ConcurrentHashMap 的 Traverser 阅读
ConcurrentHashMap 源码目前在网络上已有众多解析。本文章主要关注其基于 Traverser 的遍历实现,试图仔细解析该实现,如有错漏,请指正。
ConcurrentHashMap 的 Traverser 主要是用于内部数组的遍历功能支持,如何实现在内部数组扩容阶段期间,其他线程也能够正确地遍历输出,并保证良好的性能(不使用各种锁),Traverser 提供了一个优秀的设计实现。
1. 相关概念
2. 解析
1.相关概念
1.1 ConcurrentHashMap 支持方法 forEach(Consumer<? super K> action)、keys、elements、contains 等方法,它们的内部实现都基于 Traverser;
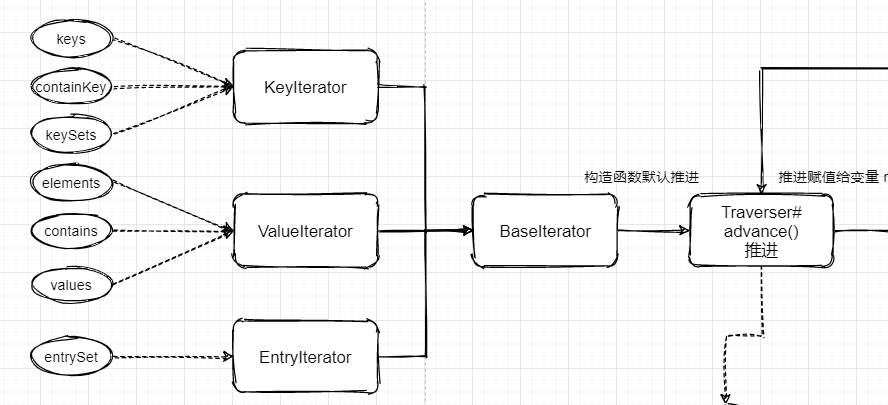
(基于 Traverser 的方法)
1.2 ConcurrentHashMap 的遍历能够保证在内部数组扩容期间,也具有优秀的性能和并发安全性。
1.3 Traverser 的主要方法:advance,其表示为:推进,与扩容期间时的 boolean 变量 advance 具有相似的意义,都是推进索引(index)的增长,以便持续向前推进元素定位。
1.4 理解在 类 Traverser 中的变量的命名,有利于对实现的理解,如:baseXxx 的变量是针对 ConcurrentHashMap 中的旧表,没有 base- 前缀的则同时针对旧表与新表(当前遍历上下文)。
2.解析
2.1 ConcurrentHashMap 统一了遍历的基础实现,即:Traverser 负责元素推进,并将元素返回;而 BaseIterator 则负责对元素进行判断,并提供迭代实现:hasNext、next;XxxIterator 则是基于 BaseIterator 提供不同的实现:针对keys的迭代、针对value的迭代、针对 entry 的迭代。
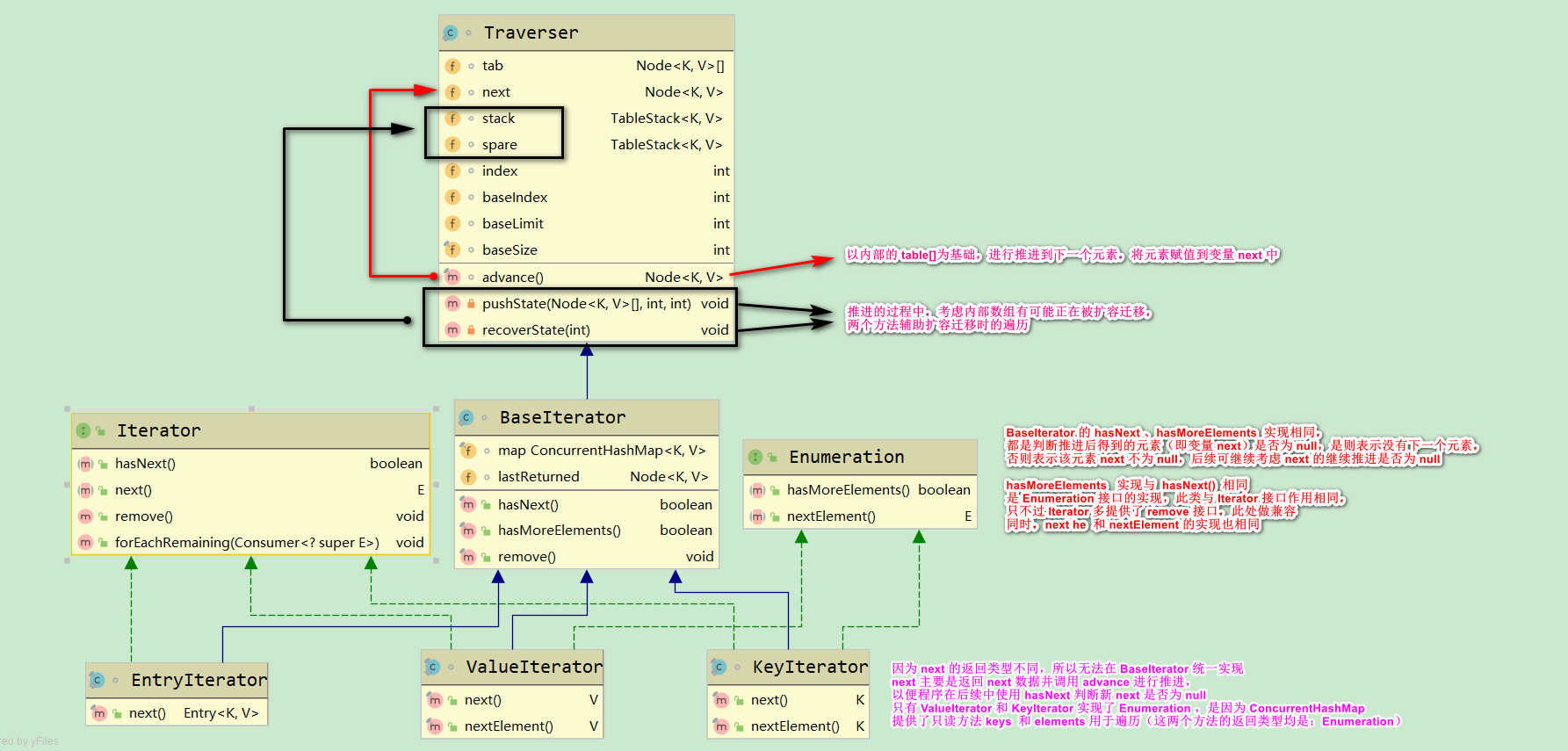
2.2 Traverser 类保持了迭代的索引:index,和对所在 ConcurrentHashMap 的内部数组—— 可能是旧表,也可能是新表的引用
