 char 数组,并从 chs[1] 开始填入。这会占用 chs[1] 和 chs[2](因为 0x1FFFF 超出了单个 char 的范围,需要两个 char)。
2、计算码点数量:
System.out.println(Character.codePointCount(chs, 0, 3));
- Character.codePointCount(chs, 0, 3) 计算从 chs[0] 到 chs[2](总共 3 个 char)的码点数量。
- 这里 "马" 是一个码点,0x1FFFF 是一个码点,所以总共是 2 个码点,尽管用了 3 个 char。
通俗理解
想象你有两张纸条,一个写着 "马"(一个字),另一个写着一个复杂的表情符号(需要两张小纸条表示)。总共有 3 张小纸条,但实际内容只有 2 个“意思”(码点)。代码就是用来数这些“意思”的个数,而不是纸条的数量。
输出
程序会输出 2,因为数组里包含 2 个独立的 Unicode 码点。
关键点
- 单个 char 只能表示部分码点,复杂的字符(如 0x1FFFF)需要两个 char。
- codePointCount 帮你数的是“真正的内容”(码点),而不是 char 的数量。
5、如何理解这段话?

这句话讲的是字符编码的基本概念,我们来简单拆解,尤其是“不同的二进制表示”这个点。
整体意思
“不同编码可能用于不同的字符集,使用不同的字节数目,以及不同的二进制表示”是指:
- 计算机用编码来表示文字,不同的编码方案(比如 ASCII、UTF-8、GBK)针对不同的语言或字符集(比如英语、中文)。
- 这些编码用不同的字节数来存储字符(1字节、2字节、3字节等)。
- 同一个字符在不同编码下,底层用二进制表示可能完全不同。
重点:二进制还有不同的表示?
是的,二进制表示确实可以“不同”,原因在于编码规则不同。简单说:
- 二进制是基础:计算机只认识 0 和 1,字符的“样子”是通过编码规则转成二进制存储的。
- 编码规则决定表示:
- 比如,字母 "A" 在 ASCII 编码里是 01000001(1字节),而在某些特殊编码中可能完全不同。
- 中文字符 "中" 在 UTF-8 编码里可能是 11100100 10001101 10101001(3字节),而在 GBK 编码里可能是 10110010 10100101(2字节)。
- 不同方案,不同结果:即使是同一个字符,不同编码用不同的二进制组合表示,因为它们的设计目标和规则不同(比如支持的字符范围、效率)。
通俗比喻
想象你给朋友发信息,约定的“暗号”不同:
- 一种规则是“A=1”,“B=2”,用 1 个数字表示。
- 另一种规则是“A=01”,“B=02”,用 2 个数字表示。
- 同一个“A”,二进制“翻译”成 0 和 1 的方式就不同,这就是“不同的二进制表示”。
总结
“不同的二进制表示”指的是同一个字符因编码方式不同,底层存储的 0 和 1 序列会变。
这取决于编码标准(如 UTF-8、GB2312)如何分配字节和二进制组合。
6、如何理解下面的代码输出结果差异?
