

(旧笔记1)MySQL
*****************************************************************************************************************
通过命令行工具可以登录MySQL客户端,连接MySQL服务器,从而访问服务器中的数据。
1、连接mysql服务器:
mysql -uroot -p密码
-u:后面的root是用户名,这里使用的是超级管理员root;
-p:(小写的p)后面的root是密码,这是在安装MySQL时就已经指定的密码;
2、连接mysql服务器并指定IP和端口:
mysql -uroot -proot -h127.0.0.1 -P3306
-h:后面给出的127.0.0.1是服务器主机名或ip地址,可以省略的,默认连接本机;
-P:(大写的P)后面的3306是连接端口,可以省略,默认连接3306端口;
3、退出客户端命令:quit或exit或 \q
4、FAQ:常见问题:

扩展内容3:

*****************************************************************************************************************
数据库及表操作
创建、删除、查看数据库
提示: (1)SQL语句对大小写不敏感。推荐关键字使用大写,自定义的名称(库名,表名,列名等)使用小写。
SHOW DATABASES; -- 查看当前数据库服务器中的所有库
CREATE DATABASE mydb1; -- 创建mydb1库
(2)并且在自定义名称时,针对多个单词不要使用驼峰命名,而是使用下划线连接。(例如:tab_name,而不是 tabName )
-- 01.查看mysql服务器中所有数据库
show databases; -- 查询服务器所有的数据库
-- 02.进入某一数据库(进入数据库后,才能操作库中的表和表记录)
-- 语法:USE 库名;
use mysql; -- 进入到‘mysql’数据库
show tables; -- 查询当前库中的所有表
-- 查看已进入的库(了解)
select database();
-- 03.查看当前数据库中的所有表
-- 先进入某一个库,再查看当前库中的所有表
use test;
show tables;
-- 04.删除mydb1库
-- 语法:DROP DATABASE 库名;
drop database mydb1; -- 删除mydb1库,但如果删除的库不存在,则会报错
-- 思考:当删除的库不存在时,如何避免错误产生?
drop database if exists mydb1;
-- 如果mydb1库存在则删除,如果不存在,也就不执行删除操作!
-- 05.重新创建mydb1库,指定编码为utf8
-- 语法:CREATE DATABASE 库名 CHARSET 编码;
-- 需要注意的是,mysql中不支持横杠(-),所以utf-8要写成utf8;
create database mydb1 charset utf8;
-- 如果不存在则创建mydb1;
create database if not exists mydb1 charset utf8;
-- 06.查看建库时的语句(并验证数据库库使用的编码)
-- 语法:SHOW CREATE DATABASE 库名;
show create database mydb1;
创建、删除、查看表
-- 07.进入mydb1库,删除stu学生表(如果存在)
-- 语法:DROP TABLE 表名;
use mydb1; -- 进入mydb1库
drop table if exists stu;-- 如果存在stu表,则删除
-- 08.创建stu学生表(编号[数值类型]、姓名、性别、出生年月、考试成绩[浮点型]),建表的语法:
CREATE TABLE 表名(
列名 数据类型,
列名 数据类型,
...
列名 数据类型
);
SQL语句:
-- 如果存在,则删除stu表
drop table if exists stu;
-- 创建stu学生表
create table stu(
id int primary key auto_increment, -- 给id添加主键约束,并设置自增
name varchar(20),
gender varchar(10) not null, -- 给gender添加非空约束
birthday date,
score double
);
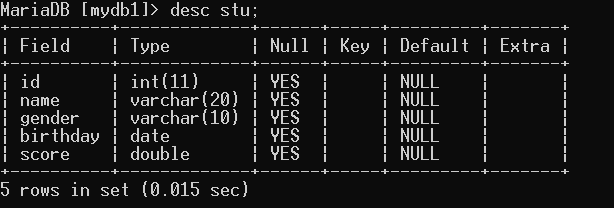
-- 09.查看stu学生表结构
desc stu;
![]()
*****************************************************************************************************************
新增、更新、删除表记录
-- 10.往学生表(stu)中插入记录(数据)
-- 语法:INSERT INTO 表名(列名1,列名2,列名3...) VALUES(值1,值2,值3...);
-- 如果是在cmd中执行插入记录的语句,先 set names gbk; 再插入记录!
