
完整教程:人工智能之数据分析 Pandas:第八章 数据可视化
人工智能之数据分析 Pandas
第八章 数据可视化
前言
本文将从 基础绘图方法、常用图表类型、高级定制、与专业库对比 四个维度,系统、详细、实战化地介绍 Pandas 数据可视化的完整能力。
一、Pandas 可视化基础
1. 核心原理
- Pandas 的
.plot()是 Matplotlib 的封装,返回matplotlib.axes.Axes对象 - 所有 DataFrame/Series 都可直接调用
.plot() - 语法简洁,适合快速查看数据分布、趋势、关系
2. 启用绘图支持(通常自动加载)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 在 Jupyter 中显示图形(非必须,但推荐)
%matplotlib inline二、Series 与 DataFrame 基础绘图
1. Series 绘图(一维数据)
s = pd.Series(np.random.randn(10).cumsum(), index=pd.date_range('2025-01-01', periods=10))
# 默认折线图
s.plot()
plt.title('Series 折线图')
plt.show()
2. DataFrame 绘图(多列数据)
df = pd.DataFrame(
np.random.randn(10, 4),
columns=['A', 'B', 'C', 'D'],
index=pd.date_range('2025-01-01', periods=10)
)
# 默认:每列一条线(折线图)
df.plot()
plt.title('DataFrame 多列折线图')
plt.show()
三、常用图表类型(通过 kind 参数指定)
| 图表类型 | kind 值 | 适用场景 |
|---|---|---|
| 折线图 | 'line' | 时间序列、趋势 |
| 柱状图 | 'bar' | 分类比较(垂直) |
| 水平柱状图 | 'barh' | 类别名较长时 |
| 直方图 | 'hist' | 数值分布 |
| 箱线图 | 'box' | 分布与异常值 |
| 密度图 | 'kde' / 'density' | 平滑分布估计 |
| 面积图 | 'area' | 累计贡献 |
| 散点图 | 'scatter' | 两变量关系 |
| 六边形图 | 'hexbin' | 大量散点密度 |
✅ 所有图表都可通过
df.plot(kind='xxx')或df.plot.xxx()调用
四、详细图表示例与参数说明
1. 折线图(Line Plot)— 默认图表
df.plot(
kind='line',
title='销售额趋势',
xlabel='日期',
ylabel='金额(万元)',
figsize=(10, 6),
grid=True,
style=['-', '--', '-.', ':'] # 线型
)
plt.show()
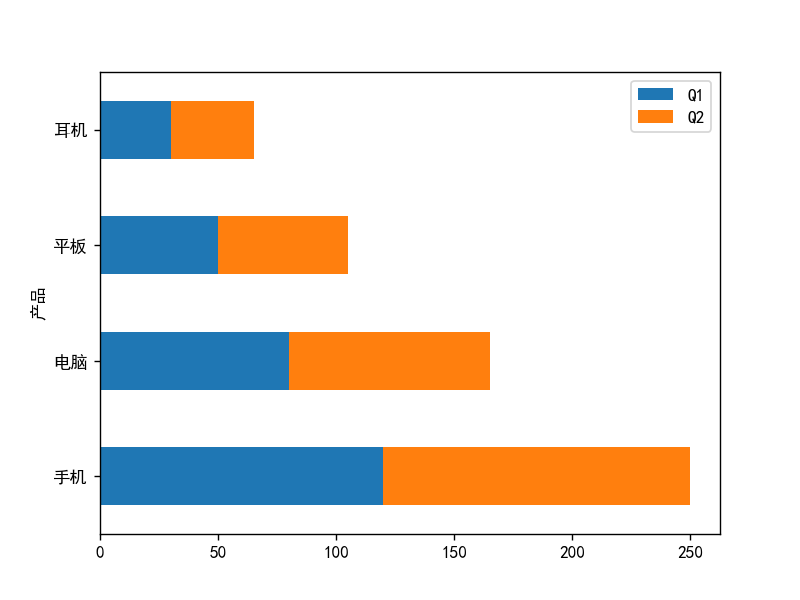
2. 柱状图(Bar Plot)
# 分类数据示例
sales = pd.DataFrame({
'产品': ['手机', '电脑', '平板', '耳机'],
'Q1': [120, 80, 50, 30],
'Q2': [130, 85, 55, 35]
}).set_index('产品')
# 垂直柱状图(默认)
sales.plot(kind='bar', figsize=(8, 5), title='各产品季度销量')
plt.xticks(rotation=0) # 横轴标签不旋转
plt.show()
# 水平柱状图
sales.plot(kind='barh', stacked=True) # 堆叠
plt.show()
3. 直方图(Histogram)— 查看分布
df['A'].plot(kind='hist', bins=20, alpha=0.7, title='A 列数据分布')
plt.show()
