
Chapter10_微服务
1、微服务的概念的理解
什么是微服务?
微服务(Microservices)是一种软件架构风格,将一个大而复杂的应用程序拆分为多个小而独立的服务。这些服务各自独立运行,
每个服务专注于完成一个特定的业务功能,并通过轻量级的通信协议(通常是 HTTP 或消息队列)相互协作。每个服务可以由独立的团队开发、部署和维护。
微服务的作用
- 独立部署:每个微服务可以独立部署,降低了对整个系统进行更新的风险。
- 灵活性:不同的微服务可以使用不同的技术栈,团队可以选择最适合解决当前问题的工具和语言。
- 可伸缩性:微服务可以独立伸缩,根据需求增加或减少资源,提高系统的整体性能和资源利用率。
- 故障隔离:单个微服务的故障不会导致整个系统的崩溃,提高了系统的可靠性和可维护性。
- 团队独立性:不同的团队可以独立开发和部署各自的微服务,减少了团队间的依赖,提高了开发效率。
通俗解释和举例说明
通俗解释
想象一下你在一个大城市经营一家餐馆。餐馆有不同的部门:厨房、服务员、清洁、采购等。每个部门都有自己特定的职责,如果所有部门都由一个人来管理,工作会变得非常繁重且难以协调。
现在,你决定将这些部门分开,每个部门由不同的人负责,他们只需要做好自己的工作,同时通过协调来确保餐馆的正常运营。这样,即使某个部门暂时出现问题,也不会影响整个餐馆的运营。
微服务架构就像是把大型的单体应用程序拆分成多个独立的“小部门”,每个“小部门”专注于完成特定的任务,并通过标准化的接口进行通信。这不仅提高了系统的灵活性和可靠性,也让开发和维护变得更加高效。
举例说明
假设我们有一个电子商务网站,其中包括用户管理、商品管理、订单管理、支付处理等功能。如果采用单体架构,所有功能都在一个大而复杂的应用程序中实现,任何一个部分的更改都需要重新部署整个应用,风险大且效率低。
采用微服务架构后,我们可以将系统拆分为多个独立的服务:
- 用户服务:负责用户的注册、登录、个人信息管理。
- 商品服务:负责商品的添加、更新、删除、展示。
- 订单服务:负责订单的创建、查看、更新、取消。
- 支付服务:负责处理支付流程、与第三方支付平台集成。
这些服务可以独立开发、部署和扩展,例如:
- 在促销活动期间,只需增加商品服务和订单服务的实例,以应对高峰流量。
- 如果支付服务需要接入新的支付方式,只需更新支付服务,而不会影响其他服务。
如果没有微服务,会带来什么问题?
如果没有微服务架构,采用传统的单体架构,可能会带来以下问题:
- 部署困难:任何一次小的更改都需要重新构建和部署整个应用程序,效率低且风险高。
- 技术债务:随着业务的发展,单体应用程序会变得越来越复杂,维护难度加大,新技术和工具难以引入。
- 扩展受限:单体应用程序难以灵活扩展,不同模块的伸缩需求无法单独处理,资源利用率低。
- 团队效率低下:多个团队同时在一个代码库中工作,团队间依赖性强,协作效率低。
- 可靠性问题:单个模块的故障可能导致整个应用程序的崩溃,系统的可靠性和稳定性差。
微服务能解决什么问题?
- 独立部署和更新:微服务允许独立开发、部署和更新,降低了更新风险,提高了部署效率。
- 技术多样性:不同的微服务可以使用最适合的技术栈,促进技术创新和优化。
- 灵活扩展:微服务可以根据需求独立伸缩,提高系统性能和资源利用率。
- 提升团队效率:独立的微服务开发减少了团队间的依赖,促进了快速迭代和交付。
- 提高可靠性:单个微服务的故障不会影响整个系统,提高了系统的整体可靠性。
总结
微服务架构通过将复杂的单体应用拆分为多个小而独立的服务,提供了更高的灵活性、可扩展性和可靠性。
它解决了传统单体架构中部署困难、技术债务、扩展受限、团队效率低下和可靠性差等问题,使得大规模系统的开发和维护变得更加高效和可管理。
2、关于如下这张图,断路器模式,应该如何理解?
