
Fluent Python2 【Chapter3_QA】
1. 如何理解sys.argv
这是在test.py脚本写下的内容
import sys print(sys.argv) # 这一行terminal中不会显示,只会在run下显示(运行结果)
# sys.argv其实就是个list, sys.argv的打印结果为:所执行的脚本所在的绝对目录: D:/xx/xx/FluentPython2/test.py
print(sys.argv[0]) # 返回 test.py
print(sys.argv[1]) # 返回 parm1
print(sys.argv[2]) # 返回 parm2,后面若还有其他参数, 逻辑以此类推
这是在pycharm命令行中执行的命令
(FluentPython2Env) D:\xx\xx\FluentPython2>python test.py parm1 parm2 ['test.py', 'parm1 ', 'parm2'] test.py parm1 parm2
2.正则表达式库re, 里面的group方法的理解
简单理解就是通过正则表达式提取出 括号 ( ) 里的内容,这个括号里的内容叫做捕获组
正则表达式中的 group() 方法用于从匹配的字符串中获取捕获组的值。捕获组是指使用圆括号()在正则表达式模式中定义的子模式。
这个方法的一般用法是:
match_obj.group(group_index)
其中 match_obj 是 re.match() 或 re.search() 方法的返回值,表示匹配到的对象。group_index 是要获取的捕获组的索引,默认为 0,表示整个匹配的字符串。
让我们通过一些例子来理解:
import re # 没有捕获组 pattern = r'\d+' match = re.match(pattern, "Number: 42") print(match.group()) # 输出: 42 # 一个捕获组 pattern = r'(\d+)' match = re.match(pattern, "Number: 42") print(match.group(0)) # 输出: 42 (整个匹配) print(match.group(1)) # 输出: 42 (第一个捕获组) # 多个捕获组 pattern = r'(\d+)/(\d+)/(\d+)' match = re.match(pattern, "2023/04/01") print(match.group(0)) # 输出: 2023/04/01 (整个匹配) print(match.group(1)) # 输出: 2023 (年份) print(match.group(2)) # 输出: 04 (月份) print(match.group(3)) # 输出: 01 (日期)
在上面的例子中:
match.group()或match.group(0)返回整个匹配的字符串。match.group(1)返回第一个捕获组的值。match.group(2),match.group(3)等依次返回后续捕获组的值。
捕获组在提取模式中的特定部分时特别有用,例如从一个日期字符串中提取年、月、日等信息。它们还可以用于替换操作,将匹配的子模式替换为其他内容。
总的来说,group() 方法让你可以从匹配的字符串中灵活地获取你所需的部分,使正则表达式的功能更加强大和实用。
3. re.compile()的理解
re.compile() 是Python中的一个内置函数,用于编译正则表达式模式,并返回一个正则表达式对象。这个对象可以被多次重复使用,从而提高性能。
在Python中使用正则表达式有两种主要方式:
- 直接使用正则表达式字符串
import re pattern = r'\d+' match = re.match(pattern, "Number: 42")
在这种情况下,每次调用 re.match() 或 re.search() 时,都会重新编译正则表达式模式。如果你需要多次使用同一个模式,这种方式会降低效率。
- 使用
re.compile()预编译正则表达式
import re pattern = re.compile(r'\d+') match = pattern.match("Number: 42")
通过 re.compile() 函数,Python会首先编译一次正则表达式模式,并返回一个正则表达式对象。以后每次使用这个对象时,就不需要重新编译模式了,从而提高了性能。
为什么要使用 re.compile()?
