

详细介绍:RNN实战案例_人名分类器(包括RNN,LSTM,GRU三种模型)
代码分为四个部分:
1:数据预处理
步骤一
第一行代码是将52个大小写英文字母加5个特殊字符共57个字符放入字符表中;
categorys是放入的分类好的国家类别列表
all_letters = string.ascii_letters + " ,.;’" print(all_letters) n_letters = len(all_letters) # print('n_letters:', n_letters) categorys = ['Italian', 'English', 'Arabic', 'Spanish', 'Scottish', 'Irish', 'Chinese', 'Vietnamese', 'Japanese', 'French', 'Greek', 'Dutch', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Czech', 'German'] category_num = len(categorys)
步骤二
2.下面这段代码是从文件从读取数据并将他们拆分后放到列表list_x和list_y中
def read_data(filename): list_x = [] list_y = [] with open(filename, mode='r', encoding='utf-8') as f: data = f.readlines() # print('data:', data) for line in data: if len(line) <= 5: continue x, y = line.strip().split('\t') list_x.append(x) # 人名 list_y.append(y) # 国家 return list_x, list_y
这是源数据代码部分内容
步骤三
构造数据集dataset:一个继承,三个重写。将list_x, list_y变成属性
将特征(人名)数值化(独热编码)和张量化,将标签张量化
class NameClassifyDataset(Dataset): def __init__(self, list_x, list_y): self.list_x = list_x self.list_y = list_y self.sample_len = len(list_y) def __len__(self): return self.sample_len # 获取第几条 样本数据,item表示下标 def __getitem__(self, item): item = min(max(item, 0), self.sample_len - 1) # print(item) x = self.list_x[item] # x是具体的名字 y = self.list_y[item] tensor_x = torch.zeros(len(x), n_letters) # tensor_x是3* 57的张量,人名长度,字符数量(57) for idx, letter in enumerate(x): tensor_x[idx][all_letters.find(letter)] = 1 tensor_y = torch.tensor(categorys.index(y)) # 找到y的下标,并将它转为张量 # print('x:', x) # print('y', y) # return x, y # print('tensor_x', tensor_x) # print('tensor_y', tensor_y) return tensor_x, tensor_y步骤四(测试dataset类)
dataset转dataloader,并且升维,将[seq_length,n_letters]的二维数据变成三维的(将batch_size加到数据前变成[batch_size,seq_length,n_letters]。这三个参数分别为:批次数;
token长度(如果人名为‘ming’,那么它就是4);映射成的独热编码维度(这里是57维)
def test_name_classify_dataset(): list_x, list_y = read_data('../data/name_classfication.txt') # print(len(list_x), len(list_y)) # print(type(list_x), type(list_y)) my_dataset = NameClassifyDataset(list_x, list_y) # 由于 batch_size=1,所以是 [1, seq_len, n_letters] 数据变成三维的,添加了一个批次数 my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1) for tensor_x, tensor_y in my_dataloader: print('tensorx:', tensor_x.shape) print('tensory:', tensor_y.shape) # break
2:模型构建
构建RNN模型
构建RNN模型:一个继承,两个重写。继承nn.Module类,重写init和forward方法。这里的inithidden()方法是初始化隐藏层数据的。在init方法中:self.rnn是构建循环神经网络,self.linear是构建一个线性层,softmax是一个激活函数通常与NLLLoss损失函数配套使用。LogSoftmax + NLLLoss 等价于 nn.CrossEntropyLoss
class MyRNN(nn.Module): def __init__(self, input_size, hidden_size, output_size, num_layers=1): super().__init__() self.input_size = input_size self.hidden_size = hidden_size # 最终结果输出数据维度大小,这里是18维度 self.output_size = output_size self.num_layers = num_layers # 准备神经网络 self.rnn = nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True) self.linear = nn.Linear(in_features=hidden_size, out_features=output_size) self.softmax = nn.LogSoftmax(dim=-1) def forward(self, input, hidden): output, hidden = self.rnn(input, hidden) #input 和 hidden 数据形状分别是[1, 4, 128] , [1, 1, 128] out = self.linear(output[:, -1]) #因为是4个token,每个token128维表示 return self.softmax(out), hidden def inithidden(self): return torch.zeros(self.num_layers, 1, self.hidden_size)测试代码
def test_my_rnn(): # 加载数据 list_x, list_y = read_data('../data/name_classfication.txt') my_dataset = NameClassifyDataset(list_x, list_y) my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1) print(my_dataloader) rnn = MyRNN(input_size=57, hidden_size=128, output_size=18, num_layers=1) for x, y in my_dataloader: output, hidden = rnn(x, rnn.inithidden()) print(output, output.shape) print(hidden, hidden.shape)依次构建LSTM和GRU模型
LSTM模型在输入参数比RNN多了一个细胞状态c0,初始化时直接初始化成和h0一样的就行,输出也是一样的。GRU和RNN就是名字不一样,其他参数相同
