

深度学习:高效处理语义分割的有限资料策略
处理语义分割中的有限数据
高效收集更多数据的策略,以针对表现不佳的模型和应采用的技术,以最大化数据的使用效率。在我们评估模型表现之后,我们通常会采取以下两种做法之一:
1.决定我们对模型在验证集上的表现感到满意,并在测试集(以及验证集)上报告模型性能。
2.从误报或漏报的角度诊断模型的问题,并制定提升表现不佳类别性能的计划。
提高模型性能,尤其是在深度学习中,最基本且影响深远的做法之一是增加训练数据集的总体规模,特别关注表现不佳的类别。然而,在遥感领域,获取高质量的训练数据标签既困难又耗时,这与其他领域相比尤为明显,因为在其他领域中,计算机视觉和机器学习技术被广泛应用。
由于在标注地理空间图像时存在这种独特的困难,我们需要做两件事:
1.仔细检查我们原始的标注数据集,寻找质量问题,例如由于日期不匹配而导致的与图像不符、类别标签错误以及标签边界不正确等问题。
2.权衡标注新标签的成本和收益,或尝试其他方法,以最大化我们已有数据对模型性能的提升。
本课的第一部分将描述设置标注活动时需要考虑的因素,同时注意数据质量问题。第二部分将介绍在标签质量充足的前提下,如何利用有限数据训练模型并最大化其性能的技术。
具体概念
第一部分:
- 如何在标注活动之前确定一个类别层次结构以及应向标注员提供哪些输入信息
- 如何高效地对地理空间图像进行语义分割(像素级分类)的标注
- 何时应该对实例分割(预测为向量)进行标注而不是语义分割(预测为栅格)
- 选择能够代表感兴趣类别的采样策略
第二部分:
- 迁移学习自预训练模型。我们将使用一个预训练的 U-net 模型,其主干网络为 Mobilenet 作为示例。
- 数据增强,或通过图像变换来扩充你的训练数据
受众:本文面向的是对基本机器学习概念有一定了解的中级用户。
第 1 部分:标注
决定标注哪些类别以及使用哪些影像作为底图
在遥感影像中标注感兴趣对象尤其具有挑战性。卫星图像可能难以解读,标注可能需要领域知识或训练。最适合标注的影像可能不是 RGB 格式。而且感兴趣对象的边界可能非常复杂,甚至与周围像素混合在一起。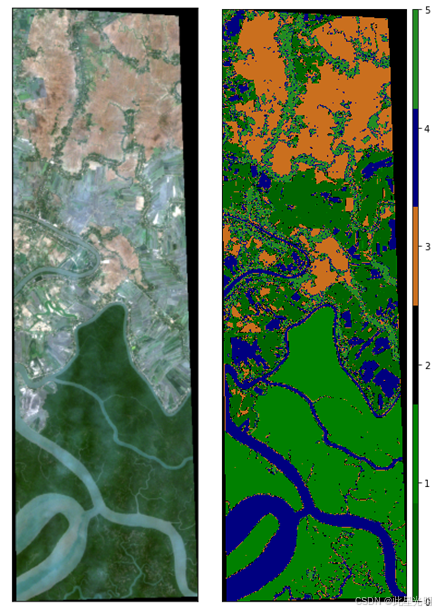
上述例子,孙德尔本斯国家公园中的红树林,说明了许多这些困难。虽然河流具有相对较清晰的边界,但图像中心的被淹没区域则更为复杂,许多不同的地表覆盖类型在紧密的环境中混合在一起。当查看左侧的图像时,设置标注的一些考虑因素包括:
应该有多少个类别?
- 我们应该识别在我们的影像中表现良好且我们关心的常见类别
- 如果某些类别是 1)罕见的,并且 2)我们不关心,我们可以将它们归入背景类别。然而,如果我们发现感兴趣的类别与不关心的罕见类别混淆,那么标注这个类别可能是值得的,以便更全面地测试模型的性能。
- 如果我们主要关注洪水森林的制图,我们可以优先标注洪水森林区域(忽略覆盖物的微小差异,例如略微更多的树冠区域)。另外,标注河流可能也是一个好主意,因为这个类别可能容易与洪水区域混淆。
这些类别应该具体到什么程度?
