

预训练的核心作用是赋予模型海量的知识,而所谓对齐,其实就是让模型与人类价值观一致,从而输出人类希望其输出的内容。也就是在数据并行的情况下, 每张GPU上的模型参数是保持一致的,训练的总批次大小等于每张卡上的批次大小之和。不过当LLM扩大到上百亿参数,单张GPU内存往往就无法存放完整的模型参数,如上图所示,此时可以将模型拆分到多个GPU上,每个GPU存放不同的层或不同部分,构建模型
1.幻觉
为什么LLM会有幻觉问题?
1)训练数据中的错误或缺失
2)LLM的核心是一个条件概率分布:P(xt∣x1,x2,...,xt−1)P(x_t|x_1,x_2,...,x_{t-1})P(xt∣x1,x2,...,xt−1),其目标是生成最流畅的句子,而不是最真实的句子。
3)语言模型只使用其参数中存储的知识,它不能实时验证信息,也不具备真正的“理解”。缺乏逻辑一致性检测和外部知识检索。
如何缓解幻觉?
1)RAG检索增强生成:在生成前,从外部知识库检索相关文档。
2)Instruction Tuning和RLHF(人类反馈强化学习):通过人工筛选的高质量数据微调模型;奖励“事实正确”“安全”“有依据”的回答;惩罚随意捏造的内容。
3)让模型使用外部API进行验证。
2.如何训练一个LLM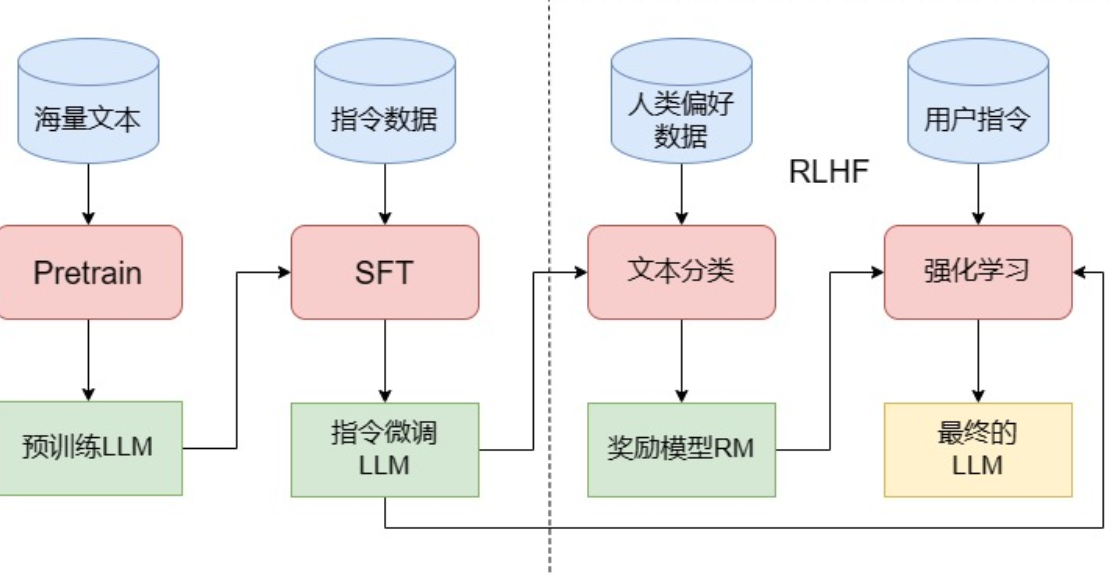
三个阶段:Pretrain、SFT、PLHF。
2.1 Pretrain
目前主流的LLM几乎都采用Decoder-Only架构,预训练任务也沿承了CLM。
分布式预训练框架 : 核心思路是数据并行和模型并行。
数据并行: 是指训练模型的尺寸可以被单个GPU容纳,但增大Batchsize会增大显存开销,同时训练数据非常大,使用单张GPU训练时长无法接受。因此,可以让模型在不同GPU和不同批数据上运行,每一次前向传递完成之后,收集所有实例的梯度并计算更新,更新模型参数后再传递到所有实例。也就是在数据并行的情况下, 每张GPU上的模型参数是保持一致的,训练的总批次大小等于每张卡上的批次大小之和。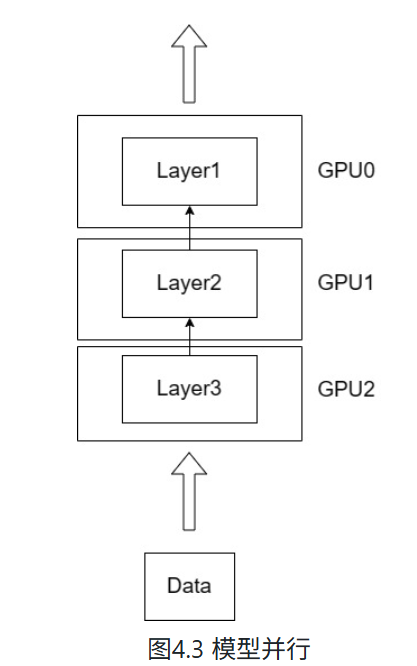
但是当LLM扩大到上百亿参数,单张GPU内存往往就无法存放完整的模型参数,如上图所示,此时可以将模型拆分到多个GPU上,每个GPU存放不同的层或不同部分,实现模型并行。
在数据并行和模型并行的思想基础上,还演化出了多种更高效的分布式方式,例如张量并行、3D 并行、ZeRO(Zero Redundancy Optimizer,零冗余优化器)等。目前,主流的分布式训练框架包括 Deepspeed、Megatron-LM、ColossalAI 等,其中,Deepspeed 使用面最广。
Deepspeed的核心策略是ZeRo和CPU-offload
ZeRo 将模型训练阶段每张卡被占用的显存分为两类:1)Model States,包括模型参数、梯度、优化器Adam的状态参数。2)Residual States,除了Model States之外的显存占用,包括激活值、各种缓存和显存碎片。
ZeRo提出了三种不断递进的优化策略:
1)ZeRo-1,对Model States中的Adam状态参数分片,每张卡只存储1/N的Adam状态参数,其它参数仍然保持每张卡一份。
2)ZeRo-2,继续对模型梯度进行分片,每张卡只存储 1/N的模型梯度和 Adam 状态参数,仅模型参数保持每张卡一份。
3)ZeRo-3,将模型参数也进行分片,每张卡只存储1/N的模型梯度、模型参数和 Adam 状态参数。