class MyLSTM(nn.Module): def __init__(self, input_size, hidden_size, output_size, num_layers=1): super().__init__() self.input_size = input_size self.hidden_size = hidden_size # 最终结果输出数据维度大小,这里是18维度 self.output_size = output_size self.num_layers = num_layers # 准备神经网络 self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True) self.linear = nn.Linear(in_features=hidden_size, out_features=output_size) self.softmax = nn.LogSoftmax(dim=-1) def forward(self, input, hidden, c0): output, (hidden, c0) = self.lstm(input, (hidden, c0)) out = self.linear(output[:, -1]) return self.softmax(out), hidden, c0 def inithidden(self): return torch.zeros(self.num_layers, 1, self.hidden_size) def test_my_lstm(): # 加载数据 list_x, list_y = read_data('../data/name_classfication.txt') my_dataset = NameClassifyDataset(list_x, list_y) my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1) print(my_dataloader) rnn = MyLSTM(input_size=57, hidden_size=128, output_size=18, num_layers=1) for x, y in my_dataloader: output, hidden, cn = rnn(x, rnn.inithidden(), rnn.inithidden()) print(output, output.shape) print(hidden, hidden.shape) print(cn, cn.shape) class MyGRU(nn.Module): def __init__(self, input_size, hidden_size, output_size, num_layers=1): super().__init__() self.input_size = input_size self.hidden_size = hidden_size # 最终结果输出数据维度大小,这里是18维度 self.output_size = output_size self.num_layers = num_layers # 准备神经网络 self.gru = nn.GRU(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True) self.linear = nn.Linear(in_features=hidden_size, out_features=output_size) self.softmax = nn.LogSoftmax(dim=-1) def forward(self, input, hidden): output, hidden = self.gru(input, hidden) out = self.linear(output[:, -1]) return self.softmax(out), hidden def inithidden(self): return torch.zeros(self.num_layers, 1, self.hidden_size) def test_my_gru(): # 加载数据 list_x, list_y = read_data('../data/name_classfication.txt') my_dataset = NameClassifyDataset(list_x, list_y) my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1) print(my_dataloader) gru = MyGRU(input_size=57, hidden_size=128, output_size=18, num_layers=1) for x, y in my_dataloader: output, hidden = gru(x, gru.inithidden()) print(output, output.shape) print(hidden, hidden.shape)
3:模型训练
RNN模型训练
大致流程就是:
构建数据集,构建模型,构建优化器,构建损失函数;
外层遍历轮次,内层遍历批次;
前向传播,损失函数计算,梯度清零,反向传播,梯度更新;
保存模型
def train_rnn_model(): # 加载数据 # 轮次 # 遍历 # # 把数据给模型 # 计算损失 # 梯度清零 # 反向传播 # 梯度更新 # 模型评估(预测) list_x, list_y = read_data('../data/name_classfication.txt') # print(len(list_x), len(list_y)) my_dataset = NameClassifyDataset(list_x, list_y) my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1) rnn = MyRNN(input_size=n_letters, hidden_size=128, output_size=category_num, num_layers=1) criterion = nn.NLLLoss() optimizer = optm.Adam(params=rnn.parameters(), lr=1e-3, betas=(0.9, 0.99)) epochs = 1 start_time = time.time() total_iter_num = 0 # 已训练的样本数 total_loss = 0.0 # 已训练的损失和 total_loss_list = [] # 每100个样本求一次平均损失 形成损失列表 total_acc_num = 0 # 已训练样本预测准确总数 total_acc_list = [] # 每100个样本求一次平均准确率 形成平均准确率列表 for epoch in range(epochs): for x, y in tqdm(my_dataloader): output, hidden = rnn(x, rnn.inithidden()) loss = criterion(output, y) optimizer.zero_grad() loss.backward() optimizer.step() total_iter_num += len(y) total_loss += loss.item() flag = (torch.argmax(output, dim=-1) == y).sum().item() total_acc_num += flag if total_iter_num % 100 == 0: avg_loss = total_loss / total_iter_num avg_acc = total_acc_num / total_iter_num total_loss_list.append(avg_loss) total_acc_list.append(avg_acc) if total_iter_num % 1000 == 0: avg_loss = total_loss / total_iter_num total_time = time.time() - start_time print('epoch:', epoch + 1, 'loss', avg_loss, 'time', total_time) spend_time = time.time() - start_time data = {'total_loss_list': total_loss_list, 'total_acc_list': total_acc_list, 'spend_time': spend_time} with open('../data/rnn.json', mode='w', encoding='utf-8') as f: f.write(json.dumps(data)) torch.save(rnn.state_dict(), '../save_model/rnn_%d.pth' % (epoch + 1))LSTM和GRU模型训练
def train_lstm_model(): list_x, list_y = read_data('../data/name_classfication.txt') # print(len(list_x), len(list_y)) my_dataset = NameClassifyDataset(list_x, list_y) my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1) lstm = MyLSTM(input_size=n_letters, hidden_size=128, output_size=category_num, num_layers=1) criterion = nn.NLLLoss() optimizer = optm.Adam(params=lstm.parameters(), lr=1e-3, betas=(0.9, 0.99)) epochs = 1 start_time = time.time() total_iter_num = 0 # 已训练的样本数 total_loss = 0.0 # 已训练的损失和 total_loss_list = [] # 每100个样本求一次平均损失 形成损失列表 total_acc_num = 0 # 已训练样本预测准确总数 total_acc_list = [] # 每100个样本求一次平均准确率 形成平均准确率列表 for epoch in range(epochs): for