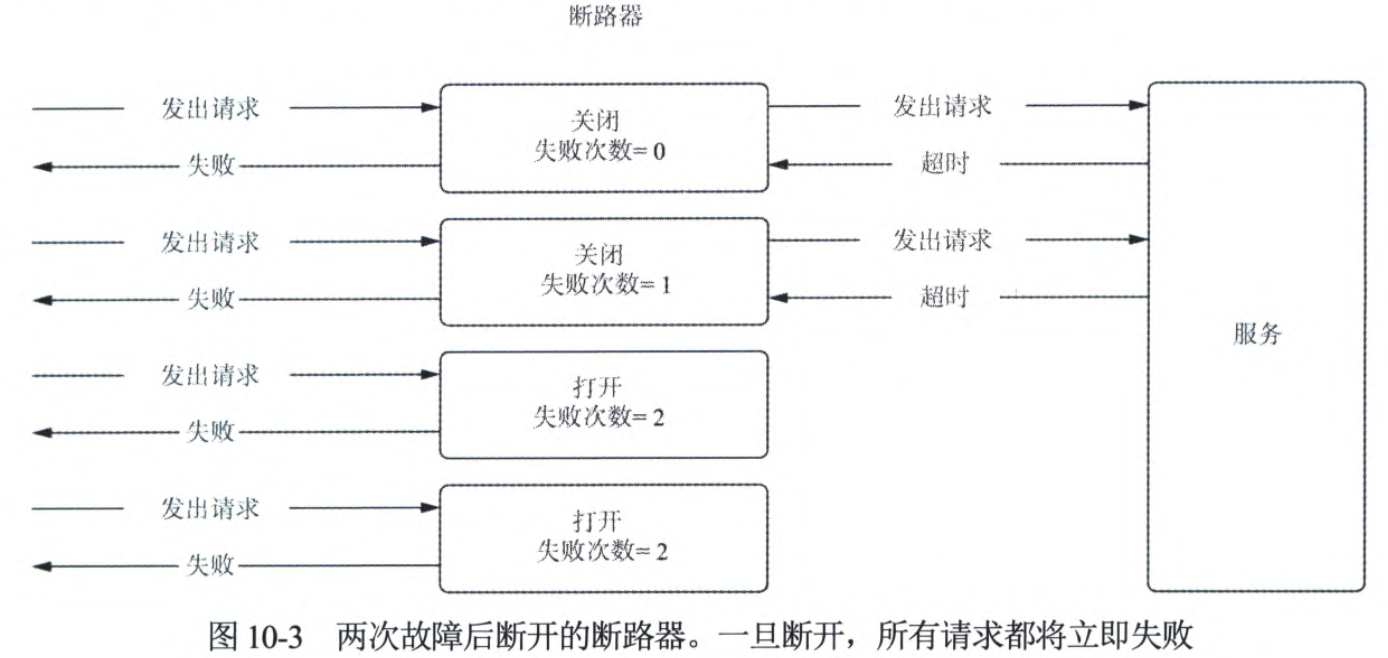
这段文字和图表介绍了"断路器模式",一种用于处理服务之间调用失败的模式。为了更通俗易懂地解释,我们可以将其类比于家庭电路中的电气断路器。
断路器模式的基本概念
- 断路器的状态:
- 关闭(Closed):正常状态下,断路器是关闭的,所有请求都可以正常通过。如果没有失败,请求会正常传递到服务。
- 打开(Open):如果检测到有多个连续请求失败,断路器会打开。在这个状态下,所有请求都会立即失败,不会传递到服务。这个目的是为了防止系统被更多的失败请求淹没。
- 半开(Half-Open):经过一段时间后,断路器会进入半开状态,发送少量请求去测试服务是否恢复。如果这些请求成功,断路器会关闭;如果仍然失败,断路器会再次打开。
断路器状态的转变
-
关闭状态(Closed):
- 正常情况下,断路器是关闭的,所有请求都直接传递到服务。
- 如果请求失败次数达到阈值(如图中的2次),断路器转到打开状态。
-
打开状态(Open):
- 一旦进入打开状态,所有请求都会立即失败,不会传递到服务。这是为了防止继续向已经可能出问题的服务发送请求,进一步导致问题扩大。
- 在图中,当连续两次请求失败后,断路器转为打开状态。
-
半开状态(Half-Open):
- 在打开状态维持一段时间后,断路器会进入半开状态,允许少量请求通过,以测试服务是否恢复。
- 如果测试请求成功,断路器会重新关闭;如果测试请求失败,断路器会再次打开。
图示解析
-
第一阶段:关闭状态:
- 发出请求,失败计数器为0。
- 发出请求,失败,计数器增加到1。
-
第二阶段:连续失败达到阈值:
- 再次发出请求,失败,计数器增加到2。
- 断路器进入打开状态。
-
第三阶段:打开状态:
- 在打开状态下,所有新请求都会立即失败,不会传递到服务。
总结
- 断路器模式类似于家里的电气断路器,可以保护系统免受连续故障的影响。
- 通过这种模式,可以避免服务因连续故障而崩溃,同时也可以在适当的时候检测服务是否恢复。
这样一来,当某个服务出现问题时,可以通过断路器模式及时切断请求,防止问题扩大,并在合适的时机重新尝试连接该服务,以确保系统的稳定性和可靠性。
3、如何理解如下代码 【from example10_11.py】
import asyncio from datetime import datetime, timedelta class CircuitOpenException(Exception): pass class CircuitBreaker: def __init__(self, callback, timeout: float, time_window: float, max_failures: int, reset_interval: float): self.callback = callback self.timeout = timeout self.time_window = time_window self.max_failures = max_failures self.reset_interval = reset_interval self.last_request_time = None self.last_failure_time = None self.current_failures = 0 async def request(self, *args, **kwargs): if self.current_failures >= self.max_failures: if datetime.now() > self.last_request_time + timedelta(seconds=self.reset_interval): self._reset('Circuit is going from open to closed, resetting!') return await self._do_request(*args, **kwargs) else: print('Circuit is open, failing fast!') raise CircuitOpenException() else: if self.last_failure_time and datetime.now() > self.last_failure_time + timedelta(seconds=self.time_window): self._reset('Interval since