Python中的traceback模块的理解和常见用法说明。
在 Python 中,import traceback 是用来引入 traceback 模块的。
这个模块主要用于处理和调试程序中的异常(errors/exceptions),尤其是当你的代码出错时,它能帮你提取、格式化并打印出异常的详细信息,比如错误发生的位置、调用栈(call stack)等。
简单来说,它就像是程序出错时的“侦探”,帮你找到问题根源。【执果索因】
通俗解释
想象一下,你在组装一个复杂的玩具,但最后发现它坏了,你不知道哪里出了问题。traceback 就像是你请来的专家,它会告诉你:“嘿,你在第5步拧螺丝的时候拧错了,之前第3步也有点问题。”
它会给出一条清晰的“线索链”(调用栈),告诉你程序从哪里开始跑偏的。
在 Python 中,当程序抛出异常(比如除以零、文件不存在等),traceback 可以帮你把错误信息整理得更清晰,甚至可以让你决定如何处理这些错误。
常见用法
traceback 模块提供了一些方法,让你捕获、格式化或打印异常信息。以下是几种常见的用法:
- traceback.print_exc()
- 用法:直接打印当前异常的详细信息。
- 场景:通常在 try-except 块中使用,当捕获到异常时,打印完整的错误栈。
- traceback.format_exc()
- 用法:返回当前异常的格式化字符串,而不是直接打印。
- 场景:当你想把错误信息存到日志文件或以其他方式处理时。
- traceback.extract_tb()
- 用法:提取异常的调用栈信息,返回一个结构化的对象。
- 场景:如果你想自己分析调用栈的细节,比如具体是哪一行代码出错。
- traceback.print_stack()
- 用法:打印当前的调用栈(即使没有异常)。
- 场景:调试时,想知道程序执行到哪一步了。
为了更直观地理解 traceback 的作用,我会通过一个例子展示“使用 traceback”和“不使用 traceback”在处理异常时的返回结果差异。
这样可以清楚地看到 traceback 如何提供更详细的信息,帮助调试。
示例场景
假设我们写了一个简单的程序,里面有一个函数会引发异常(比如除以零)。我们分别用两种方式处理异常:
- 不使用 traceback:只捕获异常并简单输出错误类型。
- 使用 traceback:捕获异常并用 traceback 输出详细的调用栈信息。
代码
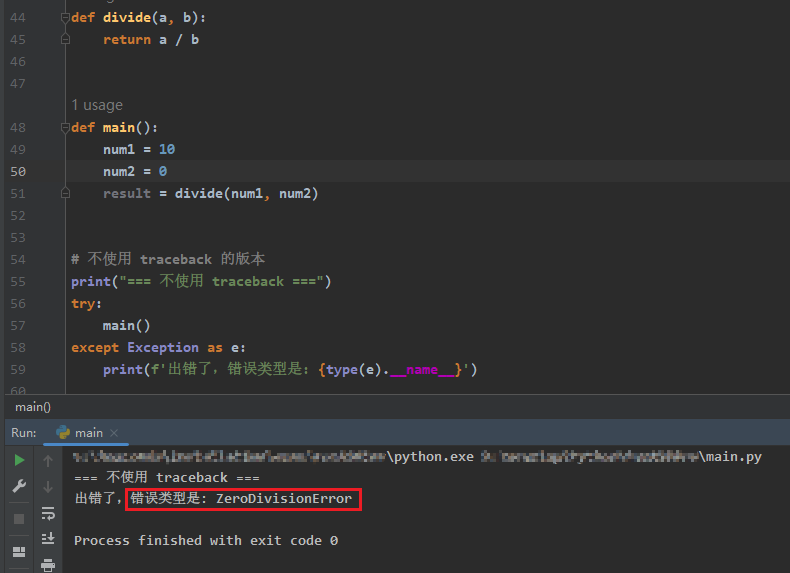
输出结果分析:
- 只告诉我们错误类型是 ZeroDivisionError(除以零错误)。
- 没有提供任何额外信息,比如错误发生在哪一行、调用栈是什么样的。
- 如果代码很复杂,你可能完全不知道问题出在哪里,只能靠猜测。
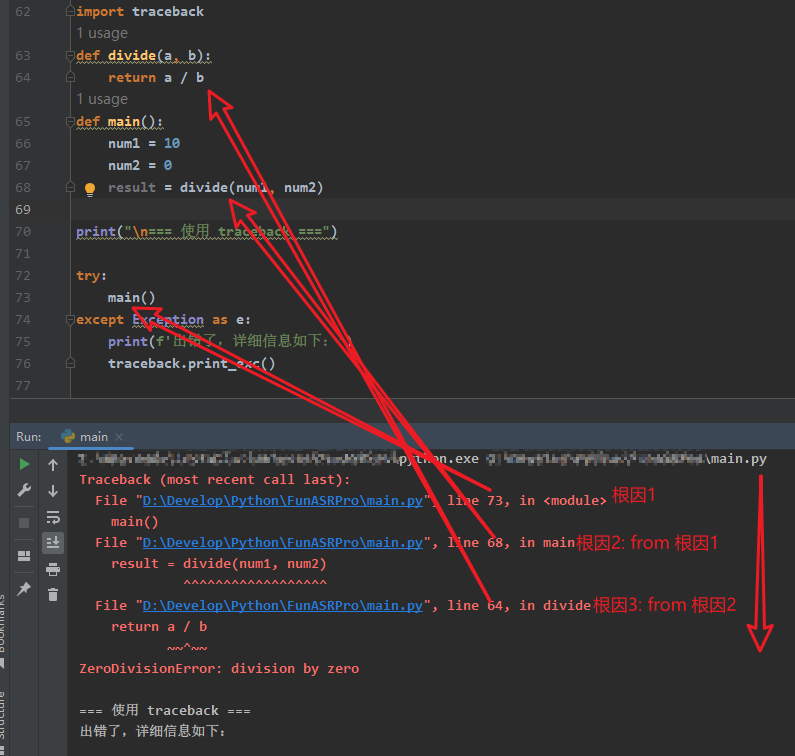
结果分析:
- 提供了完整的调用栈信息:
- 异常发生在 divide 函数的第64行(return a / b)。
- divide 是被 main 函数的第68行调用的(result = divide(num1, num2))。
- main 是被顶层代码的第73行调用的(main())。
- 不仅告诉你错误类型(ZeroDivisionError),还告诉你错误发生的具体路径和位置。
- 如果代码很复杂,这种信息能帮你快速定位问题。
结论
- 不使用 traceback:就像只知道“有人摔倒了”,但不知道在哪里摔的。
- 使用 traceback:就像拿到了一张地图,标明了“摔倒的具体位置和路线”。
- 在实际开发中,尤其是代码复杂时,traceback 是调试的利器,能大大提高效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号