x, y in tqdm(my_dataloader): output, hidden, cn = lstm(x, lstm.inithidden(), lstm.inithidden()) loss = criterion(output, y) optimizer.zero_grad() loss.backward() optimizer.step() total_iter_num += len(y) total_loss += loss.item() flag = (torch.argmax(output, dim=-1) == y).sum().item() total_acc_num += flag if total_iter_num % 100 == 0: avg_loss = total_loss / total_iter_num avg_acc = total_acc_num / total_iter_num total_loss_list.append(avg_loss) total_acc_list.append(avg_acc) if total_iter_num % 1000 == 0: avg_loss = total_loss / total_iter_num total_time = time.time() - start_time print('epoch:', epoch + 1, 'loss', avg_loss, 'time', total_time) spend_time = time.time() - start_time data = {'total_loss_list': total_loss_list, 'total_acc_list': total_acc_list, 'spend_time': spend_time} with open('../data/lstm.json', mode='w', encoding='utf-8') as f: f.write(json.dumps(data)) torch.save(lstm.state_dict(), '../save_model/lstm_%d.pth' % (epoch + 1)) def train_gru_model(): list_x, list_y = read_data('../data/name_classfication.txt') # print(len(list_x), len(list_y)) my_dataset = NameClassifyDataset(list_x, list_y) my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1) gru = MyGRU(input_size=n_letters, hidden_size=128, output_size=category_num, num_layers=1) criterion = nn.NLLLoss() optimizer = optm.Adam(params=gru.parameters(), lr=1e-3, betas=(0.9, 0.99)) epochs = 1 start_time = time.time() total_iter_num = 0 total_loss = 0.0 total_loss_list = [] total_acc_num = 0 total_acc_list = [] for epoch in range(epochs): for x, y in tqdm(my_dataloader): output, hidden = gru(x, gru.inithidden()) loss = criterion(output, y) optimizer.zero_grad() loss.backward() optimizer.step() total_iter_num += len(y) total_loss += loss.item() flag = (torch.argmax(output, dim=-1) == y).sum().item() total_acc_num += flag if total_iter_num % 100 == 0: avg_loss = total_loss / total_iter_num avg_acc = total_acc_num / total_iter_num total_loss_list.append(avg_loss) total_acc_list.append(avg_acc) if total_iter_num % 1000 == 0: avg_loss = total_loss / total_iter_num total_time = time.time() - start_time print('epoch:', epoch + 1, 'loss', avg_loss, 'time', total_time) spend_time = time.time() - start_time data = {'total_loss_list': total_loss_list, 'total_acc_list': total_acc_list, 'spend_time': spend_time} with open('../data/rnn.json', mode='w', encoding='utf-8') as f: f.write(json.dumps(data)) torch.save(gru.state_dict(), '../save_model/gru_%d.pth' % (epoch + 1))画图:
这里的read_json_data和draw_graph是基于模型训练中得到的数据转为json文件,然后进行画图,可以更加直观地展示三种模型的预测准确度,训练时间差异等
def read_json_data(filename): # 加载json文件数据 with open(filename, mode='r', encoding='utf-8') as f: data = json.loads(f.read()) # 基于data数据,获取对应的指标结果 total_loss_list = data['total_loss_list'] total_acc_list = data['total_acc_list'] spend_time = data['spend_time'] # 返回结果数据 return total_loss_list, spend_time, total_acc_list def draw_graph(): # 加载各个模型的数据 total_loss_list_rnn, total_time_rnn, total_acc_list_rnn = read_json_data('./data/rnn.json') total_loss_list_lstm, total_time_lstm, total_acc_list_lstm = read_json_data('./data/lstm.json') total_loss_list_gru, total_time_gru, total_acc_list_gru = read_json_data('./data/gru.json') # 画图,3个模型的损失曲线变化图 plt.plot(total_loss_list_rnn, label='rnn') plt.plot(total_loss_list_lstm, label='lstm', color='red') plt.plot(total_loss_list_gru, label='gru', color='orange') plt.legend(loc="best") plt.savefig("./data/loss.png") plt.show() # 画图,3个模型的运行时间柱状图 x_data = ["RNN", "LSTM", "GRU"] y_data = [total_time_rnn, total_time_lstm, total_time_gru] # 绘制训练耗时对比柱状图 plt.bar(x_data, y_data, tick_label=x_data) plt.savefig('./time.png') plt.show() # 画图,3个模型的准确率曲线变化图 plt.plot(total_acc_list_rnn, label='rnn') plt.plot(total_acc_list_lstm, label='lstm', color='red') plt.plot(total_acc_list_gru, label='gru', color='orange') plt.legend(loc="best") plt.savefig("./data/acc.png") plt.show()
4:模型评估
line2tensor方法是将输入的人名进行数据化,张量化;
下面这段代码:output是一个1*18的张量,表示一个样本在18个类别上的预测概率分布。
topk()方法是取出概率最高的值和索引。对应的索引就是在categorys中的索引,它是一个二维的数据。所以通过topi[0][i]的方式取出前三个值
topy, topi = torch.topk(output, k=3)
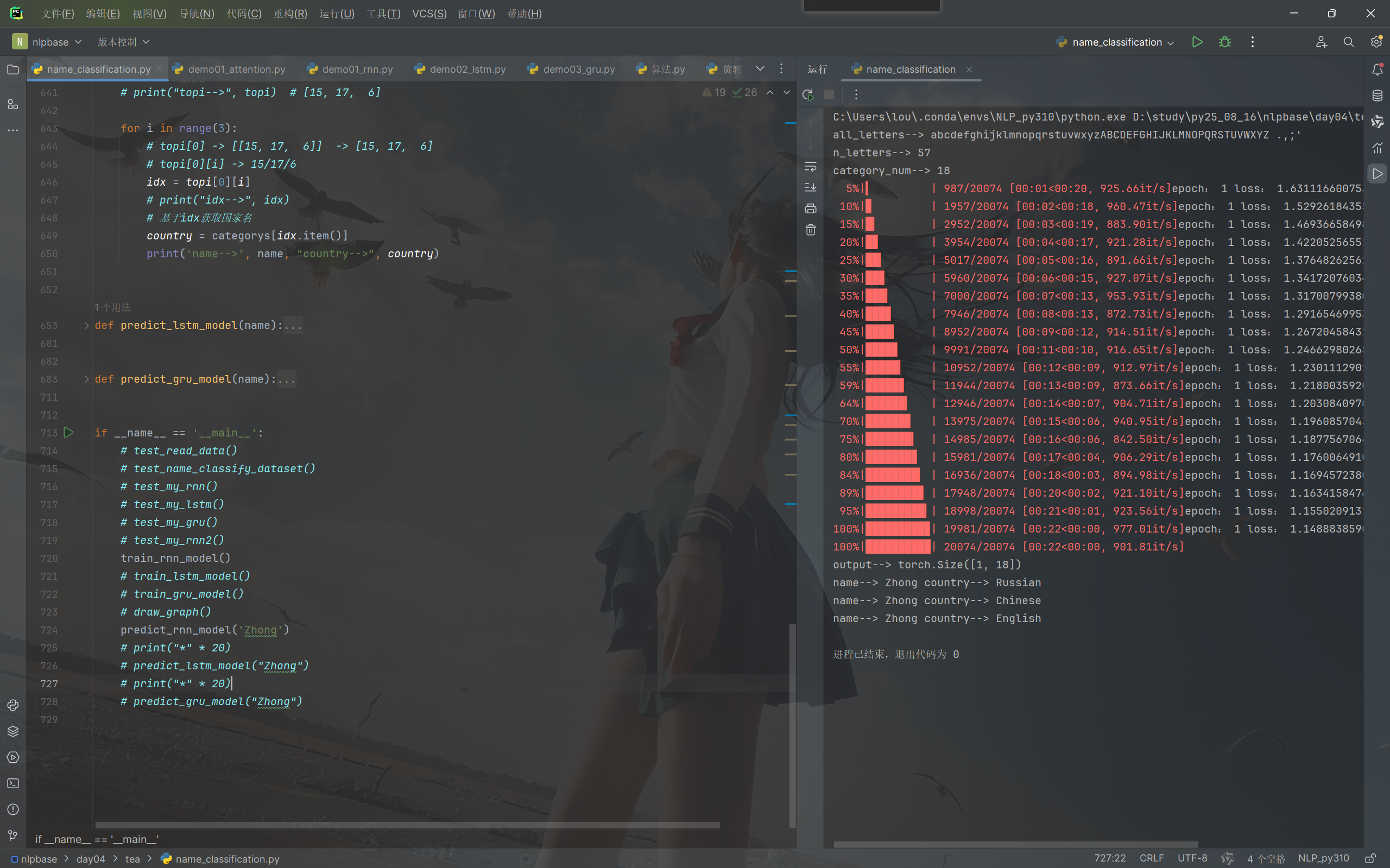
