
实用指南:Redis主从复制原理与实战:构建高可用缓存架构
一、引言
在当今高并发、高可用的互联网应用环境中,Redis已经成为现代架构中不可或缺的关键组件。作为一款内存数据库,Redis凭借其卓越的性能、丰富的数据结构和实用的功能特性,在缓存、会话管理、排行榜等场景中大放异彩。就像汽车需要备用轮胎一样,高可用性对于缓存系统也至关重要——试想一下,如果你的Redis缓存突然宕机,数据库可能会瞬间承受巨大压力,甚至导致整个系统崩溃。
本文的目标读者是中高级开发工程师、架构师以及对Redis高可用架构感兴趣的技术人员。通过阅读本文,你将获得:
- 全面理解Redis主从复制的原理和内部机制
- 掌握搭建高可用Redis缓存架构的实战技能
- 学习应对复制过程中常见问题的解决方案
- 获取生产环境中的最佳实践和运维经验
让我们一起深入Redis主从复制的世界,探索构建强大、可靠的缓存架构之道。
二、Redis主从复制基础
主从复制概念介绍
Redis主从复制(Replication)是Redis提供的一种数据冗余技术,它允许多个Redis服务器(从服务器,也称为replica或slave)拥有主服务器(master)的数据副本。这有点像古代皇帝颁布圣旨后,各地官员获得相同内容的副本并执行——主库做出更改,从库同步跟进。
主从架构的基本工作模式
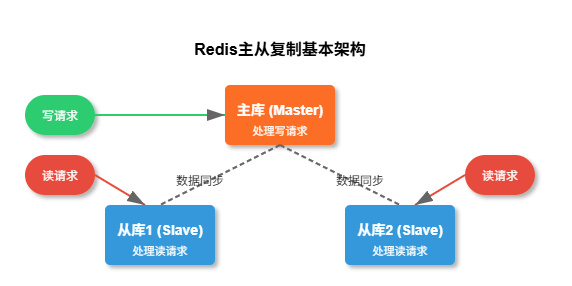
在Redis主从架构中,工作模式遵循一个简单而有效的原则:写入主库,读取从库。具体来说:
- 主库(Master)负责处理所有的写入命令,并将写操作同步给从库
- 从库(Slave/Replica)负责处理读请求,并不断从主库同步最新数据
- 主从之间通过异步复制保持数据一致性
与单机模式相比的优势
与单机模式相比,主从复制架构具有三大显著优势:
1. 数据冗余保障
主从复制为数据提供了多个副本,就像是为珍贵文件创建了多个备份。即使主库出现故障,数据依然安全地存在于从库中,大大提高了系统的容灾能力。
2. 读写分离能力
读写分离是主从架构的一大亮点。通过将读请求分发到多个从库,写请求集中到主库,系统可以支持更高的并发访问量。这就像一个高效的团队——领导做决策(写操作),团队成员执行并响应查询(读操作)。
3. 负载均衡
多个从库可以分担读取压力,避免单个Redis实例成为系统瓶颈。通过合理配置,我们可以根据不同从库的硬件配置分配不同的读取负载,实现资源的最优利用。
三、主从复制工作原理深度解析
要真正掌握Redis主从复制,就必须理解其内部工作原理。就像理解汽车不只是知道踩油门会前进,还需要了解发动机如何工作一样。
复制的三个阶段
Redis主从复制过程可分为三个关键阶段:
1. 同步阶段(Sync)
当从库连接到主库时,首先进入同步阶段。这个阶段主要完成初始数据的复制,确保从库获得主库当前的完整数据集。
# 主从同步过程示意
+--------+ +---------+
| Master |----SYNC命令请求---->| Replica |
+--------+ +---------+
| |
v v
生成RDB文件 等待数据
| |
v v
+--------+ +---------+
| Master |----发送RDB文件----->| Replica |
+--------+ +---------+
| |
v v
准备发送写命令 加载RDB2. 命令传播阶段(Command Propagation)
同步完成后,主库会将后续所有的写命令发送给从库,从库接收并执行这些命令,保持数据的持续一致。这个过程是异步进行的,这也是为什么Redis主从复制被称为"异步复制"。
3. 心跳检测(Heartbeat)
为了维持主从关系的稳定,从库会定期向主库发送PING命令(默认每秒一次),主库回复PONG。这不仅用于检测连接是否正常,还用于检测命令传播的延迟情况。
全量复制与增量复制机制
Redis的复制机制分为两种模式:
全量复制(Full Resynchronization)
全量复制发生在以下情况:
- 从库第一次连接到主库
- 复制连接长时间中断,超出复制积压缓冲区容量
- 从库执行
SLAVEOF命令切换主库
全量复制的过程:
- 主库生成RDB文件(数据快照)
- 将RDB文件发送给从库
- 从库清空自己的数据,加载RDB文件
- 主库发送缓冲区中的命令给从库
⚠️ 注意:全量复制对主库资源消耗较大,特别是内存和CPU,在生产环境中应谨慎触发。
增量复制(Partial Resynchronization)
增量复制是Redis 2.8引入的优化机制,用于短暂网络中断后的数据同步,避免全量复制的开销。
增量复制的过程:
- 从库重新连接主库,发送
PSYNC <runId> <offset>命令 - 主库验证runID和偏移量
- 如果验证通过,仅发送从库缺失的命令
主从连接的建立过程
主从连接的建立是一个多步骤的握手过程:
- 从库执行
SLAVEOF <masterIP> <masterPort>命令 - 从库与主库建立TCP连接
- 从库发送PING命令验证连接
- 主库回复PONG,连接验证成功