- 提高性能: 如果需要多次使用同一个正则表达式模式,预编译可以显著提高执行速度。
- 代码可读性: 将正则表达式模式封装在一个变量中,使代码更易于阅读和维护。
- 添加标志位:
re.compile()允许你添加额外的标志位,比如re.IGNORECASE用于忽略大小写匹配。
让我们看一个例子:
import re # 不使用 re.compile() text = "Hello, 123, world, 456" matches = re.findall(r'\d+', text) print(matches) # 输出: ['123', '456'] # 使用 re.compile() pattern = re.compile(r'\d+') matches = pattern.findall(text) print(matches) # 输出: ['123', '456'] # 使用标志位 pattern = re.compile(r'[a-z]+', re.IGNORECASE) text = "Hello, World" matches = pattern.findall(text) print(matches) # 输出: ['Hello', 'World']
在上面的例子中,我们首先直接使用正则表达式字符串查找所有数字。然后,我们使用 re.compile() 预编译了一个模式对象,并使用它来执行相同的查找操作。最后,我们使用 re.IGNORECASE 标志位来忽略大小写进行匹配。
总的来说, re.compile() 可以让你预编译正则表达式模式,提高性能和可读性,并且允许你设置额外的标志位。当你需要多次使用同一个模式时,它是一个非常有用的工具。
4. setdefault方法的理解和使用
5. defalutdict()函数的概念、作用理解
defaultdict是Python内置的一个数据类型,它继承于dict类,是dict的一个子类。它的作用是当一个key不存在于字典中时, 返回一个默认值,而不会像常规字典那样抛出KeyError异常。这可以很大程度上简化操作字典的代码。
概念:
defaultdict使用一个工厂函数来为非存在的键提供一个默认值。当我们尝试获取或设置一个不存在的键时,defaultdict会调用工厂函数来创建一个默认的实例(如列表、集合等)作为该键的值。
作用:
defaultdict常常用于处理嵌套字典(如分组字典或计数等应用场景)。使用defaultdict可以避免因为不小心尝试访问不存在的键而抛出KeyError异常,从而简化代码。
用法示例:
defaultdict(int)用于计数:
from collections import defaultdict word_counts = defaultdict(int) text = "hello world hello python" for word in text.split(): word_counts[word] += 1 print(word_counts) # Output: defaultdict(<class 'int'>, {'hello': 2, 'world': 1, 'python': 1})
在上面的例子中,每次遇到新的单词时,defaultdict会自动创建一个值为0的键值对,这样就不会抛出KeyError异常了。
defaultdict(list)用于分组:
from collections import defaultdict groups = defaultdict(list) students = [ {"name": "Alice", "grade": 9}, {"name": "Bob", "grade": 10}, {"name": "Charlie", "grade": 9}, {"name": "David", "grade": 10}, ] for student in students: groups[student["grade"]].append(student["name"]) print(groups) # Output: defaultdict(<class 'list'>, {9: ['Alice', 'Charlie'], 10: ['Bob', 'David']})
在上面的例子中,defaultdict(list)为每个新的年级自动创建了一个空列表,从而避免了手动初始化字典的步骤。
关于defaultdict(list):
defaultdict(list)在创建新的键时会自动为该键赋予一个新的空列表作为默认值。这在处理嵌套列表或者分组数据时非常有用。例如:
from collections import defaultdict nested_dict = defaultdict(list) nested_dict["colors"].append("red") nested_dict["colors"].append("green") nested_dict["numbers"].append(1) nested_dict["numbers"].append(2) print(nested_dict) # Output: defaultdict(<class 'list'>, {'colors': ['red', 'green'], 'numbers': [1, 2]})
在上面的例子中,我们不需要事先创建colors和numbers这两个键,defaultdict(list)会在第一次尝试访问这些键时自动创建对应的空列表,从而避免了手动初始化列表的步骤。
总之,defaultdict提供了一种简洁高效的方式来处理缺失键的情况,使代码更加整洁、易读。它在处理嵌套字典、分组数据、计数等场景中非常实用。
6. 关于__missing__方法的理解
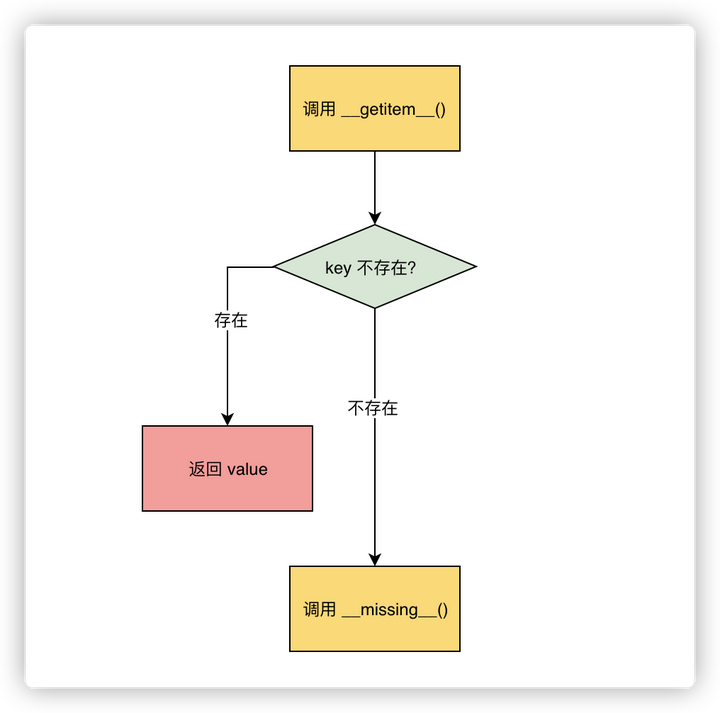
