- 程序结构分析
- 第一次作业
- 思路分析
第一次作业需要实现多项式的展开,开始设计之前考虑了教程中正则表达式匹配和递归下降的方法。由于parser当时感觉难以理解,最终选择了正则表达式匹配的处理方法。
另一大问题就是多个相邻加减号的处理问题,这个我选择在Expression类中每当找到下一个匹配项时遍历上一个匹配项尾到这个匹配项头的减号个数来确定是加还是减。这个思想在本单元的3次作业中均得到了沿用
- 结构分析
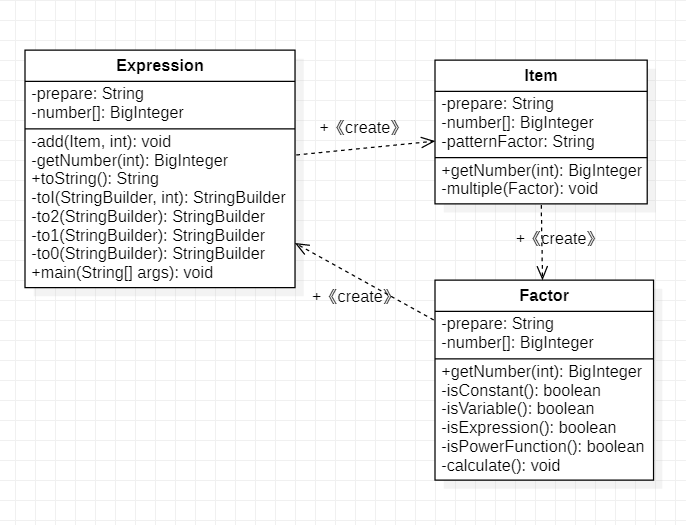
可以看出其中一共定义了3个类,类之间没有继承关系。
核心思路是每个类在创建的时候即完成内部计算,并将结果存入number中(number[i]的值表示)Expression类负责传入初始表达式并通过正则表达式匹配将其拆分成多个项,逐个调用项的getNumber并与之相加。Item也同样将其切分为多个Factor,并传入Factor类,将Factor的值相乘。Factor类负责判断传入的是什么类型的因子,并将对应参数的多项式值返回(或递归回Expression)。
最后main函数中调用最初Expression的toString方法完成输出(Expression中的toI、to2、to1、to0为输出化简时使用的,化简有较多的if-else逻辑,故针对指数不同氛围了多个方法)
- 度量分析
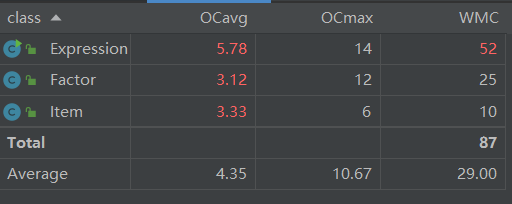

可以看出,认知复杂度(CogC)最高的几个方法都是化简时使用的方法,这几个方法嵌套在Expression的toString中,耦合度极高。除此之外,Factor的构造方法的判定结构复杂度(v(G))和设计复杂度(Iv(G))较高,是因为将所有的不同因子的判定都放入了这一类中。
- 优点
- 代码逻辑简单清晰,易于梳理思路,本地测试时面对大数据也能很快定位问题。
- 缺点
- 因为使用了一个正则表达式去匹配所有的因子可能性,正则表达式可读性极差且需要大量测试寻找可能出现的问题,可扩展性差。
- 由于将判断都写在了构造方法中,导致构造方法冗长,如果debug的时候某模块还在初始化,就无法通过toString的显示快速判断这块是否出现问题。
- 使用数组来存储时乘法的计算过于繁琐且时间复杂度很高,且当系数增大之后完全没有可扩展性的可能。
- bug分析
第一次作业的强测和互测我都没有出现bug,也许是因为本地测试的时候充分测试了正则表达式的正确性。在互测中也没有找到别人的bug。但互测结束之后观察了本房找到的3个bug之后,发现bug出现的原因一般是对于带符号数的处理问题以及化简过程出现的bug,前者或许是对于指导书的不仔细,后者大概是在(类似我这样)很大复杂度的化简过程中的一点纰漏。怎样进行逻辑清晰的化简也变得非常有必要。