- 从库发送AUTH命令(如果配置了密码)
- 从库发送端口信息给主库
- 从库发送
PSYNC命令开始数据同步
Redis 2.8后的PSYNC优化
Redis 2.8版本前,主从断线重连后总是执行全量复制,这在数据量大的场景下非常低效。2.8版本引入的PSYNC命令带来了两个关键改进:
- 复制偏移量(replication offset):主从库分别维护一个复制偏移量,记录复制的进度
- 复制积压缓冲区(replication backlog):主库维护一个固定长度的环形缓冲区,记录最近执行的写命令
通过这两个机制,从库可以在断线重连后,仅同步缺失的那部分数据,大大提高了复制效率和系统稳定性。
复制积压缓冲区的作用与配置
复制积压缓冲区是增量复制的核心组件,它就像一个循环录像机,不断记录主库的最新写操作。
关键特性:
- 固定大小的环形缓冲区,先进先出
- 只存在于主库中
- 所有从库共享同一个积压缓冲区
- 缓冲区大小通过
repl-backlog-size参数配置
最佳实践:
# 设置复制积压缓冲区大小,根据写入速率和可能的断线时间评估
# 计算公式:缓冲区大小 = 写入速率(字节/秒) × 可能的最大断线时间(秒)
repl-backlog-size 100mb经验分享:在我们的生产环境中,曾因为复制积压缓冲区太小(默认1MB),导致网络抖动后频繁全量同步。将其调整到100MB后,系统稳定性显著提高,全量同步次数减少了95%。
四、搭建主从复制环境(实战)
理论讲完了,现在让我们动手实践,搭建一个Redis主从复制环境。实践是检验真理的唯一标准,只有亲自搭建并观察其行为,才能真正理解主从复制的工作方式。
环境准备与配置要点
首先,我们需要准备至少两台Redis服务器(可以是物理机、虚拟机或Docker容器)。为了演示方便,这里使用Docker快速搭建:
# 创建Docker网络
docker network create redis-net
# 启动主库
docker run -d --name redis-master \
--network redis-net \
-p 6379:6379 \
redis:6.2 redis-server --appendonly yes
# 启动从库
docker run -d --name redis-slave1 \
--network redis-net \
-p 6380:6379 \
redis:6.2 redis-server --appendonly yes
# 启动第二个从库(可选)
docker run -d --name redis-slave2 \
--network redis-net \
-p 6381:6379 \
redis:6.2 redis-server --appendonly yes手动配置主从关系的方法
最简单的方式是通过Redis命令行动态建立主从关系:
# 连接到从库1
docker exec -it redis-slave1 redis-cli
# 设置主库地址
> SLAVEOF redis-master 6379
OK
# 连接到从库2(如果有)
docker exec -it redis-slave2 redis-cli
# 设置主库地址
> SLAVEOF redis-master 6379
OK这种方式优点是简单直接,缺点是Redis实例重启后主从关系会丢失。
通过配置文件建立持久化的主从关系
为了确保Redis重启后仍保持主从关系,最好通过配置文件设置:
# 从库配置文件redis.conf中添加
replicaof # Redis 5.0+使用replicaof
# 或
slaveof # Redis 5.0之前使用slaveof
# 如果主库设置了密码,还需要配置
masterauth 在我们的Docker示例中,可以这样修改:
# 为从库1创建配置文件
cat > slave1.conf << EOF
replicaof redis-master 6379
EOF
# 重启从库1带配置文件
docker stop redis-slave1
docker run -d --name redis-slave1 \
--network redis-net \
-p 6380:6379 \
-v $(pwd)/slave1.conf:/etc/redis/redis.conf \
redis:6.2 redis-server /etc/redis/redis.conf验证主从状态的关键命令
配置完成后,我们需要验证主从关系是否建立成功:
# 在主库执行
docker exec -it redis-master redis-cli
# 查看复制相关信息
> INFO replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.18.0.3,port=6379,state=online,offset=182,lag=1
slave1:ip=172.18.0.4,port=6379,state=online,offset=182,lag=1
...