class TestDict(dict): def __getitem__(self, key): print('call __getitem__') return super().__getitem__(key) def __missing__(self, key): print('call __missing__') raise KeyError(f'key {key} not exist') d = TestDict() print('set "a" to apple') d['a'] = 'apple' print('get "a"') print('d["a"] -> ', d['a']) print('get "b"') print('d["b"] -> ', d['b'])
返回结果如下
set "a" to apple get "a" call __getitem__ d["a"] -> apple get "b" call __getitem__ call __missing__ Traceback (most recent call last): File "D:\xx\xx\FluentPython2\test.py", line 2140, in <module> print('d["b"] -> ', d['b']) File "D:\xx\xx\FluentPython2\test.py", line 2126, in __getitem__ return super().__getitem__(key) File "D:\xx\xx\FluentPython2\test.py", line 2130, in __missing__ raise KeyError(f'key {key} not exist') KeyError: 'key b not exist'
参考博客:dict.__missing__魔术方法
7. 如下代码中的dict(*args, **kwargs)的理解,和测试用例设计
class SimpleMappingSub(abc.Mapping): def __init__(self, *args, **kwargs): self._data = dict(*args, **kwargs)
对于 dict(*args, **kwargs) 这种构造方式,可以使用任意数量的位置参数和关键字参数来构建字典。
1) 只使用位置参数:
下面是一些示例输入数据的构造方法:
data = dict([('a', 1), ('b', 2), ('c', 3)]) # 只使用位置参数其实注意加上个 [] 就好 # 这将创建一个包含三个键值对的字典 {'a': 1, 'b': 2, 'c': 3}
2) 只使用关键字参数:
data = dict(a=1, b=2, c=3) # 这将创建一个包含三个键值对的字典 {'a': 1, 'b': 2, 'c': 3}
3) 结合位置参数和关键字参数:
data = dict([('a', 1), ('b', 2)], c=3) # 这将创建一个包含三个键值对的字典 {'a': 1, 'b': 2, 'c': 3}
你可以根据函数的要求,构造适合的输入数据。
8. 请理解并解释下为什么如下代码会递归报错
class DictSub(dict): def __missing__(self, key='default'): return self[key] ds = DictSub(d=4, e=5) print(ds['f']) Traceback (most recent call last): File "D:\xx\xx\FluentPython2\test.py", line 2154, in <module> print(ds['f']) File "D:\xx\xx\FluentPython2\test.py", line 2150, in __missing__ return self[key] File "D:\xx\xx\FluentPython2\test.py", line 2150, in __missing__ return self[key] File "D:\xx\xx\FluentPython2\test.py", line 2150, in __missing__ return self[key] [Previous line repeated 496 more times] RecursionError: maximum recursion depth exceeded Process finished with exit code 1
这个代码出现递归报错的原因是由于在 __missing__ 方法中,当字典中不存在某个键时,它试图通过 self[key] 的方式再次访问字典,这将再次调用 __missing__ 方法,从而产生无限递归的情况。
让我们通过以下几个步骤来详细解释:
- 首先,我们定义了一个名为
DictSub的类,它继承自dict类。 - 在这个类中,我们重写了
__missing__方法。该方法在字典中不存在某个键时被调用。 - 在
__missing__方法中,我们返回self[key]。这个语句试图从字典中获取值。 - 当我们创建一个
DictSub的实例ds,并尝试访问不存在的键'f'时,Python 会调用__missing__方法。 - 在
__missing__方法中,它试图通过self[key]的方式获取值。但由于键'f'不存在,Python 会再次调用__missing__方法。 - 这个过程会一直重复下去,导致无限递归。每次调用
__missing__方法时,它都会再次尝试访问不存在的键,从而再次调用__missing__方法。 - Python 有一个最大递归深度的限制,一旦超过这个限制,它会引发
RecursionError异常。
为了解决这个问题,我们需要在 __missing__ 方法中提供一个默认值或者采取其他合适的操作。例如,我们可以修改 __missing__ 方法如下:
class DictSub(dict): def __missing__(self, key): # 返回一个默认值或执行其他操作 return 'Value not found' ds = DictSub(d=4, e=5) print(ds['f']) # 输出: Value not found
在上面的例子中,当字典中不存在某个键时,__missing__ 方法会返回一个默认值 'Value not found',从而避免了无限递归的情况。
9. 为什么如下代码 绝不会被类的实例,调用__missing__方法?
