深度学习的Dropout技术中,为什么所有神经元输出乘以 1−dropout_ratio?【详解】
Q1:深度学习的Dropout技术中,为什么所有神经元输出乘以 1−dropout_ratio?

解释:
一图胜千言:【秒懂】
接下来详细解析图片中提到的Dropout技术,特别是“对于各个神经元的输出,要乘上训练时的删除比例后再输出”这句话,并结合代码和通俗语言解释其含义。
1. Dropout技术的背景
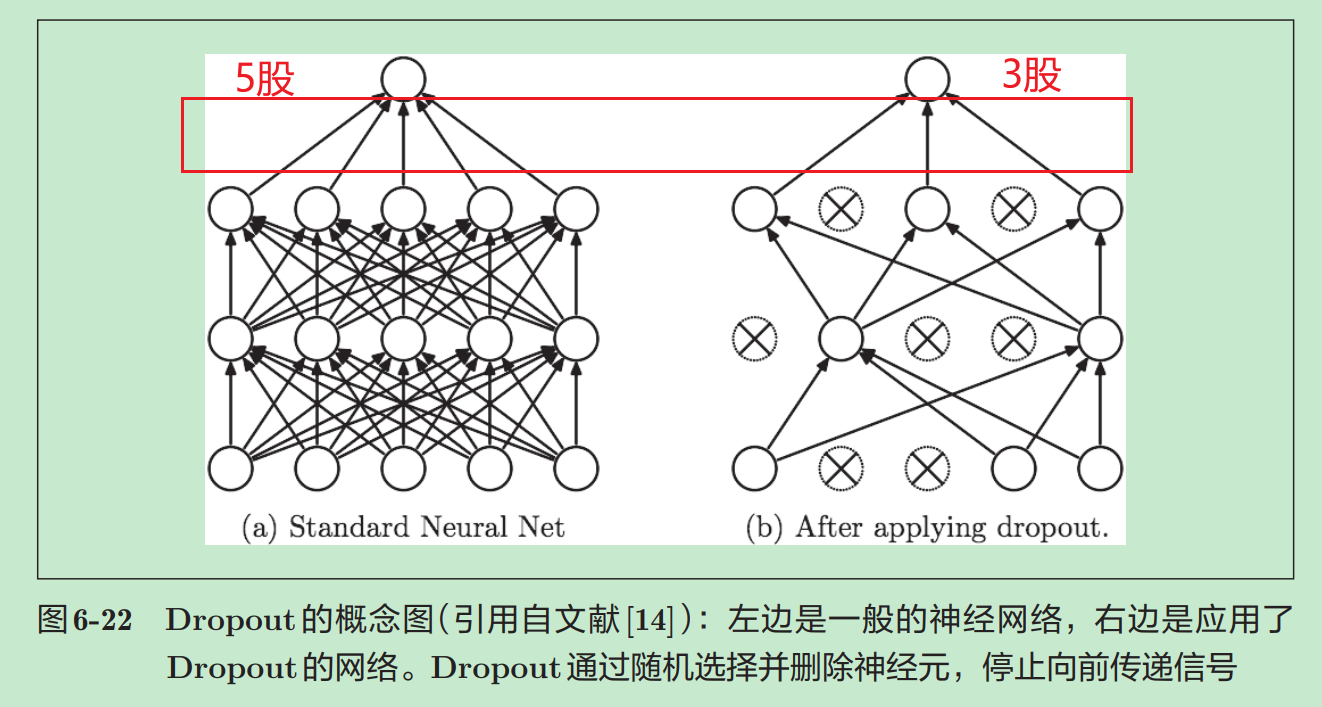
Dropout是一种在神经网络训练中常用的正则化技术,旨在防止过拟合(Overfitting)。过拟合是指模型在训练数据上表现很好,但在测试数据上表现不佳。