first failure elapsed, resetting!') print('Circuit is closed, requesting!') return await self._do_request(*args, **kwargs) def _reset(self, msg: str): print(msg) self.last_failure_time = None self.current_failures = 0 async def _do_request(self, *args, **kwargs): try: print('Making request!') self.last_request_time = datetime.now() return await asyncio.wait_for(self.callback(*args, **kwargs), timeout=self.timeout) except Exception as e: self.current_failures = self.current_failures + 1 if self.last_failure_time is None: self.last_failure_time = datetime.now() raise
这段代码实现了一个简单的断路器(Circuit Breaker)模式,用于在调用某个异步任务(如网络请求)时,检测到连续失败后阻止进一步的请求,并在一定时间后重置状态,尝试再次调用任务。让我们详细解释代码中的各个部分。
导入模块
import asyncio from datetime import datetime, timedelta
asyncio:用于处理异步任务。datetime和timedelta:用于处理时间和时间差。
自定义异常类
class CircuitOpenException(Exception): pass
CircuitOpenException:自定义异常类,当断路器处于打开状态时会抛出此异常。
断路器类
class CircuitBreaker: def __init__(self, callback, timeout: float, time_window: float, max_failures: int, reset_interval: float): self.callback = callback self.timeout = timeout self.time_window = time_window self.max_failures = max_failures self.reset_interval = reset_interval self.last_request_time = None self.last_failure_time = None self.current_failures = 0
初始化方法 __init__
callback:需要保护的异步任务(即将被调用的函数)。timeout:单个请求的超时时间。time_window:计算连续失败次数的时间窗口。max_failures:在时间窗口内允许的最大失败次数。reset_interval:断路器从打开状态到关闭状态的重置时间。last_request_time:上一次请求的时间。last_failure_time:上一次失败的时间。current_failures:当前的失败次数。
请求方法
async def request(self, *args, **kwargs): if self.current_failures >= self.max_failures: if datetime.now() > self.last_request_time + timedelta(seconds=self.reset_interval): self._reset('Circuit is going from open to closed, resetting!') return await self._do_request(*args, **kwargs) else: print('Circuit is open, failing fast!') raise CircuitOpenException() else: if self.last_failure_time and datetime.now() > self.last_failure_time + timedelta(seconds=self.time_window): self._reset('Interval since first failure elapsed, resetting!') print('Circuit is closed, requesting!') return await self._do_request(*args, **kwargs)