class SimpleMappingSub(abc.Mapping): def __init__(self, *args, **kwargs): self._data = dict(*args, **kwargs) # next three methods: abstract in ABC def __getitem__(self, key): return self._data[key] def __len__(self): return len(self._data) def __iter__(self): return iter(self._data) # never called by instances of this class def __missing__(self, key): return self[_upper(key)]
这段代码中的 __missing__ 方法永远不会被类的实例调用,主要原因是:
__missing__方法是用于处理在字典(dict)类型中不存在的键的情况。它是Python中dict类的一个特殊方法。- 在这个代码中,
SimpleMappingSub类继承自abc.Mapping抽象基类,而不是继承自dict类。 abc.Mapping是Python中用于定义不可变映射(Mapping)接口的抽象基类,它没有实现__missing__方法。- 因此,在
SimpleMappingSub类中实现了__getitem__方法来处理不存在的键,而不是使用__missing__方法。当试图访问一个不存在的键时,Python会首先尝试调用__getitem__方法,如果在该方法中没有处理缺失的键,则会引发KeyError异常。 - 所以,在
SimpleMappingSub类的实例中,永远不会调用__missing__方法,因为该方法是专门为dict类及其子类设计的。
如果你想在 SimpleMappingSub 类中处理缺失的键,你应该在 __getitem__ 方法中进行处理,而不是使用 __missing__ 方法。例如:
def __getitem__(self, key): try: return self._data[key] except KeyError: # 处理缺失的键 return 'Default value'
在这个例子中,如果键不存在,__getitem__ 方法会捕获 KeyError 异常,并返回一个默认值。这样就可以在不引发异常的情况下处理缺失的键。
10. .get()和.__getitem__()方法,有何区别?.get()函数是调用的__get__() 还是__getittem__()? 【特别容易混淆】
get() 和 __getitem__() 是两个不同的方法,它们在 Python 中具有不同的用途和行为。
__getitem__(self, key)方法:- 这是 Python 中的一个特殊方法,用于实现对象的下标访问操作,例如
obj[key]。 - 当您尝试访问对象的某个键时,Python 会自动调用
__getitem__方法。 - 如果在
__getitem__方法中没有处理缺失的键,那么它会引发KeyError异常。
- 这是 Python 中的一个特殊方法,用于实现对象的下标访问操作,例如
get(self, key, default=None)方法:- 这是
dict类中的一个内置方法,用于获取字典中指定键对应的值。 - 如果键存在,它会返回该键对应的值。
- 如果键不存在,它会返回传入的默认值,而不会引发任何异常。
- 这是
当您调用 obj.get(key) 时,Python 实际上是在调用 obj.__get__(key) 方法。这是因为 Python 会自动将点操作符 (.) 解释为调用对象的 __get__ 方法。
但是,在大多数情况下,__get__ 方法是由 descriptor 协议中的描述符类来实现的,而不是由普通的对象类来实现。因此,对于大多数内置类型和自定义类,调用 obj.get(key) 实际上会调用 obj.__getitem__(key) 方法。
具体来说:
- 对于
dict类及其子类,get方法直接调用__getitem__方法来获取值,如果键不存在,则返回默认值。 - 对于其他类型,例如
list、tuple等,它们没有实现get方法,因此调用obj.get(key)会引发AttributeError异常。您应该使用obj[key]或__getitem__(key)来访问它们的元素。
总的来说,get 方法提供了一种更安全的方式来访问字典中的值,因为它不会在键不存在时引发异常。而 __getitem__ 方法则用于实现对象的下标访问操作,如果键不存在,它会引发 KeyError 异常。在处理缺失的键时,您可以选择使用哪种方式,这取决于您的具体需求。
11. 对于 missing.py 的最后一对例子, 为什么一个返回True, 一个返回False?