# 在从库执行
docker exec -it redis-slave1 redis-cli
# 查看复制状态
> INFO replication
# Replication
role:slave
master_host:redis-master
master_port:6379
master_link_status:up
...主从复制状态监控指标
在运维Redis主从架构时,以下几个关键指标需要重点关注:
| 指标名称 | 描述 | 正常值范围 | 异常时可能的原因 |
|---|---|---|---|
| master_link_status | 主从连接状态 | up | down表示连接断开 |
| master_last_io_seconds_ago | 上次与主库通信间隔时间 | <30s | 值过大表示网络问题 |
| slave_repl_offset | 从库复制偏移量 | - | 与主库偏移量差距过大表示复制延迟 |
| master_sync_in_progress | 是否正在同步 | 0 | 1表示正在进行全量同步 |
经验分享:我们通常设置监控,当
master_link_status为down超过30秒,或复制延迟(主从偏移量差值)超过10MB时触发告警。
五、复制过程中的常见问题与解决方案
Redis主从复制在实际使用中会遇到各种挑战。掌握这些常见问题及其解决方案,就像熟悉汽车的常见故障及维修方法一样重要。
网络中断后的复制处理策略
网络中断是分布式系统中的常见问题,Redis提供了多种配置来处理网络中断情况:
# 从库断线后,是否继续接受查询请求
replica-serve-stale-data yes # 默认继续提供服务,但数据可能不是最新的
# 从库与主库连接中断超过此时间,从库会认为复制连接断开
repl-timeout 60 # 单位:秒
# 主库超过此时间没有收到从库的响应,会断开复制连接
repl-ping-replica-period 10 # 单位:秒最佳实践:
- 对于网络稳定的环境,可以适当增大
repl-timeout值,减少误判 - 对于网络不稳定的环境,可以适当减小
repl-ping-replica-period值,提高心跳频率
⚠️ 踩坑经验:在跨IDC部署时,我们曾将
repl-timeout保持默认60秒,但网络延迟经常在30-40秒,导致频繁断开重连。将repl-timeout调整到120秒后问题解决。
全量同步对主库性能的影响及缓解方法
全量同步是一个资源密集型操作,会对主库产生以下影响:
- 生成RDB文件消耗CPU和内存
- 传输RDB文件消耗网络带宽
- fork子进程可能导致主进程短暂阻塞
缓解方法:
错峰复制:避免多个从库同时进行全量同步
# 分批启动从库,避免同时触发全量同步 sleep 300; redis-server --slaveof master 6379调整RDB生成策略:
# 在非高峰期执行全量同步 # 使用专门的复制端口,避免与客户端流量冲突 repl-diskless-sync yes repl-diskless-sync-delay 5 # 等待5秒再开始传输,聚合多个从库请求使用更强力的硬件:
- 使用SSD提高RDB生成速度
- 增加内存大小,减少fork子进程的开销
- 提供足够的网络带宽
复制延迟产生的原因及优化手段
复制延迟是指主库写入命令到从库执行完成之间的时间差,常见原因包括:
- 网络延迟:主从服务器之间的网络质量不佳
- 从库性能瓶颈:从库配置较低,处理命令速度跟不上主库
- 单线程瓶颈:从库单线程处理复制命令和客户端请求
- 写入压力过大:主库写入量突增,超过从库处理能力
优化手段:
网络优化:
- 主从部署在同一局域网内
- 使用专用网络通道进行复制
- 对复制流量进行QoS保障
从库优化:
- 增强从库硬件配置
- 减少从库的查询压力
- 使用Redis 6.0+多线程IO处理能力
架构优化:
- 分片集群减少单实例写入压力
- 级联复制减少主库复制负担
# 级联复制配置
# 从库A配置为主库的从库
redis-server --port 6380 --slaveof 192.168.1.10 6379
# 从库B配置为从库A的从库
redis-server --port 6381 --slaveof 192.168.1.10 6380从库重启后的数据一致性保障
从库重启是运维操作中常见的场景,如何保证重启后与主库数据一致是关键问题:
持久化配置:从库应配置AOF持久化,确保数据持久化到磁盘
appendonly yes appendfsync everysec启动顺序控制:先确保主库完全启动,再启动从库
复制ID检查:检查重启后的
master_replid是否变化,变化表示需要全量同步手动触发全量同步:如果怀疑数据不一致,可以手动执行
# 在从库执行 SLAVEOF NO ONE # 先断开主从关系 FLUSHALL # 清空数据 SLAVEOF <masterip> <masterport> # 重新建立主从,触发全量同步
实际踩过的坑与解决方案分享
在多年的Redis运维经验中,我遇到过许多令人头疼的问题,这里分享几个典型案例:
案例1:复制缓冲区过小导致频繁全量同步
问题描述:生产环境中,网络偶尔抖动,从库断开几秒后重连,却总是触发全量同步,严重影响主库性能。
根本原因:复制积压缓冲区默认1MB太小,网络断开期间产生的写入命令超过了缓冲区大小。
解决方案:
# 根据写入速率计算合理的缓冲区大小
# 假设写入速率2MB/s,最大可能断线时间30s,则设置:
repl-backlog-size 100mb # 预留冗余,设为60MB×1.5≈100MB案例2:从库负载过高导致复制中断
问题描述:某从库负责处理复杂的分析查询,在查询高峰期经常断开与主库的连接。
根本原因:从库CPU资源被分析查询占用,导致处理复制命令不及时,主库认为从库超时。
解决方案:
- 增加从库超时时间:
repl-timeout 120 - 为分析查询单独部署从库,实现读写分离的细粒度控制
- 使用Redis 6.0+的多线程IO能力
案例3:AOF重写导致主从延迟飙升
问题描述:从库在执行AOF重写(BGREWRITEAOF)时,主从延迟突然从毫秒级上升到秒级。
根本原因:AOF重写需要fork子进程,会暂停主进程一段时间,导致复制命令积压。
解决方案:
- 错峰进行AOF重写,避开业务高峰期
- 调整重写策略,减少重写频率
- 使用混合持久化(RDB+AOF)减轻重写负担
aof-use-rdb-preamble yes
六、主从复制在高可用架构中的应用
Redis主从复制虽然提供了数据冗余,但单靠主从结构还不足以构建完整的高可用方案。就像一辆有备胎的车还需要千斤顶和换胎工具一样,我们还需要其他组件配合。
结合哨兵(Sentinel)构建自动故障转移系统
Redis Sentinel是专为Redis高可用设计的工具,它能够监控Redis实例,并在主库故障时自动进行主从切换。
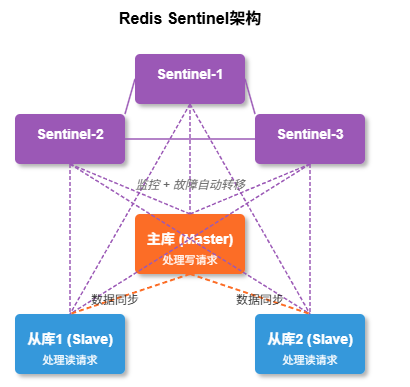
Sentinel的核心功能:
- 监控:持续检查主从库是否正常工作
- 通知:通过API通知管理员或其他程序Redis实例状态
- 自动故障转移:当主库不可用时,选择从库升级为新主库
- 配置提供者:客户端连接时,提供当前主库地址
部署Sentinel的简单示例:
# 创建Sentinel配置文件
cat > sentinel.conf << EOF
port 26379
sentinel monitor mymaster redis-master 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
EOF
# 启动Sentinel
docker run -d --name redis-sentinel1 \
--network redis-net \
-p 26379:26379 \
-v $(pwd)/sentinel.conf:/etc/redis/sentinel.conf \