Dropout的思路是:在训练过程中,随机“丢弃”(即暂时置为0)一部分神经元的输出,让网络在每次训练迭代中学习不同的子网络,从而提高模型的泛化能力。
图片中提到的是Chainer框架中的Dropout实现,代码展示了如何在训练和推理(测试)阶段处理神经元的输出。
2. 代码解析
以下是代码的关键部分:
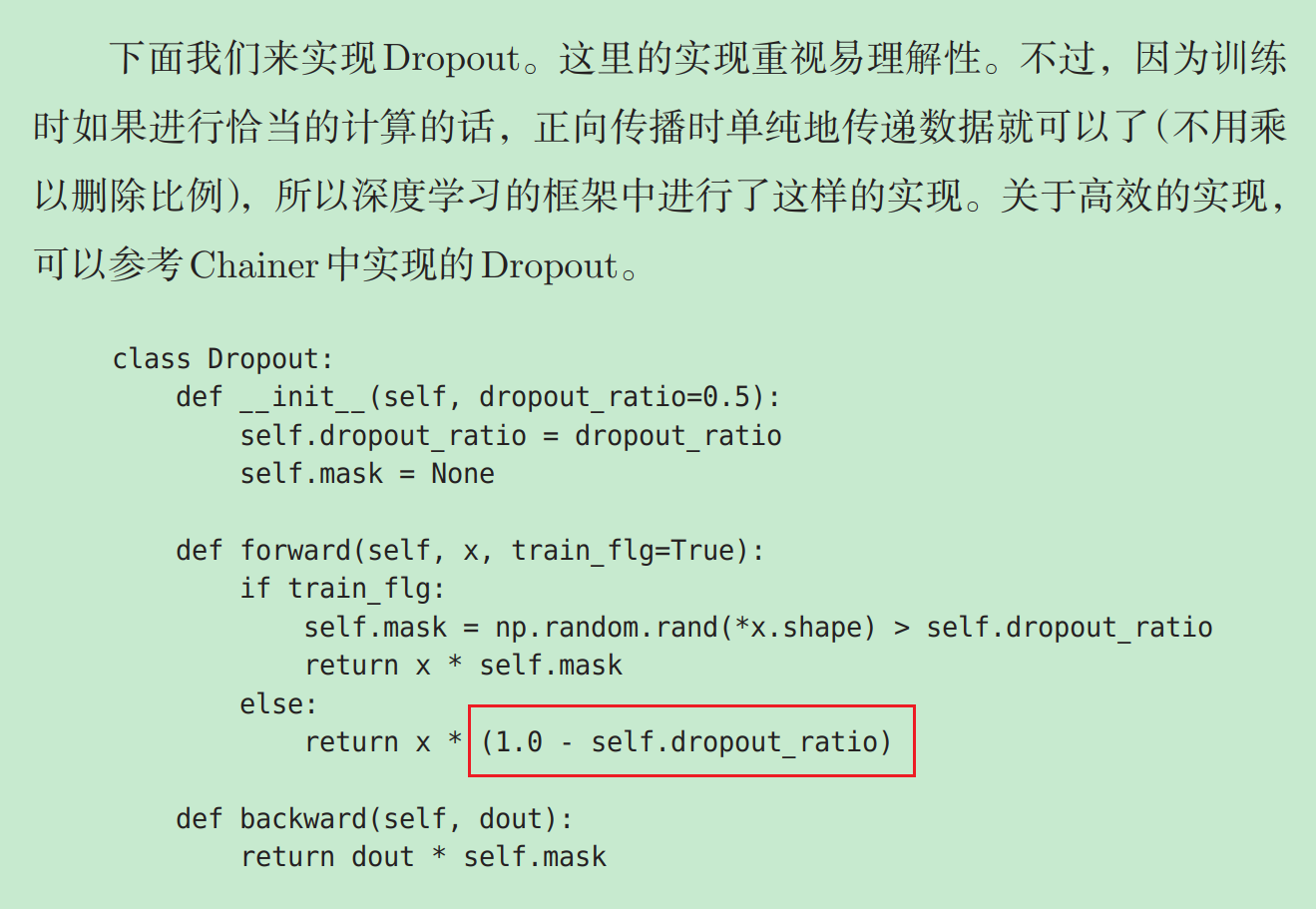
class Dropout: def __init__(self, dropout_ratio=0.5): self.dropout_ratio = dropout_ratio # 