static class Traverser<K,V> { // 默认是当前 table,如果正在重组,则会被间断性替换为 nextTable Node<K,V>[] tab; // current table; updated if resized // next 是一个关键的基础变量,作为迭代中的当前元素,主要实现:next() 和 hasNext() Node<K,V> next; // the next entry to use // 为了达到复用效果,使用一个 TableStack 在 这两个变量之间相互替换 TableStack<K,V> stack, spare; // to save/restore on ForwardingNodes 保存或恢复 // 真正遍历时的索引,有可能反复横跳,默认使用中为 index,而在 resize 中,则可能是 index、baseIndex+baseSize(因为翻倍) int index; // index of bin to use next /** * base* 是基于旧 tab(如果扩容,则存在 新 tab) * baseIndex 是在旧 tab 上的偏移 * baseSize 是旧 tab 的大小,这是为了方便存在 newTable 时,用于计算,因为 newTable.length = 2*baseSize * baseLimit 是要遍历的区间范围(也就是肯定是 limit <= size) */ int baseIndex; // current index of initial table int baseLimit; // index bound for initial table final int baseSize; // initial table size Traverser(Node<K,V>[] tab, int size, int index, int limit) { this.tab = tab; this.baseSize = size; this.baseIndex = this.index = index; this.baseLimit = limit; this.next = null; }
// ...