复杂部分详细解释
-
断路器打开时:
- 如果当前失败次数超过或等于最大失败次数 (
self.current_failures >= self.max_failures):- 检查当前时间是否超过了上一次请求时间加上重置间隔 (
datetime.now() > self.last_request_time + timedelta(seconds=self.reset_interval))。 - 如果超过了,说明断路器可以从打开状态重置到关闭状态,调用
_reset方法重置失败计数和时间,然后继续执行请求。 - 否则,断路器仍然处于打开状态,立即失败并抛出
CircuitOpenException异常。
- 检查当前时间是否超过了上一次请求时间加上重置间隔 (
- 如果当前失败次数超过或等于最大失败次数 (
-
断路器关闭时:
- 如果上一次失败时间不为空且当前时间超过了上一次失败时间加上时间窗口 (
datetime.now() > self.last_failure_time + timedelta(seconds=self.time_window)):- 调用
_reset方法重置失败计数和时间。
- 调用
- 断路器关闭,继续执行请求。
- 如果上一次失败时间不为空且当前时间超过了上一次失败时间加上时间窗口 (
重置方法
def _reset(self, msg: str): print(msg) self.last_failure_time = None self.current_failures = 0
- 重置失败计数和时间,并打印日志消息。
执行请求方法
async def _do_request(self, *args, **kwargs): try: print('Making request!') self.last_request_time = datetime.now() return await asyncio.wait_for(self.callback(*args, **kwargs), timeout=self.timeout) except Exception as e: self.current_failures = self.current_failures + 1 if self.last_failure_time is None: self.last_failure_time = datetime.now() raise
- 尝试执行请求并设置超时时间 (
asyncio.wait_for)。 - 如果请求成功,返回请求结果。
- 如果请求失败,增加失败计数,并设置或更新上一次失败时间,然后重新抛出异常。
总结
这段代码实现了一个基本的断路器模式,主要功能如下:
- 保护异步任务:在请求失败超过指定次数后,阻止进一步的请求,防止对系统造成更大压力。
- 自动重置:在一定时间后,断路器会自动重置,允许再次尝试请求。
- 异常处理:提供详细的异常处理和日志记录,方便调试和维护。
这种模式在分布式系统中非常有用,可以提高系统的稳定性和容错能力。
4、为什么最后一个函数,最后一行可以单独只写个raise?
async def _do_request(self, *args, **kwargs): try: print('Making request!') self.last_request_time = datetime.now() return await asyncio.wait_for(self.callback(*args, **kwargs), timeout=self.timeout) except Exception as e: self.current_failures = self.current_failures + 1 if self.last_failure_time is None: self.last_failure_time = datetime.now() raise
这个方法的主要作用是执行一个带有超时的异步请求,并在发生异常时更新失败计数和失败时间。我们来看一下 try 和 except 块中的代码。
try 块