-- 由于id已经设置了主键自增,所以在插入数据,id可以不用给值
insert into stu(id,name,gender,birthday,score) values (null,'tom','male','2000-3-4',89);
insert into stu values(null,'john','male','2002-5-6',78);
insert into stu values(null,'andy','female','2004-7-6',91);
-- 查询学生表中的所有记录
select * from stu;
提示:
(1)当为所有列插入值时,可以省写列名,但值的个数和顺序必须和声明时列的个数和顺序保持一致!
(2)SQL语句中的值为字符串或日期时,值的两边要加上单引号(有的版本的数据库双引号也可以,但推荐使用单引号)。
(3)(针对cmd窗口)在插入数据之前,先设置编码:set names gbk;
或者用以下命令连接mysql服务器:
mysql --default-character-set=gbk -uroot -proot
等价于:
mysql -uroot -proot
set names gbk;
-- 11.查询stu表所有学生的信息
-- 语法:SELECT 列名 | * FROM 表名
select * from stu;
-- 12.修改stu表中所有学生的成绩,加10分特长分
-- 修改语法: UPDATE 表名 SET 列=值,列=值,列=值...[WHERE子句];
update stu set score=score+10;
-- score+=10 mysql中不支持+=
-- 13.修改stu表中编号为1的学生成绩,将成绩改为83分。
update stu set score=83 where id=1;
-- 修改3号学生的性别为 'male',成绩改为99;
update stu set score=99,gender='male' where id=3;
提示:where子句用于对记录进行筛选过滤,保留符合条件的记录,将不符合条件的记录剔除。
-- 14.删除stu表中所有的记录
-- 删除记录语法: DELETE FROM 表名 [where子句]
delete from stu; -- 删除stu表中的所有记录
-- 仅删除符合条件的
delete from stu where id>2; -- 删除stu表中id大于2的记录
*****************************************************************************************************************
mysql的数据类型
数值类型
MySQL中支持多种整型,其实很大程度上是相同的,只是存储值的大小范围不同而已。
tinyint:占用1个字节,相对于java中的byte
smallint:占用2个字节,相对于java中的short
int:占用4个字节,相对于java中的int
bigint:占用8个字节,相对于java中的long
其次是浮点类型即:float和double类型
float:4字节单精度浮点类型,相对于java中的float
double:8字节双精度浮点类型,相对于java中的double
字符串类型
1、char(n) 定长字符串,最长255个字符。n表示字符数,例如:
-- 创建user表,指定用户名为char类型,字符长度不超过10
create table user(
username char(10),
...
);
所谓的定长,是当插入的数据的长度小于指定的长度时,剩余的空间会用空格填充。(这样会浪费空间)
char类型往往用于存储长度固定的数据。
2、varchar(n) 变长字符串,最长不超过65535个字节,n表示字符数,一般超过255个字符,会使用text类型,例如:
iso8859-1码表:一个字符占用1个字节,1*n < 65535, n最多等于 65535
utf8码表:一个中文汉字占用3个字节,3*n < 65535,n最多等于 65535/3
GBK码表:一个中文汉字占用2个字节,2*n < 65535,n最多等于 65535/2
-- 创建user表,指定用户名为varchar类型,长度不超过10个字符
create table user(
username varchar(10)
);
所谓的不定长,是当插入的数据的长度小于指定的长度时,剩余的空间可以留给别的数据使用。(节省空间)
总结:长度固定的数据,用char类型,这样既不会浪费空间,效率也比较高
如果长度不固定,使用varchar类型,这样不会浪费空间。
3、大文本(长文本)类型
最长65535个字节,一般超过255个字符列的会使用text。
-- 创建user表:
create table user(
resume text
);
扩展内容3:(面试题)char(n)、varchar(n)、text都可以表示字符串类型,其区别在于:
(1)char(n)在保存数据时,如果存入的字符串长度小于指定的长度n,后面会用空格补全,因此可能会造成空间浪费,但是char类型的存储速度较varchar和text快。
因此char类型适合存储长度固定的数据,这样就不会有空间浪费,存储效率比后两者还快!