删除比例,默认为0.5 self.mask = None def forward(self, x, train_flg=True): if train_flg: # 训练模式 self.mask = np.random.rand(*x.shape) > self.dropout_ratio # 生成随机掩码 return x * self.mask else: # 推理模式 return x * (1.0 - self.dropout_ratio) # 红框部分 def backward(self, dout): return dout * self.mask
关键点解释:
- dropout_ratio:删除比例,设为0.5表示有50%的神经元输出会被随机置为0。
- train_flg:一个标志,True表示训练模式,False表示推理模式。
- self.mask:一个随机生成的二值掩码(0或1),决定哪些神经元被丢弃。
- forward:前向传播函数,处理输入 x x x 的输出。
- backward:反向传播函数,计算梯度。

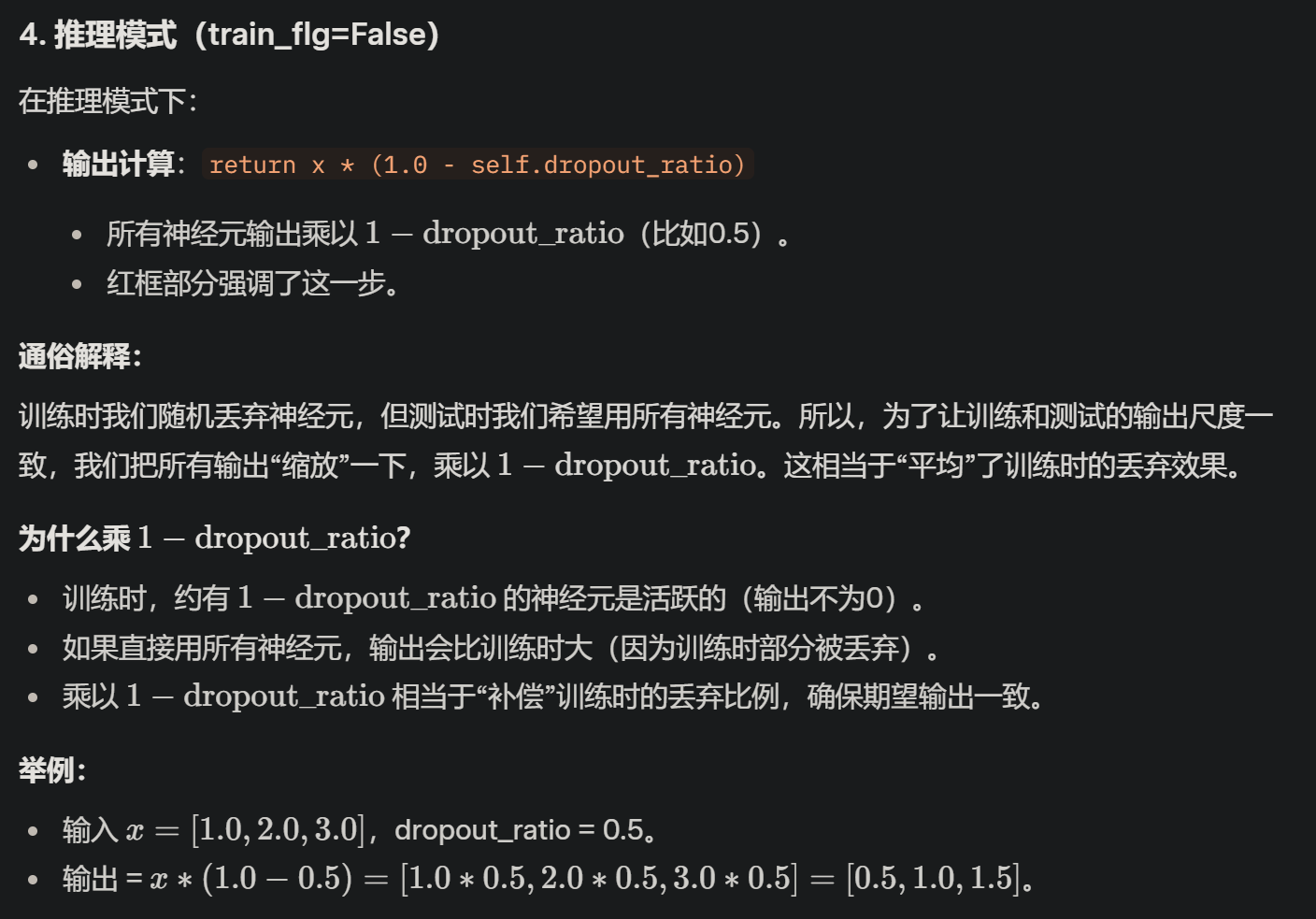


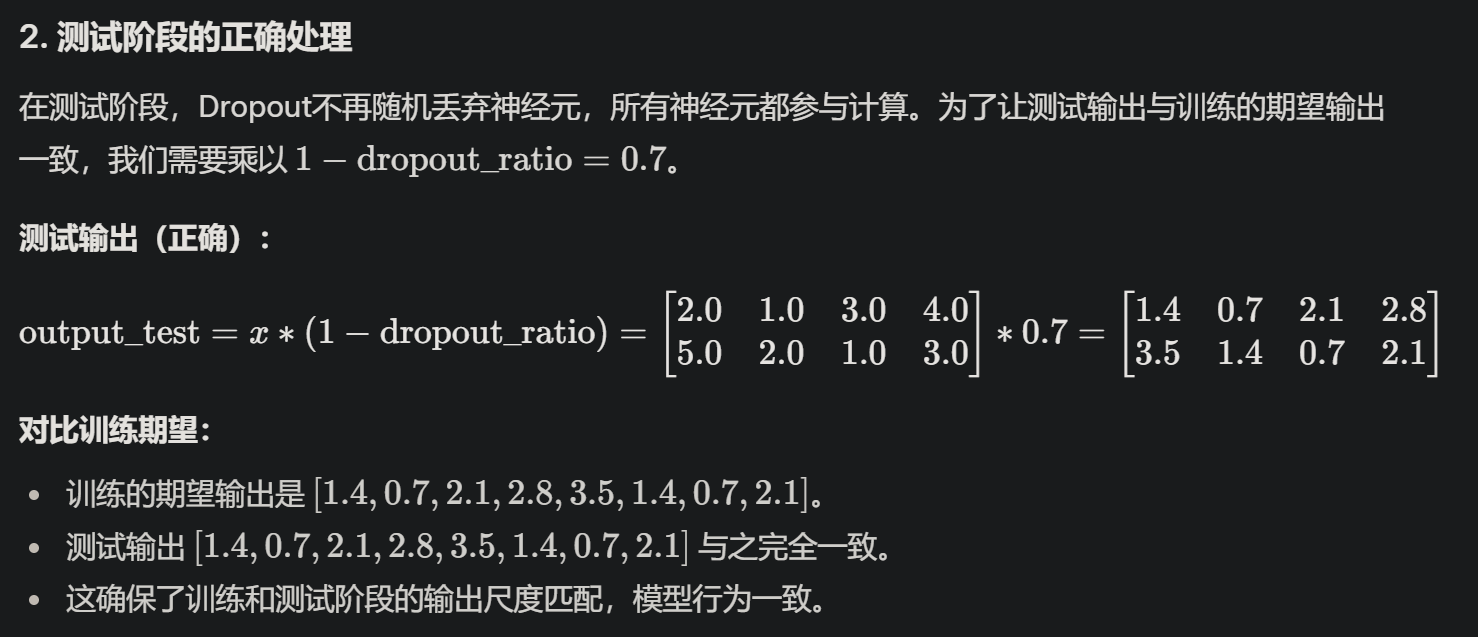
Q2:举例说明





 浙公网安备 33010602011771号
浙公网安备 33010602011771号