print('Making request!'):打印日志消息,表示开始执行请求。self.last_request_time = datetime.now():记录请求的时间。return await asyncio.wait_for(self.callback(*args, **kwargs), timeout=self.timeout):执行实际的异步请求,并设置请求的超时时间。如果在指定的时间内请求没有完成,则引发asyncio.TimeoutError异常。
except 块
except Exception as e:捕获所有类型的异常。self.current_failures = self.current_failures + 1:增加当前失败次数。if self.last_failure_time is None: self.last_failure_time = datetime.now():如果这是第一次失败,记录失败时间。
为什么单独使用 raise
单独使用 raise 的含义是重新引发当前捕获的异常。这在异常处理代码中非常有用,因为它允许你在捕获异常后执行一些操作(例如记录日志、更新状态),然后重新引发异常,使其可以被上层调用代码处理。具体来说,这里发生的情况是:
- 异常被捕获到
except块中。 - 处理一些必要的操作,如增加失败次数并记录失败时间。
- 使用
raise重新引发原来的异常。
重新引发异常的语法有以下几个特点:
- 如果在
except块中直接使用raise,它会重新引发当前捕获的异常。 - 这种方式不会改变异常类型和原始堆栈信息,从而保留异常的上下文,便于调试。
通过一个具体的例子来解释单独使用 raise 的含义以及它是如何重新引发当前捕获的异常的。
举例说明
假设我们有一个函数 process_data,它试图读取一个文件并处理数据。
如果在读取文件时发生异常,我们希望捕获该异常,记录错误日志,并重新引发异常,以便调用者能够知道发生了什么。
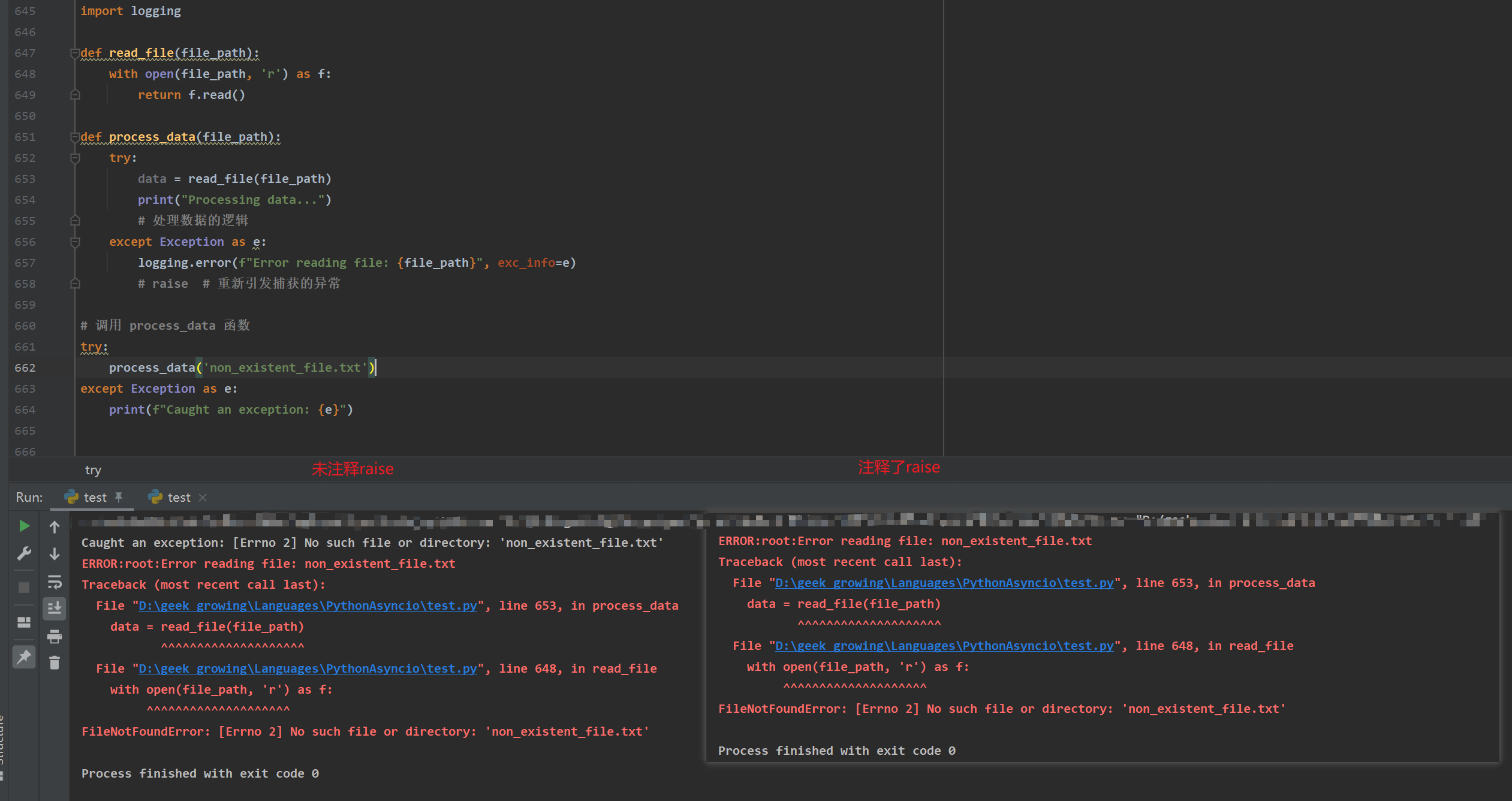
import logging def read_file(file_path): with open(file_path, 'r') as f: return f.read() def process_data(file_path): try: data = read_file(file_path) print("Processing data...") # 处理数据的逻辑 except Exception as e: logging.error(f"Error reading file: {file_path}", exc_info=e) raise # 重新引发捕获的异常 # 调用 process_data 函数 try: process_data('non_existent_file.txt') except Exception as e: print(f"Caught an exception: {e}")
详细解释
-
定义
read_file函数:read_file尝试打开并读取指定路径的文件。
-
定义
process_data函数:process_data调用read_file读取文件。- 使用
try...except块捕获所有异常。
-
捕获异常:
- 如果
read_file抛出异常(例如文件不存在),异常将被except块捕获。 - 在
except块中,记录错误日志。
- 如果
-
重新引发异常:
raise关键字在except块中单独使用。raise重新引发刚刚捕获的异常(例如FileNotFoundError)。
-
调用
process_data:- 在调用
process_data的try...except块中捕获重新引发的异常并打印。
- 在调用
运行结果
执行上述代码时,read_file('non_existent_file.txt') 会引发 FileNotFoundError。
此异常被 process_data 的 except 块捕获并记录日志,然后使用 raise 重新引发异常。外部的 try...except 块捕获到重新引发的异常并打印出异常信息。
总结
raise单独使用时重新引发当前捕获的异常。- 重新引发异常保留了原始的异常类型和堆栈信息,方便上层代码进一步处理。
- 这种方式常用于捕获异常后进行一些处理(如日志记录),然后让上层代码知道发生了异常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号