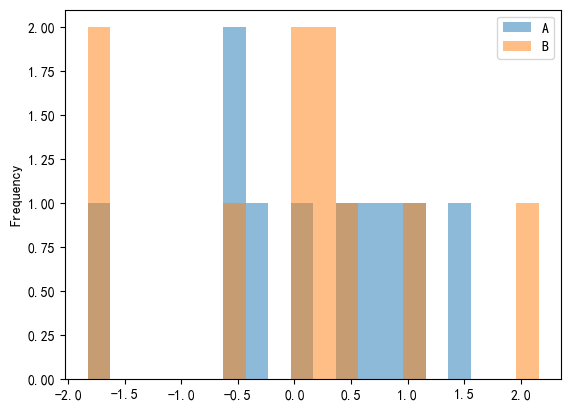
# 多列直方图(重叠)
df[['A', 'B']].plot.hist(alpha=0.5, bins=20)
plt.show()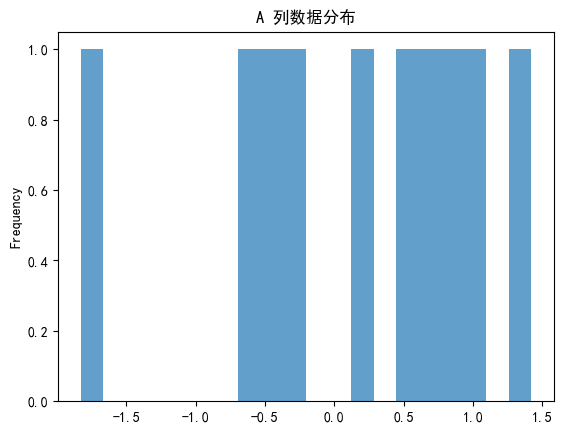
4. 箱线图(Box Plot)— 查看分布与异常值
df.plot(kind='box', title='各列数据分布箱线图')
plt.ylabel('数值')
plt.show()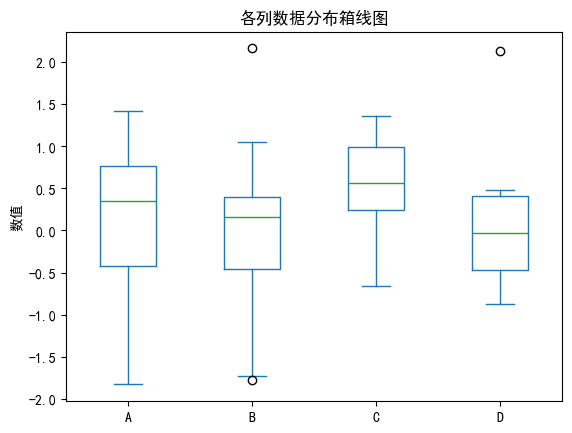
5. 散点图(Scatter Plot)— 两变量关系
# 需指定 x 和 y 列
df.plot(
kind='scatter',
x='A',
y='B',
c='C', # 颜色映射第三列
colormap='viridis',
title='A vs B (颜色=C)'
)
plt.show()
6. 面积图(Area Plot)— 累计贡献
df = df.abs()
df.plot(kind='area', stacked=True, alpha=0.7, title='累计贡献')
plt.show()
7. 密度图(KDE)— 平滑分布
df['A'].plot(kind='kde', title='A 列核密度估计')
plt.show()
⚙️ 五、通用绘图参数(适用于所有图表)
| 参数 | 说明 | 示例 |
|---|---|---|
figsize | 图形大小(宽, 高) | figsize=(10, 6) |
title | 图表标题 | title='销售分析' |
xlabel / ylabel | 坐标轴标签 | xlabel='月份' |
grid | 显示网格 | grid=True |
legend | 显示图例 | legend=True(默认) |
color | 颜色 | color=['red', 'blue'] |
alpha | 透明度(0~1) | alpha=0.5 |
rot | x 轴标签旋转角度 | rot=45 |
六、高级技巧与组合图
1. 子图(Subplots)
# 每列一个子图
df.plot(subplots=True, layout=(2, 2), figsize=(10, 8))
plt.tight_layout()
plt.show()
2. 双 Y 轴(用于不同量纲)
ax = df['A'].plot(figsize=(10, 6), color='blue', label='A')
ax2 = ax.twinx() # 共享 x 轴
df['B'].plot(ax=ax2, color='red', label='B')
ax.set_ylabel('A 值', color='blue')
ax2.set_ylabel('B 值', color='red')
plt.title('双 Y 轴图')
plt.show()
⚠️ 注意:Pandas 原生不支持
secondary_y在.plot()中直接使用(旧版本支持),建议用上述 Matplotlib 方式。
3. 分组柱状图(需数据重塑)
# 将宽表转为长表(便于分组)
sales_long = sales.reset_index().melt(id_vars='产品', var_name='季度', value_name='销量')
print(sales_long)
# 使用 Seaborn 更方便(见下文对比)
plt.figure(figsize=(10, 6))
sns.barplot(x='产品', y='销量', hue='季度', data=sales_long)
plt.title('各产品季度销量')
plt.show()
七、Pandas vs 专业可视化库
| 功能 | Pandas | Seaborn | Plotly |
|---|---|---|---|
| 易用性 | ⭐⭐⭐⭐⭐(极简) | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 统计图表 | 基础 | ⭐⭐⭐⭐⭐(箱线、小提琴等) | ⭐⭐⭐ |