- 第二、三次作业
- 思路分析
第二次作业允许了自定义函数和求和函数的出现,这为因子解析带来了更多的可能,并且从语法上产生了括号嵌套,这导致了第一次作业的分割方式已经不适合第二次作业,故进行了一定范围的重构。
由于允许非多余括号出现的机制带来了不明数量的括号嵌套,而括号嵌套是不正则的,没有办法用正则表达式提取项和因子的,所以选择了利用类似栈的思想,将项以不在括号内的加减运算符拆开,替换**为^后将因子以不在括号内的*拆开,这一点让我在遇到第三次作业时几乎不用进行任何改动。
对于自定义函数,我一开始就选择了通过新增一个Transformer类对输入进行预处理,将自定义函数作字符串替换的做法(后来听助教说不建议这么用,但我代码已经成型了也就懒得改了qwq),而且因为我是逐个函数扫描替换的,这也就导致了对于第三次作业的函数嵌套/递归调用也都能很好的处理,不用进行修改。
关于求和函数,与自定义函数相同,但是苦于展开后字符串可能过长,就在因子解析时的求和循环内部对i做字符串替换。
由于三角因子和允许大于8的指数的出现,显然第一次作业使用数组的存储方式已经不适合这次作业,我使用了Hashmap<Integer, BigInteger>来存储不带三角因子的项,使用Hashmap<Hashmap<String, Integer>, Hashmap<Integer, BigInteger>>的嵌套Hashmap存储三角因子及其多项式因子,这一存储方式能够对含三角的多项式做最基本的简化。
三角函数的内部我采用了将其视为一个新表达式进行处理,并使用Expr的toString直接返回内部化简后的值给外层函数写入String,当时的本意是为了提高三角函数内部的可扩展性,意外解决了第三次作业的三角嵌套问题。
此外,在第一次互测的时候看别人的代码发现设置一个主类可以使结构更加清晰且方便调试,第二次作业也使用了主类来容纳main函数。
- 结构分析


与第一次作业相同,每个类都在刚初始化阶段即完成所有的处理和运算,并将结果存入两个Hashmap中,外层对象只需调用其get方法即可获取其内部计算后的值,并按照相应运算逻辑进行计算。
关于计算的模块化,我将两个多项式map的乘法和加法创建一个private方法进行计算,在最终计算的时候只需要遍历三角map并分别调用多项式相乘即可。
- 度量分析
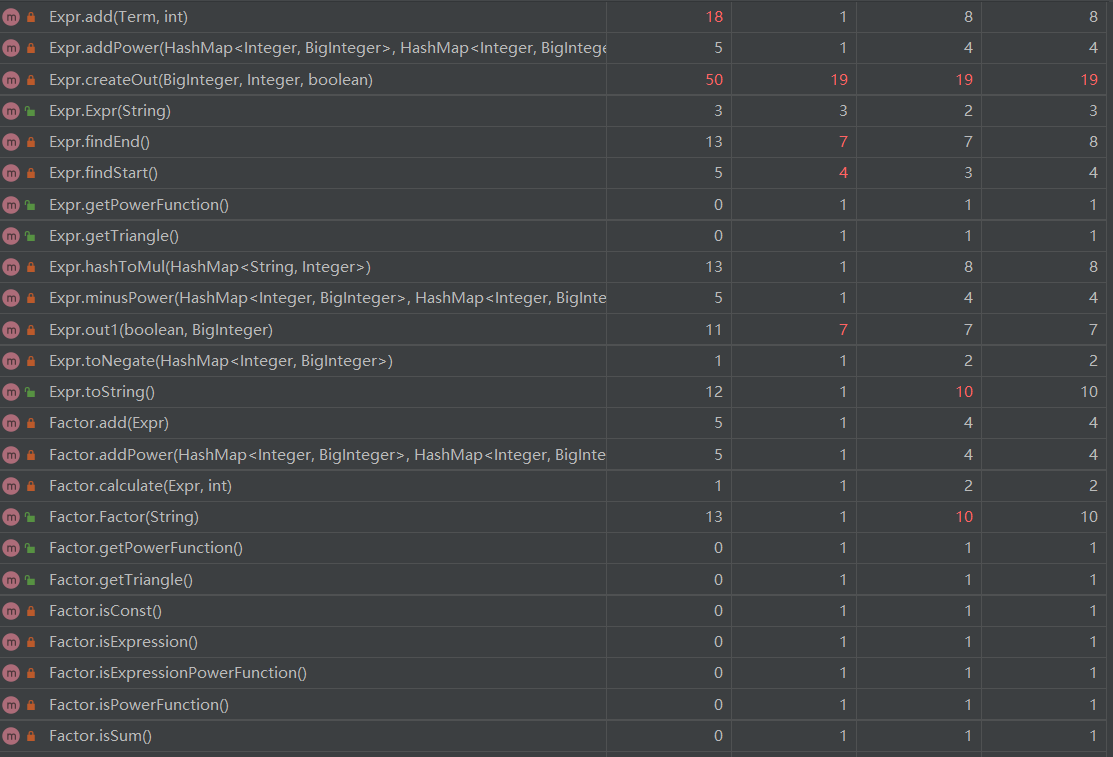
