
hadoop集群搭建
1.1 安装JDK
环境准备
1.关闭防火墙
先查看防火墙状态systemctl status firewalld.service
如果还在运行则关闭防火墙systemctl stop firewalld.service
禁用防火墙systemctl disable firewalld.service
2.创建目录
mkdir -p /home/hadoop
mkdir -p /home/java
将两个安装包上传到虚拟机中并解压
tar -zxvf /home/hadoop/hadoop-2.7.7.tar.gz
tar -zxvf /home/java/jdk-8u202-linux-x64.tar.gz
3.配置环境变量
vi /etc/profile 编辑环境变量配置文件,添加或修改环境变量
export JAVA_HOME=/home/java/jdk1.8.0_202
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/home/hadoop/hadoop-2.7.7
export HADOOP_LOG_DIR=/home/hadoop/hadoop-2.7.7/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
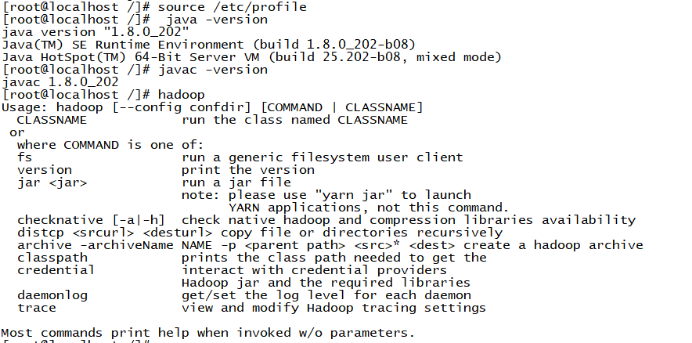
export PATH=.:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH输入 source /etc/profile 更新环境变量
输入 java -version 和 javac -version,看有无版本信息输出
1.2. hadoop搭建
环境准备
1.创建目录
mkdir -p /home/hadoop/hadoop-2.7.7/tmp 用来存放临时文件
mkdir -p /home/hadoop/hadoop-2.7.7/logs 用来存放日志文件
mkdir -p /home/hadoop/hadoop-2.7.7/hdfs 用来存储集群数据
mkdir -p /home/hadoop/hadoop-2.7.7/hdfs/name 用来存储文件系统元数据
mkdir -p /home/hadoop/hadoop-2.7.7/hdfs/data 用来存储真正的数据
进入hadoop解压后的目录下,找到两个.sh文件,修改JAVA_HOME的值
cd etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/home/java/jdk1.8.0_202
vi yarn-env.sh
修改JAVA_HOME的路径
export JAVA_HOME=/home/java/jdk1.8.0_202
2.修改核心配置文件
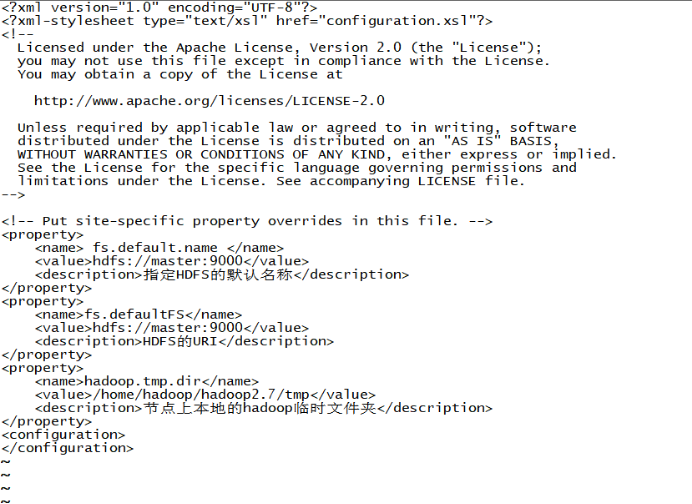
vi core-site.xml
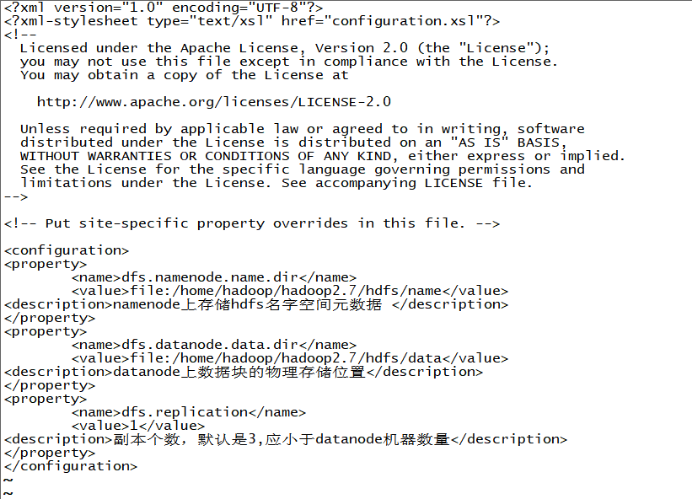
vi hdfs-site.xml
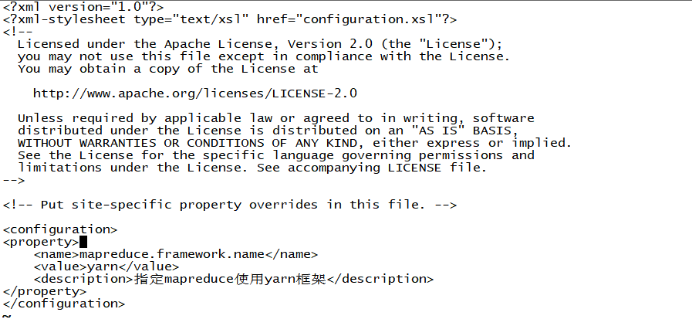
输入 cp mapred-site.xml.template mapred-site.xml 将mapred-site.xml.template文件复制到当前目录,并重命名为mapred-site.xml
vi mapred-site.xml
vi yarn-site.xml