- 我们总是希望有一个理想的类别集合可以映射,但受限于可用数据,实际可行的类别可能有所不同
- 一些我们希望区分的类别,可能由于可用数据的光谱相似性而无法有效区分
- 如上图中的一个好例子可能是两种不同的红树林物种。使用 Landsat、Sentinel-2 或 Planet 影像,我们无法对自然生长的红树林树种进行物种级别的映射。
另一种说法是,标注人员在进行标注时,是否能在卫星图像中看到光谱或纹理信号? - 如果没有信号,我们要么需要采购更好的图像数据源,要么需要细化类别,使其更加通用,以适应数据的限制。
- 如果建模方法中使用了纹理信号,那么地面真实数据需要以多边形形式创建,而不是点。基于点的参考数据无法捕捉纹理信息,只能用于训练通用的机器学习算法,如随机森林或密集连接神经网络。卷积神经网络(CNNs)需要地面真实数据以多边形形式进行标注。
图像的时间戳是什么?所有标签都需要具有与标注所用图像相对应的正确时间戳元数据。
这有助于我们考虑机器学习模型是基于哪些时间段进行训练的,以及这些标签何时是相关的。如果建模方法需要结合时间序列数据,那么这些标签必须带有时间戳以构建模型。
处理语义分割(像素级分类)地理空间图像的高效标注技巧
在进行标注活动时,还需要考虑的是:我们的标注人员是否能够准确且高效地标注我们优先的类别。让我们考虑一个例子,我们想要绘制城市中的树木覆盖、建筑物和停车场。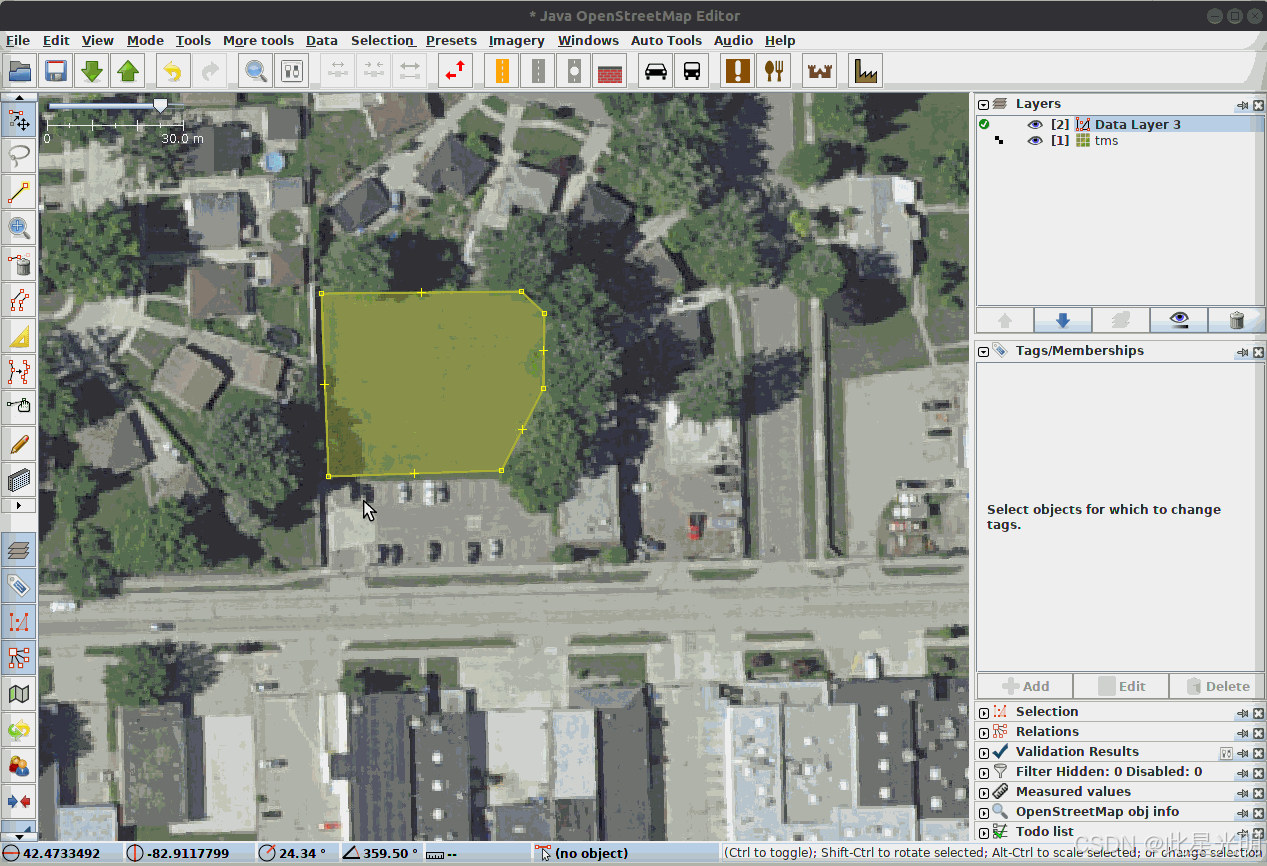
LULC 类别通常会直接相邻。因此,在支持将边与现有标注对齐并同时编辑的平台上进行标注会非常有帮助,如图所示。背景类别不需要手动标注。
这也是一个好习惯,即记录标注人员标注特定区域所需的时间,以便评估标注一组类别的成本和效益。这可以帮助你决定是否需要将一个区域划分为更小的任务,让多个标注人员协作完成某个 AOI 的标注。
标注结果应由某些监督者/专家进行审核,以评估质量、诊断问题,并与标注人员合作,将他们的反馈纳入考虑,可能调整任务或改进在标注任务前给予标注人员的指导。
当标注实例分割(预测为向量)比语义分割(预测为栅格)更有意义时
语义分割
语义分割(Semantic Segmentation)是一种将图像中的每个像素分类到特定语义类别的技术,属于像素级分类任务。它不区分同类物体的不同实例,仅关注像素的语义标签(如“人”“车”“天空”)。典型应用包括场景理解、自动驾驶中的道路分割等。常见算法包括FCN、U-Net、DeepLab系列。可以简单的认为,这个像素属于哪个类别。
实例分割
实例分割(Instance Segmentation)结合了语义分割和目标检测的特点,不仅区分像素的语义类别,还需识别同一类别中的不同个体(如区分图像中的多只猫)。其输出为每个实例的像素级掩膜及类别标签。代表性方法有Mask R-CNN、YOLACT等,常用于医学图像分析、机器人抓取等需精确对象定位的场景。在语义分割的基础上,具体需要识别该图像内的物体分割。
U-net 和其他语义分割模型的输出告诉您单个像素的类别概率(或一组类别概率)。如果您想估计停车场的总面积,或了解所有停车场像素的位置,语义分割就足够了。
然而,如果你想统计停车场(或农田或矿场)的数量,并了解各个停车场的位置和范围,则需要采用实例分割的方法。实例分割方法的输出不仅告诉你每个像素的类别概率,还能告诉你该像素属于哪个对象。
有许多方法可以得到实例分割的输出。一些深度学习模型,如 Mask R-CNN,会训练一个模型,从栅格输入直接输出实例分割结果(这可以看作是向量或多边形坐标)。另一种方法是通过对语义分割模型的结果进行后处理,从类别概率图或类别 ID 图中勾勒出多边形边界。
选择一个能代表感兴趣类别的采样策略
遥感中的检测问题具有独特性,因为很多时候我们处理的是非常大的、数百万像素的图像,但关注的是小目标。因此,对标注区域进行采样非常重要,以确保我们能够捕捉到我们关心检测的各类目标的大量实例。在 AOI 内随机选取瓦片的简单采样方法很可能不是正确的方法,因为它会导致我们感兴趣类别的样本不足,从而产生类别不平衡的问题。
在这种情况下,莉莉的感兴趣区域(AOI)是整个海洋。对整个海洋,甚至所有海岸线或主要洋流进行简单的随机抽样,都会导致背景类别的样本数量过多。因此,我们根据地理定位的海洋垃圾报告来有针对性地标注区域。DevSeed 在很多项目中采用的方法是尽可能多地开发感兴趣主要类别的代表性样本,同时还要开发一些看起来像目标类别的困难负样本。然后我们控制训练集中引入的“简单负样本”的数量,以最小化类别不平衡的问题。