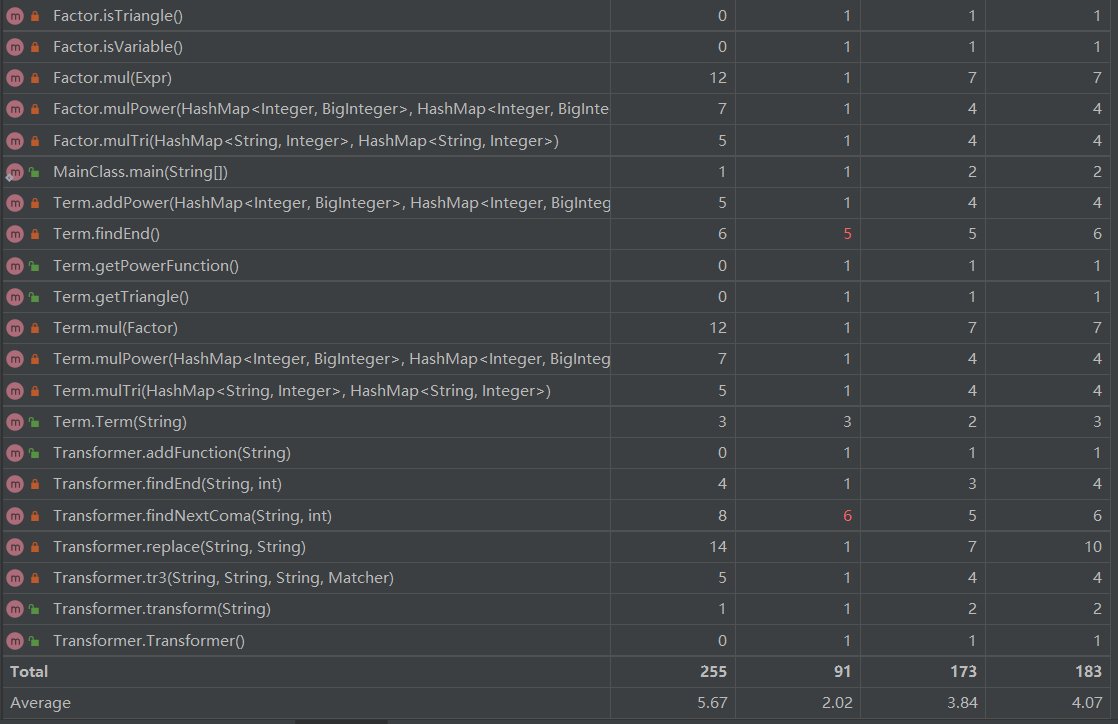
从这里看出,标红的主要还是输出方法,因为输出方法的化简判定还是需要很多情况的判定。
其次复杂度较高的是Expr中的add方法,主要是因为其中还传参了flag来决定是加法还是减法,将复杂度变为两倍以上。
- 优点
- 与第一次作业相同,这样将语法分析与计算合并在一个类的结构非常清晰,在因子判定时添加了未知因子的异常输出后总能精确定位出bug的数据的bug位置,例如在第三次互测时的"error when factor i**2"
- 由于实际上对于每一个项、因子,在创建之后实际上只使用了它的Hashmap,并且在做完加法/乘法之后就不再访问。所以程序运行所需要的内存仅取决于括号嵌套的深度,当某一项参与运算完之后即可抛弃,又因为三角函数内部直接调用的Expr的toString方法化为字符串存储,内部的类也就不用再进行保留。这大大降低了内存的占用率,可以防止在复杂表达式中溢出等问题。
- 缺点
- 3个类之间实际上关系紧密,完全可以通过继承让他们共享Hashmap的加和乘计算方法,避免我这种复制粘贴的写法,而且复制粘贴又会导致更改某个方法后如果忘记更改另一个发生错误。
- 结构层面上语法分析和计算被耦合在了一起。
- 字符串替换带来了很多特判的问题,比如函数要先代入x再代入别的,比如函数实参代入要套括号、整个函数替换后要加括号等等。导致了需要花费很多时间后期处理,也增加了出现bug的概率,如果能重来还是不要这么用。
- bug分析
在第二次第三次的强测和互测中,我一共被找出了一个bug,找到了别人的5个bug。
- 我的bug
我的bug可以被概括为sum(i,x,y,i**k)也就是我在sum的字符串代入时出现了常数的次幂,这个不符合我在因子定义的任何形式,所以无法解析。
这个bug可以说是一开始采用字符串替换的后果,在替换后也加上两端括号即可解决。可以说字符串替换相比建模的弊端就是总会因为疏忽忽略一种情况,这种情况就成了你程序bug的突破口。
关于复杂度比较,出现bug的代码位于Factor的构造方法中,在这个方法里我实现了8种不同Factor的判别并返回不同的值,代码行数为58行,圈复杂度为13,非常高,也许是这个方法过长、过大的复杂度导致的问题,但我还是更倾向于是对于字符串替换方法的天然劣势。
- 找到的bug
第二次作业中我找到了在对原表达式进行字符串预处理消掉连续加减号时忽略掉+++情况的代码,导致+++1出现异常;第二个是0**0的情况,也就是sin(0)**0在进行化简后出现的错误。