def line2tensor(name): tensor_x = torch.zeros(len(name), n_letters) for idx, letter in enumerate(name): tensor_x[idx][all_letters.find(letter)] = 1 return tensor_x # 前 k 个最高概率值 这些值对应类别标签的索引 def predict_rnn_model(name): tensor_x = line2tensor(name) rnn = MyRNN(input_size=n_letters, hidden_size=128, output_size=category_num, num_layers=1) rnn.load_state_dict(torch.load('../save_model/rnn_1.pth')) rnn.eval() output, hidden = rnn(tensor_x.unsqueeze(0), rnn.inithidden()) print('output:', output) print('output:', output.shape) # 获取结果 # 前 k 个最高概率值 这些值对应类别标签的索引 # topi = tensor([[2, 1, 0]]) 它是二维的,所以第一个取0 # output 是一个 1×18 的张量,表示一个样本在18个类别上的预测概率分布 topy, topi = torch.topk(output, k=3) for i in range(3): idx = topi[0][i] country = categorys[idx.item()] print('name:', name, 'category:', country)输出即为预测的前三个最大概率的国家名字,可以看到我们的轮次设为epoch=1,训练不够充分,可以将轮次调高一些会提高预测准确率
后边我这里训练了30轮,再次预测
5:下面是总代码~~
import string
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
import time
import json
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
# TODO 1.数据预处理
# 准备工作
# 所有字母组合
all_letters = string.ascii_letters + " .,;'"
print("all_letters-->", all_letters)
n_letters = len(all_letters)
print("n_letters-->", n_letters)
# 所有国家名
categorys = ['Italian', 'English', 'Arabic', 'Spanish', 'Scottish', 'Irish', 'Chinese', 'Vietnamese', 'Japanese',
'French', 'Greek', 'Dutch', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Czech', 'German']
# 国家名个数,18个国家,也就是18分类。
category_num = len(categorys)
print("category_num-->", category_num)
def read_data(filename):
# 定义2个列表,用于存储x和y
list_x = []
list_y = []
# with open打开文件,读取数据
with open(filename, mode='r', encoding='utf-8') as f:
data = f.readlines()
# data在with里面和外面都可以用。
# print("data-->", data)
for line in data:
# 异常样本过滤
if len(line) <= 5:
continue
# 元组拆包(解包)
x, y = line.strip().split("\t")
# print("x-->", x)
# print("y-->", y)
list_x.append(x)
list_y.append(y)
# 打印list_x和list_y的结果
# print("list_x-->", list_x)
# print("list_y-->", list_y)
# 返回结果
return list_x, list_y
def test_read_data():
list_x, list_y = read_data('./data/name_classfication.txt')
# print("list_x-->", list_x)
# print("list_y-->", list_y)
print("len(list_x)-->", len(list_x))
print("len(list_y)-->", len(list_y))
class NameClassifyDataset(Dataset):
def __init__(self, list_x, list_y):
# 属性
self.list_x = list_x
self.list_y = list_y
# 长度属性
self.sample_len = len(list_y)
def __len__(self):
return self.sample_len
def __getitem__(self, item):
# 修正item
item = min(max(item, 0), self.sample_len - 1)
# 基于item得到x和y
x = self.list_x[item]
y = self.list_y[item]
# print("x-->", x) # Abl
# print("y-->", y) # Czech
# 对x和y仅数值化和张量化
tensor_x = torch.zeros(len(x), n_letters)
# print("tensor_x-->", tensor_x.shape) # [3, 57]
for idx, letter in enumerate(x):
# 打印idx和letter:[0 A] | [1 b] | [2 l]
# print(idx, letter)
tensor_x[idx][all_letters.find(letter)] = 1
# print("tensor_x-->", tensor_x)
# 对y进行数值化和张量化
tensor_y = torch.tensor(categorys.index(y))
# print("tensor_y-->", tensor_y)
# 返回结果
return tensor_x, tensor_y
def test_name_classify_dataset():
# 加载数据
list_x, list_y = read_data('./data/name_classfication.txt')
# 初始化Dataset对象,调用了init方法
my_dataset = NameClassifyDataset(list_x, list_y)
# 把Dataset转换为DataLoader
# 作用:乱序,升维
my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1)
# 遍历
for tensor_x, tensor_y in my_dataloader:
print("tensor_x-->", tensor_x, tensor_x.shape)
print("tensor_y-->", tensor_y, tensor_y.shape)
break
# TODO 2.模型构建
class MyRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super().__init__()
# input_size:输入数据维度大小
self.input_size = input_size
# hidden_size:隐藏层(RNN输出)数据维度大小
self.hidden_size = hidden_size
# output_size:最终结果输出数据维度大小,这里我们是18分类(18个国家)
self.output_size = output_size
# num_layers:RNN的层数
self.num_layers = num_layers
# 准备神经网络
self.rnn = nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.linear = nn.Linear(in_features=hidden_size, out_features=output_size)
# 手动softmax,dim=-1,表示对数据最后一个维度进行softmax
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
# print("input-->", input.shape) # [1, 4, 57]
# print("hidden-->", hidden.shape) # [1, 1, 128]
# 把数据送给模型
output, hidden = self.rnn(input, hidden)
# print("output-->", output.shape) # [1, 4, 128]
# print("output[-1]-->", output[:, -1], output[:, -1].shape) # [1, 128]
# print("hidden-->", hidden, hidden.shape) # [1, 1, 128]
# 把最后一个token的结果送给线性层,预测18个国家中的哪一个
out = self.linear(output[:, -1])