}
在 Traverser 的构造方法中,目前的引用,都是 limit = size,也就是说,目前被引用的地方,都是对整个内部数组进行迭代,区间控制在 0 ~ limit = size 。
2.3 Traverser 的暴露的方法(修饰符为 default),只有:advance。
advance 负责推进元素,在扩容阶段,也能够让索引到新表中进行元素遍历。
final Node<K,V> advance() { Node<K,V> e; // 这是推进成功(索引增加)让外部获取到元素后,外部重新进入的流程 // 尝试赋值为 e.next,如果不为null,则进行链表的迭代或树的遍历,不推进到下一节点 if ((e = next) != null) e = e.next; for (;;) { // t -> table,要遍历的 table // i -> index ; n -> length/number Node<K,V>[] t; int i, n; // must use locals in checks // 已经在上一步赋值为 e.next,进行迭代,如果为 null,才推进下一节点 if (e != null) return next = e; /** * baseIndex >= baseLimit 最开始传入的 index 就超过 limit,显然是不正确的,直接返回 null * 边界判断,这里的 tab 有可能即是 old table 也有可能是 nextTable, * 这也导致 n 的值反复横跳,有时是 old table 的长度,有时是 nextTable 的长度 * 但 t.length(新旧表的大小)总会比当前正在遍历的偏移 index 大。 * 并且下面的判断:(index = i + baseSize) >= n 是有可能成立的 */ if (baseIndex >= baseLimit || (t = tab) == null || (n = t.length) <= (i = index) || i < 0) return next = null; /** * 如果节点的 哈希 < 0,有多种情况: * 一是判断是否正在重组(在重组中被转移了) * 如果是 ForwardingNode(hash=-1) 说明该旧表节点已经在重组中被转移了, * 使用的算法是:对于已经移动的节点(ForwardingNode),换到新表(nextTable),index 保持不变, * continue 跳出,准备到新表进行迭代 * 存储信息到 临时stack 中 * 将该节点的索引推入到栈中,并更新遍历的表格为 nextTable,重新进入(index 不变), * 则 tabAt(t,i) * 下轮遍历开始,tabAt 已经是针对 nextTable,此时不再可能是 ForwardingNode,在 nextTable 遍历完后 * 回来通过 recoverState 将 tab 重新替换为 旧table,并推进索引 * 二是:标识该节点是树节点,是则获取树结构的 first 节点,并向下执行,在 recoverState 中,将 index = index+baseSize * 也就是,将 index 跨幅度增加为元素索引在新表中 rehash 后的位置,以便下次循环从该位置开始 * 总结:也就是说,在旧表遇到 ForwardingNode 后,遍历将切换到新表, * 对索引 index 和 baseIndex + baseSize 上的元素进行遍历 */ if ((e = tabAt(t, i)) != null && e.hash < 0) { if (e instanceof ForwardingNode) { tab = ((ForwardingNode<K,V>)e).nextTable; // 赋值为 null,并 continue,以便去进行 recoverState 操作 e = null; // 保存临时信息(当前索引到的位置、旧表大小、旧表引用) pushState(t, i, n); // 假设在这里,扩容阶段被完成了,将出现什么情况? continue; } // 树节点类型的 hash 也为负数:-2 else if (e instanceof TreeBin) e = ((TreeBin<K,V>)e).first; else e = null; } /** * 无论如何,程序总是会跑到此判断上。 * 如果 stack 不为 null,说明索引 i 已经被扩容进行过 rehash, * 那么就需要遍历完新表上的索引: baseIndex 和 baseIndex+baseSize, * 再重新赋值回旧表,从 ++baseIndex 开始 */ if (stack != null) // 辅助跳到新表的 2倍 index 位置 recoverState(n); else if ((index = i + baseSize) >= n) // 超过 n(tab 大小,恢复为基于旧表偏移的大小并加 1) // 如果出现此情况,访问回旧槽 index = ++baseIndex; // visit upper slots if present } }
简化描述迭代的代码:
1. 遍历器进行普通的遍历,通过索引的增长(+1),来获取节点,节点可能为 链表结构、树节点、null。如果为链表节点,则需要现在该索引上进行:e.next 获取节点的下一节点直到为 null,才推进 index;如果为 树节点,则需要获取 e.first,然后再通过 e.next 获取下一个树节点,直到为 null;如果为 null,则直接推进 index。
2. 遍历过程中,如果节点为 ForwardingNode(不是以上三种类型),则将当前遍历的数据(或称旧表)替换为新数组(新表),并将当前遍历的信息保存起来,主要有:当前在旧表上遍历的索引、旧表、旧表大小。
3. 基于新表,先在新表上对索引 baseIndex 进行第一步的节点获取,然后通过 recoverState 对索引进行推进,推进算法为:index = baseIndex + baseSize。因为在 ConcurrentHashMap 中,扩容的新数组大小为:2 * 旧表大小。
4. 基于新表,对 baseIndex + baseSize 上的元素获取使用完成后,推进索引,此时算法中将比较,此次推进的大小是否超过新表大小,如是,则将临时信息恢复,重新回到旧表上进行遍历。推进算法为:
/** * n 总是为新表大小,即:2 * baseSize * Possibly pops traversal state. * * @param n length of current table */ private void recoverState(int n) { // ...// s == null 作为先决条件,表示退回旧表进行操作 if (s == null && (index += baseSize) >= n) index = ++baseIndex; } }
5. 最终,是通过边界判断让遍历器退出。
2.4 advance 完成了在新旧表间切换遍历的实现,主要是借助于两个方法:pushState 、recoverState。其中,pushState 主要是负责存储临时信息,而 recoverState 则负责:当表处于新表时,辅组推进索引跨幅度增长,同时还负责切换为旧表时,将索引回退为旧表的索引位置并 +1.
/** * <pre> * 为了达到复用的效果, * spare 总是被清理,称为 null,在 recoverState 中将被赋值一个清空的 stack * stack 总是被负责,以便在 recoverState 被使用,然后进行清空,等下次 pushState 被重新赋值 spare * </pre> * Saves traversal state upon encountering a forwarding node. */ private void pushState(Node<K,V>[] t, int i, int n) { // spare 备用 TableStack<K,V> s = spare; // reuse if