(2)varchar(n)保存数据时,按数据的真实长度存储,剩余的空间可以留给别的数据用,因此varchar不会浪费空间。
因此varchar适合存储长度不固定的数据,这样不会有空间的浪费。
(3)text是大文本类型,一般文本长度超过255个字符,就会使用text类型存储。
日期类型
date:年月日
time:时分秒
datetime:年月日 时分秒
timestamp:时间戳(实际存储的是一个时间毫秒值),与datetime存储日期格式相同。两者的区别是:
-
timestamp最大表示2038年,而datetime范围是1000~9999
- timestamp在插入数据、修改数据时,可以自动更新成系统当前时间(后面用到时再做讲解)
*****************************************************************************************************************
mysql的字段约束
字段约束/列约束 --> 约束: 限制
主键约束
主键约束:如果为一个列添加了主键约束,那么这个列就是主键,主键的特点是唯一且不能为空。
主键的作用: 作为一个唯一标识,唯一的表示一条表记录(作用类似于人的身份证号,可以唯一的表示一个人一样。)
添加主键约束,例如将id设置为主键:
create table stu(
id int primary key,
...
);
如果主键是数值类型,为了方便插入主键(并且保证插入数据时,主键不会因为重复而报错),可以设置一个主键自增策略。
主键自增策略是指:设置了自增策略的主键,可以在插入记录时,不给id赋值,只需要设置一个null值,数据库会自动为id分配一个值(AUTO_INCREMENT变量,默认从1开始,后面依次+1),这样既可以保证id是唯一的,也省去了设置id的麻烦。
将id主键设置为自增:
create table stu(
id int primary key auto_increment,
...
);
非空约束
非空约束:如果为一个列添加了非空约束,那么这个列的值就不能为空,但可以重复。
添加非空约束,例如为password添加非空约束:
create table user(
password varchar(50) not null,
...
);
唯一约束
唯一约束:如果为一个列添加了唯一约束,那么这个列的值就必须是唯一的(即不能重复),但可以为空。
添加唯一约束,例如为username添加唯一约束及非空约束:
create table user(
username varchar(50) unique not null,
...
);
外键约束
外键其实就是用于通知数据库两张表数据之间对应关系的这样一个列。
这样数据库就会帮我们维护两张表中数据之间的关系。
(1) 创建表的同时添加外键
create table emp(
id int,
name varchar(50),
dept_id int,
foreign key(dept_id) references dept(id)
);
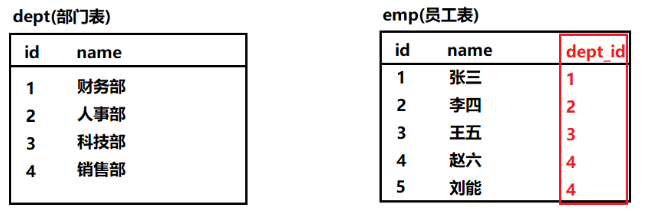
(1)如果是要表示两张表的数据之间存在对应关系,只需要在其中的一张表中添加一个列,保存另外一张表的主键,就可以保存两张表数据之间的关系。
但是添加的这个列(dept_id)对于数据库来说就是一个普通列,数据库不会知道两张表存在任何关系,因此数据库也不会帮我们维护这层关系。
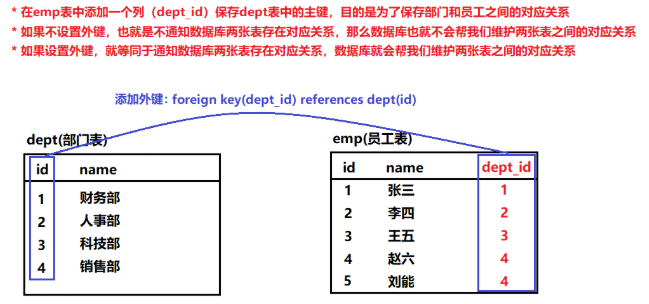
(2)如果将dept_id列设置为外键,等同于通知数据库,部门表和员工表之间存在对应关系,dept_id列中的数据要参考部门的主键,数据库一旦知道部门和员工表之间存在关系,就会帮我们维护这层关系。
*****************************************************************************************************************
查询表记录
-- 准备数据: 以下练习将使用db10库中的表及表记录,请先进入db10数据库!!!