# print("out-->", out, out.shape) # [1, 18]
# 手动softmax
return self.softmax(out), hidden
def inithidden(self):
# num_layers, batch_size, hidden_size -> (1,1,128)
return torch.zeros(self.num_layers, 1, self.hidden_size)
def test_my_rnn():
# 加载数据
list_x, list_y = read_data('./data/name_classfication.txt')
# 初始化Dataset对象,调用了init方法
my_dataset = NameClassifyDataset(list_x, list_y)
# 把Dataset转换为DataLoader
# 作用:乱序,升维
my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1)
# 调用init方法
rnn = MyRNN(input_size=57, hidden_size=128, output_size=18, num_layers=1)
# 遍历 x, y分别是数据和标签。数据是三维的形状为 [batch_size, seq_len, n_letters]
for x, y in my_dataloader:
# 调用forward方法
out, hidden = rnn(x, rnn.inithidden())
print("out-->", out, out.shape)
print("hidden-->", hidden, hidden.shape)
break
class MyLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super().__init__()
# input_size:输入数据维度大小
self.input_size = input_size
# hidden_size:隐藏层(RNN输出)数据维度大小
self.hidden_size = hidden_size
# output_size:最终结果输出数据维度大小,这里我们是18分类(18个国家)
self.output_size = output_size
# num_layers:RNN的层数
self.num_layers = num_layers
# 准备神经网络
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.linear = nn.Linear(in_features=hidden_size, out_features=output_size)
# 手动softmax,dim=-1,表示对数据最后一个维度进行softmax
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden, c0):
# print("input-->", input.shape) # [1, 4, 57]
# print("hidden-->", hidden.shape) # [1, 1, 128]
# 把数据送给模型
output, (hidden, cn) = self.lstm(input, (hidden, c0))
# print("output-->", output.shape) # [1, 4, 128]
# print("output[-1]-->", output[:, -1], output[:, -1].shape) # [1, 128]
# print("hidden-->", hidden, hidden.shape) # [1, 1, 128]
# 把最后一个token的结果送给线性层,预测18个国家中的哪一个
out = self.linear(output[:, -1])
# print("out-->", out, out.shape) # [1, 18]
# 手动softmax
return self.softmax(out), hidden, cn
def inithidden(self):
# num_layers, batch_size, hidden_size -> (1,1,128)
return torch.zeros(self.num_layers, 1, self.hidden_size)
def test_my_lstm():
# 加载数据
list_x, list_y = read_data('./data/name_classfication.txt')
# 初始化Dataset对象,调用了init方法
my_dataset = NameClassifyDataset(list_x, list_y)
# 把Dataset转换为DataLoader
# 作用:乱序,升维
my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1)
# 调用init方法
lstm = MyLSTM(input_size=57, hidden_size=128, output_size=18, num_layers=1)
# 遍历
for x, y in my_dataloader:
# 调用forward方法
# lstm():调用我们自定义的MyLSTM的forward方法,而这个方法中,有3个入参,不需要括号。
# 在自定义的forward中,再次调用PyTorch的nn.LSTM()的forward方法,而这里只有2个入参(需要有元组,需要括号)
out, hidden, cn = lstm(x, lstm.inithidden(), lstm.inithidden())
print("out-->", out, out.shape)
print("hidden-->", hidden, hidden.shape)
print("cn-->", cn, cn.shape)
break
class MyGRU(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super().__init__()
# input_size:输入数据维度大小
self.input_size = input_size
# hidden_size:隐藏层(RNN输出)数据维度大小
self.hidden_size = hidden_size
# output_size:最终结果输出数据维度大小,这里我们是18分类(18个国家)
self.output_size = output_size
# num_layers:RNN的层数
self.num_layers = num_layers
# 准备神经网络
self.gru = nn.GRU(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.linear = nn.Linear(in_features=hidden_size, out_features=output_size)
# 手动softmax,dim=-1,表示对数据最后一个维度进行softmax
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
# print("input-->", input.shape) # [1, 4, 57]
# print("hidden-->", hidden.shape) # [1, 1, 128]
# 把数据送给模型
output, hidden = self.gru(input, hidden)
# print("output-->", output.shape) # [1, 4, 128]
# print("output[-1]-->", output[:, -1], output[:, -1].shape) # [1, 128]
# print("hidden-->", hidden, hidden.shape) # [1, 1, 128]
# 把最后一个token的结果送给线性层,预测18个国家中的哪一个
out = self.linear(output[:, -1])
# print("out-->", out, out.shape) # [1, 18]
# 手动softmax
return self.softmax(out), hidden
def inithidden(self):
# num_layers, batch_size, hidden_size -> (1,1,128)
return torch.zeros(self.num_layers, 1, self.hidden_size)
def test_my_gru():
# 加载数据
list_x, list_y = read_data('./data/name_classfication.txt')
# 初始化Dataset对象,调用了init方法
my_dataset = NameClassifyDataset(list_x, list_y)
# 把Dataset转换为DataLoader
# 作用:乱序,升维
my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1)