redis:6.2 redis-sentinel /etc/redis/sentinel.conf关键配置参数解析:
sentinel monitor mymaster redis-master 6379 2:监控名为mymaster的主库,当有2个Sentinel认为主库不可用时才执行故障转移down-after-milliseconds:Sentinel认为实例不可达的时间阈值failover-timeout:故障转移操作的超时时间parallel-syncs:故障转移后,多少个从库同时与新主库同步
经验分享:生产环境中,我们通常部署至少3个Sentinel实例,分布在不同的物理机上,并设置
quorum值为Sentinel数量的一半加一(如3个Sentinel设置quorum=2),以避免网络分区导致的"脑裂"问题。
Redis Cluster与主从复制的结合
Redis Cluster是Redis官方的分布式解决方案,它结合了分片和主从复制,提供更强大的扩展性和可用性。
Redis Cluster核心特性:
- 数据自动分片到多个节点
- 每个分片可配置主从复制
- 支持在节点失效时继续运行
- 支持自动从库提升为主库
简化的Cluster部署示例:
# 创建6个Redis节点(3主3从)
for port in {7000..7005}; do
mkdir -p ./cluster-test/${port}
cat > ./cluster-test/${port}/redis.conf << EOF
port ${port}
cluster-enabled yes
cluster-config-file nodes-${port}.conf
cluster-node-timeout 5000
appendonly yes
EOF
docker run -d -v $(pwd)/cluster-test/${port}:/data \
--net host --name redis-${port} redis:6.2 \
redis-server /data/redis.conf
done
# 创建集群
docker exec -it redis-7000 redis-cli --cluster create \
127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 \
127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \
--cluster-replicas 1读写分离策略实现与代码示例
读写分离是Redis主从架构最常见的应用场景。下面以Java和Spring Boot为例,展示如何实现智能的读写分离:
/**
* Redis读写分离管理器
* 写操作路由到主库,读操作路由到从库
*/
@Component
public class RedisReadWriteSplitManager {
private final JedisPool masterPool;
private final List<JedisPool> slavePoolList;
private final Random random = new Random();
public RedisReadWriteSplitManager(
@Value("${redis.master.host}") String masterHost,
@Value("${redis.master.port}") int masterPort,
@Value("${redis.slaves}") String slavesConfig) {
// 初始化主库连接池
masterPool = new JedisPool(new JedisPoolConfig(), masterHost, masterPort);
// 初始化从库连接池列表
slavePoolList = new ArrayList<>();
String[] slaves = slavesConfig.split(",");
for (String slave : slaves) {
String[] hostPort = slave.split(":");
slavePoolList.add(new JedisPool(
new JedisPoolConfig(),
hostPort[0],
Integer.parseInt(hostPort[1])
));
}
}
/**
* 执行写操作(路由到主库)
*/
public <T> T executeWrite(Function<Jedis, T> callback) {
try (Jedis jedis = masterPool.getResource()) {
return callback.apply(jedis);
}
}
/**
* 执行读操作(路由到从库)
* 如果所有从库都不可用,则回退到主库
*/
public <T> T executeRead(Function<Jedis, T> callback) {
// 随机选择一个从库
List<JedisPool> shuffledSlaves = new ArrayList<>(slavePoolList);
Collections.shuffle(shuffledSlaves);
// 尝试从从库读取
for (JedisPool slavePool : shuffledSlaves) {
try (Jedis jedis = slavePool.getResource()) {
// 检查从库是否可用且复制状态正常
String info = jedis.info("replication");
if (info.contains("master_link_status:up")) {
return callback.apply(jedis);
}
} catch (Exception e) {
// 该从库不可用,尝试下一个
continue;
}
}
// 所有从库都不可用,回退到主库
return executeWrite(callback);
}
// 使用示例
public String get(String key) {
return executeRead(jedis -> jedis.get(key));
}
public void set(String key, String value) {
executeWrite(jedis -> jedis.set(key, value));
}
}多级复制架构设计(主-从-从)
在大规模Redis部署中,为了减轻主库复制压力,我们可以采用多级复制架构:
Master
├── Slave1
│ ├── Sub-Slave1-1
│ └── Sub-Slave1-2
└── Slave2
├── Sub-Slave2-1
└── Sub-Slave2-2配置方法:
# Slave1配置为Master的从库
replicaof
# Sub-Slave1-1配置为Slave1的从库
replicaof 多级复制的优势:
- 减轻主库复制负担,主库只需同步给一级从库
- 更好的扩展性,支持更多的读副本
- 跨区域部署时,可以按地域层次化部署
需要注意的问题:
- 增加了复制延迟,二级从库的数据比一级从库更滞后
- 链路复杂度增加,故障排查难度更高
- 任一节点故障可能影响其下所有从库
七、性能优化与调优
Redis主从架构的性能调优就像赛车调校一样,需要精细调整各个参数,才能发挥最佳性能。
关键配置参数详解与最佳实践
1. repl-timeout
# 复制超时时间,默认60秒
repl-timeout 60最佳实践:
- 局域网环境:可以维持默认值60秒
- 广域网环境:建议设置为网络RTT的5-10倍,至少120秒
- 跨国部署:可能需要设置300秒或更高
2. repl-backlog-size
# 复制积压缓冲区大小,默认1MB
repl-backlog-size 100mb计算公式:缓冲区大小 = 写入速率 × 预计最大断线时间 × 安全系数(1.5-2)
最佳实践:
- 低写入场景:10-50MB通常足够
- 高写入场景:100MB-1GB,需根据实际写入量评估
- 监控
master_repl_offset增长速率,据此调整
3. repl-ping-replica-period
# 主库向从库发送PING的间隔,默认10秒
repl-ping-replica-period 10最佳实践:
- 稳定网络:可以适当增加到30秒,减少心跳开销
- 不稳定网络:可以减少到5秒,提前发现连接问题
- 跨云部署:建议设置为较小值如3-5秒
4. min-replicas-to-write和min-replicas-max-lag
# 当可用从库数量小于min-replicas-to-write且
# 从库延迟大于min-replicas-max-lag秒时,主库拒绝写入
min-replicas-to-write 1
min-replicas-max-lag 10最佳实践:
- 对数据一致性要求高的场景:设置
min-replicas-to-write=N/2+1(N为从库总数) - 注意权衡:设置过严格可能影响系统可用性,设置过宽松可能导致数据丢失
带宽限制与网络优化
Redis复制过程可能消耗大量网络带宽,特别是全量同步时。合理的带宽控制非常重要:
# 限制主库向从库复制的带宽,单位bytes/second
# 1MB/s = 1048576
client-output-buffer-limit replica 256mb 64mb 60网络优化建议:
- 使用专用网络:为Redis复制流量提供专用网络通道
- TCP参数调优:增大TCP缓冲区大小
sysctl -w net.core.wmem_max=16777216 sysctl -w net.core.rmem_max=16777216 - 启用TCP keepalive:保持连接活跃
tcp-keepalive 300
磁盘IO对复制过程的影响与优化
磁盘IO性能直接影响Redis复制过程,特别是在RDB生成和AOF操作期间:
影响分析:
- RDB生成时的写入操作
- 从库加载RDB时的读取操作
- AOF重写对复制过程的干扰
优化建议:
- 使用SSD:相比HDD,SSD能显著提高RDB生成和加载速度
- 使用无盘复制:避免RDB文件写入磁盘
repl-diskless-sync yes repl-diskless-sync-delay 5 - 分离数据目录:将Redis数据目录与系统盘分离
- 调整系统IO调度策略:
# 设置IO调度器为deadline echo deadline > /sys/block/sda/queue/scheduler
经验分享:在生产环境中,我们发现从默认的IO调度器切换到deadline后,RDB生成时间缩短了约30%,特别是在虚拟化环境中效果更明显。
八、案例分析:大规模生产环境实践
理论讲解完毕,现在让我们深入一些实际案例,看看Redis主从复制在大规模生产环境中是如何应用的。
电商秒杀系统中的应用案例
电商秒杀是对缓存系统的极限挑战,需要处理瞬时的巨大流量。
场景特点:
- 极高的读取压力(查询商品库存)
- 突发的写入压力(减库存操作)
- 对数据一致性要求高
- 对系统可用性要求极高
架构设计:
┌─────────────┐
│ 负载均衡层 │
└──────┬──────┘
│
┌────────────────┼────────────────┐
│ │ │
┌───────▼────────┐┌──────▼─────────┐┌─────▼──────────┐
│ 应用服务器1 ││ 应用服务器2 ││ 应用服务器3 │
└───────┬────────┘└──────┬─────────┘└─────┬──────────┘
│ │ │
┌───────▼────────────────▼────────────────▼──────────┐
│ Redis读写分离管理 │
└─┬─────────────────────────┬──────────────────────┬─┘
│ │ │
┌─▼─────────┐ ┌─────▼─────┐ ┌─────▼─────┐
│ 主Redis │ │ 从Redis1 │ │ 从Redis2 │
│ (写操作) │─────────► (读操作) │ │ (读操作) │
└───────────┘ └───────────┘ └───────────┘
│
│ ┌───────────┐
└───────────► 持久化存储 │
└───────────┘核心技术实现:
库存预热:活动开始前将商品库存加载到Redis
// 预热商品库存到Redis for (Product product : products) { redisTemplate.opsForValue().set( "product:" + product.getId() + ":stock", product.getStock().toString() ); }原子减库存:使用Lua脚本保证原子性
-- 库存扣减Lua脚本 local stock = redis.call('get', KEYS[1]) if tonumber(stock) >= tonumber(ARGV[1]) then return redis.call('decrby', KEYS[1], ARGV[1]) end return 0读写分离策略:写主库,读从库,但库存查询也走主库保证一致性
// 库存查询需要保证强一致性,使用主库 public Long getStock(Long productId) { String stockStr = redisManager.executeWrite(jedis -> jedis.get("product:" + productId + ":stock") ); return stockStr != null ? Long.parseLong(stockStr) : 0; }
性能数据:
- 单机Redis主库:5万QPS写入
- 双从库:15万QPS读取
- 秒杀峰值总吞吐量:20万QPS
- 平均响应时间:15ms
用户会话管理系统架构设计
会话管理是Redis的经典应用场景,特别是在大规模Web应用中。
架构设计:
用户请求
│
┌───────▼─────────┐
│ 负载均衡器 │
└───────┬─────────┘
│
┌───▼───┐
│Session│ 会话校验/创建
│Filter │
└───┬───┘
│
┌───────▼─────────┐
│ 会话管理模块 │
└───────┬─────────┘
│
▼
┌─────────────────────┐
│ Redis Sentinel集群 │
├─────────┬───────────┤
│ 主Redis │ 从Redis×2 │
└─────────┴───────────┘技术实现要点:
会话存储格式:使用Hash结构存储会话,便于部分字段更新
// 存储会话 public void saveSession(Session session) { redisManager.executeWrite(jedis -> { String sessionKey = "session:" + session.getId(); Map<String, String> sessionMap = new HashMap<>(); sessionMap.put("userId", session.getUserId()); sessionMap.put("loginTime", String.valueOf(session.getLoginTime())); sessionMap.put("lastAccessTime", String.valueOf(System.currentTimeMillis())); sessionMap.put("data", JSON.toJSONString(session.getData())); return jedis.hmset(sessionKey, sessionMap); }); // 设置过期时间 redisManager.executeWrite(jedis -> jedis.expire("session:" + session.getId(), 1800) ); }会话读取优化:从从库读取,减轻主库压力