第三次作业中我找到了\(sum(i,1234567891234567890,1234567891234567899,i)\)的爆int类型的错误,和\(sin((cos(sin(x))+1))\)在多层嵌套且内部的第一项为\(cos(sin)\)时会导致表达式缺少括号的情况。
- 分析寻找bug的策略
关于hack,我看来最有效的策略就是构造边际数据,能进入互测的代码一般在整体结构和解析方法上不会存在问题,最有可能的就是在一些边界数据的处理上的疏忽(尤其是如果还经过了优化)。例如第二次的作业中的+++1,就是在表达式预先化简出现的问题而导致存储+++的数组爆范围;\(sin(0)**0\)则是在sin(0)的特判化简时忽略了幂次为0的特殊情况导致的(他的代码中\((0)**0\)是没有问题的)
- 架构设计体验
这一次我已经体会到了架构的重要性,也算是吃到了架构的甜头。第一次作业我就确定了Expr、Term、Factor三个类的整体架构,在第二次作业也就是更改了切分方法、增添了处理自定义函数的Transfrmer并且在Factor中增添了处理sum和三角函数的if。这也让我从第二次迭代到第三次作业的时候仅仅修改了sin和cos内部的格式。
我的架构虽然耦合度相对较高,但清晰的解析逻辑也让我在迭代和本地测试中节省了很多脑细胞和时间。
- 心得体会
第一次作业我经历了从初见第一次作业无从下手到第三次作业几乎不用修改的变化。
刚刚开始第一次作业的时候,对刚刚做完pre的我是一个很大的打击——完全没有思路,甚至想使用栈先渡过这一次作业。通过第一次训练项目和第一次课上实验,我逐步了解递归下降法的原理,但还是对parser里面基于解析和计算分离的各种各样的递归和嵌套方法一头雾水。于是我仿照着递归下降的思路,写了一个易于理解的类似于“递归函数”的解析计算方法,当时我感觉那样极其复杂的正则表达式基本无法扩展,却没想到更改了解析方法之后最终迭代了我的三次作业。甚至让我第三次作业都没有怎么进行修改就过了。
在hack方面,我第一次作业hack了63次却没有一次成功,同组的人却有两人1/7,这让我放弃了随机数据测试的思路,从第二次转为阅读部分关键代码并猜测易错点来构造数据,果然在后两次都有高hack率进账。这除了能让我学习到别人的好的架构,也锻炼了我阅读代码的能力。
这一单元是我oo课的入门,也是我oo的入门。第一次作业锻炼了我的抗压和快速学习的能力,第二三次作业让我亲身体验到了一个良好架构带来的舒适感。希望以后oo顺利。
posted @
2022-03-23 00:49
gdfwj
阅读(
114)
评论()
编辑
收藏
举报