| 美观度 | 一般(可定制) | ⭐⭐⭐⭐⭐(默认美观) | ⭐⭐⭐⭐⭐(交互式) |
| 交互性 | ❌ | ❌ | ⭐⭐⭐⭐⭐ |
| 大数据性能 | 一般 | 一般 | 较好(WebGL) |
| 适用场景 | 快速 EDA | 发表级静态图 | 仪表盘、Web 应用 |
✅ 推荐使用策略:
- 探索阶段:用 Pandas 快速画图
- 报告/论文:用 Seaborn 美化
- 交互展示:用 Plotly/Dash
示例:相同图表用 Seaborn 更简洁美观
import seaborn as sns
# 散点图 + 回归线
sns.scatterplot(data=df, x='A', y='B', hue='C')
sns.regplot(data=df, x='A', y='B', scatter=False)
plt.show()
# 箱线图(按类别)
sns.boxplot(data=sales_long, x='产品', y='销量', hue='季度')
plt.show()️ 八、常见问题与解决方案
1. 中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号2. 图形不显示(Jupyter 外)
plt.show() # 必须调用3. 时间序列 X 轴格式混乱
df.plot()
plt.gca().xaxis.set_major_formatter(plt.matplotlib.dates.DateFormatter('%Y-%m'))
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()4. 颜色自定义
df.plot(color=['#FF5733', '#33FF57', '#3357FF'])✅ 九、总结:Pandas 可视化最佳实践
| 场景 | 推荐做法 |
|---|---|
| 快速查看趋势 | df.plot()(折线图) |
| 比较分类数据 | df.plot.bar() |
| 检查数据分布 | df.plot.hist() 或 df.plot.kde() |
| 发现变量关系 | df.plot.scatter(x, y) |
| 检测异常值 | df.plot.box() |
| 需要美观/发表 | 转用 Seaborn |
| 需要交互 | 转用 Plotly |
记住:
Pandas 可视化 = 快速探索的“瑞士军刀”,
不是最终交付工具,但能极大提升分析效率!
后续
python过渡项目部分代码已经上传至gitee,后续会逐步更新。
资料关注
公众号:咚咚王
gitee:https://gitee.com/wy18585051844/ai_learning
《Python编程:从入门到实践》
《利用Python进行数据分析》
《算法导论中文第三版》
《概率论与数理统计(第四版) (盛骤) 》
《程序员的数学》
《线性代数应该这样学第3版》
《微积分和数学分析引论》
《(西瓜书)周志华-机器学习》
《TensorFlow机器学习实战指南》
《Sklearn与TensorFlow机器学习实用指南》
《模式识别(第四版)》
《深度学习 deep learning》伊恩·古德费洛著 花书
《Python深度学习第二版(中文版)【纯文本】 (登封大数据 (Francois Choliet)) (Z-Library)》
《深入浅出神经网络与深度学习+(迈克尔·尼尔森(Michael+Nielsen)》
《自然语言处理综论 第2版》
《Natural-Language-Processing-with-PyTorch》
《计算机视觉-算法与应用(中文版)》
《Learning OpenCV 4》
《AIGC:智能创作时代》杜雨+&+张孜铭
《AIGC原理与实践:零基础学大语言模型、扩散模型和多模态模型》
《从零构建大语言模型(中文版)》
《实战AI大模型》
《AI 3.0》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号