class SimpleMappingSub(abc.Mapping): def __init__(self, *args, **kwargs): self._data = dict(*args, **kwargs) # next three methods: abstract in ABC def __getitem__(self, key): return self._data[key] def __len__(self): return len(self._data) def __iter__(self): return iter(self._data) # never called by instances of this class def __missing__(self, key): return self[_upper(key)] class MappingMissingSub(SimpleMappingSub): def __getitem__(self, key): # .get()方法,调用的是 __getitem__() try: return self._data[key] except KeyError: print('MappingMissingSub __getitem__ call') return self[_upper(key)] class DickLikeMappingSub(SimpleMappingSub): def __getitem__(self, key): try: return self._data[key] except KeyError: return self[_upper(key)] def get(self, key, default=None): return self._data.get(key, default) def __contains__(self, key): return key in self._data mms = MappingMissingSub(A='letter A') print('a' in mms) # True dms = DickLikeMappingSub(A='letter A') print('a' in dms) # False
对于为什么 'a' in mms 和 'a' in dms 返回的结果不同,主要原因在于它们是如何实现 __contains__ 方法的。
在 Python 中,当你使用 key in obj 这种形式来检查一个键是否存在于对象中时,Python 实际上是在调用对象的 __contains__ 方法。
(1) 对于 MappingMissingSub 类(mms)来说,它继承自 SimpleMappingSub类,而 SimpleMappingSub 又继承自 abc.Mapping。由于 MappingMissingSub 没有重写 __contains__ 方法,因此它使用的是 abc.Mapping 中的 __contains__ 方法的默认实现。
在 abc.Mapping 的 __contains__ 方法中,它是通过调用 __getitem__ 方法来检查键是否存在的。如果 __getitem__ 方法没有引发 KeyError 异常,则认为键存在。
因此,对于 'a' in mms来说,它实际上是在调用 mms['a']。由于 MappingMissingSub 重写了 __getitem__ 方法,当键 'a' 不存在时,它会尝试获取大写键 'A' 对应的值。由于 'A' 存在于 self._data 中,因此 'a' in mms 返回 True。
(2) 而对于 DictLikeMappingSub 类(dms)来说, 'a' in dms:
DictLikeMappingSub类重写了__contains__方法。- 在
__contains__方法中,它直接检查键'a'是否在self._data字典中。 - 由于
'a'不在self._data中,所以'a' in dms返回False。
12. dict.fromkeys()这个方法的作用理解
dict.fromkeys(seq, value=None) 是Python内置的字典方法,它用于从序列 seq 创建一个新的字典。这个方法的作用主要有两点:
- 创建新字典
fromkeys 方法将 seq 中的元素作为新字典的键,使用 value 参数作为所有键对应的初始值。例如:
new_dict = dict.fromkeys(['a', 'b', 'c'], 0) # new_dict = {'a': 0, 'b': 0, 'c': 0}
- 初始化字典值
通常在需要从一个序列初始化一个字典时使用,可以快速地用相同的值初始化字典中所有键对应的值。
keys = [1, 2, 3] default_value = [] new_dict = dict.fromkeys(keys, default_value) # new_dict = {1: [], 2: [], 3: []}
注意如果没有提供 value 参数,则所有键对应的值都将是 None。
new_dict = dict.fromkeys(['a', 'b']) # new_dict = {'a': None, 'b': None}
另外,fromkeys 常用于从字符串中快速创建一个计数字典。
string = "hello" count = dict.fromkeys(string, 0) # count = {'h': 0, 'e': 0, 'l': 0, 'o': 0}
总的来说, dict.fromkeys 提供了一种快捷的方式从序列数据创建字典,并初始化字典中所有值。
13. python中说调用构造函数 例如set([1,2,3]),应该如何理解
在Python中,构造函数(constructor)通常指的是__new__和__init__这两个特殊方法的组合。
但是,当我们调用像set([1, 2, 3])这样的写法时,我们实际上是在调用set类的__init__方法,而不是__new__方法。这是因为Python在创建对象时,会先调用__new__方法来创建对象,然后再调用__init__方法来初始化对象。
对于不可变类型(immutable types)如str、int、tuple等,我们几乎从不需要去重写__new__方法,因为Python会为我们优化这个过程。而对于可变类型(mutable types)如list、dict、set等,我们通常只需重写__init__方法就可以了。
所以,当您调用set([1, 2, 3])时,实际上Python是这样做的:
- 调用
set.__new__(set)创建一个新的空集合对象 - 调用
set.__init__(new_set, [1, 2, 3])来初始化这个新集合对象,将[1, 2, 3]这个列表转换为集合
因此,在大多数情况下,我们说set([1, 2, 3])是在调用构造函数,实际上是在调用__init__方法而已。除非您要自定义一个新的类,并重写__new__方法,否则通常不需要关心__new__方法的细节。
14. 加盐哈希概念的理解
加盐哈希(salting hashes)是一种密码存储和验证的安全实践,它通过在哈希计算中引入一个随机数据(盐值),来增加密码被暴力破解的难度。下面是对加盐哈希概念、作用和实现方式的解释:
- 什么是加盐哈希?