possible if (s != null) spare = s.next; else s = new TableStack<K,V>(); // 存储旧表 s.tab = t; // 存储旧表长度 s.length = n; // 存储遍历的旧表的索引 s.index = i; s.next = stack; // stack 存储了节点 stack = s; } /** * n 总是为新表大小,即:2 * baseSize * Possibly pops traversal state. * * @param n length of current table */ private void recoverState(int n) { TableStack<K,V> s; int len; // 此方法的第一次是为 index 提供跨幅度增加,调整 index = baseIndex + baseSize // 此时的 index 总是 < n 的,所以循环不成立,退出到外部方法进行元素获取 // 第二次,此时 index + baseSize = 2*baseSize + baseIndex > n, // 此情况下,新表对应索引上的元素已经被获取了,没有其他元素,则恢复临时信息 while ((s = stack) != null && (index += (len = s.length)) >= n) { n = len; index = s.index; // 将旧表赋值回遍历器,然后将存储值置为 null tab = s.tab; s.tab = null; TableStack<K,V> next = s.next; // null s.next = spare; // save for reuse stack = next; spare = s; } // 此处恢复 index 为 baseIndex + 1 // 将 index 调整为旧表 index,并自增推进到下一个元素 // s == null 作为先决条件,表示退回旧表进行操作 if (s == null && (index += baseSize) >= n) index = ++baseIndex; } }
pushState 和 recoverState 除了实现索引的变换,实际上对 TableStack 的操作,也达到通过复用单独一个 TableStack 实现入栈出栈,重复使用的效果。主要是通过 TableStack 的 next 属性。因为在算法中,通过判断 TableStack 是否为 null 来作为先决条件控制将索引恢复为旧表索引+1,所以需要将实例化好的唯一一个 TableStack 不断关联到 next 属性上,便于下次使用时,从 next 上获取该对象。赋值 TableStack 为 null 是在 recoverState 中处理的。通过两个指针不断循环关联到 next 属性上达到了复用的效果。
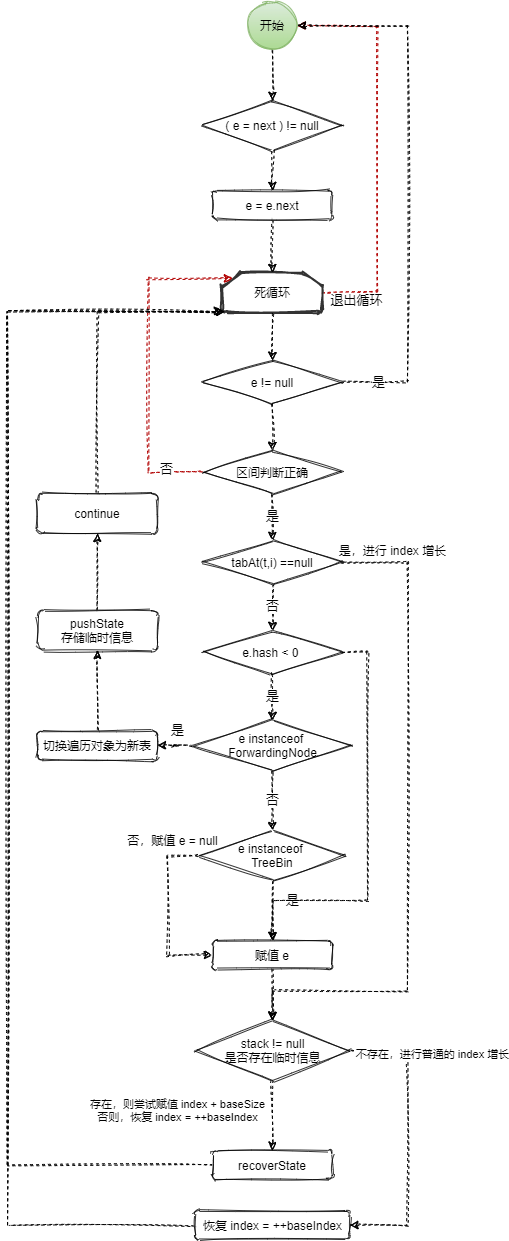

( 索引的推进 ) ( TableStack 的复用 )
2.5 其他问题:
-
-
- 当遍历到 ForwardingNode ,将信息临时存储起来后,如果此时 ConcurrentHashMap 的扩容结束,会发生什么情况?
- 实际上,Traverser 的遍历是与外部的扩容关联不大(处理新表),因为 Traverser 在创建的时候,已经使用了内部变量存储了 旧表 的引用,所以即使外部的扩容结束,原 ConcurrentHashMap 的表引用被更新为新表,但 Traverser 的旧表引用还在,还能够一致基于旧表进行遍历,但这个时候,因为旧表上已经全部是 ForwardingNode 了,所以会不断地通过 ForwardingNode 找到新表,并进行 TableStack 的存储和恢复,每一次元素遍历都在 baseIndex 和 baseIndex + baseSize 索引上获取节点数据。
- 当遍历过程中,有新元素添加,如果添加到 index 索引之前,会发生什么情况?