基础查询
SELECT 语句用于从表中选取数据。结果被存储在一个结果表中(称为结果集)。
语法:SELECT 列名称 | * FROM 表名
(2)但使用 *(星号)有时会把不必要的列也查出来了,并且效率不如直接指定列名
-- 15.查询emp表中的所有员工,显示姓名,薪资,奖金
select name,sal,bonus from emp;
-- 16.查询emp表中的所有部门和职位
select dept,job from emp;
思考:如果查询的结果中,存在大量重复的记录,如何剔除重复记录,只保留一条? */
-- 在select之后、列名之前,使用DISTINCT 剔除重复的记录
select distinct dept,job from emp;
WHERE子句查询
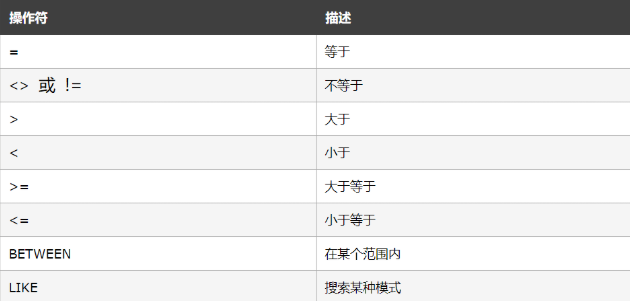
WHERE子句查询语法:SELECT 列名称 | * FROM 表名称 WHERE 列 运算符 值
WHERE子句后面跟的是条件,条件可以有多个,多个条件之间用连接词(or | and)进行连接
下面的运算符可在 WHERE 子句中使用:
-- 17.查询emp表中【薪资大于3000】的所有员工,显示员工姓名、薪资
select name,sal from emp where sal>3000;
-- 18.查询emp表中【总薪资(薪资+奖金)大于3500】的所有员工,显示员工姓名、总薪资
select name,sal+bonus from emp; -- 求所有员工的总薪资
select name,sal+bonus from emp
where sal+bonus > 3500;
-- 如果将'韩少云'的奖金更新为 null值,再执行上面的SQL语句,会有问题吗?
update emp set bonus=null where name='韩少云';
-- ifnull(列名, 值)函数: 判断指定的列是否包含null值,如果有null值,用第二个值替换null值
select name,sal+ifnull(bonus,0) from emp
where sal+ifnull(bonus,0) > 3500;
-- 注意查看上面查询结果中的表头,如何将表头中的 sal+bonus 修改为 "总薪资"
-- 使用as可以为表头指定别名
select name as 姓名,sal+ifnull(bonus,0) as 总薪资 from emp
where sal+ifnull(bonus,0) > 3500;
-- 另外as可以省略
select name 姓名,sal+ifnull(bonus,0) 总薪资 from emp
where sal+ifnull(bonus,0) > 3500;
-- 19.查询emp表中【薪资在3000和4500之间】的员工,显示员工姓名和薪资
select name, sal from emp
where sal>=3000 and sal<=4500;
-- 提示: between...and... 在...和...之间
select name, sal from emp
where sal between 3000 and 4500; -- 包括3000,也包括4500
-- 20.查询emp表中【薪资为 1400、1600、1800】的员工,显示员工姓名和薪资
select name,sal from emp
where sal=1400 or sal=1600 or sal=1800;
-- 或者
select name,sal from emp
where sal in(1400,1600,1800);
-- 21.查询薪资不为1400、1600、1800的员工,显示员工姓名和薪资
select name,sal from emp
where not(sal=1400 or sal=1600 or sal=1800);
-- 或
select name,sal from emp
where sal not in(1400,1600,1800);
-- 22.(自己完成) 查询emp表中【薪资大于4000和薪资小于2000】的员工,显示员工姓名、薪资。
select name,sal from emp
where sal>4000 or sal<2000;
-- 23.(自己完成) 查询emp表中薪资大于3000并且奖金小于600的员工,显示员工姓名、薪资、奖金。
select name,sal,bonus from emp
where sal>3000 and bonus<600; -- 结果有误差
-- 处理null值
select name,sal,ifnull(bonus,0) from emp
where sal>3000 and ifnull(bonus,0)<600;
-- 24.查询没有部门的员工(即部门列为null值)
select * from emp where dept=null; -- 条件错误!