// 读取会话信息 public Session getSession(String sessionId) { return redisManager.executeRead(jedis -> { String sessionKey = "session:" + sessionId; Map<String, String> sessionMap = jedis.hgetAll(sessionKey); if (sessionMap.isEmpty()) { return null; } Session session = new Session(); session.setId(sessionId); session.setUserId(sessionMap.get("userId")); session.setLoginTime(Long.parseLong(sessionMap.get("loginTime"))); session.setData(JSON.parseObject(sessionMap.get("data"))); // 更新最后访问时间,这个写操作路由到主库 redisManager.executeWrite(j -> j.hset(sessionKey, "lastAccessTime", String.valueOf(System.currentTimeMillis())) ); return session; }); }会话有效期延长:访问时动态延长过期时间
// 延长会话有效期 private void extendSessionExpiration(String sessionId) { redisManager.executeWrite(jedis -> jedis.expire("session:" + sessionId, 1800) ); }
系统表现:
- 3000万并发在线用户
- 会话查询平均延迟<5ms
- 会话存储平均延迟<10ms
- Redis集群内存使用:64GB
主从复制在跨机房部署中的实践
跨机房部署是提高系统可用性的重要手段,但也带来了网络延迟和复制一致性的挑战。
典型架构:
地域A 地域B
┌──────────────────────────┐ ┌──────────────────────────┐
│ ┌──────────┐ │ │ ┌──────────┐ │
│ │ 主Redis │ │ │ │ 从Redis │ │
│ └────┬─────┘ │ │ └────▲─────┘ │
│ │ │ │ │ │
│ ┌────▼─────┐ │ │ ┌────┴─────┐ │
│ │Sentinel×3│<────────────────────────────>│Sentinel×3│ │
│ └──────────┘ 心跳检测 │ │ 心跳检测 └──────────┘ │
│ │ │ │
└──────────────────────────┘ └──────────────────────────┘
│ ▲
│ 专线/VPN加密通道 │
└──────────────────────────────────────┘关键配置优化:
增大复制超时和缓冲区:
# 地域间网络延迟可能较高,增大超时设置 repl-timeout 120 # 增大复制缓冲区,应对网络波动 repl-backlog-size 1gb配置合理的心跳检测:
# 减少心跳频率,避免网络拥塞 repl-ping-replica-period 15 # Sentinel检测超时时间也要相应增加 sentinel down-after-milliseconds mymaster 10000启用压缩复制:
# Redis 6.0+支持压缩复制,可以节省带宽 repl-diskless-sync yes repl-diskless-sync-delay 5
遇到的挑战与解决方案:
挑战:跨地域网络不稳定,导致频繁断开重连和全量同步
解决方案:- 使用专线而非公网
- 实现TCP连接保活
- 增大复制缓冲区至少为15分钟写入量
挑战:跨地域复制延迟较高,影响数据一致性
解决方案:- 关键数据实现就近部署
- 非关键查询允许一定的数据不一致
- 使用异地双活方案,而非简单主从
挑战:故障转移决策困难,如何避免脑裂
解决方案:- 每个地域部署奇数个Sentinel
- 配置合理的quorum值
- 实现客户端智能路由
九、监控与运维最佳实践
再好的架构,如果没有完善的监控和运维支持,也可能在关键时刻掉链子。这一节,我们来讨论Redis主从复制环境的监控与运维最佳实践。
关键指标监控设置
监控Redis主从环境,需要关注以下关键指标:
| 指标类别 | 具体指标 | 推荐告警阈值 | 监控频率 |
|---|---|---|---|
| 复制状态 | master_link_status | 任何"down"状态 | 30秒 |
| 复制延迟 | repl_backlog_histlen | >100MB | 1分钟 |
| 同步性能 | slave_repl_offset | 与主库差值>50MB | 1分钟 |
| 连接状态 | connected_slaves | <预期从库数 | 1分钟 |
| 缓冲区使用 | client_recent_max_output_buffer | >100MB | 5分钟 |
| 系统资源 | used_memory_rss | >85%物理内存 | 1分钟 |
| 延迟指标 | latency | >200ms | 10秒 |
复制状态监控脚本示例
以下是一个监控Redis主从复制状态的Python脚本示例:
#!/usr/bin/env python3
# redis_replication_monitor.py
import redis
import time
import smtplib
from email.mime.text import MIMEText
import json
import argparse
def send_alert(subject, message, to_email):
"""发送告警邮件"""
from_email = "redis-monitor@example.com"
msg = MIMEText(message)
msg['Subject'] = subject
msg['From'] = from_email
msg['To'] = to_email
try:
smtp = smtplib.SMTP('smtp.example.com')
smtp.sendmail(from_email, [to_email], msg.as_string())
smtp.quit()
print(f"Alert sent: {subject}")
except Exception as e:
print(f"Failed to send alert: {e}")
def check_replication_status(master_host, master_port, master_password=None):
"""检查主从复制状态"""
try:
# 连接主库
master = redis.Redis(host=master_host, port=master_port, password=master_password, socket_timeout=5)
# 获取复制信息
repl_info = master.info('replication')
# 检查从库连接状态
if repl_info['role'] != 'master':
return False, f"Redis at {master_host}:{master_port} is not a master!"