- 什么都不会发生,在 Traverser 的算法中,认为这即使发生了,也属于 可保证的一致性,对遍历没有影响。当然如果是被添加到 index 之后,还是能够被遍历到的。
- 当遍历到 ForwardingNode ,将信息临时存储起来后,如果此时 ConcurrentHashMap 的扩容结束,会发生什么情况?
-
总结:
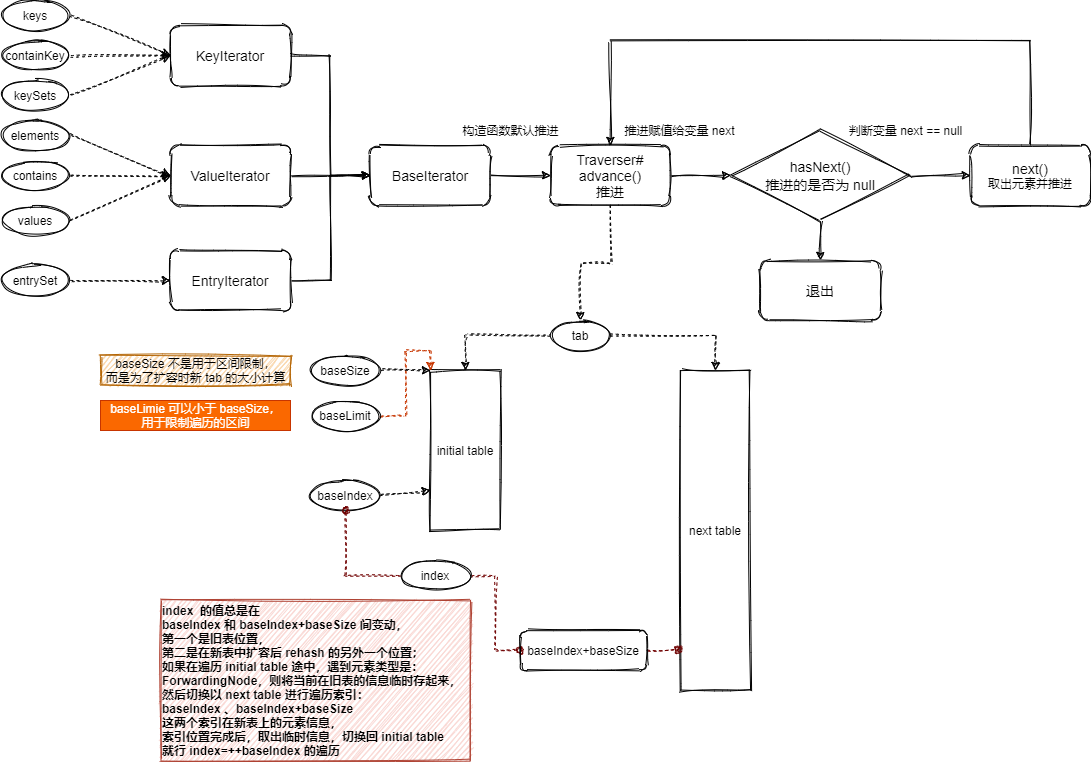
- 如果能够在脑海中,将遍历想象成两个表,一个旧表,一个新表(新表大小为旧表的 2 倍),索引移动遇到元素标识为 rehashed 时,就切换到新表做(2处不同索引的)元素获取,那这个 Traverser 就不难理解。
- 在遍历中为了保存临时信息,同时为了尽可能地复用,Traverser 实现了 TableStack 的结构,虽然看起来有点绕,但复用杠杠的
- Traverser 的遍历实现也得益于 ConcurrentHashMap 的扩容是 2倍扩容,便于推测新数组的边界范围
- 简略图如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号