vi slaves删除localhost,改为datanode的主机名

3.克隆虚拟机,克隆三个虚拟机起名为node1,node2,node3.
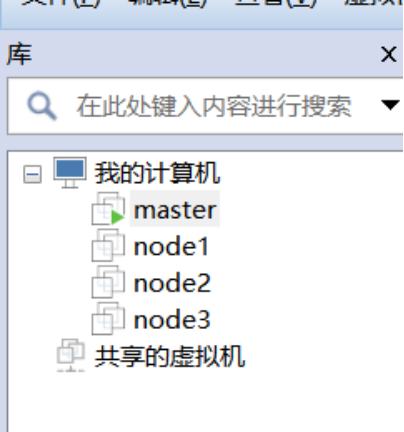
4.修改主机名。
vi /etc/hostname 修改每一台虚拟机的主机名为master,node1,node2,node3
192.168.184.130 master
192.168.184.131 node1
192.168.184.132 node2
192.168.184.133 node3 改完记得重启。
5.修改每一台主机的/etc/hosts文件
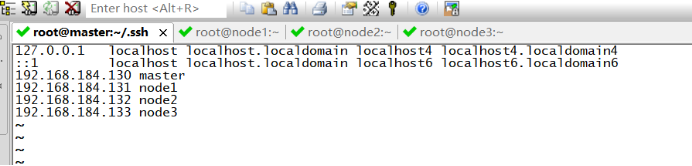
6.配置ssh免密登录
原理:通过创建无密码公钥的方式,将公钥传给对方。使用ssh协议连接时,会寻找authorized_keys文件中存放的公钥,如果有目标主机的公钥则将公钥传给目标主机,目标主机用自己的私钥和公钥进行匹配,正确匹配之后则认为两者可信,即不需要密码就可以登录
实现节点之间免密服务原理:
通过把所有节点的公钥写入authorized_keys文件中,再把这个文件传输给每一台节点,此时所有节点都有了其他节点的公钥,则登录时就不需要输入密码
在每台主机上输入 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 创建一个无密码的公钥,-t是类型的意思,dsa是生成的密钥类型,-P是密码,’’表示无密码,-f后是秘钥生成后保存的位置
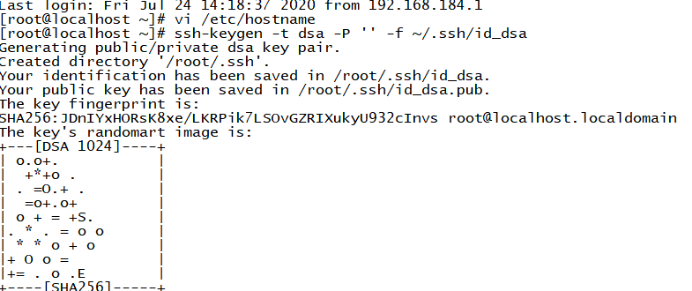
创建完成后,会出现两个文件在/root/.ssh'下
id_dsa 存放私钥
id_dsa.pub 存放公钥