expected_slaves = 2 # 预期的从库数量
if repl_info['connected_slaves'] < expected_slaves:
return False, f"Expected {expected_slaves} slaves, but only {repl_info['connected_slaves']} connected!"
# 检查从库状态
alerts = []
for i in range(repl_info['connected_slaves']):
slave_key = f"slave{i}"
if slave_key in repl_info:
slave_info = repl_info[slave_key]
# 检查复制状态
if slave_info['state'] != 'online':
alerts.append(f"Slave {slave_info['ip']}:{slave_info['port']} state: {slave_info['state']}")
# 检查复制延迟
if 'lag' in slave_info and slave_info['lag'] > 10:
alerts.append(f"Slave {slave_info['ip']}:{slave_info['port']} lag: {slave_info['lag']} seconds")
# 检查偏移量差异
if 'offset' in slave_info:
offset_diff = repl_info['master_repl_offset'] - slave_info['offset']
if offset_diff > 1000000: # 1MB
alerts.append(f"Slave {slave_info['ip']}:{slave_info['port']} offset diff: {offset_diff} bytes")
if alerts:
return False, "\n".join(alerts)
# 一切正常
return True, "Replication status normal"
except Exception as e:
return False, f"Error checking replication status: {e}"
def main():
parser = argparse.ArgumentParser(description='Monitor Redis Replication Status')
parser.add_argument('--host', default='localhost', help='Redis master host')
parser.add_argument('--port', type=int, default=6379, help='Redis master port')
parser.add_argument('--password', help='Redis password')
parser.add_argument('--interval', type=int, default=60, help='Check interval in seconds')
parser.add_argument('--alert-email', default='admin@example.com', help='Email to send alerts to')
args = parser.parse_args()
print(f"Starting Redis replication monitoring for {args.host}:{args.port}")
print(f"Check interval: {args.interval} seconds")
while True:
status_ok, message = check_replication_status(args.host, args.port, args.password)
if not status_ok:
subject = f"Redis Replication Alert: {args.host}:{args.port}"
send_alert(subject, message, args.alert_email)
time.sleep(args.interval)
if __name__ == "__main__":
main()复制链路异常报警策略
设计合理的报警策略至关重要,可以帮助运维团队及时发现并解决问题:
分级报警机制:
- P1(紧急):主从断开连接超过5分钟
- P2(重要):复制延迟超过30秒
- P3(关注):偶发的复制延迟波动
报警渠道组合:
- P1问题:短信 + 电话 + 邮件
- P2问题:短信 + 邮件
- P3问题:邮件 + 企业即时通讯工具
报警抑制与聚合:
- 同一问题30分钟内只报警一次
- 多个从库同时出现问题时,聚合为一条报警
- 系统恢复后发送恢复通知
主从切换的自动化运维工具
在大规模Redis部署中,手动进行主从切换既耗时又容易出错。以下是一个简化的主从切换工具示例:
#!/usr/bin/env python3
# redis_failover.py
import redis
import argparse
import time
import sys
def get_redis_info(host, port, password=None):
"""获取Redis服务器信息"""
try:
r = redis.Redis(host=host, port=port, password=password, socket_timeout=5)
info = r.info()
role = info.get('role', 'unknown')
return True, info, role
except Exception as e:
return False, str(e), 'unknown'
def promote_slave(slave_host, slave_port, password=None):
"""将从库提升为主库"""
try:
r = redis.Redis(host=slave_host, port=slave_port, password=password, socket_timeout=5)
# 检查当前角色
info = r.info()
if info['role'] != 'slave':
return False, "This Redis instance is not a slave"
# 提升为主库
r.slaveof() # 无参数时相当于SLAVEOF NO ONE
# 等待角色变化
for i in range(10):
time.sleep(1)
info = r.info()
if info['role'] == 'master':
return True, "Successfully promoted to master"
return False, "Failed to promote to master after 10 seconds"
except Exception as e:
return False, f"Error during promotion: {e}"
def redirect_slaves(original_slaves, new_master_host, new_master_port, password=None):
"""将从库重定向到新主库"""
results = []
for slave in original_slaves:
slave_host, slave_port = slave.split(':')
slave_port = int(slave_port)
try:
r = redis.Redis(host=slave_host, port=slave_port, password=password, socket_timeout=5)
# 检查当前角色
info = r.info()
if info['role'] != 'slave':
results.append(f"{slave}: Not a slave, skipping")
continue
# 如果是新主库自己,跳过
if slave_host == new_master_host and slave_port == new_master_port:
results.append(f"{slave}: This is the new master, skipping")
continue
# 重定向到新主库
r.slaveof(new_master_host, new_master_port)