select * from emp where dept is null; -- 条件正确!
-- 思考:如何查询有部门的员工(即部门列不为null值)
select * from emp where dept is not null;
模糊查询
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
可以和通配符(%、_)配合使用,其中"%"表示0或多个任意的字符,"_"表示一个任意的字符。
语法:SELECT 列 | * FROM 表名 WHERE 列名 LIKE 值
示例:
-- 25.查询emp表中姓名中以"刘"字开头的员工,显示员工姓名。
select name from emp where name like '刘%';
-- 26.查询emp表中姓名中包含"涛"字的员工,显示员工姓名。
select name from emp where name like '%涛%';
-- 27.查询emp表中姓名以"刘"开头,并且姓名为两个字的员工,显示员工姓名。
select name from emp where name like '刘_';
select name from emp where name like '刘__';
多行函数查询
多行函数也叫做聚合(聚集)函数,根据某一列或所有列进行统计。
常见的多行函数有:
| 多行函数 | 作用 |
|---|---|
| COUNT( 列名 | * ) | 统计结果集中指定列的记录的行数。 |
| MAX( 列名 ) | 统计结果集中某一列值中的最大值 |
| MIN( 列名 ) | 统计结果集中某一列值中的最小值 |
| SUM( 列名 ) | 统计结果集中某一列所有值的和 |
| AVG( 列名 ) | 统计结果集中某一列值的平均值 |
提示:(1)多行函数不能用在where子句中
(2)多行函数和是否分组有关,分组与否会直接影响多行函数的执行结果。
(3)多行函数在统计时会对null值进行过滤,直接将null值丢弃,不参与统计。
-- 28.统计emp表中薪资大于3000的员工个数
select count(*) from emp where sal>3000; -- 7
select count(id) from emp where sal>3000; -- 7
-- 29.求emp表中的最高薪资
select max(sal) from emp; -- 返回最高薪资,5000
-- 30.统计emp表中所有员工的薪资总和(不包含奖金)
select sum(sal) from emp; -- 薪资总和:39650
select sum(bonus) from emp; -- 奖金总和:5900,多行函数对null会处理,直接丢弃,不参与统计
-- 31.统计emp表员工的平均薪资(不包含奖金)
select avg(sal) from emp; -- 39650/12
多行函数需要注意的问题:
-
多行函数和是否分组有关,如果查询结果中的数据没有经过分组,默认整个查询结果是一个组,多行函数就会默认统计当前这一个组的数据。产生的结果只有一个。
-
如果查询结果中的数据经过分组(分的组不止一个),多行函数会根据分的组进行统计,有多少个组,就会统计出多少个结果。
select * from emp;
例如:统计emp表中的人数
select count(*) from emp; -- 12
结果返回的就是emp表中的所有人数
再例如:根据性别对emp表中的所有员工进行分组,再统计每组的人数,显示性别和对应人数
select count(*) from emp group by gender; -- 10, 2
分组查询
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT,SUM,AVG,MAX,MIN等函数。
语法:SELECT 列 | * FROM 表名 [WHERE子句] GROUP BY 列;
-- 32.对emp表,按照部门对员工进行分组,查看分组后效果。
-- 根据部门对员工进行分组
select name,dept from emp group by dept;
-- 统计分组后,每组的人数
select count(*) from emp group by dept; -- 3个组,所以会统计出三个结果
-- 33.对emp表按照职位进行分组,并统计每个职位的人数,显示职位和对应人数
-- 根据job进行分组,统计每个组的人数(每个职位的人数)
select job,count(*) from emp group by job;
-- 34.对emp表按照部门进行分组,求每个部门的最高薪资(不包含奖金),显示部门名称和最高薪资
-- 如果不分组,直接使用max(sal),这是统计整个emp表中的最高薪资
select max(sal) from emp; -- 5000;