package course.part2.chapter7.section2; public class StringTest { public static void main(String[] args) { String name1 = "老马说编程"; String name2 = "老马说编程"; System.out.println(name1 == name2); // true System.out.println(name1.equals(name2)); // true String name3 = new String("老马说编程"); String name4 = new String("老马说编程"); System.out.println(name3 == name4); // false System.out.println(name3.equals(name4)); // true }
}
一句话简单理解就是:“== 比较的是内存地址, equals()比较的是字符串的内容”
输出的结果与 Java 中字符串的内存分配和比较方式有关。让我们简要分析:
代码输出
- System.out.println(name1 == name2); // true
- name1 和 name2 都是直接赋值为 "老马说编程",Java 会把这种字面量字符串存储在字符串常量池中,name1 和 name2 指向同一个对象。所以 == 比较内存地址,结果是 true。
- System.out.println(name1.equals(name2)); // true
- equals() 比较的是字符串的内容,name1 和 name2 的内容都是 "老马说编程",所以结果是 true。
- System.out.println(name3 == name4); // false
- name3 和 name4 使用 new String() 创建新对象,即使内容相同,每个 new 都会在堆内存中生成一个独立对象,地址不同。所以 == 比较地址,结果是 false。
- System.out.println(name3.equals(name4)); // true
- 同样,equals() 比较内容,name3 和 name4 内容都是 "老马说编程",所以结果是 true。
关键点
- == 比较内存地址:检查两个变量是否指向同一个对象。
- equals() 比较内容:检查两个字符串的值是否相同。
- 字符串常量池:直接赋值(如 "老马说编程")复用常量池中的对象;new String() 创建新对象,不复用。
7、理解下如下代码的输出
public class StringBuilderTest { public static void main(String[] args) { int[] arr = new int[]{1, 2, 3, 4}; System.arraycopy(arr, 1, arr, 0, 3); System.out.println(arr[0] + "," + arr[1] + "," + arr[2]); } }
解析
- 初始化数组:
- int[] arr = new int[]{1, 2, 3, 4} 创建一个数组,初始值为 [1, 2, 3, 4]。
- System.arraycopy 方法:
- 参数含义:
- arr:源数组。
- 1:从源数组的索引 1 开始(即从 2 开始)。
- arr:目标数组(还是同一个数组)。
- 0:目标数组的起始索引(覆盖从 0 开始)。
- 3:复制 3 个元素。
- 效果:将 [2, 3, 4] 复制到 [0, 1, 2] 的位置,覆盖原数组前 3 个元素。
- 结果:数组变成 [2, 3, 4, 4](第 3 个 4 是原数组未被覆盖的部分)。
- 参数含义:
- 输出:
- System.out.println(arr[0] + "," + arr[1] + "," + arr[2]) 打印数组前三个元素。
- 即 2,3,4。
总结
代码将数组 [1, 2, 3, 4] 的子数组 [2, 3, 4] 左移到 [0, 1, 2] 位置,覆盖原值,最终输出 2,3,4。
8、如何理解如下代码的红框处的标识

追问1:nextIndex(chars, rnd) 为什么只返回元素为0时对应的index?
nextIndex(chars, rnd) 方法的逻辑并不是只返回元素为 0 时对应的索引,而是随机选择一个非空(非 0)的索引。让我们简要分析代码:
代码片段
private static int nextIndex(char[] chars, Random rnd) { int index = rnd.nextInt(chars.length); while(chars[index] != 0) { index = rnd.nextInt(chars.length); } return index; }
分析
- 初始随机选择:
- rnd.nextInt(chars.length) 生成一个 0 到 chars.length - 1 之间的随机索引。
- while 循环条件:
- while(chars[index] != 0) 检查当前索引位置的字符是否为 0(未初始化或空)。
- 如果 chars[index] 不为 0(即该位置已被占用),继续随机生成新的索引,直到找到一个值为 0 的位置。
- 返回值:
- 返回第一个找到的 chars[index] == 0 的索引,即一个“空位”。
为什么这样做?
- 目的:确保每次调用 nextIndex 时,返回一个尚未被赋值的索引(值为 0),避免覆盖已有的字符。
- 上下文:在 randomPassword() 中,nextIndex 用于随机分配特殊字符、大写字母等,确保不重复填充相同位置。
误解澄清
- 它不是“只返回元素为 0 时对应的索引”,而是返回一个当前值为 0(未使用)的随机索引。
- 如果数组中所有位置都被赋值(全非 0),循环会无限运行(需优化),但代码假设在填充过程中总有空位。
总结
nextIndex 通过随机选择并检查,确保返回一个“可用”的空索引(chars[index] == 0),以便后续赋值。这是为了控制密码字符的随机分布。
追问2:不太理解这个:如果 chars[index] 不为 0(即该位置已被占用)
背景
- chars 是一个 char 类型的数组,初始时所有元素默认是 0(Java 中 char 的默认值是 ``,即空字符)。
- 在 randomPassword() 方法中,chars 被用来存储生成的密码字符,长度为 8。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号