# 调用init方法
gru = MyGRU(input_size=57, hidden_size=128, output_size=18, num_layers=1)
# 遍历
for x, y in my_dataloader:
# 调用forward方法
out, hidden = gru(x, gru.inithidden())
print("out-->", out, out.shape)
print("hidden-->", hidden, hidden.shape)
break
class MyRNN2(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super().__init__()
# input_size:输入数据维度大小
self.input_size = input_size
# hidden_size:隐藏层(RNN输出)数据维度大小
self.hidden_size = hidden_size
# output_size:最终结果输出数据维度大小,这里我们是18分类(18个国家)
self.output_size = output_size
# num_layers:RNN的层数
self.num_layers = num_layers
# 准备神经网络
self.rnn = nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
self.linear = nn.Linear(in_features=hidden_size, out_features=output_size)
# 手动softmax,dim=-1,表示对数据最后一个维度进行softmax
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
print("input0-->", input.shape) # [1, 5, 57]
print("hidden-->", hidden.shape) # [1, 1, 128]
# 交换维度 [1, 8, 57]
# 因为模型输入要求是:[seq_len, batch_size, input_size],
# 而目前数据形状是:[batch_size, seq_len, input_size],所以需要对数据进行交换维度
input = input.transpose(0, 1)
print("input1-->", input.shape) # [5, 1, 57]
# 把数据送给模型
output, hidden = self.rnn(input, hidden)
print("output1-->", output.shape) # [5, 1, 128]
# 把数据送给线性层,得到18分类的结果,但是线性层一般接收2维数据,所以,要把3维变为2维(从3维得到2维)
# 我们是一个字母一个字母送给模型,所以拿最后一个字母的结果当做整个的最终结果了
# print('01-->', output[-1].shape) # [1, 128]
# print('02-->', output[-1, :, :].shape) # [1, 128]
out = self.linear(output[-1]) # [1, 18]
# 返回结果
return self.softmax(out), hidden
def inithidden(self):
# hidden:num_layers, batch_size, hidden_size
# 正式的训练函数中,batch_size基本上不会是1,但是这里先给1,后面再对batch_size微调
return torch.zeros(self.num_layers, 1, self.hidden_size)
def test_my_rnn2():
# 加载数据
list_x, list_y = read_data('./data/name_classfication.txt')
# 初始化Dataset对象,调用了init方法
my_dataset = NameClassifyDataset(list_x, list_y)
# 把Dataset转换为DataLoader
# 作用:乱序,升维
my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1)
# 调用init方法
rnn = MyRNN2(input_size=57, hidden_size=128, output_size=18, num_layers=1)
# 遍历
for x, y in my_dataloader:
# 调用forward方法
hidden = rnn.inithidden()
# 数据形状:[batch_size, seq_len, input_size]
# [1, 5, 57]:1个批次,5个token(5个字母), 每个字母使用57维度的向量表示,
# print("x-->", x.shape)
# print("hidden-->", hidden.shape)
out, hidden = rnn(x, hidden)
print("out-->", out, out.shape)
print("hidden-->", hidden.shape)
break
# TODO 3.模型训练
def train_rnn_model():
# 加载数据
list_x, list_y = read_data('./data/name_classfication.txt')
# 转换为Dataset
my_dataset = NameClassifyDataset(list_x, list_y)
# 转换为DataLoader
my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1)
# 初始化模型
rnn = MyRNN(input_size=n_letters, hidden_size=128, output_size=category_num, num_layers=1)
# 损失函数,这里只能是NLLLoss,因为forward函数中已经做了softmax计算了
criterion = nn.NLLLoss()
# 优化器,1e-3 = 0.001
optimizer = optim.Adam(params=rnn.parameters(), lr=1e-3, betas=(0.9, 0.99))
# 轮次
epochs = 1
# 参数
start_time = time.time()
total_iter_num = 0 # 已训练的样本数
total_loss = 0.0 # 已训练的损失和
total_loss_list = [] # 每100个样本求一次平均损失 形成损失列表
total_acc_num = 0 # 已训练样本预测准确总数
total_acc_list = [] # 每100个样本求一次平均准确率 形成平均准确率列表
# 遍历(外层遍历轮次,内层遍历批次)
for epoch in range(epochs):
for x,y in tqdm(my_dataloader):
# 把数据送给模型
output, hidden = rnn(x, rnn.inithidden())
# 计算损失
loss = criterion(output, y)
# print("loss-->", loss)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 梯度更新
optimizer.step()
# 参数纪录
# 纪录total_iter_num
total_iter_num += len(y)
total_loss += loss.item()
flag = (torch.argmax(output, dim=-1) == y).sum().item()
total_acc_num += flag
# 每隔100个样本纪录一下total_loss_list和total_acc_list,用于画图
if total_iter_num % 100 == 0:
# 计算平均损失
avg_loss = total_loss / total_iter_num
# 计算平均准确率
avg_acc = total_acc_num / total_iter_num
# 把平均损失和准确率纪录到列表中
total_loss_list.append(avg_loss)
total_acc_list.append(avg_acc)
# 每隔1000个样本打印日志
if total_iter_num % 1000 == 0:
avg_loss = total_loss / total_iter_num
total_time = time.time() - start_time
print("epoch:", epoch + 1, "loss:", avg_loss, "time:", total_time)
# 保存画图用的列表数据
spend_time = time.time() - start_time
data = {"total_loss_list" : total_loss_list, "total_acc_list" : total_acc_list, "spend_time" : spend_time}
with open('./data/rnn.json', mode='w', encoding='utf-8') as f:
f.write(json.dumps(data))