-- 如果根据部门分组,可以分为三个组,再使用max(sal),就是统计每个组的最高薪资
select dept, max(sal) from emp group by dept;
排序查询
使用 ORDER BY 子句将结果集中记录根据指定的列排序后再返回
语法:SELECT 列名 FROM 表名 ORDER BY 列名 [ASC|DESC]
ASC(默认)升序,即从低到高;DESC 降序,即从高到低。
-- 35.对emp表中所有员工的薪资进行升序(从低到高)排序,显示员工姓名、薪资。
select name,sal from emp order by sal asc;
-- 默认是升序,asc可以省略
select name,sal from emp order by sal;
-- 36.对emp表中所有员工的奖金进行降序(从高到低)排序,显示员工姓名、奖金。
select name,bonus from emp order by bonus desc;
分页查询
在mysql中,通过limit进行分页查询,查询公式为:
limit (页码-1)*每页显示记录数, 每页显示记录数
-- 37.查询emp表中的所有记录,分页显示:每页显示3条记录,返回所有页的数据。
-- 每页显示3条,查询第1页数据
select * from emp limit 0,3;
-- 每页显示3条,查询第2页数据
select * from emp limit 3,3;
-- 每页显示3条,查询第3页数据
select * from emp limit 6,3;
-- 每页显示3条,查询第4页数据
select * from emp limit 9,3;
-- 38.求emp表中薪资最高的前3名员工的信息,显示姓名和薪资
-- 先根据薪资降序(从高到低)排序
select name,sal from emp order by sal desc;
-- 在排序的基础上,分页查询,每页显示3条,只查询第1页
select name,sal from emp order by sal desc limit 0,3;
其他函数
| 函数名 | 解释说明 |
|---|---|
| curdate() | 获取当前日期,格式是:年月日 |
| curtime() | 获取当前时间 ,格式是:时分秒 |
| sysdate()/now() | 获取当前日期+时间,格式是:年月日 时分秒 |
| year(date) | 返回date中的年份 |
| month(date) | 返回date中的月份 |
| day(date) | 返回date中的天数 |
| hour(date) | 返回date中的小时 |
| minute(date) | 返回date中的分钟 |
| second(date) | 返回date中的秒 |
| CONCAT(s1,s2..) | 将s1,s2 等多个字符串合并为一个字符串 |
| CONCAT_WS(x,s1,s2..) | 同CONCAT(s1,s2,..)函数,但是每个字符串之间要加上x,x是分隔符 |
-- 39.查询emp表中所有【在1993和1995年之间出生】的员工,显示姓名、出生日期。
-- 将运算符两边的值都转成日期类型,再进行比较!
select name,birthday from emp
where birthday>='1993-1-1' and birthday<='1995-12-31';
-- 或者,将日期中的年份提取出来,用年份和年份进行比较
select name,birthday from emp
where year(birthday)>=1993 and year(birthday)<=1995;
-- 40.查询emp表中本月过生日的所有员工
select * from emp
where month( now() )=month( birthday );
-- 41.查询emp表中员工的姓名和薪资(薪资格式为: xxx(元) )
select name,concat(sal,'(元)') from emp; -- concat(s1,s2,s3,s4...)
-- 补充练习:查询emp表中员工的姓名和薪资(薪资格式为: xxx/元 )
-- 用concat函数实现
select name,concat(sal,'/元') from emp;
-- 或,用concat_ws函数实现, concat_ws(x,s1,s2,s3...)
select name,concat_ws('/', sal, '元') from emp;
*****************************************************************************************************************

 浙公网安备 33010602011771号
浙公网安备 33010602011771号