加盐哈希就是在哈希计算之前,先将密码与一个随机生成的字符串(盐值)进行拼接,再对这个组合字符串进行哈希运算。这样即使不同用户使用相同的密码,由于盐值不同,计算出的哈希值也是不同的。
- 加盐哈希的作用
- 防止相同密码的哈希值相同:由于盐值的引入,使得即使相同的密码,计算出的哈希值也是不同的,从而增加攻击者破解的难度。
- 防止预计算哈希表攻击:由于不同用户的盐值不同,攻击者无法预先计算出一个密码哈希表,再对存储的哈希值进行查表匹配。
- 避免暴力破解时所有记录同步解密:如果不加盐,攻击者破解一个密码后,可应用于所有其他相同哈希值。加盐后,需要分别破解每个记录。
- 通俗解释和示例
想象一下,密码是房子的大门钥匙,哈希就像是把钥匙压扁变形,生成一个无法直接推导出钥匙的复杂形状。而加盐就相当于在钥匙上先系一个不同的钥匙扣,再将钥匙压扁。即使两个人使用了一模一样的钥匙(密码),由于钥匙扣(盐值)不同,压扁后的形状(哈希值)也不一样了。
# 不加盐哈希 pwd1 = "hello123" pwd2 = "hello123" hash1 = hash(pwd1) hash2 = hash(pwd2) print(hash1 == hash2) # True,相同密码的哈希值相同 # 加盐哈希 import hashlib, os salt1 = os.urandom(32) # 生成32字节随机盐值 salt2 = os.urandom(32) # 生成另一个盐值 pwd1 = "hello123" pwd2 = "hello123" # 将盐和密码拼接后再哈希 digest1 = hashlib.pbkdf2_hmac('sha256', pwd1.encode(), salt1, 100000) digest2 = hashlib.pbkdf2_hmac('sha256', pwd2.encode(), salt2, 100000) print(digest1 == digest2) # False,盐值不同导致哈希值不同
在上述hashlib.pdkdf2_hmac这个API中,这个API hashlib.pbkdf2_hmac('sha256', pwd1.encode(), salt1, 100000)。
这是Python标准库hashlib模块中的pbkdf2_hmac函数,它用于执行"基于密码的密钥derivation函数2"(Password-Based Key Derivation Function 2, PBKDF2)加盐哈希运算。
这个函数的签名是:
hashlib.pbkdf2_hmac(hash_name, password, salt, iterations, dklen=None)
各个参数的含义是:
hash_name: 指定用于PBKDF2的哈希算法,如'sha256'、'sha512'等。password: 要进行哈希的密码,通常是字节串。这里使用pwd1.encode()将字符串转为字节串。salt: 盐值,一个任意的字节串,用于加盐。这里使用os.urandom(32)生成32字节长度的随机字节串作为盐。iterations: PBKDF2算法的迭代次数,设置越大,耗时越长,但安全性也越高。这里设置为100000次。dklen: 可选参数,指定导出的密钥的长度。如果不指定,则根据所使用的哈希算法而定。
该函数的返回值是一个字节串,就是最终计算出的哈希值。
PBKDF2算法本质上是对原始密码通过大量重复哈希运算,并且每次都使用之前的哈希值再重新计算,这个过程迭代执行iterations次。同时引入了随机的salt值,使得相同密码的最终哈希值不同。
这种算法相对于简单哈希函数,耗时更长,但能极大提高暴力破解的难度。在密码学领域,PBKDF2因其设计合理而被广泛采用,成为存储密码哈希值的推荐算法。
总的来说,这段代码使用sha256哈希算法,对密码字符串pwd1加上随机盐值salt1,执行100000次PBKDF2迭代计算,最终产生一个加盐的密码哈希值。
14. .fromfile() .tofile() 方法的含义是什么?