# 模型保存
torch.save(rnn.state_dict(), './save_model/rnn_%d.pth' % (epoch + 1))
def train_lstm_model():
# 加载数据
list_x, list_y = read_data('./data/name_classfication.txt')
# 转换为Dataset
my_dataset = NameClassifyDataset(list_x, list_y)
# 转换为DataLoader
my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1)
# 初始化模型
lstm = MyLSTM(input_size=n_letters, hidden_size=128, output_size=category_num, num_layers=1)
# 损失函数,这里只能是NLLLoss,因为forward函数中已经做了softmax计算了
criterion = nn.NLLLoss()
# 优化器,1e-3 = 0.001
optimizer = optim.Adam(params=lstm.parameters(), lr=1e-3, betas=(0.9, 0.99))
# 轮次
epochs = 1
# 参数
start_time = time.time()
total_iter_num = 0 # 已训练的样本数
total_loss = 0.0 # 已训练的损失和
total_loss_list = [] # 每100个样本求一次平均损失 形成损失列表
total_acc_num = 0 # 已训练样本预测准确总数
total_acc_list = [] # 每100个样本求一次平均准确率 形成平均准确率列表
# 遍历(外层遍历轮次,内层遍历批次)
for epoch in range(epochs):
for x,y in tqdm(my_dataloader):
# 把数据送给模型
output, hidden, cn = lstm(x, lstm.inithidden(), lstm.inithidden())
# 计算损失
loss = criterion(output, y)
# print("loss-->", loss)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 梯度更新
optimizer.step()
# 参数纪录
# 纪录total_iter_num
total_iter_num += len(y)
total_loss += loss.item()
flag = (torch.argmax(output, dim=-1) == y).sum().item()
total_acc_num += flag
# 每隔100个样本纪录一下total_loss_list和total_acc_list,用于画图
if total_iter_num % 100 == 0:
# 计算平均损失
avg_loss = total_loss / total_iter_num
# 计算平均准确率
avg_acc = total_acc_num / total_iter_num
# 把平均损失和准确率纪录到列表中
total_loss_list.append(avg_loss)
total_acc_list.append(avg_acc)
# 每隔1000个样本打印日志
if total_iter_num % 1000 == 0:
avg_loss = total_loss / total_iter_num
total_time = time.time() - start_time
print("epoch:", epoch + 1, "loss:", avg_loss, "time:", total_time)
# 保存画图用的列表数据
spend_time = time.time() - start_time
data = {"total_loss_list" : total_loss_list, "total_acc_list" : total_acc_list, "spend_time" : spend_time}
with open('./data/lstm.json', mode='w', encoding='utf-8') as f:
f.write(json.dumps(data))
# 模型保存
torch.save(lstm.state_dict(), './save_model/lstm_%d.pth' % (epoch + 1))
def train_gru_model():
# 加载数据
list_x, list_y = read_data('./data/name_classfication.txt')
# 转换为Dataset
my_dataset = NameClassifyDataset(list_x, list_y)
# 转换为DataLoader
my_dataloader = DataLoader(dataset=my_dataset, shuffle=True, batch_size=1)
# 初始化模型
gru = MyGRU(input_size=n_letters, hidden_size=128, output_size=category_num, num_layers=1)
# 损失函数,这里只能是NLLLoss,因为forward函数中已经做了softmax计算了
criterion = nn.NLLLoss()
# 优化器,1e-3 = 0.001
optimizer = optim.Adam(params=gru.parameters(), lr=1e-3, betas=(0.9, 0.99))
# 轮次
epochs = 1
# 参数
start_time = time.time()
total_iter_num = 0 # 已训练的样本数
total_loss = 0.0 # 已训练的损失和
total_loss_list = [] # 每100个样本求一次平均损失 形成损失列表
total_acc_num = 0 # 已训练样本预测准确总数
total_acc_list = [] # 每100个样本求一次平均准确率 形成平均准确率列表
# 遍历(外层遍历轮次,内层遍历批次)
for epoch in range(epochs):
for x,y in tqdm(my_dataloader):
# 把数据送给模型
output, hidden = gru(x, gru.inithidden())
# 计算损失
loss = criterion(output, y)
# print("loss-->", loss)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 梯度更新
optimizer.step()
# 参数纪录
# 纪录total_iter_num
total_iter_num += len(y)
total_loss += loss.item()
flag = (torch.argmax(output, dim=-1) == y).sum().item()
total_acc_num += flag
# 每隔100个样本纪录一下total_loss_list和total_acc_list,用于画图
if total_iter_num % 100 == 0:
# 计算平均损失
avg_loss = total_loss / total_iter_num
# 计算平均准确率
avg_acc = total_acc_num / total_iter_num
# 把平均损失和准确率纪录到列表中
total_loss_list.append(avg_loss)
total_acc_list.append(avg_acc)
# 每隔1000个样本打印日志
if total_iter_num % 1000 == 0:
avg_loss = total_loss / total_iter_num
total_time = time.time() - start_time
print("epoch:", epoch + 1, "loss:", avg_loss, "time:", total_time)
# 保存画图用的列表数据
spend_time = time.time() - start_time
data = {"total_loss_list" : total_loss_list, "total_acc_list" : total_acc_list, "spend_time" : spend_time}
with open('./data/gru.json', mode='w', encoding='utf-8') as f:
f.write(json.dumps(data))
# 模型保存
torch.save(gru.state_dict(), './save_model/gru_%d.pth' % (epoch + 1))
def read_json_data(filename):
# 加载json文件数据
with open(filename, mode='r', encoding='utf-8') as f:
data = json.loads(f.read())
# 基于data数据,获取对应的指标结果
total_loss_list = data['total_loss_list']
total_acc_list = data['total_acc_list']
spend_time = data['spend_time']