results.append(f"{slave}: Redirected to new master {new_master_host}:{new_master_port}")
except Exception as e:
results.append(f"{slave}: Error - {e}")
return results
def main():
parser = argparse.ArgumentParser(description='Redis Failover Tool')
subparsers = parser.add_subparsers(dest='command', help='Commands')
# 检查服务器状态命令
check_parser = subparsers.add_parser('check', help='Check Redis server status')
check_parser.add_argument('--host', required=True, help='Redis host')
check_parser.add_argument('--port', type=int, required=True, help='Redis port')
check_parser.add_argument('--password', help='Redis password')
# 手动故障转移命令
failover_parser = subparsers.add_parser('failover', help='Perform manual failover')
failover_parser.add_argument('--new-master', required=True, help='New master (host:port)')
failover_parser.add_argument('--slaves', required=True, help='Comma-separated list of slaves (host:port)')
failover_parser.add_argument('--password', help='Redis password')
args = parser.parse_args()
if args.command == 'check':
success, info, role = get_redis_info(args.host, args.port, args.password)
if success:
print(f"Server: {args.host}:{args.port}")
print(f"Role: {role}")
print(f"Redis Version: {info.get('redis_version', 'unknown')}")
print(f"Connected Clients: {info.get('connected_clients', 'unknown')}")
if role == 'master':
print(f"Connected Slaves: {info.get('connected_slaves', 0)}")
print(f"Replication Offset: {info.get('master_repl_offset', 0)}")
elif role == 'slave':
print(f"Master Host: {info.get('master_host', 'unknown')}")
print(f"Master Port: {info.get('master_port', 'unknown')}")
print(f"Master Link Status: {info.get('master_link_status', 'unknown')}")
print(f"Slave Replication Offset: {info.get('slave_repl_offset', 0)}")
else:
print(f"Error checking server: {info}")
sys.exit(1)
elif args.command == 'failover':
# 解析新主库和从库信息
new_master_host, new_master_port = args.new_master.split(':')
new_master_port = int(new_master_port)
slaves = args.slaves.split(',')
# 提升新主库
print(f"Promoting {args.new_master} to master...")
success, message = promote_slave(new_master_host, new_master_port, args.password)
if not success:
print(f"Failed to promote new master: {message}")
sys.exit(1)
print(message)
# 重定向其他从库
print("Redirecting slaves to new master...")
results = redirect_slaves(slaves, new_master_host, new_master_port, args.password)
for result in results:
print(result)
if __name__ == "__main__":
main()使用示例:
# 检查服务器状态
python redis_failover.py check --host redis-1 --port 6379
# 执行手动故障转移
python redis_failover.py failover \
--new-master redis-2:6379 \
--slaves redis-1:6379,redis-2:6379,redis-3:6379 \
--password mypassword十、总结与展望
经过深入探讨Redis主从复制的原理与实践,我们已经掌握了构建高可用Redis缓存架构的核心知识。让我们总结一下关键要点,并展望未来的发展方向。
主从复制技术的核心价值回顾
Redis主从复制技术的价值可以用四个关键词概括:可靠性、扩展性、性能和灵活性。
具体表现在:
数据冗余与备份:主从复制为数据提供了多个副本,大大增强了系统的容灾能力。正如我们在电商秒杀系统案例中看到的,即使在极端负载下,系统依然保持高可用。
负载分担:读写分离架构使系统能够支持更高的并发访问,每个从库都能分担一部分读取负载,显著提升整体性能。
高可用基础:主从复制为Sentinel和Cluster等高可用方案提供了基础支持,使得自动故障转移成为可能。
地理分布:通过跨地域部署主从架构,我们能够实现就近读取,降低用户访问延迟,提升用户体验。
Redis未来版本中的复制机制改进
Redis复制机制在不断演进,未来版本可能带来以下改进:
增强的部分重同步:更智能的复制机制,能够在从库重启后只同步必要的数据,减少全量同步的需要。
同步复制选项:为关键操作提供同步复制选项,确保数据写入多个节点后才返回成功,提高数据安全性。
复制流量压缩:更高效的复制流量压缩算法,减少网络带宽消耗,特别是在跨地域复制场景。
智能复制调度:基于负载和网络状况自动调整复制策略,优化资源利用。
增强的监控与诊断:更详细的复制状态指标和诊断工具,帮助运维人员快速定位和解决复制问题。
高可用缓存架构的发展趋势
缓存架构也在不断演进,以下是值得关注的发展趋势:
混合架构:结合多种缓存技术,如Redis+本地缓存的多级缓存架构,或Redis+其他存储系统的混合架构。
无状态化:将缓存系统设计为更加无状态的服务,便于容器化部署和弹性扩展。
自动化运维:更智能的自动扩缩容、自动故障转移和自动参数调优,减少人工干预。
多云部署:跨云厂商的缓存架构部署,避免单一云厂商的依赖和风险。
边缘计算整合:将缓存系统扩展到边缘节点,进一步降低访问延迟。
个人经验总结与建议
经过多年的Redis实践,我想分享一些个人心得:
从简单开始:先搭建基础的主从结构,掌握基本原理后再考虑引入Sentinel或Cluster。
监控先行:在引入生产环境前,确保有完善的监控系统,能够及时发现和报警潜在问题。
定期演练:定期进行故障转移演练,确保团队熟悉应急流程,系统真正出现问题时不会手忙脚乱。
参数调优是艺术:Redis配置调优没有放之四海而皆准的标准,需要根据具体业务场景和资源条件不断调整和验证。
持续学习:Redis生态在不断发展,定期关注官方文档和社区动态,保持技术敏感度。
最后,记住一句话:没有完美的架构,只有最适合当前业务场景的架构。希望本文能帮助你在Redis主从复制和高可用缓存架构的道路上走得更远!
感谢阅读本文!如果你有任何问题或经验想要分享,欢迎在评论区留言交流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号