

【前瞻创想】Kurator:站在巨人肩膀上的分布式云原生创新实践 - 指南
引言
在云原生技术蓬勃发展的今天,企业面临着日益复杂的多云、混合云和边缘计算场景。如何有效管理分布式基础设施,实现应用的统一编排和治理,成为数字化转型的关键挑战。Kurator作为一个开源的分布式云原生平台,通过深度集成多个优秀的开源项目,为这些挑战提供了创新性的解决方案。
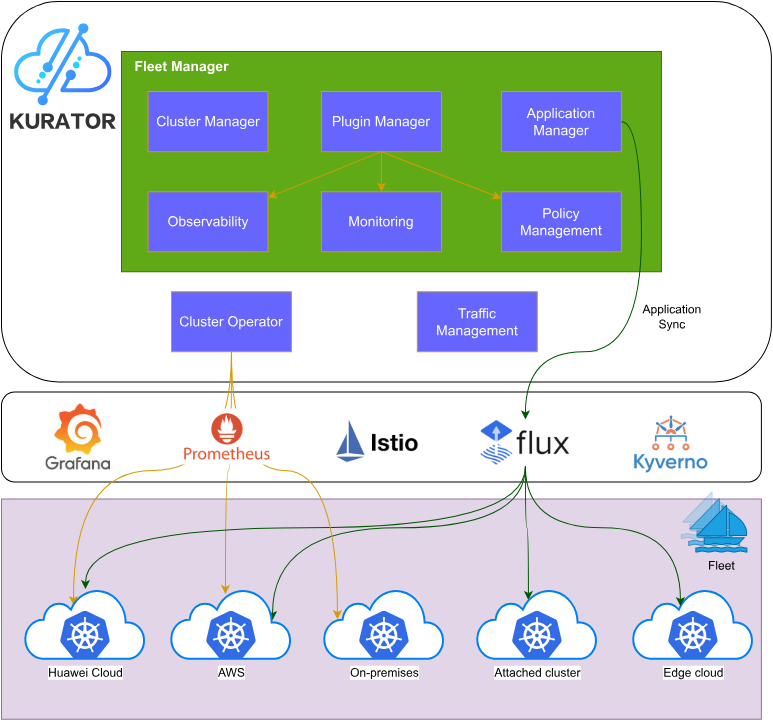
一、Kurator集成的开源项目生态
1.1 核心组件概览
Kurator构建在以下主流云原生项目之上:
容器编排层
- Kubernetes:作为容器编排的事实标准,提供基础的工作负载管理能力
- Karmada:实现多集群应用分发和调度的核心引擎
服务网格与流量管理
- Istio:提供服务间通信、安全和可观测性能力
边缘计算
- KubeEdge:扩展Kubernetes能力到边缘节点,实现云边协同
批处理与AI工作负载
- Volcano:专为高性能计算和机器学习优化的批处理调度系统
可观测性
- Prometheus:云原生监控和告警的标准方案
GitOps与持续交付
- FluxCD:实现声明式的应用交付和基础设施管理
策略管理
- Kyverno:Kubernetes原生的策略引擎
1.2 各组件的协同价值
这些项目各自在特定领域表现出色,但Kurator的价值在于将它们有机整合,形成完整的分布式云原生解决方案:
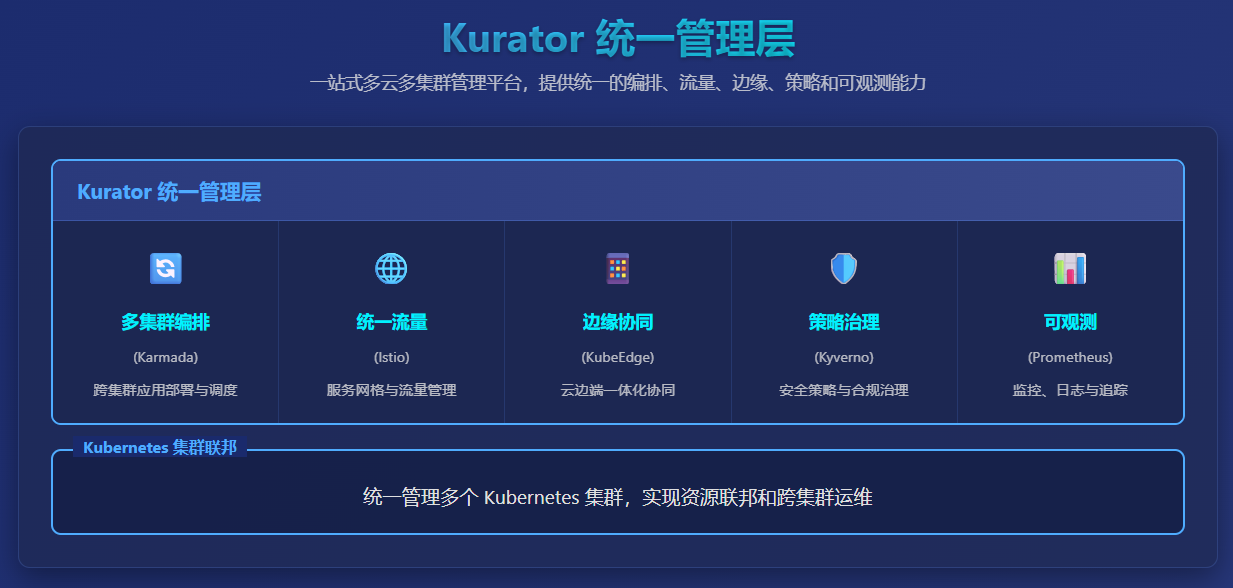
二、Kurator的创新优势分析
2.1 基础设施即代码的深度实践
创新点1:声明式全栈管理
传统IaC工具主要关注基础设施层面,而Kurator将这一理念延伸到整个云原生栈:
# 示例:一键部署完整的分布式应用环境
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: production-fleet
spec:
clusters:
- name: cloud-cluster
provider: aws
region: us-west-2
- name: edge-cluster
provider: kubeEdge
location: factory-01
addons:
- istio
- prometheus
- volcano
policies:
- name: security-baseline
engine: kyverno这种方式相比传统方案的优势:
- 一致性保证:所有集群使用相同的配置模板
- 版本控制:基础设施变更可追溯、可回滚
- 自动化程度高:减少人工干预和配置漂移
2.2 统一的多集群管理抽象
创新点2:Fleet概念的引入
Kurator创新性地提出"Fleet"(车队)概念,将多个集群视为一个逻辑单元:
传统方案:
集群A → 独立管理 → 应用部署A
集群B → 独立管理 → 应用部署B
集群C → 独立管理 → 应用部署C
Kurator方案:
Fleet(A+B+C) → 统一管理 → 应用自动分发核心优势:
统一资源视图
- 跨集群的命名空间一致性
- ServiceAccount的自动同步
- 服务发现的透明化
智能调度决策
apiVersion: apps.kurator.dev/v1alpha1 kind: Application spec: placement: clusterAffinity: - weight: 100 preference: matchExpressions: - key: region operator: In values: [us-west, eu-west] spreadConstraints: - maxSkew: 2 topologyKey: zone故障自愈能力