输入 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥id_dsa.pub添加进authorized_keys

执行后会创建authorized_keys文件,这个文件用来放其他节点的公钥
在非master节点上输入 ssh-copy-id -i ~/.ssh/id_dsa.pub master 将自己的公钥传输给master节点。
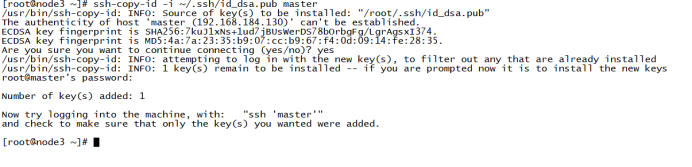
这时,master节点拥有所有节点的公钥。在master中输入
scp -r /root/.ssh/authorized_keys root@node1:/root/.ssh/
scp -r /root/.ssh/authorized_keys root@node2:/root/.ssh/
scp -r /root/.ssh/authorized_keys root@node3:/root/.ssh/

在每一台主机上输入 chmod 600 authorized_keys 修改文件权

重启服务 service sshd restart
此时每个节点都保存了所有的公钥,节点之间也就可以ssh免密登录了(第一次仍然需要密码)

7.格式化hdfs
hdfs namenode -format 格式化namenode,第一次使用需格式化一次,之后就不用再格式化,如果修改了一些配置文件,则需要重新格式化。(由于配置了环境变量任意位置执行都可以)
8.启动hadoop
start-all.sh,输入yes即可启动
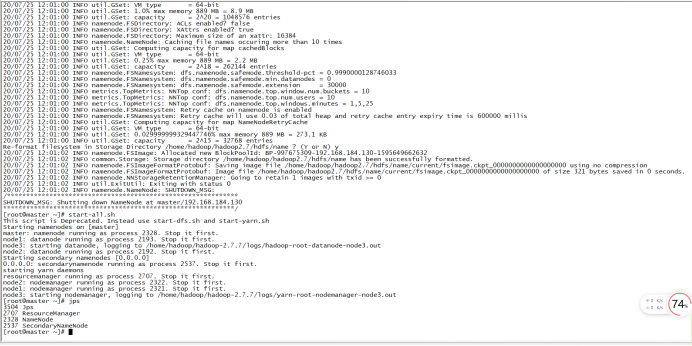
使用jps命令查看节点进程。
Master机器:
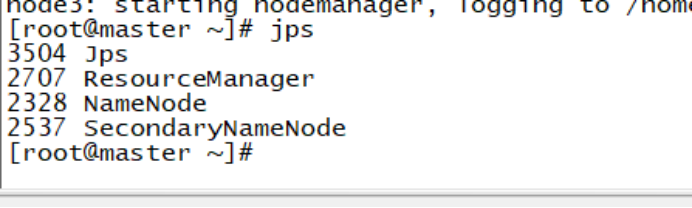
Node机器:

输入http://192.168.184.130:8088/
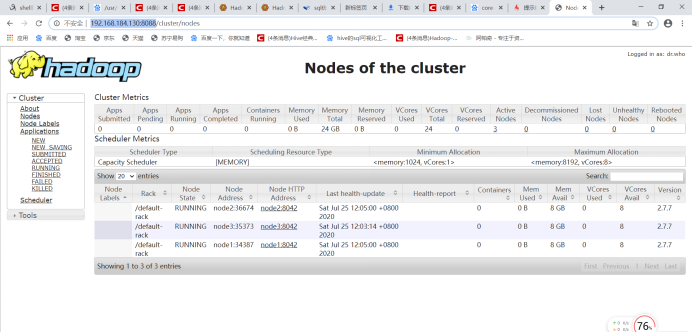

 浙公网安备 33010602011771号
浙公网安备 33010602011771号