CPU-offload(CPU卸载) 指的是:模型训练或推理过程中,将一部分原本需要放在 GPU 显存中计算或存储的数据(比如模型权重、优化器状态、激活值等)临时转移到 CPU 内存中存储或计算,以减轻 GPU 显存压力。
2.2 SFT(Supervised Fine-Tuning)
LLM 的预训练任务就是经典的 CLM,也就是训练其预测下一个 token 的能力,在没有进一步微调之前,其无法与其他下游任务或是用户指令适配。
所谓指令微调,即我们训练的输入是各种类型的用户指令,而需要模型拟合的输出则是我们希望模型在收到该指令后做出的回复。例如,我们的一条训练样本可以是:
input:告诉我今天的天气预报?
output:根据天气预报,今天天气是晴转多云,最高温度26摄氏度,最低温度9摄氏度,昼夜温差大,请注意保暖哦一般SFT使用的指令数据集包含以下三个键:
{
"instruction":"即输入的用户指令",
"input":"执行该指令可能需要的补充输入,没有则置空",
"output":"即模型应该给出的回复"
}{
"instruction":"将下列文本翻译成英文:",
"input":"今天天气真好",
"output":"Today is a nice day!"
}多轮对话能力:是在SFT阶段学出来的。
方式一:只预测最后一句
input = <prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>
output = [MASK][MASK][MASK][MASK][MASK]<completion_3> 模型只学习最后一轮回答,中间对话都被当做输入,不参与训练。导致丢失中间轮次的信息。
方式二:每轮生成一个样本
input_1 = <prompt_1>
output_1 = <completion_1>
input_2 = <prompt_1><completion_1><prompt_2>
output_2 = <completion_2>
input_3 = <prompt_1><completion_1><prompt_2><completion_2><prompt_3>
output_3 = <completion_3> 样本间有大量重叠,重复计算相同的token。
方式三:在一次样本中预测所有轮次的回答
input = <prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>
output = [MASK]<completion_1>[MASK]<completion_2>[MASK]<completion_3>模型仍然能做CLM,从左到右预测token,模型看到<prompt_1>时,就会预测<completion_1>,看到<prompt_2>时,就会预测<completion_2>。
不丢信息:每一轮都被训练。无冗余:不重复计算相同上下文。
2.3 RLHF
从功能上出发,我们可以将 LLM 的训练过程分成预训练与对齐(alignment)两个阶段。预训练的核心作用是赋予模型海量的知识,而所谓对齐,其实就是让模型与人类价值观一致,从而输出人类希望其输出的内容。在这个过程中,SFT 是让 LLM 和人类的指令对齐,从而具有指令遵循能力;而 RLHF 则是从更深层次令 LLM 和人类价值观对齐,令其达到安全、有用、无害的核心标准。
RLHF 分为两个步骤:训练 RM(Reward Model) 和 PPO 训练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号