- 集群故障时自动迁移工作负载
- 基于Karmada的高级调度策略
2.3 云边端协同的创新实践
创新点3:三层架构的无缝整合
Kurator在KubeEdge基础上,实现了更完善的云边端协同:

关键创新:
分层流量管理
- 云端:Istio提供全局流量治理
- 边缘:EdgeMesh实现边缘侧服务网格
- 智能路由:根据网络状况自动选择最优路径
差异化资源管理
apiVersion: policy.kurator.dev/v1alpha1 kind: ResourceQuota spec: targets: - clusterSelector: matchLabels: type: edge quotas: cpu: "2" memory: "4Gi" - clusterSelector: matchLabels: type: cloud quotas: cpu: "32" memory: "128Gi"
2.4 统一可观测性的创新
创新点4:联邦式监控架构
Kurator整合Prometheus实现跨集群的统一监控:
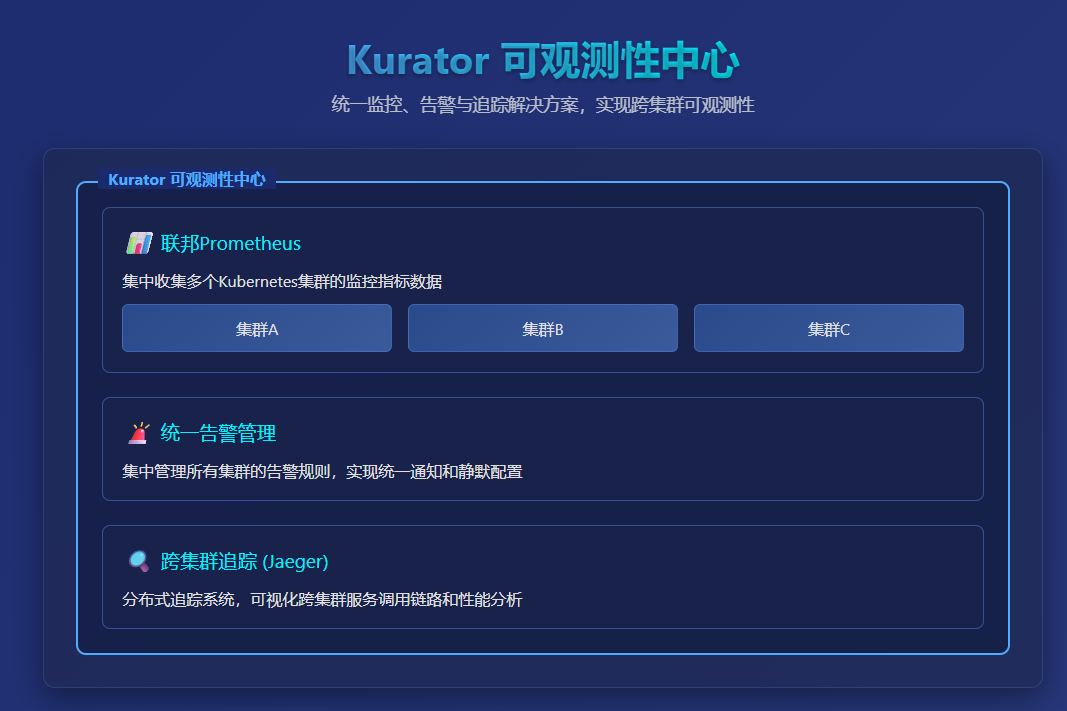
优势体现:
- 单一视图查看所有集群指标
- 跨集群的分布式追踪
- 智能告警聚合和去重
2.5 策略即代码的治理创新
创新点5:Kyverno策略的Fleet级应用
apiVersion: policy.kurator.dev/v1alpha1
kind: FleetPolicy
metadata:
name: security-baseline
spec:
# 应用到所有生产集群
clusterSelector:
matchLabels:
env: production
policies:
# 镜像安全策略
- apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-image-signature
spec:
validationFailureAction: enforce
rules:
- name: check-signature
match:
resources:
kinds:
- Pod
verifyImages:
- imageReferences:
- "*"
attestors:
- entries:
- keys:
publicKeys: |-
-----BEGIN PUBLIC KEY-----
...
-----END PUBLIC KEY-----创新价值:
- 策略的集中管理和分发
- 合规性的自动化保证
- 策略冲突的智能检测
三、相比传统方案的综合优势
3.1 降低运维复杂度
| 维度 | 传统多集群方案 | Kurator方案 |
|---|---|---|
| 集群管理 | 每个集群独立操作 | Fleet统一管理 |
| 应用部署 | 手动多次部署 | 一次定义,自动分发 |
| 监控告警 | 多套监控系统 | 统一可观测平台 |
| 策略管理 | 分散配置 | 集中治理 |
| 学习曲线 | 需掌握多个工具 | 统一API和CLI |
3.2 提升开发效率
开发者视角的对比:
传统方案:
1. 编写应用配置
2. 为每个集群调整配置
3. 逐个集群部署
4. 分别配置监控
5. 手动验证各集群状态
总耗时:约2-4小时
Kurator方案:
1. 编写Fleet级应用配置
2. 一键部署到所有集群
3. 自动配置监控和策略
4. 统一视图验证状态
总耗时:约15-30分钟3.3 增强系统可靠性
故障场景对比:
场景:某个区域的集群故障
传统方案:
1. 监控系统发现故障(5-10分钟)
2. 人工介入分析(10-30分钟)
3. 手动迁移工作负载(30-60分钟)
4. 更新DNS/负载均衡配置(10-20分钟)
总恢复时间:55-120分钟
Kurator方案:
1. 自动检测故障(1-2分钟)
2. Karmada自动重调度(2-5分钟)
3. Istio自动更新路由(1-2分钟)
4. 应用自动恢复服务(2-3分钟)
总恢复时间:6-12分钟四、对分布式云原生技术发展的建议
基于在云原生社区的参与经验,我对分布式云原生技术的发展提出以下建议:
4.1 标准化与互操作性
建议1:推动多集群管理标准的制定
当前各厂商的多集群方案各自为政,建议:
建立统一的多集群API标准
- 参考Kubernetes的成功经验
- 在CNCF层面推动标准化工作
- 确保不同实现间的互操作性
制定集群联邦的最佳实践
# 建议的标准化配置结构 apiVersion: multicluster.io/v1 kind: ClusterFederation metadata: name: global-federation spec: members: - cluster: cluster-a role: control-plane - cluster: cluster-b role: member policies: scheduling: karmada networking: istio observability: prometheus
4.2 边缘计算的深度整合
建议2:强化云边端的统一管理能力
边缘计算是未来趋势,但当前仍面临挑战:
网络不稳定场景的优化
- 开发更智能的离线工作模式
- 实现边缘侧的自主决策能力
- 优化数据同步策略
边缘资源的细粒度管理
# 建议增强的边缘节点管理 apiVersion: edge.kurator.dev/v1alpha1 kind: EdgeNodePool spec: selector: matchLabels: location: factory resources: cpu: "4" memory: "8Gi" gpu: "1" # 支持边缘AI autonomy: level: high # 高度自治 offlineMode: enabled: true cacheDuration: 24h
4.3 AI与云原生的融合
建议3:原生支持AI/ML工作负载
随着AI应用的普及,建议:
增强GPU等异构资源的调度
- Volcano已经在这方面做了很好的工作
- 需要更好地与多集群管理集成
- 支持跨集群的GPU资源池化
优化模型训练的分布式调度
apiVersion: batch.kurator.dev/v1alpha1 kind: DistributedTrainingJob spec: framework: pytorch workers: 8 placement: # 智能选择GPU资源最优的集群 strategy: gpu-optimized constraints: - gpu.type: A100 minGPUs: 8
4.4 安全性的全面提升
建议4:构建零信任的多集群安全架构
强化跨集群的身份认证
- 实现统一的身份管理
- 支持细粒度的RBAC
- 集成SPIFFE/SPIRE等标准
增强数据传输的安全性
apiVersion: security.kurator.dev/v1alpha1 kind: CrossClusterSecurity spec: encryption: inTransit: mTLS atRest: enabled compliance: standards: - PCI-DSS - GDPR auditLog: enabled: true retention: 90d