.fromfile() 方法通常用于从【文件】中读取数据并将其加载【到】【内存】中。它是许多 Python 库(如 NumPy 和 PIL 等)中常见的方法之一。
具体来说,.fromfile() 方法允许用户从文件中读取二进制数据,并将其转换为适当的数据结构,例如数组、图像等,以便在程序中进行进一步处理或分析。通常,用户可以指定数据的格式、大小、偏移量等参数,以确保正确地读取文件并解析数据。
例如,在 NumPy 库中,可以使用 .fromfile() 方法从二进制文件中读取数据并创建 NumPy 数组:
import numpy as np # 从文件中读取数据并创建 NumPy 数组 data = np.fromfile('data.bin', dtype=np.float64)
这将从名为 'data.bin' 的文件中读取数据,并将其解释为 64 位浮点数数组。
.tofile() 方法通常用于将数据从【内存】中写入【到】【文件】中。它是许多 Python 库(如 NumPy 和 PIL 等)中常见的方法之一。
具体来说,.tofile() 方法允许用户将数据结构(例如数组、图像等)中的数据写入到文件中,以便将其保存到磁盘上以供后续使用。
例如,在 NumPy 库中,可以使用 .tofile() 方法将 NumPy 数组中的数据写入到二进制文件中:
import numpy as np # 创建一个 NumPy 数组 data = np.array([1, 2, 3, 4, 5]) # 将数据写入到文件中 data.tofile('output.bin')
这将创建一个名为 'output.bin' 的二进制文件,并将数组 data 中的数据以二进制形式写入其中。
15. 为什么这个maxsize+1后,还是能在pycharm中打印出,并不报错呢?不是已经到了最大吗?
import sys print(sys.maxsize) num = 9223372036854775807 + 1 print(num)
在Python中, sys.maxsize 表示的是 Python 整数对象所能表示的最大正整数值。在64位 Python 中,这个值为 9223372036854775807。
但是,Python 的整数实际上没有固定的存储大小限制,它使用了一种被称为 "无限精度整数" 的实现,可以表示任意大小的整数,只要系统内存足够。
所以,当您执行 num = 9223372036854775807 + 1 时,Python 会自动分配更多的内存来存储这个超过 sys.maxsize 的值。这就是为什么您可以在 PyCharm 中成功打印出 9223372036854775808 这个更大的整数值,而不会引发任何错误。
Python 的这种无限精度整数实现,使得它可以处理任意大小的整数,只受系统可用内存的限制。这一点不同于像 C 语言这样的语言,在 C 语言中整数有固定的存储大小,一旦超过最大值就会导致溢出错误。
所以,虽然 sys.maxsize 确实代表了 Python 整数对象的一个界限,但并不是绝对的上限,您仍然可以处理更大的整数值。这使得 Python 在进行大数运算时更加方便和灵活。
16. 如下代码 hashdiff.py的return表达式如何理解?
import sys MAX_BITS = len(format(sys.maxsize, 'b')) print(f'{MAX_BITS + 1}-bit Python build') def hash_diff(o1, o2): h1 = f'{hash(o1):>0{MAX_BITS}b}' h2 = f'{hash(o2):>0{MAX_BITS}b}' diff = ''.join('!' if b1 != b2 else ' ' for b1, b2 in zip(h1, h2)) count = f'!= {diff.count("!")}' width = max(len(repr(o1)), len(repr(o2)), 8) sep = '-' * (width * 2 + MAX_BITS) return (f'{o1!r:{width}} {h1}\n
{" ":{width}} {diff} {count}\n' f'{o2!r:{width}} {h2}\n
{sep}') if __name__ == '__main__': print(hash_diff(1, 1.0)) print(hash_diff(1.0, 1.0001)) print(hash_diff(1.0001, 1.0002)) print(hash_diff(1.0002, 1.0003))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号