负样本的定义与作用
在深度学习中,负样本是指与目标任务无关或属于错误类别的数据样本,用于帮助模型区分正样本(目标类别)与其他无关类别。例如,在二分类任务中,正样本代表目标类别(如“猫”),负样本则代表非目标类别(如“狗”或背景)。通过同时学习正负样本的特征差异,模型能够更准确地分类或检测目标,避免过拟合或误判。负样本的合理选择对模型的泛化能力和鲁棒性至关重要。本质上就是告诉对方,图像长成这样的就不是我们要预测的。
第 2 部分:处理有限数据的技术
现在我们将转向学习一些技术,以放大我们已有数据的影响,假设我们已经考虑了上述所有问题。首先,我们将确保已安装并导入所需的库。
# 安装所需的软件包
!pip install -q -U tfds-nightly
!pip install -q focal-loss==0.0.7
#!pip install -q matplotlib==3.5 # UNCOMMENT if running on LOCAL
!pip install -q scikit-learn==1.2.2
!pip install -q scikit-image==0.19.3
!pip install -U -q segmentation-models==1.0.1
!pip install -q tensorflow==2.2.1
!pip install -q keras==2.5
!pip install -q albumentations==1.2.1# 导入必要的库
import os, functools # 操作系统接口和函数工具库
# 设置环境变量,确保segmentation_models库使用tensorflow的keras
os.environ["SM_FRAMEWORK"] = "tf.keras"
import tensorflow as tf # 深度学习框架
import tensorflow_datasets as tfds # TensorFlow数据集工具
tfds.disable_progress_bar() # 禁用数据加载进度条
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 绘图库
import matplotlib as mpl # 绘图配置库
mpl.rcParams['axes.grid'] = False # 关闭坐标轴网格
mpl.rcParams['figure.figsize'] = (12,12) # 设置默认图形大小
import pandas as pd # 数据处理库
import skimage.io as skio # 图像I/O库
from IPython.display import clear_output # 用于清除输出(通常在Jupyter中使用)
import segmentation_models as sm # 图像分割模型库
from focal_loss import SparseCategoricalFocalLoss # 用于处理类别不平衡的焦点损失函数
# 数据增强库
from albumentations import (
Compose, Blur, HorizontalFlip, VerticalFlip,
Rotate, ChannelShuffle
)
# 设置文件夹路径
if 'google.colab' in str(get_ipython()):
# 如果是Google Colab环境
# 挂载Google Drive
drive.mount('/content/gdrive')
# 设置处理后的输出目录(在Google Drive中)
processed_outputs_dir = '/content/gdrive/My Drive/tf-eo-devseed-processed-outputs/'
# 设置用户输出目录
user_outputs_dir =
 浙公网安备 33010602011771号
浙公网安备 33010602011771号