redis zset源码
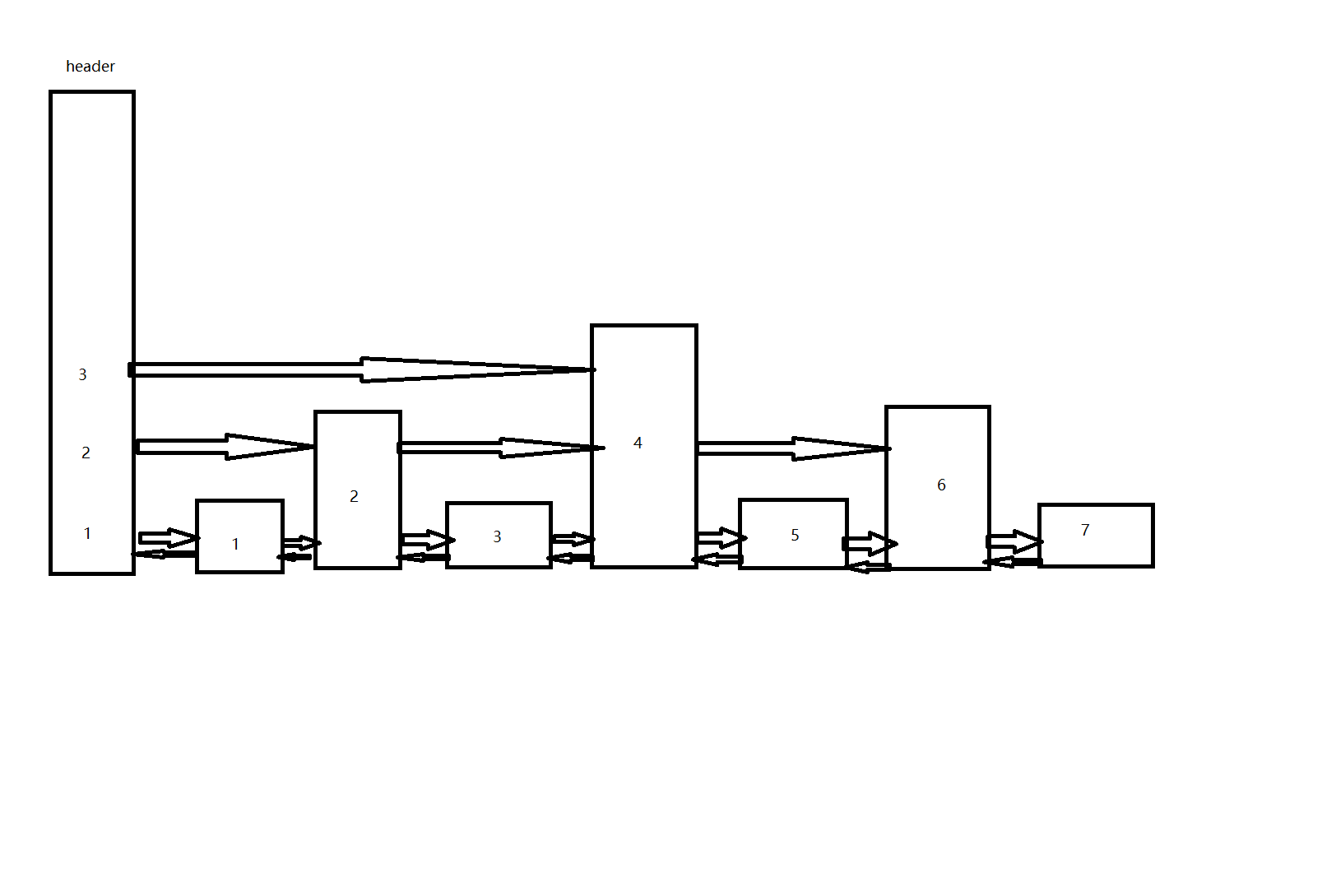
zset底层是由hash字典和跳表实现的,字典存储member->分数的映射关系,这样根据membe查询score的 时间复杂度O为1
跳表可以理解为多个层级的有序链表,每个节点可能在不同层级上,通过在不同层级的跳跃查找,把查询时间复杂度降低到 Olgn
1.随机层数,只有0.25的概率升级层数,最多64层
50%概率分配到第一层,25%概率分配到第二层。。
2.查找过程:
从最高层级开始查找,找到最后一个比查找元素小的节点,然后降一级,再次查找,直到找到改元素
例如,查找3
先从最高层开始找,发现4>3, 不满足,降低一层
从第二层开始找,发现2<3,满足,跨度=2,rank+=2;接着 2的下一个节点是4,4>3,不满足,降低一层,
从节点2的第一层开始找,3=3,满足,跨度=1,所以rank=3
- 结构体定义
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; // member
double score;
struct zskiplistNode *backward; // 回溯指针,只有第一层才有值
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[]; // 层级节点数组
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头尾指针
unsigned long length;
int level; // 跳表层数
} zskiplist;
typedef struct zset {
dict *dict; // 字典,member->score 映射关系
zskiplist *zsl; // 跳表结构
} zset;
- 方法列表
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 初始化每一层,最多64层
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
#define ZSKIPLIST_MAXLEVEL 64 /* Should be enough for 2^64 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
// 生成随机层数
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
// 跳表插入元素
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele)
// 查找某个元素的排名
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号