# 返回结果数据
return total_loss_list, spend_time, total_acc_list
def draw_graph():
# 加载各个模型的数据
total_loss_list_rnn, total_time_rnn, total_acc_list_rnn = read_json_data('./data/rnn.json')
total_loss_list_lstm, total_time_lstm, total_acc_list_lstm = read_json_data('./data/lstm.json')
total_loss_list_gru, total_time_gru, total_acc_list_gru = read_json_data('./data/gru.json')
# 画图,3个模型的损失曲线变化图
plt.plot(total_loss_list_rnn, label='rnn')
plt.plot(total_loss_list_lstm, label='lstm', color='red')
plt.plot(total_loss_list_gru, label='gru', color='orange')
plt.legend(loc="best")
plt.savefig("./data/loss.png")
plt.show()
# 画图,3个模型的运行时间柱状图
x_data = ["RNN", "LSTM", "GRU"]
y_data = [total_time_rnn, total_time_lstm, total_time_gru]
# 绘制训练耗时对比柱状图
plt.bar(x_data, y_data, tick_label=x_data)
plt.savefig('./time.png')
plt.show()
# 画图,3个模型的准确率曲线变化图
plt.plot(total_acc_list_rnn, label='rnn')
plt.plot(total_acc_list_lstm, label='lstm', color='red')
plt.plot(total_acc_list_gru, label='gru', color='orange')
plt.legend(loc="best")
plt.savefig("./data/acc.png")
plt.show()
# TODO 4.模型评估(预测)
def line2tensor(name):
# 创建一个全零矩阵
tensor_x = torch.zeros(len(name), n_letters)
# 遍历,对name进行one-hot编码,把对应的位置改为1
for idx, letter in enumerate(name):
tensor_x[idx][all_letters.index(letter)] = 1
# 返回结果
return tensor_x
def predict_rnn_model(name):
# 对name(人名)数值化+张量化
tensor_x = line2tensor(name)
# print("tensor_x-->", tensor_x, tensor_x.shape) # [5, 57]
# 初始化模型
rnn = MyRNN(input_size=n_letters, hidden_size=128, output_size=category_num, num_layers=1)
# 加载模型的参数
rnn.load_state_dict(torch.load("./save_model/rnn_1.pth"))
# 设置模型为评估模式
rnn.eval()
# 把数据送给模型
# 我们设置了batch_first=True,所以升维只能在0维升 [1, 5, 57]
output, hidden = rnn(tensor_x.unsqueeze(0), rnn.inithidden())
print("output-->", output.shape)
# 获取结果
topv, topi = torch.topk(output, k=3)
# print("topv-->", topv) # [-0.6926, -1.9749, -2.1583]
# print("topi-->", topi) # [15, 17, 6]
for i in range(3):
# topi[0] -> [[15, 17, 6]] -> [15, 17, 6]
# topi[0][i] -> 15/17/6
idx = topi[0][i]
# print("idx-->", idx)
# 基于idx获取国家名
country = categorys[idx.item()]
print('name-->', name, "country-->", country)
def predict_lstm_model(name):
# 对name(人名)数值化+张量化
tensor_x = line2tensor(name)
# print("tensor_x-->", tensor_x, tensor_x.shape) # [5, 57]
# 初始化模型
lstm = MyLSTM(input_size=n_letters, hidden_size=128, output_size=category_num, num_layers=1)
# 加载模型的参数
lstm.load_state_dict(torch.load("./save_model/lstm_1.pth"))
# 设置模型为评估模式
lstm.eval()
# 把数据送给模型
# 我们设置了batch_first=True,所以升维只能在0维升 [1, 5, 57]
output, hidden, cn = lstm(tensor_x.unsqueeze(0), lstm.inithidden(), lstm.inithidden())
print("output-->", output.shape)
# 获取结果
topv, topi = torch.topk(output, k=3)
# print("topv-->", topv) # [-0.6926, -1.9749, -2.1583]
# print("topi-->", topi) # [15, 17, 6]
for i in range(3):
# topi[0] -> [[15, 17, 6]] -> [15, 17, 6]
# topi[0][i] -> 15/17/6
idx = topi[0][i]
# print("idx-->", idx)
# 基于idx获取国家名
country = categorys[idx.item()]
print('name-->', name, "country-->", country)
def predict_gru_model(name):
# 对name(人名)数值化+张量化
tensor_x = line2tensor(name)
# print("tensor_x-->", tensor_x, tensor_x.shape) # [5, 57]
# 初始化模型
gru = MyGRU(input_size=n_letters, hidden_size=128, output_size=category_num, num_layers=1)
# 加载模型的参数
gru.load_state_dict(torch.load("./save_model/gru_1.pth"))
# 设置模型为评估模式
gru.eval()
# 把数据送给模型
# 我们设置了batch_first=True,所以升维只能在0维升 [1, 5, 57]
output, hidden = gru(tensor_x.unsqueeze(0), gru.inithidden())
print("output-->", output.shape)
# 获取结果
topv, topi = torch.topk(output, k=3)
# print("topv-->", topv) # [-0.6926, -1.9749, -2.1583]
# print("topi-->", topi) # [15, 17, 6]
for i in range(3):
# topi[0] -> [[15, 17, 6]] -> [15, 17, 6]
# topi[0][i] -> 15/17/6
idx = topi[0][i]
# print("idx-->", idx)
# 基于idx获取国家名
country = categorys[idx.item()]
print('name-->', name, "country-->", country)
if __name__ == '__main__':
# test_read_data()
# test_name_classify_dataset()
# test_my_rnn()
# test_my_lstm()
# test_my_gru()
# test_my_rnn2()
train_rnn_model()
# train_lstm_model()
# train_gru_model()
# draw_graph()
predict_rnn_model('Zhong')
# print("*" * 20)
# predict_lstm_model("Zhong")
# print("*" * 20)
# predict_gru_model("Zhong")
 浙公网安备 33010602011771号
浙公网安备 33010602011771号