4.5 可观测性的智能化
建议5:引入AIOps能力
智能异常检测
- 利用机器学习识别异常模式
- 自动关联跨集群的事件
- 预测性维护
根因分析自动化
apiVersion: observability.kurator.dev/v1alpha1 kind: IntelligentMonitoring spec: aiops: enabled: true features: - anomalyDetection - rootCauseAnalysis - predictiveMaintenance alerting: smartGrouping: true autoRemediation: true
4.6 成本优化与FinOps
建议6:内置成本管理能力
多云环境下的成本控制至关重要:
实时成本可见性
- 按集群、命名空间、应用维度统计
- 跨云厂商的成本归一化
- 成本趋势分析和预测
智能资源优化
apiVersion: finops.kurator.dev/v1alpha1 kind: CostOptimization spec: budget: monthly: 10000 alertThreshold: 80% optimization: autoScaling: enabled: true strategy: cost-aware spotInstances: enabled: true maxPercentage: 50%
4.7 开发者体验的持续改进
建议7:降低使用门槛
提供更友好的CLI和UI
# 理想的用户体验 kurator init my-fleet kurator cluster add aws-prod --region us-west-2 kurator cluster add azure-prod --region westus kurator app deploy my-app --fleet my-fleet kurator app status my-app # 统一查看所有集群状态完善的文档和示例
- 按场景组织的快速入门指南
- 丰富的实战案例
- 交互式教程
4.8 社区生态的建设
建议8:加强开源社区协作
建立更开放的治理模式
- 吸引更多厂商和个人贡献者
- 设立技术指导委员会
- 定期举办社区会议和Meetup
培养生态系统
- 鼓励第三方插件开发
- 建立认证体系
- 提供商业支持选项
五、结语
Kurator通过深度整合Kubernetes、Istio、Karmada、KubeEdge、Volcano、Prometheus等优秀开源项目,不仅实现了"1+1>2"的协同效应,更在此基础上创新性地提出了Fleet管理、统一可观测性、云边端协同等理念,为分布式云原生技术的发展树立了新的标杆。
展望未来,分布式云原生技术将朝着更加标准化、智能化、安全化的方向发展。作为云原生社区的一员,我们应该:
- 积极参与标准制定,推动技术的互操作性
- 关注新兴场景,如边缘计算、AI/ML工作负载
- 提升安全性,构建零信任架构
- 优化用户体验,降低技术使用门槛
- 加强社区协作,共同推动生态繁荣
Kurator的成功实践告诉我们,开源协作的力量是无穷的。通过站在巨人的肩膀上,我们能够更快地创新,更好地服务于企业的数字化转型需求。让我们携手共建更加美好的云原生未来!
参考资料:
- Kurator官方文档:https://kurator.dev
- CNCF技术雷达
- Kubernetes多集群SIG工作组报告
- 边缘计算产业联盟白皮书

 浙公网安备 33010602011771号
浙公网安备 33010602011771号